您好!
欢迎来到京东云开发者社区
登录
首页
博文
课程
大赛
工具
用户中心
开源
首页
博文
课程
大赛
工具
开源
更多
用户中心
开发者社区
>
博文
>
由 Mybatis 源码畅谈软件设计(五):ResultMap 的循环引用
分享
打开微信扫码分享
点击前往QQ分享
点击前往微博分享
点击复制链接
由 Mybatis 源码畅谈软件设计(五):ResultMap 的循环引用
wy****
2024-12-25
IP归属:北京
658浏览
本节我们来了解 Mybatis 是如何处理 ResultMap 的循环引用,它的解决方案非常值得在软件设计中参考。另外作为引申,大家可以了解一下 Spring 是如何解决 Bean 的循环注入的。 以单测 `org.apache.ibatis.submitted.permissions.PermissionsTest#checkNestedResultMapLoop` 为例,它对应表结构和表中的数据为: ```sql create table permissions ( resourceName varchar(20), principalName varchar(20), permission varchar(20) ); insert into permissions values ('resource1', 'user1', 'read'); insert into permissions values ('resource1', 'user2', 'read'); insert into permissions values ('resource1', 'user1', 'create'); insert into permissions values ('resource2', 'user1', 'delete'); insert into permissions values ('resource2', 'user1', 'update'); ``` 在 Mapper 中定义的循环引用的 `ResultMap` 为: ```xml <mapper namespace="org.apache.ibatis.submitted.permissions.PermissionsMapper"> <resultMap id="resourceResults" type="Resource"> <id property="name" column="resourceName" /> <collection property="principals" resultMap="principalResults" /> </resultMap> <resultMap id="principalResults" type="Principal"> <id property="principalName" column="principalName" /> <collection property="permissions" resultMap="permissionResults" /> </resultMap> <resultMap id="permissionResults" type="Permission"> <result property="permission" column="permission" /> <association property="resource" resultMap="resourceResults" /> </resultMap> <!-- ... --> </mapper> ``` `resourceResults` 引用 `principalResults` 引用 `permissionResults` 引用 `resourceResults`,构建成了循环引用。 将数据库中数据映射为 Java 对象的类定义如下: ```java public class Resource { private String name; private List<Principal> principals = new ArrayList<>(); } public class Principal { private String principalName; private List<Permission> permissions = new ArrayList<>(); } public class Permission { private String permission; private Resource resource; } ``` 为了方便大家理解,在看源码前,先给大家图示下循环引用构造结果对象的流程: 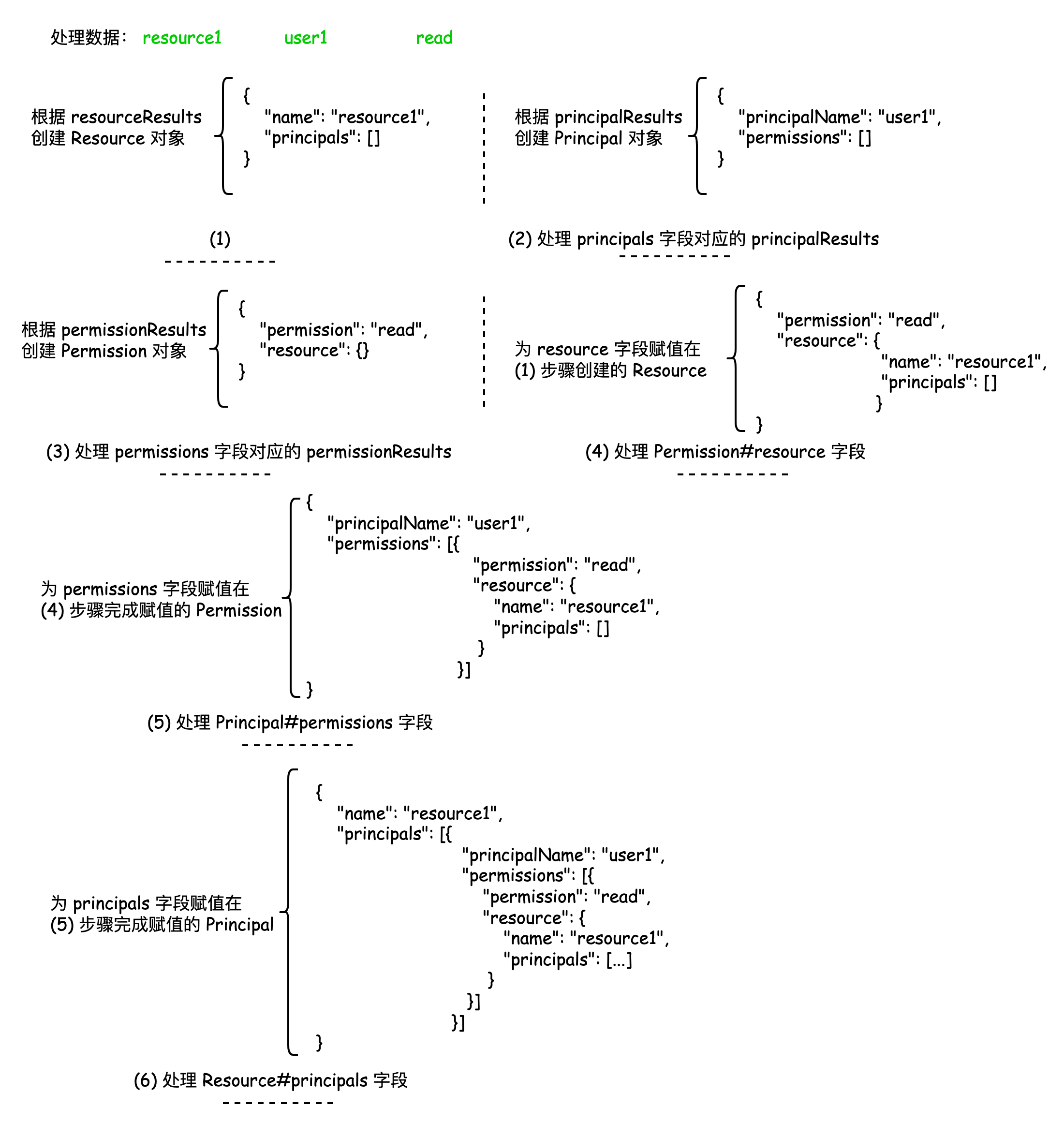 由图示可知,Mybatis 在处理循环引用时,会根据引用关系创建最外层对象,每遇到新的引用,都会创建新的对象,并将这些对象“存”起来,当遇到现有对象需要被引用时,则会从“缓存”中取,不断地回归处理引用关系,这和算法中“递归”的思想一致,接下来我们看一下源码中是如何处理的,我们直接看 `org.apache.ibatis.executor.resultset.DefaultResultSetHandler#handleRowValuesForNestedResultMap` 方法,它是处理循环引用的入口: ```java public class DefaultResultSetHandler implements ResultSetHandler { // ... private final Map<CacheKey, Object> nestedResultObjects = new HashMap<>(); private void handleRowValuesForNestedResultMap(ResultSetWrapper rsw, ResultMap resultMap, ResultHandler<?> resultHandler, RowBounds rowBounds, ResultMapping parentMapping) throws SQLException { final DefaultResultContext<Object> resultContext = new DefaultResultContext<>(); ResultSet resultSet = rsw.getResultSet(); skipRows(resultSet, rowBounds); Object rowValue = previousRowValue; while (shouldProcessMoreRows(resultContext, rowBounds) && !resultSet.isClosed() && resultSet.next()) { final ResultMap discriminatedResultMap = resolveDiscriminatedResultMap(resultSet, resultMap, null); // 根据ID字段名和值(或其他字段名和值,不包括循环引用字段)信息创建缓存 key,这样同一个字段的同一个值就对应了一个缓存对象,避免重复创建对象 // 这样,在做一对多或多对一时,便能根据 key 值获取到所属对象 final CacheKey rowKey = createRowKey(discriminatedResultMap, rsw, null); // 循环引用对象缓存中获取对象;partial 的释义为 adj.部分的,如此命名表示该对象中一对多或多对一关系未被处理完成 Object partialObject = nestedResultObjects.get(rowKey); if (mappedStatement.isResultOrdered()) { if (partialObject == null && rowValue != null) { nestedResultObjects.clear(); storeObject(resultHandler, resultContext, rowValue, parentMapping, resultSet); } rowValue = getRowValue(rsw, discriminatedResultMap, rowKey, null, partialObject); } else { // 获取该行数据库对应的 Java 对象 rowValue = getRowValue(rsw, discriminatedResultMap, rowKey, null, partialObject); if (partialObject == null) { storeObject(resultHandler, resultContext, rowValue, parentMapping, resultSet); } } } if (rowValue != null && mappedStatement.isResultOrdered() && shouldProcessMoreRows(resultContext, rowBounds)) { storeObject(resultHandler, resultContext, rowValue, parentMapping, resultSet); previousRowValue = null; } else if (rowValue != null) { previousRowValue = rowValue; } } } ``` 在这个方法中需要特别关注两个点: **第一点**:缓存 `CacheKey rowKey` key的创建规则和缓存 `Map<CacheKey, Object> nestedResultObjects`。它们的作用是什么呢?`CacheKey` 会根据字段和字段值完成创建,比如以 `Resource` 中字段 `name` 值为 `resource1` 的数据为例,虽然在数据库中有多行相同的 `name` 值数据(文章开篇示例 SQL 中向 `permissions` 表中插入多条 `name` 值相同的数据),但是它们会对应到同一个 `CacheKey` 对象,那么这样在解决 `resourceResults` 中定义的 **collection 标签** 的一对多关系时,能直接获取到对应的 `Resource` 对象,并向其中表示一对多关系的集合中添加值。