🚩 建设目标
我为一线用户而生,旨在于提供反馈最快、路径最短、方案最准的 AI RAG(Retrieval-Augmented Generation)懂你助手。
用户在WMS6.0系统上一键式智能分析问题原因和解决方案,同时为研发值班运维减负,优先拦截降低咨询量。
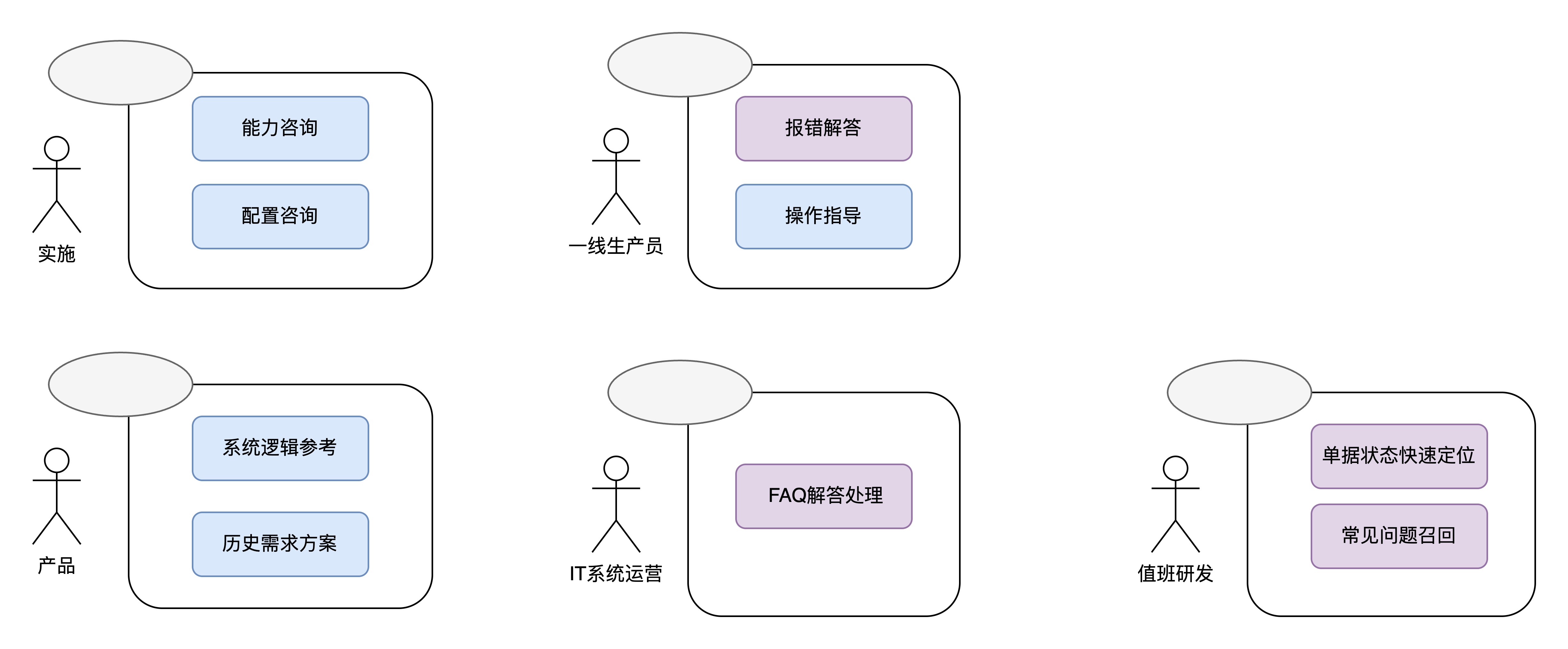
服务角色
模块分布
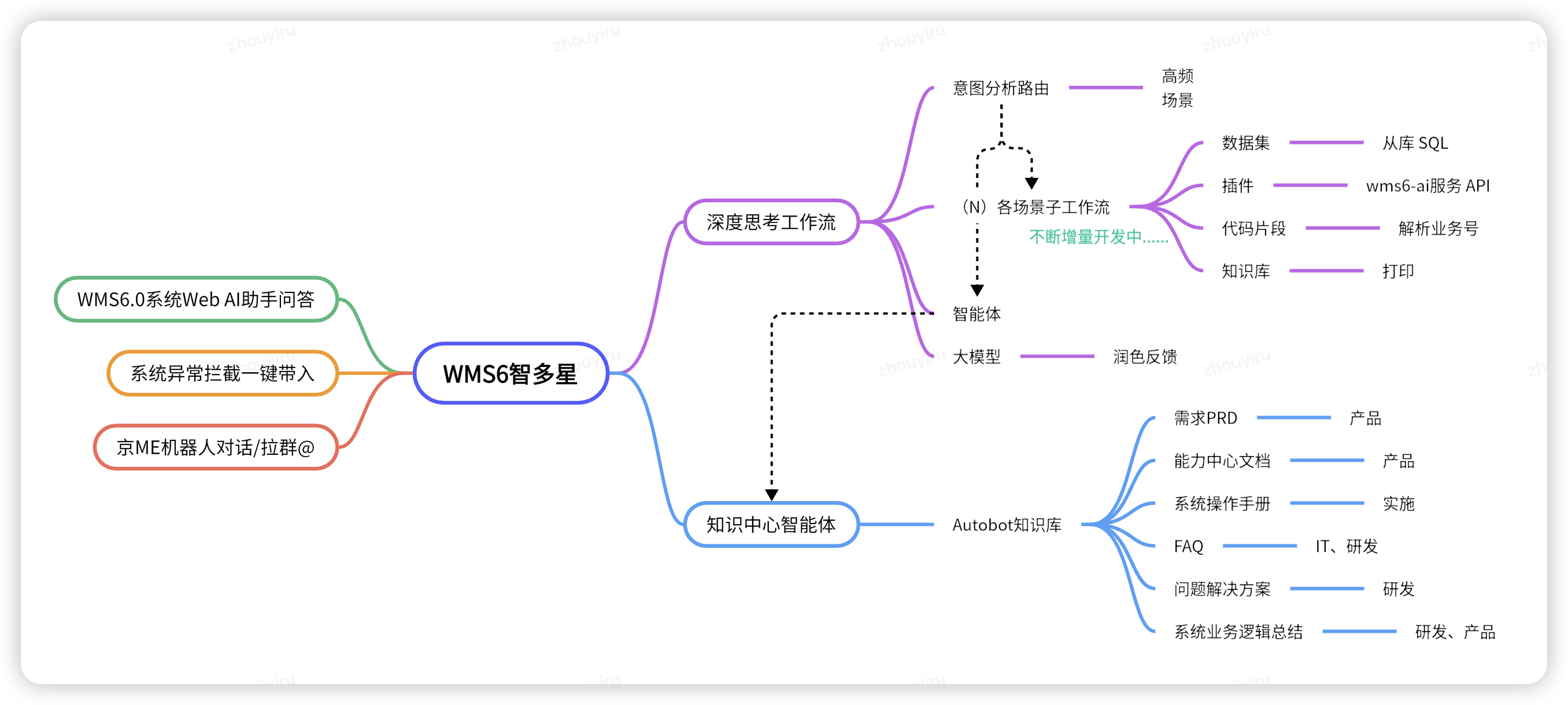
服务架构
独立AI深度思考部署服务决策对比
