




论文链接: https://arxiv.org/abs/2602.23978 (已录用SIGIR2026)
1. 背景与挑战
1.1 业务背景
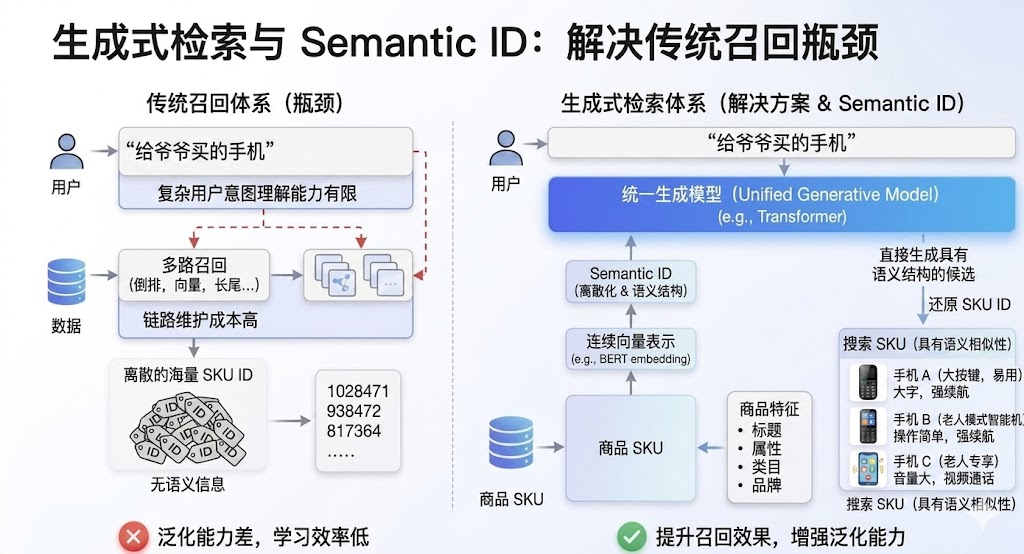
随着搜索场景中用户意图日益复杂,传统召回体系逐渐在表达能力、链路维护成本以及长尾商品覆盖能力等方面暴露出瓶颈。生成式检索的核心思路,是用统一的生成模型基于用户上下文直接生成候选 SKU,从而提升召回阶段对复杂语义的理解能力,并增强系统的统一建模与扩展能力。但生成式检索要解决的一个关键问题在于:模型需要“生成 SKU”,而原始 SKU ID 本身缺乏语义信息,直接对海量离散 ID 进行建模,不仅学习效率低,而且泛化能力有限。Semantic ID 的作用,正是将 SKU 的连续向量表示离散化为一组具有语义结构的 token,使商品能够以更适合生成模型学习的形式进行表示。这样一来,模型不仅能够更高效地建模商品空间,也能够在生成过程中更好地利用商品之间的语义相似性,从而提升召回效果与泛化能力。
1.2 技术挑战
搜索召回的核心,是根据用户 query 从海量商品中找出最相关的结果。与推荐任务相比,搜索更强调 query 与 item 之间的精确语义匹配,即系统能否准确理解用户的显式需求并完成高质量召回。基于此,搜索场景对 Semantic ID 提出了更高要求:同一 Semantic ID 下聚合的多个 SKU,应尽可能保持一致的 query 相关性;否则,当相关程度不同的商品被压缩到同一语义 ID 中,模型在生成 SID 后再映射回具体商品时,就容易引入“语义桶内噪声”,损害检索精度。这个问题在搜索中尤为突出,因为 query 的意图粒度天然存在明显差异,如“手机”“苹果手机”“苹果 17 Pro Max”到“苹果 17 Pro Max 2TB”,约束条件逐步收缩;若 Semantic ID 粒度不足,就容易将粗粒度相关性与细粒度精确匹配混合,进而影响结果准确性。因此,搜索场景下的 Semantic ID 设计应重点关注两点:一是增强不同 SKU 在 embedding 空间中的可分性,尤其要拉开标题、属性、规格等仅有细微差异商品之间的语义边界;二是提升 Semantic ID 向近似一对一映射逼近的能力,尽量减少多个 SKU 共享同一 ID 的情况,从而降低相关性不一致带来的干扰,提升检索精度与结果可控性。
