



外发脱敏版本见: https://joyspace.jd.com/h/personal/pages/JmfJmSdeVqddJBP5BEbt 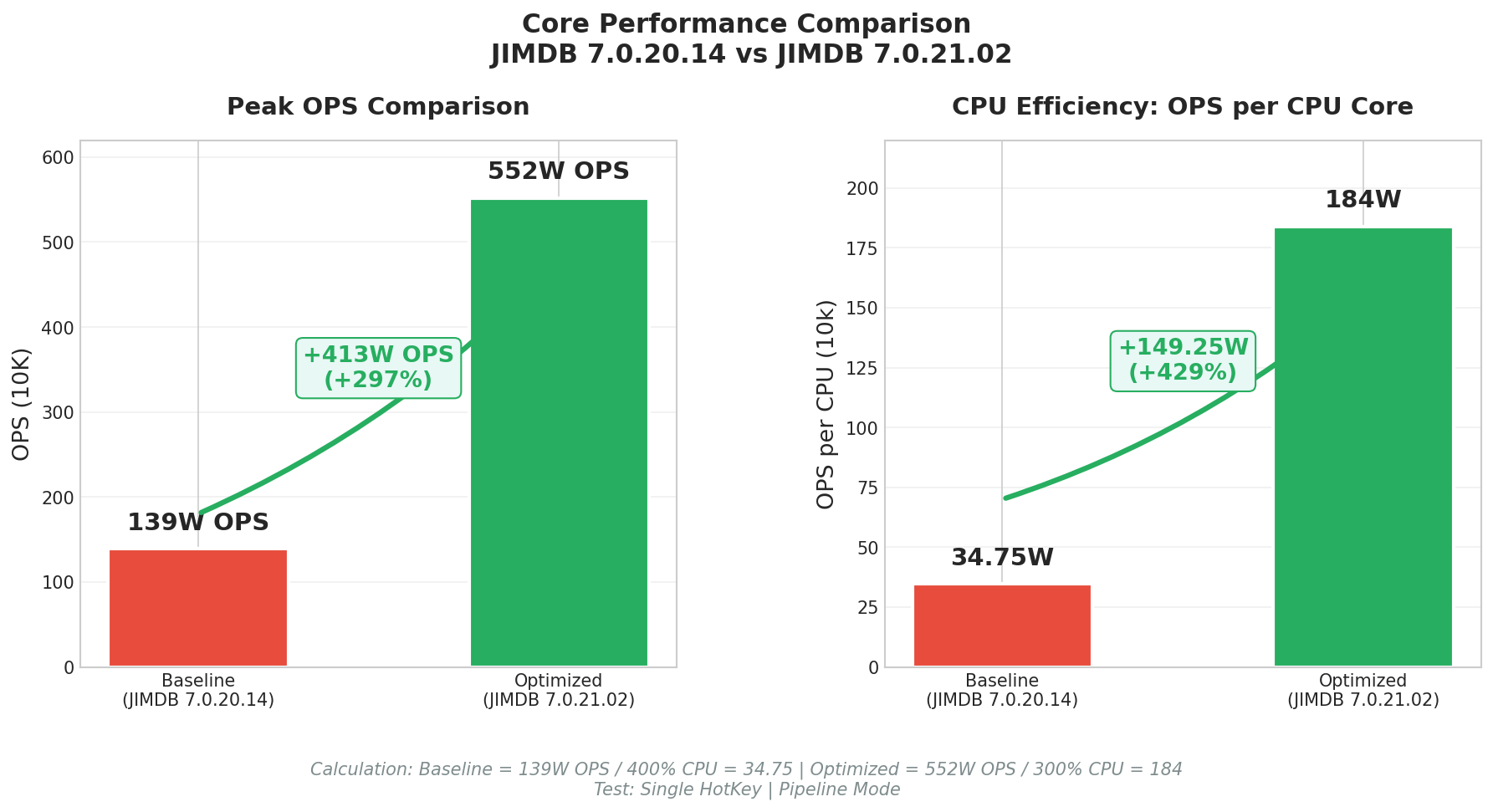
摘要
在高并发分布式缓存场景下,热 Key(Hot Key)不仅是单点性能瓶颈,更是引发集群雪崩的关键诱因。JIMDB 此前推出的大热 Key(Big‑Hot Key)主动治理方案已成功解决“既大又热”场景下的 CPU 与带宽瓶颈。然而当 Key 的 Value 极小、OPS 极高(即“纯热 Key”)时,瓶颈由序列化转移至单线程事件循环本身,传统优化收效甚微。本文在回顾大热 Key 成果的基础上,深入剖析纯热 Key 场景的性能边界,提出一种基于 JIMDB 异步 IO 线程的 “IO 线程旁路缓存” 架构。该架构通过预序列化热点 GET/HGET 响应并在 IO 线程层短路返回,将主线程从高频读取路径中彻底剥离,释放多核 CPU 算力,以4C20G容器为例,单机极限吞吐量从 139 万 OPS 跃升至 552 万 OPS,性能提升约300%,内存下降25%。结合国际主流方案对比,本文还探讨了“性能‑一致性‑透明性”三维权衡模型,论证了内核级透明治理在超大规模分布式系统中的独特价值。
第一章 问题定义与演进:从大热 Key 到纯热 Key 的盲区
1.1 大 Key、热 Key 与大热 Key:三层递进
在分布式缓存中,“大 Key”与“热 Key”是两类最经典的问题:
- 大 Key (Big Key):Value 体积过大(如包含5000元素的 集合 或数 MB 的 String),单次读写操作消耗大量 CPU 序列化时间和网络带宽。
- 热 Key (Hot Key):被大量客户端高频访问的 Key,无论 Value 大小,都会导致请求集中于单个实例,造成 CPU 过载。
这两类问题的共同后果表现为单核 CPU 打满、网络拥塞、雪崩风险,但二者的触发机制不同:大 Key 源于数据规模,热 Key 源于访问频率。长期实践中,我们发现真实生产故障往往发生在二者的交叠区域——一个 Key 可能既不大、也不满足传统热 Key 阈值,但其数据量与访问频率的叠加效应却足够击垮单节点。基于此,JIMDB 提出了“大热 Key (Big‑Hot Key)”概念:不再静态地看 Key 的属性,而是衡量其对服务端 CPU 和网络带宽的实时消耗。这一“从属性定义到影响定义”的范式转换,使得一系列隐藏瓶颈浮出水面。
1.2 大热 Key 方案已解决的成就
在《超越大小与热度:JIMDB“大热 Key”主动治理解决方案深度解析》一文中,我们介绍了一套完整的治理体系:
- 多维度实时识别引擎:融合带宽检测、集合规模静态预判和基于机器学习的 CPU 算力预测,在命令执行路径上以极低开销识别大热 Key。
- 服务端自动缓存序列化结果:对于读密集且数据量大的操作(如 HGETALL、LRANGE),服务端将完整的序列化响应缓存在内存中,后续相同请求直接返回预序列化数据,完全绕过原始数据结构遍历和 RESP 编码,CPU 使用率从 100% 降至 30% 左右。
- 自动熔断与手动黑名单:提供“一刀切”式保护,快速切断问题请求。
- 客户端智能协同:SDK 层面的版本号校验本地缓存,保证强一致性的同时大幅降低网络开销。
该方案成功解决了“又大又热”的读密集型 Key 问题,已在超五十万个实例中落地,显著降低了线上 CPU 告警和由大热 Key 引起的端口阻塞事故。
1.3 纯热 Key:大热 Key 方案的盲区
然而,线上统计显示,还存在另一类同等危险但一直被忽视的场景:
Key 的 Value 很小(几十到几百字节),但 OPS 极高(单个 Key 数万甚至数十万 QPS)。
典型如秒杀库存标记、活动状态位、全局配置开关等。这些场景下,每次请求的数据量极小,序列化成本几乎可以忽略不计——一个几百字节的 Value,RESP 编码仅需几微秒,大热 Key 方案中“异步序列化缓存”的优化空间微乎其微。换言之,大热 Key 方案的“药不对症”。
我们通过火焰图(图1)进一步验证了这一判断。
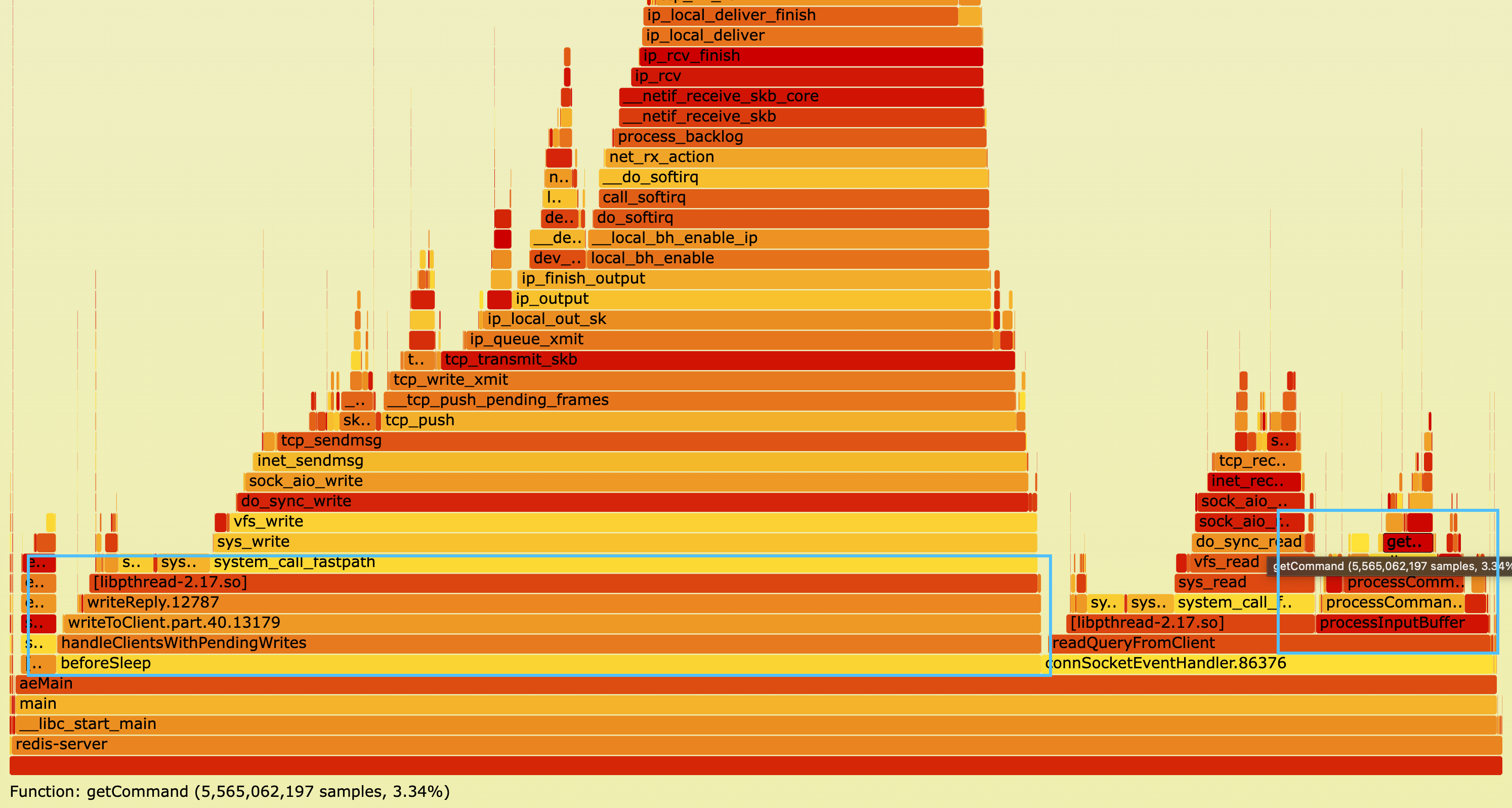
