您好!
欢迎来到京东云开发者社区
登录
首页
博文
课程
大赛
工具
用户中心
开源
首页
博文
课程
大赛
工具
开源
更多
用户中心
开发者社区
>
博文
>
由 Mybatis 源码畅谈软件设计(四):动态 SQL 执行流程
分享
打开微信扫码分享
点击前往QQ分享
点击前往微博分享
点击复制链接
由 Mybatis 源码畅谈软件设计(四):动态 SQL 执行流程
wy****
2024-12-25
IP归属:北京
679浏览
本节我们探究动态 SQL 的执行流程,由于在前一节我们已经对各个组件进行了详细介绍,所以本节不再赘述相关内容,在本节中主要强调静态 SQL 和动态 SQL 执行的不同之处。在这个过程中,`SqlNode` 相关实现值得关注,它为动态 SQL 标签都定义了专用实现类,遵循单一职责的原则,并且应用了 **装饰器模式**。最后,我们还会讨论动态 SQL 避免注入的解决方案,它是在 Mybatis 中不可略过的一环。 ### 动态 SQL 执行流程 以单测 `org.apache.ibatis.session.SqlSessionTest#dynamicSqlParse` 为例,动态 SQL 执行查询时,第一个需要注意点是获取 `BoundSql` 对象: ```java public final class MappedStatement { // sqlSource 存储 SQL 语句,区分静态、动态SQL private SqlSource sqlSource; public BoundSql getBoundSql(Object parameterObject) { BoundSql boundSql = sqlSource.getBoundSql(parameterObject); // ... } // ... } ``` 在讲解 `MappedStatement` 时,我们提到了包含动态标签和 `$` 符号的 SQL 会被解析成 `DynamicSqlSource`,所以它在获取 `BoundSql` 时会执行如下逻辑: ```java public class DynamicSqlSource implements SqlSource { private final Configuration configuration; private final SqlNode rootSqlNode; public DynamicSqlSource(Configuration configuration, SqlNode rootSqlNode) { this.configuration = configuration; this.rootSqlNode = rootSqlNode; } public BoundSql getBoundSql(Object parameterObject) { // 创建动态 SQL 的上下文信息 DynamicContext context = new DynamicContext(configuration, parameterObject); // 根据上下文信息拼接 SQL,处理 SQL 中的动态标签 // 处理完成后 SQL 为不包含任何动态标签,为可能包含 #{} 占位符的 SQL 信息,SQL 会被封装到上下文的 sqlBuilder 对象中 rootSqlNode.apply(context); // 处理拼接完成后 SQL 中的 #{} 占位符,将占位符替换为 ? SqlSourceBuilder sqlSourceParser = new SqlSourceBuilder(configuration); Class<?> parameterType = parameterObject == null ? Object.class : parameterObject.getClass(); // 解析完成后的 SqlSource 均为 StaticSqlSource 类型,其中记录解析完成后的完整 SQL SqlSource sqlSource = sqlSourceParser.parse(context.getSql(), parameterType, context.getBindings()); // StaticSqlSource 获取 BoundSql SQL 的方法就非常简单了:将 SQL 和参数信息记录下来 BoundSql boundSql = sqlSource.getBoundSql(parameterObject); // 在 BoundSql 对象中 additionalParameters Map 中添加 key 为 _parameter,value 为入参 的附加参数信息 context.getBindings().forEach(boundSql::setAdditionalParameter); return boundSql; } } ``` 首先它会创建动态 SQL 上下文信息 `DynamicContext`,这里并不复杂,所以不再追溯源码信息。`rootSqlNode` 对象在讲解映射配置时我们提到过,它会被解析成 `MixedSqlNode` 类型,其中包含着各个节点的信息,如下所示: 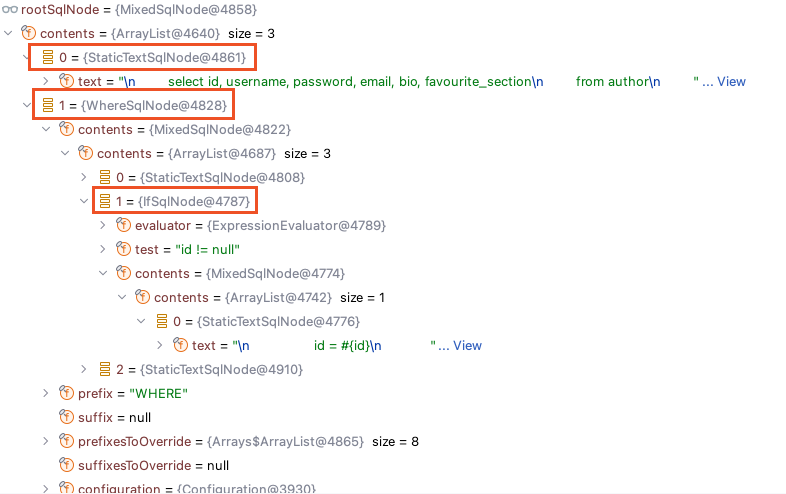 `MixedSqlNode` 会根据上下文信息完成 `apply` 操作,如注释信息所述,最终会将带有动态标签的多个节点的 SQL 解析成一条 SQL 字符串记录在上下文中。