2. 相关工作
SID目前大多围绕量化方法、防碰撞策略、引入协同信息/多模态信号、解决SID与模型训练两阶段目标不一致问题、长尾/泛化能力、可解释性与推理能力等方面展开。
量化方法方面,DSI使用层次化聚类生成文档的层次化ID,TIGER第一次引入RQ-VAE生成商品的语义ID,OneRec使用RQ- Kmeans获得语义ID,OneSearch针对最后一层的残差通过OPQ来编码商品的独立属性,DOS对embedding进行正交旋转以获得最佳向量方向,Qarm-v2使用FSQ获得更加均匀的编码。
针对不同商品编码的冲突问题,现有方法往往通过防碰撞策略或约束来解决。Tiger在SID的最后加一层随机token使得每个商品有独立的编码,Forge在SID的最后一层通过阈值限制同一SID下的商品数量,Onerec通过balanced kmeans算法缓解碰撞问题,SaviorRec通过sinkhorn算法强制SID均匀分配,LETTER、CAT-ID2等则通过多样性正则化、熵正则化等约束均匀化embedding分布。除此之外,商品碰撞可以分为合理的碰撞与不合理碰撞,quaSID通过区分碰撞类型来解决不合理的商品碰撞。
现有方法一般在embedding生成阶段或量化阶段实现协同信号引入或多模态信息融合, OneRec 通过真实u2i样本对预训练的多模态模型进行微调;为进一步增强不同模态之间的一致性,MME-SID采用对比学习来加强模态间的对齐与融合;MMQ 设计了一种多模态共享-特定tokenizer,在量化过程中引入了MOE架构,同时保留模态特定的codebook和共享codebook,由路由器对来自不同 codebook 的输出进行加权聚合;BBQRec 提出了一种行为对齐的多模态量化方法,以从多模态数据中提取与行为相关的信息。
SID量化的目标为向量在量化过程中的损失最小,与模型训练任务目标不一致,这种不一致性可能导致信息损失,为解决这一问题,现有方法通常将下游目标引入量化过程,或者在模型训练过程中,同时进行码本的更新,通过Gumbel-Softmax来实现梯度回传。
泛化能力方面,MTGRec通过从RQ-VAE训练过程中相邻epoch保存的多个模型checkpoint中提取不同版本的tokenizer,为同一商品生成多个语义相关但表达方式各异的token序列,提升冷门商品的曝光频率。
