导语
手搓一个简单的数据库分表组件,KISS原则,简单够用。困于其他组件之局限而自起,无它,够用足矣。
背景
在大型系统中,流量大,数据量大,很容易出现大表,一般来说,大表有以下几方面特征:
数据量维度:通常认为单表数据量超过1000万行或10GB以上可以视为大表。
性能维度:当表的查询、插入、更新、删除操作开始出现明显性能下降。
维护维度:当对表进行DDL操作(如添加索引、修改字段)需要很长时间(如超过1小时)。
业务维度:根据具体业务场景,影响核心业务流程的表即使数据量不大也可能被视为大表。
以库存流水表为例,一天的流水量是3400万行,大小为31GB。
大表会伴随着产生读写性能下降、服务耗时长、DDL、DML时间长、备份恢复难度大、统计信息不准确等弊端,需要进行大表治理优化。
治理方案
大表的治理优化方案
一般有几个思路:
分库分表:按业务维度(仓号、SKU、主键ID等)水平拆分。
表分区:按时间、哈希或范围分区,提高查询效率。
冷热分离:冷数据归档结转,超过一定时间的热数据则转为冷数据存储。
索引优化:删除冗余和低效索引,减少索引维护成本,提升单表读写性能。
读写分离:主库写操作,从库读操作,减轻主库压力。
在本系统的治理中,除了表分区方式暂未使用,其他优化策略均有使用,尤其是在分库分表方面,通过水平拆分数据量降维最直接高效,也是本文阐述的重点,其他策略不重点赘述。
分表组件选择
分库方面,之前已接入分库,按仓号分库,但流水表尚未分表,单表的流水量依然很大,其中一个分库下20天的单表存量数据行在四五千万行左右。
本次是在分库的基础上进行分表。在分库分表的组件选择上,业界常用的分库分表组件有Sharding-JDBC、Mycat、Cobar、TDDL、Atlas等,他们的优劣势各不相同,但这些分库分表插件在SQL语法支持上都存在自己的局限性。
例如:
Sharding-JDBC
SQL语法限制:
不支持复杂的SQL语法,如OR、UNION和UNION ALL等操作
不支持HAVING子句
不支持子查询的完整支持
不支持DISTINCT聚合操作
不支持SELECT LAST_INSERT_ID()语句
不支持CASE WHEN语句
不支持VALUES后有多行数据的INSERT语句
不支持dual虚拟表
Mycat
SQL语法限制:
不支持跨库多表关联查询和子查询
不支持CREATE TABLE LIKE xxx和CREATE TABLE SELECT xxx等语句
不支持SELECT FOR UPDATE、SELECT LOCK IN SHARE MODE等语句
不支持跨分片的UPDATE/DELETE操作
不支持多表UPDATE或UPDATE分片键
不支持跨分片的ORDER BY LIMIT操作
Cobar
SQL语法限制:
不支持跨库情况下的JOIN、分页、排序、子查询操作
不支持SAVEPOINT操作
SET语句执行会被忽略(事务和字符集设置除外)
分库情况下INSERT语句必须包含拆分字段列名
分库情况下UPDATE语句不能更新拆分字段的值
仅支持部分SQL数据节点
TDDL
SQL语法限制:
不支持JOIN、多表查询等语法
不支持跨库JOIN操作
不支持存储过程、函数等复杂SQL操作
Atlas
SQL语法限制:
社区维护较久,功能相对有限
不支持跨库JOIN等复杂操作
这些组件在SQL语法支持上的局限性主要源于分库分表场景下对SQL解析和路由的复杂性,以及各组件架构设计的差异。
正因为这些SQL语法的局限性,在之前分库时,部门没再继续使用Sharding-jdbc作为分库分表的插件,而是部门自研了一个适合自己的分库插件。关于自研这件事,造轮子目的很直接简单,并不是为了证明什么,仅仅是为了适配自己的场景,组件设计和实现也并不复杂,远远不如行业里的哪些插件强大,根据KISS原则,够用+1而已。
