您好!
欢迎来到京东云开发者社区
登录
首页
博文
课程
大赛
工具
用户中心
开源
首页
博文
课程
大赛
工具
开源
更多
用户中心
开发者社区
>
博文
>
0 源码基础学习 Spring 源码系列(二)——Spring 如何解决循环依赖
分享
打开微信扫码分享
点击前往QQ分享
点击前往微博分享
点击复制链接
0 源码基础学习 Spring 源码系列(二)——Spring 如何解决循环依赖
RyanHan
2023-03-22
IP归属:北京
13882浏览
推荐
### 1.1 解决循环依赖过程 #### 1.1.1 三级缓存的作用 循环依赖在我们日常开发中属于比较常见的问题,spring对循环依赖做了优化,使得我们在无感知的情况下帮助我们解决了循环依赖的问题。 最简单的循环依赖就是,A依赖B,B依赖C,C依赖A,如果不解决循环依赖的问题最终会导致OOM,但是也不是所有的循环依赖都可以解决,spring只可以解决通过属性或者setter注入的单例bean,而通过构造器注入或非单例模式的bean都是不可解决的。  通过上文创建bean的过程中我们知道,在获取bean的时候,首先会尝试从缓存中获取,如果从缓存中获取不到才会去创建bean,而三层的缓存正是解决循环依赖的关键: ``` protected Object getSingleton(String beanName, boolean allowEarlyReference) { // Quick check for existing instance without full singleton lock //从一级缓存中加载 Object singletonObject = this.singletonObjects.get(beanName); if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) { //从二级缓存中加载 singletonObject = this.earlySingletonObjects.get(beanName); //allowEarlyReference为true代表要去三级缓存中查找,此时为true if (singletonObject == null && allowEarlyReference) { synchronized (this.singletonObjects) { singletonObject = this.singletonObjects.get(beanName); if (singletonObject == null) { singletonObject = this.earlySingletonObjects.get(beanName); if (singletonObject == null) { //从三级缓存中加载 ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName); if (singletonFactory != null) { singletonObject = singletonFactory.getObject(); this.earlySingletonObjects.put(beanName, singletonObject); this.singletonFactories.remove(beanName); } } } } } } return singletonObject; } ``` 可以看到三层缓存其实就是三个hashmap: ``` /** Cache of singleton objects: bean name to bean instance. */ private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256); /** Cache of singleton factories: bean name to ObjectFactory. */ private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16); /** Cache of early singleton objects: bean name to bean instance. */ private final Map<String, Object> earlySingletonObjects = new ConcurrentHashMap<>(16); ``` 三级缓存的作用: - singletonObjects:用于存放完全初始化好的 bean,从该缓存中取出的 bean 可以直接使用 - earlySingletonObjects:提前曝光的单例对象的cache,存放原始的 bean 对象(尚未填充属性),用于解决循环依赖 - singletonFactories:单例对象工厂的cache,存放 bean 工厂对象,用于解决循环依赖 #### 1.1.2 解决循环依赖的流程 根据上文,我们都知道创建bean的流程主要包括以下三步: 1. **实例化bean** 1. **装配bean属性** 1. **初始化bean** 例如我们现在有 A依赖B,B依赖A,那么spring是如何解决三层循环的呢? 1. 首先尝试从缓存中加载A,发现A不存在 1. 实例化A(没有属性,半成品) 1. 将实例化完成的A放入第三级缓存中 1. 装配属性B(没有属性,半成品) 1. 尝试从缓存中加载B,发现B不存在 1. 实例化B 1. 将实例化完成的B放入第三级缓存中 1. 装配属性A 1. 尝试从缓存中加载A,发现A存在于缓存中(第3步),将A从第三级缓存中移除,放入第二级缓存中,并将其赋值给B,B装配属性完成 1. 此时B的装配属性完毕,初始化B,并将B从三级缓存中移除,放入一级缓存 1. 返回第四步,此时A的属性也装配完成 1. 初始化A,并将A放入一级缓存 自此,实例A于B都分别完成了创建的流程。 用一张图来描述: 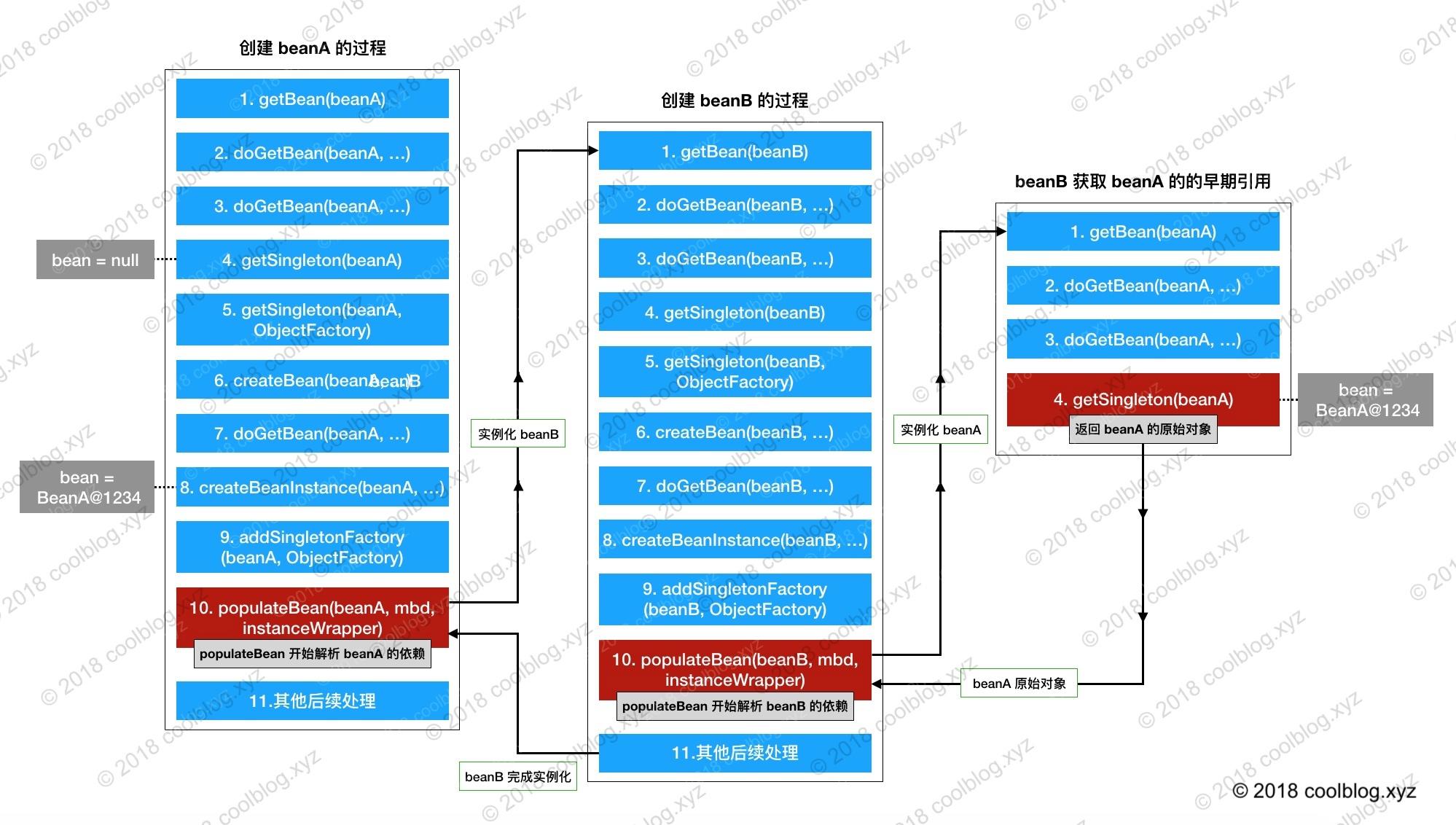 **那么此时有一个问题,在第9步中B拥有的A是只实例化完成的对象,并没有属性装配以及初始化,A的初始化是在11步以后,那么在最后全部创建完成此时B中的的属性A是半成品还是已经可以正常工作的成品呢?答案是成品,因为B对A可以理解为引用传递,也就是说B中的属性A于第11步之前的A为同一个A,那么A在第11步完成了属性装配,自然B中的属性也会完成属性装配。** 例如我们在一个方法中传入一个实例化对象,如果在方法中对实例化对象做了修改,那么在方法结束后该实例化对象也会做出修改,需要注意的是实例化对象,而不是java中的几种基本对象,基本对象是属于值传递(其实实例化对象也是值传递,不过传入的是对象的引用,可以理解为引用传递)。 ``` private static void fun3(){ Student student = new Student(); student.setName("zhangsan"); System.out.println(student.getName()); changeName(student); System.out.println(student.getName()); String str = "zhangsan"; System.out.println(str); changeString(str); System.out.println(str); } private static void changeName(Student student){ student.setName("lisi"); } private static void changeString(String str){ str = "lisi"; } //输出结果 zhangsan lisi zhangsan zhangsan ``` 可以看出引用传递会改变对象,而值传递不会。 ### 2.2 为什么是三层缓存 #### 2.2.1 三级缓存在循环依赖中的作用 有的小伙伴可能已经注意到了,为什么需要三层缓存,两层缓存好像就可以解决问题了,然而如果不考虑代理的情况下确实两层缓存就能解决问题,但是如果要引用的对象不是普通bean而是被代理的对象就会出现问题。 大家需要知道的是,spring在创建代理对象时,首先会实例化源对象,然后在源对象初始化完成之后才会获取代理对象。 我们先不考虑为什么是三级缓存,先看一下在刚才的流程中代理对象存在什么问题 回到我们刚刚举的例子,加入现在我们需要代理对象A,其中A依赖于B,而B也是代理对象,如果不进行特殊处理的话会出现问题: > 1. 首先尝试从缓存中加载A,发现A不存在 > 1. 实例化A(没有属性,半成品) > 1. 将实例化完成的A放入第三级缓存中 > 1. 装配属性B(没有属性,半成品) > 1. 尝试从缓存中加载B,发现B不存在 > 1. 实例化B > 1. 将实例化完成的B放入第三级缓存中 > 1. 装配属性A > 1. 尝试从缓存中加载A,发现A存在于缓存中(第3步),将A从第三级缓存中移除,放入第二级缓存中,并将其赋值给B,B装配属性完成 > 1. 