



论文标题:RTPrune: Reading-Twice Inspired Token Pruning for Efficient DeepSeek-OCR Inference
作者:Ben Wan,Yan Feng,Zihan Tang,Weizhe Huang,Yuting Zeng,Jia Wang,Tongxuan Liu
论文链接: https://arxiv.org/pdf/2605.00392
背景
- 近期的视觉语言模型 (VLM)在多模态理解方面取得了强劲性能,但在光学字符识别 (OCR) 任务上仍面临挑战。DeepSeek-OCR不仅通过大幅增强 OCR 能力克服了这一挑战,还通过少量的视觉token加速了大型语言模型 (LLM) 的推理,证明了视觉模态作为文本信息高效压缩介质的有效性。然而,尽管视觉 Token 比原始文本更紧凑,但仍容易出现冗余。

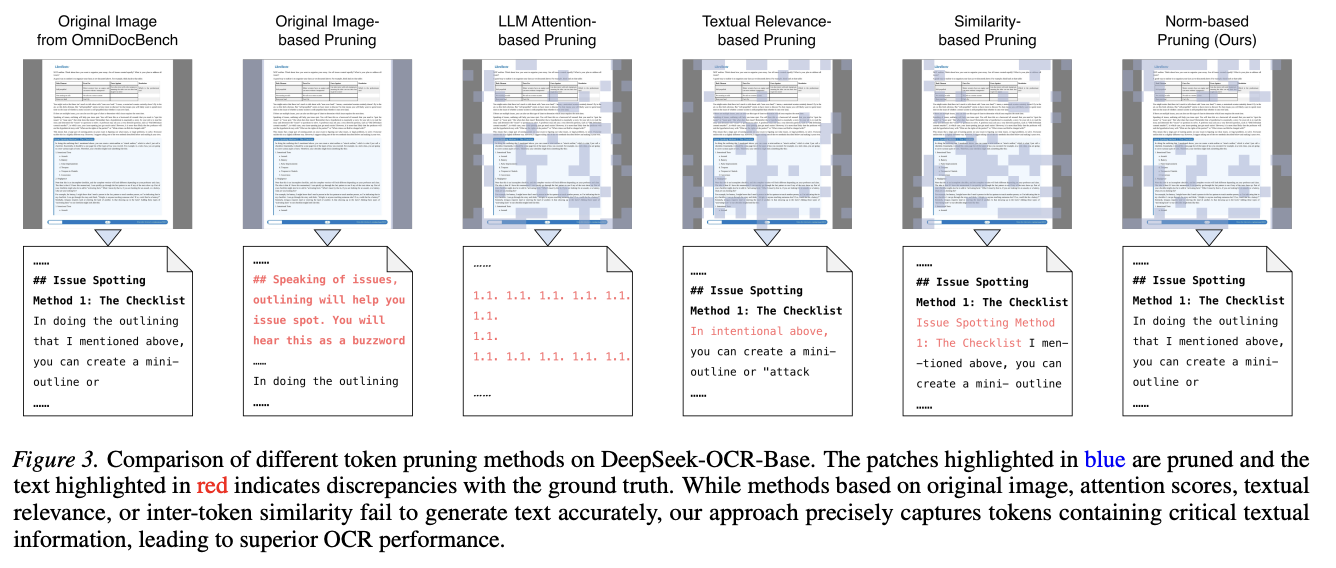
- 现有的基于注意力分数、文本相关性或token间相似度的视觉token剪枝方法无法直接应用于DeepSeek-OCR。首先,与传统VLM不同,DeepSeek-OCR中视觉编码器的重新训练削弱了视觉与语言之间的多模态对齐,导致文本信息与其原始视觉位置出现偏差。其次,与查询驱动的视觉问答不同,OCR 旨在恢复图像中的所有文本内容,这在严格保持识别准确性的前提下,严重限制了激进压缩的空间。因此,DeepSeek-OCR需要一种专门的剪枝方法,既能保留包含文本信息的视觉token,又能根据每个输入图像自动调整剪枝比例。