下面我们重点看一下 **动态标签 <WHERE>** 的处理逻辑,它使用到了 **装饰器模式** 和 **静态代理模式**,`WhereSqlNode` 实现了 `TrimSqlNode`,但是它几乎并没有承载任何功能,只是定义了 SQL 连接符信息,这个实现类起到更多的作用是增强代码可读性和遵守单一职责的原则: ```java public class WhereSqlNode extends TrimSqlNode { private static final List<String> prefixList = Arrays.asList("AND ", "OR ", "AND\n", "OR\n", "AND\r", "OR\r", "AND\t", "OR\t"); public WhereSqlNode(Configuration configuration, SqlNode contents) { super(configuration, contents, "WHERE", prefixList, null, null); } } ``` 处理逻辑均在 `TrimSqlNode` 中实现,它在其中定义了 `SqlNode contents`,其中最重要的是 `apply` 方法,装饰器模式便体现在这里:它对组合进来的其他 `SqlNode` 的 `apply` 方法进行增强,添加处理前缀和后缀标识符信息的逻辑,如下所示: ```java public class TrimSqlNode implements SqlNode { private final SqlNode contents; @Override public boolean apply(DynamicContext context) { FilteredDynamicContext filteredDynamicContext = new FilteredDynamicContext(context); boolean result = contents.apply(filteredDynamicContext); // 处理前缀和后缀标识符信息 filteredDynamicContext.applyAll(); return result; } private class FilteredDynamicContext extends DynamicContext { // ... } } ```  实现处理前缀和后缀表示逻辑的 `FilteredDynamicContext` 是定义在 `TrimSqlNode` 中的内部类,它使用到了静态代理模式,在 Mybatis 框架中,出现 `delegate` 字段命名时,便需要对代理模式多留意了,而且这种命名也提醒我们,未来在使用到代理模式时,可以将被代理对象命名为 `delegate`。 `DynamicContext delegate` 对象被代理,由代理对象 `FilteredDynamicContext` 完成前后缀处理,最后将处理完的 SQL 拼接到原上下文中: ```java public class TrimSqlNode implements SqlNode { // ... private class FilteredDynamicContext extends DynamicContext { private final DynamicContext delegate; private boolean prefixApplied; private boolean suffixApplied; private StringBuilder sqlBuffer; public void applyAll() { sqlBuffer = new StringBuilder(sqlBuffer.toString().trim()); String trimmedUppercaseSql = sqlBuffer.toString().toUpperCase(Locale.ENGLISH); if (trimmedUppercaseSql.length() > 0) { // 处理前缀标识符比如,WHERE,SET applyPrefix(sqlBuffer, trimmedUppercaseSql); // 处理后缀标识符,一般用于自定义 TrimSqlNode applySuffix(sqlBuffer, trimmedUppercaseSql); } delegate.appendSql(sqlBuffer.toString()); } } } ``` 这段逻辑并不复杂,除此之外我们需要再关注下 `IfSqlNode` 的逻辑,探究 **IF 标签** 中的内容是如何被拼接到 SQL 中的: ```java public class IfSqlNode implements SqlNode { private final ExpressionEvaluator evaluator; private final String test; private final SqlNode contents; @Override public boolean apply(DynamicContext context) { // 判断表达式,如果 if 标签中 test 判断为 true 则将对应的 SQL 片段拼接到 SQL 上 if (evaluator.evaluateBoolean(test, context.getBindings())) { contents.apply(context); return true; } return false; } } ``` 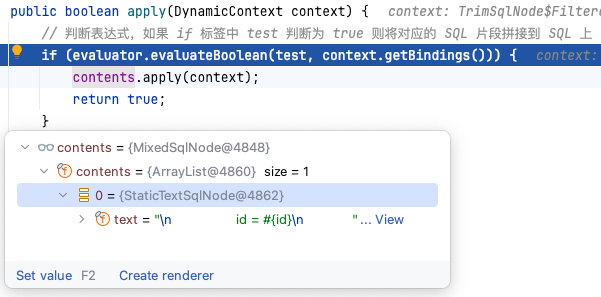 它会借助 **OGNL** 完成 test 表达式内容的判断,为 True 则会追加对应 SQL 信息。 