



一、新闻
先播放一条最新新闻,通义团队官宣开源了两个智能体Alias-Agent和Data-Juicer Agent。
Alias-Agent提供了RaAct,Planner,DeepResearch三种模式,以实现灵活的任务执行。
DataJuicer 智能体是一个数据专员,由数据处理智能体,代码开发智能体,MCP 智能体,数据分析与可视化智能体,问答智能体五个智能体组成。
看到这里已经相当炸裂了!可能很多伙伴对智能体(Agent)的范式不熟悉,还不理解ReAct、Planner、反思叭叭这些名词。那你们就来对了地方,我用最容易理解的方式带大家一起看下智能体内部是什么样子的。

产品化的智能体由多Agent,反思,计划,推理与行动,记忆,RAG,工具,MCP组成的。首先聊下“Multi-Agent”,它非常好玩!
二、Multi-Agent 的7种设计模式
要让AI代替人工作,现阶段的单体智能体(仅通过系统提示词赋能的LLM)是很难实现的。我们很快意识到,要构建高效的系统,需要多个专业化智能体协同工作、自主组织。为实现这一目标,AI 智能体领域已涌现出多种架构模式。多个智能体组成实现的,也就是Multi-Agent,发展到现在有7种实现方式。
1. 工作流模式
 在《Agentic Design Patterns》中叫Prompt Chaining,每个智能体都逐步地完成输出,比如一个生成代码,另一个审核代码,第三个部署代码。每一步的输出作为下一步的输入。这种信息传递建立了依赖链,前序操作的上下文和结果会引导后续处理,使 LLM 能够在前一步基础上不断完善理解,逐步逼近目标解。
在《Agentic Design Patterns》中叫Prompt Chaining,每个智能体都逐步地完成输出,比如一个生成代码,另一个审核代码,第三个部署代码。每一步的输出作为下一步的输入。这种信息传递建立了依赖链,前序操作的上下文和结果会引导后续处理,使 LLM 能够在前一步基础上不断完善理解,逐步逼近目标解。
他非常适合应用在工作流自动化、ETL和多步骤推理pipeline场景。
2. 路由模式
 路由模式为智能体的操作框架引入了条件逻辑,使其从固定执行路径转变为动态评估标准,从一组可能的后续动作中进行选择的模式,从而实现一套更灵活,并且具备上下文感知的。一个控制器智能体将任务分配给合适的专业智能体,这是上下文感知智能体路由的基础,正如在MCP、A2A框架中所看到的那样。
路由模式为智能体的操作框架引入了条件逻辑,使其从固定执行路径转变为动态评估标准,从一组可能的后续动作中进行选择的模式,从而实现一套更灵活,并且具备上下文感知的。一个控制器智能体将任务分配给合适的专业智能体,这是上下文感知智能体路由的基础,正如在MCP、A2A框架中所看到的那样。
路由模式的实现有四种:
- 根据LLM路由,通过提示语言模型分析输入,并输出指示下一步或目标的标识符或指令。这里有显式路由和隐式路由两类,显示直接使用智能体的结构化输出来确定将消息路由到哪个智能体。隐式路由是将下游智能体包装成工具函数,这样路由智能体就可以根据用户查询决定调用哪个工具。
""" 伪代码示例 """
router = ReActAgent(
name="Router",
sys_prompt="#角色#你是一个路由智能体。你的目标是将用户查询路由到正确的后续任务,注意你不需要回答用户的问题。
#任务#选择正确的后续任务,如果任务太简单或没有合适的任务,则选择 ``None``",