在分表时,依然选择了部门自研这个条路,原因同样简单:无它,够用+1而已。
组件设计
基于 MyBatis 插件机制实现的分表拦截器,采用 策略模式 + 责任链模式 的架构设计。

┌─────────────────────────────────────────────────────────────┐
│ MyBatis 插件链 │
├─────────────────────┬───────────────────────────────────────┤
│ SQLMarkingPlugin │ SQLBasedDatabaseProtectorPlugin │
├─────────────────────┼───────────────────────────────────────┤
│ DataSourceRouting │ TableShardingInterceptor │
│ Interceptor │ (分表拦截器) │
└─────────────────────┴───────────────────────────────────────┘
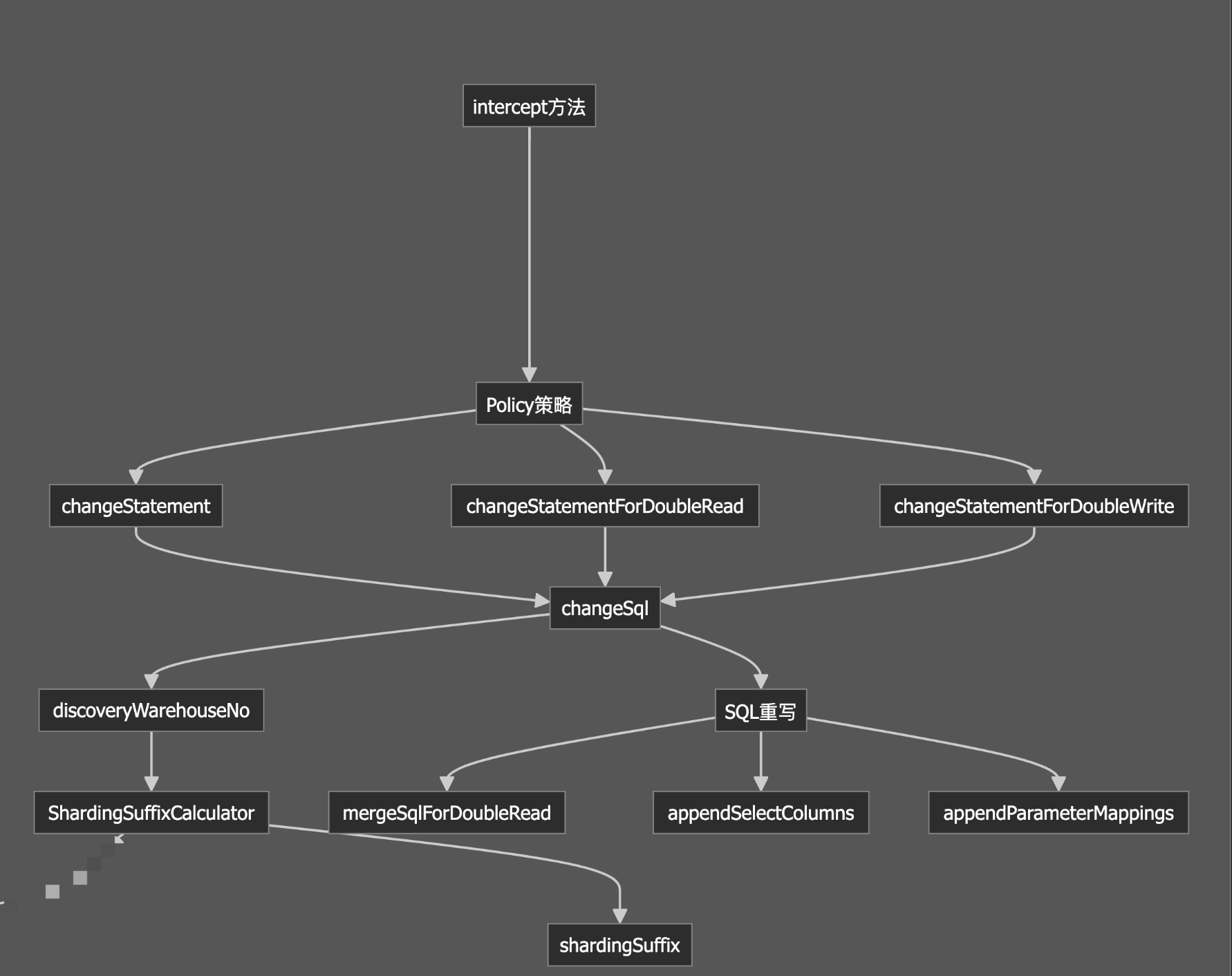
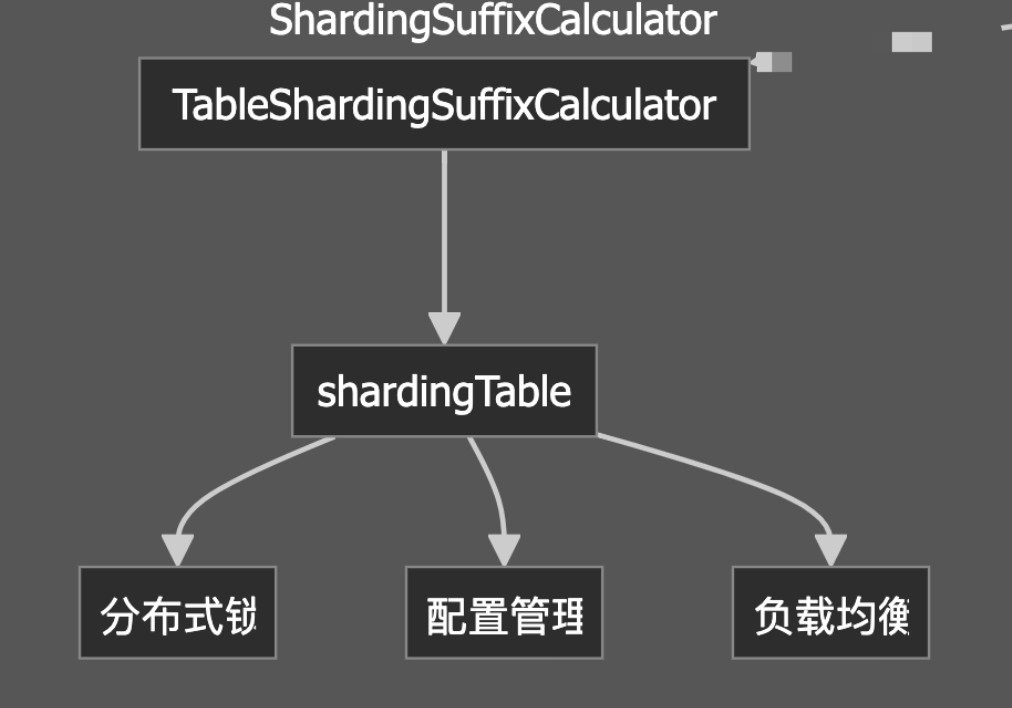
模块划分
拦截处理模块:intercept() 方法,负责拦截 SQL 执行。
策略模块:Policy 枚举,定义不同的读写策略。
SQL处理模块:负责 SQL 的解析、修改和重写。
路由计算模块:与 ShardingSuffixCalculator 交互,计算分表后缀。
参数处理模块:处理 SQL 参数映射。
组件研发
分表策略
分表规则:
- 基于仓库编号(warehouseNo)进行分表
- 支持多种分表策略:单写单读、单写双读、双写单读、双写双读
- 分表数量可配置,如
st_stock_stream:128表示分为128张表
分表后缀计算:
// 分表后缀计算流程
1. 从SQL参数中提取 warehouseNo
2. 查询配置表,看是否已有分配的分表
3. 如果有,直接使用
4. 如果没有,通过负载均衡算法选择一个分表
5. 使用分布式锁确保分配的唯一性
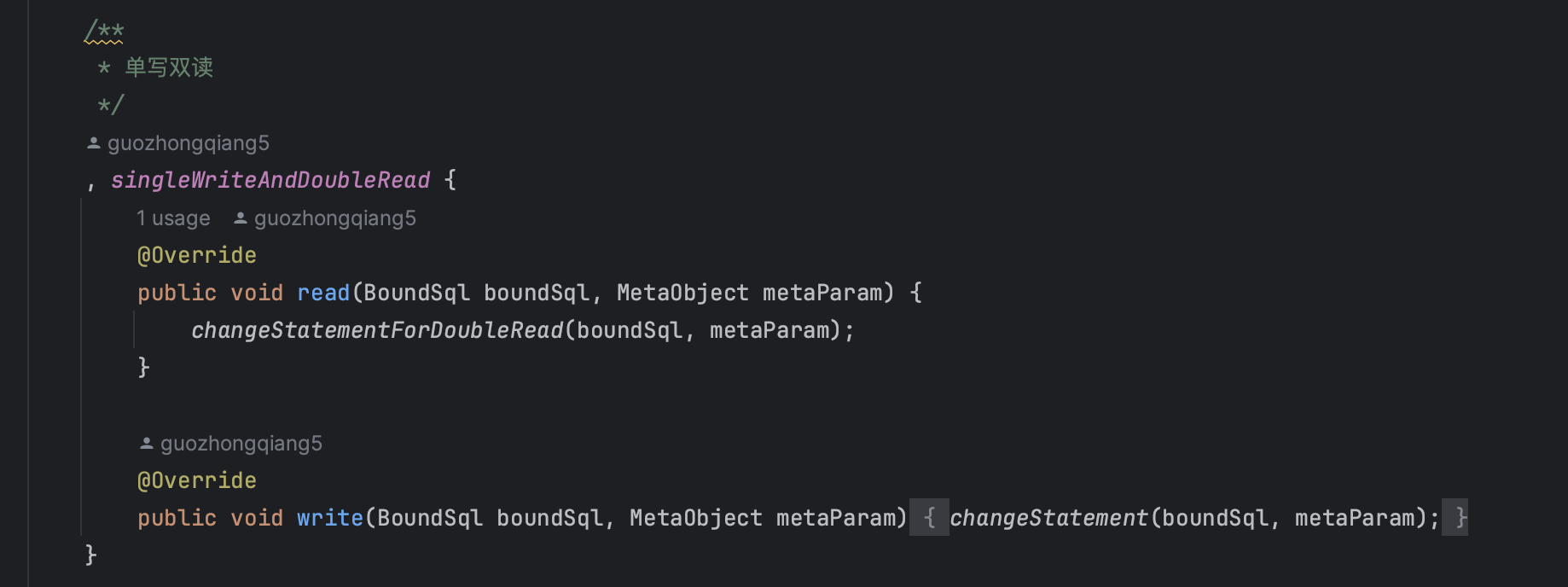
读写策略
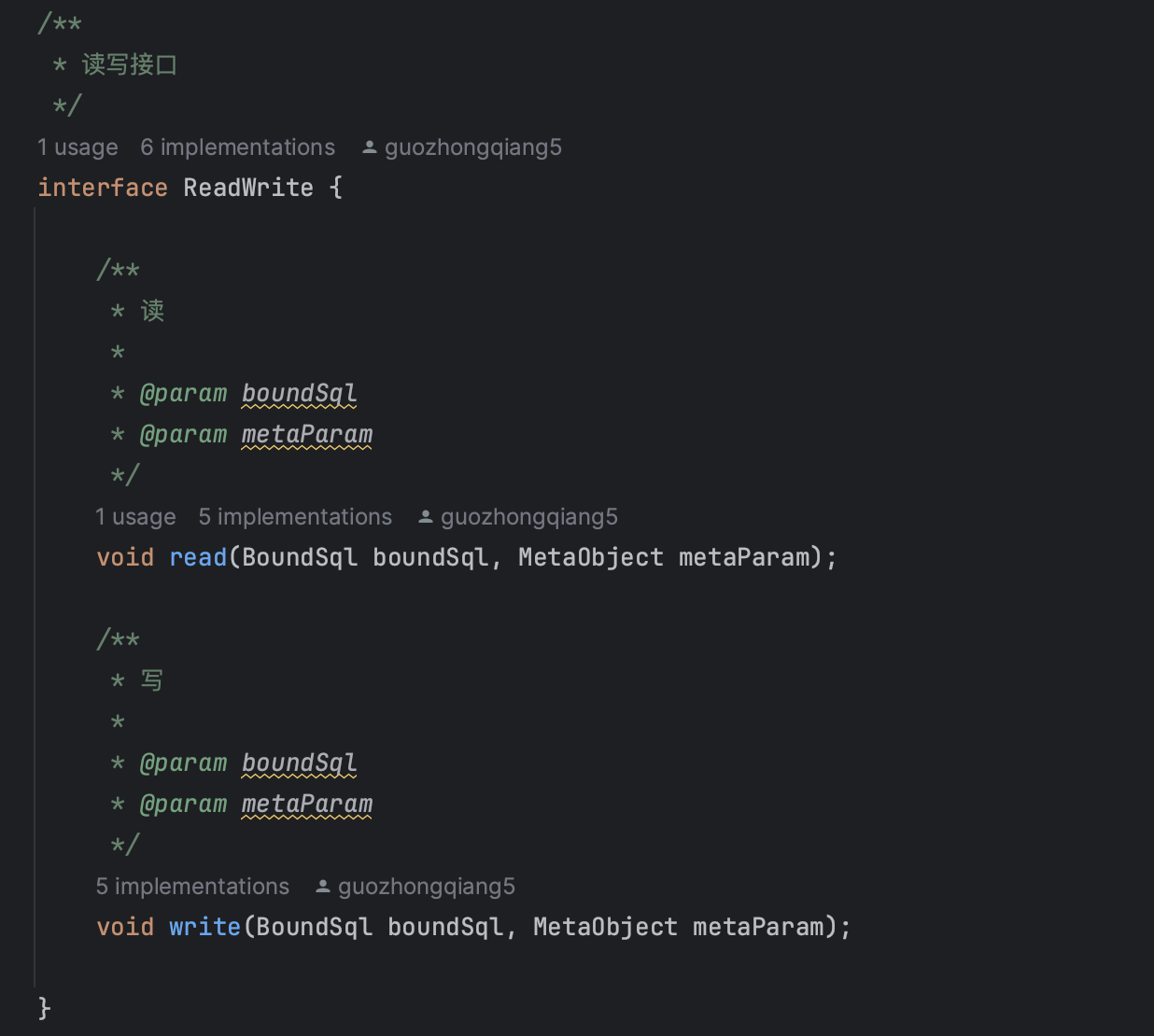

四种策略模式:
- doubleWriteAndReadOld:双写读旧表
- 写操作:同时写入旧表和新表
- 读操作:只读旧表
- doubleWriteAndReadNew:双写读新表
- 写操作:同时写入旧表和新表
- 读操作:只读新表(分表)
- singleWriteAndReadOld:单写读旧表
- 写操作:只写入新表(分表)
- 读操作:只读旧表
- singleWriteAndReadNew:单写读新表
- 写操作:只写入新表(分表)
- 读操作:只读新表(分表)
- singleWriteAndDoubleRead:单写双读
- 写操作:只写入新表(分表)
- 读操作:同时读旧表和新表,结果合并
SQL处理机制
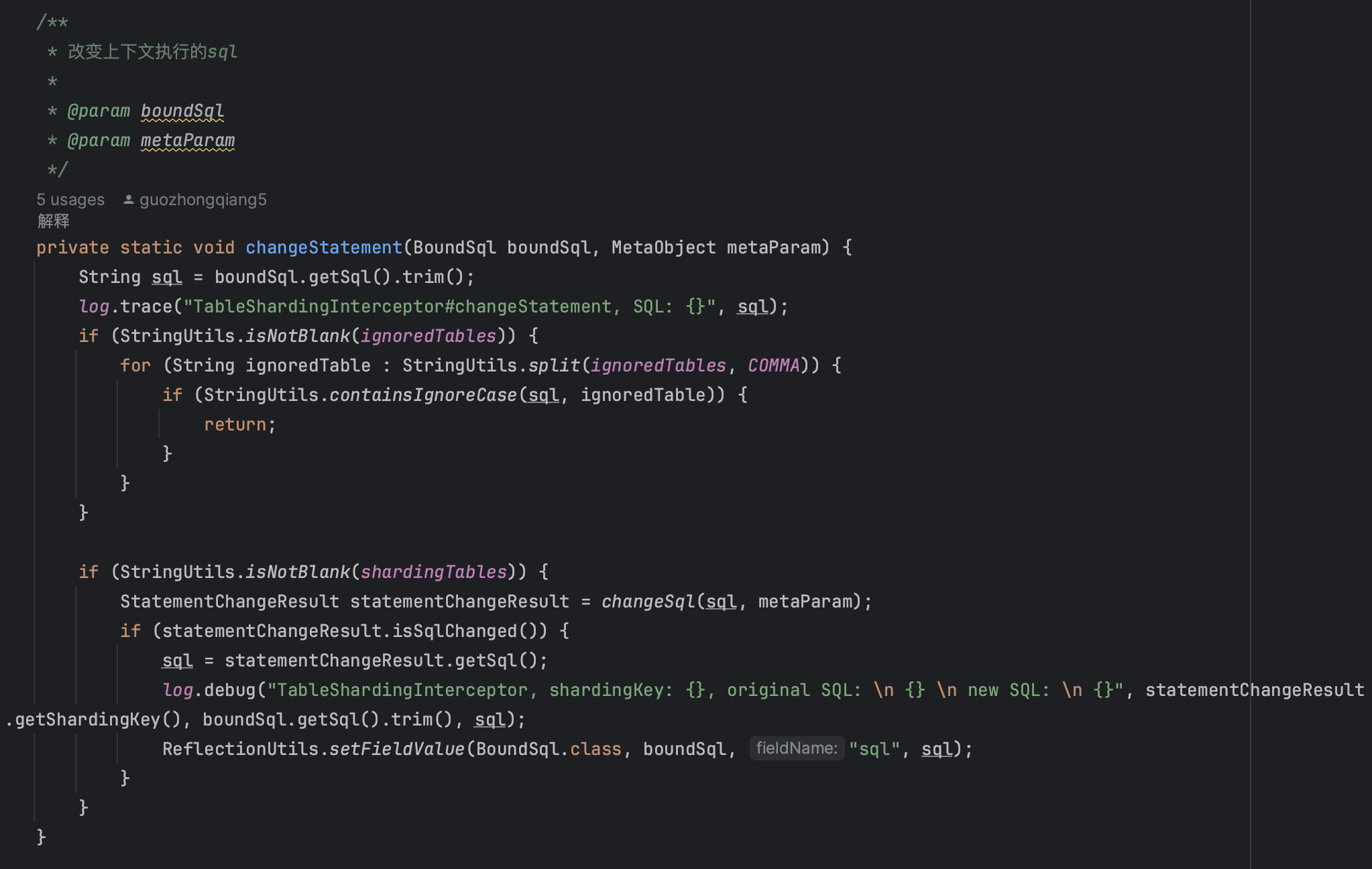
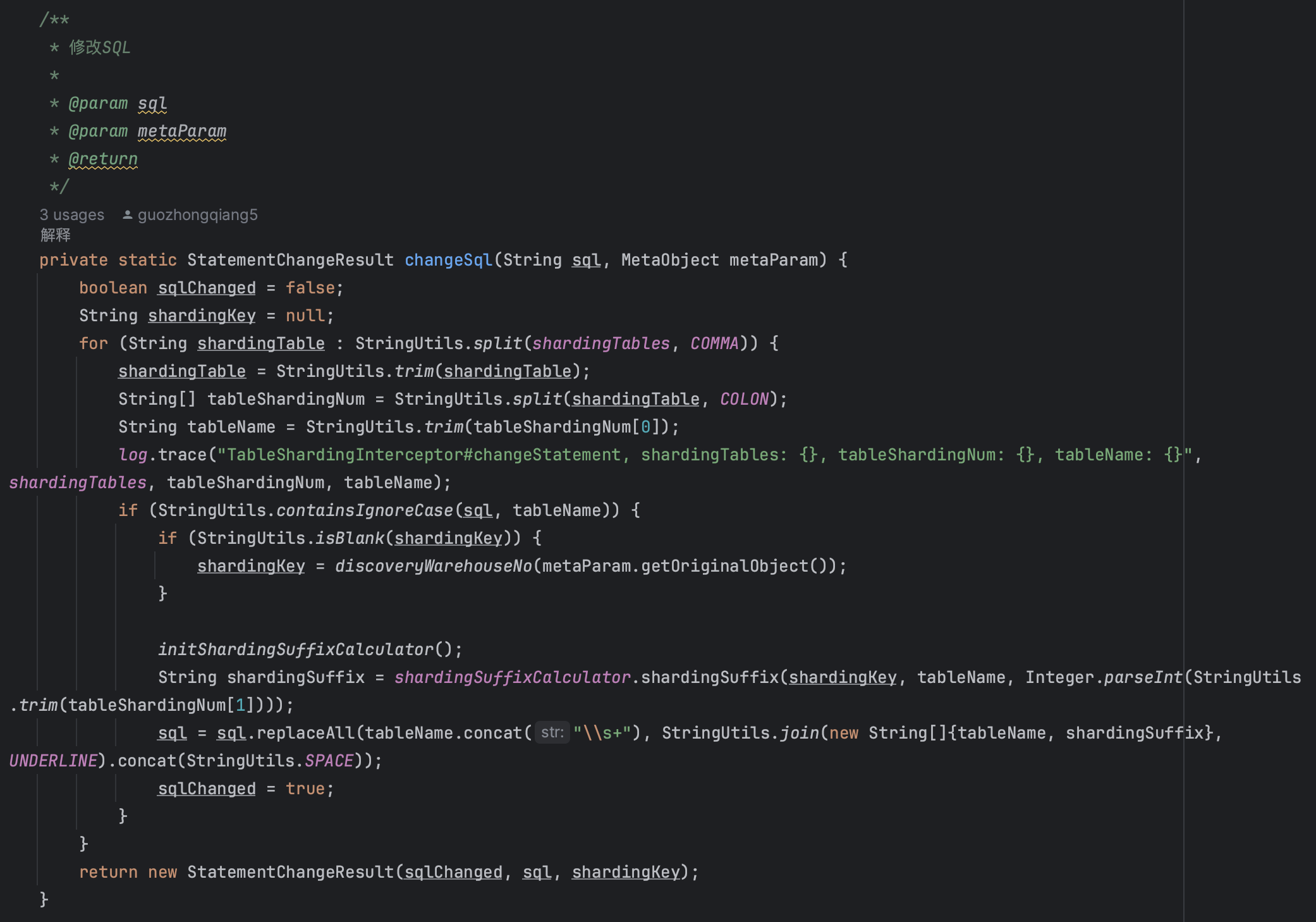
SQL解析与重写:
- 识别SQL中的表名
- 判断是否需要分表处理
- 提取分表键(warehouseNo)
- 计算分表后缀
- 重写SQL,替换表名
- 处理参数映射