可解释性角度,目前的工作集中在sid2title、sid2cate等对齐任务上,例如谷歌的plum、腾讯的lc-rec、快手onerec-think等;推理能力角度,显式推理有onerec-think、onesearch-think,主要工作在于数据的构建,缺陷在于时延问题;隐式推理通常在推理SID之前首先推理若干个token,对齐不同目标,比如S2GR,在生成SID之前加入一个think token,让模型先在隐空间中预测一个粗粒度语义,再生成对应层级的 SID code。
以下列出了几个较主要的参考论文及其介绍。
| 论文 | 量化方法 | 降低碰撞率 | 协同信号 | 多模态 | 总结 |
| TIGER | RQ-VAE | ✅ | 基于语义信息,通过RQ-VAE得到层级化的语义ID,末尾添加额外token确保item的唯一性 | ||
| LETTER | RQ-VAE | ✅ | ✅ | 添加码本多样性正则化loss缓解冲突问题,添加协同正则化loss引入i2i协同信号 | |
| OneRec | RQ-Kmeans | ✅ | ✅ | ✅ | 基于Qformer构建多模态表征,并引入先验i2i协同信号,通过balanced kmeans缓解冲突问题 |
| FORGE | RQ-VAE | ✅ | ✅ | ✅ | 淘宝推荐在SID方面的实战经验:提出了两个防冲突策略,以及和召回效果正相关的评价指标 |
| OneSearch | RQ-OPQ | ✅ | ✅ | ✅ | 快手电商搜索场景的SID:通过表征对齐与核心关键词增强技术弱化冗余信息干扰,并通过对最后一层的残差进行OPQ来实现商品独特特征的编码 |
| cat-ID2 | RQ-VAE | ✅ | 通过类别约束、簇约束、分散损失三种约束使SID分布更加均匀 | ||
| MACRec | RQ-VAE | ✅ | 通过共享的量化结构对不同模态进行联合建模,并在量化过程中逐步引入跨模态对齐约束 | ||
| OneMall/QARM-V2 | RQ-Kmeans+FSQ | ✅ | ✅ | ✅ | 微调多模态大模型获得商品/短视频表征,并在最后一层引入FSQ,用更规则的码空间缓解ID冲突 |
针对 Semantic ID 构建中一对一、一对多映射关系及编码长度分布等关键问题,现有业内相关研究仍相对有限,仍是一个亟待深入探索的研究方向。
3. 核心方法
3.1 动机
