



1 前言
2025年,虚拟试衣已成为电商行业不可或缺的核心环节,从技术落地到商业变现,全行业都在加速布局这一赛道。什么是虚拟试衣?其背后的核心技术方案有哪些?国内外电商大厂又有哪些典型实践案例?如何突破技术瓶颈,打造更贴合用户需求的试穿体验?电商平台又该如何构建完整的AIGC能力矩阵?
本文分享将基于京东零售视觉与AIGC部负责人李岩(Jason Li)博士在AICon2025的演讲内容整理呈现,深度拆解虚拟试衣的技术逻辑、行业实践与未来趋势,解锁电商AIGC的全域布局思路。

内容围绕以下板块展开:首先解析虚拟试穿的定义与分类;其次回顾虚拟试穿的技术发展历程;随后深度拆解行业内主流虚拟试衣产品的核心能力;再介绍京东在虚拟试穿领域的探索及实践沉淀的实践经验;在此基础上,分享京东零售AIGC布局的全景图;最后探讨虚拟试衣及电商AIGC行业的未来发展趋势。

2 虚拟试穿的定义与分类


虚拟试穿的底层逻辑可概括为A+B=AB,其中A指模特的图片或视频,B则是服饰图。通过视觉生成技术将服饰“穿”到模特身上,最终以静态或动态效果呈现给用户,核心要求是保证模特与服饰的关键信息不被破坏、不被篡改。
从不同维度划分,虚拟试穿可分为以下类别:

首先,从服饰呈现形式来看分类。服饰的素材形态主要有三种:一是平铺的白底服饰图,二是真人模特上身的服饰图,三是假人台模特上身的服饰图。
其次,以服饰数量为划分标准,这一类可以分为单件服饰和多件服饰两类。单件服饰涵盖上装、下装、长款连衣裙以及单件内衣等;多件服饰则是多种单件服饰的组合搭配,这里鞋子、包包、配饰等,也都在虚拟试衣的服务范畴之内。以上就是从服饰的不同维度对虚拟试衣进行的分类。

接下来,换个角度,从模特的视角来拆解虚拟试衣的分类。
从模特类型来看,可分为全身模特、半身模特、多人模特以及视频模特;
从输出形态来看,则可以分为静态图像模特和动态视频模特两类。
讲到这里大家不难发现,虚拟试衣任务的输入条件其实是相当丰富且复杂的。因此,一个优质的虚拟试穿算法,需要对上述所有的组合矩阵都具备良好的适配能力。而截至目前,要实现这一点,依然存在不小的技术挑战。
2 虚拟试穿的核心价值:三大视角的必要性分析

虚拟试穿技术的推进源于行业发展、消费者需求与商家痛点三大核心诉求,具体可从三个视角展开:
从行业大环境来看,三年疫情直接推动服饰行业从线下向线上转移。2019年中国服饰线上销售额占整体零售额的25%~30%,2023~2024年这一比例提升至40%,2025年更是突破50%,线上购衣已成为主流消费习惯。
从消费者视角来看,购物的便捷性和私密性需求日益凸显。调研数据显示,65%的女性和54%的男性对传统实体试衣间感到不自在、不方便——狭小空间内的脱衣穿衣操作、冬季厚重衣物的繁琐试穿流程,以及公共区域的疾病交叉感染风险等,均降低了线下试衣体验。而用户天然存在查看服装上身效果的需求,因此AI试穿被视为服饰线上零售在体验上的“最后一公里”。
从商家视角来看,高退货率是服饰电商的核心痛点。这里有一张图,可能经常网购的女生会了解这个梗,现在有不少买家会做“穿完即退”的操作,尤其是礼服类服饰,穿着新衣服拍照打卡、出席活动后,就无理由退货,导致衣服沾染污渍异味,商家根本无法二次销售。为此,商家想出了用“大尺寸+硬质材料”的“巨型吊牌”,来对这种恶意退货进行物理防御。抛开这个梗不谈,普通电商平台的服饰退货率普遍在25%~60%,内容电商直播场景的退货率更高,部分可达80%~90%。商家每处理一件退货,平均需付出15~30元成本,涵盖物流、包装、折旧、仓储及人工处理等环节,跨境电商业务的成本则更高。此外,“穿完即退”等恶意退货行为也加剧了商家损失,因此行业亟需稳定、可靠的线上试穿技术与产品能力解决上述问题。
3 虚拟试穿的行业核心难点:用户预期的三层进阶需求

虚拟试穿到底好不好做,行业的核心难点又在哪里?聚焦C端场景,虚拟试穿的核心难点集中在用户对技术的三层进阶预期,各层次需求对应的挑战各不相同:
第一层是基础型需求,核心是服装上身效果的精准还原,包括颜色、款式、版型和面料质感。这一层面的难点主要有四:一是用户相册中往往缺乏直接可用的素材,尤其男性用户,难以提供合格的全身或头肩部位肖像;二是试衣算法需保证模特脸部等关键信息不被篡改,尤其是脸部特征,试穿前是什么样子,试穿后核心的面部ID信息必须保持一致,试穿前后核心面部ID信息保持一致;三是真实还原与美学增强的平衡“矛盾体”——算法初期优先追求信息还原,但女性用户对美观度诉求强烈,部分用户可接受轻微肖像修改以提升效果;四是试衣模型多基于扩散模型搭建,试穿效果依赖模型储备的世界知识。
第二层是尺码合身需求,这是大众认知里,虚拟试穿最核心的刚需,也是目前实现难度最高的需求,行业内尚无成熟技术方案。从算法层面看,核心瓶颈是尺码错配训练数据的极度匮乏——电商平台买家秀多为合身尺码展示,缺乏“小体型穿大码”“大体型穿小码”等这类尺码mismatch的完整数据;此外,大量长尾服饰本身存在尺码信息缺失问题,不同品牌、品类的尺码标准不统一,这也是为什么有些店家会建议用户拍大一码或拍小一码。并且,用户对尺码存在个性化偏好,有人偏爱宽松的大码版型,有人则更倾向于合身的小码版型。所以说,尺码合身这个需求,是目前虚拟试穿技术实现中最大的难题,这进一步提升了实现难度。
第三层是突破型需求,即基于用户身材与具体场景的智能穿搭推荐及个性化风格探索。这一层,用户的典型诉求是基于自身身材与具体场景,获得智能穿搭建议,甚至进行个性化的风格探索。比如:用户可以输入自身情况,提出“要参加朋友婚礼该怎么穿搭”“出席孩子家长会适合穿什么”这类场景化需求;也可以针对已有单品提问,比如“我有一件这个颜色的上衣,搭什么下装最合适”“这条裙子配哪种外套更好看”。这些都是用户在穿搭推荐上的典型诉求。这一需求的实现难点在于:一是模型必需精准理解用户的身材特征,避免推荐不符合体型的服饰,比如不能给体型偏胖的用户推荐短款显壮的衣服;二是做好用户历史偏好建模,准确捕捉用户过往的服饰品味,让推荐更贴合其个人喜好,不能给穿衣风格偏保守的用户推荐过多潮流品牌;三是需要获取并理解“时空人”信息,就像现在12月的北京已经入冬,天气寒冷,推荐时就应该优先考虑羽绒服这类御寒衣物。最后,既然要做风格探索,就必须持续投入穿搭知识库的构建,同时积极追踪最新的时尚潮流,这样才能给用户提供前沿且合适的穿搭建议。
4 虚拟试穿的技术发展历程:从学术起源到行业主流

