




CVPR2026: Design Your Ad: Personalized Advertising Image and Text Generation with
Unified Autoregressive Models
论文链接:https://arxiv.org/abs/2605.12138
代码链接:https://github.com/JD-GenX/Uni-AdGen
摘要:在存量竞争与存量增长并行的电商时代,广告创意不仅要“精美”,更要“精准”。传统的广告设计流程往往面临人力成本高、响应慢的挑战,而现有的 AI 生成方案也大多受限于文案与图像的“割裂生成”——即 LLM 生成文案、扩散模型生成图像,这不仅导致系统架构臃肿,更难以实现图文语义的深度契合及真正的“千人千面”。京东零售广告创意团队近日提出了Uni-AdGen,这是首个将个性化广告图文生成统一在单一自回归模型下的技术框架。该模型摒弃了模态间的壁垒,通过创新的由粗到精(Coarse-to-Fine)偏好建模与前景感知控制,在百万级数据集 PAd1M 上证明了其卓越性能。Uni-AdGen 不仅能一键生成高美感的广告视觉,更能敏锐捕捉不同用户的视觉审美与文案偏好,为电商营销的智能化转型提供了全新的范式。
一、背景及现状
在存量竞争激烈的电商时代,高质量的广告创意(图像与文案的组合)是提升点击率的核心。然而,面对数以亿计的商品和差异化的用户群体,传统的广告生产模式正面临三大核心挑战:
- 人力成本与响应速度的冲突:传统的广告创意高度依赖专业设计师和文案策划,不仅制作成本高昂,且面对瞬息万变的市场趋势,人工设计的响应周期过长,难以实现海量 SKU 的即时覆盖。
- 模态间的语义“割裂”:如图1(a)所示,当前的自动生成方案大多采用“分治法”——利用大语言模型(LLM)生成文案,再通过扩散模型(Diffusion Model)生成图像背景。这种架构导致图文生成过程相互独立,缺乏深层语义的一致性,系统维护成本高且推理延迟大。
- 个性化建模中的“噪声”困境:现有的创意生成多以点击率作为唯一反馈。然而,CTR 往往代表了大众的“平均口味”,忽略了用户个体的独特审美。如图1(b)所示,想要建模用户的个性化偏好,还需克服用户行为中的样本和模态噪声:
- 样本层面的噪声(Sample-level Noise):用户的历史轨迹中往往包含大量与当前目标商品毫不相关的干扰项。当模型试图为沐浴液设计广告时,历史行为中的“茶壶”或“桌子”等无关样本,其视觉风格和文案特征与目标商品严重不匹配。
- 模态层面的噪声(Modality-level Noise):用户的点击行为往往是“图文耦合”的结果。例如,一个用户可能因为被精美的背景图吸引而点击,但对文案内容并不感冒。然而,系统收到的信号仅为一个简单的“点击”,无法自动区分用户到底是对哪种模态产生了偏好。
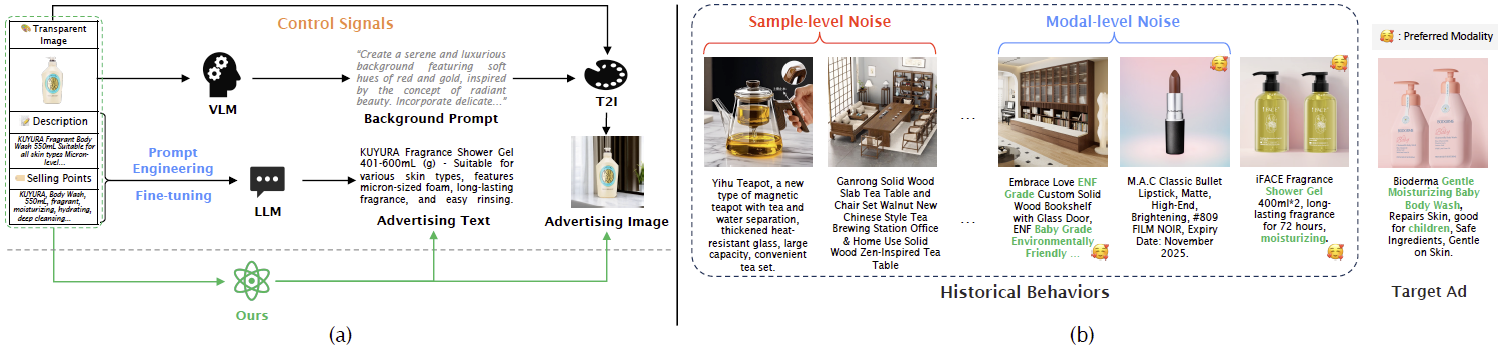
图1:现有方法和用户历史行为中的问题
二、整体方案介绍
在明确了背景挑战后,Uni-AdGen 将视觉与文本深度统一的生成范式。本节将从任务定义与架构概览两个核心维度,揭秘该方案如何实现精准的创意生成。
1. 任务定义:从用户足迹到创意的精准触达
Uni-AdGen 的核心目标是根据用户的历史偏好与目标商品信息,量身定制最能触达其痛点的广告图文。
- 输入端(多源异构信息):
- 历史行为序列:记录用户过去L次点击的图文对,这是捕捉用户审美与文案偏好的“线索库”。
- 目标商品信息P:包括商家提供的商品透底图、商品描述和商品卖点池。
- 输出端(协同预测): 生成预测的图文组合(I^pred,T^pred),其核心逻辑是最大化生成结果与用户真实点击意向(I^GT,T^GT)之间的相似度。
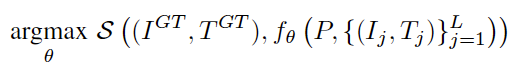
2. 架构概览:两阶段进化路径
为了应对广告生成中的一致性与个性化噪声问题,Uni-AdGen 的架构设计分为两个循序渐进的模块:
- 基础阶段:通用广告生成(General Ad Generation) 如图2(a)所示,我们基于自回归框架(Autoregressive Framework)构建了 Uni-AdGen 基础模型。通过引入专门的控制信号,模型能够生成符合商品特性的图像和标题。
- 进阶阶段:个性化偏好理解(Personalized Ad Generation) 如图2(b)所示,在基础模型之上进一步扩展了由粗到精的偏好理解模块(Coarse-to-fine preference understanding module)。该模块从用户带有噪声的多模态历史行为中提取出精准的偏好信号,从而在生成阶段实现“千人千面”的精准定制。