在真实电商场景中,商品交互天然呈现严重的长尾分布:少量头部商品贡献了绝大部分用户行为,而大量尾部和冷启动商品交互极其稀疏。这种分布会给Semantic ID构建带来两个问题:一方面,头部sku过于密集,容易共享相同的 Semantic ID,产生ID collision,导致表示检索精度下降;另一方面,尾部sku数据稀疏,往往只能形成孤立的一对一映射,难以学习可泛化的语义结构,冷启动表现也会受限。
3.2 整体框架
针对于上述问题,我们提出了(Anchored Curriculum with Sequential Adaptive Quan- tization),旨在同时兼顾头部 SKU 的可区分性与尾部 SKU 的泛化能力。整体上包含两个核心模块:(Anchored Curriculum Residual Quantization)和(Sequential Adaptive Quantization),模型整体框架图如下所示。
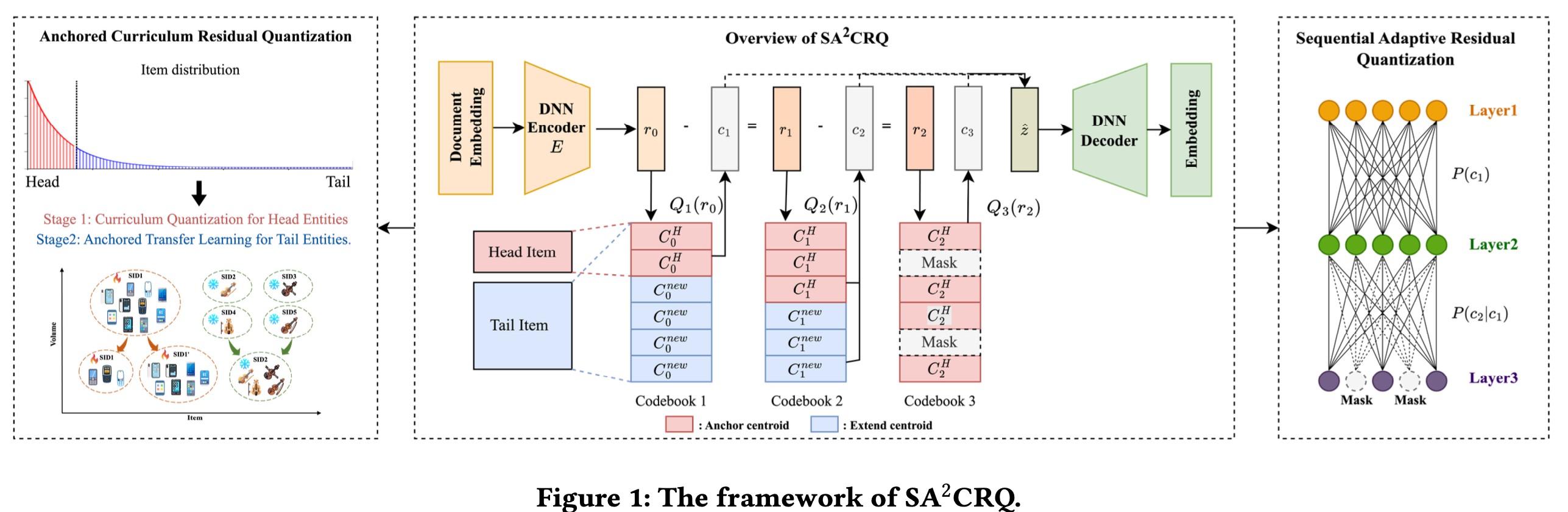
ACRQ的核心思想是:针对电商场景中普遍存在的长尾分布特征,先提升头部 SKU 的可区分性,再将头部 SKU 学到的稳定语义结构迁移到尾部 SKU 上,该模块整体分为两个阶段:第一阶段是Head Training,基于搜索点击日志筛选出头部 SKU,并为头部 SKU 分配更多的聚类中心,使头部商品能够获得更有区分性的 Semantic ID,从而缓解头部 SKU 之间的 ID collision 问题。第二阶段是Tail Training:在训练尾部 SKU 时,模型不再从零开始学习,而是将第一阶段学到的头部码本作为冻结的语义锚点,同时引入一部分可训练的新 codebook,为尾部 SKU 提供补充表达空间。这样尾部 SKU 既可以对齐到已有的头部语义结构,也可以在新增 codebook 中形成更适合自身分布的聚类结果。
SARQ的核心思想是:固定长度的 Semantic ID 难以同时兼顾头部商品的可区分性与尾部商品的泛化能力,因此可以为不同 SKU 自适应分配不同长度的 Semantic ID。具体而言,根据 SKU 在量化路径上的信息量,动态决定是否继续向更深层进行编码。为此,SARQ 会通过路径熵衡量当前 Semantic ID 路径的不确定性判断是否需要继续量化。