您好!
欢迎来到京东云开发者社区
登录
首页
博文
课程
大赛
工具
用户中心
开源
首页
博文
课程
大赛
工具
开源
更多
用户中心
开发者社区
>
博文
>
高性能MySQL实战(一):表结构
分享
打开微信扫码分享
点击前往QQ分享
点击前往微博分享
点击复制链接
高性能MySQL实战(一):表结构
wy****
2023-08-16
IP归属:北京
1311浏览
最近因需求改动新增了一些数据库表,但是在定义表结构时,具体列属性的选择有些不知其所以然,索引的添加也有遗漏和不规范的地方,所以我打算为创建一个高性能表的过程以实战的形式写一个专题,以此来学习和巩固这些知识。 ### 1\. 实战 我使用的 MySQL 版本是 5.7,建表 DDL 语句如下所示:根据需求创建 **接口调用日志** 数据库表,请大家浏览具体字段的属性信息,它们有不少能够优化的点。 ```sql CREATE TABLE `service_log` ( `id` bigint(100) NOT NULL AUTO_INCREMENT COMMENT '主键', `service_type` int(10) DEFAULT NULL COMMENT '接口类型', `service_name` varchar(30) DEFAULT NULL COMMENT '接口名称', `service_method` varchar(10) DEFAULT NULL COMMENT '接口方式', `serial_no` int(10) DEFAULT NULL COMMENT '消息序号', `service_caller` varchar(15) DEFAULT NULL COMMENT '调用方', `service_receiver` varchar(15) DEFAULT NULL COMMENT '接收方', `status` int(3) DEFAULT '10' COMMENT '状态 10-成功 20-异常', `error_message` varchar(200) DEFAULT NULL COMMENT '异常信息', `message` text DEFAULT NULL COMMENT '报文内容', `create_user` varchar(50) DEFAULT NULL COMMENT '创建者', `create_time` datetime NOT NULL COMMENT '创建时间', `update_user` varchar(50) DEFAULT NULL COMMENT '更新者', `update_time` datetime NOT NULL COMMENT '更新时间', `is_delete` tinyint(1) NOT NULL DEFAULT '0' COMMENT '刪除标志', `ts` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '时间戳', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='接口调用日志'; ``` 我会在下文中将其中包含的问题和可以进行优化的地方一一进行解释,主要参考的书目是《高性能MySQL 第四版》,也希望大家有精力去看原书。 ### 2\. 优化和改进 #### 慷慨不是明智的 一般来说,要尽量使用能够正确存储和表示数据的最小数据类型,更小的数据类型通常更快,因为它们占用的磁盘、内存和CPU缓存的空间更少,并且处理时需要的CPU周期也更少。但是,这也要确保没有低估需要存储的值的范围,否则会因入库失败而造成数据丢失,而且表结构修改的流程审批也很麻烦。 我们以表中 `id` 和 `message` 列为例来说: `id` 为主键列,它使用的是整数类型 BIGINT(64位),除此之外还有 TINYINT(8位)、SMALLINT(16位)、MEDIUMINT(24位) 和 INT(32位),可以存储的取值范围是从 -2<sup>(N - 1)</sup> 到 2<sup>(N - 1)</sup> - 1,所以 BIGINT 类型值的最大值是9223372036854775808(19位数)。 显然,主键定义100位宽度是有些“无脑的”,而且也是没有意义的:因为 **它不会限制值的合法范围**,即使是定义了 BIGINT(100) 也没办法存储宽度为100的数字,实际上定义 BIGINT(1) 和 BIGINT(20) 的 **存储空间是相同的**,宽度的定义只是规定了 MySQL 的一些交互工具(MySQL命令行客户端)用来显示字符的个数。 整数类型有可选的 **UNSIGNED 属性**,它表示不允许负值,这大约能使正整数的上限提高一倍。例如 TINYINT UNSIGNED 可以存储的值范围是 0 ~ 255,而 TINYINT 的值的存储范围是 -128 ~ 127。我们的ID列是从0开始递增的,所以可以选用这个属性。 