您好!
欢迎来到京东云开发者社区
登录
首页
博文
课程
大赛
工具
用户中心
开源
首页
博文
课程
大赛
工具
开源
更多
用户中心
开发者社区
>
博文
>
线上FullGC问题排查实践——手把手教你排查线上问题
分享
打开微信扫码分享
点击前往QQ分享
点击前往微博分享
点击复制链接
线上FullGC问题排查实践——手把手教你排查线上问题
RyanHan
2023-04-28
IP归属:北京
3316浏览
## 一、问题发现与排查 ### 1.1 找到问题原因 问题起因是我们收到了jdos的容器CPU告警,CPU使用率已经达到104% <img src="https://s2.loli.net/2023/04/21/YSjctzhJGagNXi5.png" alt="image-20230421152602849" style="zoom:50%;" /> 观察该机器日志发现,此时有很多线程在执行跑批任务。正常来说,跑批任务是低CPU高内存型,所以此时考虑是FullGC引起的大量CPU占用(之前有类似情况,告知用户后重启应用后解决问题)。 通过泰山查看该机器内存使用情况: 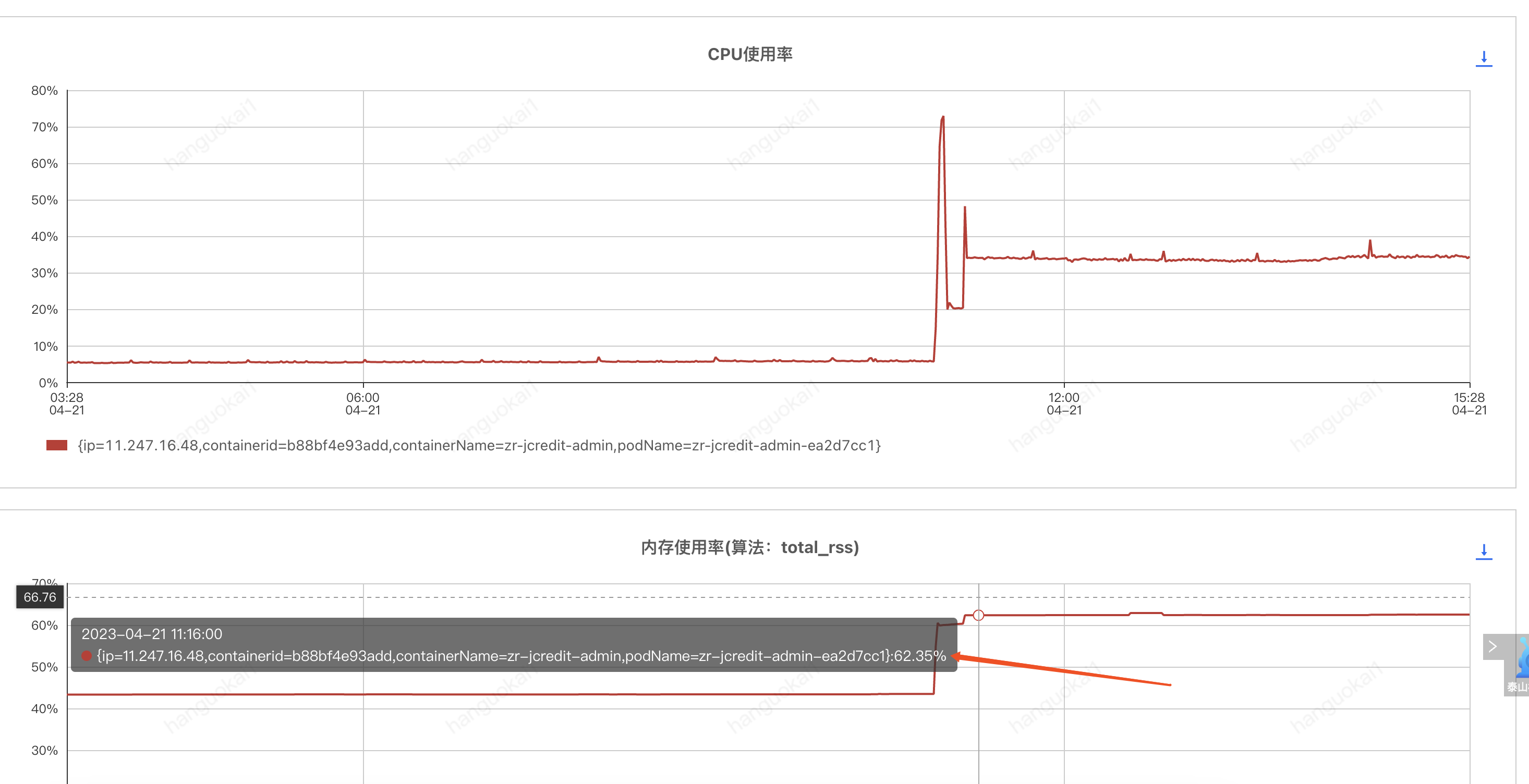 可以看到CPU确实使用率偏高,**但是内存使用率并不高,只有62%,**属于正常范围内。 到这里其实就有点迷惑了,按道理来说此时内存应该已经打满才对。 后面根据其他指标,例如流量的突然进入也怀疑过是jsf接口被突然大量调用导致的cpu占满,所以内存使用率不高,不过后面都慢慢排除了。其实在这里就有点一筹莫展了,现象与猜测不符,只有CPU增长而没有内存增长,**那么什么原因会导致单方面CPU增长?