



一、Elastic认证技术专家考试概述
1.1什么是Elastic认证技术专家考试
Elastic认证技术专家Elastic Certified Engineer简称ECE是Elastic官方的技术认证考试,用来验证考生在Elasticsearch集群部署、数据管理、搜索优化及运维等方面的能力,通过后会获得一个电子证书,有考生名字、证书编号、签发日期等,签发人是Elastic公司首席执行官(CEO)Ash Kulkarni和首席技术官(CTO)Shay Banon,同时官网验证平台会展示资质用来核实,具体如下:

考试通过后颁发的证书
https://certified.elastic.co/a5faf01a-80b7-471d-8dc1-2ece3f65db53#acc.0CJqAH2Zhttps://certified.elastic.co/a5faf01a-80b7-471d-8dc1-2ece3f65db53#acc.0CJqAH2Z
官网验证信息地址
ECE在2018年06月首次发布,从6.5版本到8.15版本,经历5次变化,每次都贴合自身演进以及行业需求,6.5强调集群搭建、索引管理,7.2侧重安全配置、角色控制、复杂查询,8.15推广索引生命周期管理、数据快照等,这种导向使考生尽量适应实际挑战。
| 版本号 | 开始时间 | 结束时间 | 持续时长(天) |
|---|---|---|---|
| 6.5 | 2018年06月29日 | 2019年08月05日 | 402 |
| 7.2 | 2019年08月06日 | 2021年06月30日 | 694 |
| 7.13 | 2021年07月01日 | 2022年08月03日 | 398 |
| 8.1 | 2022年08月04日 | 2025年01月23日 | 904 |
| 8.15 | 2025年01月24日 | 现在 | 待定 |
1.2这门考试可以带来的收益
技术影响力提升:作为Elastic公司推出的权威考试,其标准由Elastic核心团队制定,在全球范围内被互联网、金融、电商等行业认可,Elasticsearch是目前最主流的搜索引擎和数据分析引擎之一,在整个技术生态中相对算硬通货。
职业背书与信任加成:考生需要掌握复杂查询、集群管理、分片机制、副本策略等深度知识,同时考察方案否完整和有效,评判标准带主观因素,死记硬背较难通过,导致通过率较低,截止2025年7月全球通过3400多人,中国仅通过数百人,间接提升了证书的‘稀缺性‘和’含金量’。
以考促学倒逼个人成长:需要系统梳理,并对部分知识专项学习,扫除盲区,将知识串联形成完整知识体系,后续可快速找到对应知识点,同时高强度学习后通过考试,也可获得较高成就感。
1.3考试的流程、费用、形式等
1.3.1考试流程
共计4步,注册报名、考试时间预约、参加考试、结果通知

1.3.2注册报名:
考试介绍、考纲、报名均在这里:
https://www.elastic.co/cn/training/elastic-certified-engineer-exam
有考试主题、考点范围、考试时长等,报名时尽量选带拼音的护照,因为在身份验证环节监考官不懂中文,沟通相对麻烦,其次考试费用起初是400美金,近两年上涨到了500美金,按汇率折合人民币3600多元,未通过不会退款,也不能补考,试错成本较高,建议准备充分后再报名,避免资金浪费,同时准备好信用卡例如Visa、MasterCard、银联等方便使用。
1.3.3预约考试时间
报名后可预约未来365天内任意1天,也就是并不会组织统一考试,考生根据自己时间安排,充分体现了西方世界的‘松弛感’。

预约成功后的通知邮件

考试现场的部分要求
1.3.4参加考试
不用去外地,有一个安静的房间即可,这点很方便,到时间后登录系统,首先上传护照录入身份、人脸验证及用摄像头环绕录制现场确保周围没人,桌上仅允许放一瓶水,可申请外接显示器,但必须禁用原屏幕,也就是只有一块屏幕,全程会有摄像头监控防止作弊,期间有问题可用内置聊天工具与监考官交流,但对方不懂专业知识仅提供IT支持,语言问题可用它的翻译网站。
开卷考试,但不能上外网包括百度、谷歌等,考生根据题目要求在官方文档找到对应的样例进行改造,限时3个小时,顺利的话大概1个半小时就能完成,共10-12道题,形式包括集群配置、API操作(Kibana devTools)、问答类(填写DSL语句)等,没有选择、填空,均为实操类。
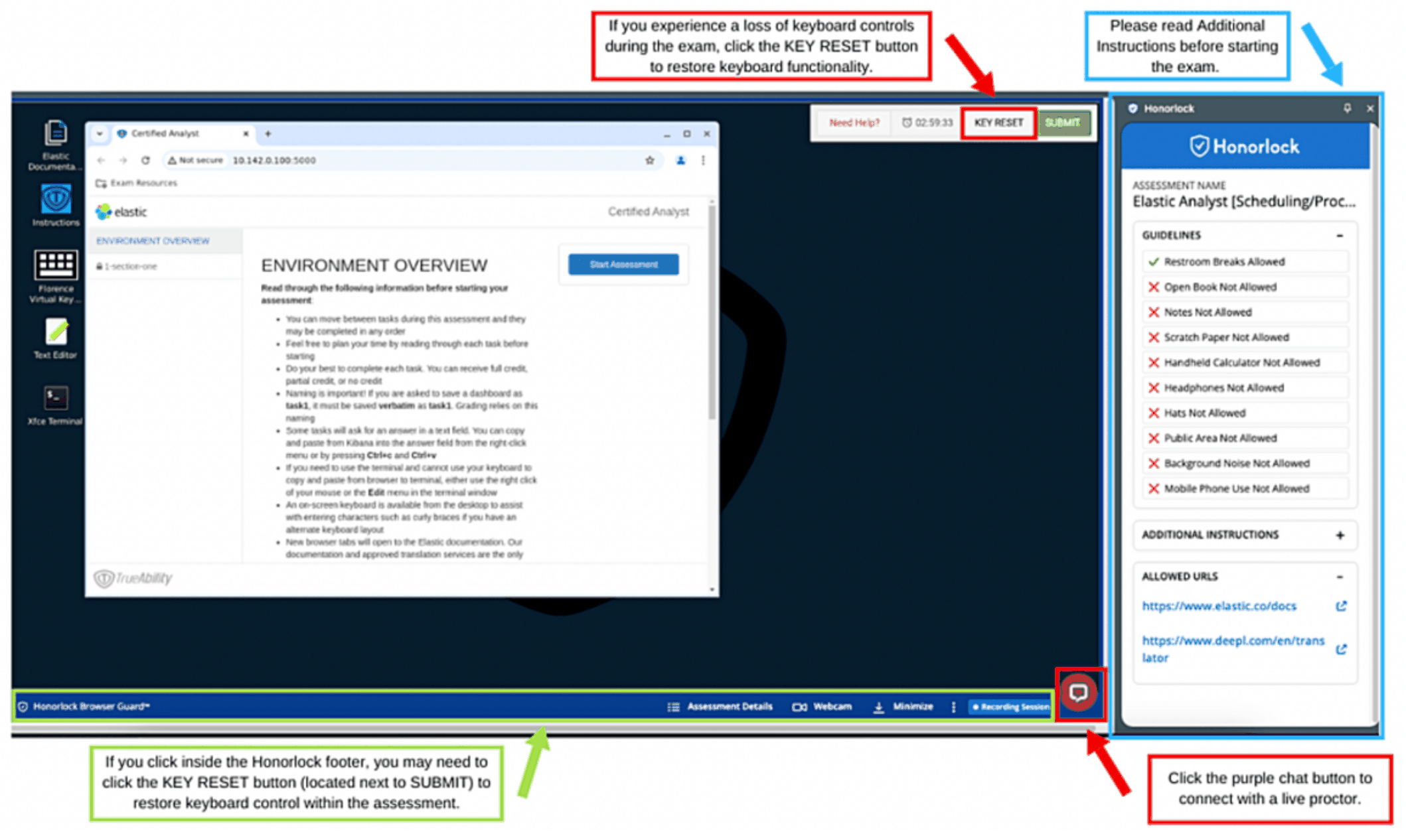
利用浏览器远程访问集群,期间有问题可与技术支持沟通
考试环境检测网站:https://webcammictest.com/
考试可使用翻译网站:https://www.deepl.com/zh/translator
1.3.5发放结果
考后一周无论成功与否均会邮件通知,通过了先是表示祝贺并明确给一个PASS,不通过会表示遗憾并鼓励再次考试。
二、知识点脉络梳理
考纲有5个部分共25条要求,可按这些方向复习,节选部分内容:
| 序号 | 部分 | 考纲具体要求 |
|---|---|---|
