您好!
欢迎来到京东云开发者社区
登录
首页
博文
课程
大赛
工具
用户中心
开源
首页
博文
课程
大赛
工具
开源
更多
用户中心
开发者社区
>
博文
>
由 Mybatis 源码畅谈软件设计(七):从根上理解 Mybatis 一级缓存
分享
打开微信扫码分享
点击前往QQ分享
点击前往微博分享
点击复制链接
由 Mybatis 源码畅谈软件设计(七):从根上理解 Mybatis 一级缓存
wy****
2024-12-25
IP归属:北京
687浏览
本篇我们来讲 **一级缓存**,重点关注它的实现原理:何时生效、生效范围和何时失效,在未来设计缓存使用时,提供一些借鉴和参考。 ### 1. 准备工作 #### 定义实体 ```java public class Department { public Department(String id) { this.id = id; } private String id; /** * 部门名称 */ private String name; /** * 部门电话 */ private String tel; /** * 部门成员 */ private Set<User> users; } ``` ```java public class User { private String id; private String name; private Integer age; private LocalDateTime birthday; private Department department; } ``` #### 定义 Mapper.xml DepartmentMapper.xml,两条 SQL:一条根据 ID 查询;一条清除缓存,标记了 **fulshCache** 标签,将其设置为 true 后,只要语句被调用,都会将本地缓存和二级缓存清空(默认值为 false) ```xml <select id="findById" resultType="Department"> select * from department where id = #{id} </select> <select id="cleanCathe" resultType="int" flushCache="true"> select count(department.id) from department; </select> ``` UserMapper.xml,联表查询用户信息: ```java <select id="findAll" resultMap="userMap"> select u.*, td.id, td.name as department_name from user u left join department td on u.department_id = td.id </select> ``` ### 2. 一级缓存 一级缓存的生效范围 `SqlSession` 级别的,不同 `SqlSession` 间不共享缓存,它默认情况下是启用的。主要作用是减少在同一个查询 SQL 会话中对数据库的重复查询,从而提高性能。