**然后又朝这个方向排查了半天也都被否定了。 后面突然意识到,**会不会是监控有“问题”?** 换句话说应该是我们看到的监控有问题,这里的监控是机器的监控,而不是JVM的监控! JVM的使用的CPU是在机器上能体现出来的,而JVM的堆内存高额使用之后在机器上体现的并不是很明显。 遂去sgm查看对应节点的jvm相关情况: 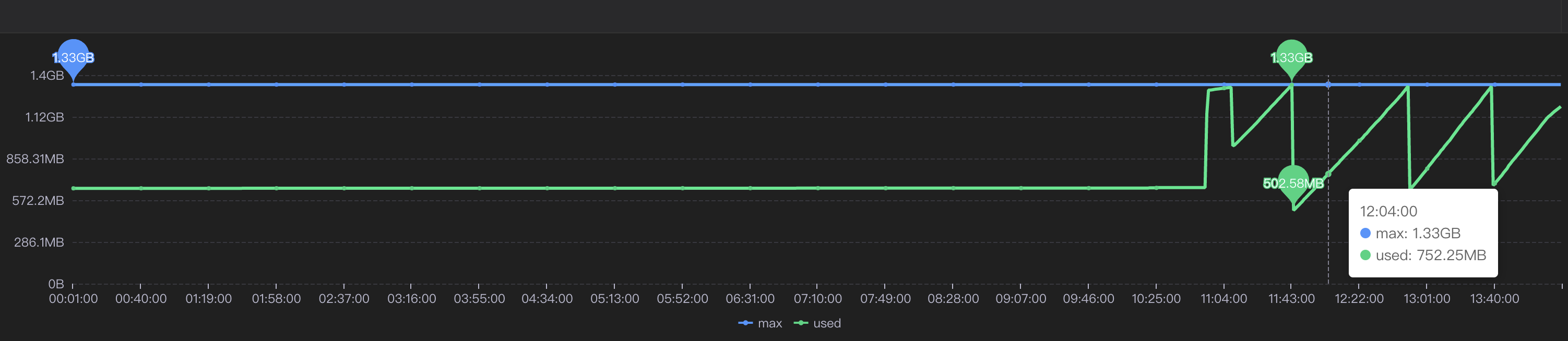 可以看到我们的堆内存老年代确实有过被打满然后又清理后的情况,查看此时的CPU使用情况也可以与GC时间对应上。 那么此时可以确定,是Full GC引起的问题。 ### 1.2 找到FULL GC的原因 我们首先dump出了gc前后的堆内存快照, 然后使用**JPofiler**进行内存分析。(JProfiler是一款堆内存分析工具,可以直接连接线上jvm实时查看相关信息,也可以分析dump出来的堆内存快照,对某一时刻的堆内存情况进行分析) 首先将我们dump出来的文件解压,修改后缀名`.bin`,然后打开即可。(我们使用行云上自带的dump小工具,也可以自己去机器上通过命令手工dump文件) 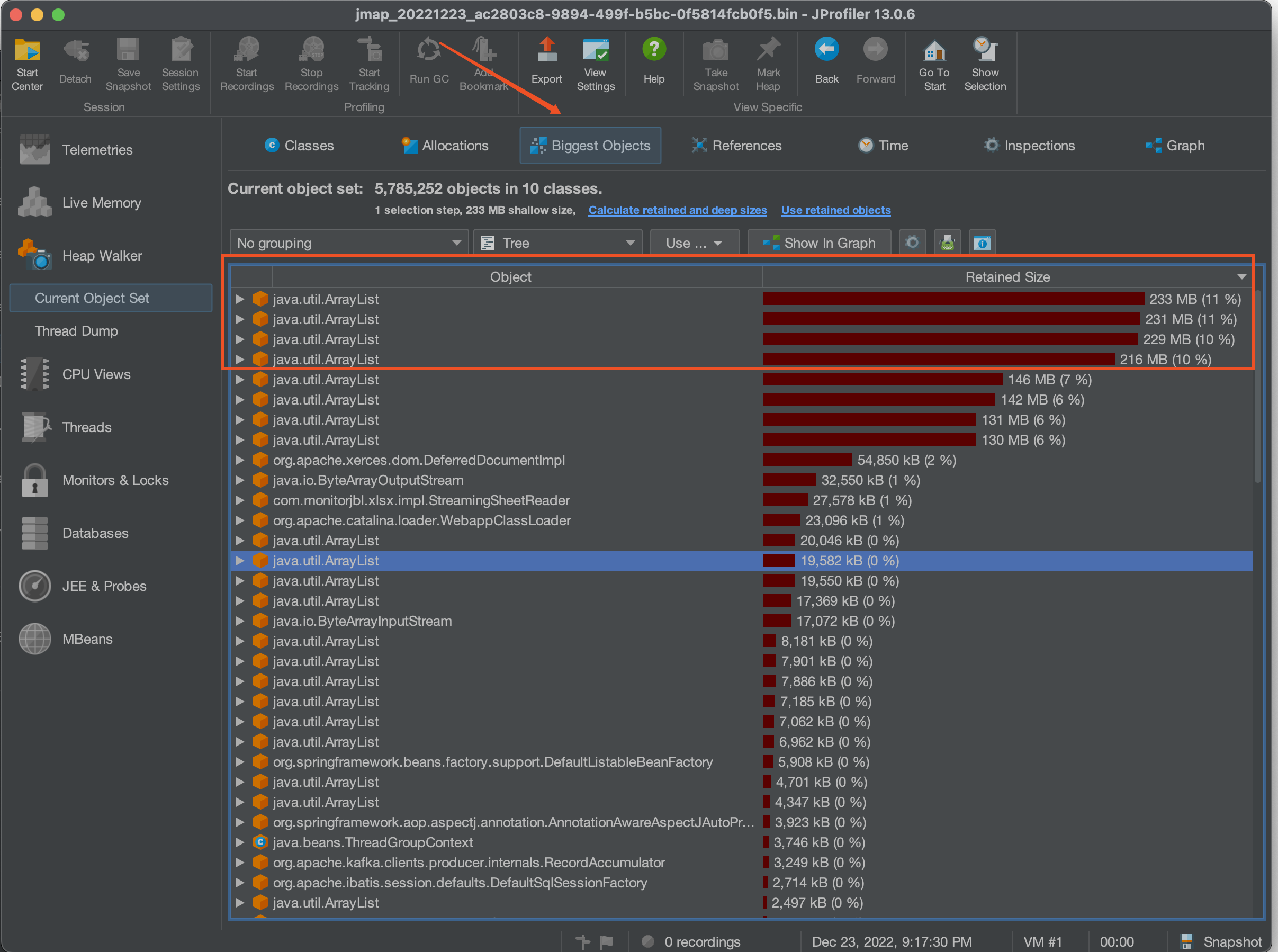 首先选择Biggest Objects,查看当时堆内存中最大的几个对象。 从图中可以看出,四个List对象就占据了**近900MB的内存**,而我们刚刚看到堆内存最大也只有1.3GB,因此再加上其他的对象,很容易就会把老年代占满引发full gc的问题。  