| 1 | Data Management 数据管理(共4条) | 1、Define an index that satisfies a given set of requirements 2、Define and use a dynamic template that satisfies a given set of requirements等 |
| 2 | Searching Data 数据搜索(共7条) | 1、Write and execute a search query for terms and/or phrases in one or more fields of an index 2、Write and execute a search query that is a Boolean combination of multiple queries and filters 3、Write an asynchronous search等 |
| 3 | Developing Search Applications 复杂数据搜索(共3条) | 1、Sort the results of a query by a given set of requirements 2、Implement pagination of the results of a search query 3、Define and use index aliases |
| 4 | Data Processing 数据处理(共5条) | 1、Define a mapping that satisfies a given set of requirements 2、Define and use multi-fields with different data types and/or analyzers 3、Use the Reindex API and Update By Query API to reindex and/or update documents等 |
| 5 | Cluster Management 集群管理(共6条) | 1、Diagnose shard issues and repair a cluster's health 2、Backup and restore a cluster and/or specific indices 3、Configure a snapshot to be searchable等 |
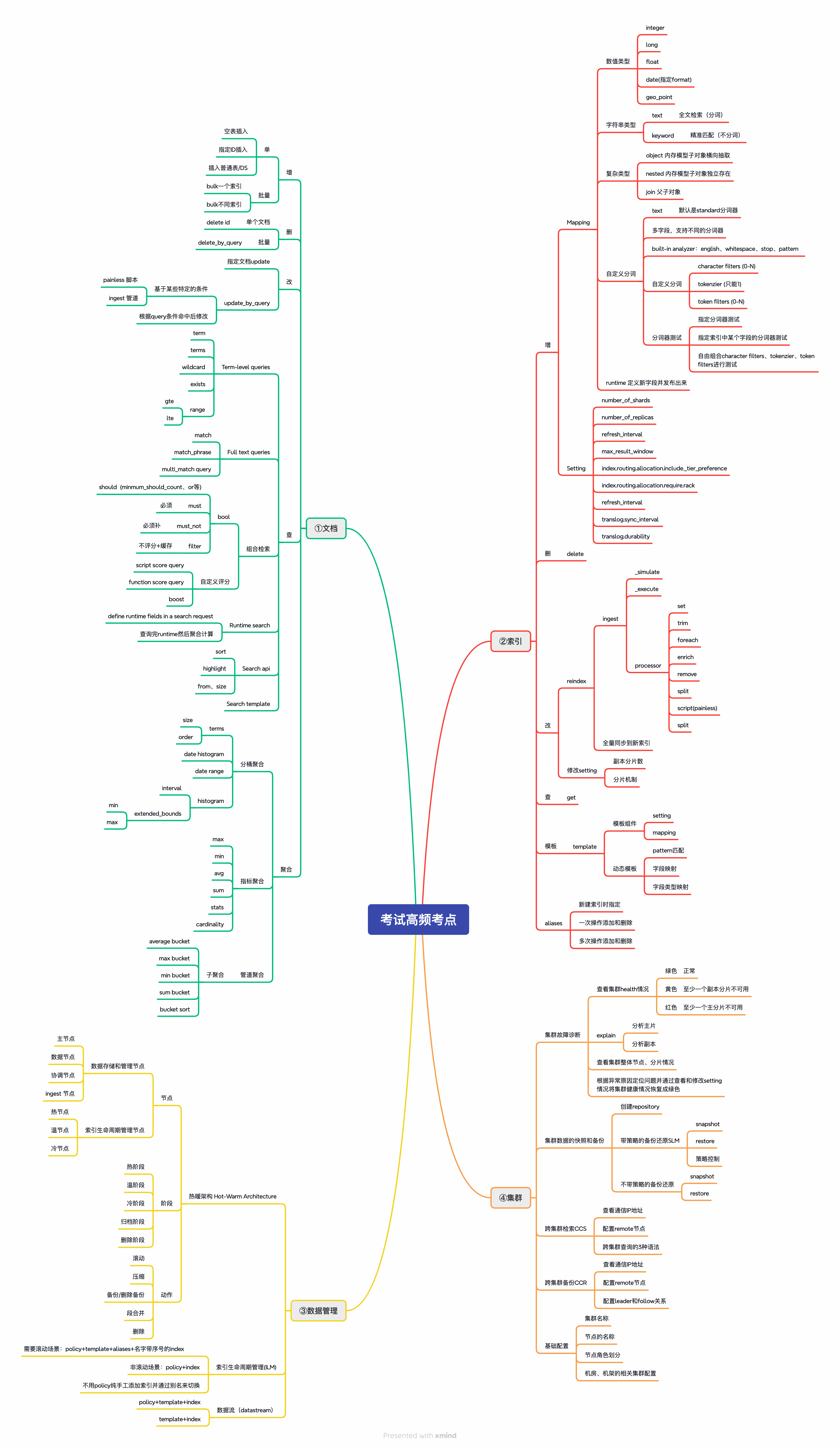
考纲虽然给了方向但相对较泛,举个例子‘Write and execute metric and bucket aggregations’,意思是‘书写并执行指标聚合和桶聚合’,短短几个字,备考时却发现指标聚合和桶聚合加在一起有50多个命令,每个命令都有它不同的参数,命令和参数组合起来又有很多变化,这导致备考范围非常大,需要很多时间,本文在考纲的基础之上根据作者经验总结出来高频、核心的具体命令,用思维导图将这些知识点分类串联,方便读者阅读,共140+个知识点,主要包括文档、索引、数据管理、集群4大模块,基本可覆盖考试范围,具体如下:
三、核心知识点讲解及模拟题解析
为平衡讲解深度和阅读精力,本文对部分知识深度解读,同时考虑到版权问题,以模拟题的形式呈现,方便读者对考试有一个大体感受。
3.1考题一:综合搜索
write a single search query for the movies index on cluster1 that meets the following requirements:
1、at least one of the fields (title, overview, tagline) contains the keyword "Batman"
2、the matching score for the title field should be boosted with a factor of 4
3、documents containing keywords Action can get higher score
In the text field below, provide only the JSON portion of your search requestØ 题目分析:
要求在cluster1集群的movies写一个DSL指令,考试时需要仔细选对集群,具体要求如下:
1、至少一个字段(title、overview、tagline)包含关键词‘Batman’,这是一个硬性筛选条件,意味必须命中才能搜到。
2、title字段的匹配得分要乘以4倍系数,让title中包含‘Batman’的文档更靠前。
3、字段keywords包含‘Action’关键字的文档应获得更高的相关性分数,这是在基础筛选之上让特定文档分数更高。
Ø 相关知识点详解:
1)function_score查询
在基础查询上自定义得分逻辑,通过functions添加多种得分调整规则(加权重、衰减函数等),适合需要精细化控制相关性排序场景,其作用是打破默认TF-IDF,按业务强化特定权重。
2)filter与match的区别
filter相对match仅用于筛选文档,不参与得分计算,可缓存结果,因而效率更高。