此时B的装配属性完毕,初始化B,并将B从三级缓存中移除,放入一级缓存 > 1. 返回第四步,此时A的属性也装配完成 > 1. 初始化A,并将A放入一级缓存 跟之前一样的流程,**那么此时B拥有的对象是A的普通对象,而不是代理对象**,这就有问题了。 可能有同学会问,不是存在引用传递吗?A被代理完成不是还是会被B所拥有吗? 但是答案也很简单,并不是,**A跟A的代理对象肯定时两个对象,在内存中肯定也是两个地址**,因此需要解决这种情况。 #### 2.2.2 解决代理对象的问题 我们来看看spring是如何解决这个问题的: 根据bean创建的过程我们知道,bean会首先被实例化,在实例化完成之后会执行这样一段代码: ``` //3.是否需要提前曝光,用来解决循环依赖时使用 boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences && isSingletonCurrentlyInCreation(beanName)); if (earlySingletonExposure) { if (logger.isTraceEnabled()) { logger.trace("Eagerly caching bean '" + beanName + "' to allow for resolving potential circular references"); } addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean)); } ``` 这也是我们2.2.5(详见上篇文章)中的代码,主要有两部分 首先会判断是否需要提前曝光,判断结果由三部分组成,分别是: 1. 是否是单例模式,默认情况下都是单例模式,spring也只能解决这种情况下的循环依赖 1. 是否允许提前曝光,默认是true,也可以更改 1. 是否正在创建,正常来说一个bean在创建开始该值为true,创建结束该值为false 可以看到正常情况下一个bean的这些结果都为true,也就是会进入到下面的方法中,该方法中有一个lamda表达式,为了可读性这里进行了拆分。 ``` ObjectFactory<Object> objectFactory = new ObjectFactory<Object>() { @Override public Object getObject() throws BeansException { return getEarlyBeanReference(beanName, mbd, bean); } } ; addSingletonFactory(beanName, objectFactory); ``` 该方法的主要内容就是创建了一个ObjectFactory,其中getObject()方法返回了getEarlyBeanReference(beanName, mbd, bean)这个方法调用结果。 看看addSingletonFactory()这个方法都干了什么 ``` protected void addSingletonFactory(String beanName, ObjectFactory<?> singletonFactory) { Assert.notNull(singletonFactory, "Singleton factory must not be null"); synchronized (this.singletonObjects) { if (!this.singletonObjects.containsKey(beanName)) { //向三级缓存中添加内容 this.singletonFactories.put(beanName, singletonFactory); this.earlySingletonObjects.remove(beanName); this.registeredSingletons.add(beanName); } } } ``` 其中最主要的一行代码就是向三级缓存中添加了对象,而添加的对象就是传入的objectFactory,注意,此处添加的不是bean,而是factory。这也是我们上文解决循环依赖过程中第三步的操作。 