



编者荐语:
5.x 是 Apache ShardingSphere从分库分表中间件向分布式数据库生态转化的里程碑,从 4.x 版本后期开始打磨的可插拔架构在 5.x 版本已逐渐成型,项目的设计理念和 API 都进行了大幅提升。欢迎大家测试使用!
距离最后一个 4.x 版本的发布时间已半年有余,在此期间, Apache ShardingSphere 社区对产品不断的打磨和优化,并在刚刚过去的双十一前夕发布了其 5.x 的首个版本—— 5.0.0-alpha。
它是 Apache ShardingSphere 从分库分表中间件向分布式数据库生态转化的里程碑。从 4.x 版本后期伊始打磨的可插拔架构在 5.x 版本终见雏型,项目的设计理念和 API 都随之大幅革新。
本文将向读者阐述其新一代分布式数据库生态圈的设计理念和产品变革精髓。
在 Apache ShardingSphere 全新发布的 5.0.0-alpha 中,除去例行的功能优化、缺陷修复以及代码重构外,其里程碑更新是可插拔架构、独立化的 SQL 解析引擎以及全新 DistSQL 的支持。
可插拔架构是内核层面的重大提升,工程师能够通过可插拔的方式自由定制所需功能。
经过长年累月打磨而成的 SQL 解析引擎,在独立化之后,能够为开发者提供 JSqlParser等同类开源项目之外的另一个选择。
DistSQL 的出现,使 Apache ShardingSphere 的所有操作均可通过 SQL 完成。它的存在意义是让 Apache ShardingSphere 从数据库中间件的预先配置的工作流程,转向分布式数据库的动态操作的工作流程。
下文我将详细阐述 Apache ShardingSphere 5.x 的重要革新点,主要包括三个部分:
日月之行,若出其中。星汉灿烂,若出其里——可插拔架构
不受百炼,难以成钢——独立化 SQL 解析引擎
万物之始,大道至简,衍化至繁——DistSQL支持
可插拔架构是 Apache ShardingSphere 长期以来一直致力于打造的“微内核,强生态”架构模式。它追求各个模块的相互独立和互无感知,并且通过一个高灵活度,可插拔和可扩展内核,以叠加的方式将各种功能组合使用。
目前,数据分片、读写分离、数据加密、影子库等功能,以及 MySQL、PostgreSQL、SQLServer、Oracle 等 SQL 与协议的支持,均通过插件的方式织入项目。开发者能够像使用积木一样定制属于自己独特的数据库系统。
可插拔架构的完善,使 Apache ShardingSphere 从分库分表中间件蜕变成为分布式数据库的生态系统。项目从提供功能,转化为提供基础设施(积木)和最佳实践(功能)。Apache ShardingSphere 完全遵循开闭原则(OCP),真正的做到了面向修改关闭,面向扩展开放。开发者通过实现系统所提供的扩展点进行扩展,而无需改写项目已有代码。
扩展点划分为技术扩展点和功能扩展点两大类。
包括 SQL 方言解析、数据库协议、分布式事务、注册中心等。开发者可以通过技术扩展点将更多技术组件融入 Apache ShardingSphere 生态圈。
SQL 解析
主要包括 SQL 语法树解析和SQL 语法树遍历的扩展点。
SQL 语法树解析器内置提供了 MySQL、PostgreSQL、SQLServer、Oracle 和 SQL92 的实现。开发者可以通过实现 SQL 解析扩展点自行实现 Apache ShardingSphere 还未支持的 SQL 方言,如:DB2。