3)boost_mode参数
控制基础得分与函数得分的组合方式:
multiply:基础分×函数分,适合需要显著放大权重的场景。
sum:基础分+函数分,适合温和提升得分的场景。
4)multi_match多字段匹配
通过fields参数中的^n语法为特定字段设置权重,可将该字段得分乘以n后再参与计算,将重要字段优先排序。
Ø 解题思路:
针对movies索引查询,核心目标是筛选出含‘Batman’且突出‘Action’关键词的文档,具体如下:
基础筛选层(query子句)核心使用multi_match语法实现‘至少在title、overview、tagline字段中匹配Batman’的要求,同时通过title^4为title字段设置4倍权重,确保title出现‘Batman’的文档基础得分更高,这一层是准入门槛。
得分优化层(functions子句)通过function_score的functions数组添加额外得分规则,用filter筛选出keywords字段包含‘Action’的文档,这一步不影响基础分,仅作为加分,为符合条件的文档赋予weight10,即额外增加10倍权重,通过boost_mode的multiply模式将基础得分与额外权重相乘,显著提升含‘Action’关键词的文档总得分,外层boost的1表示不对整体结果额外缩放,保持得分计算原始比例。
Ø 参考答案:
GET movies/_search
{
"query": {
"function_score": {
"query": {
"bool": {
"must": [
{
"multi_match": {
"query": " Batman’",
"fields": [
"title^4",
"overview",
"tagline"
]
}
}
]
}
},
"functions": [
{
"filter": {
"match": {
"keywords": "Action"
}
},
"weight": 10
}
],
"boost": 1,
"boost_mode": "multiply"
}
}
}3.2考题二:数据处理
There is an index named movies and another index movies_poster containing poster_path for each movie.
Please reindex movies to a new index satisfying the following requirements.
1、the new index name is task3
2、task3 has same fileds with movies index
3、split field keywords to array and store it to keywords_list field with type keyword
4、add a new field number_of_keywords which is the length of keywords_list
5、add poster_path field from movies_poster to task3 indexØ 题目分析:
Movies表存储标题、粉丝数、发行时间等,movies_poster表存电影海报poster_path字段,两表之间用id字段关联,需要创建新索引task3,通常新建索引都跟题目编号保持一样,所以当时这道题应该是第3题,同时必须完整保留movies索引的全部原有字段,需要对movies中的keywords字段按特定分隔符拆分为数组,存储到新的字段keywords_list中,且该字段类型需定义为keyword以支持精确匹配,新增number_of_keywords字段来存储keywords_list的数组长度,最终还需提取movies_poster索引中poster_path字段并整合到task3中,实现跨索引的数据关联。
Ø 相关知识点详解
1)Enrich策略
通过enrich的policy建立源索引与目标索引的关系,从source索引提取字段并添加到目标文档中,解决跨索引字段融合问题,其思想如下:
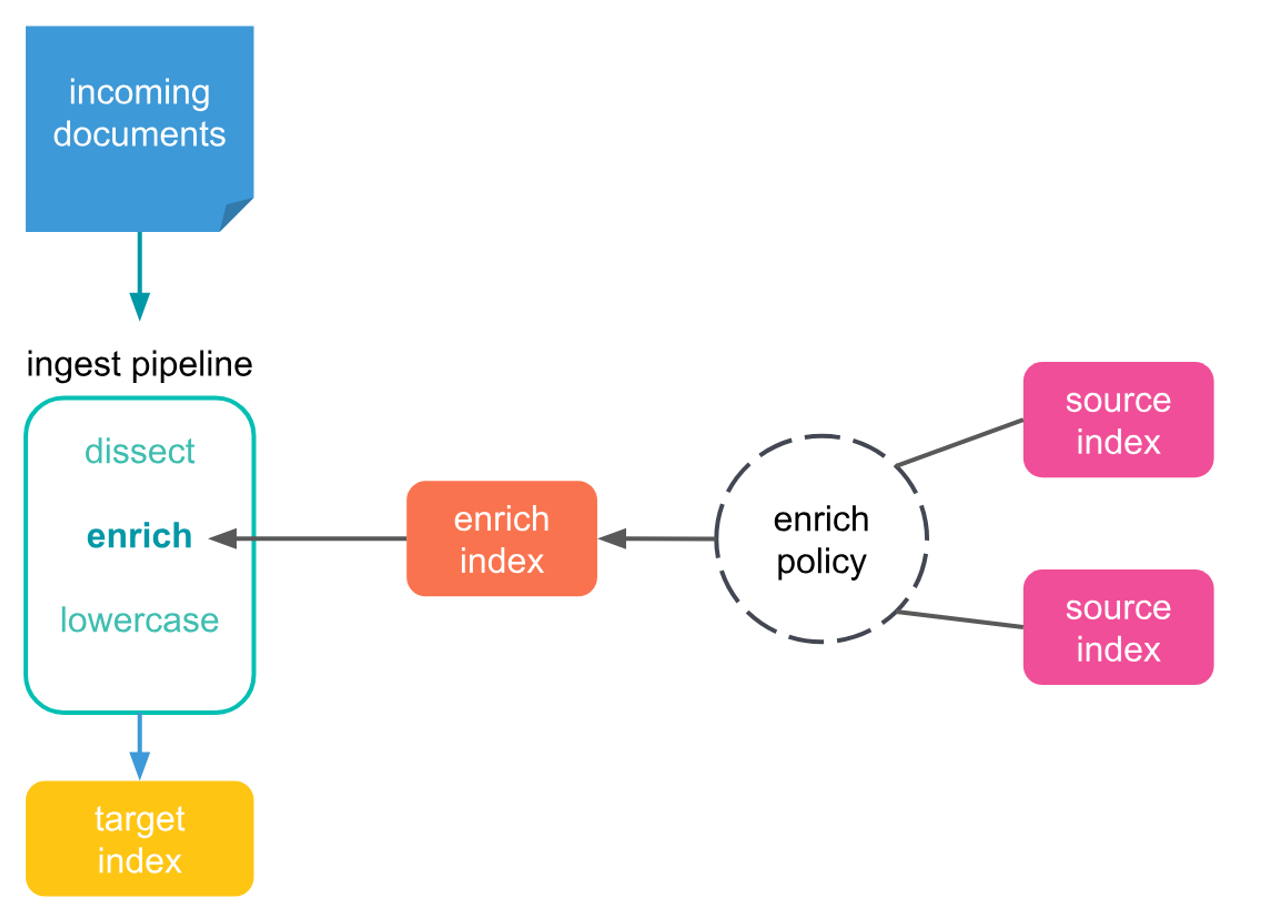
2)Ingest Pipeline 管道
用于数据预处理,可包含一系列处理器processor,如拆分字段、新增计算字段等,在本题中,这个工具是处理数据的一个利器。
3)Reindex API
Elasticsearch中修改数据有reindex、update_by_query等,reindex可实现本索引修改,也可以实现将一个索引复制到一个新索引中。
Ø 解题思路:
其中较难的应该是enrich这个知识点,有部分读者朋友可能平时用的不多,先创建enrich的一个policy,指定source索引为movies_poster并关联上movies索引,匹配字段为ID,提取poster_path字段,执行policy后将movies_poster数据加载到enrich索引中,生成可供查询的关联数据并拿到句柄对象,为后续pipeline获取poster_path提供基础。