那么,我们应该对 `id` 列的定义如下所示: ```sql `id` bigint UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '主键' ``` `message` 列保存的是接口交互报文内容,定义的类型是 TEXT,它还有一些相关的类型,具体如下(L代表字符串的字节长度,数字表示存储字符串字节长度的字节数): | Data Type | Storage Required(Bytes) | | --- | --- | | TINYTEXT | L + 1, L < 2<sup>8</sup> | | TEXT | L + 2, L < 2<sup>16</sup> | | MEDIUMTEXT | L + 3, L < 2<sup>24</sup> | | LONGTEXT | L + 4, L < 2<sup>32</sup> | 若报文内容中每个字符只占用1字节的话,那么 TEXT 类型能最多存储大约 65535 个字符,而实际上报文内容远远达不到这个长度,而且 TEXT 类型是为了存储很大的数据而设计的字符串数据类型。 我们可以将其调整成 VARCHAR 类型,并根据实际的报文长度都不超过 1000 来指定它的字符数为 1000,避免发生因报文长度过长而无法保存数据的情况。**通常情况下MySQL会在内容分配固定大小的内存来保存值**,我们这样做节省了存储空间,对性能也有帮助。 `message` 的更改后的定义如下所示: ```sql `message` varchar(1000) DEFAULT NULL COMMENT '报文内容' ``` VARCHAR 类型也需要额外使用 1 或 2 字节来记录字符串字节的长度:如果列的最大长度小于或等于 255 字节,则只使用 1 字节来表示;否则使用 2 字节来表示。 > MySQL 字符串长度定义的不是字节数,而是字符数。像 UTF-8 这样复杂的字符集可能需要多个字节来存储一个字符。 #### 更小的通常更好 MySQL 总是为 CHAR 类型分配所定义长度的空间,所以它是固定长度的,它相比于 VARCHAR 在面对经常修改的数据时表现更好,因为固定长度的列不容易出现内存碎片,而且对于 CHAR(1) 这种非常短的列,它要比 VARCHAR(1) 更高效,因为前者只占用 1 个字节的空间,后者占用 2 个字节(其中 1 字节记录长度)。 CHAR 类型适合存储非常短的字符串或者所有值长度都几乎相同的字符串,不过需要注意的是,MySQL 会将所有 **尾随的空格移除**。 `service_method` 字段实际上保存的是接口协议,无非是 HTTP 和 TCP 这两种,我们可以将其定义修改为如下所示: ```sql `service_method` char(4) DEFAULT NULL COMMENT '接口方式' ``` 但是实际上,**整型数据比字符数据的比较操作代价更低**,如果在允许改变字段类型的情况下,我们将其修改为 TINYINT 类型,通过定义枚举值来表示不同的协议效率会更高。 ```sql `service_method` tinyint DEFAULT NULL COMMENT '接口方式 1-HTTP 2-TCP' ``` `service_caller` 和 `service_receiver` 字段也是一样的道理,这些值都是固定的枚举,最初应该也定义成 TINYINT 的形式,如下 ```sql `service_caller` tinyint DEFAULT NULL COMMENT '调用方', `service_receiver` tinyint DEFAULT NULL COMMENT '接收方' ``` `service_type` 字段中存储的是对应接口的编码值,它们都是宽度为 4 的整型数据,最大值不会超过 9999,所以根据它的取值范围将其修改为 SMALLINT 类型会更合适,如下 ```sql `service_type` smallint DEFAULT NULL COMMENT '接口类型' ``` `service_name` 字段接口名称最长也不会超过15个字符,所以我们将它的 VARCHAR 定义字符长度修改一下: ```sql `service_name` varchar(15) DEFAULT NULL COMMENT '接口名称' ``` `status` 字段只有 10 和 20 两种值,相比于 INT,使用 TINYINT 更合适一些 ```sql `status` tinyint DEFAULT 10 COMMENT '状态 10-成功 20-异常' ``` #### DATETIME 和 TIMESTAMP 这两种类型非常相似,对于大多数系统来说,这两种类型都可以,不过它们也有所不同。 DATETIME 可以保存的日期范围更大,从 1000 年到 9999 年,精度为 1 微秒,非小数部分 占用 5 个字节的存储空间,小数部分根据精度大小占用 0 ~ 3 个字节,并且它 **与时区无关**。