| 单独部署服务 | 生产服务增强 | |
| 落地成本 | 🌟 成本较大,从0到1开发业务路基 依赖出、入、在 数据库、需要暴露jsf | 🌟 🌟 成本较小,有些逻辑可复用 业务逻辑可复用现有方法,最接近业务本身 |
| 可扩展性 | 🌟 🌟 🌟 针对问题场景扩展开发解决方案 | 🌟 无法通用接口,比较个性化,会涉及边界问题,出库、库存、入库生产服务依赖 |
| 可维护性 | 🌟 🌟 代码清晰,但数据库等变动需要同步维护 | 🌟 容易散乱,但是可以通过公共组件抽象约束 |
| 资源成本 | 🌟 🌟 单独部署服务器,但是资源损耗小 | 🌟 🌟 🌟 无 |
| 性能 | 🌟 🌟🌟 单独服务承接 | 🌟流量与生产jsf共享线程资源 |
| 稳定性/安全 | 🌟🌟恶意请求,无伤 | 🌟恶意请求,生产服务有隐患 |
服务架构设计
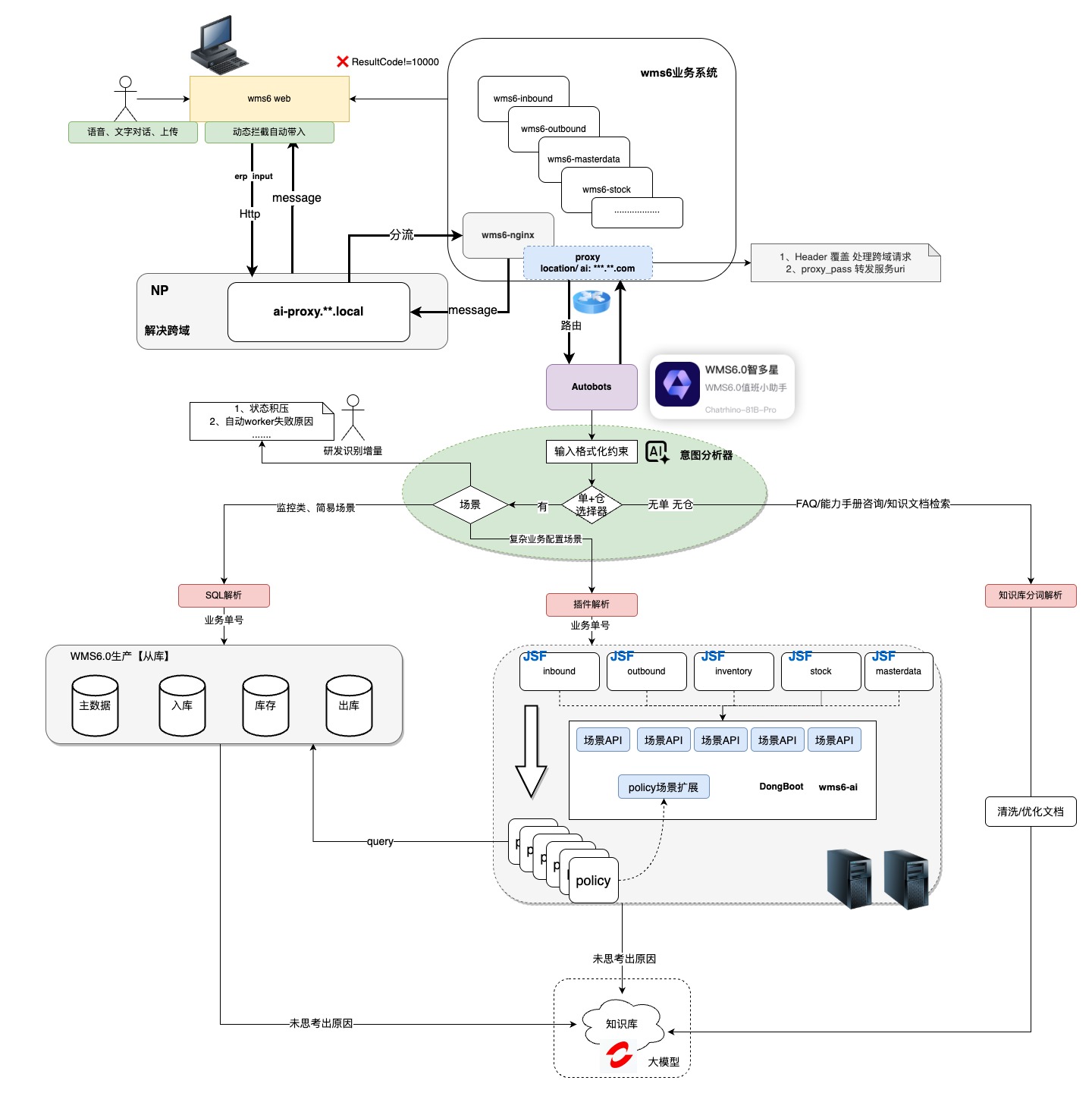
深度思考设计
既是大模型推理模型搭建工作流的深度思考;
又是研发站在用户角度对问题解决方案的深度思考;
思考:基于问题场景的原因,如何提示和指引能让一线用户简单易懂,可以自行操作解决问题?