model=ChatModel(
model_name="gpt-4",
api_key="",
stream=False,
)
)根据Embedding路由,利用嵌入能力,将查询路由到最相似的路径上,适用于语义路由,即决策基于输入的含义而非关键词。
""" 伪代码示例 """
def __init__(self):
# 使用轻量级的句子编码模型
self.model = ChatModel( model_name="gpt-4", api_key="", stream=False, )
# 定义不同的路由能力和对应的处理函数
self.routes = {
'code_help': {
'description': '编程,代码',
'handler': self.handle_code_question
},
'general_chat': {
'description': '聊天,日常对话',
'handler': self.handle_general_chat
}
}
# 预计算所有路由描述的嵌入向量
self.route_embeddings = {}
for route_name, route_info in self.routes.items():
embedding = self.model.encode([route_info['description']])
self.route_embeddings[route_name] = embedding
def route_query(self, user_question):
# 1. 将用户问题转换为嵌入向量
question_embedding = self.model.encode([user_question])
# 2. 使用余弦计算与各个路由的相似度
similarities = {}
for route_name, route_embedding in self.route_embeddings.items():
similarity = cosine_similarity(question_embedding, route_embedding)[0][0]
similarities[route_name] = similarity
# 3. 选择相似度最高的路由
best_route = max(similarities, key=similarities.get)
best_score = similarities[best_route]
# 4. 调用对应的处理器
handler = self.routes[best_route]['handler']
response = handler(user_question)
return {
'route': best_route,
'confidence': best_score,
'response': response
}
....- 根据定义规则路由,硬编码方式,根据关键词、模式或结构化数据进行路由。此方法比 LLM 路由更快、更确定,但灵活性较低。
- 根据自训小模型路由,采用如分类器等判别模型,在小规模标注数据集上专门训练以实现路由任务。与向量嵌入方法类似,但其特点是监督微调过程,路由逻辑编码在模型权重中。与 LLM 路由不同,决策组件不是推理时执行提示的生成模型,而是已微调的判别模型。LLM 可用于生成合成训练数据,但不参与实时路由决策。