默认情况下,MySQL 以 yyyy-MM-dd HH:mm:ss 的格式显示时间,如果需要指定精度,可以以 `datetime(6)` 的形式定义。 TIMESTAMP 类型存储的是自 1970 年 1 月 1 日格林尼治标准时间以来的秒数(精度也为 1 微秒),非小数部分占用 4 个字节的存储空间,小数部分与 DATETIME 类型占用空间规则一致,所以它的取值范围相比于 DATETIME 要小,只能表示从 1970 年到 2038 年 1 月 19 日的时间范围。而且该类型与MySQL服务指定的 **时区相关**,这就使得在查询日期时,会将时间戳转换为所在时区的时间后再显示,所以不同地区看到的同一时间戳的实际时间展示是不一样的。 > MySQL 可以使用 FROM\_UNIXTIME() 函数将 UNIX 时间戳转换成日期,使用 UNIX\_TIMESTAMP() 函数将日期转换为 UNIX 时间戳。 使用 DATETIME 类型还是使用 TIMESTAMP 类型需要考虑以下问题: * 存储空间对我们来说重要吗? * 需要支持前后多大时间范围的日期和时间? * 保存的日期数据有精度要求吗? * 是在MySQL中处理时区还是在代码中处理时区? 拿我们的应用来说,DATETIME 类型会更合适一些: ```sql `create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间', `update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '更新时间', `ts` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '时间戳' ``` > 如果想要对时间戳进行记录,可以考虑使用 BIGINT 类型,它不会遇到 2038 年的问题。 #### 避免使用 NULL 通常情况下,最好指定列为 NOT NULL,除非明确的需要存储为 NULL 值。可为 NULL 的列会使用更多的存储空间,在 MySQL 中需要特殊的处理;查询中包含可为 NULL 的列对 MySQL 来说更难优化,因为可为 NULL 的列使得索引、索引统计和值的比较更为复杂。 > MySQL 默认的行格式为 DYNAMIC,它会在每行数据中记录额外信息,其中就包括对 NULL 值列表的记录,如果我们所有的列都为 NOT NULL 的话,那么这部分额外信息是不需要记录的。 > > 了解:COMPRESSED 行格式与 DYNAMIC 不同的是,它会对存储数据的页进行压缩以节省空间;COMPACT 行格式与 DYNAMIC 和 COMPRESSED 不同的是在对溢出列的处理上,COMPACT 会存储溢出列的部分数据,剩余的数据使用其他数据页保存,并记录下保存这些数据页的指针,DYNAMIC 和 COMPRESSED 则是将该列所有数据都保存在其他数据页中,在该列数据处只保存对应溢出页的地址。 > > 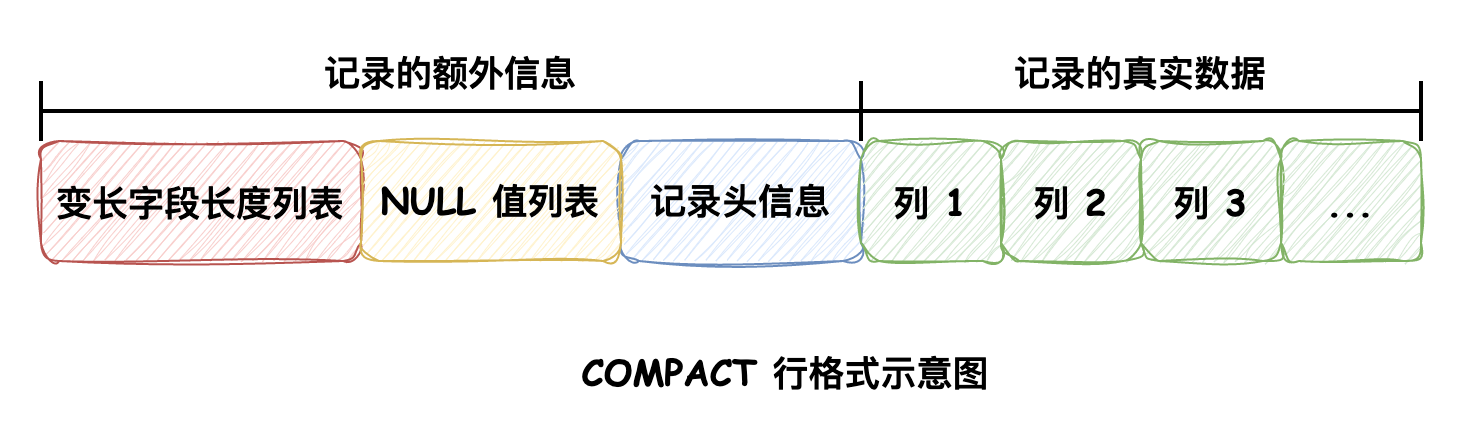 但是实际上将列的定义修改为 NOT NULL 带来的性能提升并不明显,所以并不会将这种优化作为首选,而是在表结构初始化时考虑到这一点。 修改好,最终初始化表结构的 DDL 语句如下: ```sql CREATE TABLE `service_log` ( `id` bigint UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '主键', `service_type` smallint NOT NULL DEFAULT -1 COMMENT '接口类型', `service_name` varchar(30) DEFAULT '' COMMENT '接口名称', `service_method` tinyint NOT NULL DEFAULT -1 COMMENT '接口方式 1-HTTP 2-TCP', `serial_no` int DEFAULT -1 COMMENT '消息序号', `service_caller` tinyint DEFAULT -1 COMMENT '调用方', `service_receiver` tinyint DEFAULT -1 COMMENT '接收方', `status` tinyint DEFAULT 10 COMMENT '状态 10-成功 20-异常', `error_message` varchar(200) DEFAULT '' COMMENT '异常信息', `message` varchar(1000) DEFAULT '' COMMENT '报文内容', `create_user` varchar(50) DEFAULT '' COMMENT '创建者', `create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间', `update_user` varchar(50) DEFAULT '' COMMENT '更新者', `update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '更新时间', `is_delete` tinyint NOT NULL DEFAULT 0 COMMENT '刪除标志', `ts` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '时间戳', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='接口调用日志'; ``` #### TINYINT 表示 Boolean 类型 需要注意,Boolean 类型的值在 MySQL 中是通过 TINYINT 来映射的,如果在数据库中该值为 0,那么映射到 Java 对象中为 False,如下所示: 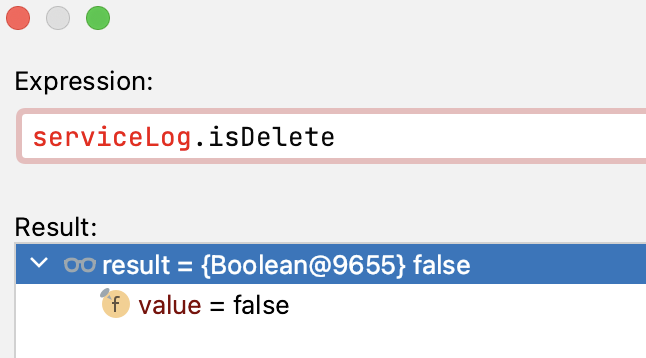 --- #### 实数类型 实数类型因为在该表结构中使用不到我们没有介绍,所以在这里进行补充。 MySQL 既支持 **精确计算** 的类型(DECIMAL),也支持 **近似计算** 的浮点类型(FLOAT 和 DOUBLE)。 FLOAT 使用 4 个字节的存储空间,DOUBLE 使用 8 个字节的存储空间,可以指定列的精度,但是通常情况下建议 **只指定数据类型,而不指定精度**,否则 MySQL 会根据精度自行进行舍入,而且它们还会受到平台或实现依赖性的影响。 我们看下边这个例子: ```sql CREATE TABLE `real_number` ( `f1` float(7, 4) NOT NULL, `f2` float NOT NULL, `d1` double(7, 4) NOT NULL, `d2` double NOT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='实数'; # 插入数据 INSERT into real_number values ( 3.1415926535, 3.1415926535, 3.1415926535, 3.1415926535 ); # 查询结果 select * from real_number; ``` | f1 | f2 | d1 | d2 | | --- | --- | --- | --- | | 3.1416 | 3.14159 | 3.1416 | 3.1415926535 | 根据结果值我们可以发现,指定了精度的浮点类型进行了舍入,没有指定精度的 FLOAT 类型默认保留了小数点后 5 位小数,自行的舍入可能会引起混淆。 通常情况下,我们为了保证最大限度的实现 **可移植性**,需要存储近似数字数据值的代码应该使用 FLOAT 或 DOUBLE,而不指定精度或位数。 还有一种情况需要注意,如果我们要插入超过指定精度的整数范围,会导致数据入库失败,如下: ```sql # 指定 f1 列整数宽度为 4,实际定义允许的最大宽度为 3 INSERT into real_number values ( 3210.1415926535, 3.1415926535, 3.1415926535, 3.1415926535 ); # 结果 SQL 错误 [1264] [22001]: Data truncation: Out of range value for column 'f1' at row 1 ``` 如果没有指定精度范围,那么则会对小数部分进行压缩,精度变小,而不是提示入库失败,如下: ```sql # f2 列插入该值,查看结果 INSERT into real_number values ( 3.1415926535, 3210.1415926535, 3.1415926535, 3.1415926535 ); ``` | f1 | f2 | d1 | d2 | | --- | --- | --- | --- | | 3.1416 | 3210.14 | 3.1416 | 3.1415926535 | DECIMAL 与 FLOAT 和 DOUBLE 不同,在进行精确的小数计算时,**需要指定它的精度**,否则默认情况下为 `DECIMAL(10, 0)` ,只保存整数。而且它在存储相同范围的值是会占用更多的空间,所以出于对额外的空间需求和计算成本的考虑,我们只在需要对小数进行精确计算时才使用该类型。 DECIMAL 的最大位数为 65,而且当为 DECIMAL 列指定的值小数点后位数超过小数位数精度范围时,该值将舍入为精度范围。