图1:纯热 Key 场景下的主线程火焰图
这表明:在纯热 Key 场景下,主线程的 CPU 时间并非消耗在“命令执行”本身,而是消耗在“让命令有机会被执行”的流水线串行调度上。
这一发现彻底改变了优化思路。传统单线程模型中,网络读取、协议解析、命令执行、结果写回全在主线程排队,即便每次操作仅需几微秒,当 OPS 达到几十万时,主线程的 CPU 也会被这套“流水线”完全占满。因此,瓶颈不在 Value 大小,而在于请求数量本身,以及它们必须经过主线程这一刚性约束。
线上数据显示,热 Key 中String 和 Hash 类型占比超过 95%,其中绝大多数访问为GET和HGET命令。这意味着只需针对这两个命令做定向优化,即可覆盖绝大多数纯热 Key 场景。
于是,问题从“如何减少序列化开销”演变为“如何让主线程少干活,甚至不干活”。这需要一种新的架构能力——IO 线程短路响应。
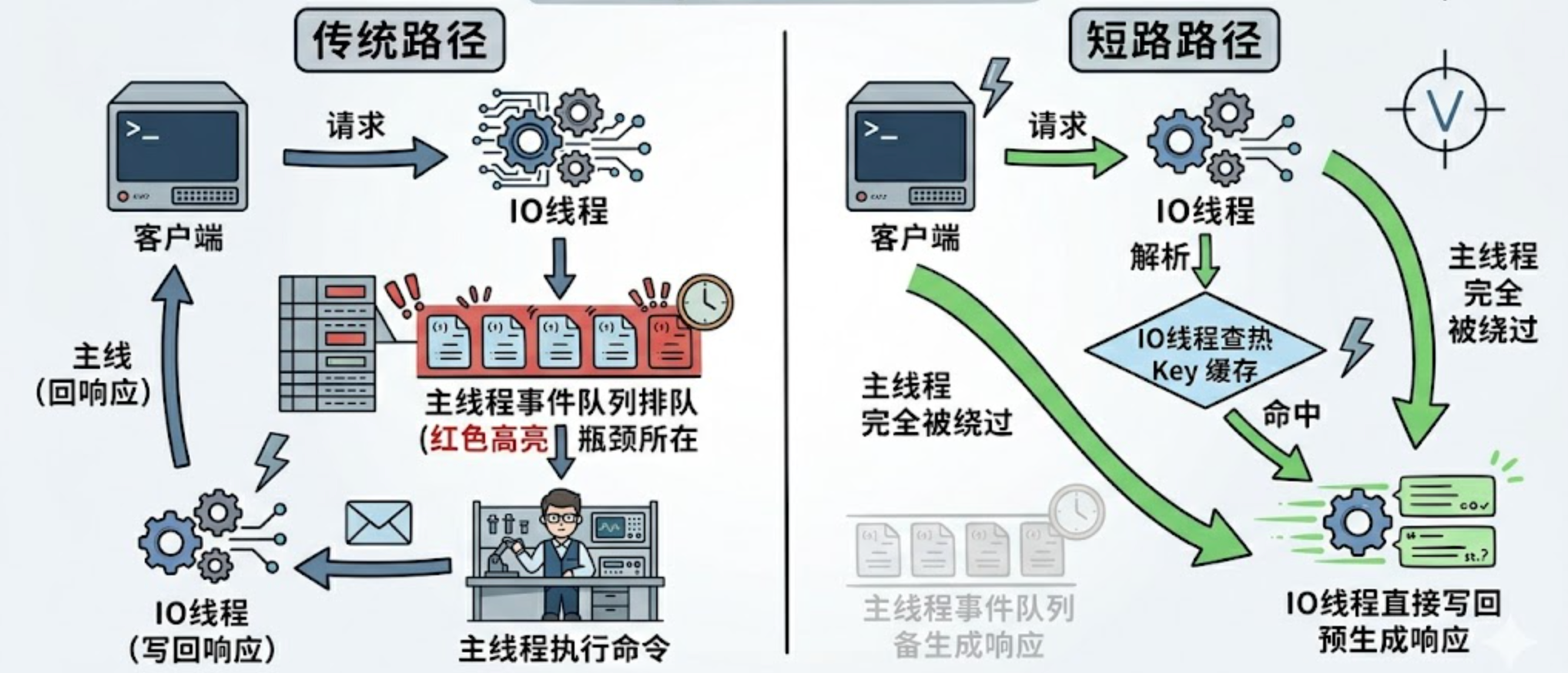
图2:请求路径对比流程图
第二章 业界热 Key 治理技术全景
目前业界主流的热 Key 治理思路,总体上可划分为云厂商托管方案和开源/自研方案,它们在“性能”、“一致性”和“透明性”三角上各有取舍。
2.1 云厂商托管方案
2.1.1 阿里云 Tair:代理查询缓存(Proxy Query Cache) + 应用层扩展
Tair 在代理层提供了 Proxy Query Cache,能缓存热点 Key 的请求与响应,在有效时间窗口内直接返回,无需访问后端分片。
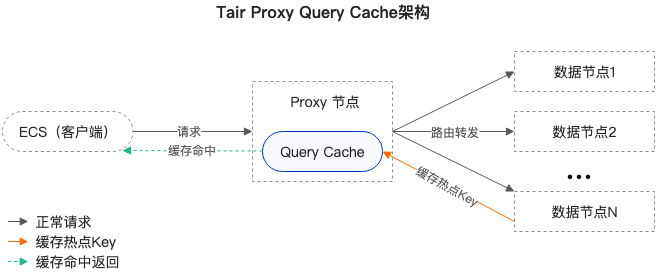
优势:Proxy Query Cache 对客户端完全透明,无需任何代码改造即可生效;产品化程度高,配置即用。
局限:缓存位于 Proxy 层,Proxy 本身可能成为性能瓶颈;Proxy 缓存在 TTL 窗口内存在数据不一致风险(官方明确标注“可能读到脏数据”);真正的客户端进程内缓存需业务自行实现。
2.1.2 腾讯云 Redis(CRS):API 级热 Key 检测 + 应用层治理
腾讯云 Redis(CRS)提供热 Key 的 实时查询能力,通过API接口支持实时、近 30 分钟、近 6 小时、近 24 小时等多个时间维度的热 Key 查询。
在治理层面,腾讯云推荐的方式是在应用层对热点 Key 进行分片拆分,通过跨节点访问将集中流量打散。配合共享连接池技术,可让单节点吞吐能力提升 50% 以上。
优势:与腾讯云生态(API Explorer、SDK、监控)无缝集成;热 Key 检测接入便捷,支持多时间维度。
局限:缺乏平台内建的热 Key 自动缓存或熔断能力;治理手段主要依赖应用层改造。
2.1.3 华为云 GeminiDB Redis:存算分离 + API 查询
华为云 GeminiDB Redis 采用存算分离架构,支持热数据从存储池自动加载到内存,冷数据淘汰后仍保留在存储池中。在热 Key 治理方面,提供热Key诊断功能,快速发现热key,为服务优化提供基础。

优势:存算分离架构天然缓解单节点内存压力;实时热 Key 查询便于对接告警系统。
局限:以识别为主,治理能力相对薄弱;缺乏热 Key 的自动缓存或熔断机制。
2.2 开源 / 自研方案
2.2.1 Redis 8.6:原生HOTKEYS命令
Redis 8.6 版本首次引入了原生的HOTKEYS命令族,标志着社区 Redis 在热 Key 治理方面迈出了关键一步。该功能由 Redis 内核内置的采样引擎驱动,能够实时检测并报告高频访问的 Key,帮助识别性能瓶颈并在集群环境中优化数据分布 。HOTKEYS命令族包含三个子命令:
HOTKEYS START [METRICS ...]:启动热 Key 追踪采样,可选择按 CPU 消耗或网络字节数等维度进行追踪 。HOTKEYS STOP:停止追踪。HOTKEYS GET:返回当前或最近一次追踪会话的结果,包括追踪元数据(开始时间、持续时间、采样比率等)、性能统计(CPU 时间、网络字节数)以及按指定指标排序的热 Key 列表 。
该功能在 Redis 集群模式下同样可用——每个分片主节点可独立追踪该分片的热 Key,对业务无侵入性、无需额外客户端配置。