对于交互充分、分布密集的头部 SKU,模型会倾向于分配更长的 Semantic ID,使其获得更细粒度、更有区分性的表达,从而缓解头部 SKU 之间的 ID collision;对于交互稀疏的尾部 SKU,模型会更早停止量化,生成更短、更具泛化性的 Semantic ID,使相似尾部 SKU 能够共享语义路径,避免过度拟合到孤立的一对一映射。SARQ 不再用固定长度的 ID 去表示所有 SKU,而是根据不同 SKU 的信息丰富程度,自适应地调整表达粒度。最终目标是让头部 SKU 更可区分、尾部 SKU 更可泛化,从而提升模型在下游任务上的表现。
3.3 实验结果
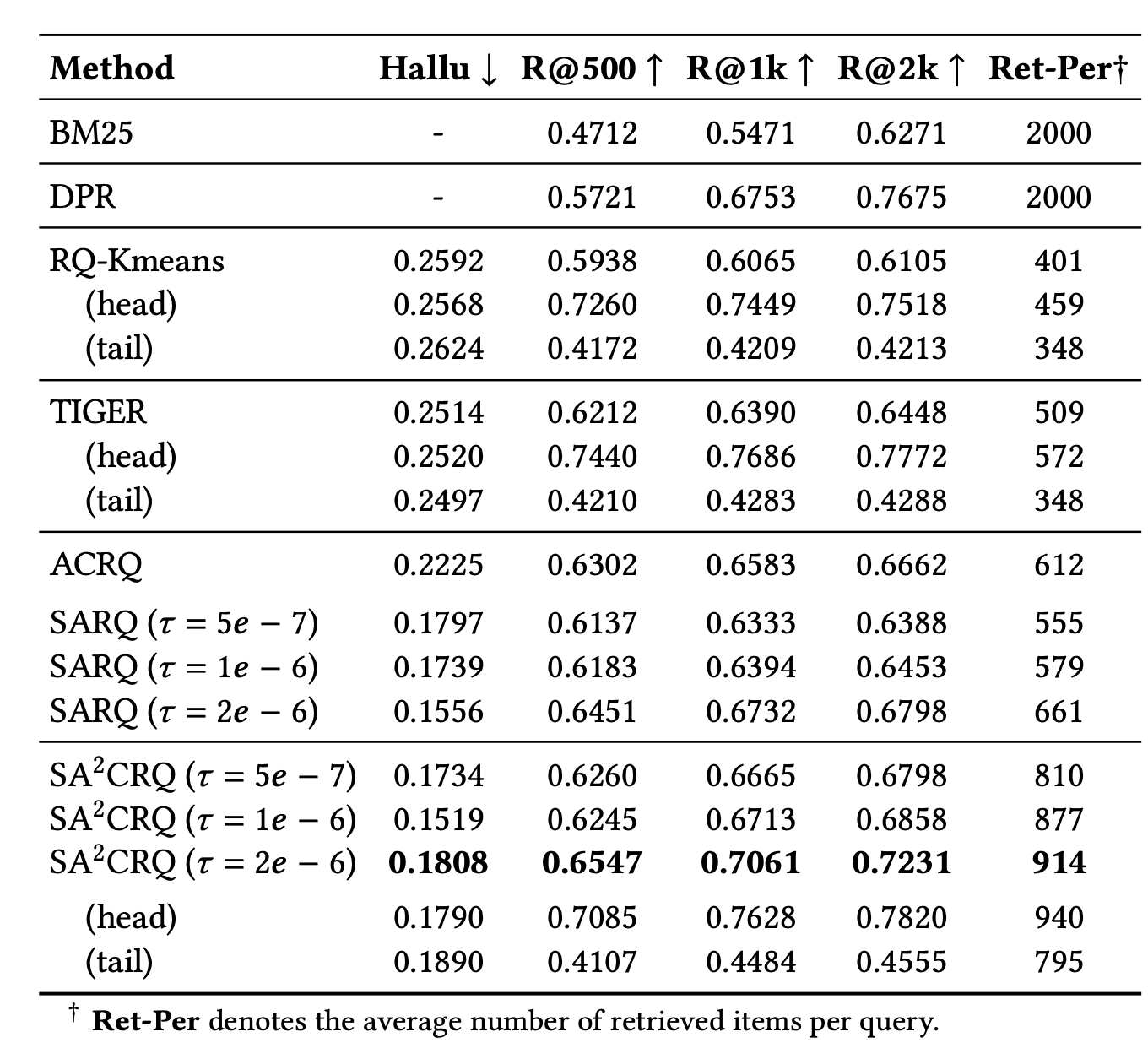
在京东大规模工业电商搜索数据集上,我们的方法在生成式检索任务中取得了最优表现。相比于TIGER,sku recall@k有明显提升,同时幻觉率也有明显下降。在线上A/B实验中,我们提出的方法在真实搜索流量上同样带来了稳定收益,其中UCVR提升0.13%,UV价值提升0.42%。目前,该方法已成功部署到生产系统,所训练的1.7B模型在单张NVDIA RTX 5090上可以达到30QPS、TP99约50ms的服务性能,进一步验证了该方法在工业级生成式搜索场景中的可落地性。
4. 线上落地实践
4.1 embedding
在 Semantic ID 构建中,embedding 承担着底层语义表达的作用,它将 SKU 的标题、核心属性等多源信息压缩为语义一致、可计算相似度的向量表示,为后续聚类和编码提供高质量输入。
4.1.1 embedding的输入特征
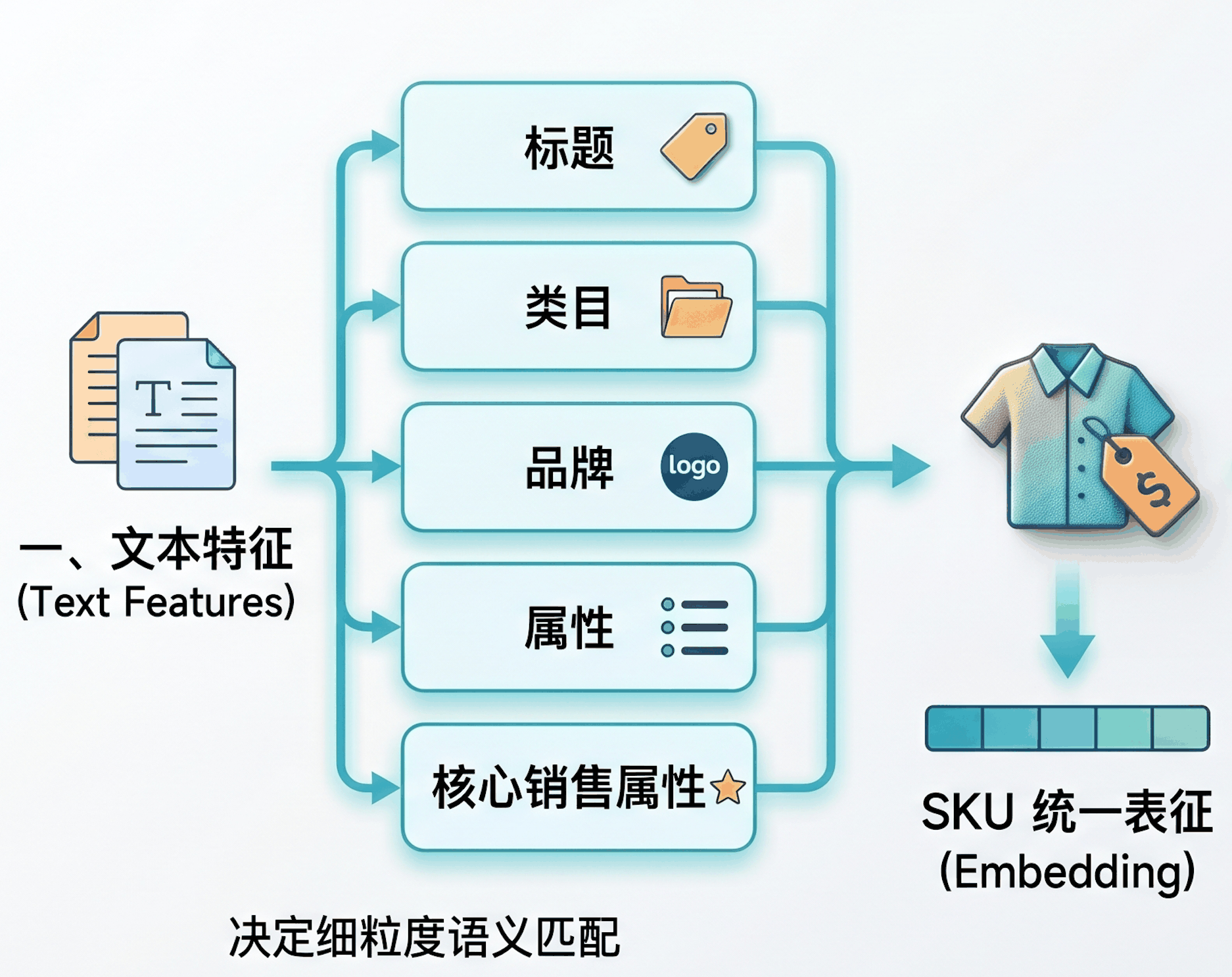
在 embedding 构建阶段,SKU 的输入特征通常主要包括文本特征与图像特征两类。其中,文本特征涵盖标题、类目、品牌、属性等。这些信息往往直接决定商品能否与用户 query 实现细粒度语义匹配。除文本外,图像特征也是重要补充。实际业务中,通常会选取一张或多张商品图片作为输入,用于捕捉文本特征难以完整表达的视觉信息,如外观样式、颜色、版型等。
在落地实践中,虽然图像表征在构建semantic id时具有一定辅助价值,但在我们的前期尝试中,直接使用图搜的多模态embedding,对下游任务的增益并不显著,考虑到计算资源与精力的投入产出比(ROI),我们认为现阶段针对 SKU 标题等文本信息的优化性价比更高,因此将重心放在了增强 SKU 的文本语义表示上。