SQL 语法树遍历器内置提供了转化为 Apache ShardingSphere 内核所需的 SQLStatement 提取器,目前正在完善 SQL 格式化的默认实现。开发者同样可以通过扩展点自行实现未支持的功能,如:SQL 审计。
数据库协议
主要包括数据库协议层和数据源 URL 识别的扩展点。
目前对 MySQL 协议支持比较完善,也支持 PostgreSQL 协议。
分布式事务
主要包括事务管理器的扩展点。
事务管理器支持 XA 事务和柔性事务,其中 XA 事务还支持基于多种不同类型的事务管理器实现。京东内部的分布式事务引擎 JDTX 也是事务管理器扩展点的一个实现。
注册中心
主要包括注册中心支持的扩展点。
目前比较完善的支持 ZooKeeper 和 ETCD 作为注册中心的实现,也简单支持 Apollo 和 Nacos 作为配置中心的实现。
包括内核级扩展点和细化功能级扩展点。
内核级扩展点包括元数据加载、路由引擎、改写引擎、执行引擎、归并引擎和配置等。
开发者可以通过实现内核级扩展点完成定制化功能的开发。
目前,Apache ShardingSphere 基于内核扩展点实现了数据分片、读写分离、数据加密和影子库的功能,高可用功能正在开发中,我所在的公司内部也正在基于这些扩展点实现其他高阶功能。
配置是用户与 Apache ShardingSphere 交互的桥梁,是添加新功能所必须实现的扩展点。它具体包括规则创建、YAML 转换和快捷方式定义、Spring 自定义命名空间和 Spring Boot Starter 配置等。
其他扩展点的使用,需要根据具体的功能需求来确定。
数据分片实现了元数据加载、路由引擎、改写引擎、执行引擎和归并引擎的全部扩展点;
读写分离则只需实现路由引擎扩展点即可;
数据加密实现了元数据加载、改写引擎和归并引擎扩展点;
影子库实现了路由引擎和改写引擎扩展点;
每个功能又可划分各自细化的功能级扩展点。
数据分片功能提供分片算法、分布式主键生成策略和时间服务扩展点。
读写分离功能提供从库负载均衡扩展点。
数据加密功能提供加解密算法扩展点。
影子库功能暂无扩展点。
功能扩展点的发布,一改 Apache ShardingSphere 以数据分片为核心的原产品形态,新架构将数据分片从项目内核中抽离,并沉淀为一个与读写分离、数据加密和影子库相同的可选功能。功能之间相互隔离,互无感知,但能够以叠加的方式组合使用。
原架构模型的数据分片(必须) + 读写分离(可选) + 数据加密(可选)固定的组合方式,在新架构中能够以数据分片(可选) + 读写分离(可选) + 数据加密(可选)+ 其他(可选)的方式自由组合使用。
技术扩展点和功能扩展点以相乘的方式排列组合,加之用户可以自行定制化所需扩展点来完成的个性化功能,形成了庞大 的Apache ShardingSphere 生态圈。它成为连接异构数据库和统一化增量功能的桥梁。
功能的可扩展空间十分多,除了社区正在开发中的高可用之外,多租户、SQL 旁路审计、异构索引优化、TTL 等功能,都能够通过扩展点无缝的加入到生态之中。未来社区也会提供更多的任务,欢迎感兴趣的同学一起贡献。功能之间的相互隔离和互无感知,降低了开发者实现新扩展点的难度,他们无需关注其他扩展点的细节,只要将精力集中在当前实现的功能需求即可。