创建Ingest Pipeline通道,添加split处理器将keywords字段按分隔符拆分为数组,存储到keywords_list字段,同时添加script处理器,通过脚本计算keywords_list的长度,赋值给number_of_keywords字段,需要考虑判空问题,虽然不会明说但需要考生自己发现并处理,最后使用上一步创建的enrich处理器来提取poster_path字段。
手动创建task3索引,不能直接用reindex,因为字符串在默认创建方式下的类型不一定和预期一样,所以一定要手动将movies索引的原有字段映射复制过来,并新增 keywords_list(keyword 类型)、number_of_keywords(integer 类型)、poster_path(keyword类型)的字段,确保字段类型符合要求,最后使用reindex指令将movies索引复制到目标索引task3,同时在reindex请求中指定上一步中创建的pipeline,使数据在迁移过程中经过管道处理。
创建后一定要验证结果,确保task3索引中包含movies原有字段、正确拆分的keywords_list、准确的number_of_keywords,及从 movies_poster关联的poster_path等。
Ø 参考答案:
第一步:创建一个enrich策略
PUT /_enrich/policy/movies_poster-policy
{
"match": {
"indices": "movies_poster",
"match_field": "id",
"enrich_fields": ["poster_path"]
}
}第二步:执行enrich策略
POST /_enrich/policy/movies_poster-policy/_execute第三步:模拟执行pipeline,防止出现问题,这一点很重要
POST _ingest/pipeline/_simulate
{
"pipeline": {
"processors": [
{
"enrich": {
"policy_name": "movies_poster-policy",
"field": "id",
"target_field": "poster",
"max_matches": "1"
}
},
{
"set": {
"field": "poster_path",
"value": "{{{poster.poster_path}}}",
"if": "ctx.poster != null && ctx.poster.poster_path != null"
}
},
{
"remove": {
"field": "poster",
"if": "ctx.poster != null && ctx.poster.poster_path != null"
}
},
{
"split": {
"field": "keywords",
"separator": ",",
"target_field": "keywords_list"
}
},
{
"script": {
"lang": "painless",
"source": """
if(ctx.keywords == ""){
ctx.keywords_list = []
}
ctx.number_of_keywords = ctx.keywords_list.length;
"""
}
}
]
},
"docs": [
{
"_source": {
"overview": "The film follows one day in the lives of the Tyrone family, each member is troubled and has been damaged by alcohol and/or drugs. In addition, they have issues with each other that lead to fights and an inability to reconcile completely with one another.",
"keywords": "Drama,History",
"directors": [
"Sidney Lumet"
],
"rating": 6.9,
"title": "Long Day's Journey Into Night",
"revenue": 0,
"release_date": "1962-10-09T00:00:00Z",
"tagline": "PRIDE...POWER...PASSION...PAIN!",
"id": "43004",
"vote_count": 25
}
}
]
}第四步:真实创建管道
PUT _ingest/pipeline/fix_movies
{
"processors": [
//参考上一步中的写法,为节省篇幅,此处省略。
]
}第五步:新建task3索引,将movies中的映射粘贴过来,并新增相关字段
PUT task3
{
"mappings" : {
"properties" : {
"keywords" : {
"type" : " keyword ",