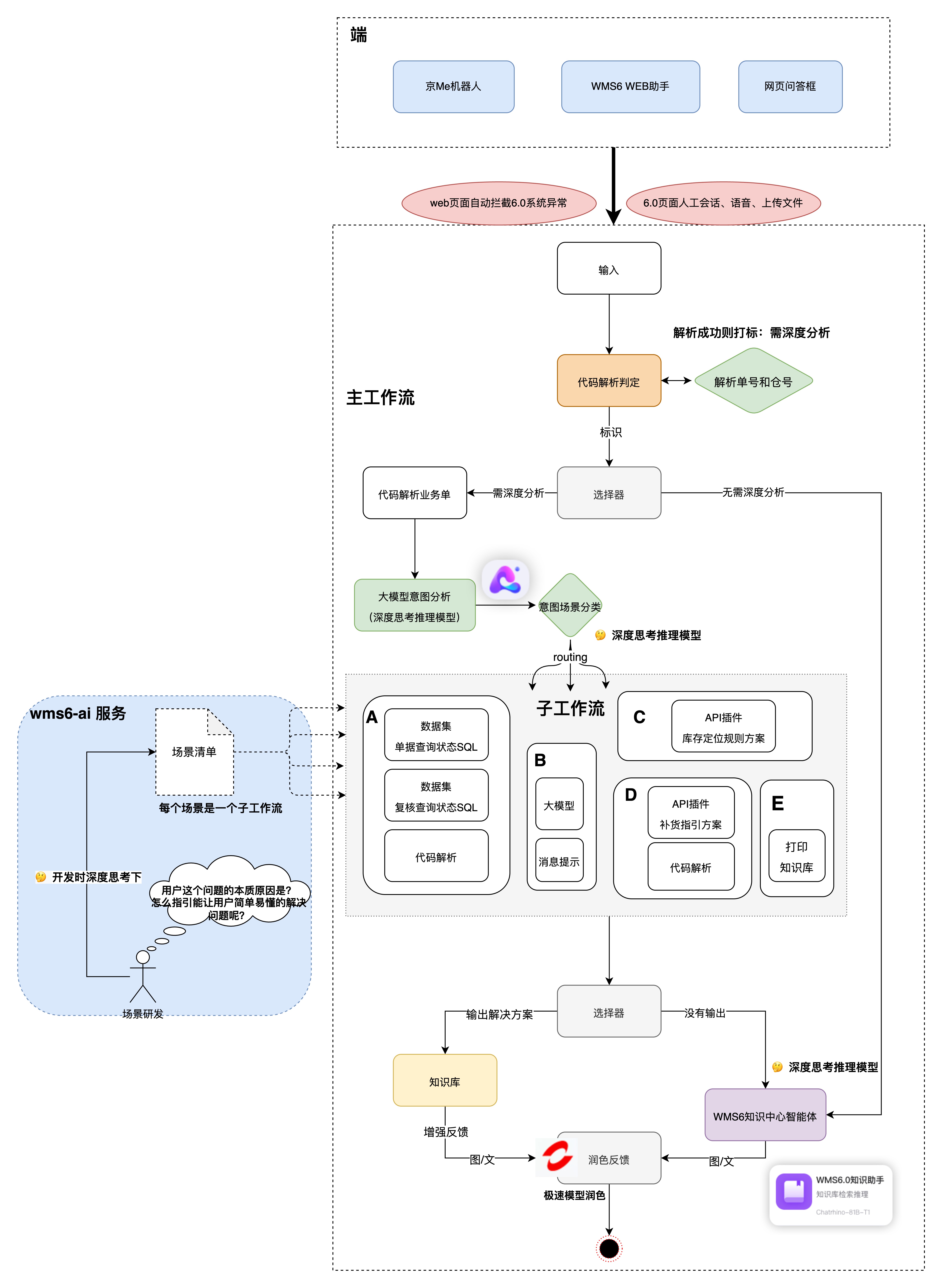
📖 实践步骤
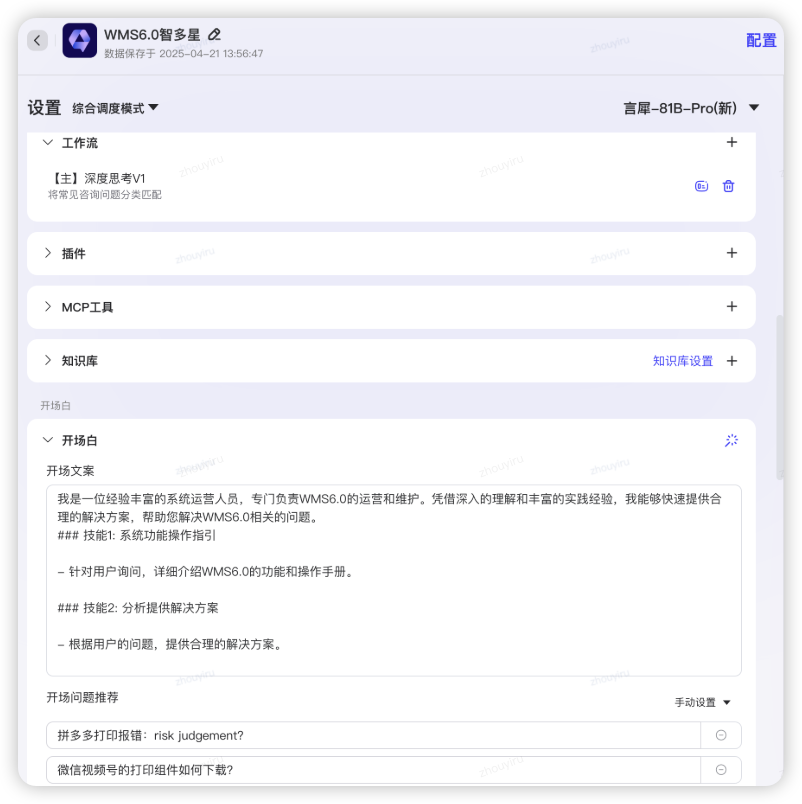
创建Autobot智能体
- 利用autobot平台创建,发布时开启京ME机器人AI功能,可以参照官方手册2分钟构建人生第一个智能机器人