优势:内核原生支持,无外部依赖,部署形态轻量简单;基于 CPU 周期和网络字节,度量维度全面;不依赖任何淘汰策略即可运行。
局限:目前仅提供“检测 + 查询”能力,没有配套的自动化治理机制(如自动缓存、自动熔断等);采样引擎本身会消耗额外的内存和 CPU 开销(默认约 2-3%)。
2.2.2 Valkey:离线探测 + 服务端辅助客户端缓存
Valkey 社区目前提供两种与热 Key 相关的机制:
- 离线热 Key 探测:通过
valkey-cli --hotkeys命令扫描实例中的所有 Key,结合 LFU 淘汰策略找出访问频率最高的那些。该命令仅当maxmemory-policy设置为 LFU 相关策略时可用,本质是运维排查工具,并非实时检测 。 - 服务端辅助客户端缓存(Server-Assisted Client-Side Caching):遵循 RESP3 协议实现,服务端记录客户端访问的 Key 集合,当 Key 发生写变更时主动推送 invalidation 消息。
CLIENT TRACKINGINFO命令可返回当前连接的跟踪状态信息 。
优势:--hotkeys无需额外部署;RESP3 客户端缓存命中后零网络开销。
局限:缺乏服务端原生实时热 Key 自动检测能力;客户端缓存要求 SDK 支持 RESP3 协议,侵入性较强。
2.2.3 JIMDB 现有机制:服务端实时检测与主动推送
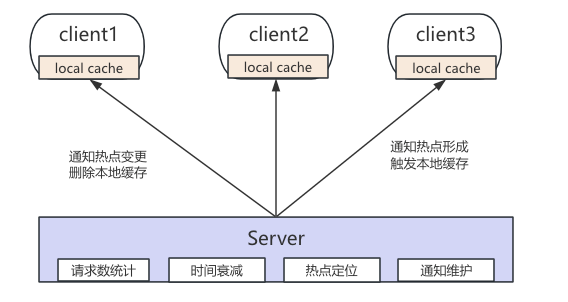
与前述方案不同,JIMDB 在存储引擎内部实现了一套完整的热 Key 实时检测与推送机制,不依赖外部代理或离线分析。其核心原理是:
- 引擎对每个 Key 维护访问计数器,基于滑动窗口(1 秒)+ OPS 阈值(可动态配置)实时判定热 Key;
- 通过自动衰减机制(定时任务周期性降低热度值)让热 Key 集合自动跟随流量变化,持续高访问的 Key 保持热度,访问回落的 Key 自然退出;
- 检测到热 Key 后,服务端通过双缓冲机制主动将热 Key 信息推送给订阅客户端,客户端据此建立本地缓存,将热 Key 请求从服务端卸载,形成"检测 → 推送 → 客户端缓存"的完整闭环。
优势:服务端拥有全局视角,能准确识别真正的热 Key;推送机制让所有客户端实例同步感知,避免各客户端独立统计的不一致问题;检测发生在命令执行路径上,延迟极低(毫秒级感知),阈值可按实例动态调整。
局限:极端的纯热Key场景(单Key数百万QPS),即使客户端缓存拦截了大部分请求,漏网的请求仍会因主线程单线程瓶颈导致导致 CPU打满,而且服务端客户端异步同步也可能有短时间不一致情况。这正是本文进一步引入 IO 线程旁路缓存的动因
2.3 差异性对比
| 方案 | 检测能力 | 治理层级 | 对客户端要求 | 核心优势 | 核心局限 |
| Redis 8.6 HOTKEYS | ✅ 实时,内核采样引擎 | 仅检测 | 无 | 原生多维检测,部署极简 | 无配套治理,纯查询工具 |
| Valkey --hotkeys | ⚠️ 离线,需 LFU | 仅检测 | 无 | 无额外依赖 | 离线快照,无法实时响应 |
| Redis/Valkey Client‑Side Caching | ❌ 无自动检测 | 客户端 | 需 RESP3 协议 | 命中后零网络开销 | 侵入性强,需客户端改造 |
| 阿里云 Tair | ✅ Proxy 层 | Proxy(服务端) | Proxy 缓存无要求;进程内缓存需自行集成 | 多层次治理,配置即用 | Proxy 有 TTL 不一致窗口(官方标注可能读到脏数据) |
| 腾讯云 CRS | ✅ API 级实时 | 应用层 | 需业务改造 | API 生态集成好 | 治理依赖应用层配合 |
| 华为云 GeminiDB | ✅ API 级实时 | 仅检测 | 无 | 存算分离缓解内存压力 | 治理能力薄弱 |
| JIMDB(现有) | ✅ 实时 | 服务端 + 客户端 | 客户端可选 | 覆盖大热 Key + 热 Key,自动化治理 | 纯热 Key 在服务端有单线程瓶颈 |
| JIMDB(本文) | ✅ 实时 | IO 线程 | 完全透明 | 服务端独立兜底,释放多核算力 | 仅针对 GET/HGET |