Apache ShardingSphere 目前已提供数十个 SPI (Service Provider Interface)作为系统的扩展点,仍在不断增加中。
详情请参考:
https://shardingsphere.apache.org/document/current/cn/dev-manual/。
由于版本刚刚发布,文档比较潦草,未来会进一步完善。基于可插拔架构搭建的 Apache ShardingSphere 结构见下图:
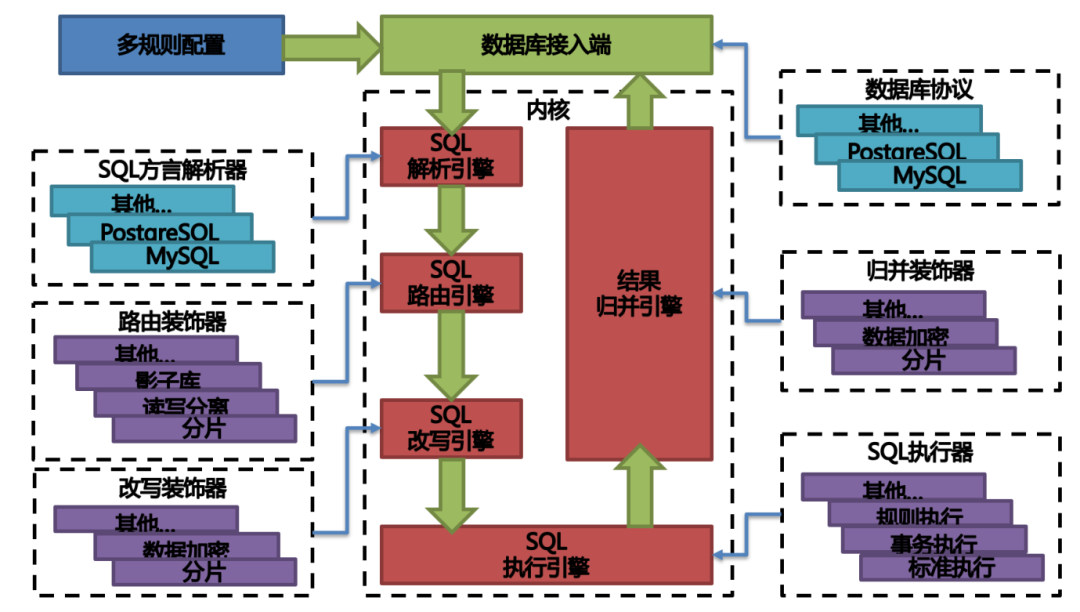
在本部分结束之际,解释一下标题中出自曹操所著四言乐府诗《观沧海》中名句:日月之行,若出其中。星汉灿烂,若出其里。这首诗是曹操在登碣石山观海时,所描述出的大海吞吐日月、包蕴万千的景象。
可插拔架构让 Apache ShardingSphere 的关注点从排他性转变为融合性。用户无需再考虑 MySQL 和 PostgreSQL 谁更优越,也无需关注分布式事务应该使用 XA 还是柔性事务的解决方案。这些技术方案,在 Apache ShardingSphere 生态圈中都占有一席之地,并可以共存与协作。希望 Apache ShardingSphere 在未来能够支持更多的数据库以及融入更多的功能,打造成为像大海一样可容纳一切的平台级生态体系,并构建属于自己的行业标准。
在 Apache ShardingSphere 开源的五年的发展历程中,SQL 解析引擎是不可或缺的基石,也是项目中最稳定的基础设施。在本次发布中,我们将它与主项目完全剥离,让它能够为开发者独立的提供 SQL 处理相关服务。
目前 Apache ShardingSphere 的 SQL 解析引擎提供了 MySQL、PostgreSQL、SQLServer、Oracle 和 SQL 92 这 5 种 SQL 方言支持,其中 MySQL 目前已基本具备 100% 的兼容能力, PostgreSQL 的兼容性也已相当可观。
SQL 解析引擎采用 ANTLR 作为语法解析器,它的优点是语法文件采用 BNF(巴科斯范式)风格完成描述声明,语法风格简单易读且易于维护,为开发者扩展其他数据库方言提供了便利条件。除了标准语法树的解析和生成,Apache ShardingSphere 将语法树访问器以 SPI 的方式向外提供扩展,并计划提供大量的内置访问器已满足对 SQL 操作的各种需求。Apache ShardingSphere 直接使用的 SQLStatement 解析结果,也是经由 SPI 的语法树访问器提供而来。
了解 Apache ShardingSphere 历史的人可能知道,当前的 SQL 解析引擎已是第三代。经过了前两代 SQL 解析引擎的摸索,第三代解析引擎继承了前代的稳定性。虽然采用 ANTLR 的代码生成的方式,降低了 SQL 解析引擎的性能,但却提升了可维护性和可扩展性,对于一个开放的社区来说,这种权衡是值得的。在Apache ShardingSphere 中,SQL 解析的性能并非是决定系统性能的瓶颈,它通过缓存将 SQL 解析的性能损耗降至最低。
不受百炼,难以成钢,是历经了五年三代的 SQL 解析引擎的真实写照。在承载 Apache ShardingSphere 的全部需求之后,它成功的迈出独立的一步。虽然与 JSqlParser 等老牌 SQL 解析引擎相比,它还略显稚嫩,但易于扩展和更完善的 SQL 方言支持,足以让其成为开源界中的另一选择。希望它能够随着社区的发展不断完善,成为数据库生态中不可或缺的利器。