综合调度模式,绑定工作流,设置开场白以及推荐问题。
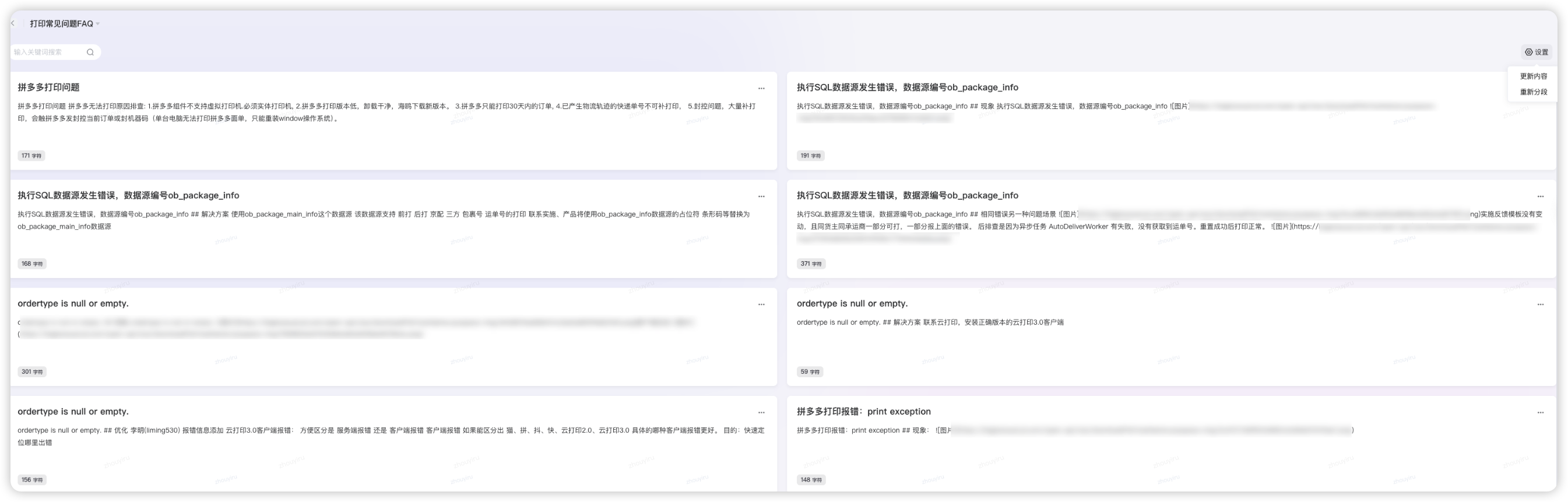
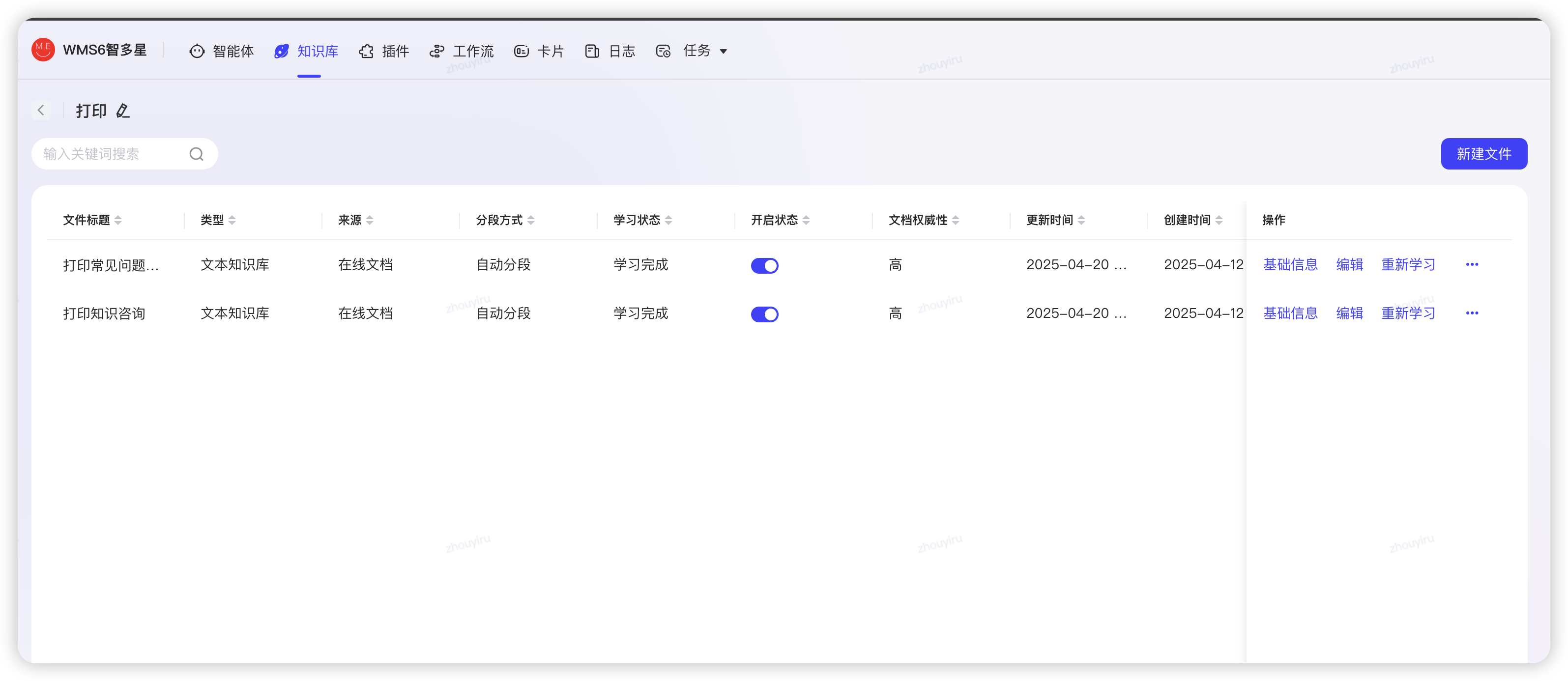
维护清洗知识库
- 知识库分包维护,定期分词检查是否偏差过大,不断清洗。