3. 并行模式
 每个智能体负责处理不同的子任务,例如数据爬虫、网络检索和摘要生成,它们的输出会合并为一个单一结果。非常适合减少高吞吐量管道中的延迟。(如文档解析或API编排)
每个智能体负责处理不同的子任务,例如数据爬虫、网络检索和摘要生成,它们的输出会合并为一个单一结果。非常适合减少高吞吐量管道中的延迟。(如文档解析或API编排)
4. 循环模式
 智能体不断优化自身输出,直到达到预期质量。非常适合校对、报告生成或创意迭代,在这些场景中,系统会在确定最终结果前再次思考。反思就是在此模式上进行的优化。
智能体不断优化自身输出,直到达到预期质量。非常适合校对、报告生成或创意迭代,在这些场景中,系统会在确定最终结果前再次思考。反思就是在此模式上进行的优化。
5. 聚合模式
 许多智能体生成部分结果,由主智能体将这些结果整合为一个最终输出。因此,每个智能体都形成一个观点,而一个Master智能体将这些观点汇总成共识。在RAG的检索融合、投票系统等场景中很常见。
许多智能体生成部分结果,由主智能体将这些结果整合为一个最终输出。因此,每个智能体都形成一个观点,而一个Master智能体将这些观点汇总成共识。在RAG的检索融合、投票系统等场景中很常见。
6. 网络模式
 这里没有明确的层级结构,智能体之间可以自由交流,动态共享上下文。用于模拟、多智能体游戏以及需要自由形式行为的集体推理系统中。agentscope-samples ,模拟了9个智能体的狼人杀游戏。
这里没有明确的层级结构,智能体之间可以自由交流,动态共享上下文。用于模拟、多智能体游戏以及需要自由形式行为的集体推理系统中。agentscope-samples ,模拟了9个智能体的狼人杀游戏。
7. 层级模式
 一个顶级规划智能体,将子任务分配给工作智能体,跟踪它们的进度,并做出最终决策。这和经理及其团队的工作方式完全一样(很多中间件的架构也是类似这种模式如Redis、ES、Nocas)。意图识别就是采用此模式。
一个顶级规划智能体,将子任务分配给工作智能体,跟踪它们的进度,并做出最终决策。这和经理及其团队的工作方式完全一样(很多中间件的架构也是类似这种模式如Redis、ES、Nocas)。意图识别就是采用此模式。
小节:
我们一直在思考的一件事,不是哪种模式看起来最酷,而是哪种模式能最大限度地减少智能体之间的摩擦。启动10个智能体并称之为一个团队很容易。难的是设计沟通流程,以确保:没有两个智能体会做重复工作。每个智能体都知道何时行动何时等待,使这个系统作为一个整体,比其任何单个部分都更智能。为此我们遵循 building-effective-agents 设计。
三、Multi-Agent 框架
多智能体模式将人工智能工作流构建为一个智能体团队,它们相互协作,每个智能体都有明确的角色。每个智能体能够感知输入、进行推理(通过思维链)并执行操作以完成子任务。每个智能体通常都配置有特定角色,并且只能访问该角色所需的工具或信息。例如,PM AGent负责需求判断是否需要其他智能体参与,若需要技术决策则联动Tech lead agent。智能体将循环进行思考(“思考……”)和行动(“行动……”),直到完成其工作部分的任务。如下图
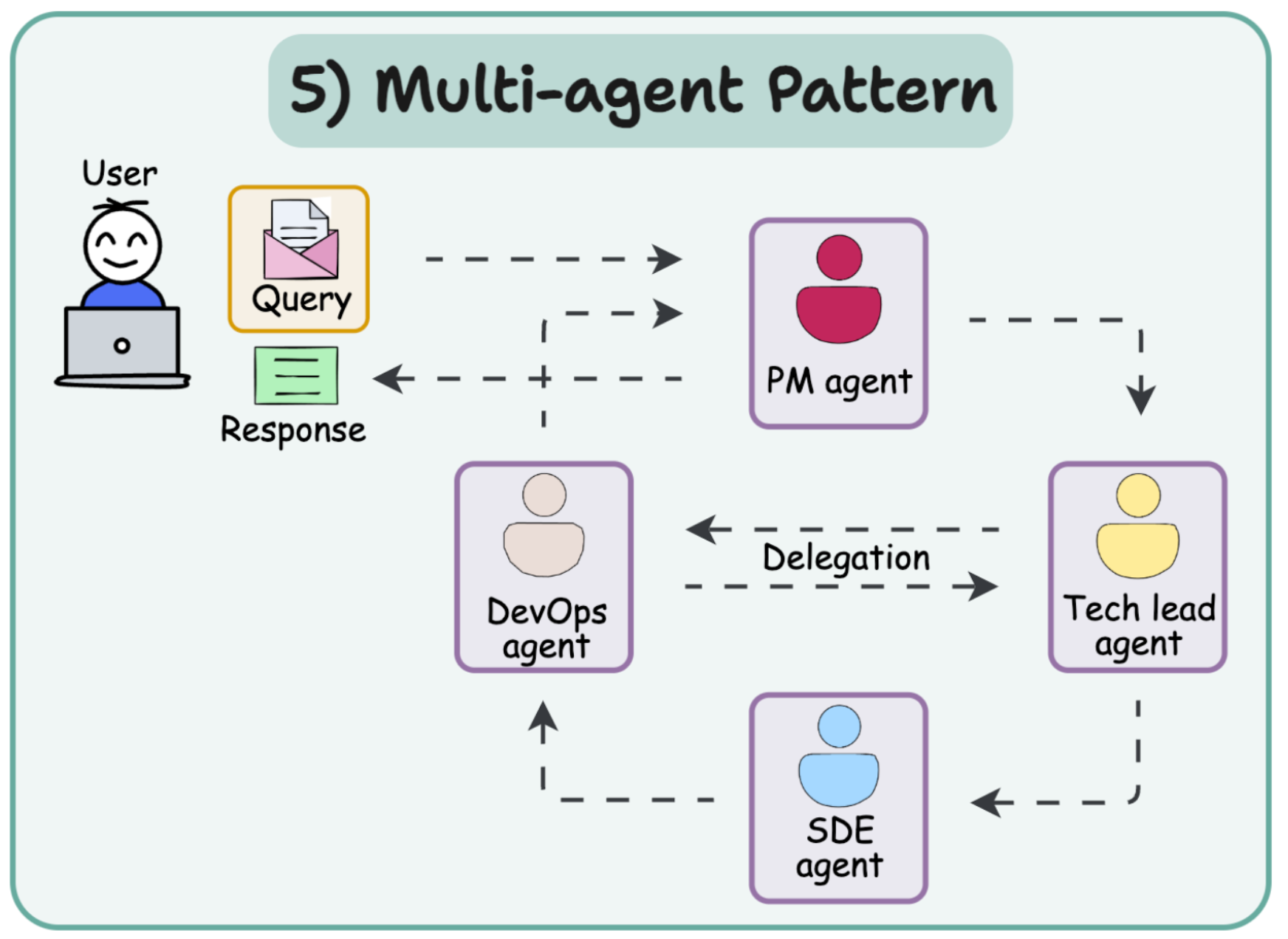
以上简单介绍了多智能体的设计模式,那么当下是不是已经有了成熟的架构供我们使用呢?答案是肯定的!