以我们的样例数据为例,查询完毕后的对象如下所示: 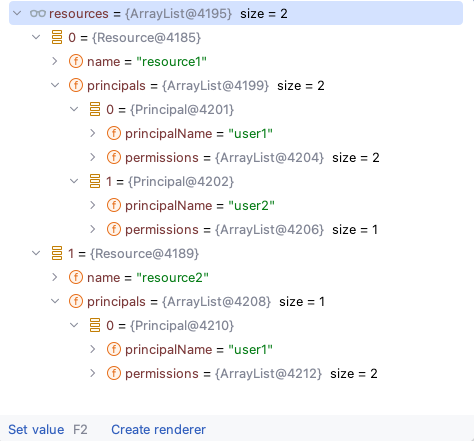 可以发现 `resource1` 的 `principals` 字段会对应多个 `Principal` 对象,那么在解析完数据库中第一行 `resource1` 的数据时,它所需要的 `Principal` 集合的一对多关系并没有完成赋值,会将其缓存起来,那么在处理数据库中第二行 `resource1` 的数据时,需要将它添加到一对多集合中,这时候便会从缓存 `Map<CacheKey, Object> nestedResultObjects` 获取出来处理第一行的数据,因为第二行数据的 `name` 同样为 `resource1` 所以能通过 `CacheKey` 获取到已完成处理的第一行数据对应的对象,这样便能完成一对多关系的封装。 **第二点**:`DefaultResultSetHandler#getRowValue` 方法,它是处理循环引用,将数据库中数据处理成 Java 对象的核心方法,如下所示: ```java public class DefaultResultSetHandler implements ResultSetHandler { private final Map<String, Object> ancestorObjects = new HashMap<>(); private Object getRowValue(ResultSetWrapper rsw, ResultMap resultMap, CacheKey combinedKey, String columnPrefix, Object partialObject) throws SQLException { final String resultMapId = resultMap.getId(); Object rowValue = partialObject; if (rowValue != null) { // rowValue 不为 null 时,表示数据库包含多行相同键值数据,需要处理它们的聚合关系,一对多or多对一 final MetaObject metaObject = configuration.newMetaObject(rowValue); ancestorObjects.put(resultMapId, rowValue); // 处理循环引用的映射关系 applyNestedResultMappings(rsw, resultMap, metaObject, columnPrefix, combinedKey, false); ancestorObjects.remove(resultMapId); } else { final ResultLoaderMap lazyLoader = new ResultLoaderMap(); // 创建未赋值的结果对象 rowValue = createResultObject(rsw, resultMap, lazyLoader, columnPrefix); if (rowValue != null && !hasTypeHandlerForResultObject(rsw, resultMap.getType())) { final MetaObject metaObject = configuration.newMetaObject(rowValue); boolean foundValues = this.useConstructorMappings; if (shouldApplyAutomaticMappings(resultMap, true)) { foundValues = applyAutomaticMappings(rsw, resultMap, metaObject, columnPrefix) || foundValues; } // 根据 result mapping 中配置的字段和数据库列的映射关系,从 resultSet 中取值后封装给 metaObject foundValues = applyPropertyMappings(rsw, resultMap, metaObject, lazyLoader, columnPrefix) || foundValues; // 添加到 ancestor 缓存中,用于封装循环引用对象;ancestor 祖先,原型 ancestorObjects.put(resultMapId, rowValue); // 处理循环引用的映射关系 foundValues = applyNestedResultMappings(rsw, resultMap, metaObject, columnPrefix, combinedKey, true) || foundValues; ancestorObjects.remove(resultMapId); foundValues = lazyLoader.size() > 