具体而言,我们在 embedding 构建阶段融入了更丰富的文本信息,并结合纯语义 embedding 模型对商品进行统一表征,使模型能够更充分地刻画 SKU 在标题、类目、品牌及核心销售属性上的细粒度差异。更强的文本表征能力使不同 SKU,尤其是头部高频相似 SKU 之间,形成了更清晰的语义边界,从而降低了它们在 Semantic ID 构建过程中发生冲突的概率,并进一步减少多个 SKU 共享同一语义编码所带来的桶内噪声。整体来看,这一实践表明,在搜索场景下,围绕文本语义做深做细,能够以较低的系统复杂度有效提升 Semantic ID 的区分性、稳定性与可控性,并为后续生成式检索的线上效果提升奠定基础。
4.1.2 embedding模型
在 embedding 模型选择上,通常可分为通用开源模型和面向业务微调的模型两类。前者主要提供较强的通用语义表示能力,典型如 BGE-M3、Qwen-Embedding、Youtu-Embedding 等;后者则更强调与具体业务目标的对齐。在 Semantic ID 场景中,微调模型的核心价值在于利用点击、加购、购买、共现、共购等行为信号优化 item embedding,使其在具备通用语义表达能力的同时,更准确地刻画搜索相关性、推荐协同性及商品间的细粒度差异。例如,query-item 双塔模型可基于用户反馈日志构造正负样本进行训练,使 query 与相关 item 在向量空间中更接近;多模态 embedding 模型则进一步融合文本与图像信息,以增强商品表示的完整性。
在 embedding 模型的选型上,我们的实践经验表明,开源模型方案各具特色,最终效果高度依赖于具体的业务场景。由于搜索场景天然受到用户 Query 语义的强约束,相比于召回场景中包含协同信号的 KNN 模型,纯语义 embedding 模型往往能展现出更强的区分度,其产出的表征在 SKU 间具有更显著的语义边界。此外,我们还尝试使用了搜索相关性模型的表征,在实际的下游生成式检索任务中,其表现仍逊于纯语义模型。因此,在搜索 Semantic ID 的构建中,优先选择纯语义 embedding 模型通常是更为稳健的起点。
在后处理方案的探索中,尽管我们参考了业界先进的 ORQ 思想并尝试了白化(Whitening)手段,但实践发现,这些方法对最终码字分布的改善并不显著。相比之下,通过 PCA 将 embedding 映射到更低维度展现出了极佳的效果。这种降维过程实质上起到了空间规整与特征去噪的作用,它能够剔除语义空间中的冗余信息,从而显著放大 SKU 之间的相对差异。实验表明,随着 PCA 维度的适当降低,embedding 的区分度得到进一步增强,确保了生成的 Semantic ID 更趋向于理想的“一对一”映射,