加入存在循环依赖的话,此时A已经被加入到缓存中,当A被作为依赖被其他bean使用时,按照我们之前的逻辑会调用缓存 ``` //从三级缓存中加载 ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName); if (singletonFactory != null) { //从刚刚添加的objectFactory获取其中的对象,也就是调用getObject,也就是获取getEarlyBeanReference方法的内容 singletonObject = singletonFactory.getObject(); this.earlySingletonObjects.put(beanName, singletonObject); this.singletonFactories.remove(beanName); } ``` 从刚刚添加的objectFactory获取其中的对象,也就是调用getObject,也就是获取getEarlyBeanReference方法的内容 那么我们看看为什么会返回一个factory而不是一个bean `exposedObject = bp.getEarlyBeanReference(exposedObject, beanName);` `return wrapIfNecessary(bean, beanName, cacheKey);` **根据链路可以看到,最终调用到这个方法中返回的,也就是说当实例A被别的bean依赖时,返回的其实是这个方法中的结果**。 ``` protected Object wrapIfNecessary(Object bean, String beanName, Object cacheKey) { if (StringUtils.hasLength(beanName) && this.targetSourcedBeans.contains(beanName)) { return bean; } if (Boolean.FALSE.equals(this.advisedBeans.get(cacheKey))) { return bean; } if (isInfrastructureClass(bean.getClass()) || shouldSkip(bean.getClass(), beanName)) { this.advisedBeans.put(cacheKey, Boolean.FALSE); return bean; } // 如果是一个需要被代理对象的话,会在此处返回被代理的对象 Object[] specificInterceptors = getAdvicesAndAdvisorsForBean(bean.getClass(), beanName, null); if (specificInterceptors != DO_NOT_PROXY) { this.advisedBeans.put(cacheKey, Boolean.TRUE); Object proxy = createProxy( bean.getClass(), beanName, specificInterceptors, new SingletonTargetSource(bean)); this.proxyTypes.put(cacheKey, proxy.getClass()); return proxy; } this.advisedBeans.put(cacheKey, Boolean.FALSE); return bean; } ``` 看到这里应该就是一目了然了spring是如何处理存在代理对象且存在循环依赖的情况的。 **回到之前的逻辑,例如此时实例B需要装填属性A,会从缓存中查询A是否存咋,查询到A已经存在,则调用A的getObject()方法,如果A是需要被代理的对象则返回被代理过得对象,否则返回普通bean。** 此外还需要注意的是:先创建对象,再创建代理类,再初始化原对象,和初始化之后再创建代理类,是一样的,这也是可以提前暴露代理对象的基础。 #### 2.2.3 二级缓存的作用 **那么二级缓存是干什么用的呢**? `addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));` 可以在源代码中看出每调用一次`getObject()`然后调用`getEarlyBeanReference()`中 `createProxy()`都会产生一个新的代理对象,并不不符合单例模式。 (网上有很多文章说是因为调用lamda表达式所以会产生新的对象,其实如果非代理bean并不会产生新的对象,因为objectFactory所持有的是有原始对象的,即时多次调用也会返回相同的结果。