2.4 从外挂到内嵌:热 Key 治理的演进与 JIMDB 的定位
将上述方案放入热 Key 治理技术的演进脉络中审视,可以清晰地看到一条从“外部补救”到“内核自治”的发展轨迹。
第一代:离线排查与被动响应。以 Valkey--hotkeys为代表,依赖运维人员手动执行离线命令或查看监控面板来发现热 Key。发现问题后,通常只能通过垂直扩容、增加副本等粗粒度手段应对。这种方式响应慢、自动化程度低,在突发流量面前往往只能“事后止损”。
第二代:检测与治理分离。Redis 8.6HOTKEYS和华为云 GeminiDB 迈出了重要一步——将热 Key 检测能力原生集成到内核或控制台,实现了实时或准实时的精准识别。然而,它们止步于检测:HOTKEYS只输出排序列表,GeminiDB 只提供诊断面板,后续的缓存、限流等治理动作仍需用户自行实现。“识别到了问题,但解决不了问题”,治理闭环存在明显断层。
第三代:外挂式治理。阿里云 Tair 的 Proxy Query Cache 和 Redis/Valkey 的 Client-Side Caching 更进一步,不仅检测,还能自动缓存。但它们将治理能力放置在“外部”——Tair 依赖 Proxy 节点,Client-Side Caching 依赖客户端协议改造。这种外挂模式虽然有效,但引入了新的代价:Proxy 层的 TTL 不一致风险(可能读到脏数据),或者对客户端 SDK 的强侵入性要求(需 RESP3 协议)。
JIMDB 的定位:迈向内核自治。JIMDB 现有的服务端热 Key 机制已经实现了“检测→推送→客户端缓存”的闭环,比单纯检测方案更完整,比外挂方案更贴近内核。本文提出的 IO 线程旁路缓存方案,则是在此基础上的再进一步——当客户端缓存未能覆盖(版本老旧、未配置、或生效延迟)时,服务端 IO 线程独立完成热 Key 的短路响应。这一方案的核心价值在于:治理能力内嵌于存储引擎的 IO 路径中,对客户端完全透明,不依赖任何外部组件。在“性能‑一致性‑透明性”的三维权衡中,它为分布式缓存的热点治理提供了一种新的均衡解。
本章参考
阿里云.Tair 代理查询缓存功能介绍.https://help.aliyun.com/zh/redis/product-overview/features-of-proxy-nodes?spm=5176.26122959.console-base_help.dexternal.2cfb7aac5jWKiU#b7defbda8biry
腾讯云.查询实例热 Key .https://cloud.tencent.cn/document/product/239/38920 华为云.查询 Redis 实例的热 key.https://support.huaweicloud.com/intl/zh-cn/api-nosql/nosql_05_0058.html Redis Ltd.Redis 8.6 — What's New.https://redis.io/docs/latest/develop/whats-new/8-6/ Redis Ltd.HOTKEYS GET Command.https://redis.io/docs/latest/commands/hotkeys-get/ Valkey.io.CLIENT TRACKINGINFO Command.https://valkey.io/commands/client-trackinginfo/ DeepWiki.Valkey-go Client-Side Caching.https://deepwiki.com/valkey-io/valkey-go/5.2-client-side-caching
第三章 方案设计:IO 线程旁路缓存
3.1 短路思想:让主线程“不干活”
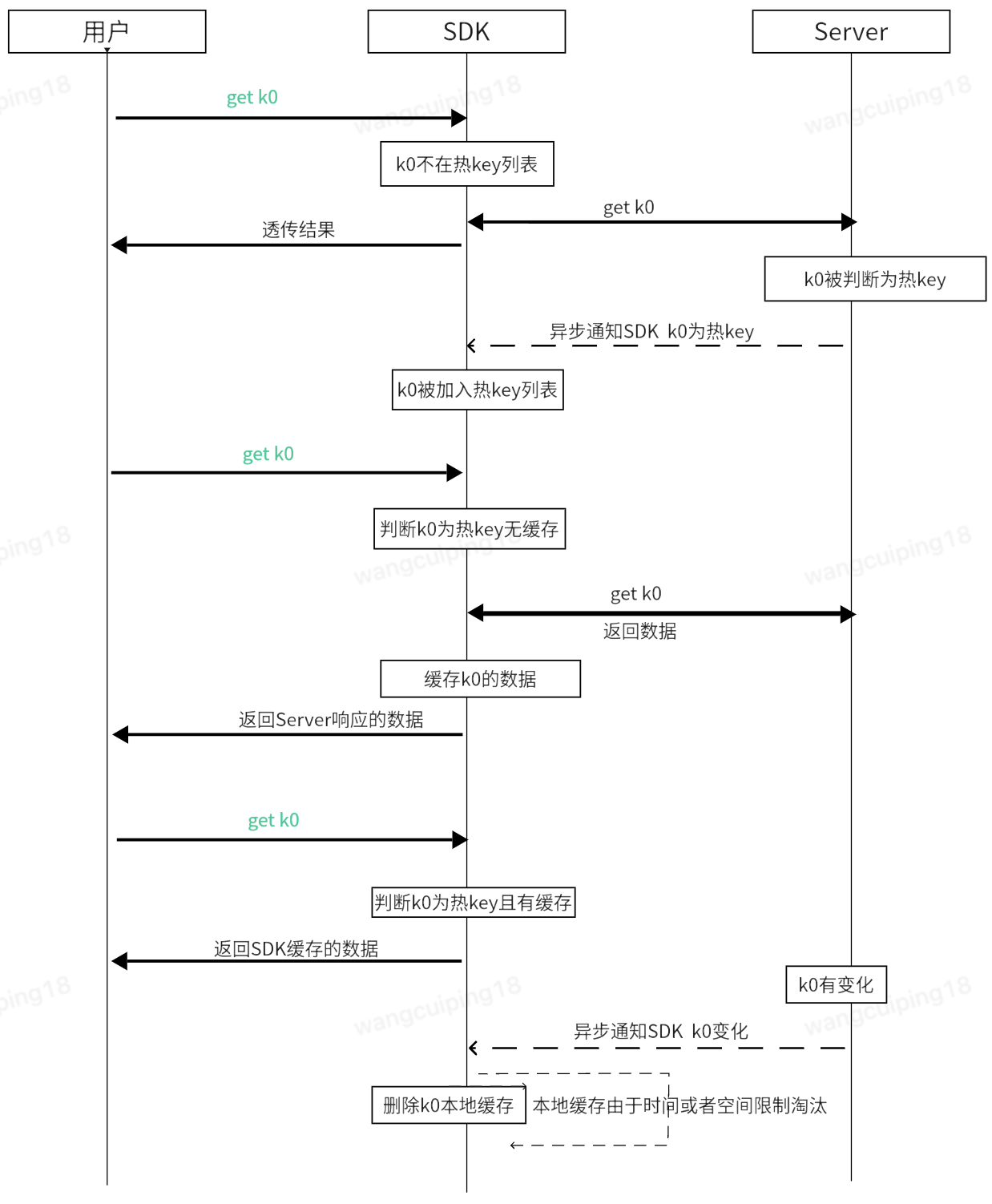
JIMDB 请求的传统生命周期如图 3 所示。每个请求从网络读取、协议解析、命令执行到响应写回,全部在主线程中串行完成。这条流水线在正常负载下运转良好,但当单一热 Key 的 QPS 达到数十万乃至百万级时,主线程的每微秒都被压榨殆尽——即便其他 CPU 核心完全空闲,系统吞吐也已触达物理天花板。