选择其中一个**最大的对象作为我们要查看的对象** 这个时候我们已经可以定位到对应的大内存对象对应的位置: 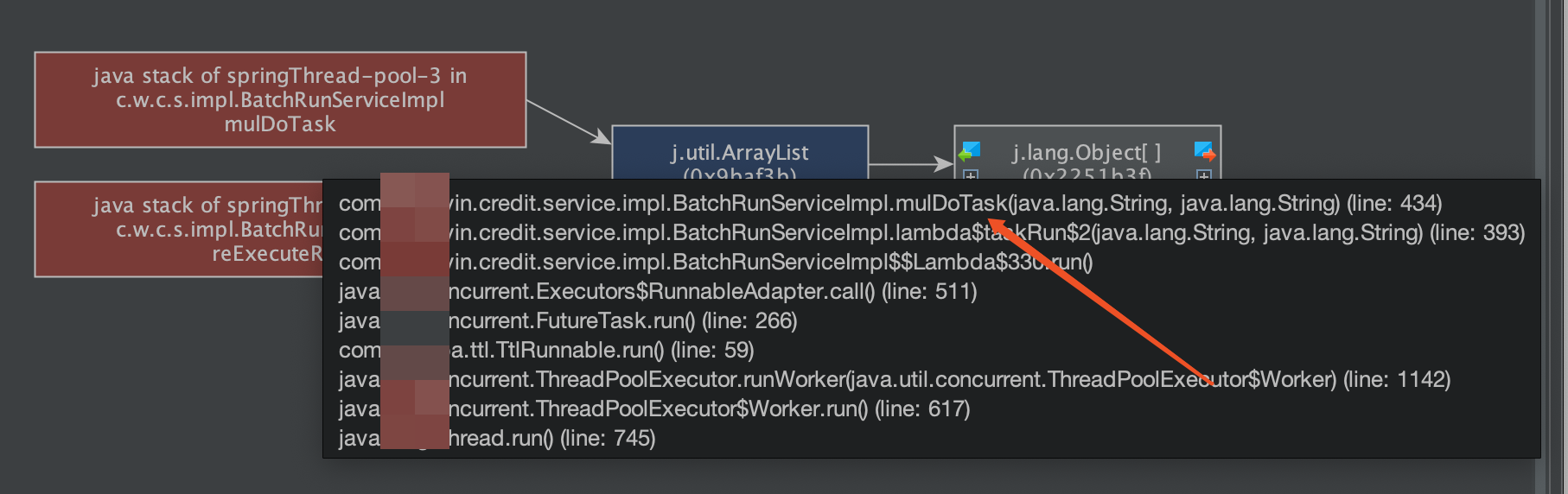 其实至此我们已经能够大概定位出问题所在,如果还是不确定的话,可以查看具体的对象信息,方法如下: 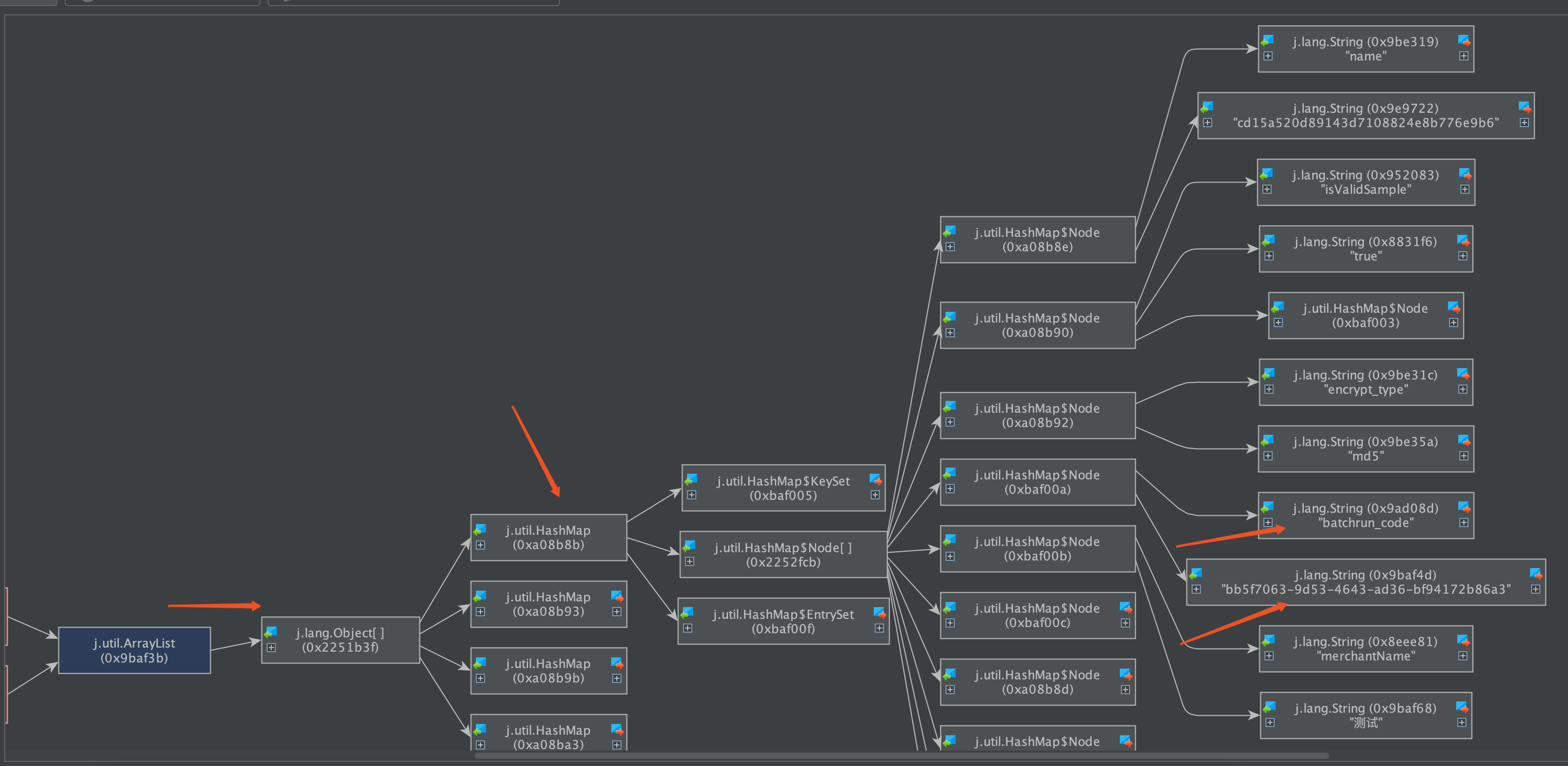 可以看到我们的大List对象,其实内部是很多个Map对象,而每个Map对象中又有很多键值对。 在这里也可以看到Map中的相关属性信息。 也可以在以下界面直接看到相关信息:  然后一路点下去就可以看到对应的属性。 至此,我们理论上已经找到了大对象在代码中的位置。 ## 二、问题解决 ### 2.1 找到大对象在代码中的位置与问题的根本原因 首先我们根据上述过程找到对应位置与逻辑 我们的项目中大概逻辑是这样的: 1. 首先会解析用户上传的Excel样本,并将其加载到内存中作为一个List变量,即我们上述看到的变量。一个20w的样本,此时字段数量有a个,大概占用空间100mb左右。 2. 然后遍历循环用户样本,根据用户样本中的数据,**再增加一些额外的请求数据**,根据此数据请求相关结果。此时字段数量有a+n个,占用空间已经在200mb左右。 3. 循环完成后将此200mb的数据存入缓存。 4. 开始生成excel,将200mb数据从缓存中取出,并根据之前记录的a个字段,取出初始的样本字段填充至excel。 用流程图表示为: 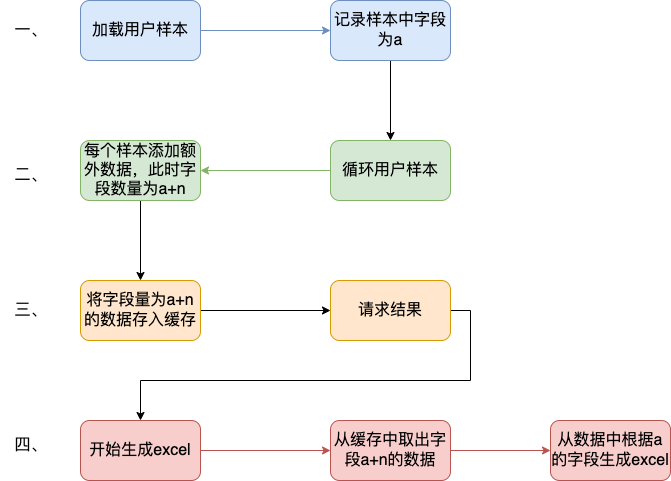 结合一些具体排查问题的图片: 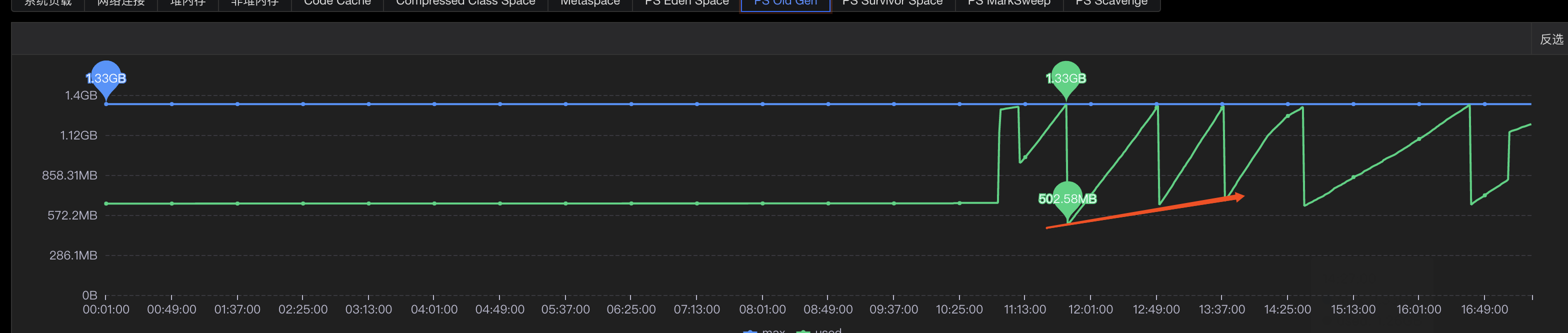 其中一个现象是每次gc后的最小内存正在逐步变大,对应上述步骤中第二步,内存正在逐步膨胀。 **结论**: 将用户上传的excel样本加载到内存中,并将其作为一个`List<Map<String, String>>`的结构存储起来,**首先一个20mb的excel文件以此方式存储会膨胀占用120mb左右堆内存**,此步骤会大量占用堆内存,**并且因为任务逻辑原因,该大对象内存会在jvm中存在长达4-12小时之久**,导致一但任务过多,jvm堆内存很容易被打满。 这里列举了为什么使用HashMap会导致内存膨胀,其主要原因是存储空间效率比较低: > 一个Long对象占内存计算:在HashMap<Long,Long>结构中,只有Key和Value所存放的两个长整型数据是有效数据,共16字节(2×8字节)。这两个长整型数据包装成java.lang.Long对象之后,就分别具有8字节的MarkWord、8字节的Klass指针,再加8字节存储数据的long值(一个包装对象占24字节)。 > > 然后这2个Long对象组成Map.Entry之后,又多了16字节的对象头(8字节MarkWord+8字节Klass指针=16字节),然后一个8字节的next字段和4字节的int型的hash字段(8字节next指针+4字节hash字段+4字节填充=16字节),为了对齐,还必须添加4字节的空白填充,最后还有HashMap中对这个Entry的8字节的引用,这样增加两个长整型数字,实际耗费的内存为(Long(24byte)×2)+Entry(32byte)+HashMapRef(8byte)=88byte,空间效率为有效数据除以全部内存空间,即16字节/88字节=18%。 > > ——《深入理解Java虚拟机》5.2.6 以下是刚上传的excel中dump出的堆内存对象,其占用的内存达到了128mb,而上传的excel实际只有17.11mb。   **空间效率17.1mb/128mb≈13.4%** ### 2.2 如何解决此问题 暂且不讨论上述流程是否合理,解决办法一般可以分为两类,**一类是治本**,即不把**该对象放入jvm内存中**,转而存入缓存中,不在内存中则大对象问题自然迎刃而解。**另一类是治标**,即缩小该大内存对象,在日常使用场景下使其一般不会触发频繁的full gc问题。 两种方式各有优劣: #### 2.2.1 激进治疗:不把他存入内存 解决逻辑也很简单,例如在加载数据时,将其按照样本加载数据一条一条存入redis缓存,然后我们只需要知道样本中有多少的数量,按照数量的先后顺序从缓存中取出数据,即可解决该问题。 优点:可以从根本上解决此问题,以后基本上不会存在该问题,数据量再大只需要添加相应的redis资源即可。 缺点:首先会增加许多redis缓存空间消耗,其次从显示考虑对于我们项目来说,此处代码古老且晦涩难懂,改动需要较大工作量与回归测试。 <img src="https://s2.loli.net/2023/04/21/ePNYzHcmU5dBwJD.png" alt="伏羲运营后台fullgc-第 2 页.drawio" /> #### 2.2.2 保守治疗:缩减其数据量 分析2.1的上述流程,首先第三步是完全没必要的,先存入缓存再取出,额外占用缓存空间。(猜测系历史问题,此处不再深究)。 其次是在第二步中,多出来的字段n,在请求结束后该字段就已经无用了,因此可以考虑在请求结束后删除无用字段。 