4.1 学术起源与框架演进

虚拟试穿的技术发展历程是什么?从虚拟试穿技术的发展看京东零售技术实践和未来发展方向。
通过文献梳理可以发现虚拟试穿(Virtual Try On)的学术概念最早于2001年由日内瓦大学研究人员正式提出,这样早期研究给出了网络环境下基于人体克隆的服装试穿解决方案。采用高度定制化技术,需从特定角度对人体拍照取样,依赖流程化、模块化操作及关键节点定位技术,这就是虚拟试穿技术的学术开端。
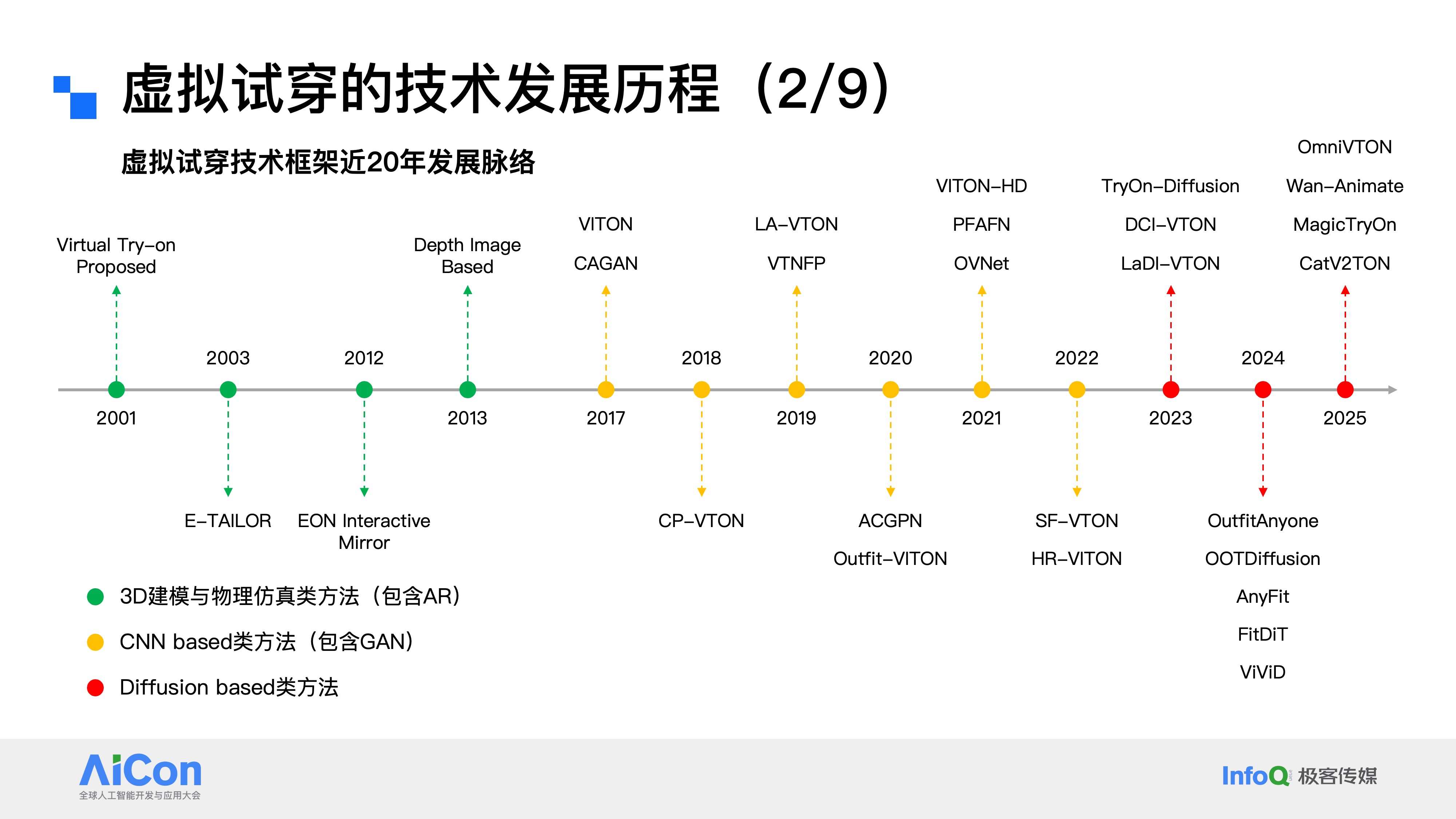
2001年至2025年的二十余年间,虚拟试穿技术在学术界的框架演进可分为三个核心阶段:
第一阶段2001年至2013年,主流方案以3D建模、物理仿真及AR(增强现实)技术为核心;
第二阶段2017年至2022年,技术路径转向基于CNN与生成对抗网络(GAN)的框架;
第三阶段2023年起,扩散模型(Diffusion Model)异军突起,此后绝大多数研究都聚焦于这一技术方向,直到现在扩散模型依然是虚拟试穿领域的最主流技术方案。

与此同时,虚拟试穿技术在学术界“绕不开”的四类核心研究文献可归纳为四类:第一类是生成对抗网络(GAN)方向,相关研究主要集中在2017到2022年,核心都是基于GAN技术来实现虚拟试穿。第二类是扩散模型方向,正如之前提到的,2023年之后这类研究开始爆发,不同的网络结构和试穿任务场景,都能在这个方向找到具有行业影响力的论文。