1.AutoGPT:Github 180k Star
2.Dify: Github 118k Star
3.AutoGen: Github 51.4k Star
4.CrewAI:Github 40.1k Star
5.LangGraph: Github 20.6k Star
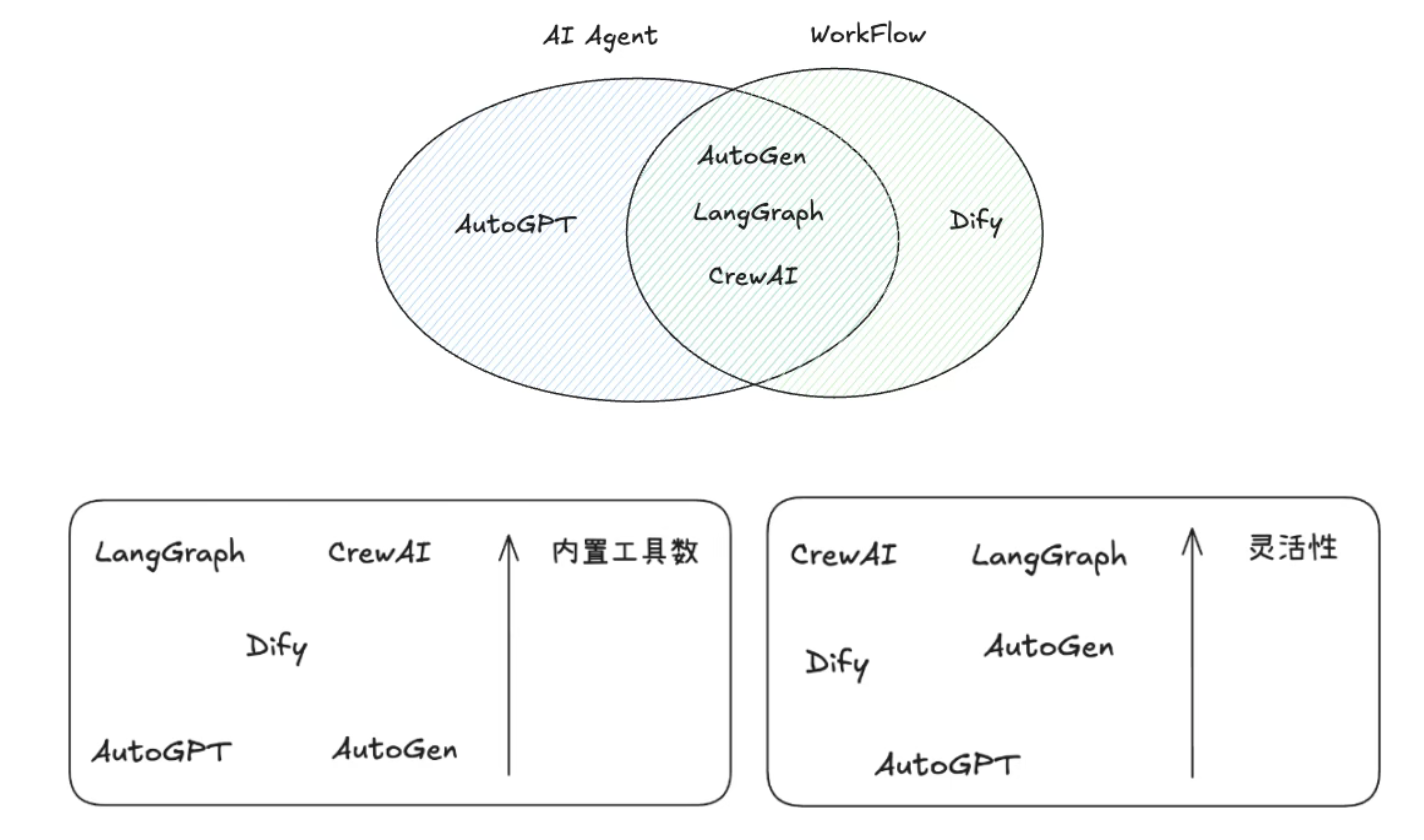
为什么需要使用Agent框架?
只要“问题不可完全穷举、要跨多系统查证、并且需要在对话中澄清、协商、决策”,就更应该用 Agent 框架,而不是纯 Workflow。
纯 Workflow 的“天花板”
Workflow 在对话中的“澄清—再决策—再行动” 并不天然友好,需要把每一步提问、回答、重试都画成节点,复杂而脆弱。
场景:用户发起:“我的包裹还没到,怎么办?”
通过Workflow创建如下智能体:(先不期待GPT-6 会自主思考的智能体)
- 意图识别智能体:识别用户诉求(查询进度/催促/投诉/报损/退货等)
- 物流状态智能体:实时拉取承运商状态,判断包裹位置、异常
- 政策规则智能体:查询当前时段政策(节假日、大促、平日),判断是否特殊处理
- 用户画像智能体:判断用户等级、历史行为、是否会员
- 异常检测智能体:分析是否有报损、拒收、欺诈等信号
- 澄清与补充智能体:信息不全时自动向用户提问,补齐决策所需信息
- 解决方案生成智能体:综合所有智能体结果,输出最优处理方案(比如:建议等待/补发/赔偿/升级处理/转人工等)