特殊SQL处理:
- COUNT查询:
SELECT COUNT(*) FROM table→SELECT SUM(countNumForSharding) FROM (SELECT COUNT(*) AS countNumForSharding FROM table_0 UNION ALL ...) - SUM查询:
SELECT SUM(column) FROM table→SELECT SUM(sumNumForSharding) FROM (SELECT SUM(column) AS sumNumForSharding FROM table_0 UNION ALL ...) - ORDER BY/LIMIT:在双读模式下需要特殊处理
双写的处理
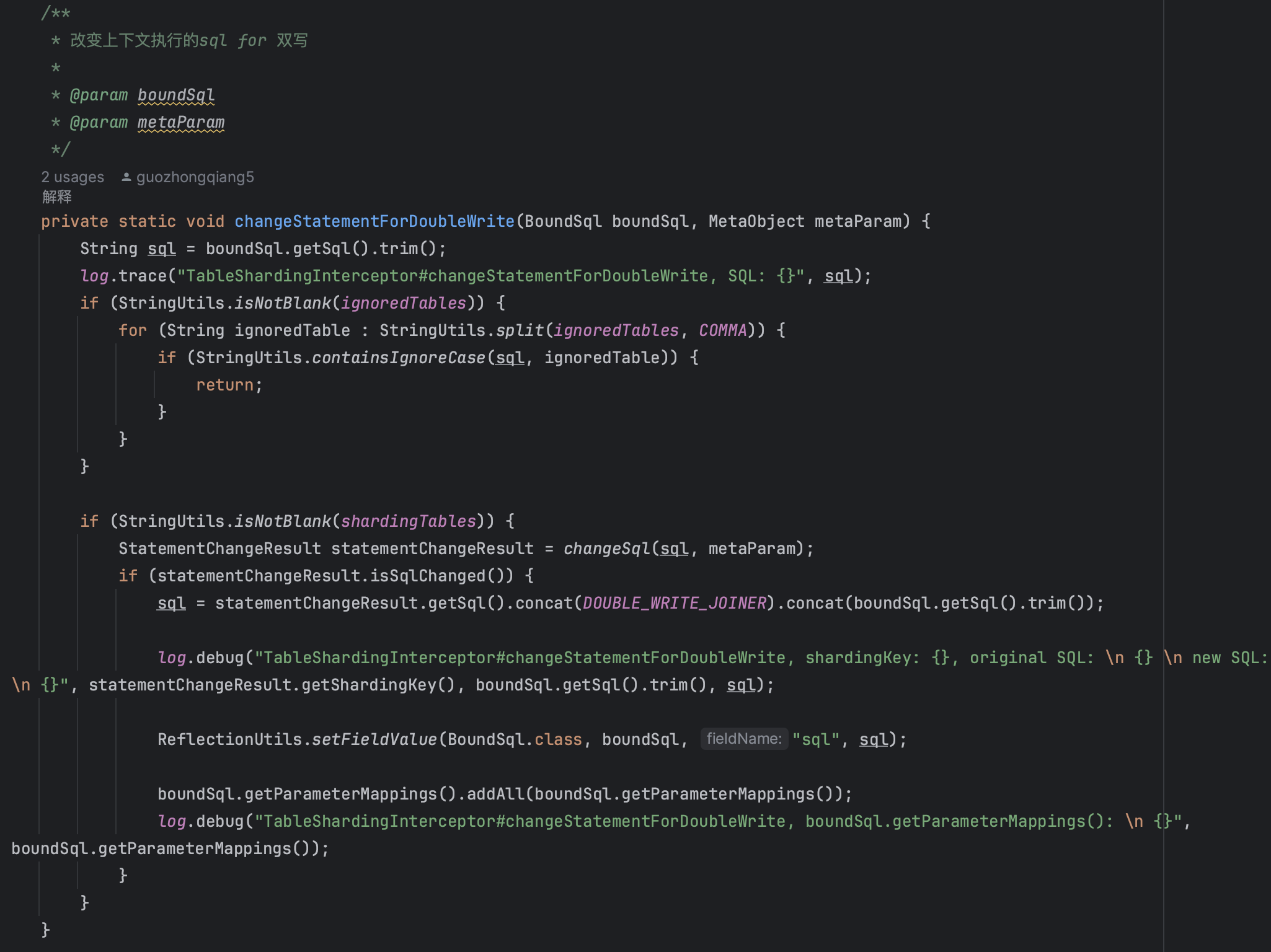
核心功能
该方法的核心功能是:将单条写入 SQL 转换为双写 SQL,即同时写入原始表和分表。
实现逻辑详解
1. 前置检查
String sql= boundSql.getSql().trim();
log.trace("TableShardingInterceptor#changeStatementForDoubleWrite, SQL: {}", sql);
// 检查是否在忽略列表中if (StringUtils.isNotBlank(ignoredTables)) {
for (String ignoredTable : StringUtils.split(ignoredTables, COMMA)) {
if (StringUtils.containsIgnoreCase(sql, ignoredTable)) {
return; // 忽略配置的表,不进行双写
}
}
}
逻辑说明:
- 首先获取原始 SQL 并记录日志
- 检查当前 SQL 涉及的表是否在忽略列表中
- 如果是忽略的表,则直接返回,不进行双写处理
2. 分表处理
if (StringUtils.isNotBlank(shardingTables)) {
StatementChangeResultstatementChangeResult= changeSql(sql, metaParam);
if (statementChangeResult.isSqlChanged()) {
// 构建双写 SQL
sql = statementChangeResult.getSql().concat(DOUBLE_WRITE_JOINER).concat(boundSql.getSql().trim());
// 更新 BoundSql 中的 SQL
ReflectionUtils.setFieldValue(BoundSql.class, boundSql, "sql", sql);
// 复制参数映射
boundSql.getParameterMappings().addAll(boundSql.getParameterMappings());
}
}
逻辑说明:
- 检查是否配置了分表
- 调用
changeSql方法处理 SQL,获取分表后的 SQL - 如果 SQL 发生变化(即需要分表),则构建双写 SQL
- 使用
DOUBLE_WRITE_JOINER(;)连接分表 SQL 和原始 SQL - 更新
BoundSql对象中的 SQL - 复制参数映射,确保双写 SQL 的参数正确
3. 双写 SQL 构建示例
原始 SQL:
INSERT INTO st_stock_stream (id, warehouse_no, sku, quantity) VALUES (?, ?, ?, ?)