接下来继续回到 `DynamicSqlSource#getBoundSql` 方法,将 `#{}` 占位符替换为 `?` 的逻辑在讲解映射配置时已讲过,不清楚的小伙伴可以再去了解一下,这部分内容没有特别需要关注的,了解下该方法的作用即可: ```java public class DynamicSqlSource implements SqlSource { // ... @Override public BoundSql getBoundSql(Object parameterObject) { // ... // 处理拼接完成后 SQL 中的 #{} 占位符,将占位符替换为 ? SqlSourceBuilder sqlSourceParser = new SqlSourceBuilder(configuration); Class<?> parameterType = parameterObject == null ? Object.class : parameterObject.getClass(); // 解析完成后的 SqlSource 均为 StaticSqlSource 类型,其中记录解析完成后的完整 SQL SqlSource sqlSource = sqlSourceParser.parse(context.getSql(), parameterType, context.getBindings()); // StaticSqlSource 获取 BoundSql SQL 的方法就非常简单了:将 SQL 和参数信息记录下来 BoundSql boundSql = sqlSource.getBoundSql(parameterObject); // 在 BoundSql 对象中 additionalParameters Map 中添加 key 为 _parameter,value 为入参 的附加参数信息 context.getBindings().forEach(boundSql::setAdditionalParameter); return boundSql; } } ``` 到这里,带有动态标签的 SQL 已被处理成可能带有 `?` 占位符的 SQL 字符串了,后续逻辑与上一节中介绍 SQL 的执行流程没有区别,便不再赘述了。接下来我们讨论下 `#{}` 占位符是如何避免 SQL 注入的问题。 ### #{} 是如何解决 SQL 注入的? 我们已经了解到 `#{}` 占位符会被解析成 `?`,在 SQL 被执行时,由 JDBC 的 `PreparedStatement` 将对应的参数会绑定到对应的位置上,它并 **不是直接将内容拼接到 SQL 上**,注入的 SQL 内容将会 **被看作字符串处理**,它便是通过这种方式来避免 SQL 注入的。 以 `org.apache.ibatis.session.SqlSessionTest#dynamicTableName` 单测为例: ```java class SqlSessionTest extends BaseDataTest { @Test void dynamicTableName() { try (SqlSession session = sqlMapper.openSession()) { AuthorMapper mapper = session.getMapper(AuthorMapper.class); List<Author> author = mapper.selectDynamicTableName("author"); assertEquals(2, author.size()); } } } ``` ```sql <select id="selectDynamicTableName" parameterType="string" resultMap="selectAuthor"> select id, username, password, email, bio, favourite_section from #{tableName} </select> ``` 我们想使用 `#{}` 占位符动态替换表名,试验下能不能成功,结果控制台打印以下内容: ```text ### SQL: select id, username, password, email, bio, favourite_section from ? ### Cause: java.sql.SQLSyntaxErrorException: You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near ''author'' at line 2 ``` 发现它将表名参数作为字符串处理,实际执行的 SQL 为: ```sql select id, username, password, email, bio, favourite_section from 'author' ``` 所以任何要注入的 SQL 内容是不能影响到 SQL 语句的,保证了安全性。那么 `$` 占位符是如何实现动态 SQL 拼接的呢?