但是对于代理对象则会每次新create一个,所以其实会产生新的代理对象而不会是新产生普通对象。**所以就其本质为什么使用二级缓存的原因是因为创建代理对象是使用createProxy()的方法,每次调用都会产生新的代理对象,那么其实只要有一个地方能根据beanName返回同一个代理对象,也就不需要二级缓存了,这也是二级缓存的本质意义。其实也可以在getObject()方法中去缓存创建完成的代理对象,只不过这样做就太不优雅,不太符合spring的编码规范。** ) ``` Object proxy = createProxy( bean.getClass(), beanName, specificInterceptors, new SingletonTargetSource(bean)); ``` 例如A依赖于B,B依赖与A、C、D,而C、D又依赖于A,如果不进行处理的话,A实例化完成之后,在B创建过程中获取A的代理对象A1,然后C、D获取的代理对象就是A2、A3,显然不符合单例模式。 因此需要有一个地方存储从factory中获取到的对象,也就是二级缓存的功能: ``` if (singletonFactory != null) { singletonObject = singletonFactory.getObject(); //存储获取到的代理对象或普通bean this.earlySingletonObjects.put(beanName, singletonObject); //此时三级缓存的工厂已经没有意义了 this.singletonFactories.remove(beanName); } ``` #### 2.2.4 代理对象什么时候被初始化的 本来以为到这里就结束了,但是在梳理有代理对象的循环依赖时,突然又发现一个问题: 还是A、B都有代理互相依赖的例子,在B装配完A的代理对象后,B初始化完成,A开始初始化,但是此时的A是原始beanA1,并不是代理对象A2,而B持有的是代理对象A2,那么原始对象A1初始化A2并没有初始化,这不是有问题的吗? 在经过一天的查找以及搜寻资料还有debug后,终于在一篇文章中到答案: > 不会,这是因为不管是`cglib`代理还是`jdk`动态代理生成的代理类,内部都持有一个目标类的引用,当调用代理对象的方法时,实际会去调用目标对象的方法,A完成初始化相当于代理对象自身也完成了初始化 也就是说原始对象A1初始化完成后,因为A2是对A1的封装以及增强,也就代表着A2也完成了初始化。 #### 2.2.5 什么时候返回代理对象 此外还有一点需要注意的是,在A1装配完之后,以后其他bean依赖的应该是A2,并且加入到一级缓存中的也应该是A2,那么什么时候A1被换成A2的呢? ``` //在上方已经判断过,一般为true if (earlySingletonExposure) { //1.注意此处传入的是false,并不会去三级缓存中查找,并且如果是代理对象的话此时会返回代理对象 Object earlySingletonReference = getSingleton(beanName, false); if (earlySingletonReference != null) { //2.判断经过后置处理器后对象是否被改变 ==的话说明没有被改变 那么如果是代理对象的话返回被代理的bean if (exposedObject == bean) { exposedObject = earlySingletonReference; } else if (!this.allowRawInjectionDespiteWrapping && hasDependentBean(beanName)) { String[] dependentBeans = getDependentBeans(beanName); Set<String> actualDependentBeans = new LinkedHashSet<>(dependentBeans.length); for (String dependentBean : dependentBeans) { if (!removeSingletonIfCreatedForTypeCheckOnly(dependentBean)) { actualDependentBeans.add(dependentBean); } } if (!actualDependentBeans.isEmpty()) { throw new BeanCurrentlyInCreationException(beanName, "Bean