"analyzer" : "english"
},
"keywords_list": {
"type": "keyword"
},
"number_of_keywords" : {
"type" : "integer"
},
"poster_path" : {
"type" : "keyword"
}
……忽略部分字段
}
}
}第六步:通过reindex指令将数据导入到新的索引中
POST _reindex
{
"source": {
"index": "movies"
},
"dest": {
"index": "task3",
"pipeline": "fix_movies"
}
}3.3考题三:数据生命周期管理
Define a new data stream on cluster1 that meets the following requirements:
1、the index pattern of the data stream is solar-metrics-*
2、the associated ILM policy name is task12-policy
3、the corresponding index template name is task12
4、data is initially allocated to the data_hot tier and remains there for the first 3 minutes, after which it rolls over and moves to the data_warm tier
5、data stays in the data_warm tier for 10 minutes before being migrated to the data_cold tier
6、data is deleted 15 minutes after the rollover operation is completedWhen your data stream is created, index the following document.
POST solar-metrics-task12/_doc
{
"@timestamp":"2023-11-12T02:12:32.000Z",
"count": 12
}Ø 题目分析:
随着数据量增加,如不能有效管理则系统会出现性能、稳定性等问题,但大部分场景数据并不是一直很热,例如微博的帖子随着时间推移热度逐步下降,浏览量、点赞等操作频次也会下降,面对此类时序数据场景,数据流Data Stream应运而生,从此索引并不是唯一选择,也可以考虑新建数据流,索引和数据流是平级关系,本题要求定义一个数据流,匹配索引名称是solar-metrics-*,关联的ILM policy为task12-policy,对应索引模板名为task12,数据生命周期管理处理hot、warm、delete等阶段。
Ø 相关知识点详解
1)数据数据流(Data Stream)
存储时序数据如log、metrics的抽象层,由多个隐藏索引组成,支持自动滚动rollover,适合持续生成的时序数据管理。
2)索引生命周期管理(ILM)
定义索引从创建到删除的全生命周期阶段(hot/warm/cold/delete等),可配置各阶段的留存时间、迁移节点等。
3)索引模板(Index Template)
预定义索引的映射mapping、settings及关联的ILM policy等。
4)节点层级(Tier)
按数据热度划分的节点角色(data_hot/data_warm/data_cold),hot用于高频写入和查询,warm/cold用于存储低频访问数据,通过ILM实现数据按生命周期在不同tier间迁移。
5)滚动(Rollover)
数据流的关键操作,当满足条件(如时间、文档数)时,创建新的隐藏索引,旧索引进入下一生命周期阶段。
Ø 解题思路:
其实ILM不一定需要policy只是有的话更方便,而本题需创建policy的,定义生命周期阶段hot阶段配置滚动触发条件为3分钟,随后数据分配至warm阶段,留存10分钟后进入到cold阶段,最后15分钟后数据被删除,这里比较绕的是min_age(最小年龄)和max_age(最大年龄),min_age表示索引必须在当前阶段至少停留的最短时间,是进入下一阶段的最低门槛,确保索引有足够时间完成当前任务(如数据写入、聚合分析等),避免过早进入下一阶段(如冻结、删除),max_age表示索引在当前阶段允许停留的最长时间,是强制进入下一阶段的上限约束,防止索引在某一阶段无限停留。
其次使用索引模板正则匹配solar-metrics-*,配置中务必添加‘data_stream: {}’关键字,否则无法生效,在settings中关联ILM policy,指定优先进入hot,并通过PUT _data_stream/solar-metrics-* 创建数据流,此时数据流会自动应用索引模板。
最后插入一条数据,并通过相关指令来验证是否生效,确认各阶段的tier迁移时间、滚动触发条件及删除时间是否正确。
Ø 参考答案:
第一步:创建ILM policy
PUT _ilm/policy/task12-policy
