




什么是实验的异质性
1. 如何理解实验结果中的指标变化
当我们看到如下试金石实验指标结果时
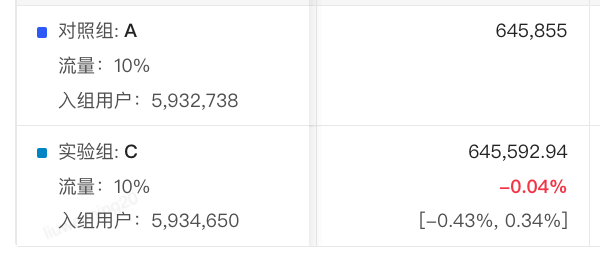
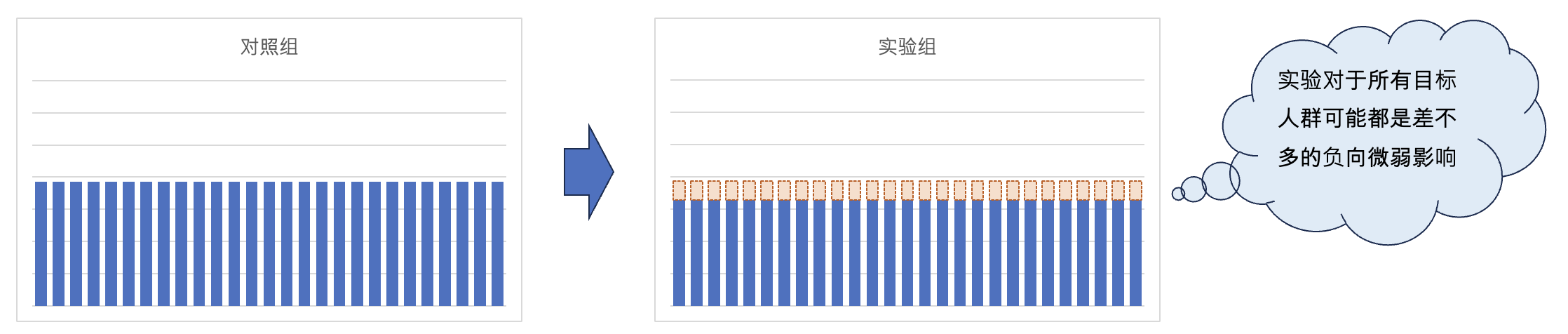
在进行分析前,可能我们的第一直觉是这样的
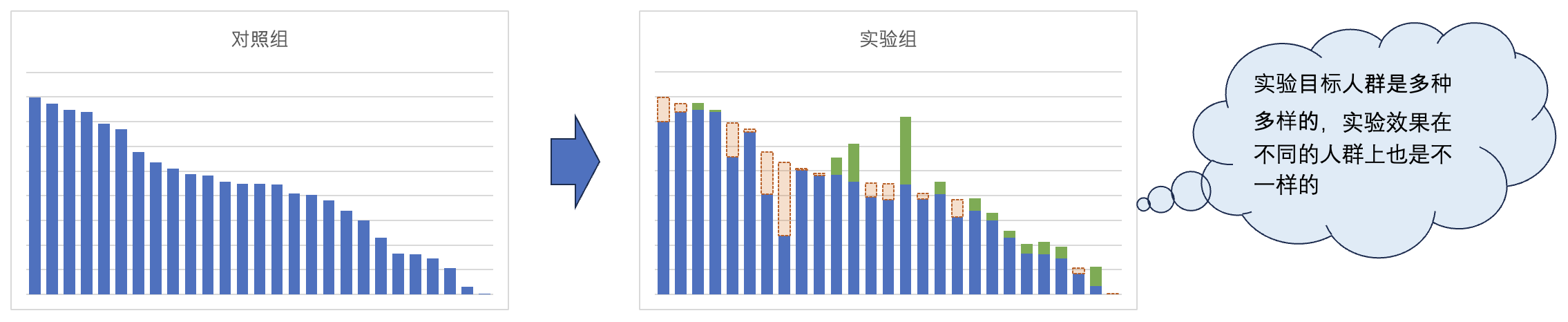
经过异质性分析后,可能会发现实际情况是这样的
2. 概念解析与定义
实验的异质性,一般被称为HTE(即Heterogeneous Treatment Effects),意为实验中同一个treatment对不同的实验样本,得到的策略效果可能是不一样的。另外还有一些重要的概念需要大家理解
| 英文简称 | 英文全称 | 中文译名 | 含义 | 公式 |
|---|---|---|---|---|
| ATE | Average Treatment Effect | 平均处理效应 | 所有实验对象的平均实验效果 | |
| CATE | Conditional Average Treatment Effect | 条件平均处理效应 | 满足一定条件的实验对象的平均实验效果 | |
| ITE | Individual Treatment Effect | 个体处理效应 | 某个实验对象的实验效果 |
* 此处采用Donald Rubin提出的潜在因果框架(Potencial outcome)来对实验效果进行统计公式上的描述 [1]
* 由于业内并没有统一的定义,HTE、CATE、ITE概念在一定程度上会有混用的情况,读者需要参考描述以及上下文综合判断名词的含义
3. 异质性分析对于业务的意义
- 了解策略对于不同用户的不同效果,协助挖掘背后的业务逻辑,辅助迭代、进行新一轮的实验
- 尝试寻找策略最优子人群,让整体无效的策略,有机会进行部分先推全;反之依然,让部分负向的策略,减少损失
- 对实验结果建模后预测,对线上提供动态的最优人群支持
根据试金石测算,以某产品线下6月运行中的35个实验为例,仅23%左右的实验没有在实验人群视角发现异质性
异质性分析方法概述
1. 异质性分析的维度选择
1. 对于分流单元的维度X,当X满足以下条件时,可以作为异质性的维度进行后续分析
- ,即分析维度与实验分流无关 (Unconfoundedness)
- 分析工具化的常见简化方式:对于一个分流ID,选取他在首次进入实验前一天的标签取值
- 简单推导:
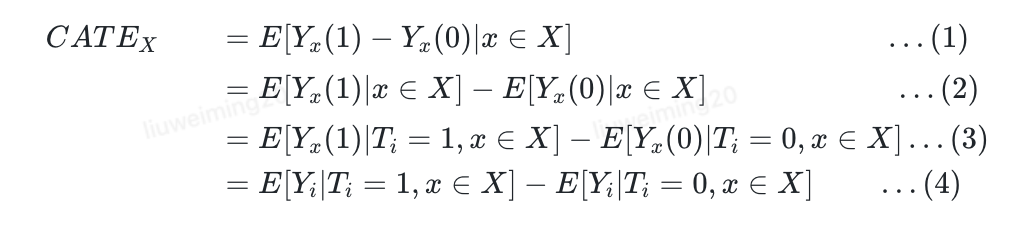
T是随机化的,,所以,所以(3)成立
2. 异质性分析的维度分析bad case举例
假设我们需要分析的实验策略为:根据用户的活跃度标签,低、中、高频用户的优惠券策略分别做了新/老策略迭代
| 分析目标 & 常见错误方法举例 | 不成立原因简述 | 推荐的实验分析方式 |
|---|---|---|
| 不同活跃度人群的策略效果 在实验运行7天后,利用实验用户在第7天的活跃度标签进行结果拆解 | 在实验开始后,用户的活跃度标签受到了策略影响,即T⊥X不成立 | 使用用户在进入实验前1天的活跃度标签值 |