此时也有两种解决方案,一种是**只删除无用字段缩减其map大小**,然后将其作为参数传递给生成excel使用;**另一种方式是请求完成直接删除该map**,然后在生成excel时再重新读取用户上传的excel样本。 优点:改动较小,不需要太复杂的回归测试 缺点:在极端大数据量情况下,仍有可能出现full gc的情况 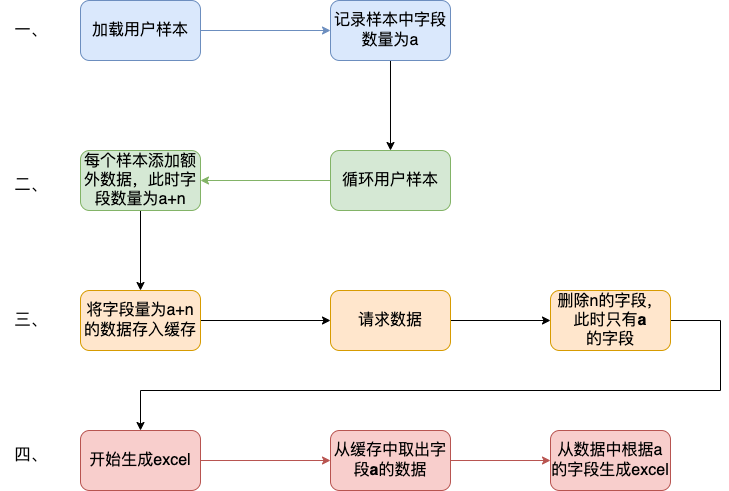 具体实现方式就不展开了。 其中一种实现方式 ```java //获取有用的字段 String[] colEnNames = (String[]) colNameMap.get(Constant.BATCH_COL_EN_NAMES); List<String> colList = Arrays.asList(colEnNames); //去除无用的字段 param.keySet().removeIf(key -> !colList.contains(key)); ``` ## 三、拓展思考 首先本文中监控图是在复现当时场景时人为制造的gc常见。 在cpu使用率图中,大家可以观察到cpu使用率上升时间确实跟gc的时间相吻合,**但是并没有出现当时场景中的104%的CPU使用率**。 <img src="https://s2.loli.net/2023/04/23/1RAHEKj5enLyf29.png" alt="image-20230423103730420" style="zoom: 50%;" /> <img src="https://s2.loli.net/2023/04/23/QYgxGmFZ1Hp8uVE.png" alt="image-20230423103800435" style="zoom: 67%;" /> 其实直接原因比较简单,就是因为系统虽然出现了full gc,但是并没有**频繁**出现。 