双写 SQL:
INSERT INTO st_stock_stream_5 (id, warehouse_no, sku, quantity) VALUES (?, ?, ?, ?) ; INSERT INTO st_stock_stream (id, warehouse_no, sku, quantity) VALUES (?, ?, ?, ?)
使用场景
1. 数据迁移场景
在从单表架构向分表架构迁移的过程中,使用双写策略可以确保:
- 新数据同时写入旧表和新表
- 保证迁移期间的数据一致性
- 支持平滑迁移,可随时回滚
2. 策略配置
双写策略通过 policy 配置项控制:
doubleWriteAndReadOld:双写读旧表doubleWriteAndReadNew:双写读新表
关键点
1. SQL 连接符
public static final String DOUBLE_WRITE_JOINER=" ; ";
使用分号作为 SQL 语句分隔符,这是 SQL 支持的多语句执行格式。
2. 参数映射处理
boundSql.getParameterMappings().addAll(boundSql.getParameterMappings());
由于双写 SQL 包含两套相同的参数,需要将参数映射列表复制一份,确保参数正确绑定。
3. 反射更新
ReflectionUtils.setFieldValue(BoundSql.class, boundSql, "sql", sql);
使用反射机制更新 BoundSql 对象中的 SQL,这是 MyBatis 插件开发中的常用技巧。
执行流程图
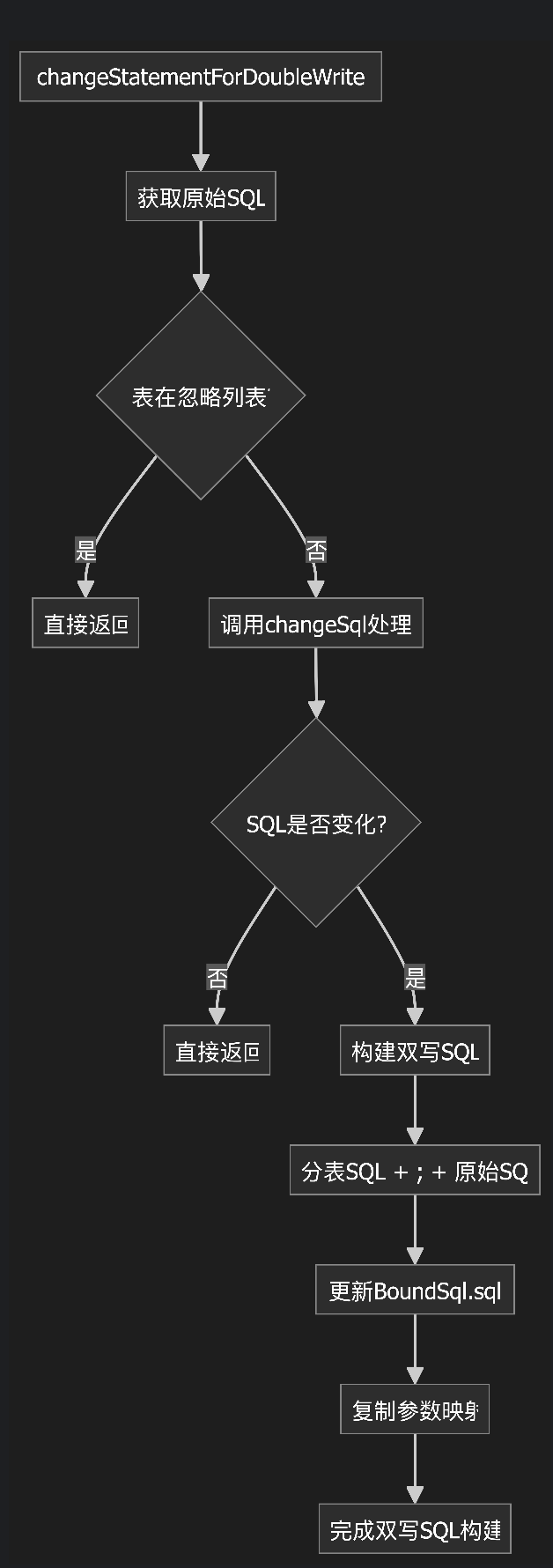
changeStatementForDoubleWrite 方法是实现平滑数据迁移的关键组件,它使得系统可以在不中断服务的情况下,从单表架构平滑过渡到分表架构,大大降低了系统升级的风险。
双读的处理
用于实现双读策略下的 SQL 处理。在双读模式下,系统会同时查询原始表和分表,并将结果合并,确保在数据迁移过程中能够读取到完整的数据。
方法
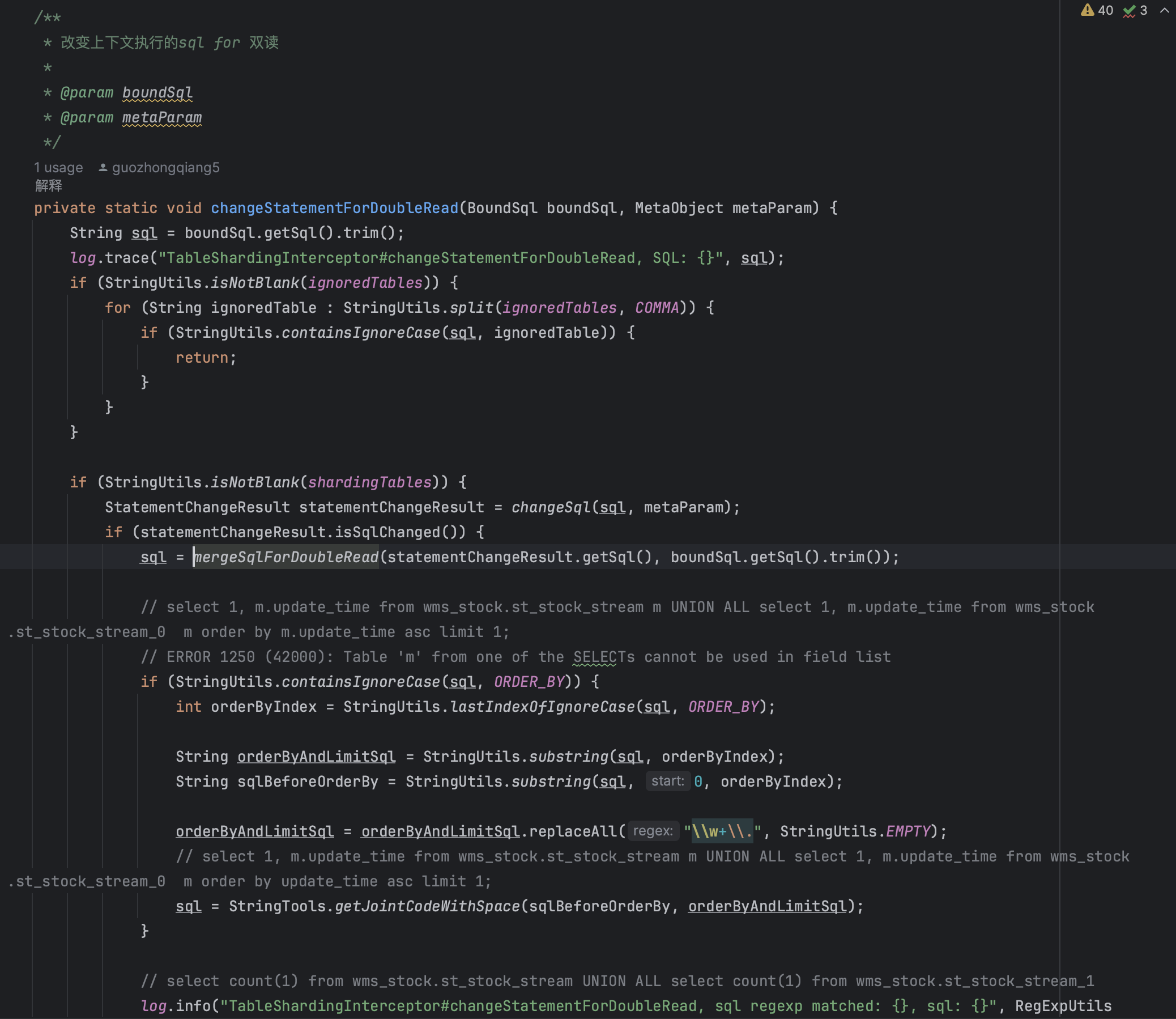
private static void changeStatementForDoubleRead(BoundSql boundSql, MetaObject metaParam)
核心功能
该方法的核心功能是:将单表查询 SQL 转换为双读 SQL,即同时查询原始表和分表,并处理结果合并。
实现逻辑详解
1. 前置检查
String sql= boundSql.getSql().trim();
log.trace("TableShardingInterceptor#changeStatementForDoubleRead, SQL: {}", sql);
// 检查是否在忽略列表中if (StringUtils.isNotBlank(ignoredTables)) {
for (String ignoredTable : StringUtils.split(ignoredTables, COMMA)) {
if (StringUtils.containsIgnoreCase(sql, ignoredTable)) {
return; // 忽略配置的表,不进行双读
}
}
}
逻辑说明:
- 获取原始 SQL 并记录日志
- 检查当前 SQL 涉及的表是否在忽略列表中
- 如果是忽略的表,则直接返回,不进行双读处理
2. 分表处理与SQL重写
if (StringUtils.isNotBlank(shardingTables)) {
StatementChangeResultstatementChangeResult= changeSql(sql, metaParam);
if (statementChangeResult.isSqlChanged()) {
sql = mergeSqlForDoubleRead(statementChangeResult.getSql(), boundSql.getSql().trim());
// 处理ORDER BY子句
if (StringUtils.containsIgnoreCase(sql, ORDER_BY)) {
intorderByIndex= StringUtils.lastIndexOfIgnoreCase(sql, ORDER_BY);
StringorderByAndLimitSql= StringUtils.substring(sql, orderByIndex);
StringsqlBeforeOrderBy= StringUtils.substring(sql, 0, orderByIndex);
// 移除表别名前缀,避免UNION ALL后的列引用错误
orderByAndLimitSql = orderByAndLimitSql.replaceAll("\\w+\\.", StringUtils.EMPTY);
sql = StringTools.getJointCodeWithSpace(sqlBeforeOrderBy, orderByAndLimitSql);
}
// 处理COUNT查询
if (StringUtils.containsIgnoreCase(sql, COUNT_NUM_FOR_SHARDING)) {
sql = "SELECT SUM( " + COUNT_NUM_FOR_SHARDING + " ) FROM (" + sql + ") ".concat(TEMP_TABLE_NAME);
}
// 处理SUM查询
if (StringUtils.containsIgnoreCase(sql, SUM_NUM_FOR_SHARDING)) {
sql = "SELECT SUM( " + SUM_NUM_FOR_SHARDING + " ) FROM (" + sql + ") ".concat(TEMP_TABLE_NAME);
}
// 更新BoundSql
ReflectionUtils.setFieldValue(BoundSql.class, boundSql, "sql", sql);
appendParameterMappings(boundSql);
}
}
关键技术点解析
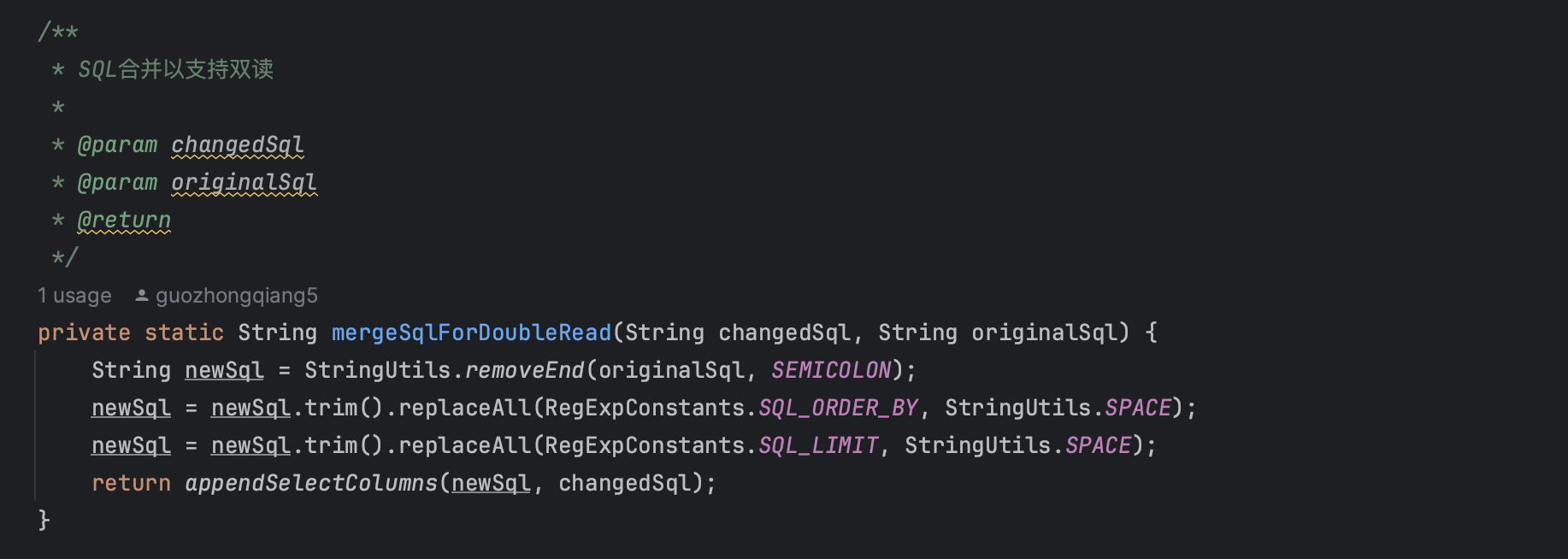
1. SQL合并机制
private static String mergeSqlForDoubleRead(String changedSql, String originalSql) {
StringnewSql= StringUtils.removeEnd(originalSql, SEMICOLON);
newSql = newSql.trim().replaceAll(RegExpConstants.SQL_ORDER_BY, StringUtils.SPACE);