方法
LLM 解码过程中的注意力变化观察
为了寻找新的剪枝线索,本文分析了模型在解码过程中的注意力模式,发现了一种明显的两阶段阅读行为 。在浅层网络中,模型主要将注意力集中在那些具有较高嵌入L2-范数的视觉token上,因为它们通常编码了最核心的文本和结构信息 。而在深层网络中,模型的注意力会发生转移,开始关注其他token,包括剩余的高范数token,以补充结构和上下文线索 。这一核心观察直接启发了后续的两阶段剪枝方法设计 。
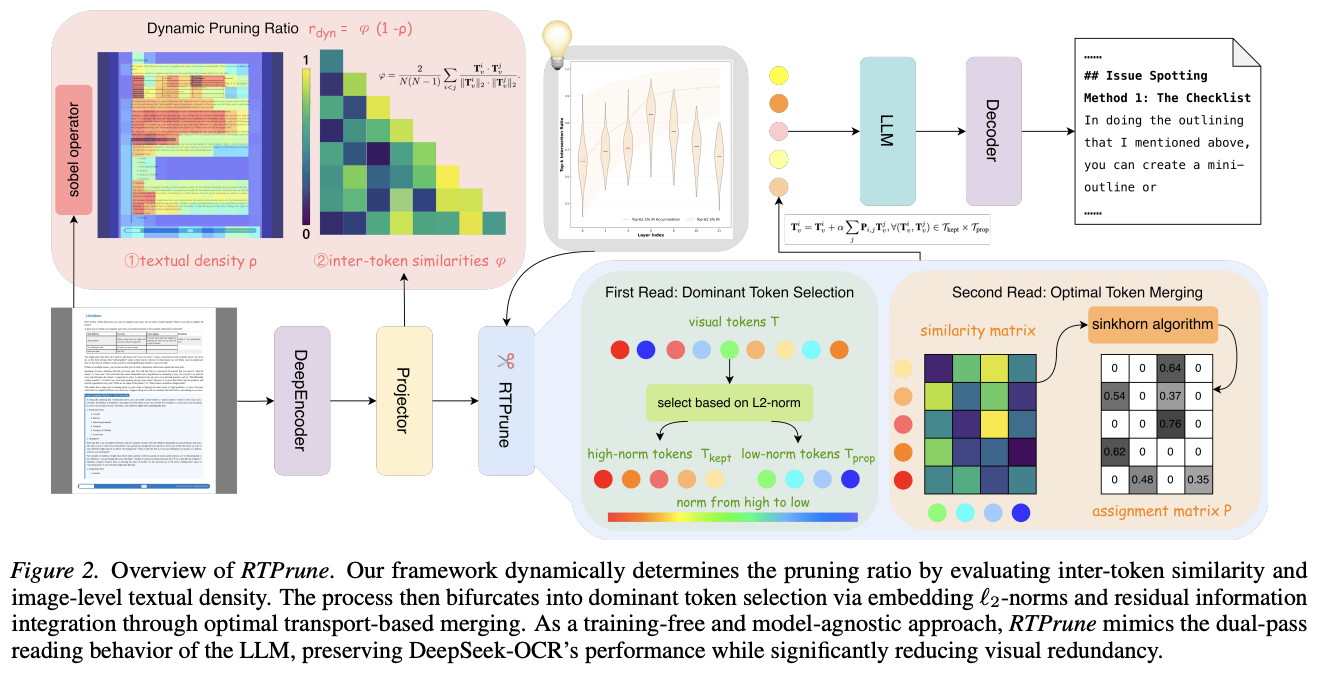
RTPrune
- 第一阶段:主导词元选择
为了模拟大模型在浅层的首次阅读行为,该阶段以视觉token的特征L2-范数作为重要性评估的唯一标准 。特征范数越大的token,包含的关键文本信息越多。算法会根据目标剪枝率,优先保留范数最大的那一批token,而将剩余特征范数较小的划入待剪枝集 。
- 第二阶段:最优词元融合
为了模拟大模型在深层的注意力重分配,该阶段旨在将待剪枝集中的有效信息补偿给已保留的token。本文引入了最优传输理论,通过计算特征相似度,在保留集和待剪枝集之间建立最优匹配矩阵P,并引入一个垃圾桶来吸收差异过大、无法匹配的完全冗余token。最后,将成功配对的待剪枝token加权融合到保留token中,从而在大幅减少序列长度的同时挽回信息损失 。
- 动态剪枝率策略