同样地,如果整数部分的宽度大于指定的精度范围,那么也会发生超出列范围的异常而导致无法正常入库,如下: ```sql create table `decimal_t` ( `d1` decimal(7, 4) NOT NULL )ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='DECIMAL'; INSERT INTO decimal_t values (3.1415926535); # 结果值为 3.1416 INSERT INTO decimal_t values (1234.1415926535); # Data truncation: Out of range value for column 'd1' at row 1 ``` 除此之外,在一些大容量的场景下,可以考虑使用 BIGINT 代替 DECIMAL,在存储时根据小数的位数乘以相应的倍数即可。这样就可以同时避免浮点数计算不精确、 DECIMAL 精确计算代价高和数值精度范围限制的问题。 --- ### 巨人的肩膀 * 《高性能 MySQL 第四版》:第六章 * [11.7 Data Type Storage Requirements](https://dev.mysql.com/doc/refman/5.7/en/storage-requirements.html) * [mysql的日期时间类型及精度问题](https://blog.csdn.net/doublepg13/article/details/128301235) * [MySQL之DATETIME与TIMESTAMP的时间精度问题](https://www.jb51.net/article/276192.htm) * [11.8 Choosing the Right Type for a Column](https://dev.mysql.com/doc/refman/5.7/en/choosing-types.html) * [11.1.4 Floating-Point Types (Approximate Value) - FLOAT, DOUBLE](https://dev.mysql.com/doc/refman/5.7/en/floating-point-types.html) * [B.3.4.8 Problems with Floating-Point Values](https://dev.mysql.com/doc/refman/5.7/en/problems-with-float.html) * 《MySQL 是怎样运行的》:第四章
上一篇:系统架构合理性的思考
下一篇:京东小程序数据中心架构设计与最佳实践
wy****
文章数
47
阅读量
43282
作者其他文章
01
用“分区”来面对超大数据集和超大吞吐量
1. 为什么要分区?分区(partitions) 也被称为 分片(sharding),通常采用对数据进行分区的方式来增加系统的 可伸缩性,以此来面对非常大的数据集或非常高的吞吐量,避免出现热点。分区通常和复制结合使用,使得每个分区的副本存储在多个节点上,保证数据副本的 高可用。如下图所示,如果数据库被分区,每个分区都有一个主库。不同分区的主库可能在不同的节点上,每个节点可能是某些分区的主库,同时是
01
深入理解分布式共识算法 Raft
“不可靠的网络”、“不稳定的时钟”和“节点的故障”都是在分布式系统中常见的问题,在文章开始前,我们先来看一下:如果在分布式系统中网络不可靠会发生什么样的问题。有以下 3 个服务构成的分布式集群,并在 server_1 中发生写请求变更 A = 1,“正常情况下” server_1 将 A 值同步给 server_2 和 server_3,保证集群的数据一致性:但是如果在数据变更时发生网络问题(延迟
01
缓存之美:从根上理解 ConcurrentHashMap
本文将详细介绍 ConcurrentHashMap 构造方法、添加值方法和扩容操作等源码实现。ConcurrentHashMap 是线程安全的哈希表,此哈希表的设计主要目的是在最小化更新操作对哈希表的占用,以保持并发可读性,次要目的是保持空间消耗与 HashMap 相同或更好,并支持利用多线程在空表上高效地插入初始值。在 Java 8 及之后的版本,使用 CAS 操作、 synchronized
01
缓存之美:万文详解 Caffeine 实现原理(上)
由于神灯社区最大字数限制,本文章将分为两篇,第二篇文章为缓存之美:万文详解 Caffeine 实现原理(下)文章将采用“总-分-总”的结构对配置固定大小元素驱逐策略的 Caffeine 缓存进行介绍,首先会讲解它的实现原理,在大家对它有一个概念之后再深入具体源码的细节之中,理解它的设计理念,从中能学习到用于统计元素访问频率的 Count-Min Sketch 数据结构、理解内存屏障和如何避免缓存伪
wy****
文章数
47
阅读量
43282
作者其他文章
01
用“分区”来面对超大数据集和超大吞吐量
01
深入理解分布式共识算法 Raft
01
缓存之美:从根上理解 ConcurrentHashMap
01
缓存之美:万文详解 Caffeine 实现原理(上)
添加企业微信
获取1V1专业服务
扫码关注
京东云开发者公众号




 wy****
wy**** 2023-08-16
2023-08-16 1311浏览
1311浏览