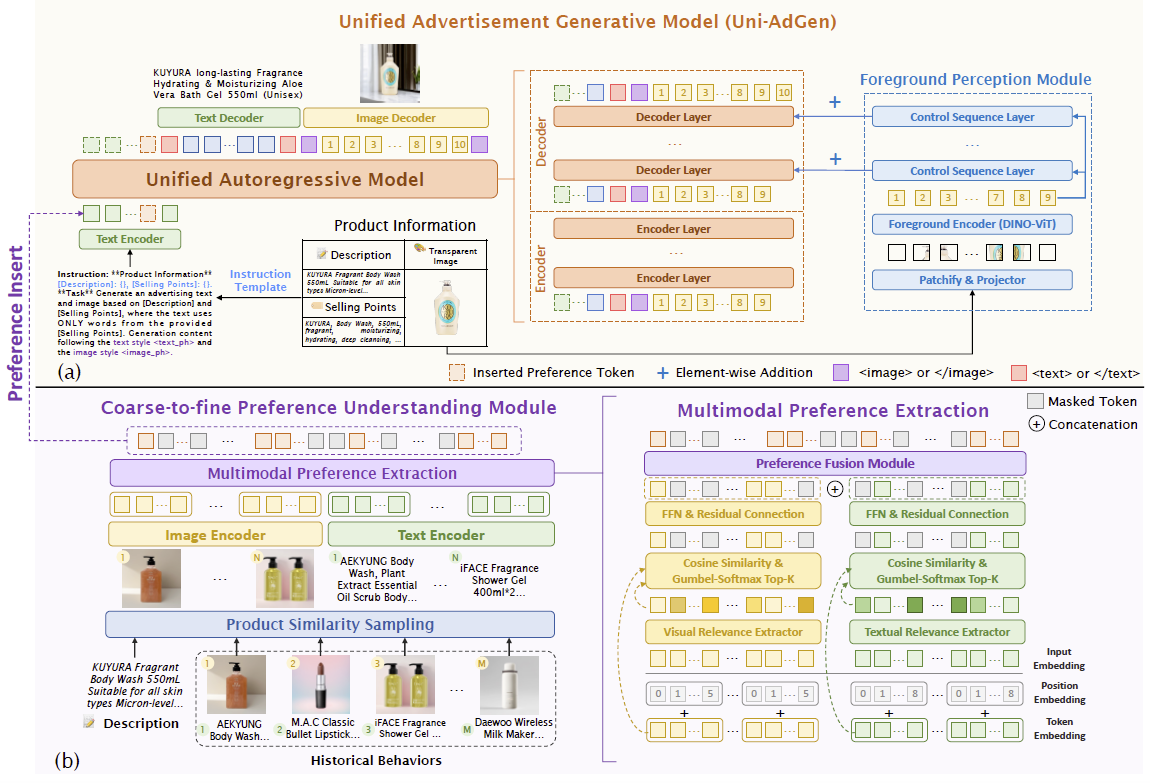
图2:整体框架图
三、广告图文一体化生成
Uni-AdGen采用自回归视觉-语言架构进行图文广告生成。该模型使用结构化指令,包括任务定义、产品描述和卖点,以指导生成。我们使用特殊标记<text>和</text>来标记文本生成范围,随后使用<image>触发图像生成,并用</image>标记其完成。模型输出连接到独立的图像和文本解码器,将预测的标记解码为各自的模态。图像解码器采用VQ-GAN架构,通过代码簿查找将离散标记映射到像素空间。得益于多模态范式,Uni-AdGen实现了端到端的广告生成,而无需现有方法所需的多个独立模型。
Uni-AdGen的训练遵循下一个标记预测范式。给定包含N个标记的指令序列s = {s1, s2, …, sN},模型自回归地预测包含M个标记的文本序列t = {t1, t2, …, tM}和包含K个标记的图像序列g = {g1, g2, …, gK}。我们联合优化广告文本和图像生成任务进行训练。文本生成损失通过最大化给定输入序列和先前生成的文本标记的文本标记的可能性来实现:
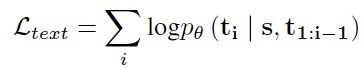
图像生成损失通过最大化在输入序列、文本标记和先前生成的图像标记条件下的图像标记的可能性来实现:
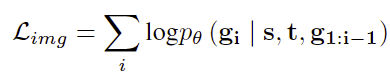
总体损失可以定义为:
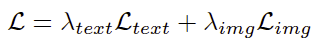
由于普通的自回归模型由于缺乏有效的控制,难以生成与商品一致的广告图像和标题。为了解决这个问题,我们为Uni-AdGen配备了专门为图像和文本设计的控制方法。对于图像生成,我们设计了一个前景感知模块来处理商品的透底图像,如图2(a)所示。透底图像通过patchify和投影层被离散化为小块,然后由基于DINOv2的前景编码器编码为视觉嵌入。这些嵌入进一步通过简单的多层感知器(MLP)对齐到自回归模型的潜在空间,称为控制序列层。最后,视觉嵌入通过逐元素加法注入到自回归解码器的每4层中:
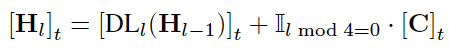