| 分别分析低频策略、中频策略、高频策略对于低、中、高频用户的策略效果 按天取每天用户的活跃度标签,对实验结果进行拆解 | 用户的活跃度标签受到了策略影响,即T⊥X不成立 ·用户所在分组应该是确定的,不随时间改变 | 分别建立3个人群正交实验 |
| 分析高单价类目商品(3C家电)和低单价类目商品(休闲食品)的转化率差异 选取xx类目曝光用户,计算实验周期内对应类目的曝光订单转化率 | 分析目标是面向指标维度的(sku所在类目),而非分流单元的维度(C端实验通常为账号、设备),不适用本文提到的异质性分析方法 | 试金石现已支持指标维度下钻 曝光订单转化率的分子、分母均受到策略影响,需在观测全面后综合判断 |
2. 异质性分析的方法选择
| 研究对象 | 研究方法 | 适用场景 | pros & cons |
|---|---|---|---|
| CATE | 维度下钻 | ·低维 ·分析目标明确 | + 快速简单,便于理解 + 产品化容易 - 维度选择依赖分析师经验 - 交互效应处理困难 |
| 方差分析(ANOVA,ANCOVA) | ·低维 ·分析目标较明确 ·交互效应评估 | + 解释性强,统计学理论背书 + 可以处理低维度交互效应 + 可作为feature selection的候选方法 - 基于线性模型假设 - 高维度交互效应解读困难 | |
| 因果树(Causal Tree) | ·高维 ·分析目标不明确,希望探索 | + 建模方法符合分析直觉 - 模型复杂度不足,无法准确描述复杂的现实世界效果 - 本方法为现代机器学习因果算法的基石之一,有更好的替代方案 | |
| ITE | Meta - Learner | ·高维 ·希望输出ITE ·算法训练 | + 算法常用,可大规模并行,有工程化先例 + 在过往的simulation中X-learner对ITE估计的准确度表现优秀 + X-learner通常使用xgboost模型,对各种feature有较强的处理能力 - 计算量大,耗资源 - 需要调参 - 由于缺乏统计推断结果,一般不会直接产出p-value,存在对于ITE数值准确性的质疑,算法利用结果的rank居多 |
| DML | ·高维 ·希望输出ITE和置信区间 | + 有严谨统计理论证明ITE估计的无偏有效性,可产出样本级的ITE以及置信区间 + 在过往的simulation中Causal Forest DML对ITE估计的准确度表现优秀 + DML模型框架本身具备一定的robust特性,在结合Forest模型后,调参需求低,不容易过拟合,对各种feature有较强的处理能力 - 慢,耗资源,工程化先例少 | |
| ITE + CATE hybrid | ITE Model + Decision Tree Interpreter | ·高维 ·分析目标不明确,希望探索 | + 决策树的建模方法符合分析直觉 + ITE模型可以较好的对复杂的现实世界进行抽象总结 - ITE模型可能会慢 |
* CATE、ITE建模方法的细节可参考Appendix
CATE下钻探索工具MVP版逻辑介绍
项目地址:http://xingyun.jd.com/codingRoot/abtest_ds/CATE_model
模型逻辑:多维度的维度下钻 + Decision Tree Interpreter
快速开始:
from CATE_model.utils.workflow import CateWorkFlow
yaml_path = 'config.yaml' # 按分析要求配置YAML文件
cate_workflow = CateWorkFlow(yaml_path) # 初始化CATE对象
cate_workflow.prepare_analysis() # 初始化ABTestAnalyzer
cate_workflow.execute_cate_auto() # 自动执行所有环节
cate_workflow.df_out.styler # 输出CATE差异最大子人群目标指标统计项目基本流程
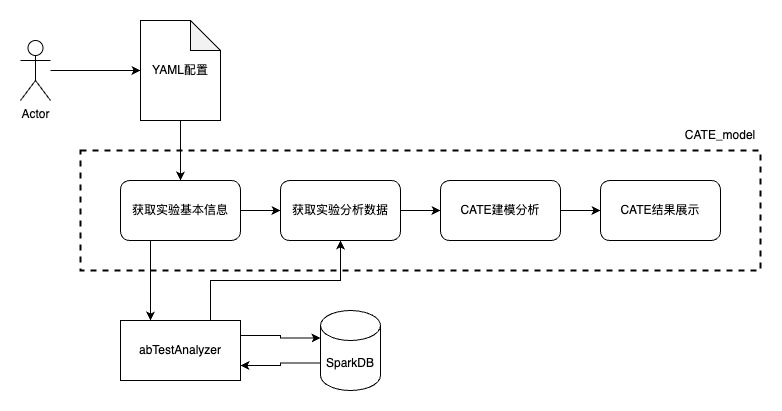
YAML配置方法:第一次可以先根据项目demo修改,并参考YAML配置说明.md
项目MVP功能说明
- 通过填写YAML配置,自动生成实验分析SQL,并执行取数,目前包括
- 自动获取试金石实验分流信息
- 自动获取试金石实验指标信息
- 解析实验CATE研究使用的用户标签表
- 自动生成所有数据源的关联关系
- 为实验CATE研究提供自动化工具,目前包括
- 自动化生成实验目标指标的CATE差异最大化子人群
- 提供调参接口,高级用户可自定义模型参数
- 提供可视化的模型结果输出,高级用户可根据输出调节模型表现
- 为实验的下钻分析提供探索、分析功能,目前包括
- CATE人群的实验效果统计检验
- CATE人群的多指标拆解
- CATE人群的特征描述
实验异质性分析show case
针对近期某频道重点改版实验,此项目整体实验指标为负向不显著,但通过运行分析工具后发现,有两类子人群分别具有正向和负向的显著效果
| 实验HTE人群统计 |
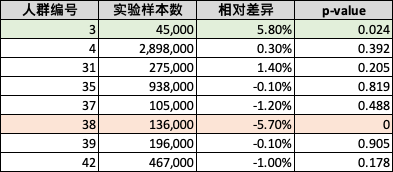 |
对于这些子人群,我们发现他们在业务漏斗上的变化并不一样,那么下次对于频道进行迭代时,产品经理可以整理有针对性的选择对负向人群进行针对性的优化
| 人群编号 | 用户画像总结 | 频道uv | 点击uv | 加车uv | 转化订单数 |
|---|---|---|---|---|---|
| 3 | 年轻人,低活跃 | 1.0% | 2.2% | 2.6% | 5.8% |
| 38 | 非年轻人,高线城市,plus用户 | -2.2% | -2.2% | -3.1% | -5.7% |
未来展望
- 自定义分流表
- 自定义画像表 & 经海路画像表
- CATE模型迭代
- 通用维度配置模版 & 业务场景模版
- 图形化交互界面,简化输入配置
Appendix & 参考资料
【1】因果分析框架 & Donald Rubin的Potencial Outcome
- Potencial Outcome
- 设代表第i个样本是否收到了处理(treatment,策略影响),是为1,否为0
- 代表个体i的结果,另外记为个体i接受处理、对照的潜在结果
- 每个个体通常只会有1个状态,个体因果作用无法直接观测,我们只有
- 在随机化实验的场景下,我们可以得到
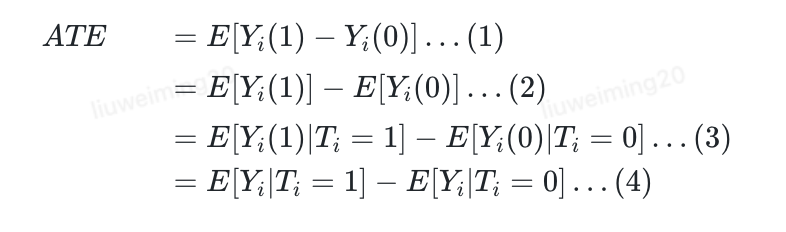
其中最重要的逻辑为:
T是随机化的,,所以,所以(3)成立