以如下用例为例: ```java public static void main(String[] args) throws IOException { InputStream xml = Resources.getResourceAsStream("mybatis-config.xml"); SqlSessionFactoryBuilder sqlSessionFactoryBuilder = new SqlSessionFactoryBuilder(); // 开启二级缓存需要在同一个SqlSessionFactory下,二级缓存存在于 SqlSessionFactory 生命周期,如此才能命中二级缓存 SqlSessionFactory sqlSessionFactory = sqlSessionFactoryBuilder.build(xml); SqlSession sqlSession = sqlSessionFactory.openSession(); DepartmentMapper departmentMapper = sqlSession.getMapper(DepartmentMapper.class); System.out.println("----------department第一次查询 ↓------------"); departmentMapper.findById("18ec781fbefd727923b0d35740b177ab"); System.out.println("----------department一级缓存生效,控制台看不见SQL ↓------------"); departmentMapper.findById("18ec781fbefd727923b0d35740b177ab"); } ``` 可以发现在第二次查询时,一级缓存生效,控制台没有出现SQL: 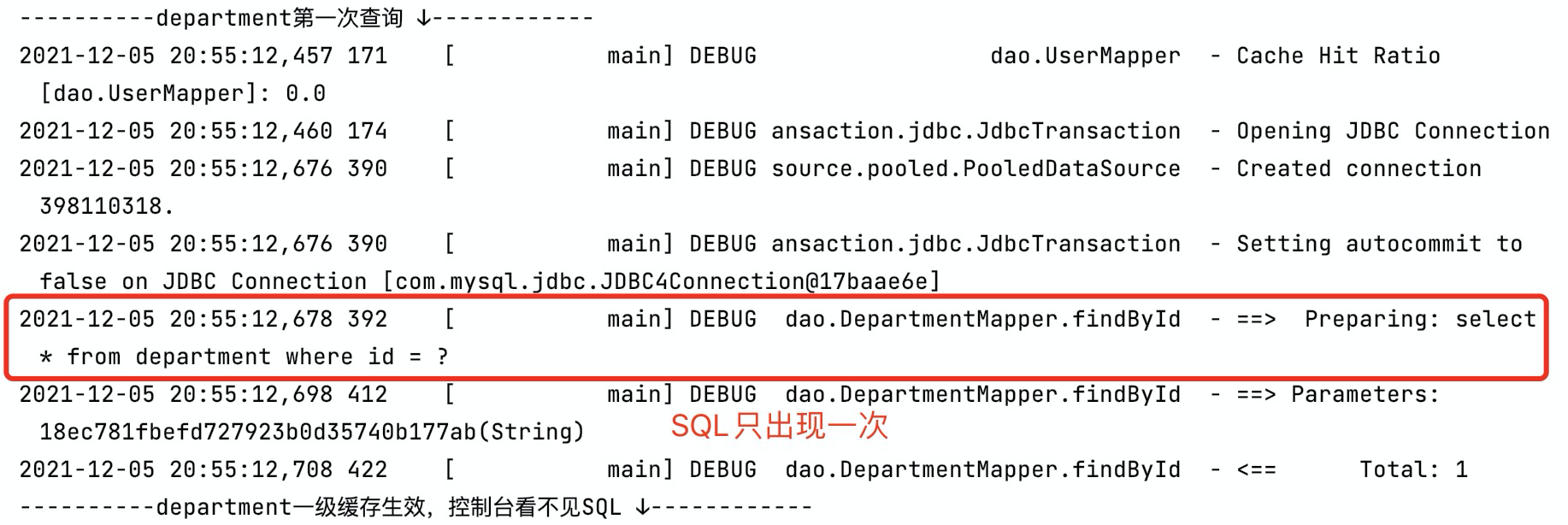 而我们清空下一级缓存再试试: ```java public static void main(String[] args) throws IOException { InputStream xml = Resources.getResourceAsStream("mybatis-config.xml"); SqlSessionFactoryBuilder sqlSessionFactoryBuilder = new SqlSessionFactoryBuilder(); // 开启二级缓存需要在同一个SqlSessionFactory下,二级缓存存在于 SqlSessionFactory 生命周期,如此才能命中二级缓存 SqlSessionFactory sqlSessionFactory = sqlSessionFactoryBuilder.build(xml); SqlSession sqlSession = sqlSessionFactory.openSession(); DepartmentMapper departmentMapper = sqlSession.getMapper(DepartmentMapper.class); System.out.println("----------department第一次查询 ↓------------"); departmentMapper.findById("18ec781fbefd727923b0d35740b177ab"); System.out.println("----------department一级缓存生效,控制台看不见SQL ↓------------"); departmentMapper.findById("18ec781fbefd727923b0d35740b177ab"); System.out.println("----------清除一级缓存 ↓------------"); departmentMapper.cleanCathe(); System.out.println("----------清除后department再一次查询,SQL再次出现 ↓------------"); departmentMapper.findById("18ec781fbefd727923b0d35740b177ab"); } ``` 控制台日志很清晰,清除缓存后又重新查了一遍:  接下来我们看一下不同 `SqlSession` 间一级缓存是否共享,创建一个新的 `SqlSession sqlSession1` 执行相同的SQL: ```java public static void main(String[] args) throws IOException { SqlSession sqlSession = sqlSessionFactory.openSession(); SqlSession sqlSession1 = sqlSessionFactory.openSession(); DepartmentMapper departmentMapper = sqlSession.getMapper(DepartmentMapper.class); DepartmentMapper departmentMapper1 = sqlSession1.getMapper(DepartmentMapper.class); System.out.println("----------department第一次查询 ↓------------"); departmentMapper.findById("18ec781fbefd727923b0d35740b177ab"); System.out.println("----------sqlSession1下department执行相同的SQL,控制台出现SQL ↓------------"); departmentMapper1.findById("18ec781fbefd727923b0d35740b177ab"); } ``` 如控制台日志所示,可以发现在不同的 `SqlSession` 下不共享一级缓存: 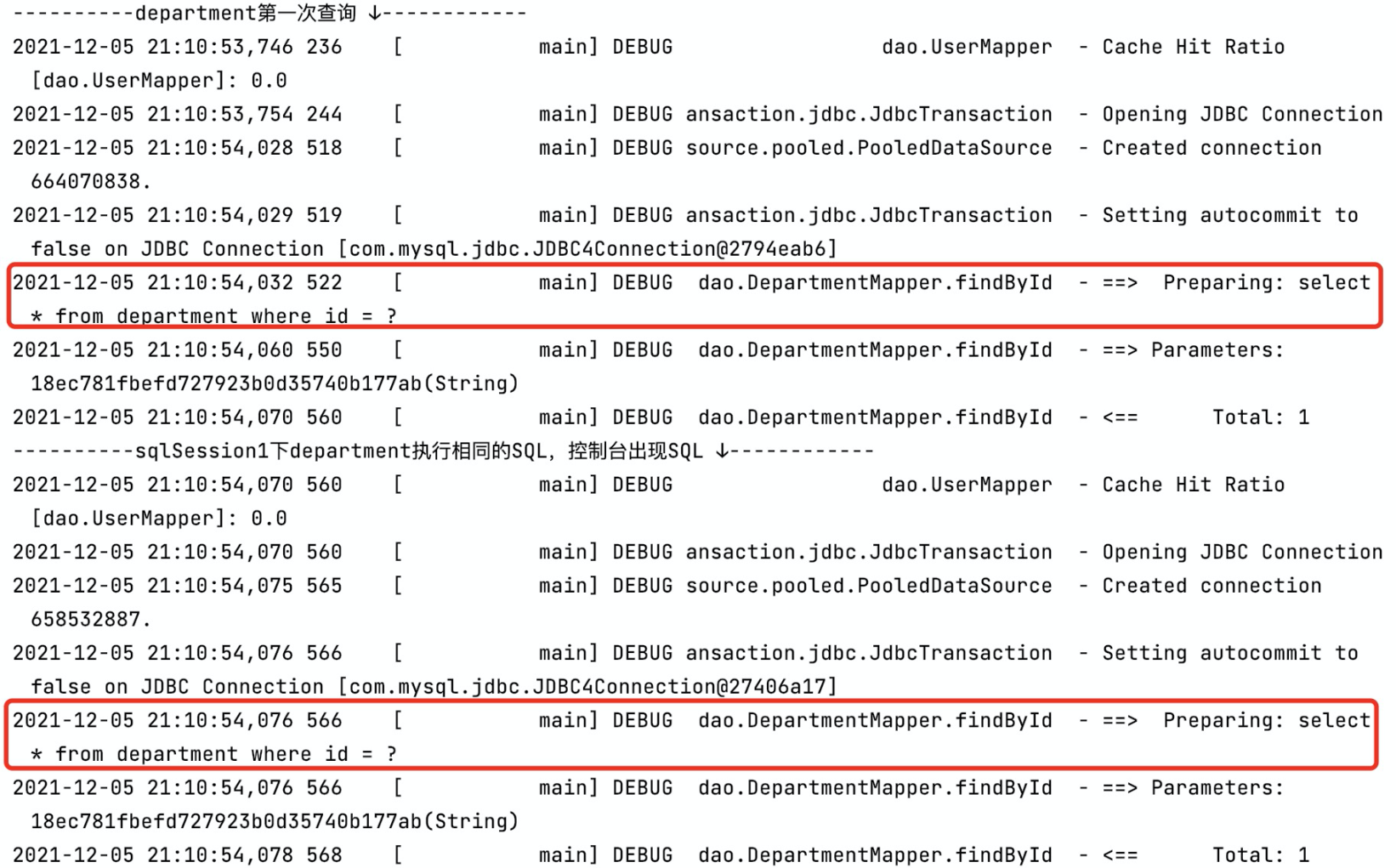 ### 3. 一级缓存原理 一级缓存在查询方法 `org.apache.ibatis.executor.BaseExecutor#query` 中生效,如下所示: ```java public abstract class BaseExecutor implements Executor { // ... // 一级缓存 protected PerpetualCache localCache; public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException { ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId()); if (closed) { throw