小范围低频率的full gc不太会引起系统的cpu飙升,这也是我们所看到的现象。 那么当时的场景是什么原因呢? 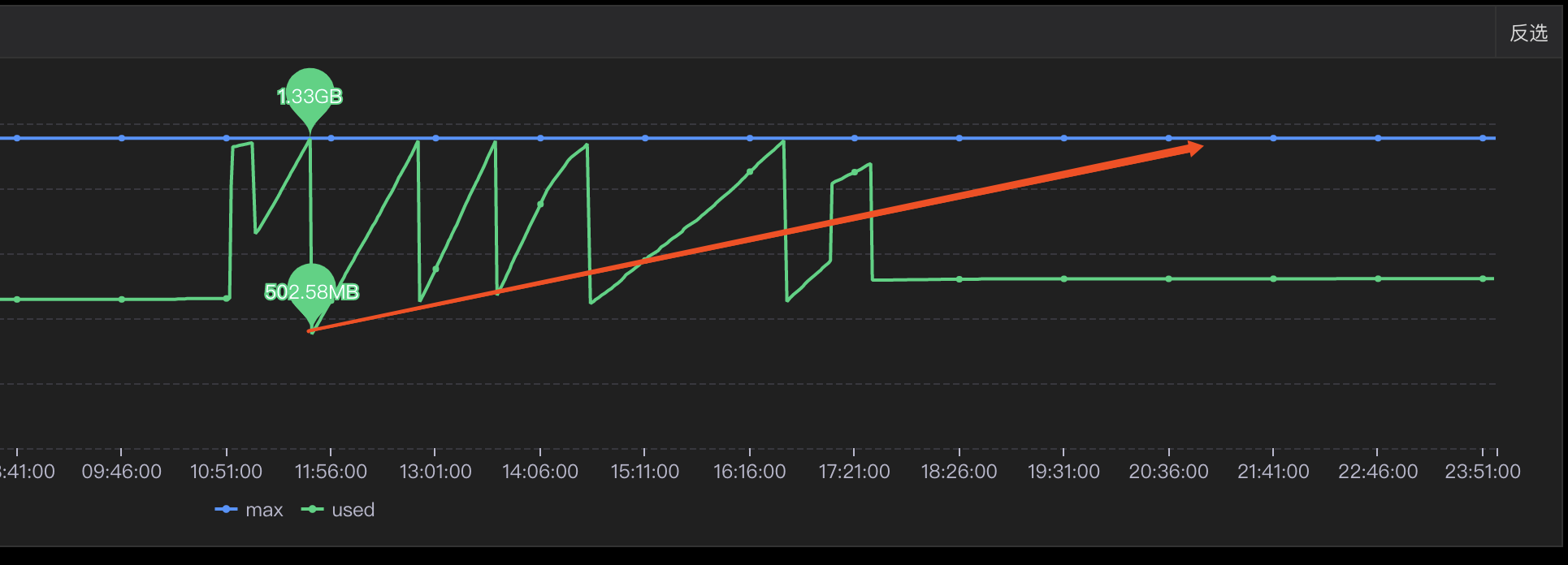 我们上文提到过,我们在**堆内存中的大对象是会随着任务的进行逐步膨胀的**,那么当我们的任务足够多,时间足够长,就有可能导致每次full gc后可用空间变得越来越小,当可用空间小到一定程度之后就,**每次full gc完成之后发现空间还是不够使用**,就会触发下一次的gc,从而导致最终结果的频繁发生gc,引起cpu频率的飙升不下。 ## 四、问题排查总结 - 当我们遇到线上cpu使用率过高的情况时,可以先查看是否是full gc引起的问题,注意要看的是jvm的监控,或者使用jstat相关命令查看。不要被机器内存监控所误导。 - 如果确定是gc引起的问题,可以通过JProfiler直连线上jvm或者使用dump保存堆快照后离线分析。 - 首先可以找到最大的对象,一般情况下是大对象引起的full gc。还有一种情况是,不像这么明显是四个大对象,也可能是比较均衡的十几个50mb的对象,具体情况还需要具体分析。 - 通过上述工具找到确定有问题的对象后找到其堆栈对应的代码位置,通过代码分析找到问题的具体原因,**通过其他现象推演猜测是否正确**,进而找到问题的真正原因。 - 根据问题的原因解决此问题。 当然,上述只是不算很复杂的排查情况,不同的系统肯定有不同的内存情况,我们应当具体问题具体分析,而从此次问题中可以学到的就是如果排查解决问题的思路。
上一篇:Webpack5构建性能优化:构建耗时从150s到60s再到10s