一直以来,Apache ShardingSphere 的项目定位都是数据库中间件。数据库中间件通常是搭建在数据库之上的代理层,对已有的数据库进行增强。因此,大部分使用者都采用先部署数据库并创建数据库表结构,再通过 Apache ShardingSphere 配置数据库分片策略的使用流程。数据库与中间件之间是相互割裂的,数据库采用 SQL 进行操作,中间件则通过 YAML 的方式进行配置。若采用集群模式,通过 YAML 的配置则不能满足分布式的需求,用户还需要将配置存储至注册中心。SQL、YAML 和注册中心的多点输入,使中间件模式难于被习惯了 SQL 操作便捷性的 DBA 所接纳。
数据库通常使用 SQL 完成全部操作。为了让 Apache ShardingSphere 向分布式数据库方向全面转化,DistSQL 是重要的战略转折点之一。它提供了仅通过 SQL 即可完成对 Apache ShardingSphere 的全部操作能力。
当前版本的 DistSQL 还刚刚起步,仅包含了RDL 类型的语句。RDL 即 Rule Definition Language,是用于定义规则的语句,规则目前仅包括数据分片,未来会不断扩充读写分离、数据加密和影子表等规则。除了规则定义,RDL 还提供了资源定义,即管理能够被 Apache ShardingSphere 所使用的数据源。
RDL 语法使用下列语句创建资源:
CREATE datasources (
ds0=127.0.0.1:3306:demo_ds_0:root:pwd,
ds1=127.0.0.2:3306:demo_ds_1:root:pwd);使用下列语句创建规则:
CREATE shardingrules (
t_order=hash_mod(order_id, 4),
t_item=mod(item_id, 2));为了搭配与 RDL 一起使用,原有的允许用户通过自定义 Java 类或行表达式的分片算法的自由定制化模式,也在保留其基础的情况下增加了自动分片模式。自动分片模式提供了取模、哈希取模、范围、时间等各种维度的简化分片算法。示例中 的RDL语句描述了对 t_order 表采用哈希取模的算法分为4片,分片键是 order_id,以及对 t_order_item 表采用取模的算法分为 2 片,分片键是 item_id 的规则配置。
除了 RDL,未来会将更多类型的针对Apache ShardingSphere 的分布式相关操作加入到 DistSQL 中,如:Hint、SCTL 等。
DistSQL 是 Apache ShardingSphere 迈向分布式数据库的准入门槛。正如标题所言,万物之始,大道至简,衍化至繁。对于数据库来说,命令行 + SQL 是它的根源。由 SQL 衍化而来的各项分布式功能,才是分布式数据库被开发者和 DBA 所接受的路径。DistSQL 打通了 Apache ShardingSphere 从数据库中间件向分布式数据库迈进的脉络,为未来承载更多的数据库内核层和存储层的功能提供了有效而统一的入口。
时代一直在前行,变革从来不是一蹴而就。期望当未来的Apache ShardingSphere生态圈深入人心之后,同社区一路走过来的朋友们,能够在回溯变革的萌芽时,能依稀回忆起当前版本。
https://shardingsphere.apache.org