newSql = newSql.trim().replaceAll(RegExpConstants.SQL_LIMIT, StringUtils.SPACE);
return appendSelectColumns(newSql, changedSql);
}
处理步骤:
- 移除原始SQL末尾的分号
- 移除ORDER BY子句(后续会重新处理)
- 移除LIMIT子句(后续会重新处理)
- 调用
appendSelectColumns合并SELECT列
2. ORDER BY处理
if (StringUtils.containsIgnoreCase(sql, ORDER_BY)) {
intorderByIndex= StringUtils.lastIndexOfIgnoreCase(sql, ORDER_BY);
StringorderByAndLimitSql= StringUtils.substring(sql, orderByIndex);
StringsqlBeforeOrderBy= StringUtils.substring(sql, 0, orderByIndex);
// 关键:移除表别名前缀,避免"Unknown column"错误
orderByAndLimitSql = orderByAndLimitSql.replaceAll("\\w+\\.", StringUtils.EMPTY);
sql = StringTools.getJointCodeWithSpace(sqlBeforeOrderBy, orderByAndLimitSql);
}
问题背景: 在UNION ALL查询中,如果ORDER BY子句包含表别名(如m.update_time),会导致"SQL Unknown column"错误,因为UNION ALL后的结果集不再有原始表的别名。
3. COUNT查询处理
if (StringUtils.containsIgnoreCase(sql, COUNT_NUM_FOR_SHARDING)) {
sql = "SELECT SUM( " + COUNT_NUM_FOR_SHARDING + " ) FROM (" + sql + ") ".concat(TEMP_TABLE_NAME);
}
转换示例:
- 原始:
SELECT COUNT(*) FROM table - 双读:
SELECT COUNT(*) AS countNumForSharding FROM table_0 UNION ALL SELECT COUNT(*) AS countNumForSharding FROM table - 最终:
SELECT SUM(countNumForSharding) FROM (SELECT COUNT(*) AS countNumForSharding FROM table_0 UNION ALL SELECT COUNT(*) AS countNumForSharding FROM table) tempForSharding
4. SUM查询处理
与COUNT查询类似,将多个分表的SUM结果再求和。
5. 参数映射处理
private static void appendParameterMappings(BoundSql boundSql) {
Stringsql= boundSql.getSql().trim();
intlimitIndex= StringUtils.lastIndexOfIgnoreCase(sql, LIMIT);
if (limitIndex < 0) {
// 无LIMIT,直接复制所有参数
boundSql.getParameterMappings().addAll(boundSql.getParameterMappings());
return;
}
// 处理LIMIT参数
StringlimitOffset= StringUtils.substring(sql, limitIndex);
intcountMatches= StringUtils.countMatches(limitOffset, SQL_PLACEHOLDER);
if (countMatches == 2) {
// LIMIT ?, ? (offset, pageSize)
List<ParameterMapping> originalParameterMappings = Lists.newArrayList(boundSql.getParameterMappings());
// 移除最后两个参数(LIMIT参数)
boundSql.getParameterMappings().remove(boundSql.getParameterMappings().size() - 1);
boundSql.getParameterMappings().remove(boundSql.getParameterMappings().size() - 1);
// 添加完整的参数列表
boundSql.getParameterMappings().addAll(originalParameterMappings);
}
// ... 其他情况处理
}
SQL转换示例
1. 简单查询
原始SQL:
SELECT * FROM st_stock_stream WHERE warehouse_no = ? AND deleted =0
双读SQL:
SELECT * FROM st_stock_stream_5 WHERE warehouse_no = ? AND deleted =0 UNION ALL SELECT * FROM st_stock_stream WHERE warehouse_no = ? AND deleted =0
2. 带ORDER BY和LIMIT的查询
原始SQL:
SELECT * FROM st_stock_stream WHERE warehouse_no = ? ORDERBY update_time DESC LIMIT 10
双读SQL:
SELECT * FROM st_stock_stream_5 WHERE warehouse_no = ? UNION ALL SELECT * FROM st_stock_stream WHERE warehouse_no = ? ORDERBY update_time DESC LIMIT 10
3. COUNT查询
原始SQL:
SELECT COUNT(*) FROM st_stock_stream WHERE warehouse_no = ?
双读SQL:
SELECT SUM(countNumForSharding) FROM (
SELECT COUNT(*) AS countNumForSharding FROM st_stock_stream_5 WHERE warehouse_no = ?
UNION ALL
SELECTCOUNT(*) AS countNumForSharding FROM st_stock_stream WHERE warehouse_no = ?