{
"policy": {
"phases": {
"hot": {
"actions": {
"rollover": {
"max_age": "3m"
}
}
},
"warm": {
"min_age": "0s",
"actions": {}
},
"cold": {
"min_age": "10m",
"actions": {}
},
"delete": {
"min_age": "15m",
"actions": {
"delete": {}
}
}
}
}
}第二步:创建索引模板,关联ILM policy
PUT /_index_template/task12
{
"index_patterns": [
"solar-metrics-*"
],
"data_stream": {},
"template": {
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0,
"index.lifecycle.name": "task12-policy",
"index.routing.allocation.include.box_type":"hot"
}
}
}第三步:添加一条数据
POST solar-metrics-task12/_doc
{
"@timestamp":"2023-11-12T02:12:32.000Z",
"count": 12
}第四步:验证相关参数是否正常
GET solar-metrics-task12/_search
GET _cat/indices/solar-metrics-task12*
GET _cat/shards/.ds-solar-metrics-task12-*
GET _data_stream/_stats
GET solar-metrics-task12/_ilm/explain 四、考试哪里难
4.1整理有效备考材料难
备考知识点众多,每个点均需要认真梳理和反复实践,虽然有官方考纲,但是整理出有效的备考资料相对有一定难度,包括具体考题形式、知识点串联关系、完整解决方案等,网上大部分都是一些碎片化信息,甚至有一些资料已经过期,目前被整理好的材料也都是一些收费社区或组织垄断,并未公开,本质上讲这个考试还是西方舶来品,来到中国时间不长,属于小众考试,没有形成行业标准。
4.2考试环境难以搭建
考试均为实操题,因而就需要搭建本地环境进行验证和练习,单机版还算简单,但后期集群版还是需要一定的运维能力,这期间我经历到的问题有MAC电脑的网络安全问题导致集群无法形成、设置的集群分片策略影响后边的索引创建、本地磁盘超出水位线等,这会耗费一定时间。
4.3需要较强的自控力,坚持较难
这个考试跟高考不在一个维度上,全身心复习大概需要20天,200小时,通常IT技能考试都不会很难,但依然需要较强的自控力,面向年轻朋友,可能时间宽裕但或多或少有一定程度拖延,个人自控力也不同,这种情况建议用学习小组,美国宪法之父詹姆斯 麦迪逊提出‘如果人都是天使,就不需要政府,如果是天使统治人,就不需要对政府监管’,这一思想为三权分立奠定基础,所以互相监督还是有效的,另一类上班族,我备考过程中认识的‘战友’有小孩父母、团队leader、甚至还有挺着肚子的孕妈,每天缠着很多琐事,再抽出时间是很难的,这种情况可运用《毛选》第二卷中的论持久战军事思想,如不能速生,那就利用零打碎敲的时间逐个攻破知识点,用小型战役消灭敌人有生力量,积小胜为大胜,逐步改变敌我力量对比,夺取最终胜利。
4.4考试前、后没有人和机制来衡量学习效果,及时纠偏难
由于不同知识点需要学到的程度不同,但缺乏有效反馈机制就很难检验当前学习效果,例如像match、term、must这些是有固定的逻辑关系,这些原理是透明的,而一些运维的知识,如配置集群设置分片的偏好,‘它是让集群做一些感知行为,而不是具体动作,我们只能影响它,却无法控制它’,这个在考前就不太好评判应该学到什么程度,同时考后不会提供任何细节及评分标准,也就是说很有可能自己认为答的还可以,但其实是不对的,但是又不知道自己改进方向是什么,这两条就导致很难及时纠偏。
五、如何正确看待认证考试的作用和价值
考试通过了就证明自己很厉害吗,可以证明自己把Elasticsearch都掌握透彻了吗,答案是否定的,任何学科的知识都是非常庞杂和深奥的,学海无涯,永无止境,考试通过只能证明自己对Elasticsearch的70%高频知识点掌握,可以应对日常的开发工作并具有解决一定复杂度问题的能力,但是相对比较深入的知识,包括底层存储模型、性能优化、安全机制等知识点还需要持续学习,后边依然需要保持空杯心态,谦虚低调,不能因为一个证书就止步不前。
六、通过考试引发的关联思考
6.1、从DSL引发的思考