另外两类分别是视频试穿方向和套装试穿方向。随着单件服饰图像试穿技术逐渐成熟,学术界开始朝着不同维度拓展研究边界,一个是从静态图像延伸到动态视频,一个则是从单件服饰试穿升级到多件搭配的套装试穿。
4.2 京东零售虚拟试穿技术的四代演进
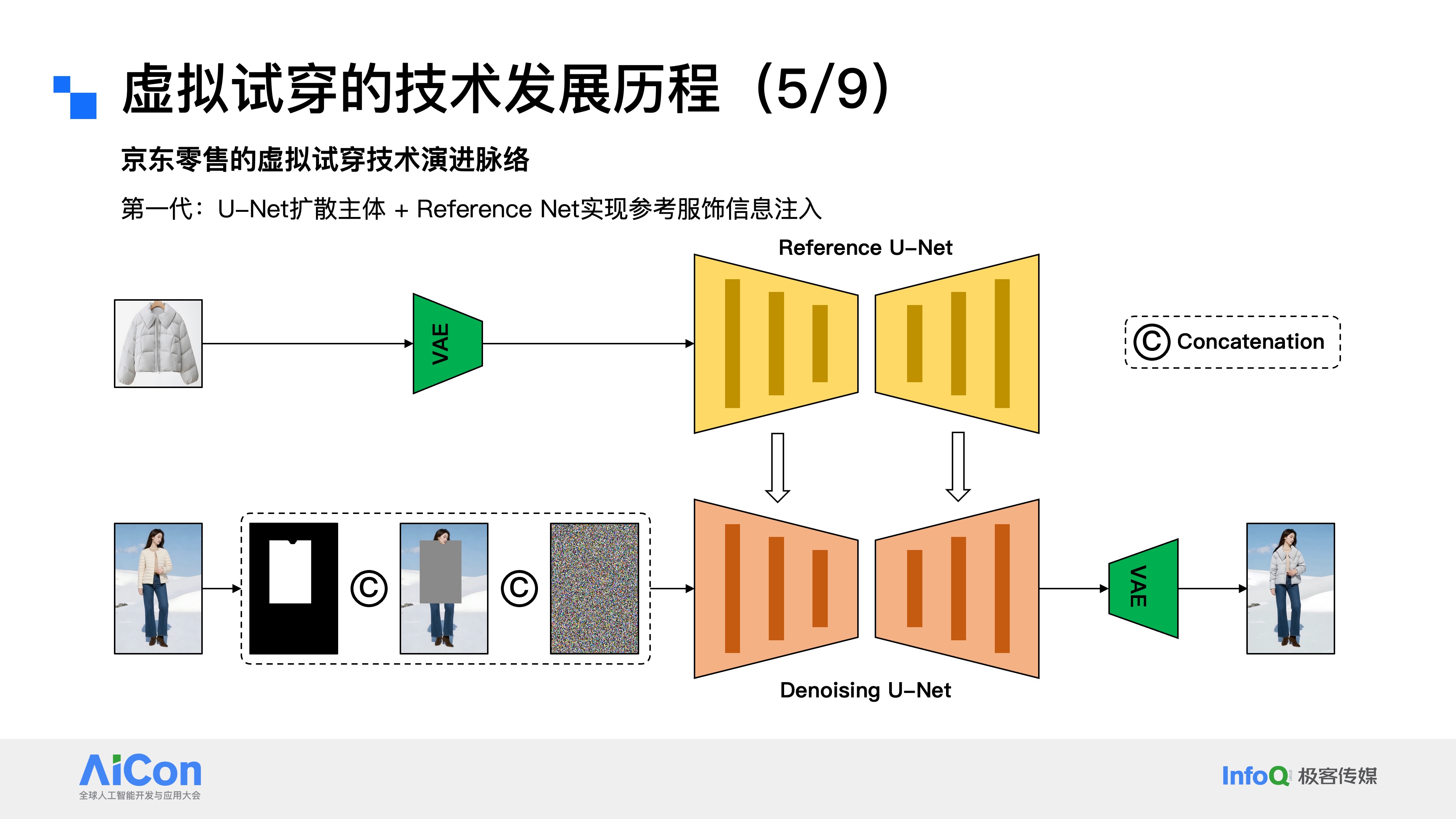
而京东零售自2023年启动虚拟试穿项目研发,至今已有两年多的积累,期间历经了四代大的技术框架迭代,积累了丰富实践经验:
第一代是非常早期的架构,以U-Net作为扩散模型主体,搭配Reference Net来实现参考服饰的信息注入。这个框架大家应该比较熟悉,属于Stable Diffusion时代的产物,它的扩散模型参数规模不算大,对应的图像生成效果也相对有限。
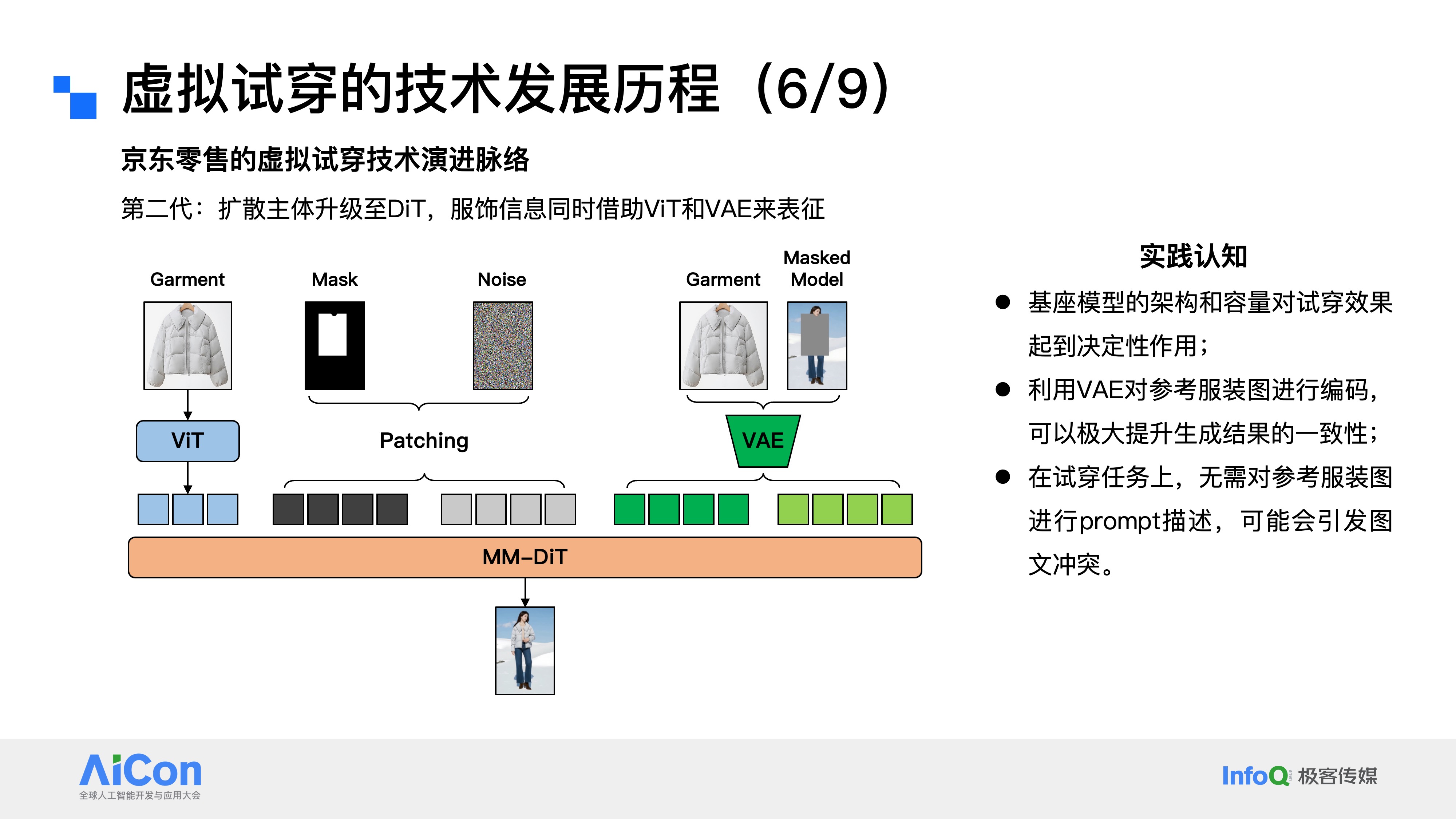
第二代技术框架将扩散模型主体结构从U-Net升级为DiT,服饰信息特征表示借助ViT与VAE完成,与2024年行业技术趋势同步(Sora的出现推动行业普遍完成U-Net到DiT的切换)。这次升级其实和行业趋势同步,2024年年初Sora横空出世,让大家看到了DiT作为扩散模型框架的先进性,因此大部分行业机构都在2024年上半年完成了从U-Net到DiT的技术切换。基于第二代技术框架的实践,我们也沉淀了三个比较重要的认知分享给大家。第一,基座模型的架构和容量对试穿效果起到决定性作用。这一点也印证了扩散模型的Scaling Law,从最初的1B模型,到3B、10B、20B,再到融入VL框架后升级至30B乃至更大参数规模,模型的生成效果有着肉眼可见的提升。第二,利用VAE对参考图像进行编码,能极大提升生成结果的一致性。ViT的表征更偏语义层面,而VAE的训练以重构残差最小为优化目标,更擅长捕捉图像细节。在实际试穿中,若遇到衣服logo等细节还原不佳的问题,往往就是因为没有正确使用VAE编码器来做服饰特征表征。第三,在这套框架的试穿任务中,无需对参考图进行prompt描述,如强行加入文本描述,反而很可能引发图文冲突与对抗。不过这个结论并非绝对,要结合具体技术框架来看,在当前的DiT+ViT+VAE框架下,我们是可以剥离文本模块的,但后续融入VL模型表征后,文本侧的信息也能发挥相应的价值。
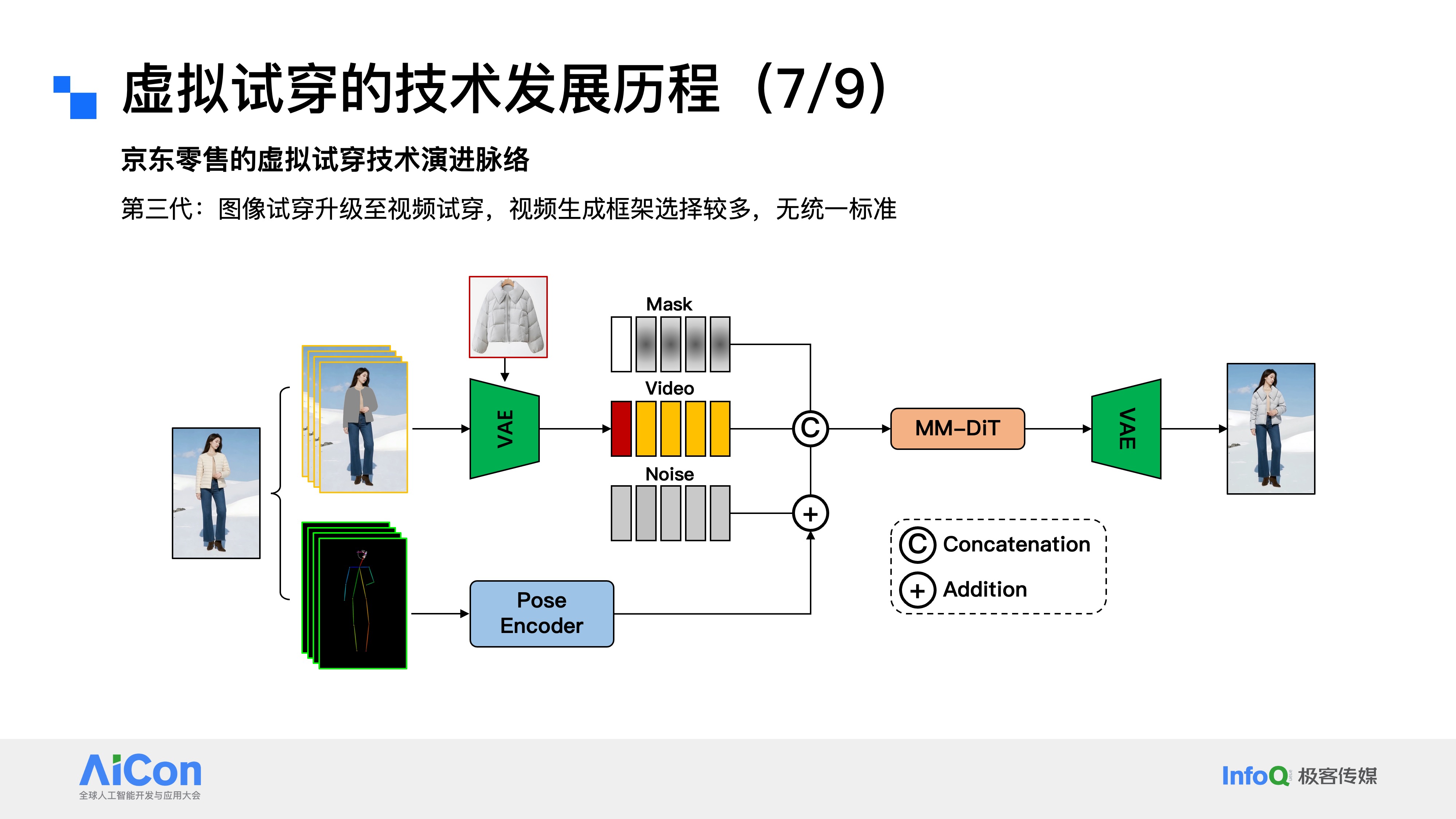
京东零售的第三代虚拟试穿技术,核心完成了从图像试穿到视频试穿的模态升级。目前行业内的视频生成框架尚未形成统一标准,我们可以分享一套可供参考的技术方案:首先将原始视频解析为带mask的视频帧序列,以及类似OpenPose的“火柴棍”姿态帧序列;再分别对这两类序列进行编码、建模、,最终通过MM-DiT完成去噪,生成服饰上身的视频试穿效果。
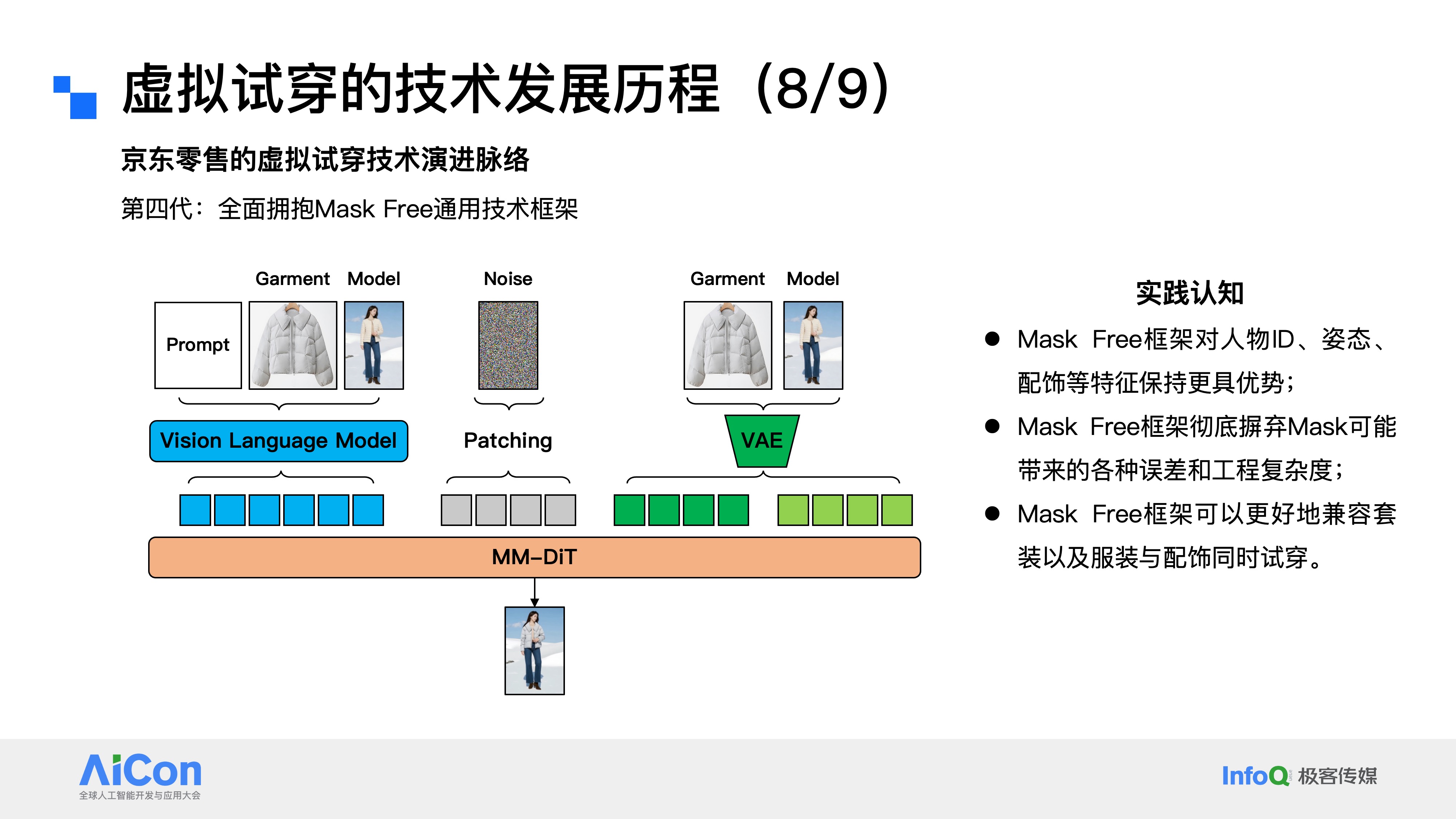
而京东零售最新的第四代虚拟试穿技术,这一代框架最显著的变化,就是完全摒弃了Mask模块,全面拥抱Mask Free的通用技术架构。与此同时,参考图的表征方式也从原来的纯视觉维度,进化为融合文本模态的多模态统一表征,这里我们引入了Vision Language Model 视觉语言模型来专门完成参考图的特征提取。基于第四代框架的实践,我们也沉淀了几个关键认知:第一,Mask Free框架对人物的身份特征、肢体姿态、服饰细节以及配饰元素,都能实现更好的保留效果;第二,该框架彻底摆脱了Mask模块可能带来的误差累积,同时大幅降低了工程研发的复杂度。毕竟从研发角度来说,系统模块越简洁,引入连带问题的概率就越低,而Mask模块本身会因不同应用场景产生各种badcase,容易引发新问题;第三,Mask Free框架可以更好地兼容套装试穿,以及服装与配饰的同步试穿需求。举个简单的例子:在传统Mask方案中,需要先mask掉用户原有的衣物,再叠加新服饰,可如果用户原本还斜挎着小包,这个包包大概率会随旧衣被mask掉,相当于破坏了用户的原始信息,而通过Mask Free的技术框架,就能实现“新衣上身,配饰保留”的效果。
4.3 技术小结与核心观点