其中,[H_l]_t表示第l个解码器层中第t个位置的输入标记,DL_l代表第l个解码器层。C是来自前景感知模块的对齐控制信号。指示函数I_{l \mod 4=0}在l能被4整除时等于1,否则为0。
对于广告文本生成,我们采用指令微调来增强模型对产品信息的遵循性。具体来说,我们设计了多样化的指令模板,自动将产品描述和卖点转换为生成指令,其中一个示例格式为:“**产品信息** [描述]:{},[卖点]:{}。**任务** 基于[描述]和[卖点]生成广告文本和图像,其中文本仅使用提供的[卖点]中的词语。”然后,我们利用大型语言模型(LLM)清理训练数据,移除那些无法从给定卖点推断出真实广告文本的噪声样本。通过指令微调,这种方法使模型能够学习一致的生成策略。
四、个性化广告生成
基于通用广告图文生成模型,我们进一步设计了一个由粗到细的偏好理解模块,以利用历史行为进行个性化广告生成。如图2(b)所示,该模块首先通过产品相似性从大量的M个历史行为(其中M ≫ N)中粗略选择前N个行为,以减少样本级噪声。具体来说,我们测量历史产品文本与目标产品描述之间的语义相似性,然后通过重要性采样从历史行为中构建一个候选集,采样权重为p:
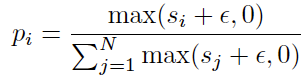
其中s_i表示第i个产品的语义相似性, \epsilon设为1e-6以防止除以0。由于语义相似的商品通常共享广告风格和文本模式,通过商品相似性采样获得的候选集可以有效减少样本级噪声。同时,我们经验性地观察到某些语义相似性较低的历史商品仍然提供有用的视觉或文本参考,例如图1中的书架和口红。通过我们的采样策略,候选集以概率方式纳入这些项目,从而增加参考的多样性。
在粗理解之后,尽管通过商品相似性采样可以获得高度相关的历史行为候选集,但由于模态级噪声,我们仍然无法评估用户在特定模态上的兴趣。为了解决模态级噪声问题,我们引入了多模态偏好提取。如图2(b)所示,首先将采样得到的N个历史图文对通过图像和文本编码器编码为token序列。这些token随后被用于多模态偏好提取,其中两个独立的Transformer编码器作为视觉和文本标记的相关性提取器。每个提取器通过注意力机制衡量标记的重要性,并通过计算输入和输出嵌入之间的余弦相似性生成标记级别的掩码,接着使用可微的Gumbel-Softmax G()和Top-K选择TK()保留相关内容,同时抑制模态级噪声:
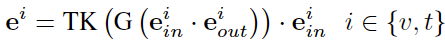
其中, e_i^{in}和e_i^{out})分别表示相关性提取器的输入和输出标记,v和t分别代表视觉和文本模态。生成的token e_i进一步处理以获得融合后的图像token e_v^{fused}和融合后的文本token e_t^{fused}:
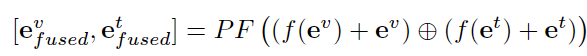
其中,f()表示具有残差连接的前馈层(FFN),PF()表示用于在连接操作后融合多模态token的另一个Transformer编码器。最后,我们通过在指令末尾添加样式约束:“生成内容参考文本风格<text_ph>和图像风格<image_ph>”,其中占位符<text_ph>和<image_ph>表示插入的位置。
五、实验结果
(1)数据集
为了支撑个性化广告生成的研究,我们基于真实的业务场景,通过系统化的多阶段流水线构建了大规模、多样化的个性化广告图文数据集PAd1M,并针对行业痛点提出了全新的评估指标。
如图3所示,相较于现有的公开数据集,PAd1M 在规模和维度上实现了量级跨越:
- 超大规模 (Large-Scale):涵盖114.5 万名活跃用户及1,892 万次点击行为,平均每位用户包含超过 16 条多模态历史行为记录,远超 SER30K 等传统数据集。
- 全类目覆盖 (Comprehensive):数据横跨 40 多个核心商品类目,不仅包含精美的广告图文,还整合了由Grounded SAM提取的商品前景、卖家提供的描述及卖点,支持更细粒度的建模。
- 领域创新 (Field Innovation):不同于以往关注群体点击率(CTR)的指标,PAd1M 首次显式建立了个体用户与特定创意之间的偏好链接,实现了从“群体画像”到“个人偏好”的精准跨越。
(2)评价指标
在评价生成图像和目标图像的相似度时,传统的图像指标(如 CLIP 或 DINO)往往过度关注商品主体,而忽略了广告中至关重要的背景信息。
- 文本评估:沿用 BLEU 和 ROUGE 指标,通过字符级分词衡量生成文案与用户真实点击文案的重合度。