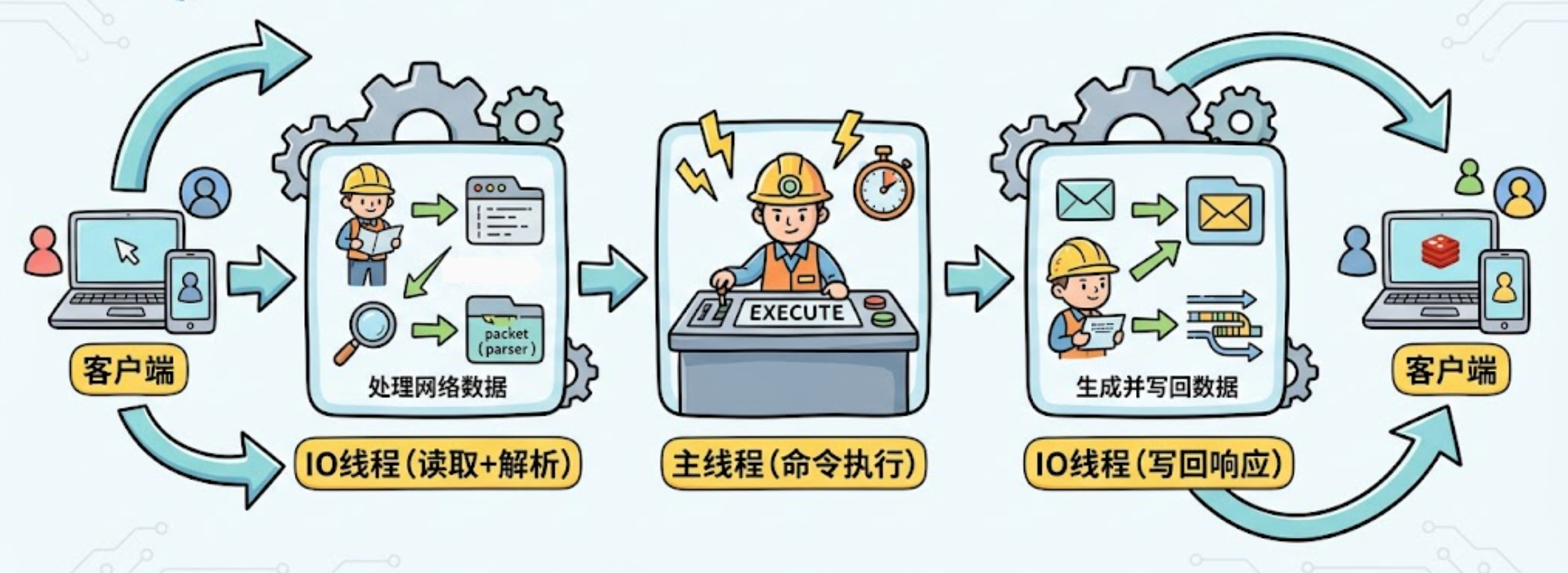
图3:JIMDB请求的传统生命周期
IO 线程旁路缓存的核心思想,就是在这条流水线上开一扇“快捷通道”。如图 4 所示,当 IO 线程完成协议解析后,并非一律将请求转交主线程,而是先做一次极速判断:当前命令是否为 GET 或 HGET?目标 Key 是否在热点缓存池中?
- 命中:IO 线程直接从缓存池取出预序列化的 RESP 响应字节流,拷贝至客户端输出缓冲区并立即返回。整个过程主线程零参与。
- 未命中:走传统路径,交由主线程正常执行
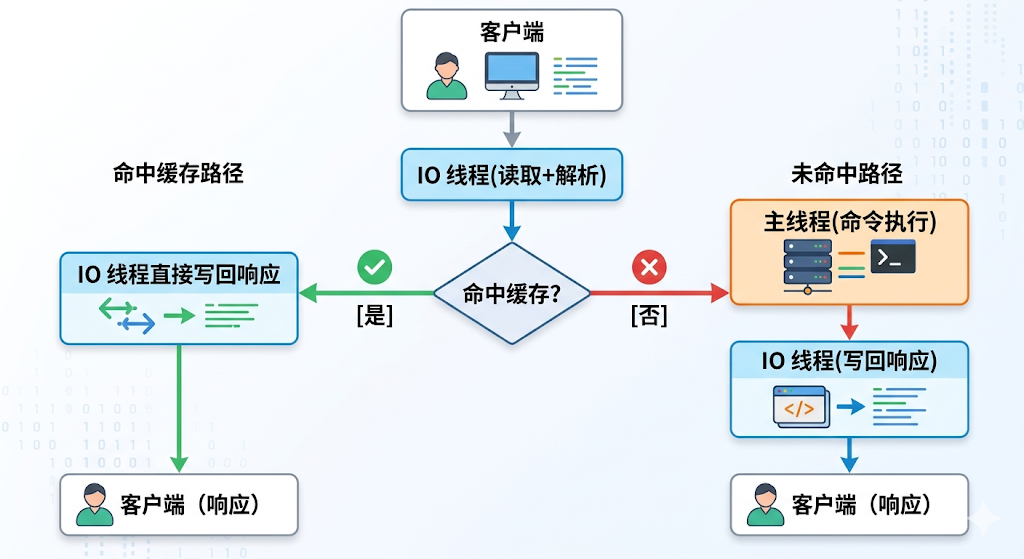
图4:IO线程旁路缓存流程
若当前命令为 GET 或 HGET,且目标 Key 位于热点缓存池,IO 线程就直接从内存中取出预生成的 RESP 响应字节流,拷贝至客户端缓冲区并返回。整个过程没有主线程参与,彻底解耦 CPU 资源。
3.2 预序列化:缓存字节流而非对象
要实现 IO 线程独立返回响应,缓存中存储的不能是原始数据对象,而必须是可以直接发送的字节流。因此,缓存条目是预序列化的 RESP 协议响应。例如 String Key 值为"hello",缓存中直接存储$5\r\nhello\r\n。
这意味着命中缓存时,IO 线程无需执行任何数据转换或协议编码——既不用将字符串对象重新序列化为 RESP 格式,也不用拼装协议头。它唯一要做的是一次内存拷贝,将这段字节流从缓存池复制到客户端的输出缓冲区。
一次memcpy的代价(微秒级)相比主线程完整执行命令路径(含锁竞争、键空间查找、数据序列化,数十至上百微秒)几乎可以忽略。这种方式既消除了序列化开销,又避免了主线程的竞争,将单次热点请求的 CPU 占用降到极低。
3.3 生命周期管理
整个缓存生命周期与数据同步紧密耦合:
- 写入:主线程在处理
GET/HGET时,若该 Key 已被实时检测标记为热 Key 但尚未缓存,则将该命令的响应预序列化后写入缓存池。 - 失效:所有写操作(
SET、DEL、HSET等)继续在主线程执行。主线程在变更数据后,同步清除该 Key 的缓存条目。若 Key 过期或被从热 Key 列表中淘汰,同样清除缓存。 - 一致性保证:由于缓存仅存储读操作的静态快照,写操作直接失效缓存,因此在任何时刻读到的数据都与最新写入保持一致,可达强一致性。
3.4 并发控制
多个 IO 线程与主线程共享缓存池,需解决并发读写冲突。方案采用 pthread_rwlock:
- 读锁:IO 线程查询缓存时持有读锁,允许多个线程并发读取,充分利用多核。
- 写锁:主线程更新或清理缓存条目时持有写锁,会短暂阻塞读操作。
热 Key 写频率远低于读频率,写锁几乎不存在竞争,实测性能损耗可忽略。
3.5 缓存容量与淘汰
缓存池设计为一个固定大小的哈希表(默认 127 个槽位),使用 Key 的 slot 哈希值定位起始位置,线性探测解决冲突。达到容量上限时,新条目会直接替换同一起始位置的老条目。设计依据:
- 线上同一时刻热 Key 数量通常不超过几十个,127 槽位充裕,且符合蝉的哲学。
- 固定数组避免动态内存分配,查找路径极短,且限制单条目大小(绕过过大 Value,交由大热 Key 异步序列化处理),防止槽位被个别大 Key 占据。
第四章 效果验证:从 139 万到 552 万的跨越
4.1 测试条件
- 硬件环境:8核 JDOS AMD EPYC 7H12 64-Core Processor
- 压力模型:单实例、单热点 Key、纯
GET命令。 - 对比组:优化前(基线版本,无旁路缓存),优化后(开启 IO 线程旁路缓存)。
4.2 吞吐量
4.2.1极限Pipeline场景
为验证 IO 线程旁路缓存在极端热点下的性能上限,我们在 Pipeline 模式下对单一热 Key 进行极限压测,结果如下表所示:
| 测试场景 | 基准版本 (OPS) | 优化版本 (OPS) | 性能变化 | CPU 变化 |
| 单一热 Key,命中 IO 缓存 | 1,394,018 | 5,518,589 | ↑ 295% | ↓ 25%(400% → 300%) |