智能体数量✖️物流状态✖️用户等级✖️物流政策....你的分支会爆炸。所以需要用Dify这类的可以支持动态决策,动态推理和澄清的智能体框架。
Agent 框架解决的核心问题
以 AutoGen、CrewAI 这类 Agent 框架为例,它们把“在对话里动态规划与调用工具”作为第一性能力:
场景:用户说“我10.1买的手机现在还没到,给我退货!另外,你们的运费险的保账期是多久?”
一个合格的客服 Agent 团队会做什么?
没有路由决策,首先会动态匹配所有Query,对Query进行改写成“查询用户的订单”,“用户想要退货”,“运费险的保账范围和条款”。
- 意图识别 + 澄清
- Planner Agent:拆出多意图(物流异常、退货、计费异常、运费险条款),先问关键(订单号、地址)。
- 跨系统取证
- OMS/物流工具:查轨迹与 SLA;
- 计费/支付工具:核对重复扣款交易;
- CRM:看是否 Plus、是否有历史补偿记录;
- 保库:查询运费险
- 政策推理与合规
Policy Agent:套用“假期延误 + Plus + 运费险”的组合条款,评估可给的补偿区间、是否触发风控人工复核。
这些动作里,很多步骤无法事先“画”成固定分支,需要在对话上下文里做决策、需要跨工具动态组合、需要“问一句 → 查一下 → 再决定”,这正是 Agent 的强项。
结尾:
以上是对多智能体的总结,你会了吗?
参考:
https://mp.weixin.qq.com/s/qyCLff0WG15bEQvjodF-GQ