我们将 SQL 修改一下: ```sql <select id="selectDynamicTableName" parameterType="string" resultMap="selectAuthor"> select id, username, password, email, bio, favourite_section from ${tableName} </select> ``` 先前我们提到过,包含 `$` 占位符的 SQL 也会被识别为动态 SQL(`SqlSource` 类型为 `DynamicSqlSource`),同样我们需要看一下它获取 `BoundSql` 的逻辑 `org.apache.ibatis.scripting.xmltags.DynamicSqlSource#getBoundSql`。在执行该方法时,可以发现整条 SQL 语句被解析为字符串保存在 `TextSqlNode` 中:  我们继续看一下 `apply` 方法的逻辑,发现它会创建一个专门替换 `${}` 占位符 `GenericTokenParser` 解析器: ```java public class TextSqlNode implements SqlNode { // eg: select id, username, password, email, bio, favourite_section from ${tableName} private final String text; @Override public boolean apply(DynamicContext context) { GenericTokenParser parser = createParser(new BindingTokenParser(context, injectionFilter)); context.appendSql(parser.parse(text)); return true; } private GenericTokenParser createParser(TokenHandler handler) { return new GenericTokenParser("${", "}", handler); } } ``` 这样它在执行 `GenericTokenParser#parser` 方法时,便会根据上下文信息 **将 `${}` 替换成参数直接拼接到 SQL 上**,最终 SQL 为: ```sql select id, username, password, email, bio, favourite_section from author ``` 它会直接 原 SQL 上进行拼接,所以会有 SQL 注入的风险,而且我们也能理解包含 `${}` 的 SQL 节点被命名为 `TextSqlNode` 的原因了,`Test` 便表示 SQL 会被解析为一段 SQL 的文本表达式。 ### 巨人的肩膀 - [百度百科 - OGNL](https://baike.baidu.com/item/OGNL/10365326)
上一篇:由 Mybatis 源码畅谈软件设计(七):从根上理解 Mybatis 一级缓存
下一篇:纯配时效服务-双Redis集群设计
wy****
文章数
47
阅读量
43391
作者其他文章
01
用“分区”来面对超大数据集和超大吞吐量
1. 为什么要分区?分区(partitions) 也被称为 分片(sharding),通常采用对数据进行分区的方式来增加系统的 可伸缩性,以此来面对非常大的数据集或非常高的吞吐量,避免出现热点。分区通常和复制结合使用,使得每个分区的副本存储在多个节点上,保证数据副本的 高可用。如下图所示,如果数据库被分区,每个分区都有一个主库。不同分区的主库可能在不同的节点上,每个节点可能是某些分区的主库,同时是
01
深入理解分布式共识算法 Raft
“不可靠的网络”、“不稳定的时钟”和“节点的故障”都是在分布式系统中常见的问题,在文章开始前,我们先来看一下:如果在分布式系统中网络不可靠会发生什么样的问题。有以下 3 个服务构成的分布式集群,并在 server_1 中发生写请求变更 A = 1,“正常情况下” server_1 将 A 值同步给 server_2 和 server_3,保证集群的数据一致性:但是如果在数据变更时发生网络问题(延迟
01
缓存之美:从根上理解 ConcurrentHashMap
本文将详细介绍 ConcurrentHashMap 构造方法、添加值方法和扩容操作等源码实现。ConcurrentHashMap 是线程安全的哈希表,此哈希表的设计主要目的是在最小化更新操作对哈希表的占用,以保持并发可读性,次要目的是保持空间消耗与 HashMap 相同或更好,并支持利用多线程在空表上高效地插入初始值。在 Java 8 及之后的版本,使用 CAS 操作、 synchronized
01
缓存之美:万文详解 Caffeine 实现原理(上)
由于神灯社区最大字数限制,本文章将分为两篇,第二篇文章为缓存之美:万文详解 Caffeine 实现原理(下)文章将采用“总-分-总”的结构对配置固定大小元素驱逐策略的 Caffeine 缓存进行介绍,首先会讲解它的实现原理,在大家对它有一个概念之后再深入具体源码的细节之中,理解它的设计理念,从中能学习到用于统计元素访问频率的 Count-Min Sketch 数据结构、理解内存屏障和如何避免缓存伪
wy****
文章数
47
阅读量
43391
作者其他文章
01
用“分区”来面对超大数据集和超大吞吐量
01
深入理解分布式共识算法 Raft
01
缓存之美:从根上理解 ConcurrentHashMap
01
缓存之美:万文详解 Caffeine 实现原理(上)
添加企业微信
获取1V1专业服务
扫码关注
京东云开发者公众号




 wy****
wy**** 2024-12-25
2024-12-25 679浏览
679浏览