4.2 构建方法
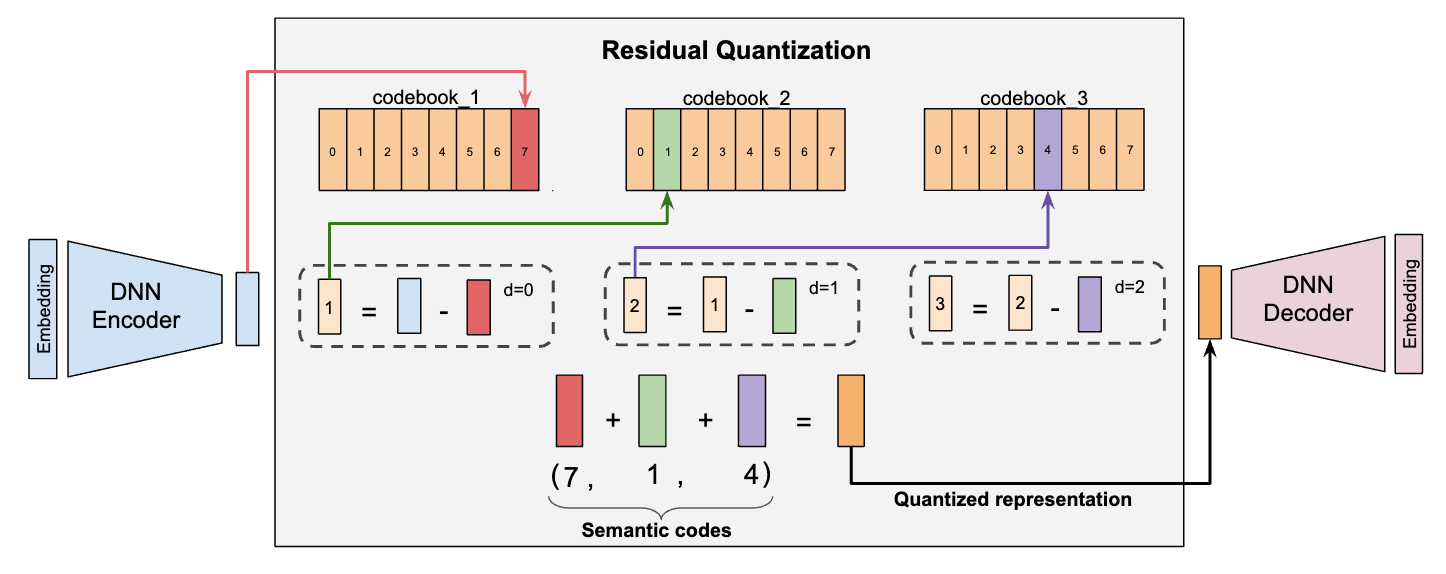
在 Semantic ID 构建中,常见的一类方法是基于残差量化(Residual Quantization)的层级离散编码。RQ-KMeans 就是其中的典型代表,它通过多轮聚类逐步编码前一轮尚未表示的残差信息,从而把高维 embedding 压缩为一组具有层次结构的离散编码;RQ-VAE 则进一步将残差量化与变分自编码器结合起来,在学习连续隐空间表示的同时,逐级量化残差并生成多层离散 token,因此适合用于构建层级化的 Semantic ID。基于这类方法,后续又发展出一些融合式改进方案。例如,RQ-OPQ 试图同时兼顾层次语义建模和细粒度信息保留:传统的 RQ-VAE 或 RQ-KMeans 更擅长提取相似商品共享的语义特征,但容易忽略每个 item 独有的细节属性;而 OPQ 虽然更有利于保留整体信息,却不擅长形成清晰的层次化语义结构。因此,RQ-OPQ 将二者结合起来,先利用 RQ-KMeans 建模商品的层次语义,再用 OPQ 对残差中的独特特征进行补充编码。与之类似,RQ-FSQ 的核心思路是前几层继续采用残差 K-Means 保留商品的层次语义信息,而在最后一层引入 FSQ 对残差进行量化,以减少 code 冲突并提升离散编码的稳定性。
4.3 评估方式
4.3.1 分布评估
- 独立编码率( Independent Coding Rate , ICR):在最终码表分布中,仅映射到单个 SKU 的 Semantic ID 数量,占全部 Semantic ID 数量的比例。
- 码本利用率( Codebook Utilization Rate ,CUR):衡量最终码本中有多少编码被实际使用,反映离散编码空间是否被充分利用。通常分层计算,计算每一层的码本利用率。
- 平均数、中位数、分位数:平均数、中位数和分位数用于描述每个 Semantic ID 下 SKU 数量的整体分布情况,其中平均数反映总体水平,分位数则用于刻画分布的离散程度和长尾特征。通常会看90分位数到999分位数的分布来看头部的一对多现象。