下一篇:实践篇(二):通过自动化单元测试的形式守护系统架构
RyanHan
文章数
15
阅读量
120114
作者其他文章
01
三十分钟入门基础Go——Java小子版
本篇文章适用于学习过其他面向对象语言(Java、Php),但没有学过Go语言的初学者。文章主要从Go与Java功能上的对比来阐述Go语言的基础语法、面向对象编程、并发与错误四个方面。
01
Dubbo源码浅析(一)—RPC框架与Dubbo
RPC,Remote Procedure Call 即远程过程调用,与之相对的是本地服务调用,即LPC(Local Procedure Call)。
01
0源码基础学习Spring源码系列(一)——Bean注入流程
通过本文,读者可以0源码基础的初步学习spring源码,并能够举一反三从此进入源码世界的大门!
01
0 源码基础学习 Spring 源码系列(二)——Spring 如何解决循环依赖
循环依赖在我们日常开发中属于比较常见的问题,spring对循环依赖做了优化,使得我们在无感知的情况下帮助我们解决了循环依赖的问题。
RyanHan
文章数
15
阅读量
120114
作者其他文章
01
三十分钟入门基础Go——Java小子版
01
Dubbo源码浅析(一)—RPC框架与Dubbo
01
0源码基础学习Spring源码系列(一)——Bean注入流程
01
0 源码基础学习 Spring 源码系列(二)——Spring 如何解决循环依赖
添加企业微信
获取1V1专业服务
扫码关注
京东云开发者公众号




 RyanHan
RyanHan 2023-04-28
2023-04-28 3316浏览
3316浏览