结合虚拟试穿技术发展历程和京东零售的技术实践,给正在做或将要做虚拟试穿的企业或相关产研人员建议,可总结以下核心观点:
一是启动项目前一定要拿到最好的图像生成基座模型,因为模型的世界知识和基础能力,直接决定了整个项目的起跑线。请大家始终相信Scaling Law,至少在30B参数规模以内,这种效应的验证效果是非常清晰的。
二是Mask Free技术框架会成为未来的主流方向,大道至简,越简洁的技术路线越正确,如果现在还有同学在Mask based方案里摸索,建议果断舍弃那些冗余的模块,尽快拥抱Mask Free的通用技术框架。
三是从单件试穿到多件试穿是必然的技术趋势,而且必须要兼顾配饰。在我们看来,“试穿+穿搭”才是更具想象力的产品形态。我们现在聊的更多是“穿”的环节,但从产品层面来说,更关键的其实是“搭”的能力。
四是试穿结果的视频化,是用户的核心诉求,这一点毋庸置疑。毕竟线下试衣时,大家都会对着镜子转身、摆动,动态效果才更贴近真实体验。但这需要我们长期攻克推理效率的难题,目前生成一段10秒的试穿视频,耗时基本还是分钟级,这样的速度对线上用户体验的影响是比较大的。
五是数据的价值,用于试穿的训练数据,会成为各大电商平台的核心资产。极致的试穿效果,主要依赖于企业的in-house数据。我们都知道,数据是大模型的核心,虽然有些从业者为了凸显技术深度,会刻意回避甚至弱化数据的重要性,但事实就是如此。尤其是虚拟试穿这类赛道,每个企业都会建立自己的数据壁垒。同时,随着AIGC能力的提升,模型训练早期可以借助AIGC数据快速收敛到任务需求,后续再用真实数据校正,就能有效规避AIGC生成内容带来的失真。
5 虚拟试穿的行业实践方案:国内外典型案例解析

