



引言
在电商产品视频的制作环节中,多镜头场景的视觉一致性与制作效率之间的平衡始终是一个核心课题。本次以一款机器狗的商详视频制作为例,需在一段40多秒的客厅场景(全片约1分钟)中呈现人物与机器狗全景、中景及局部特写等多组镜头,且所有画面保持统一的空间透视、光影关系与材质表现。
在本次实践中,笔者尝试以单张已定稿的主场景图像作为全片70%镜头的视觉来源,依托无限画布功能,结合拍我模型与可灵模型,实现了一条由单一图像驱动、多分镜连续延展并最终生成动态视频的制作流程。下文将对该流程进行完整的记录与分析。

一、 初始素材与制作目标
1. 初始素材说明
本项目在启动初期考虑到进一步做提效尝试,目标通过一张客厅场景(图1)延展视频70-80%的镜头内容,该客厅场景已确定色调、整体氛围及客厅布局。产品(机器狗-图2)与人物形象(图3)均未置入画面。
| 客厅(图1) | 产品(图2) | 人物(图3) |
|---|---|---|
 |  |  |
2. 制作目标
- 在主场景中完成人物与产品的合成,确保光影融合符合物理逻辑。
- 基于同一场景延展出以下分镜画面:全景画面,展示机器狗在环境中的完整形态;侧面机位画面,丰富场景层次;人物面部与机器人头部交互的特写画面。
- 将上述分镜画面生成为连续的动态视频,快速提效但保证视频内容的丰富度与产品、人物一致性。
二、 制作流程分阶段记录
阶段一:人物与场景的融合处理
首先,需要在初始客厅图像中植入人物和产品,并使其与场景的光影、色调达成视觉统一。
操作步骤:
- 在灵境平台的无限画布中导入初始客厅图像,作为基础图层。
- 导入一张人物三视图和机器狗的正面图,通过提示词描述画面内容。
- 使用灵境-香蕉2-Flash/Seedream 5.0 Lite模型,生成人物、产品与环境的合成结果,将此图作为后续其他分镜延展的图生图参考基础(图4)。
| 合成图(图4) |
|---|
 |
阶段二:基于单一图像的多视角分镜延展
获得融合后的主合成图像后,后续所有分镜画面的生成均未引入任何外部新素材,完全通过无限画布的提示词控制与局部重绘功能实现。
分镜一:延展正面视角(展示机器狗纯侧面视角)
- 操作:基于主场景图生图功能,选择灵境-香蕉2-Flash/Seedream 5.0 Lite模型,输入提示词“延展正面角度,女生伤心的把头靠在膝盖上,其他内容不变”(图5)。以此在图生图延展正面的中景镜头(图6)。
| 分镜一(图5) | 延展(图6) |
|---|---|
 |  |
分镜二:延展特写镜头(展示机器狗的质感绒毛)
- 操作:基于主场景图生图功能,选择灵境-香蕉2-Flash/Seedream 5.0 Lite模型,输入提示词“参考这张图的场景,特写机器狗抬头看向女生的方向”(图7)。以此在图生图延展机器狗正面特写(图8)。