C/C++、Java、Python、Go这一路走来分号越来越非必需、指针大量屏蔽、自动垃圾回收逐步成为标配,这些演化本质是想剔除业务无关的语法,方便使用者聚焦业务,现代语言的趋势就是告诉机器要做什么What,而不是怎么做How,因此DSL(Domain Specific Language特定领域语言)被发展出来,SQL、CSS、JSON等均是DSL,Elasticsearch采用JSON格式来书写指令,这也是DSL,而C++、Java、Python等语言被称为GPPL(General Purpose Programming Language)通用目标语言,DSL是为了让‘外行’也可以编程,快速上手,曾和中国农业大学的一个研究生导师聊过一个问题,既然R语言远没有Python强大,为什么还要坚持设置这门课,他说其实很多非计算机领域的研究者更常用R而非Python,因为R语言几乎本身就是为数据科学设计,它语法层面即可支持数据处理,更方便做‘农作物基因分析’等工作,不用太考虑计算机的事,所以在未来使用GPPL的工程师会有一个很重要的任务就是开发DSL给其他领域的从业人员,比如医疗领域DSL、生物学领域DSL、AI人工智能DSL等,这种GPPL和DSL的分工会推进整个行业的进步。
6.2各行业不同技能学习的相通之处
有幸和一位从事多年舞蹈教学工作的资深人士沟通,其对舞蹈那种极致追求让人钦佩,其实舞蹈和IT技能之间有一些规律很有意思,首先舞蹈是先从基本步到技术再返璞归真到基本步,而IT技能有一种方式是从代码到思维再回到基本关系研究,业内戏称‘吃了吐、吐了吃’,其次随着不断进阶舞蹈在同一个节拍内考虑的动作、节奏、重心等因素越来越多,比如国标中一个‘西班牙拖步’不仅要想步子还要考虑重心、头的摆放和节奏等,而软件开发是一开始主要考虑功能实现,到后来性能、高可用、安全、扩展,及具备抽象、结构、工具等思维,最终形成‘架构美感’,同时舞蹈中想要具有一定的‘科班性’,通常会从认知美丑、提升审美、观察反思、接纳解决、坚持练习这5个方面提升,这点IT技能也部分适用,总之舞蹈艺术和IT技能看似是两个不相关的领域,但舞蹈在逐步进阶的学习中也存在像编代码一样的逻辑,反之IT技能也存在像舞蹈动作一样的审美,两者有一定的相通性。
6.3人生就是对外界认知不断提升的过程
随着人的成长认知也不断提升,认知有价值交换、目标筛选、灰度对错等,本文想介绍量化认知,其实‘提升认知的过程就是把对这个世界的感受逐步量化的过程’,就好比我们现在知道人体最舒适的温度通常在20-26度、被广泛认可的黄金比例约0.618:1、声乐中虽然每个人音高、音色不同,但好听的声音公认是440赫兹左右,学习一个技能在某种程度上也是逐步量化的过程,在备考中将越来越多的小细节量化出来就证明自己对这个技能掌握的越来越熟练了。
七、推荐用书
《一本书讲透Elasticsearch》基于8.X版本,从软件安装、语法介绍深入浅出的体系化讲解,方便读者构建完整知识体系,同时每一章还配置了总结性思维导图,加深印象,几乎可以覆盖大部分考点,此外在最后几章高阶部分讲解了数据存储和搜索的底层原理和性能优化的实用技巧,是系统化学习的字典类书籍。
https://item.jd.com/10094296084455.html

《Elasticsearch搜索引擎构建入门与实战》基于7.X版本,它的特点是双语教学,每一个案例均配置了Java和DSL两套语法来讲解,不仅有理论知识,还教实践开发,尤其是最后一章介绍了搜索建议、线性加权、特殊语法等在实际开发中很实用的技巧,可以通过本书掌握一些具体实操方式。
https://item.jd.com/10116584162087.html

八、常见部分高频考点的文档总结
分词器:
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/analysis-analyzers.html
多字段:
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/multi-fields.html
运行时字段:
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/runtime.html
索引相关:
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/indices.html
更新索引的设置
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/indices-update-settings.html
文档操作:
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/docs.html
别名操作:
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/indices-aliases.html
索引模板:
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/index-templates.html
批量插入:
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/docs-bulk.html
Ingest pipelines:
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/ingest.html
搜索模板:
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/search-template.html