而在虚拟试穿的行业实践方案,目前国内外电商大厂已推出多款虚拟试穿产品,覆盖C端购物场景与B端商家服务场景,各产品特点与局限性各有不同:

首先来看整个行业的发展概况,这里有三组关键数据分享。
第一组数据是200亿美元,2025年全球虚拟试穿平台的市场规模预计将突破200亿美元,这其中涵盖图像生成、增强现实(AR)以及3D虚拟试衣等多个细分技术方向,而中国市场的规模,预计将占到其中的50亿美元左右。
第二组数据是60余个品牌,截至今年12月,国内已有超过60家服装品牌对外宣称具备虚拟试穿能力,覆盖快时尚、运动等多个品类,这些品牌的核心分布区域,也集中在欧美中日韩等时尚消费的核心地带,像Zara、Nike、Gap、H&M,以及中国的李宁、安踏等,都在其列。
第三组数据是60%,有机构预测,到2026年,全球将有超60%的服装品牌采用不同形式的虚拟试穿解决方案,届时,这项技术将从当前的“可选配置”,正式升级为整个行业的“标配能力”。
上方是目前国内外在虚拟试穿领域具备技术储备的部分机构和企业,供大家参考。
5.1 国内C端购物场景案例分析
逐个拆解虚拟试穿行业里几家互联网大厂的典型实践方案。

阿里Lookie:它是一款主打虚拟形象搭配试穿的AI娱乐工具。
这款产品的核心特点有两个:一是玩法丰富、搭配自由度高,而且自带很强的分享属性;二是“电子衣橱”的概念很有新意,精准命中了用户多件服饰试穿搭配的潜在需求。
当然,我们也客观地分析一下它当前存在的局限性。第一,Lookie目前仅支持套装试穿,不支持单件试穿。套装试穿在娱乐场景下确实很有吸引力,但电商平台的用户购买行为更多集中在单件服饰,这就形成了一个明显的场景缺口。第二,它作为淘宝的一款中心化小程序,入口相对较深,导致产品的购物属性偏弱。如何从“好玩”迭代到“好用”,最终实现商业变现,是Lookie团队需要重点回答的问题。第三,从试穿效果来看,生成的形象和用户真实身材仍存在一定差异,大家可以去淘宝小程序里亲自体验感受。第四,Lookie的人物形象建模,在一定程度上依赖于LoRA数字分身技术。熟悉这个技术的人应该知道,早期的妙鸭也是这样,需要用户上传十几张个人照片,付费后等待模型训练,才能生成专属数字分身,后续试穿也都基于这个数字分身来完成。但这种技术方案对训练资源的要求较高,算不上是行业内ROI最优的选择。不过值得一提的是,Lookie目前已经开始尝试支持单张图像建模,在降低用户使用门槛上往前又迈出了一步。

淘宝AI试穿:它是一款入口布局激进、功能设计清爽的购物助手。
这款产品的核心特点有两个:第一,它的入口直接设置在搜索双列的商卡上,这个位置的选择相当大胆激进,能最大程度触达购物链路中的用户;第二,它的推理速度较快,试穿效果稳定,产品功能也足够聚焦,整体使用体验十分清爽。
当然,它也存在两处明显的局限性:其一,目前淘宝AI试穿仅支持上传用户相册里的全身正面站立照,这个要求对不少用户来说存在使用门槛,而且产品缺乏虚拟形象定制能力,毕竟从相册里找出完全符合要求的照片,并不是一件容易的事。而虚拟形象定制恰恰是降低使用门槛的有效方式。其二,它现阶段只具备单品试穿能力,没有搭载穿搭推荐功能。我们之前提到过,穿搭是试穿场景中非常重要的延展环节。不难发现,阿里的这两款试穿产品在一定程度上形成了互补:淘宝AI试穿专注于单件试穿场景,深度嵌入核心购物链路;而它所欠缺的穿搭能力,正好可以由Lookie小程序来补齐。
5.2 海外C端购物场景案例分析
介绍完国内电商平台的试穿产品,我们再把目光转向海外,看看海外的虚拟试穿技术能力。

Google Shopping Try On:这是一款主打高真实性的购物决策工具。
它的核心特点有三个:第一,具备跨端覆盖的试穿能力,同时支持移动端与桌面端,能满足不同用户的使用习惯;第二,服饰覆盖率极高,几乎涵盖了Google Shopping平台上的全量服饰品类;第三,支持用户上传个人照片或使用AI模特,而且对用户上传素材的包容度很高,要知道,通常模特姿态越简单,试穿效果越容易把控,但Google Shopping Try On即便是面对坐姿、非标准站立等有难度的姿态,也能处理得比较好。
当然,它也存在明显的局限性,这点和淘宝AI试穿有些类似,即仅支持单品试穿,暂未开放穿搭组合的试穿功能。
5.3 C端内容电商服务场景案例分析
介绍完货架电商场景下的典型AI试穿能力,我们再把目光转向内容电商,这里以抖音的AI试穿为例来分析。
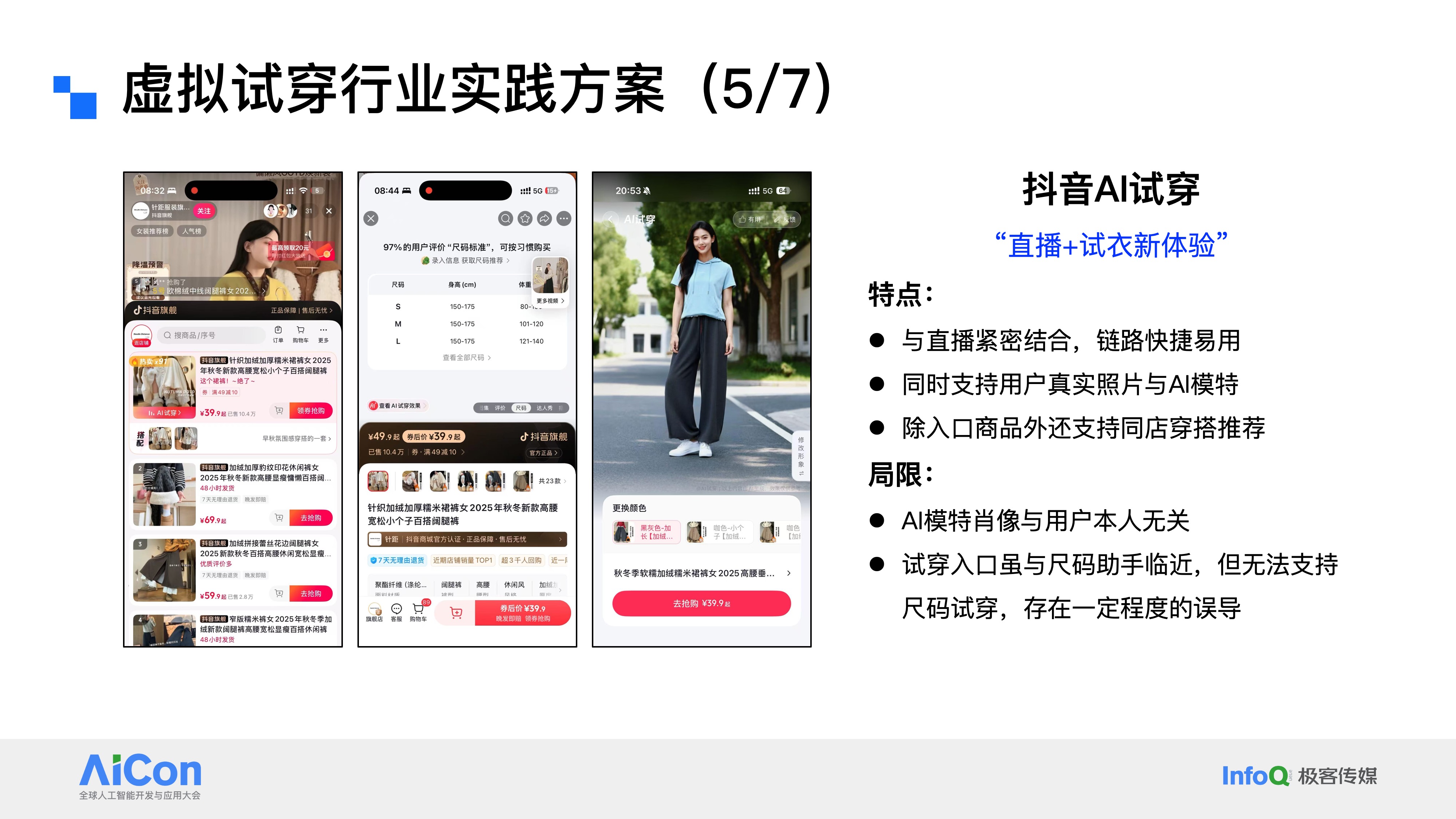
抖音AI试穿:是一款主打“直播+试穿”的新体验产品。
它的核心特点有三个:第一,与直播场景紧密结合,用户从看到商品到完成试穿的链路快捷又易用;第二,同时支持上传用户真实照片和使用AI模特,在一定程度上降低了用户的使用门槛;第三,除了当前入口的商品,还能支持同店铺内的穿搭推荐,正好契合了我们之前提到的试穿延展需求。
这款产品也存在两处局限性:其一,虽然配备了AI模特,但这些模特的肖像和用户本人没有关联,更像是一张“平均脸”,用户会觉得是陌生人在试穿,而非自己,体验上会有割裂感;其二,它的其中一个试穿入口设置在商品详情页的尺码助手附近,而目前行业内并没有成熟的技术能支持尺码合身效果的试穿,这就容易给用户造成误导,用户本以为点进来能看尺码是否合适,实际却只能看到服饰上身的基础效果,从产品入口设计的角度来看,还有进一步优化的空间。
5.4 B端商家服务场景案例分析
介绍完面向C端的虚拟试穿产品方案,接下来看一个B端的典型案例。