| 单一热 Key,命中主线程缓存 | 1,302,383 | 1,620,807 | ↑ 24% | 持平(400%) |
| 10000 Key 并发,未命中,无热 Key | — | 1,325,495 | ↑ 2%(基本持平) | 持平(400%) |
命中 IO 缓存是本方案的最佳路径。Pipeline 模式下请求密集排队,IO 线程的多核并行优势被充分释放:预序列化响应直接短路返回,主线程从高频读取路径中彻底解脱,吞吐量从 139 万飙升至 552 万,性能提升近 3 倍;同时 CPU 使用率从 400% 降至 300%,节省了 25% 的算力。这意味着在同等硬件成本下,单实例可扛住近 4 倍的热点流量。
命中主线程缓存时,跳过了数据查找和序列化,但仍需经过主线程调度与执行,性能提升 24%,幅度低于 IO 缓存路径。这验证了瓶颈的本质——不是数据访问慢,而是主线程“过手”本身就成了瓶颈。
未命中场景测试了 10000 个 Key 并发且不存在热 Key 的普通负载。优化版本与基准版本性能持平,说明旁路缓存的额外开销(缓存查找、热 Key 检测)在未命中路径上几乎可忽略,不会对正常业务造成性能退化。
4.2.2 模拟线上热key场景
为进一步验证方案在真实业务负载下的表现,我们模拟了线上热 Key 场景,使用ForceBot平台调用JIMDB JAVA SDK发起热Key请求,由客户端自动决策是否压缩成pipeline发送,逐步增加客户端并发线程数,观察吞吐与延迟的变化趋势:
| 客户端线程数 | TPS(最大/平均) 优化前 | TPS(最大/平均) 优化后 | TPS 最大提升 | TP50/TP99/TP999 优化前 | TP50/TP99/TP999 优化后 |
|---|---|---|---|---|---|
| 线程数10 | 656743 / 585159 | 808080 / 773707 | +32% | 1 / 2 / 3 | 1 / 1 / 3 |
| 线程数20 | 817924 / 700545 | 1266556 / 1112988 | +58% | 2 / 3 / 5 | 1 / 2 / 4 |
| 线程数40 | 920328 / 756476 | 1398520 / 1303256 | +72% | 3 / 5 / 8 | 2 / 3 / 6 |
| 线程数160 | 1009701 / 802769 | 2028061 / 1918015 | 138% | 11 / 17 / 36 | 5 / 9 / 30 |
| 线程数200 | 1003325 / 823748 | 2236669 / 2043855 | 148% | 15 / 25 / 48 | 6 / 16 / 41 |
| 线程数320 | 1026336 / 811967 | 2198305 / 2053355 | 152% | 22 / 36 / 61 | 8 / 37 / 62 |
第一,吞吐量大幅提升,且饱和度显著右移。优化前,TPS 在 160 线程即触达天花板(约 100 万),此后增至 320 线程几乎无增长——主线程已成为刚性瓶颈。优化后,TPS 在 200 线程才趋于平稳(约 224 万),且同等线程数下提升幅度随并发增大而愈发显著:10 线程时提升 23%,200 线程时提升 148%,320 线程时提升 152%。IO 线程短路响应彻底打破了主线程的单点限制,将系统吞吐上限翻了一番有余。
第二,中低并发下延迟全面下降,长尾收敛尤为明显。40 线程时,优化后 TP50 从 3ms 降至 2ms(↓33%),TP99 从 5ms 降至 3ms(↓40%),TP999 从 8ms 降至 6ms(↓25%);160 线程时,TP50 从 11ms 降至 5ms(↓55%),TP99 从 17ms 降至 9ms(↓47%),TP999 从 36ms 降至 30ms(↓17%)。说明在真实负载区间内(通常几十到上百线程),旁路缓存路径的延迟优势尤为突出。
第三,低并发也有正向收益。10 线程时,平均 TPS 从 58.5 万提升至 77.4 万(+32%),TP999 持平于 3ms,TP50 和 TP99 均有 1ms 的改善。表明即使客户端数量有限、请求密度不足以触发 Pipeline 批量收益,IO 线程的直接短路响应依然能带来提速,且稳定性不受影响。