- 创新指标 PBS (Product Background Similarity): 针对图像背景,我们提出了基于 MoCov3 改进的产品背景相似度 (PBS)指标。通过在 68 万对“同商品、异背景”的图像对上进行对比学习训练,PBS 能够敏锐捕捉背景的细微差异。
如图3(d)所示,在验证测试中,PBS 对背景变化的敏感度得分差距达0.421,而传统的 CLIP 和 DINO 指标均低于 0.05,证明了 PBS 在评估个性化背景适配性上的卓越性能。
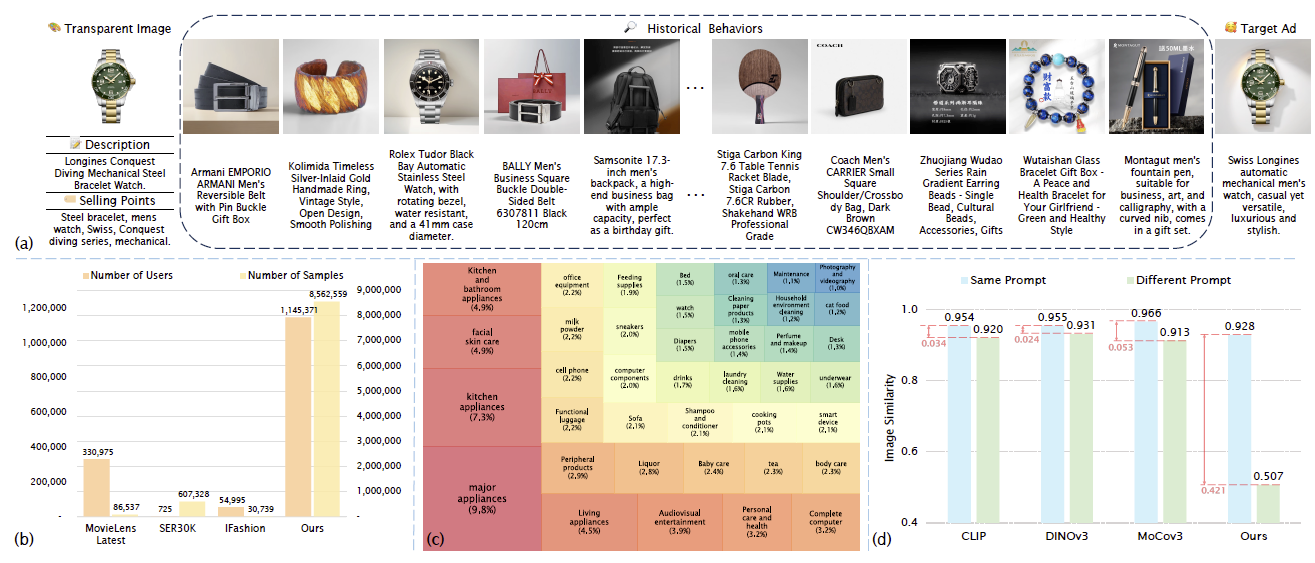
图3:PAd1M数据集以及PBS指标评估
(3)通用广告生成性能
如表1所示,Uni-AdGen 在通用图文广告生成任务上均展现出卓越性能。在视觉方面,本方法在 ImageReward 指标上取得最优表现,并在 PickScore 和人工评估中位列第二,成功在视觉美学与广告实用性之间实现了最佳平衡,克服了竞品在美学与可用性上顾此失彼的局限。在文本生成方面,本方法在人工评估中排名第二,在 m-BLEU 和 m-ROUGE 等指标上表现与业界先进基线相当。此外,通过对比单模态变体模型,验证了多模态训练的有效性。
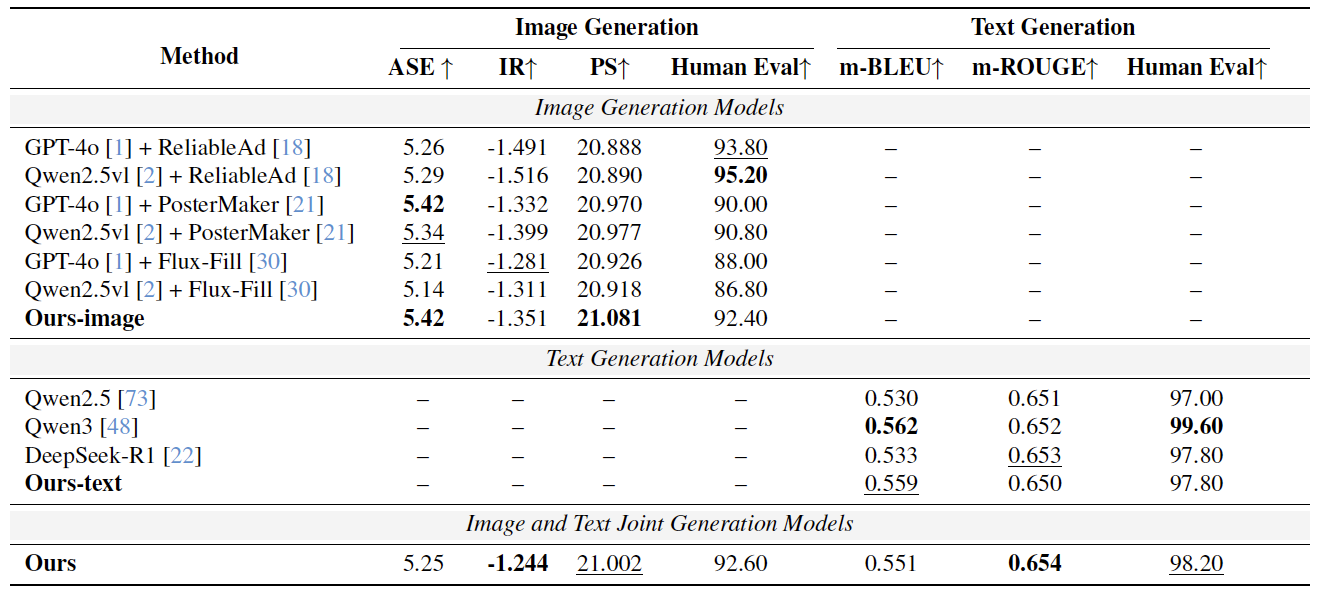
表1:通用广告图文生成效果评估
(4)个性化广告生成性能
在个性化生成任务中,Uni-AdGen 在图像与文本两方面均显著优于基线模型。可视化结果显示,Flux-Kontext 因无法理解用户偏好且易受样本噪声影响,导致生成结果偏离真实;Pigeon 受限于单模态设计,偏好建模不准确;而 Qwen3 与 DeepSeek-R1 生成的文本对真实点击中的卖点覆盖不足。相比之下,Uni-AdGen 通过其粗到细的偏好理解模块,联合建模用户图文历史兴趣,使生成的广告更贴合实际点击。消融实验进一步验证了历史数据、产品相似性采样(PSS)及多模态偏好提取对性能提升的关键作用。
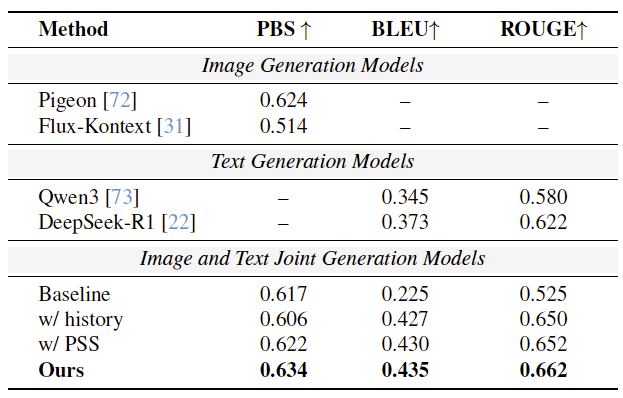
表2:个性化广告图文生成效果评估
Note:
欢迎大家交流与探讨,如有任何问题或建议,请随时联系:fengwei25@jd.com。
京东广告创意部门诚邀AIGC/大模型领域人才加入,共同推动技术的进步和创新。欢迎大家踊跃投递简历,期待与您在京东相遇!