分页查询:
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/paginate-search-results.html
Query和Filter:
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/query-filter-context.html
Boolean查询:
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/query-dsl-bool-query.html
高亮查询:
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/highlighting.html
最小查询值:
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/query-dsl-bool-query.html#bool-min-should-match
集群Node角色:
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/modules-node.html
数据备份和恢复:
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/snapshot-restore.html
索引分配:
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/modules-cluster.html#cluster-shard-allocation-filtering
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/index-modules-allocation.html
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/modules-cluster.html#shard-allocation-awareness
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/cluster-allocation-explain.html
跨集群搜索:
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/modules-cross-cluster-search.html
集群健康程度检查:
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/cluster-allocation-explain.html
索引生命周期:
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/index-lifecycle-management.html
数据流:
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/data-streams.html
字段映射:
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/explicit-mapping.html
具体字段定义和用法:
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/mapping-types.html
nested字段:
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/nested.html
自定义分词器:
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/analysis-custom-analyzer.html
测试分词器:
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/test-analyzer.html
日期分桶:
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/search-aggregations-bucket-datehistogram-aggregation.html
平均指标聚合:
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/search-aggregations-metrics-avg-aggregation.html
最大桶聚合:
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/search-aggregations-pipeline-max-bucket-aggregation.html
拉取生命周期管理配置:
https://www.elastic.co/guide/en/elasticsearch/reference/8.1/ilm-settings.html