) tempForSharding
执行流程图
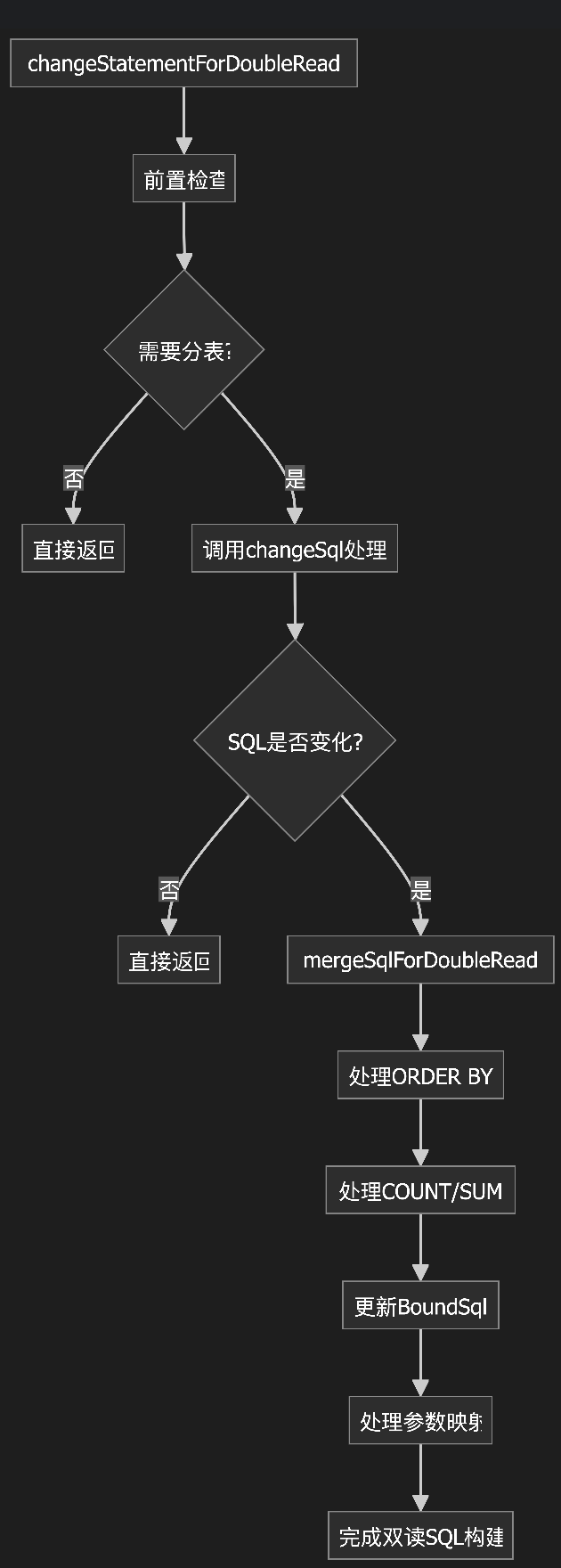
在从单表向分表架构迁移的过程中,使用双读策略可以:
- 确保读取到完整的数据(旧表+新表)
- 支持平滑迁移,无需停机
- 提供回滚能力
路由计算
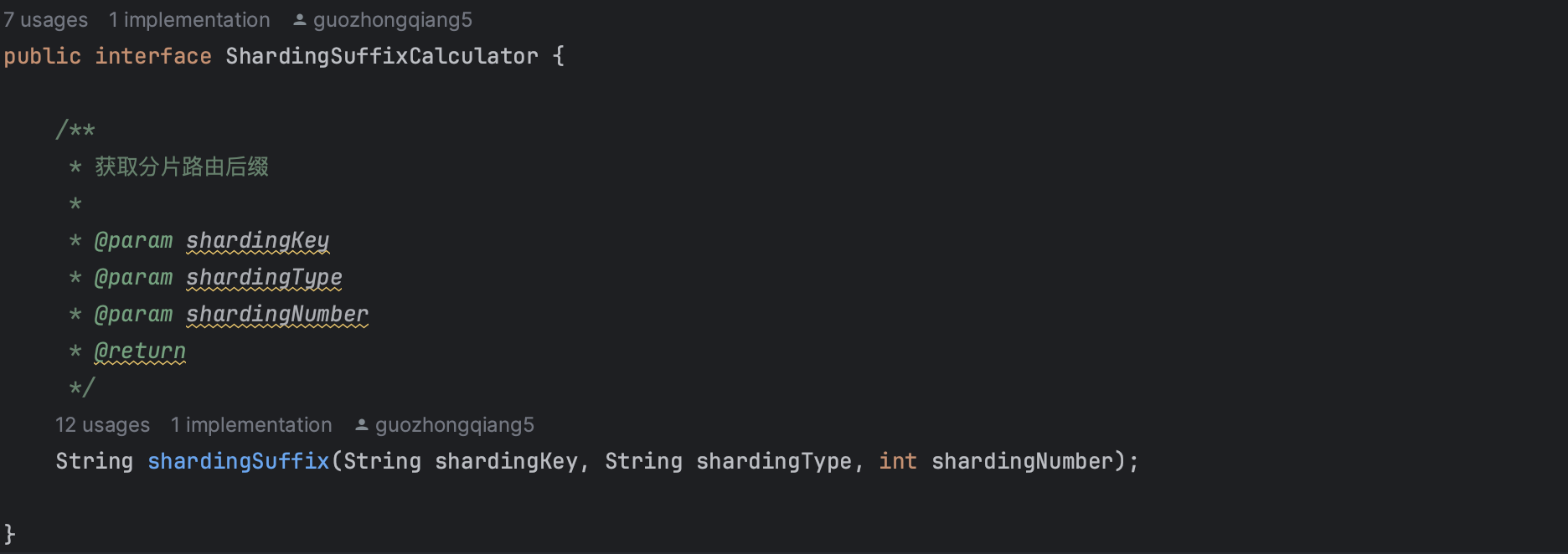
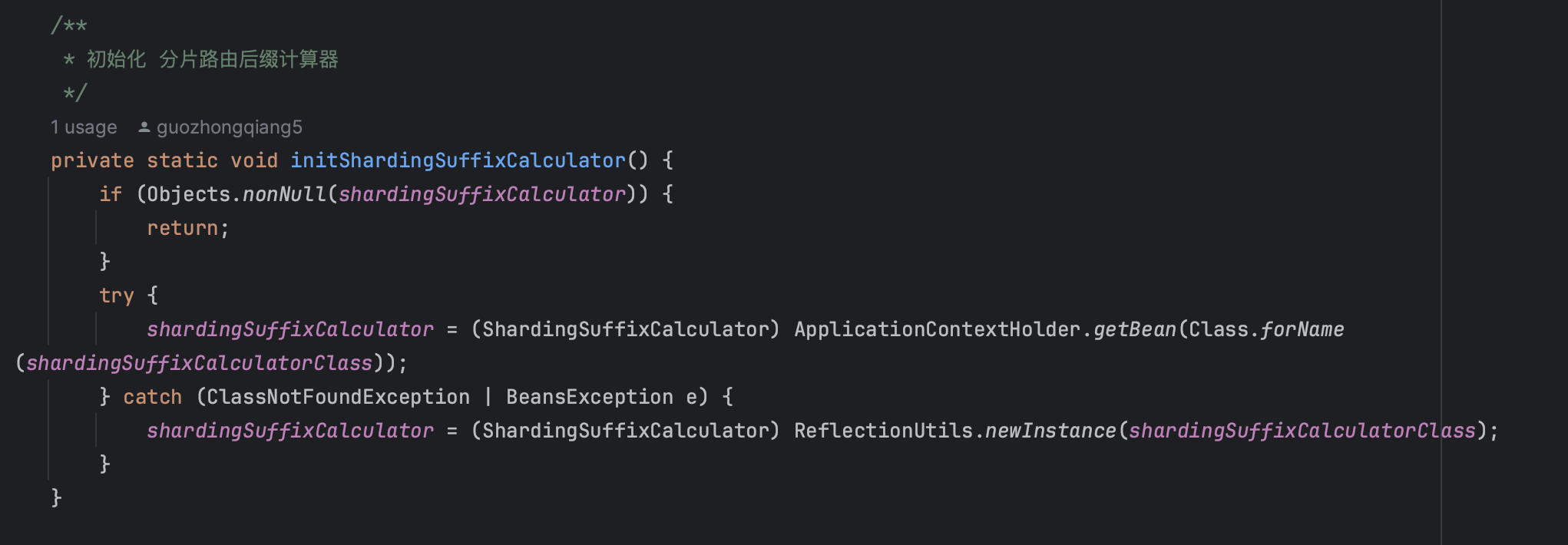
分表路由的一个具体实现,可以扩展实现为其他方式。
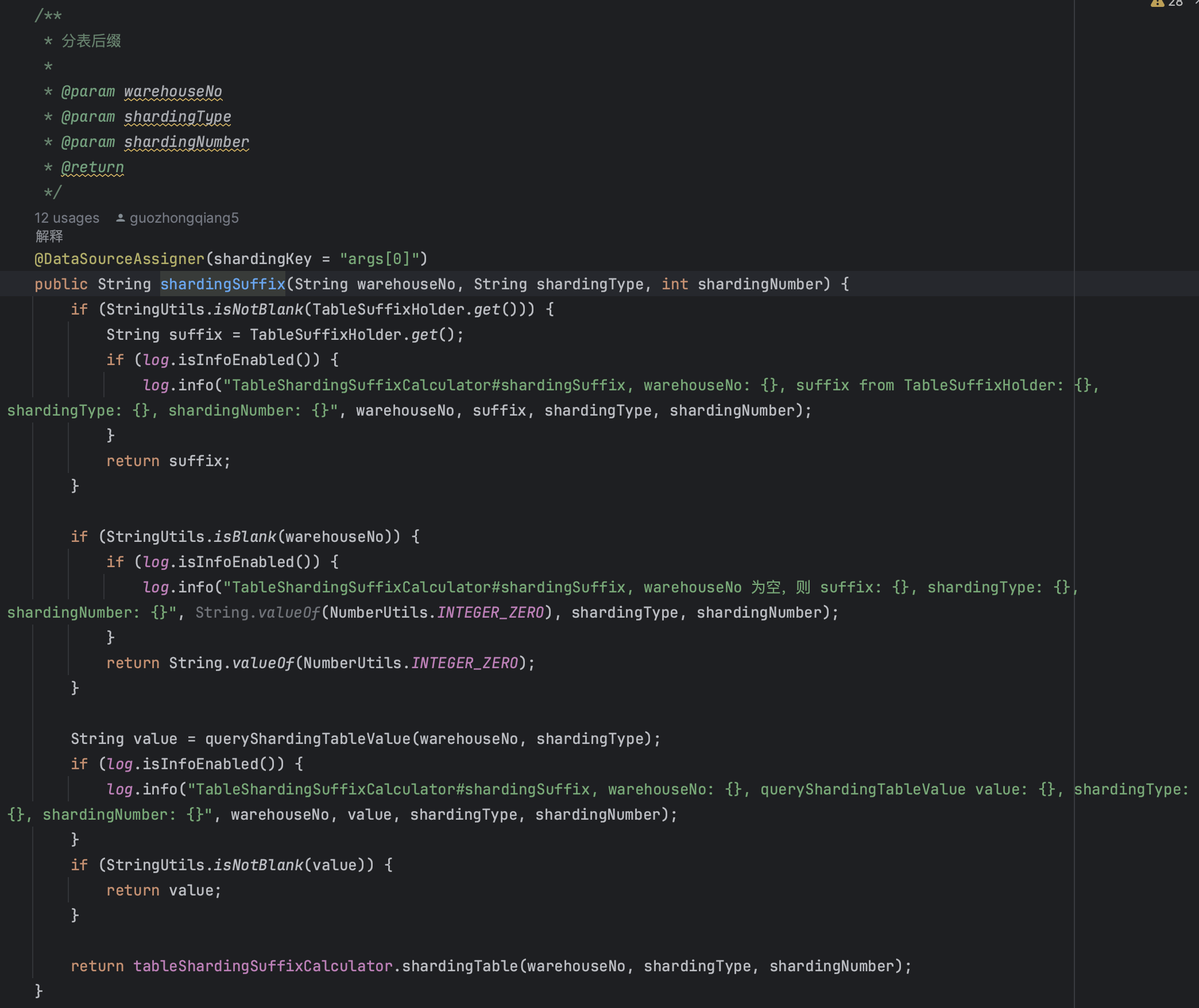
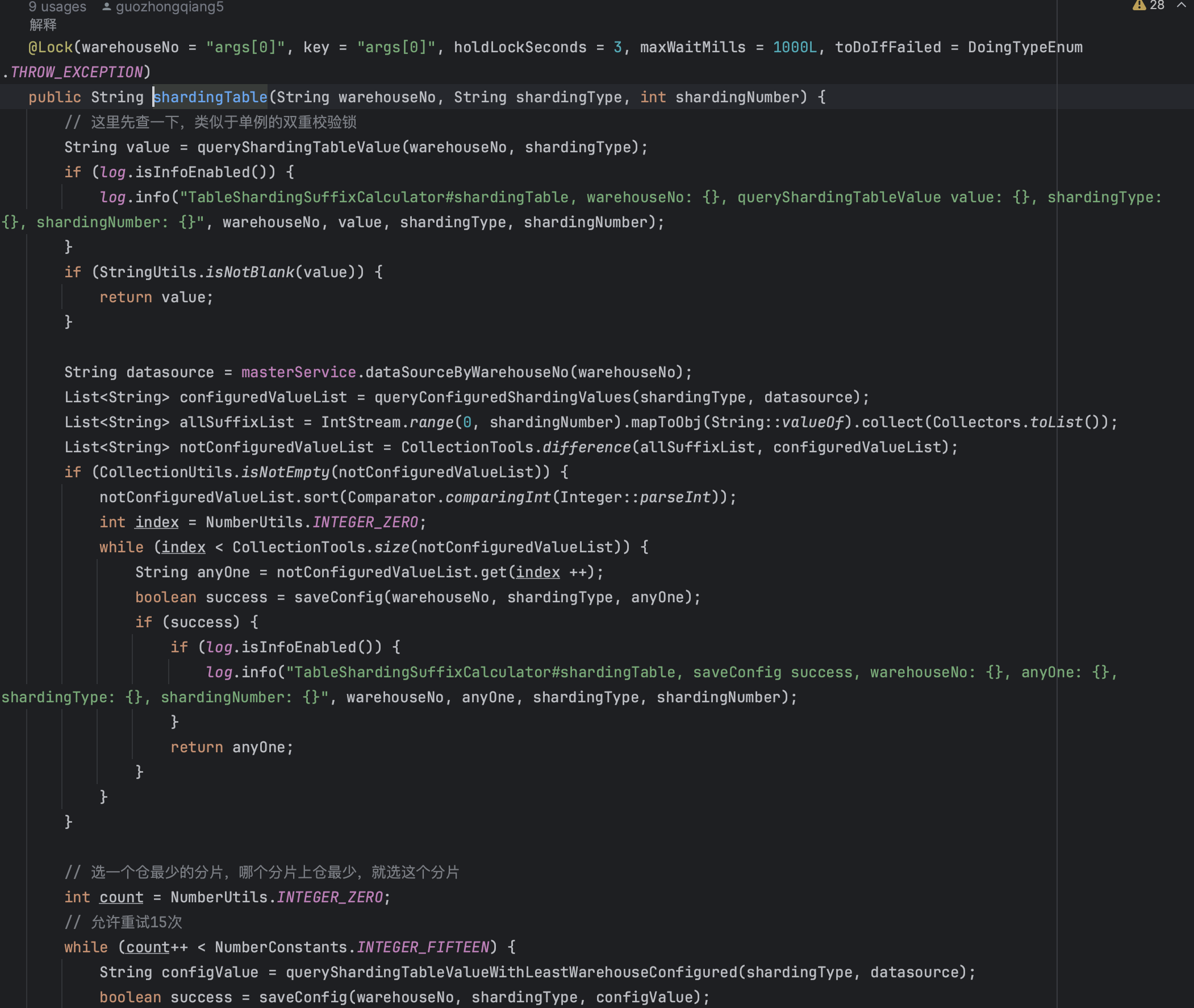
路由算法:
- 配置优先:首先检查是否已有配置的分表
- 负载均衡:选择分配仓库最少的分表
- 分布式锁:使用分布式锁确保分配的唯一性
- 容错机制:支持重试。
参数处理
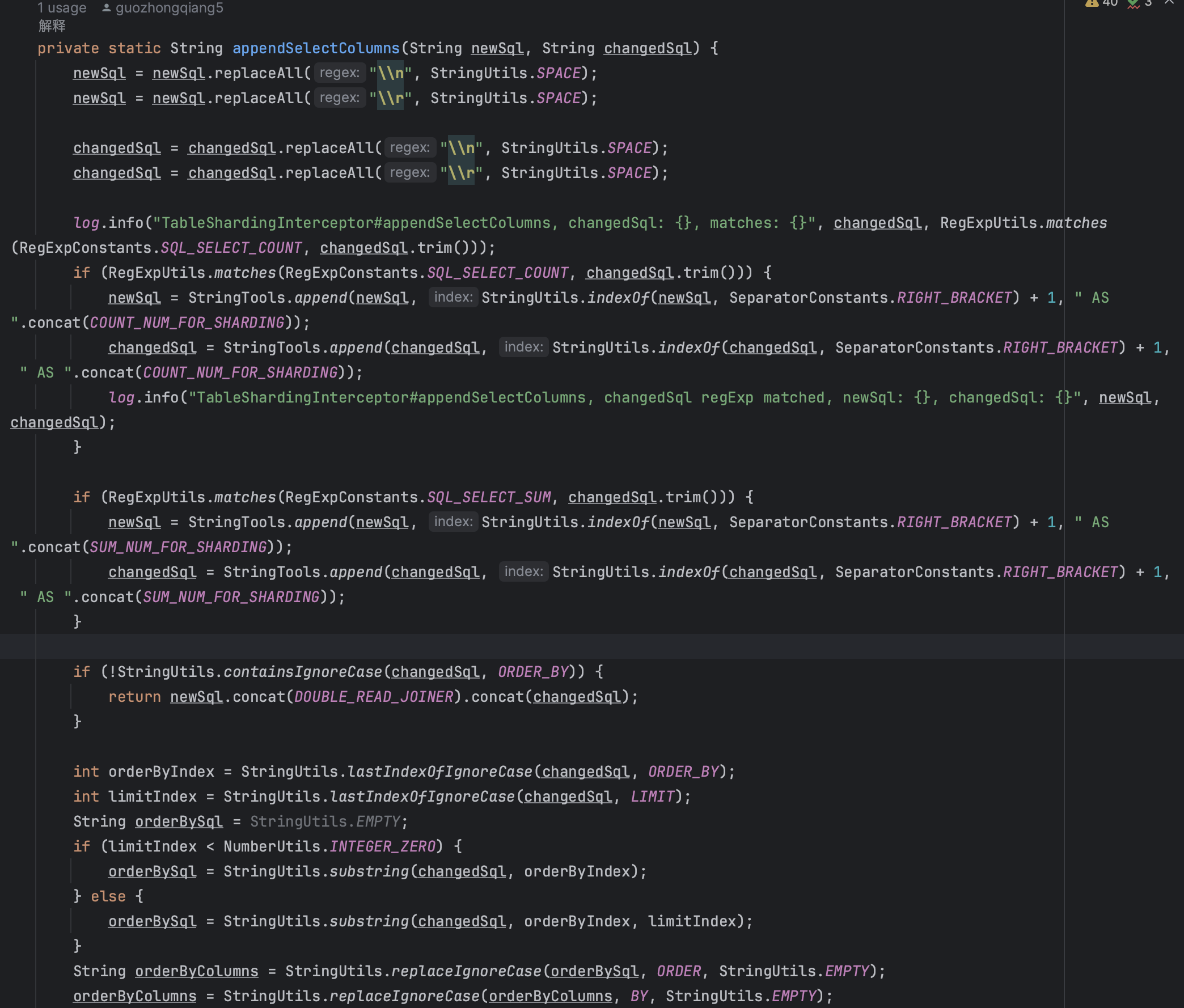
参数映射处理:
- 双写模式下,参数列表需要复制一份
- 双读模式下,需要根据LIMIT子句调整参数
- 保持参数与SQL占位符的一致性
性能优化
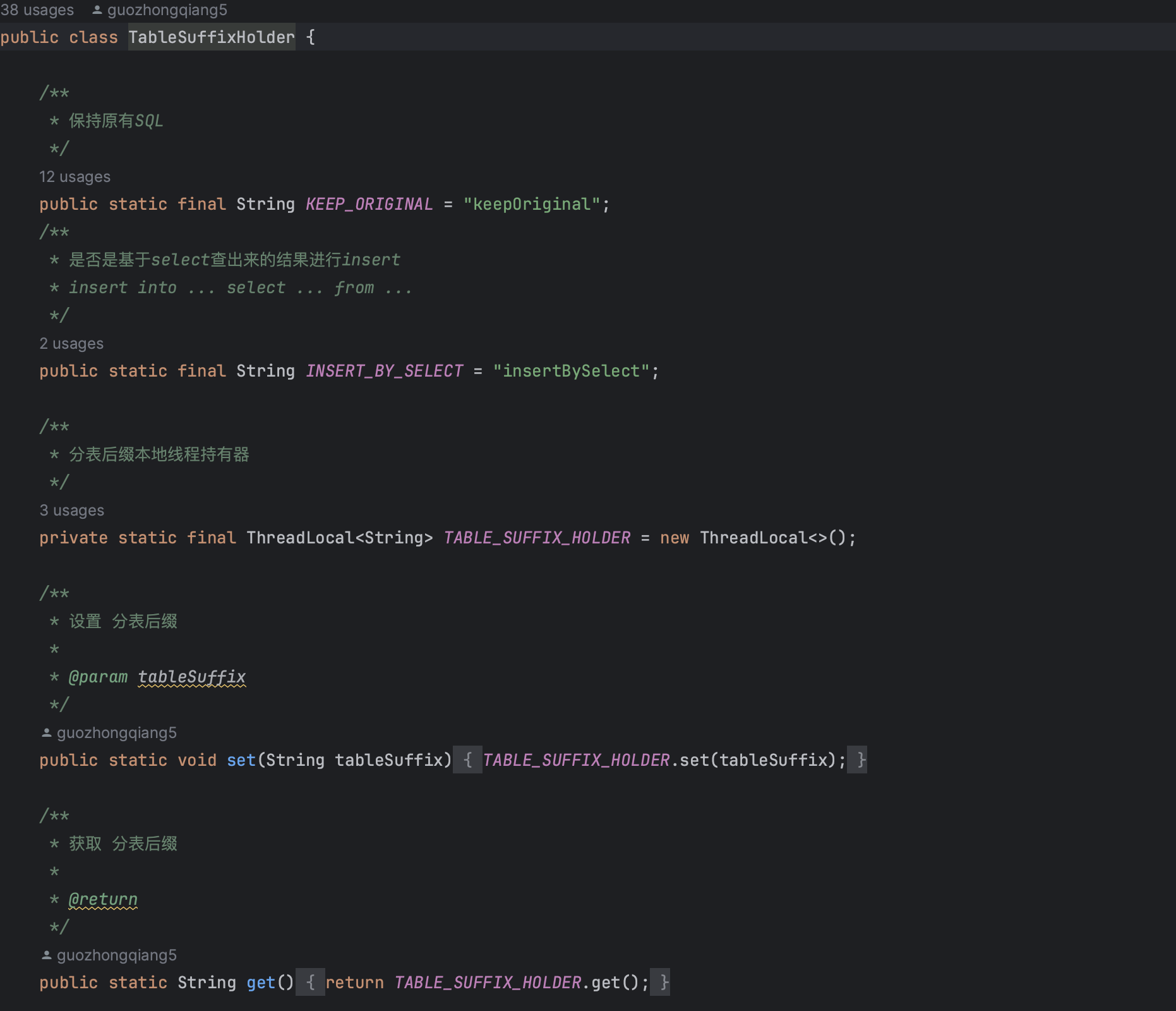