with name '" + beanName + "' has been injected into other beans [" + StringUtils.collectionToCommaDelimitedString(actualDependentBeans) + "] in its raw version as part of a circular reference, but has eventually been " + "wrapped. This means that said other beans do not use the final version of the " + "bean. This is often the result of over-eager type matching - consider using " + "'getBeanNamesForType' with the 'allowEagerInit' flag turned off, for example."); } } } } ``` 以上有两个需要注意的地方: 1. 因为在之前在B装配属性A的时候,即从三级缓存中查找A的时候,如果查到了会将A的bean(有可能是代理对象)放入二级缓存,然后删除三级缓存,那么此时`getSingleton()`返回的就是二级缓存中的bean。 1. 这里判断经过后置处理器的bean是否被改变,一般是不会改变的,除非实现`BeanPostProcessor`接口手工改变。如果没有改变的话则将缓存中的数据取出返回,也就是说如果此时二级缓存中的是代理beanA2,此时会返回A2而不是原始对象A1,如果是普通bean的话则都一样。而如果对象已经被改变则走下面的判断有没有可能报错的逻辑。 ### 3.1循环依赖总结 在学习代理在循环依赖的,发现其实并不太需要二级缓存,可以在bean实例化完成之后就选择要不要生成代理对象,如果要生成的话就往三级缓存中放入代理对象,否则的话就放入普通bean,这样别人过来拿的时候就不用判断是否需要返回代理对象了。 后面发现在网络上有很多跟我想得一样的人,目前参考别人的想法以及自己进行了总结大概是这样子的: 无论是实例化完成之后就进行对象代理还是选择返回一个factory在使用的时候进行代理其实效率上都没有什么区别,只不过一个是提前做一个是滞后做,那么为什么spring选择滞后做的这件事呢?我自己的思考是: **道理也很简单,既然效率没有什么提升的话,为什么要破坏普通bean的创建流程,本来循环依赖就是一件非常小概率的事,没必要因为小概率事情并且滞后也可以解决,从而选择需要修改普通bean的创建逻辑,这无异于是本末倒置,而这也是二级缓存或者说三级缓存中存放的是factory的意义。**
原创文章,需联系作者,授权转载
上一篇:Dubbo源码浅析(一)—RPC框架与Dubbo
下一篇:0源码基础学习Spring源码系列(一)——Bean注入流程
相关文章
京东金融APP的鸿蒙之旅:技术、挑战与实践
“轻松上手!5分钟学会用京东云打造你自己的专属DeepSeek”
何必舍近求远 计算工厂帮你一键部署DeepSeek云主机
RyanHan
文章数
15
阅读量
117010
作者其他文章
01
三十分钟入门基础Go——Java小子版
本篇文章适用于学习过其他面向对象语言(Java、Php),但没有学过Go语言的初学者。文章主要从Go与Java功能上的对比来阐述Go语言的基础语法、面向对象编程、并发与错误四个方面。
01
Dubbo源码浅析(一)—RPC框架与Dubbo
RPC,Remote Procedure Call 即远程过程调用,与之相对的是本地服务调用,即LPC(Local Procedure Call)。
01
0源码基础学习Spring源码系列(一)——Bean注入流程
通过本文,读者可以0源码基础的初步学习spring源码,并能够举一反三从此进入源码世界的大门!
01
0 源码基础学习 Spring 源码系列(二)——Spring 如何解决循环依赖
循环依赖在我们日常开发中属于比较常见的问题,spring对循环依赖做了优化,使得我们在无感知的情况下帮助我们解决了循环依赖的问题。
RyanHan
文章数
15
阅读量
117010
作者其他文章
01
三十分钟入门基础Go——Java小子版
01
Dubbo源码浅析(一)—RPC框架与Dubbo
01
0源码基础学习Spring源码系列(一)——Bean注入流程
添加企业微信
获取1V1专业服务
扫码关注
京东云开发者公众号