new ExecutorException("Executor was closed."); } // 判断是否刷新本地缓存 if (queryStack == 0 && ms.isFlushCacheRequired()) { clearLocalCache(); } List<E> list; try { queryStack++; // 判断一级缓存是否存在,存在则直接作为结果返回,否则查询数据库 list = resultHandler == null ? (List<E>) localCache.getObject(key) : null; if (list != null) { // 存储过程相关逻辑 handleLocallyCachedOutputParameters(ms, key, parameter, boundSql); } else { // 未命中一级缓存,查询数据库 list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql); } } finally { queryStack--; } if (queryStack == 0) { for (DeferredLoad deferredLoad : deferredLoads) { deferredLoad.load(); } // issue #601 deferredLoads.clear(); if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) { // issue #482 clearLocalCache(); } } return list; } private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException { List<E> list; // 一级缓存占位 localCache.putObject(key, EXECUTION_PLACEHOLDER); try { list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql); } finally { // 查询完成后清除一级缓存 localCache.removeObject(key); } // 添加到一级缓存中 localCache.putObject(key, list); // 存储过程相关逻辑 if (ms.getStatementType() == StatementType.CALLABLE) { localOutputParameterCache.putObject(key, parameter); } return list; } } ``` 其中 `PerpetualCache localCache` 便是一级缓存,它的实现借助了 `HashMap`: ```java public class PerpetualCache implements Cache { private final String id; private final Map<Object, Object> cache = new HashMap<>(); // ... } ``` 一级缓存生效的逻辑也非常简单,如下所示: 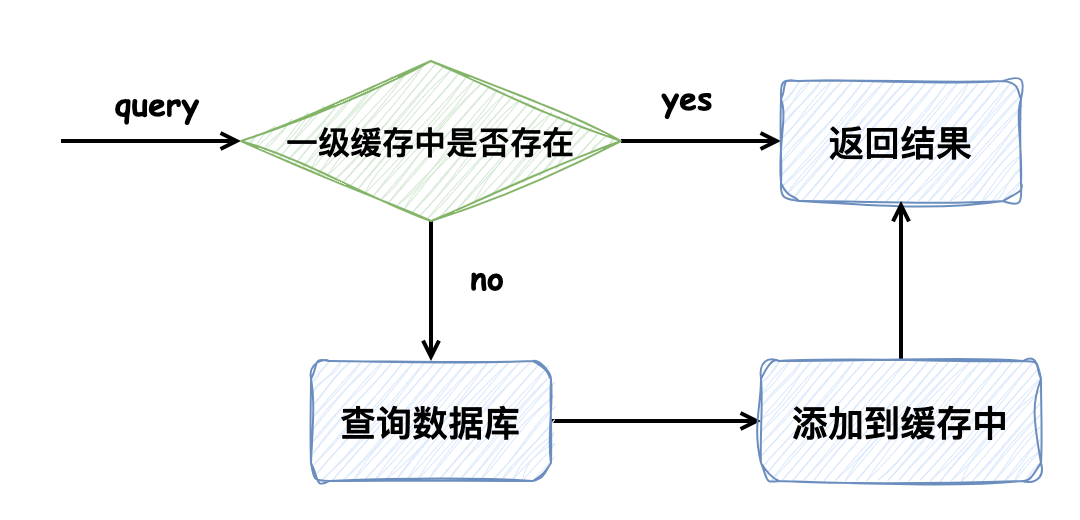 `queryFromDatabase` 方法中有一段蛮有意思的逻辑 `localCache.putObject(key, EXECUTION_PLACEHOLDER);`:在添加一级缓存前会先添加缓存 **占位符 EXECUTION\_PLACEHOLDER**,但是这个占位符并没有被用作一个明确的同步机制来阻止其他线程的查询执行,所以它只是标记一个查询正在进行,**提供了** 防止在同一事务上下文中重复执行相同的查询的 **基础**,这种设计可能是 MyBatis 开发者认为在多数情况下,数据库查询的开销相对较小或同一事务中几乎不执行多次相同的查询,而不是为了在多线程环境下保证不击穿数据库,降低数据库的压力。 这种设计模式在分布式缓存系统中很常见,一般用于 **解决 ”缓存击穿“ 问题**,帮助系统在高并发环境下保持稳定性。 #### 一级缓存失效场景 * 两次相同查询SQL间有 **Insert、Delete、Update** 语句执行时:**Insert、Delete、Update** 的 **flushCache标签 默认为 true** ,执行它们时,会将一级缓存清空 * 调用 `sqlSession#clearCache` 方法 * `SqlSession` 被关闭时,一级缓存也会被清空 #### 缓存的是对象的引用 以如下代码为例,第一次查询结果中 name 字段的值为 null,将其赋值再进行第二次查询: ```java System.out.println("----------department第一次查询 ↓------------"); Department department = departmentMapper.findById("18ec781fbefd727923b0d35740b177ab"); System.out.println(department); department.setName(" 把名字改了"); System.out.println("----------department一级缓存生效,控制台看不见SQL ↓------------"); System.out.println(departmentMapper.findById("18ec781fbefd727923b0d35740b177ab")); ``` 可以发现第二次查询取缓存的结果是 **更改name结果之后的**: 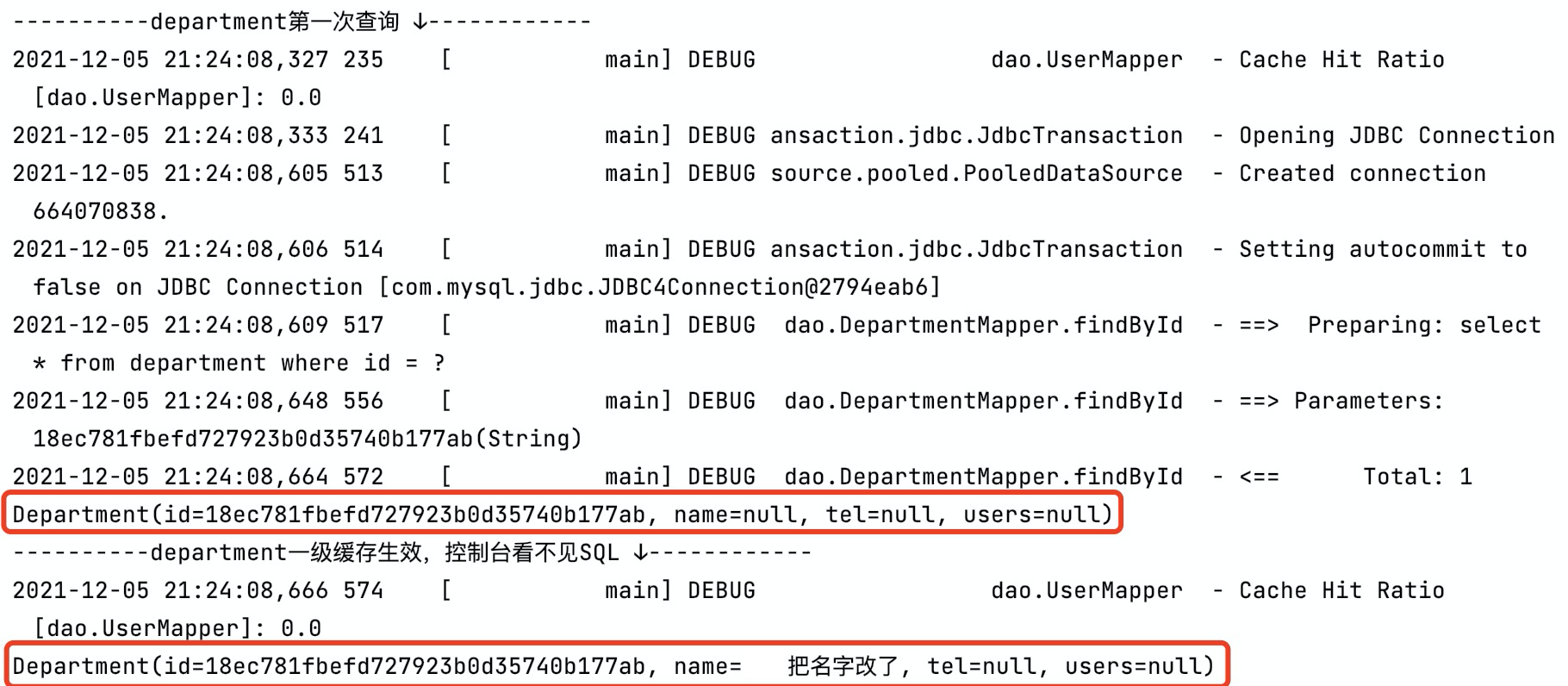 这是因为一级缓存中 **存放的数据其实是对象的引用**,导致第二次从一级缓存中查询到的数据,就是我们刚刚改过的数据,而并不是数据库中真实的数据。在同一个 `SqlSession` 中,如果对缓存中返回的对象进行了修改,而没有同步更新数据库,那么在后续的查询中会返回被修改的对象,而不是数据库中的最新数据,导致脏读。 ### 4. 