阿里绘蛙:这是一个专门服务服饰电商商家的AI内容生成平台。
核心特点有三个:第一,自带海量素材库,涵盖参考图与模特素材,为商家提供了充足的选择空间;第二,同时支持单件与多件服饰上身生成,而且输出素材的分辨率较高,清晰度能满足电商展示、内容种草等多类场景的需求;第三,试穿功能可与平台内其他AI工具无缝联动,比如用试穿能力生成效果图后,能直接在平台内调用图像编辑功能进行二次优化,操作流程十分顺畅。
当然,绘蛙也存在一些局限性:一方面,作为B端生成式服务平台,它目前的生产效率相对偏低,推理耗时基本是分钟级,暂不支持大量素材的批量生成,这对于有规模化生产需求的商家来说是个不小的遗憾;另一方面,受B端的产品定位所限,平台缺少C端用户的使用场景,毕竟普通消费者更习惯在手机购物链路中使用试穿功能,而绘蛙的核心用户群体始终是电商商家,主要用于制作商品相关素材。
5.5 行业分析小结

结合上述案例,可总结行业实践核心要点,从四方面展开:
第一,B端与C端的定位分化清晰,PC端或Web端聚焦服务B端商家,提供模特生成、AI试穿、素材二次编辑等能力,批量化、低成本生产是商家的核心诉求。如果平台能打通“素材生产—投放—效果验证”的闭环,并将验证结果反馈给模型辅助进化,会成为中小商家的一大福音。而APP端或小程序端则瞄准C端用户,主打简化操作流程,联动购物闭环以适配移动端的碎片化体验;再次强调,对于C端而言,“穿”是刚需,但“搭”才蕴藏着更多产品机会。
第二,入口形态决定产品定位。电商平台的AI试穿入口无非两种:第一种是非中心化入口,将试穿能力嵌入购物全流程,比如直接放在每个商品的商卡上,实现“见品即试穿”,核心目标是强化用户的及时决策;第二种是中心化入口,类似阿里Lookie的小程序单入口,不依附于具体sku,能打造独立场景,延伸穿搭推荐、社交分享等功能,让产品从购物工具升级为内容娱乐的社交载体。
第三,通过多元方案降低用户使用门槛。针对用户相册难以找到合格全身照的痛点,行业内普遍采用多种路径打破传图依赖:一是虚拟捏人;二是非标图像兼容,提升算法能力,支持半身照等非标准素材试穿,比如用半身照试穿上衣;三是“大头照+身材参数”实现数字形象,以此降低C端用户的试穿启动门槛,这些都是值得肯定的产品尝试。
第四,尺码破局需要技术与策略双重保障。单纯依靠算法模型,很难解决尺码合身的试穿问题。行业的可行思路是联动尺码助手、用户试穿报告等策略工具,用“技术生成效果+策略辅助决策”的双重模式降低用户购物决策风险,最终实现退货率的下降。
6 京东的虚拟试穿实践:产品特点与核心经验

6.1 京东虚拟试穿产品现状

京东零售虚拟试穿产品目前处于小流量测试阶段,产品主要有四大特点:精准的身材识别、逼真的材质渲染、高效快速的生成、智能的搭配推荐,这也是京东零售虚拟试穿一直持续打磨的产品目标。现阶段产品已覆盖超百万服饰SKU,实验阶段用户量突破100万,覆盖70多个服饰类目,合作头部服饰品牌超500家。

从具体功能来看,产品设计包括三大核心模块:
一是最左侧图示,商详主图的试穿入口,目前这个入口的设置比较保守,没有像淘宝AI试穿那样直接嵌入搜推双列商卡,我们认为在实验阶段,还是尽量避免影响用户原有的购物体验,后续会根据测试效果考虑提升入口优先级。
二是中间三张图示,我们重点探索的同款不同色服装试穿,用户从某一款颜色的服饰(比如图中的粉色羽绒服)进入试穿页面后,可以一键切换同SPU下的白色、黑色等其他配色,便捷完成多色试穿对比。
三是最右侧图示,我们正在积极推进的上下装搭配试穿,系统会为入口服饰,比如这件羽绒服,匹配同店铺内的裤子、裙子等下装,让用户直观感受不同搭配的视觉效果。当前我们把搭配候选池限定在同店铺内,从消费者视角来看,打破店铺限制可能会更有吸引力。从技术层面来讲,跨店铺搭配的实现难度也并不大,核心在于业务逻辑的梳理,这需要我们与商家做更深入的调研沟通,明确背后的商业价值后,再考虑进一步的功能升级。
6.2 京东虚拟试穿产品实践经验

京东在虚拟试穿项目实践中沉淀下来的三点核心经验:
一是需全力降低用户使用门槛——我们有一组数据可以佐证这个观点,目前线上使用虚拟试穿的用户中,超过半数无法上传符合要求的试穿照片。即便我们在上传页面做了详细的规则引导,用户从相册里找到合规照片的难度依然很高。为此,我们果断加入了数字人模式,采用“真实照片上传+虚拟数字人形象”的双轨方案,用户如果找不到合适的照片,或者不愿上传个人照片,就可以输入身高、体重等参数打造专属数字人;若能提供肖像照,数字人会更贴近用户本人,没有肖像照也可以使用默认形象,这是降低用户使用门槛非常行之有效的方法。
二是穿搭场景中,“搭”大于“穿”。正如之前提到的,“穿”是用户的基础性刚需,而“搭”属于突破性需求。但在电商场景下,用户对穿搭的期待其实很高,所以我们一直在积极探索为用户提供多样化的搭配可能性,以此挖掘更多产品价值。
三是试穿效果要兼顾“像”与“美”,二者缺一不可。这一点往往被很多项目组忽略。用户对试穿效果的核心要求是“真、像、美”:“真”是衣服和人物的真实感,不能有明显的AI痕迹;“像”是人物ID、服饰细节、环境背景的精准保留;而“美”常常被忽视,但其实至关重要。我们在算法侧也把评测标准,从最开始的“衣服还原不出错”,升级为“可用率+美观度”的多维度评估体系。这里可以举个例子:大家做虚拟试穿,都是希望提升转化率、降低退货率,但如果忽略了“美”的需求,很可能连转化率都会受影响。没有试穿时,用户看商详主图觉得衣服不错就会下单,但AI试穿后发现效果不好看,反而会直接放弃购买。这其实是大模型在落地原生AI场景时会遇到的阵痛,所以我也呼吁行业同仁,面对这类问题要保持长期心态,用户心智的培养和行业的迭代,都需要一个过程
6.3 京东虚拟试穿未来探索方向