4.3.2 同品率与相关性不一致率
- 同品率:基于人工标注或工具辅助标注的同品 SKU 样本进行评估,可从两个角度计算:一是从 SKU 角度观察同品 SKU 是否聚合到同一个 SID;二是从 SID 角度观察同一 SID 下的 SKU 是否主要由同品商品构成。
- 相关性不一致率:基于(query, item)相关性对,并结合相关性模型的打分结果进行计算,用于衡量同一 SID 下不同 SKU 在相同 query 下的相关性档位是否一致;不一致比例越高,说明该 SID 内部的搜索相关性一致性越差。
4.3.3 熵与基尼系数
作用:熵和基尼系数通常按 Semantic ID 的不同层级分别统计,用于衡量各层编码分布是否均匀,以及码本利用是否存在过度集中现象。
- 熵:熵高说明这一层各个编码使用得比较均衡;熵低说明这一层各个编码分布比较集中,存在聚集现象
- 基尼系数:基尼系数越低,说明这一层分布更均匀;基尼系数越高,说明这一层分布不均衡
4.3.4 下游任务
为了验证 Semantic ID 的有效性,我们进一步将其接入下游生成式检索任务,观察模型是否能更准确地召回目标 SKU。具体指标包括SKU Recall、SID Recall 和 SKU MRR等,分别从真实商品召回、Semantic ID 生成准确性以及目标 SKU 排序质量等多个角度衡量效果。
4.3.5 小结
在线实践中,我们对 Semantic ID 的评估遵循“以下游效果为主,以上游分布分析为辅”的原则。其中,最核心的仍然是下游生成式检索任务上的 Recall 指标,因为 Semantic ID 的价值最终需要通过真实召回效果来验证。考虑到不同编码方案的码分布存在差异,为了尽可能公平地比较不同方法的能力,我们通常会适当放大 beam size,并以 SKU Recall@K 作为最主要的下游评价指标,直接衡量模型对目标商品的召回能力。在此基础上,我们还会结合一系列分布指标对编码质量进行分析:例如,平均数、ICR 和高分位数主要用于刻画 Semantic ID 到 SKU 的映射分布,分别反映整体的一对多水平、独立编码占比,以及头部 SKU 是否存在明显聚集现象;进一步地,我们还会观察同品率和相关性不一致率,评估同一 SID 内商品在一致性和搜索相关性上的稳定程度;同时结合 熵 和 基尼系数,分析各层码本的使用是否均衡、是否存在过度集中。