总结 * 一级缓存基于 `SqlSession`,不同 `SqlSession` 间不共享一级缓存 * 一级缓存被保存在 `BaseExecutor` 的 `PerpetualCache` 中,本质上是 `HashMap` * 执行 **Insert、Delete、Update** 语句会使一级缓存失效 * 一级缓存存放的数据是对象的引用,若对它进行修改,则之后取出的缓存为修改后的数据 ### 巨人的肩膀 * [ 为什么要实现序列化:MyBatis的一级缓存、二级缓存演示以及讲解,序列化异常的处理](https://www.cnblogs.com/ncl-960301-success/p/10976255.html) * [为什么MyBatis二级缓存Cache Hit Ratio始终等于0:二级缓存的生命周期在同一个SqlSessionFactory中](https://www.it610.com/article/1304085366302609408.htm)
上一篇:由 Mybatis 源码畅谈软件设计(五):ResultMap 的循环引用
下一篇:由 Mybatis 源码畅谈软件设计(四):动态 SQL 执行流程
wy****
文章数
47
阅读量
44057
作者其他文章
01
用“分区”来面对超大数据集和超大吞吐量
1. 为什么要分区?分区(partitions) 也被称为 分片(sharding),通常采用对数据进行分区的方式来增加系统的 可伸缩性,以此来面对非常大的数据集或非常高的吞吐量,避免出现热点。分区通常和复制结合使用,使得每个分区的副本存储在多个节点上,保证数据副本的 高可用。如下图所示,如果数据库被分区,每个分区都有一个主库。不同分区的主库可能在不同的节点上,每个节点可能是某些分区的主库,同时是
01
深入理解分布式共识算法 Raft
“不可靠的网络”、“不稳定的时钟”和“节点的故障”都是在分布式系统中常见的问题,在文章开始前,我们先来看一下:如果在分布式系统中网络不可靠会发生什么样的问题。有以下 3 个服务构成的分布式集群,并在 server_1 中发生写请求变更 A = 1,“正常情况下” server_1 将 A 值同步给 server_2 和 server_3,保证集群的数据一致性:但是如果在数据变更时发生网络问题(延迟
01
缓存之美:从根上理解 ConcurrentHashMap
本文将详细介绍 ConcurrentHashMap 构造方法、添加值方法和扩容操作等源码实现。ConcurrentHashMap 是线程安全的哈希表,此哈希表的设计主要目的是在最小化更新操作对哈希表的占用,以保持并发可读性,次要目的是保持空间消耗与 HashMap 相同或更好,并支持利用多线程在空表上高效地插入初始值。在 Java 8 及之后的版本,使用 CAS 操作、 synchronized
01
缓存之美:万文详解 Caffeine 实现原理(上)
由于神灯社区最大字数限制,本文章将分为两篇,第二篇文章为缓存之美:万文详解 Caffeine 实现原理(下)文章将采用“总-分-总”的结构对配置固定大小元素驱逐策略的 Caffeine 缓存进行介绍,首先会讲解它的实现原理,在大家对它有一个概念之后再深入具体源码的细节之中,理解它的设计理念,从中能学习到用于统计元素访问频率的 Count-Min Sketch 数据结构、理解内存屏障和如何避免缓存伪
wy****
文章数
47
阅读量
44057
作者其他文章
01
用“分区”来面对超大数据集和超大吞吐量
01
深入理解分布式共识算法 Raft
01
缓存之美:从根上理解 ConcurrentHashMap
01
缓存之美:万文详解 Caffeine 实现原理(上)
添加企业微信
获取1V1专业服务
扫码关注
京东云开发者公众号




 wy****
wy**** 2024-12-25
2024-12-25 687浏览
687浏览