0 || foundValues; rowValue = foundValues || configuration.isReturnInstanceForEmptyRow() ? rowValue : null; } if (combinedKey != CacheKey.NULL_CACHE_KEY) { nestedResultObjects.put(combinedKey, rowValue); } } return rowValue; } } ``` 其中有两个分支,分别为 `partialObject` 是否为空的情况,为空时会创建对应的结果对象,并为非循环引用的字段赋值(`applyPropertyMappings` 方法),不为空时它便是我们在我们上述的 `nestedResultObjects` 缓存中获取到了对象,来处理它的聚合关系。该方法中使用到的 `Map<String, Object> ancestorObjects` 缓存需要强调下,它是用来 **处理循环引用关系的缓存**。回到文章开头的流程图示,在第 4 步中,要获取 `Resource` 对象赋值便是从 `ancestorObjects` 缓存中获取的,`Resource` 对象先被创建后并置于缓存中,当后续有对象引用它时,直接在缓存中获取,避免重复创建,解决循环引用的问题。 其中 `applyNestedResultMappings` 方法是用于处理循环引用关系的方法: ```java public class DefaultResultSetHandler implements ResultSetHandler { private final Map<CacheKey, Object> nestedResultObjects = new HashMap<>(); private final Map<String, Object> ancestorObjects = new HashMap<>(); private boolean applyNestedResultMappings(ResultSetWrapper rsw, ResultMap resultMap, MetaObject metaObject, String parentPrefix, CacheKey parentRowKey, boolean newObject) { boolean foundValues = false; for (ResultMapping resultMapping : resultMap.getPropertyResultMappings()) { final String nestedResultMapId = resultMapping.getNestedResultMapId(); if (nestedResultMapId != null && resultMapping.getResultSet() == null) { try { final String columnPrefix = getColumnPrefix(parentPrefix, resultMapping); final ResultMap nestedResultMap = getNestedResultMap(rsw.getResultSet(), nestedResultMapId, columnPrefix); if (resultMapping.getColumnPrefix() == null) { // 为未声明列前缀的 result_mapping 封装循环引用对象 Object ancestorObject = ancestorObjects.get(nestedResultMapId); if (ancestorObject != null) { if (newObject) { linkObjects(metaObject, resultMapping, ancestorObject); } continue; } } // 同样创建缓存 KEY,并从循环应用缓存中获取已经创建但可能未完成一对多和多对一关系的对象 final CacheKey rowKey = createRowKey(nestedResultMap, rsw, columnPrefix); final CacheKey combinedKey = combineKeys(rowKey, parentRowKey); Object rowValue = nestedResultObjects.get(combinedKey); boolean knownValue = rowValue != null; instantiateCollectionPropertyIfAppropriate(resultMapping, metaObject); if (anyNotNullColumnHasValue(resultMapping, columnPrefix, rsw)) { // 获取该行数据 rowValue = getRowValue(rsw, nestedResultMap, combinedKey, columnPrefix, rowValue); if (rowValue != null && !knownValue) { // 封装到结果对象中 linkObjects(metaObject, resultMapping, rowValue); foundValues = true; } } } catch (SQLException e) { throw new ExecutorException( "Error getting nested result map values for '" + resultMapping.getProperty() + "'. Cause: " + e, e); } } } return foundValues; } private void linkObjects(MetaObject metaObject, ResultMapping resultMapping, Object rowValue) { final Object collectionProperty = instantiateCollectionPropertyIfAppropriate(resultMapping, metaObject); // 如果是一对多关系,则添加到对应集合中 if (collectionProperty != null) { final MetaObject targetMetaObject = configuration.newMetaObject(collectionProperty); targetMetaObject.add(rowValue); } else { // 否则直接为对应字段赋值 metaObject.setValue(resultMapping.getProperty(), rowValue); } } } ``` 值得关注的是该方法中也调用了 `getRowValue` 方法,这样便形成了 **递归调用**,这也是解决循环引用问题的关键。另一个需要关注的是其中的 `linkObjects` 封装结果的方法,如果是一对多关系,它会向集合中进行添加,否则便直接为对象赋值。 ResultMap 的循环引用并不复杂,在本节中我们并没有深入源码的细节,更多关注的是解决循环引用的方法,即 **递归 + 缓存** 的解决方案,建议大家执行对应单测来熟悉流程并了解相关细节。
上一篇:设计模式之代理模式:武器附魔之道
下一篇:由 Mybatis 源码畅谈软件设计(七):从根上理解 Mybatis 一级缓存
wy****
文章数
47
阅读量
37765
作者其他文章
01
用“分区”来面对超大数据集和超大吞吐量
1. 为什么要分区?分区(partitions) 也被称为 分片(sharding),通常采用对数据进行分区的方式来增加系统的 可伸缩性,以此来面对非常大的数据集或非常高的吞吐量,避免出现热点。分区通常和复制结合使用,使得每个分区的副本存储在多个节点上,保证数据副本的 高可用。如下图所示,如果数据库被分区,每个分区都有一个主库。不同分区的主库可能在不同的节点上,每个节点可能是某些分区的主库,同时是
01
深入理解分布式共识算法 Raft
“不可靠的网络”、“不稳定的时钟”和“节点的故障”都是在分布式系统中常见的问题,在文章开始前,我们先来看一下:如果在分布式系统中网络不可靠会发生什么样的问题。有以下 3 个服务构成的分布式集群,并在 server_1 中发生写请求变更 A = 1,“正常情况下” server_1 将 A 值同步给 server_2 和 server_3,保证集群的数据一致性:但是如果在数据变更时发生网络问题(延迟
01
缓存之美:从根上理解 ConcurrentHashMap
本文将详细介绍 ConcurrentHashMap 构造方法、添加值方法和扩容操作等源码实现。ConcurrentHashMap 是线程安全的哈希表,此哈希表的设计主要目的是在最小化更新操作对哈希表的占用,以保持并发可读性,次要目的是保持空间消耗与 HashMap 相同或更好,并支持利用多线程在空表上高效地插入初始值。在 Java 8 及之后的版本,使用 CAS 操作、 synchronized
01
缓存之美:万文详解 Caffeine 实现原理(上)
由于神灯社区最大字数限制,本文章将分为两篇,第二篇文章为缓存之美:万文详解 Caffeine 实现原理(下)文章将采用“总-分-总”的结构对配置固定大小元素驱逐策略的 Caffeine 缓存进行介绍,首先会讲解它的实现原理,在大家对它有一个概念之后再深入具体源码的细节之中,理解它的设计理念,从中能学习到用于统计元素访问频率的 Count-Min Sketch 数据结构、理解内存屏障和如何避免缓存伪
wy****
文章数
47
阅读量
37765
作者其他文章
01
用“分区”来面对超大数据集和超大吞吐量
01
深入理解分布式共识算法 Raft
01
缓存之美:从根上理解 ConcurrentHashMap
01
缓存之美:万文详解 Caffeine 实现原理(上)
添加企业微信
获取1V1专业服务
扫码关注
京东云开发者公众号




 wy****
wy**** 2024-12-25
2024-12-25 658浏览
658浏览