优化策略:
- 缓存机制:使用ThreadLocal缓存分表后缀
- 批量处理:支持批量操作的分表
- 索引优化:分表键上有索引,提高查询效率
- 连接池优化:每个分表使用独立的连接池
可扩展性
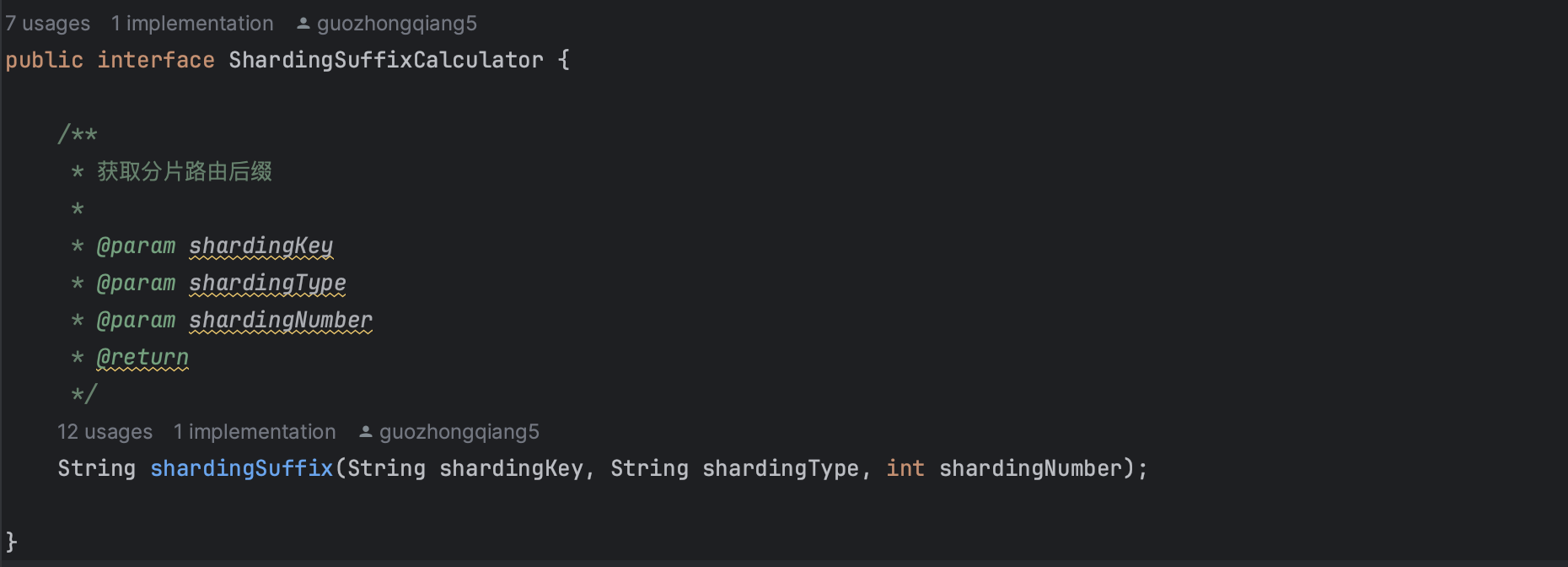
扩展点:
- 自定义分表策略:通过实现
ShardingSuffixCalculator接口 - 灵活配置:通过mybatis-config.xml配置分表规则
- 策略模式:支持多种读写策略,可动态切换
监控与日志

监控指标:
- SQL重写耗时
- 分表路由计算耗时
- 分表命中率
- 分布式锁竞争情况
日志记录:
- 分表键提取日志
- SQL重写前后对比
- 路由计算结果
- 异常情况记录
组件研发过程问题和解决方案
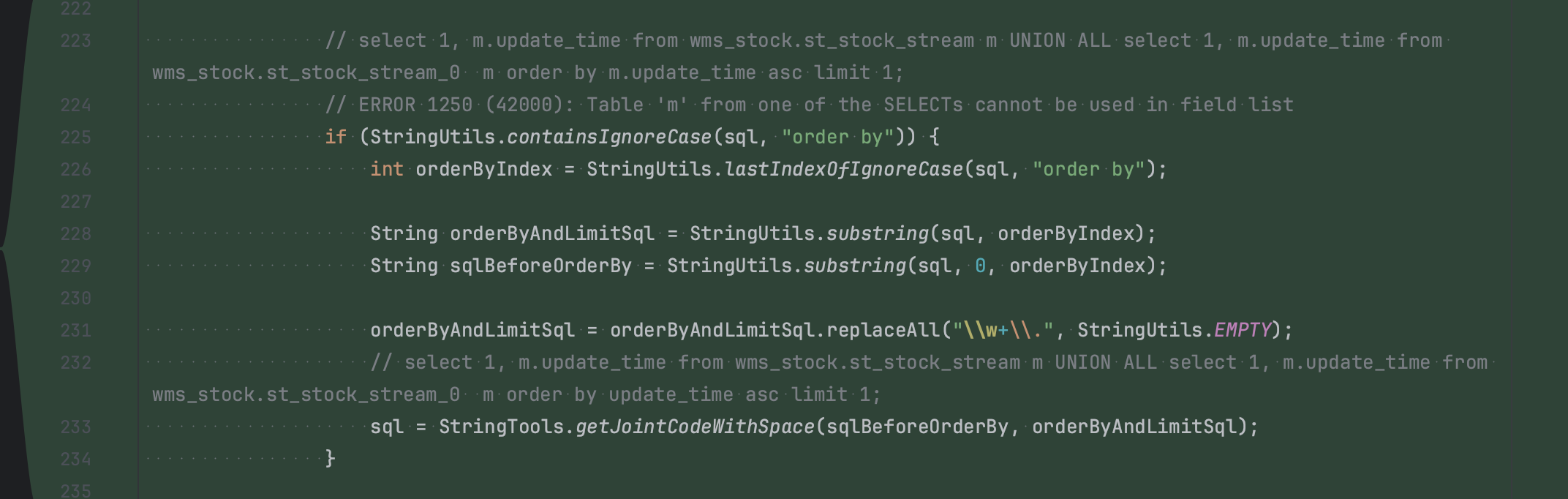
1、双读,排序字段缺失报错
案例:
报错信息:
ERROR 1250 (42000): Table 'm' from one of the SELECTs cannot be used in field list
解决方案:将排序字段放在子查询的select column中