第四,极端高并发下延迟持平,但吞吐翻倍。320 线程时,优化后的 TP99 和 TP999 与优化前基本持平(甚至 TP999 略升 1ms),但这是在吞吐量翻倍的背景下得到的——优化前用 22ms 的 TP50 扛住 100 万 TPS,优化后用 8ms 的 TP50 扛住 220 万 TPS。单位延迟的吞吐产出提升了约 3 倍。
4.3 线上效果
开启该特性后,即便大量客户端未配置本地缓存或 SDK 版本较老,热点实例的 CPU 使用率仍出现显著下降。我们选取了部分热 Key 高发集群,对比升级前后的 CPU 指标与单核吞吐能力,结果如图 5 所示。
图 5 左展示了升级前后各集群的 CPU 使用率对比:升级后集群 CPU 使用率普遍大幅回落,峰值压力得到明显缓解。图 5 右则展示升级后各集群每颗 CPU 核心平均承载的 OPS:在 CPU 整体使用率降低的同时,单核 OPS 反而更高,说明单位算力产出明显提升——这正是短路径将高频读取从主线程卸载至 IO 线程后,多核效能被充分释放的结果。
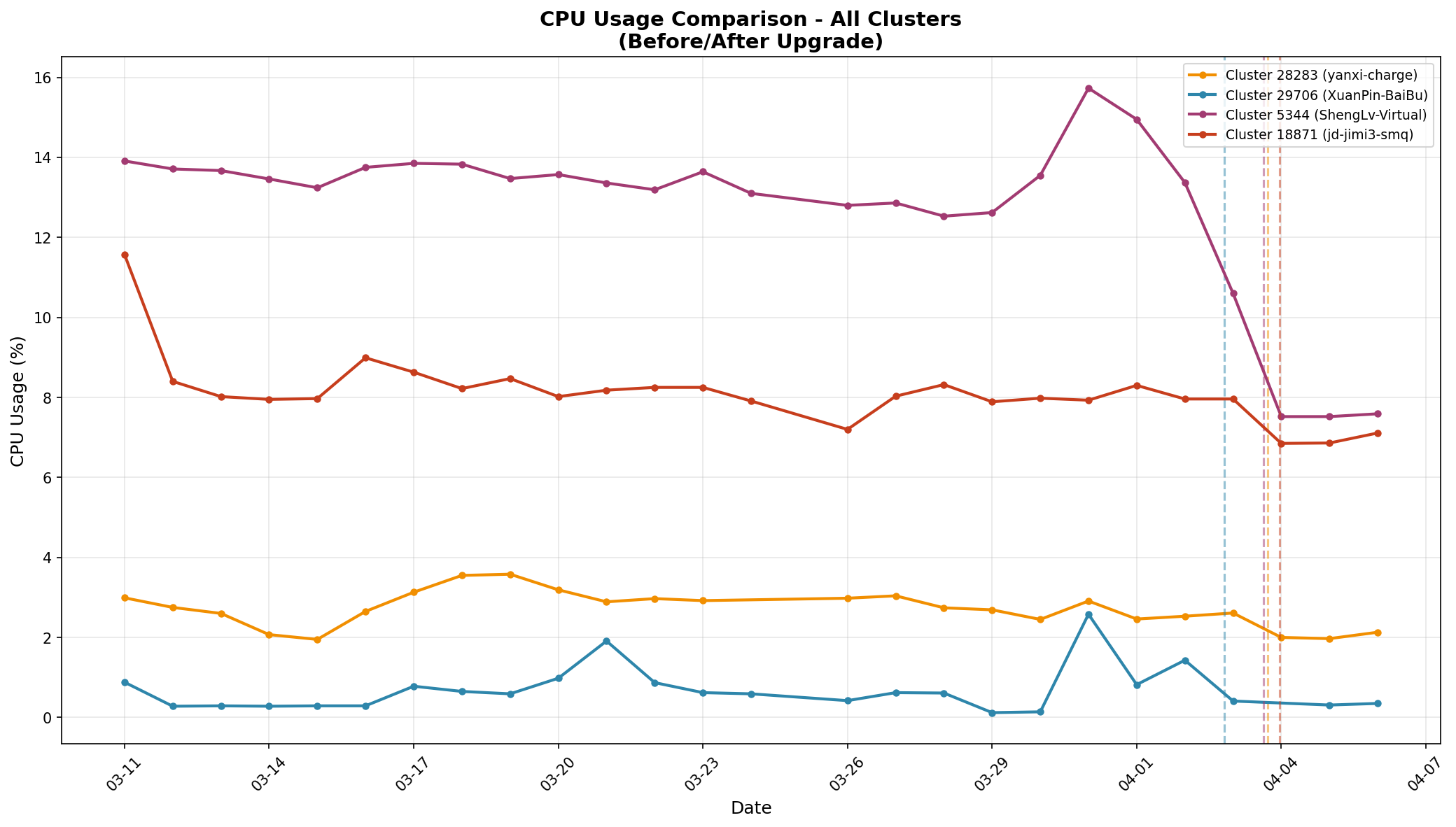
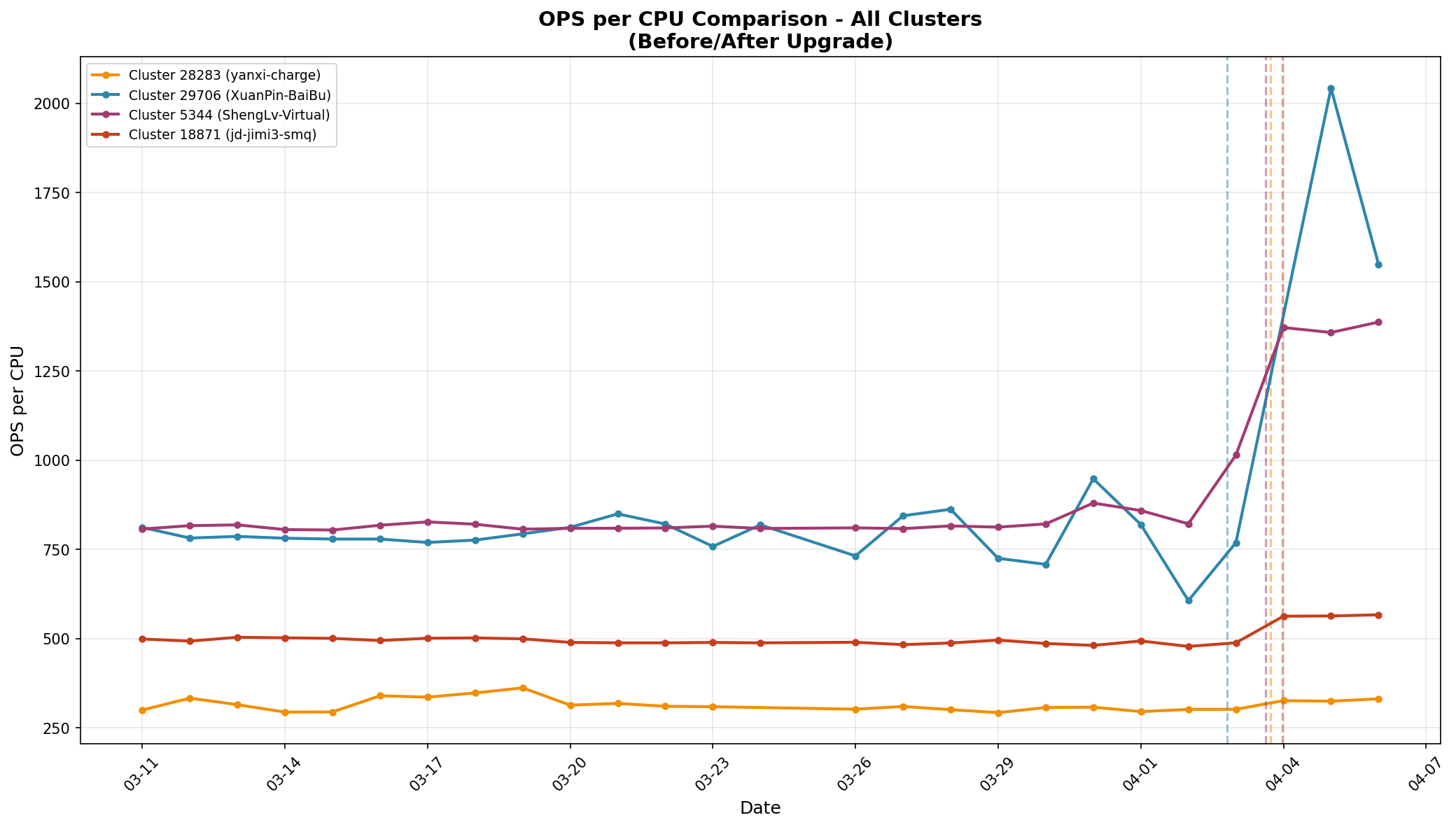
图5:升级前后性能对比
这一结论在更细粒度的线程级统计中得到了进一步印证。图6是某集群实例升级一周内不同线程统计的命中热Key缓存数量,其中io_threads_0是主线程,其余三个线程为IO线程。数据显示,每个 IO 线程平均命中 4000 万+ 次,而主线程仅命中 121 万+ 次——IO 线程承担了超过 99% 的热点请求短路响应。

图6:IO线程命中热Key缓存统计
主线程与 IO 线程命中量两个数量级的差距,直观地验证了旁路缓存的设计初衷:热点请求在 IO 层即被拦截返回,主线程几乎不再参与高频读取路径。这不仅解释了 CPU 使用率下降的根因,也说明方案在实际生产环境中真正实现了“让主线程不干活”的目标——不是把活从主线程挪到另一个单点,而是将压力均匀分散到多个 IO 线程上,化单核瓶颈为多核均摊。
第五章 总结与展望
5.1 热 Key 治理的完整拼图
经过多轮迭代,JIMDB 在热点流量治理领域已形成三层纵深防御体系:
| 层级 | 方案 | 应对场景 | 核心特点 |
|---|---|---|---|
| 客户端 | 热 Key 本地缓存 + 版本号校验 | 一切读热点(Value 任意大小) | 效果最佳,需 SDK 配合,一致性可控 |
| IO 线程 | 旁路缓存(本文方案) | 纯热 Key(高 OPS、低带宽) | 完全透明,释放多核算力,服务端独抗 |
| 主线程 | 大热 Key 异步序列化缓存 | 大热 Key(高 OPS、高带宽) | 解耦序列化开销,避免 CPU 打满与 OOM |
三层协同,使得 JIMDB 能在各种热点形态下自动选择最优治理路径,真正实现从“被动救火”到“主动防御”的跨越。具体而言:
- 可能引发 OOM 的大热 Key:通过大热 Key 实时识别 + 异步序列化缓存,将昂贵的遍历和编码从主线程剥离,CPU 和内存风险一并化解。
- 高 OPS 低带宽的纯热 Key:通过本文的 IO 线程旁路缓存,跳过主线程直接短路返回,服务端即使无客户端配合也能独立扛住极端读压力。
不过,仍有一类风险尚未被现有体系完全覆盖——极端的超大 Key。这类 Key 单次请求即可造成主线程长时间阻塞(例如对一个百万元素的集合执行HGETALL),而大热 Key 的识别引擎需要第一次请求完成后才能判定,存在“首请求盲区”。针对这一遗留问题,JIMDB 后续计划推出Top Key 实时统计能力,在写入阶段即对 Key 的数据规模进行实时统计与标记,结合已有的熔断能力,将超大 Key 的风险拦截在首次读请求到来之前。届时,JIMDB 将完整覆盖“大 Key 一次性阻塞 → 大热 Key 高频阻塞 → 纯热 Key 高频瓶颈”的全谱系热点风险,形成真正意义上的全维度异常流量自治闭环。
附录 JIMDB主流版本性能对比
目前线上主要有4个大版本JIMDB,如下,
| 版本号 | 底层基础版本 | 核心支持能力 |
|---|---|---|