- 因果推断(一):因果推断两大框架及因果效应:https://zhuanlan.zhihu.com/p/652174282
- 因果推断简介之二:Rubin Causal Model (RCM) 和随机化试验:https://cosx.org/2012/03/causality2-rcm/
【2】ANOVA与CATE的交互效应分析
当需要进行异质性分析的维度为X时,我们可以通过构建下列回归方程去描述X在实验中是否存在显著的异质性,当对应的F-test显著时,我们就可以认为实验在维度X上存在显著的异质性
当时,我们可以用下图来进行异质性的理解
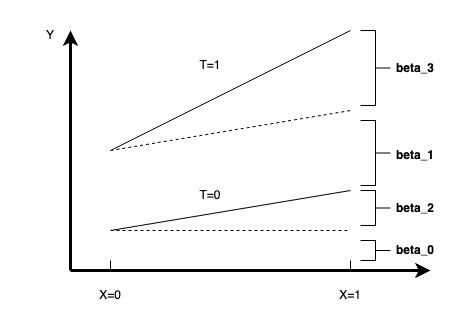
【3】CATE & ITE估计
idea1:对于每个参与实验的对象i,如果能得到和的合理估计,那么ITE就可求了
idea2:对于实验人群X,如果能找到一种观测方式,求得,那么CATE就有了
- Meta Learner的极简介绍
- S-Learner
- stage1: 利用模型估计
- stage2: 定义CATE结果如下
- T-Learner
- stage1: 利用两个模型,分别估计
- stage2: 定义CATE结果如下
- X-Learner
- stage1:利用两个模型,分别估计
- stage2:实验组、对照组数据交叉拟合构造
- stage3:定义CATE为模型估计值的加权平均,权重来自于在condition x下实验组、对照组的样本比例
- 更多资料参考uber的causalML项目:https://causalml.readthedocs.io/en/latest/methodology.html
- Causal Forest的极简介绍
- 如果将普通决策树算法的叶子分裂准则从最小化整体的MSE,替换为最大化叶子结点的CATE差异,那么根据贪心算法,我们可以得到一个拆解CATE的Causal Tree(还有很多保证样本平衡、估计可靠的weighting和honest的方法细节没有介绍)
- 为了克服一棵树带来的high variance,仿照random forest,构建由Causal Tree组成的森林,并且我们可以通过观察在不同树中样本是否被多次划入一个叶子结点来调节本样本对当前叶子估计的权重,最终得道一个可以产出ITE估计的森林模型
- DML的极简介绍
- 我们定义为CATE,那么构建下列函数
- stage1: 拟合g、f函数,求得残差
- stage2: 拟合残差,求得CATE估计
- 如果我们将上述double ML的过程用GMM的方式写成矩函数,
那么根据Neyman orthogonality condition,我们可以证明此过程估计的在大样本下具备无偏一致性,此特性与在一定程度上没有关系
- 关于doubly robust,R-learner,CausalForestDML等方法呢?是否有理论框架能总结这一类利用残差进行推断的方法呢?参考:Orthogonal Statistical Learning Arxiv:1901.09036V3
- 更多关于DML、CausalForest资料请参考微软的EconML项目:https://www.pywhy.org/EconML/spec/overview.html