结合行业趋势、实践经验与用户需求我们认为未来值得探索的虚拟试穿产品形态,以下三类产品形态具有较高探索价值:
第一个是万物成套的试穿试戴系统,服饰试穿已经从单件升级到多件,但对于注重OOTD的用户来说,鞋子、配饰、包包甚至手机壳,都是穿搭的重要组成部分。我们希望未来能实现全品类的组合式穿搭,打造真正的“万物穿搭”试穿效果。
第二个是数字人虚拟试穿+AI导购,想象一下,每个用户都有专属的数字人形象,它既可以是你的分身,也可以是你的AI导购助手。你在逛商品流的时候,轻触商卡就能把衣服“穿”到数字人身上,同时还能和这个数字人对话,让它帮你推荐搭配,实现7×24小时的购物陪伴。这其实也是电商2.0时代追求的极致沉浸式个性化体验,我们甚至畅想过一个更极端的场景:用户浏览服饰商卡时,卡面展示的就是自己穿着这件衣服的形象,滑一屏都是专属的上身效果,选款会更直观。不过这种形态需要充分尊重用户意愿,避免造成冒犯,同时也面临着推理资源、生成效率等工程侧的巨大挑战。
第三个是电子衣橱。这个概念虽然已有部分产品提及,但我们认为还有很大的深挖空间。用户可以把已购、收藏的服饰都放进这个虚拟衣橱,系统根据天气、出席场合等场景,为用户提供交互式、陪伴式的试穿搭配建议,真正实现“衣随场景搭”。
7 从虚拟试穿到全域布局:京东电商AIGC能力矩阵

7.1 京东电商AIGC能力矩阵
从虚拟试衣切入,到更大范畴的电商AIGC。京东零售在电商AIGC领域的能力布局,整体可以分为八大能力板块,全面覆盖商品素材制作、营销推广、用户体验等关键环节。

第一,商品智能抠图。这是所有电商平台最关键、最基础的技术能力,抠图效果的优劣,直接影响后续整条素材制作链路的最终呈现质量。第二,商品素材生成。我们依托AIGC技术,实现主图、商详图、广告素材的自动化生成。在技术加持下,内容制作周期大幅缩短,素材迭代效率提升了数十倍。第三,视频生成。从2024年开始,视频生成技术的效果已经被大家广泛认可,国内相关技术也实现了大幅跃升。我们主要聚焦主图视频和营销视频两大场景:主图视频时长较短、镜头单一,主打快速展示商品核心卖点;营销视频则篇幅更长、内容更丰富,通常会搭配剧本与口播,用于深度种草和品牌宣传。第四,AI模特。这项能力不仅服务于服饰场景,也覆盖了众多非服饰品类的素材生成需求。传统模式下,头部商家会邀请明星代言,中型商家则需要对接外部服务商拍摄,不仅成本高昂,还会拖慢商品上新节奏。而AI模特能力通过AIGC技术,为商家快速生成适配不同场景、不同风格的模特素材,有效降本增效。

第五,虚拟试穿。这项能力不过多赘述了,今天的分享主题基本都围绕它展开,核心是通过AIGC技术实现服饰的虚拟上身与搭配,降低用户决策成本。第六,AI设计家。也可以称之为“放我家”功能,主要服务于家具等大件商品场景。用户上传自家房屋照片后,AI就能将目标家具植入到真实家居环境中,直观呈现摆放效果;同时还能针对毛坯房、清水房,按照用户需求设计出对应的装修风格,解决家居选购与装修设计的可视化难题。第七,3D立影。这是京东零售自研的AIGC裸眼3D技术,能让商品从商卡中“跳脱”出来,以3D形态呈现。这项技术能显著提升品牌商品的点击率,以及直播场景下的用户互动率。第八,数字人。相信大家对京东数字人并不陌生,目前已有超2万个品牌在使用这项能力,相关场景的转化率提升了30%。它最直接的价值是实现7×24小时数字人直播卖货,打破传统直播的时间限制,持续为商家创造收益。
7.2 京东电商AIGC实践案例
接下来,选取其中几项能力,展开分享京东零售在业务侧取得的实际成果。

第一个是商品素材AIGC生成。这里展示的是一款起泡酒的案例,覆盖商品主图、商详图、卖点图和广告图等全类型素材。目前这项能力已经改变了京东超100万商家的内容设计模式,既大幅提升了素材制作效率,又显著降低了制作成本。

第二个是AI模特。模特图生成技术正逐步在头部品牌中批量落地,我们过去已与Nike、阿迪达斯、海澜之家三大时尚品牌达成深度合作。在批量应用阶段,合作品牌的商品转化率提升29%,商品上架速度提升90%,同时商品素材制作成本大幅下降。大家现在在这些品牌店铺里看到的部分模特图,正是由我们的AIGC技术生成,再结合虚拟试穿能力完成服饰上身的。

第三个是AIGC裸眼3D技术,立影。这里有SK-II和华为耳机两组合作案例,这项技术能明显带动品牌点击率与销售转化率的提升。目前它主要应用于广告投放、家具搭配、直播互动、互动游戏以及试装试戴等场景。
7.3 京东电商AIGC设计智能体:焕新版京点点Oxygen Vision

京东零售电商AIGC内容生成平台“京点点”整合了上述大部分能力,目前已支持超过30种业务场景(覆盖商品发品、运营、营销等环节),日能力调用量超1000万次,服务超100万京东商家,助力商家内容生产成本降低90%,生产效率提升95%。

近期,京点点平台完成系统性升级,焕新版命名为Oxygen Vision平台。新版平台和老版最大的差别,一方面是集成了更多的AIGC能力项,另一方面则是把交互形式从原来的纯GUI交互,升级为Linguistic UI + GUI的混合模式。
具体来说,新版平台具备四大核心特点:第一,对话式人机交互,支持纯自然语言的交互方式,操作更便捷;第二,大模型驱动的任务规划与执行,能够拟人式地分步骤、有序完成各项操作;第三,强一致性且不失多样性的商品素材生成能力,确保生成内容既贴合商品属性,又能满足多样化需求;第四,无缝接入京东AB实验平台的能力。正如我们之前所说,一个合格的B端AIGC内容生成平台,必须打通“素材生产—投放—实验回收—模型迭代”的完整闭环,而这一点,新版京点点平台已经完全具备。