| JIMDB-4.2.24 | 基于 Redis 2.8 | 支持无感迁移、版本升级 |
| JIMDB-4.3.0 | 基于 JIMDB-4.2 | 支持大热 key 识别、缓存、熔断等能力 |
| JIMDB-7.0.20 | 基于 Redis 8.2 | 支持异步 IO 线程;支持大热 key 识别、缓存、熔断 |
| JIMDB-7.0.21(本文) | 基于 JIMDB-7.0.20 | 新增支持热 key 旁路缓存 |
其中7.0.20以上版本有较大性能提升,且优化了内存占用,线上已升级集群平均内存占用下降10%,建议升级,升级请联系@wangqiwang1。
正常读流量
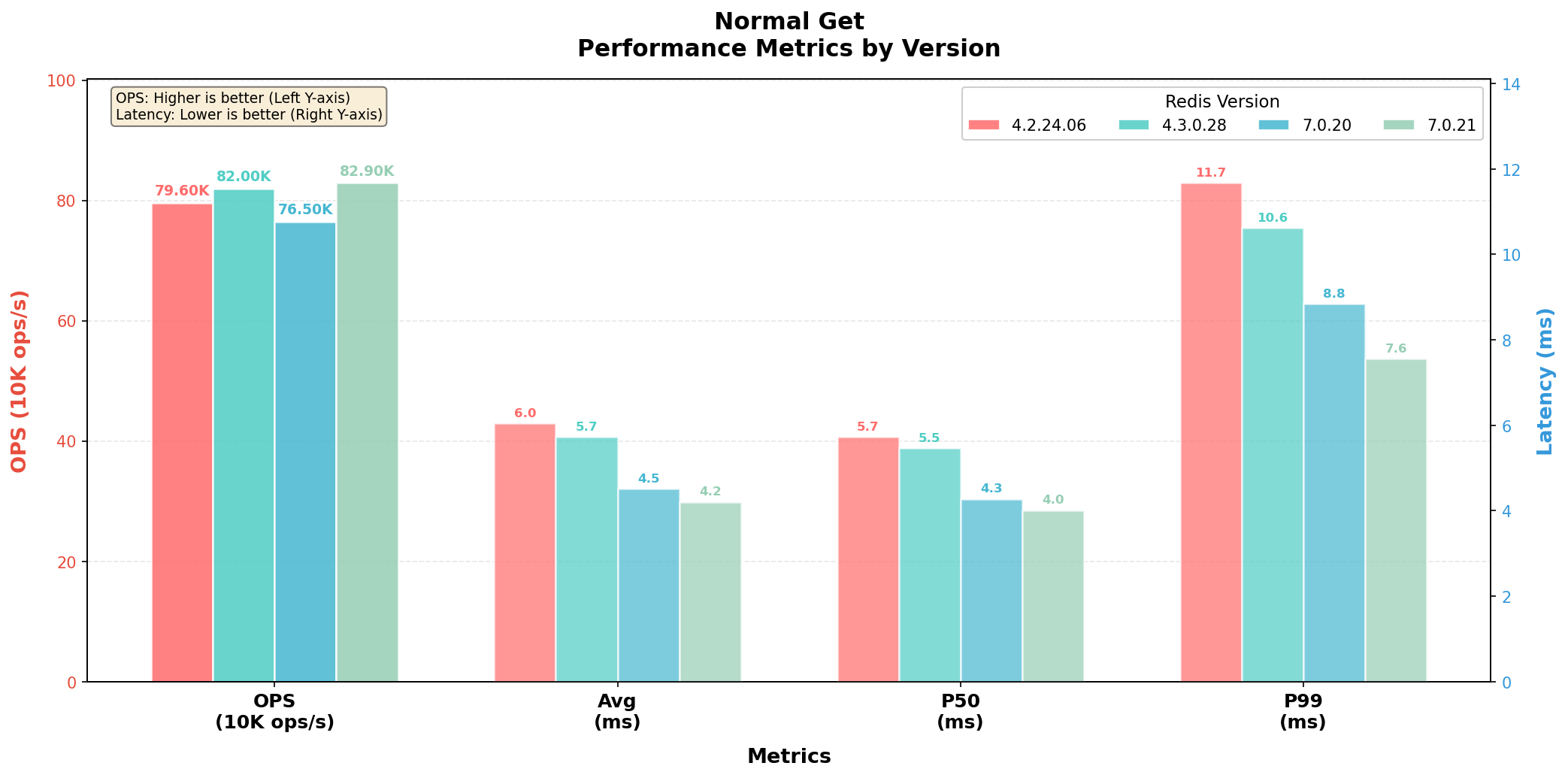
常规读流量场景,请求压力相差不大,但延迟分布呈现明显代际提升。基于 Redis 8.2 异步 IO 线程的 7.0.20/7.0.21,P95 延迟维持在 5.7~6.3ms,P99 约 7.6~8.8ms,全面优于 4.x 的 8.5~9.2ms 和 10.6~11.7ms,验证了异步 IO 架构在通用负载下的低延迟优势。
大热Key场景
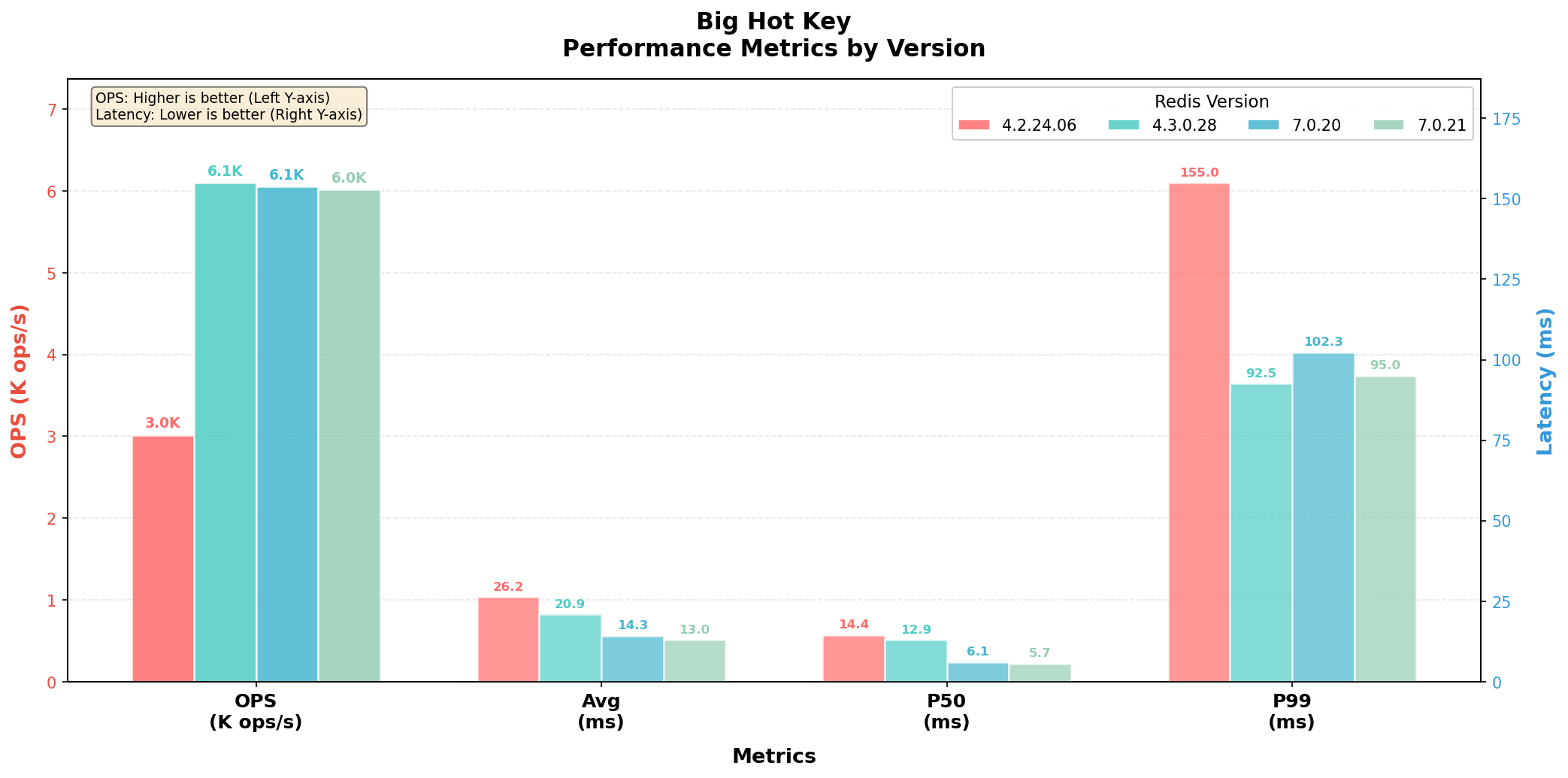
大热Key场景,JIMDB-4.2.24 因完全不具备大热 Key 识别与缓存能力,吞吐仅 3K OPS,P99 延迟高达 155ms,性能明显掉队。7.0.20 和 7.0.21 均继承了 4.3 引入的大热 key 缓存/熔断能力,吞吐稳定在 6K OPS 以上,时延大幅收敛,证明大热 key 防护能力已成为性能基线。
纯热Key场景
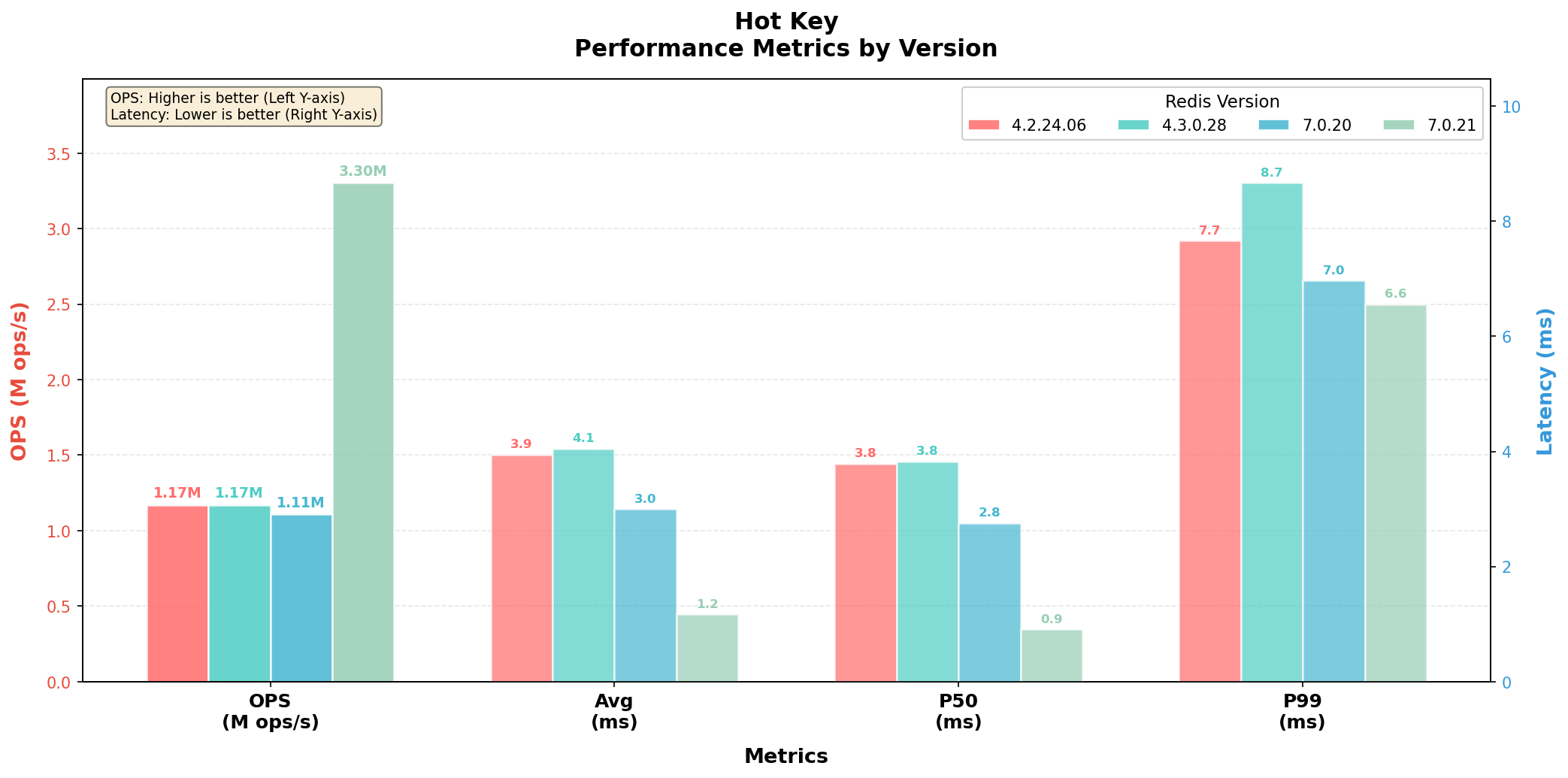
纯热Key场景,4.x 和 7.0.20 均无热 key 旁路缓存,吞吐在 110 万 rps 左右,延迟也处于同一量级。7.0.21 新增热 key 旁路缓存后,单热点 get 吞吐直接飙升至 330 万 rps,提升近 3 倍,平均延迟从约 3ms 降至 1.17ms,P95 从 4.3ms 压缩到 2.0ms,效果极为突出,实现了热点读场景的质变。
附录 JIMDB 7.0.21 vs Redis 8.2 实测对比
为更直观地佐证本文方案的工程价值,我们在相同硬件(4C20G 容器)与相同压测脚本下,对 JIMDB 7.0.21(启用 IO 线程旁路缓存) 与 社区 Redis 8.2 在两个典型场景中进行了端到端对比,结果如下两张图所示。
1)大热Key场景(Big Hot Key)
在大 Value、高 OPS 的混合负载下,主线程同时承担"序列化 + 调度"双重压力,最能体现 Redis 单线程模型的天花板:
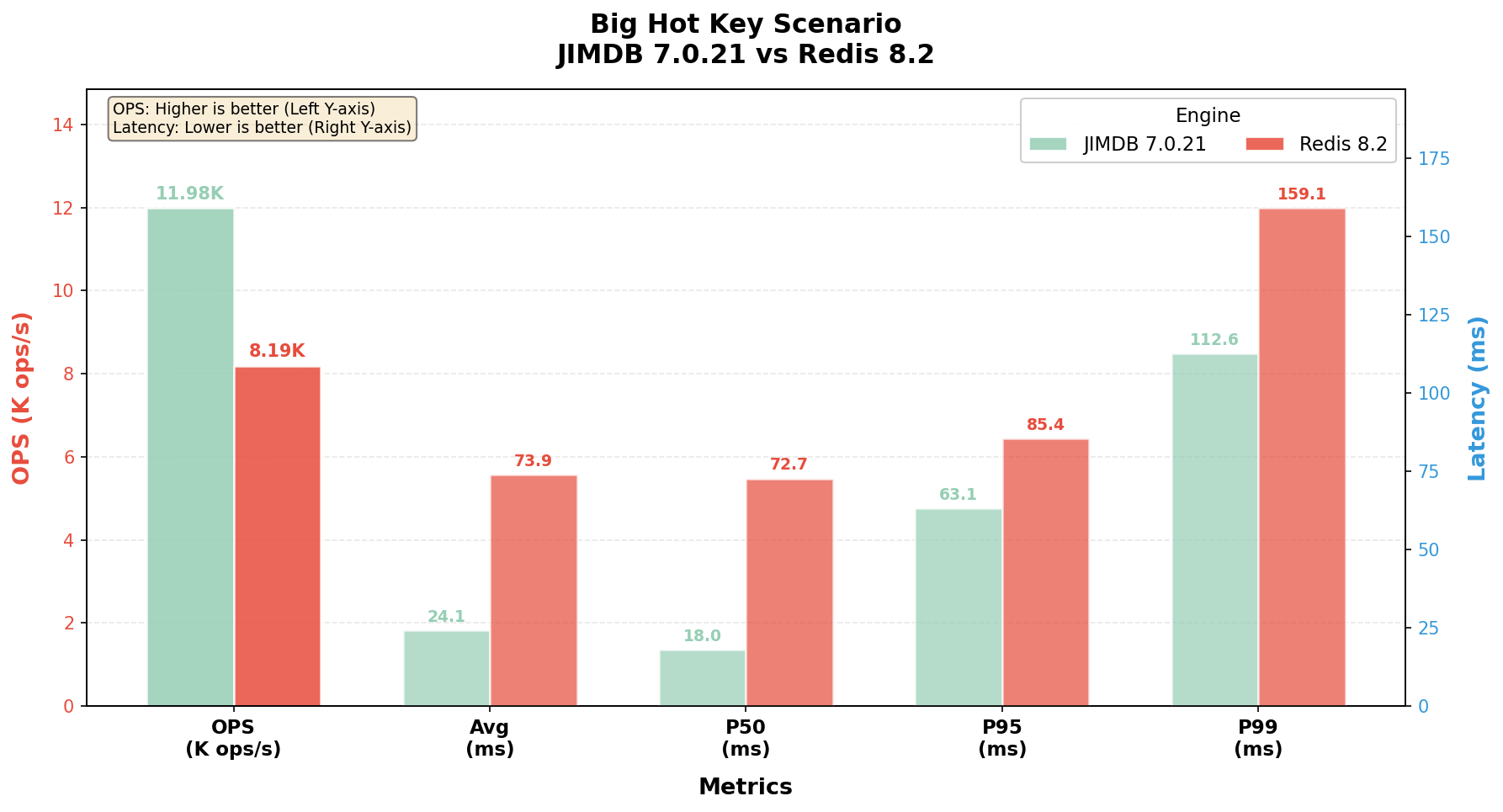
JIMDB 凭借"大热 Key 异步序列化缓存"机制,将昂贵的序列化与遍历从主线程剥离,相同 CPU 预算下吞吐提升约 1.46 倍,平均延迟仅为 Redis 的 1/3,P50 延迟更是降到 Redis 的 1/4。这正是第一章所述"用结果定义热度、主动治理"理念在大 Value 路径上的直接收益。
2)热 Key 场景(Hot Key,纯热点 GET)
在 Value 极小、QPS 极高的纯热点场景下,瓶颈从"序列化"彻底转移到"主线程事件循环"本身,这正是本文 IO 线程旁路缓存的主战场:
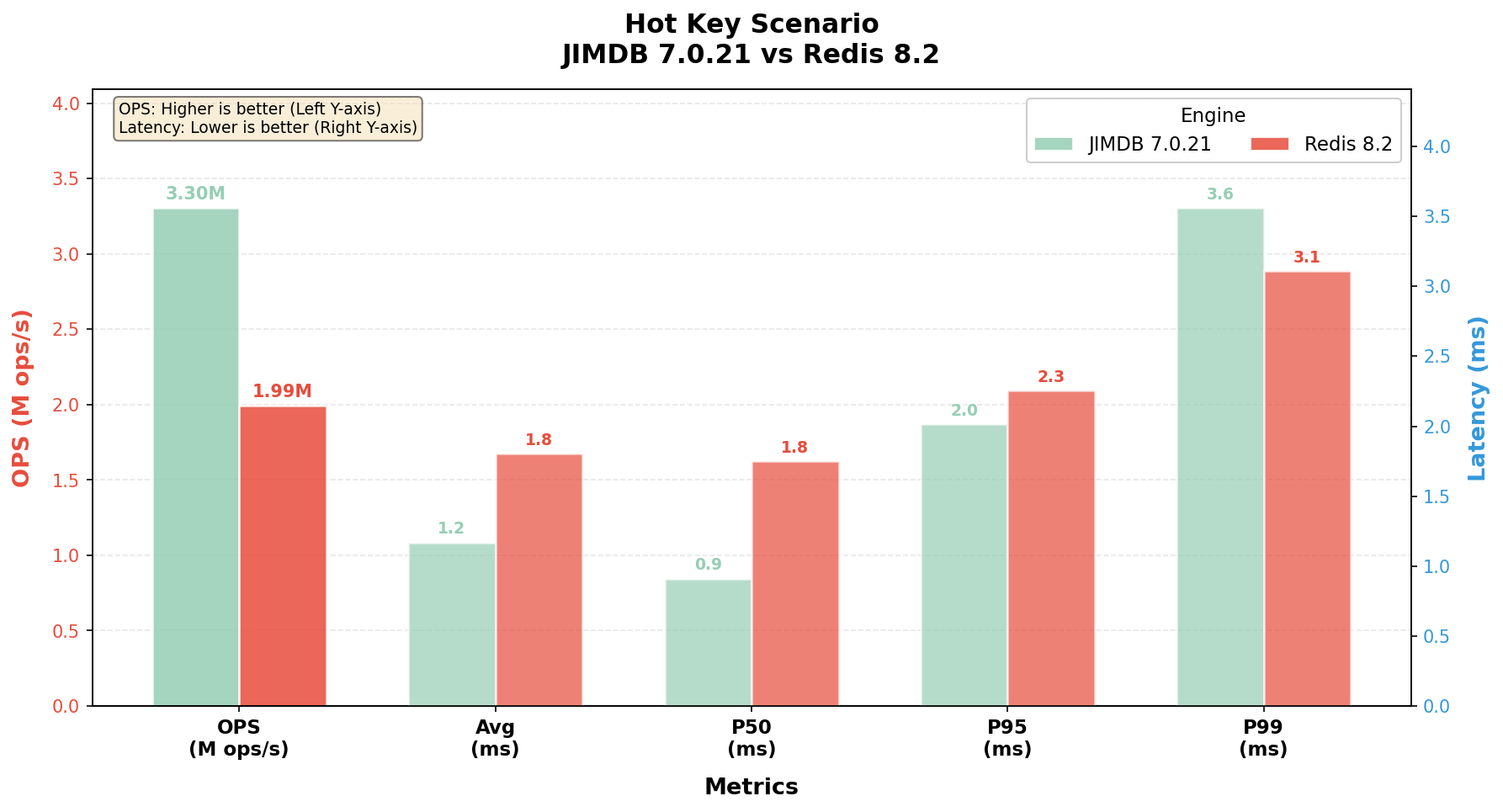
JIMDB 在纯热点路径上达到 330 万 OPS,相对 Redis 8.2 的 199 万 OPS 提升约 66%,P50 延迟降至亚毫秒级(0.91ms),约为 Redis 的一半。值得说明的是,P99 上 Redis 略优于 JIMDB(3.1ms vs 3.6ms),但考虑到 JIMDB 在同一时间窗口内多扛了 130 万 OPS 的额外吞吐,单位吞吐对应的尾延迟实际反而更优——即"在更高负载下保持了更低的平均与中位延迟"。
这意味着在同等硬件成本下,业务方无需任何代码改造,即可获得近 2 倍的热点抗压能力与显著更稳定的尾延迟表现,这正是"内核级透明治理"在超大规模分布式缓存中的独特价值。