考虑到 OCR 对精度要求极高,不能对所有图像采用一刀切的剪枝比例,本文设计了一种动态剪枝率计算方法 。该策略联合评估两个关键指标:token间特征相似度φ(反映非文本区域的结构重复度和理论可压缩空间)与图像文本密度ρ(利用 Sobel 算子检测边缘,反映真实的文本信息丰富度)。根据这两个指标,模型能自适应地为每张输入图像分配最佳剪枝比例,在文本密集的区域保守剪枝,在背景冗余的区域激进剪枝,从而达到最优的效率-精度平衡 。
实验
有效性
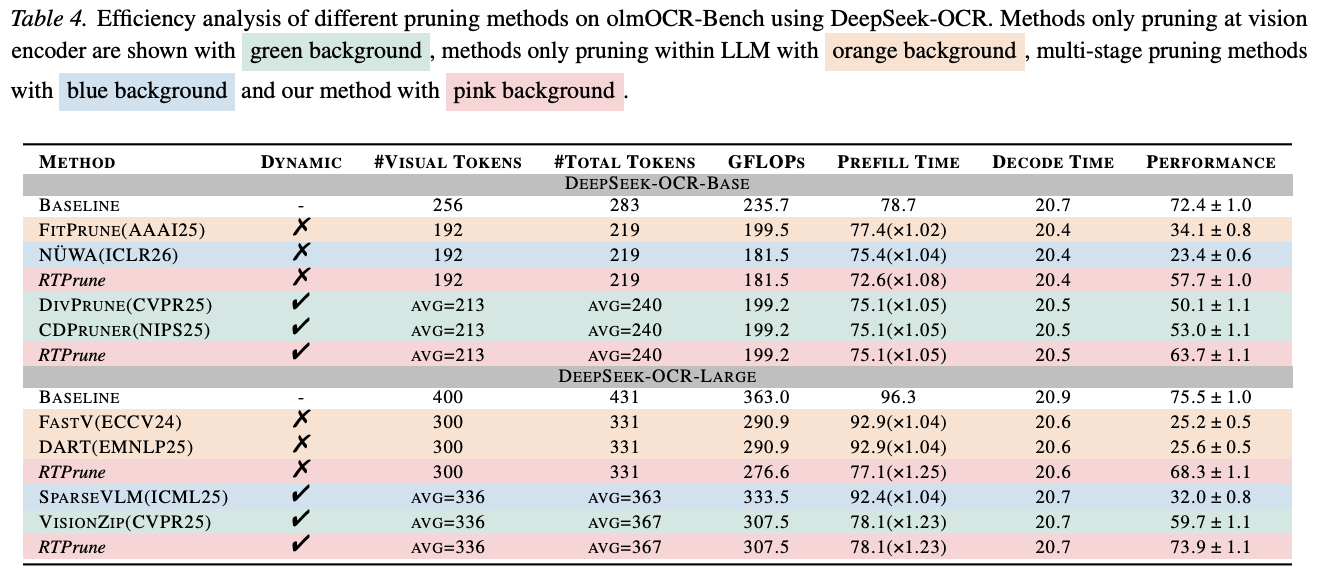
本文在多个主流OCR基准测试集(OmniDocBench,OlmOCR-Bench,Ocean-OCR Benchmark)上对 RTPrune 进行了全面的评估。实验结果表明,RTPrune 成功地在大幅降低计算开销与维持极高OCR准确率之间取得了当前最优的平衡 。例如在OmniDocBench测试中,在保持 99.47% 准确率的同时,RTPrune成功减少了近 15.29% 的GFLOPs,并将预填充时间缩短了近18.90% 。
泛化性
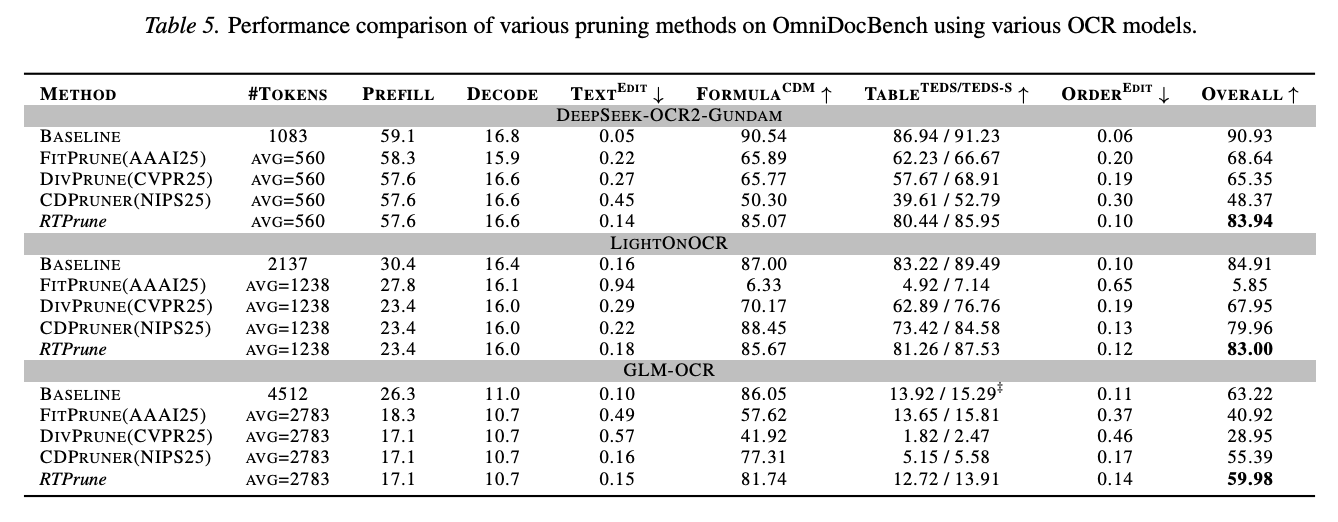
随着端到端 OCR 模型(如 DeepSeek-OCR2、LightOnOCR、GLM-OCR)的不断涌现,预期富文本token具有更大范数这一现象将不仅限于 DeepSeek-OCR,而具有普适性。为了验证RTPrune并非仅针对DeepSeek-OCR量身定制,本文进一步在OmniDocBench基准测试上,针对近期发布的几种端到端OCR模型评估了该方法的泛化能力。实验表明:1) 其他剪枝方法在不同 OCR 模型上的性能表现波动较大,而RTPrune则始终保持稳定,在所有测试模型中均能保留原始模型 95% 以上的性能。2) RTPrune在这些指标上取得了强劲的结果,在大幅提升推理速度的同时,性能下降极小,这进一步证明了方法的有效性和泛化能力。