select 1, m.update_time from wms_stock.st_stock_stream m UNION ALL select 1, m.update_time from wms_stock.st_stock_stream_0 m order by m.update_time asc limit 1;
2、双读,select count 报错
案例:
select count(1) from wms_stock.st_stock_stream UNION ALL select count(1) from wms_stock.st_stock_stream_1
解决方案:先将select count 通过UNION ALL 合并,然后外层进行sum

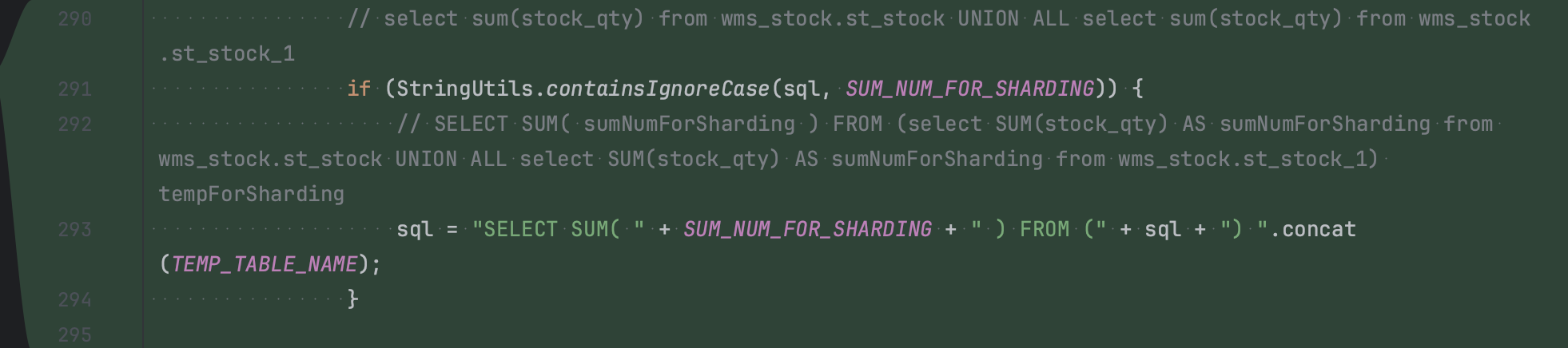
3、sum() 函数 UNION ALL 后需要再次 sum
案例:
select sum(stock_qty) from wms_stock.st_stock UNION ALL select sum(stock_qty) from wms_stock.st_stock_1
解决方案:每个sum 语句作为子查询,外层再次sum,累加所有的子数量,作为总数量。