8 电商AIGC的未来展望:技术纵深与商业价值

8.1 AIGC应用的三层分类与技术复杂度
最后未来展望,来看电商AIGC的技术纵深与商业价值,分享个人观点和思考。
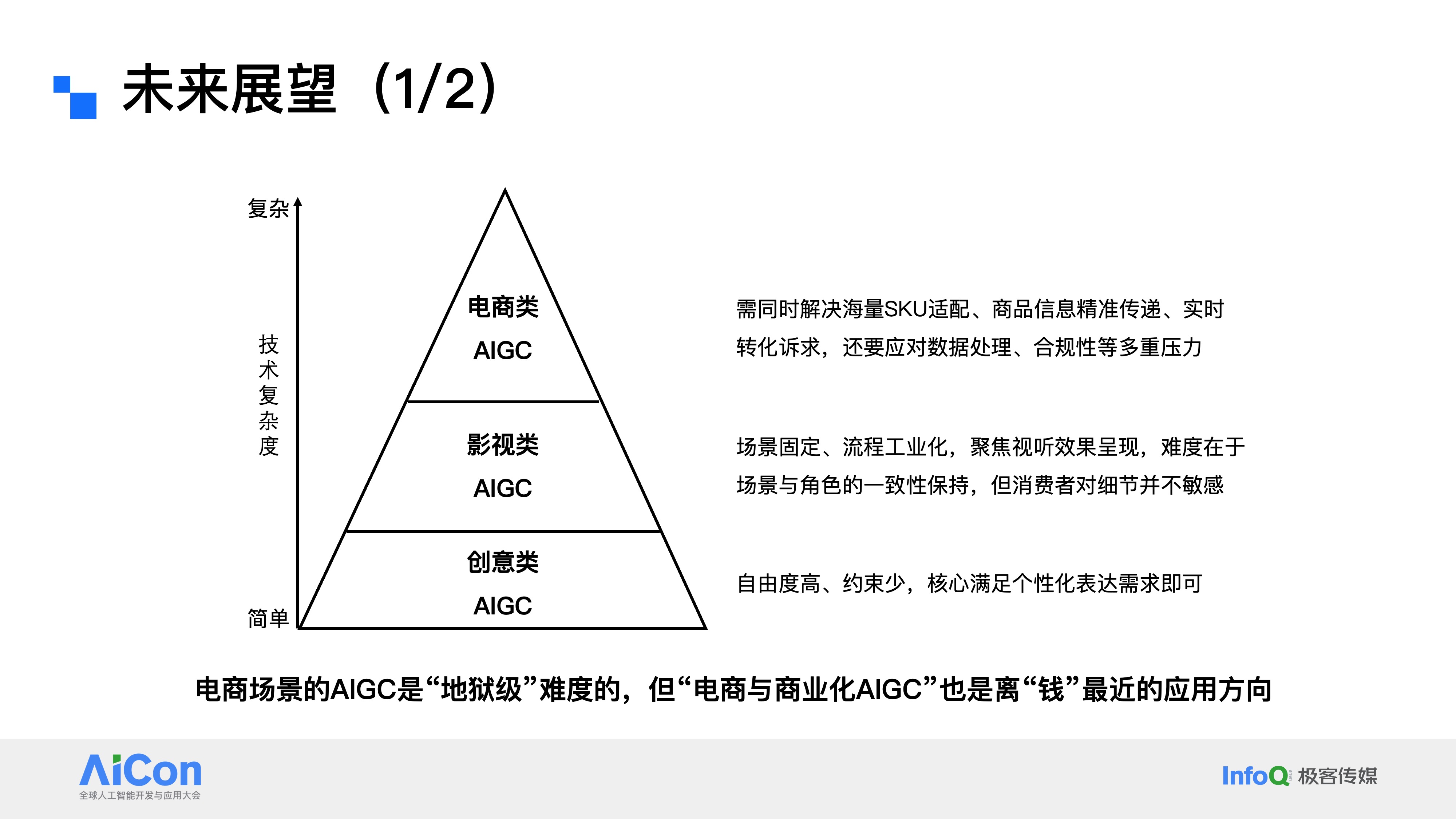
首先,从上图来看,AIGC的应用分成了三个层次。最底层的是创意类应用,这类应用的自由度高、约束少,核心是满足用户的个性化表达需求,比如短视频平台的魔法表情特效,运营活动需要的banner海报、插画设计,都属于这个范畴。往上一层是影视类应用。如果大家了解即梦、可灵、海螺这些视频生成工具,应该会有体感,这类应用的核心是通过AIGC实现角色和场景的一致性保持,技术难点也集中在这里。不过说实话,普通消费者对于这类内容的细节一致性,敏感度其实没那么高。而最上层的,就是我们今天一直在聊的电商类AIGC,这个方向,需要解决海量SKU的适配问题,要确保商品信息的准确传递,还要满足实时转化的业务诉求,同时还要应对严格的合规风险。
如果从技术复杂度排序,创意类最简单,影视类次之,电商类堪称地狱级难度。为什么这么说?因为电商AIGC对商品一致性的要求是极致严苛的,哪怕是一个细节的偏差,比如裙子本该没有花边,生成的素材里却加了花边,用户收到货发现“货不对版”,就可能引发客诉,甚至是官司。这和影视类的一致性要求完全不是一个量级,更别说创意类的开放创作模式了。但有意思的是,这三类应用里,电商类AIGC恰恰是距离商业化、距离“钱”最近的。做了这么久的AIGC应用,有一个很直观的体感:有两类应用场景是可以直接实现变现的。第一类,就是影视类AIGC。这个很好理解,举个例子,拍摄《速度与激情》时,要呈现兰博基尼和法拉利相撞的画面,在没有AIGC技术之前,这样一个镜头的成本可能高达上百万;而现在,依托可灵、即梦这类视频生成工具,成本有可能直接降到几百美金。无论是文本生成视频、图像生成视频,还是首尾帧驱动的视频生成技术,都能支撑这类特效镜头的制作。更值得一提的是,现在很多视频生成能力还叠加了音画直出功能,这让电影级别的多媒体内容高效输出,变得越来越有可能。第二类,就是电商与商业化AIGC。这里我们暂时不做细致区分,核心逻辑很简单:我们用AIGC生成的电商素材,是直接供商家用于商品运营和投放的,最终指向的就是GMV的增长,这是最直接的收益。商业化场景也是同理,通过AIGC制作广告素材,直接面向广告主和用户,素材投放后带来的广告消耗,直接对应着平台的营收。所以在我看来,电商与商业化AIGC,是现阶段离“钱”最近的应用方向。这就是个人对整个AIGC行业应用落地的一些理解。
8.2 未来展望

最后,再分享三个总结性的观点。
第一,从技术角度来看,像虚拟试穿这类垂直业务,未来不会再依赖专属定制模型。一个明确的技术趋势是,越来越多的电商AIGC任务,会统一到通用大模型框架之下,就像nano banana pro这类架构一样,用户只需要在prompt层面定义好业务需求,就能完成相应任务。只不过现在还有不少虚拟试穿方案,还停留在定制化思路上,这个转变需要一个过程。
第二,想和所有AIGC创业者、以及大厂里做AI提效的同学聊一句:不是所有业务都需要升级到LUI(对话式交互)的形式。有些功能用GUI(图形界面)来承载,体验反而会更好。不要觉得套上LUI的壳,就是做了AI native的升级,很多时候这种做法反而属于“故弄玄虚”。这两年大家应该也见过不少“AI小助手”“智能XX工具”,本质上就是把原来的GUI功能强行改成对话式,看似用上了大模型和Agent,实际体验反而不如从前。尤其是编辑类需求,图形化的交互方式往往更直接高效。而新京点点平台之所以选择LUI+GUI的混合模式,核心是看服务对象,我们主要服务的是京东的采销同学。他们每个人负责的SKU数量极多,不可能针对每个商品去定制化制作素材,更需要“一句话指令”就能自动生成内容的傻瓜式操作。这样才能让采销把精力聚焦在拿货、议价、仓储运营这些核心工作上,而不是耗费在素材制作上。
第三,关于电商2.0核心方向,极致的沉浸式与个性化购物体验是核心目标。虚拟试穿是沉浸式体验的重要探索,而个性化购物的底层支撑是“千人千面”的商品素材生成能力。这也是京东在探索大模型时代电商2.0形态的一条核心技术路线。大家对“千人千面”并不陌生,过去京东零售的搜索推荐就是如此,同样搜索一个关键词,不同用户看到的结果页截然不同。但到了商品素材层面,目前商品素材仍处于“千人一面”状态,商家只维护了一套主图、商详图和卖点介绍。而“千人千面”的商品素材生成,就是要打破这种单一性。比如:一款中性款冲锋衣,面对三类不同需求的买家,可以用算法提炼出他们各自关注的核心卖点,定制差异化的素材,既精准吸引用户,又提升购物体验。第一类是户外功能型买家,他们最关心面料科技、防风防水、透气耐磨这些专业指标,AI就在商品图上重点呈现这些性能参数;第二类是外观穿搭型买家,他们不纠结材质,只在意设计风格、版型潮流和穿搭适配,AI就主打OOTD相关的素材生成,突出颜值和搭配感;第三类是价格敏感型买家,他们不关注功能和颜值,只看价格、优惠和赠品,AI就直接在图片贴片上展示最低价标识、优惠券、赠品信息等内容,实现精准引流与体验提升。通过这个案例,大家应该能更直观地理解什么是“千人千面”的商品素材能力。当然这个话题还有很多细节可以展开,可点击查看《从 “千人千面” 的搜索推荐到 “千人千面” 的商品素材技术探索》文章,里面有更详尽的介绍。