[1] DeepSeek-OCR 2: Visual Causal Flow. Arxiv26 [2] LightOnOCR: A 1B End-to-End Multilingual Vision-Language Model for State-of-the-Art OCR. Arxiv26 [3] GLM-OCR Technical Report. Arxiv26
消融实验
在DeepSeek-OCR-Base平均减少16%视觉token的设置下,进一步验证各组件的累加效应,以证明方法核心设计选择的合理性。
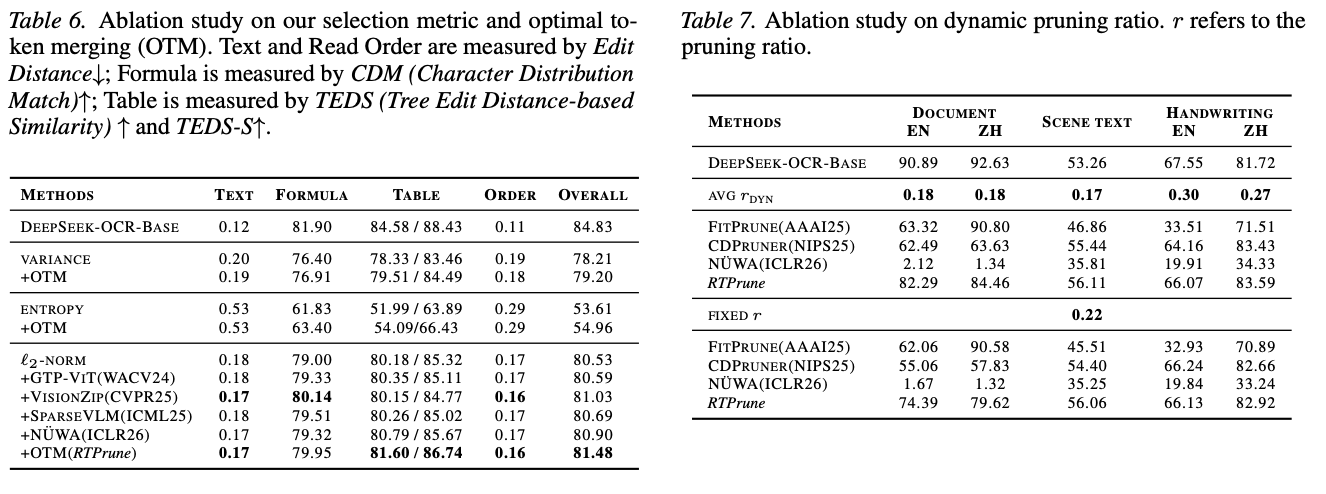
- 筛选指标:L2-范数的表现优于其他重要性指标。基于方差的筛选也取得了较好的结果,因为范数较大的特征通常表现出更宽的数值分布,从而具有更高的方差;但该指标可能会遗漏那些范数增长主要源于特征整体偏移而非数值分散的token。
- 合并方法: 在不同的筛选准则下,基于OT(最优传输)的方法始终能获得最佳的综合性能,这验证了基于 OT 的特征匹配在视觉token传递中的有效性。
- 动态剪枝比例: 相同的平均剪枝率下,在自适应剪枝率较高的场景中(例如文档提取和场景文本识别),所提出的策略比固定比例剪枝的准确率提高了高达 13.5%。实验结果进一步验证了基于输入内容的动态剪枝比例的有效性。