| 分镜二(图7) | 延展(图8) |
|---|---|
 |  |
分镜三:延展正面人物其他姿势镜头(增加叙事感)
操作:基于分镜二的正面镜头进行图生图,选择灵境-香蕉2-Flash/Seedream 5.0 Lite模型,输入提示词“女生不穿拖鞋改为抱着机器狗躺在沙发上睡着了,机器狗需要看着女生”(图9)。以此再根据图9图生图延展女生眼睛瞳孔特写(图10)。
| 分镜三(图8) | 延展(图9) | 延展(图10) |
|---|---|---|
 |  |  |
分镜四:延展机器狗俯视正面镜头(突出趣味性)
操作:基于主场景图生图功能,选择灵境-香蕉2-Flash/Seedream 5.0 Lite模型,输入提示词“延展俯视特写玩具狗”(图11)。通过图生视频时的提示词描述可以为简单的分镜增加额外的趣味效果,如生视频时增加“机器狗背后出现两个悲伤的emoji表情”(图12)以及“机器狗背后出现两个桃心emoji表情升起”(图13)。
| 分镜四(图11) | 延展(图12) | 延展(图13) |
|---|---|---|
 |  |  |
分镜四:一张人物图搞定补充镜头(提升效率)
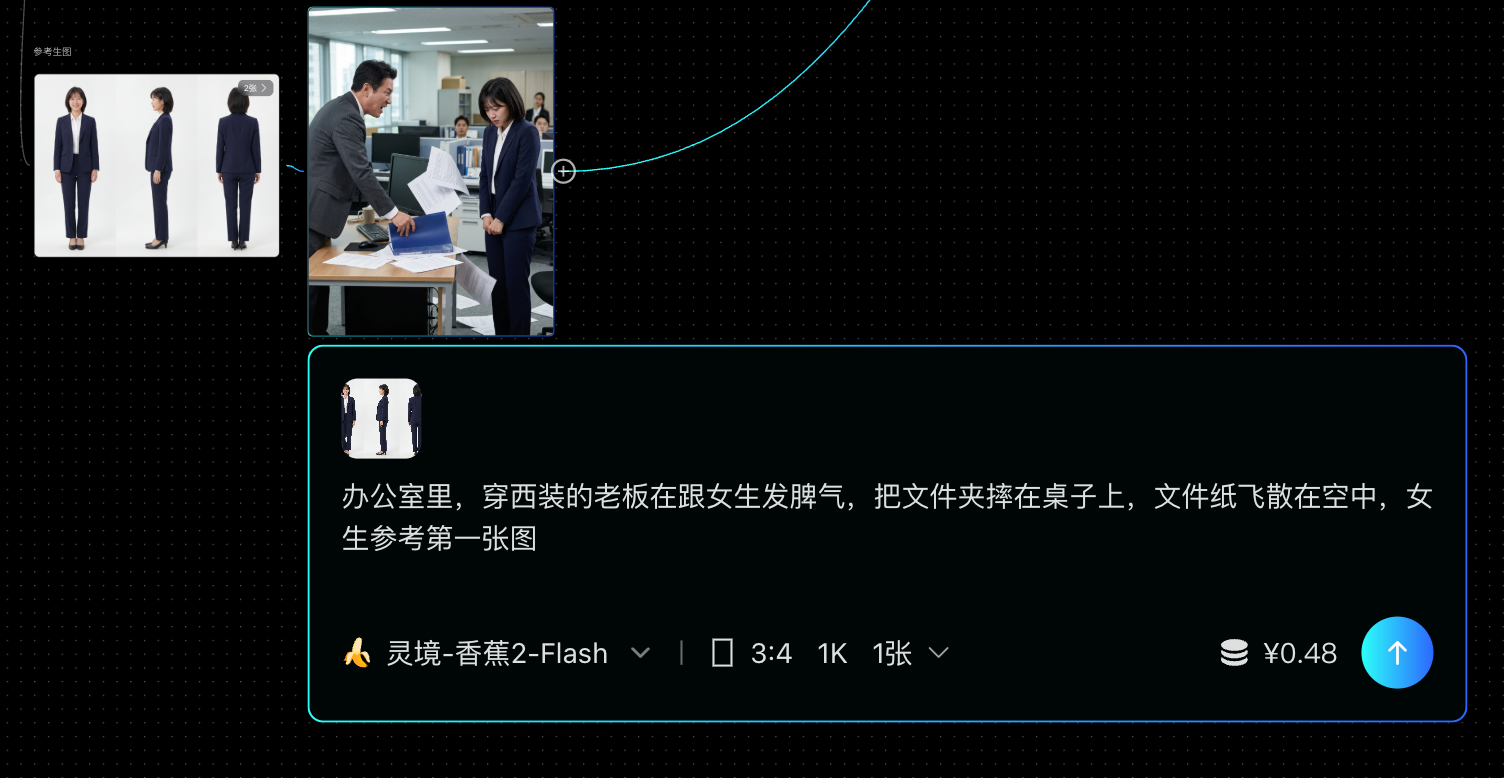
阶段三:视频生成与输出
获得分镜图像序列后,进入视频生成环节。所有图像均使用灵境平台内的可灵V3模型/拍我Pixverse V6(视频模式) 进行动态化处理。
参数设置:
- 全景画面:运镜指令设置为 “缓慢推进,电影级光照”。
- 特写画面:运镜指令设置为 “轻微摇移,焦点落于机器狗眼部”。
最终将生成的视频片段在剪辑软件中进行时序排列并添加背景音效,完成成片输出。
三、 工作流效率分析
本次实践验证了“单图驱动多分镜视频”工作流的可行性,其在以下几个维度体现出效率优势:
- 素材依赖度降低:全流程仅需1-3张定稿主视觉图,免去了多机位拍摄或三维多角度渲染的环节。
- 视觉一致性保障:所有延展画面继承主图的空间数据与光照参数,避免了多源素材拼接时常见的光影穿帮问题。
- 修改响应速度提升:当需要对人物位置、产品朝向等细节进行调整时,仅需以一张图为基础,通过提示词控制即可实现,无需重新生成全部素材。
相较于每个镜头重新生图的工作流,通过一张主图延展多视角分镜提效约40%。
(不过该工作流可能更适合产品功能少、叙事情节较单一、对高频多角度展示产品的脚本做提效参考)
四、 结语
本次以机器狗商详视频为对象的制作实践,展示了灵境无限画布功能在电商视觉生产流程中的应用潜力。通过单一主图的空间延展与模型协同处理,在保障画面品质的前提下显著缩短了制作周期。作为一种新的工作流思路,该方法对于需要高频产出多角度产品展示视频的团队具有一定的参考价值。