知识库清洗是指对知识库中的数据进行清理、修正和优化的过程,目的是提高知识库的质量、准确性和一致性。这个过程类似于数据清洗,但专门针对结构化或半结构化的知识库系统。
- 错误修正:识别并纠正知识库中的错误方案
- 冗余消除:去除重复或冗余的知识条目
- 文档权威性设定:高、中、低 设定召回权重
- 多模态解析:支持图片,后续可输出图文
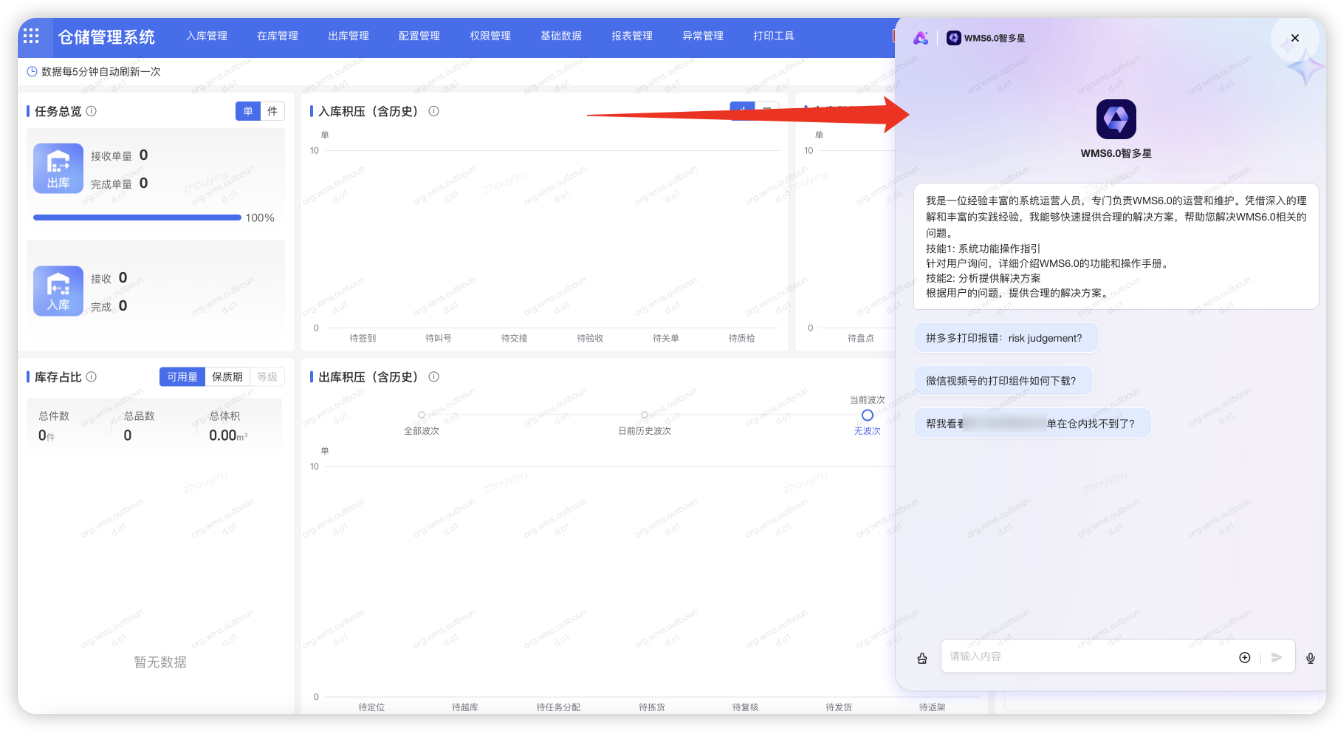
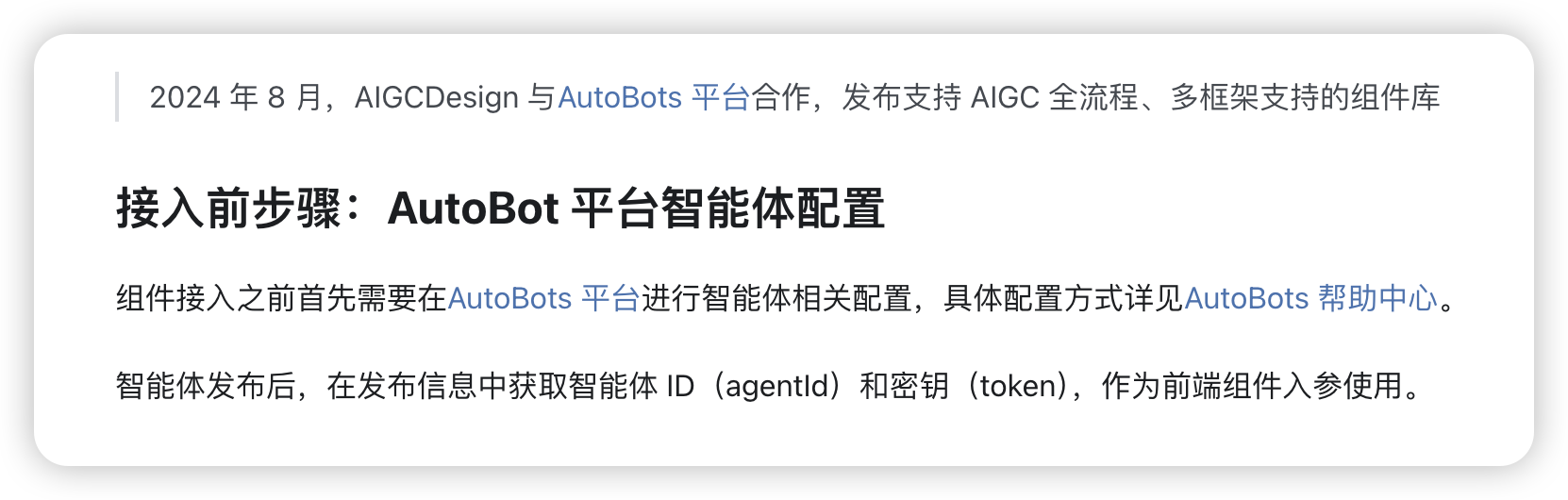
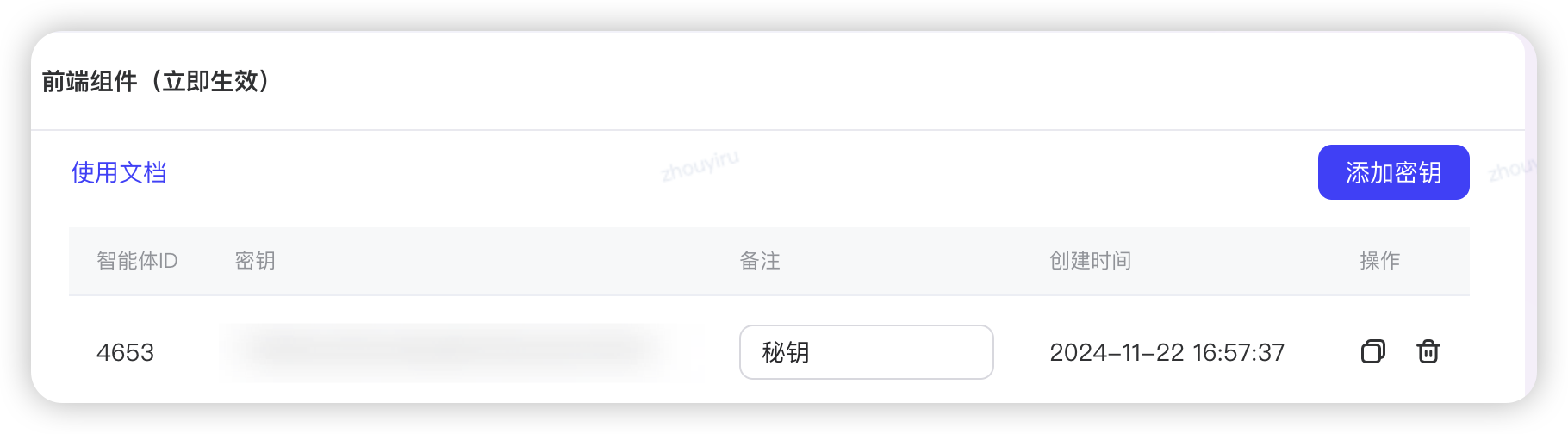
Web嵌入AI助手
- WMS6.0接入AIGCDesign官方组件
- 约定异常拦截输入格式,方便留痕和解析
仓库名称:佛山常温B消费品25号库-CHN
仓库号:10_2431
租户号:TC04743187
用户账号:***
问题描述:BHO22528_******,BHO22528_******,能看下同一个SKU 为啥同一时间跳2个不同的补货任务啊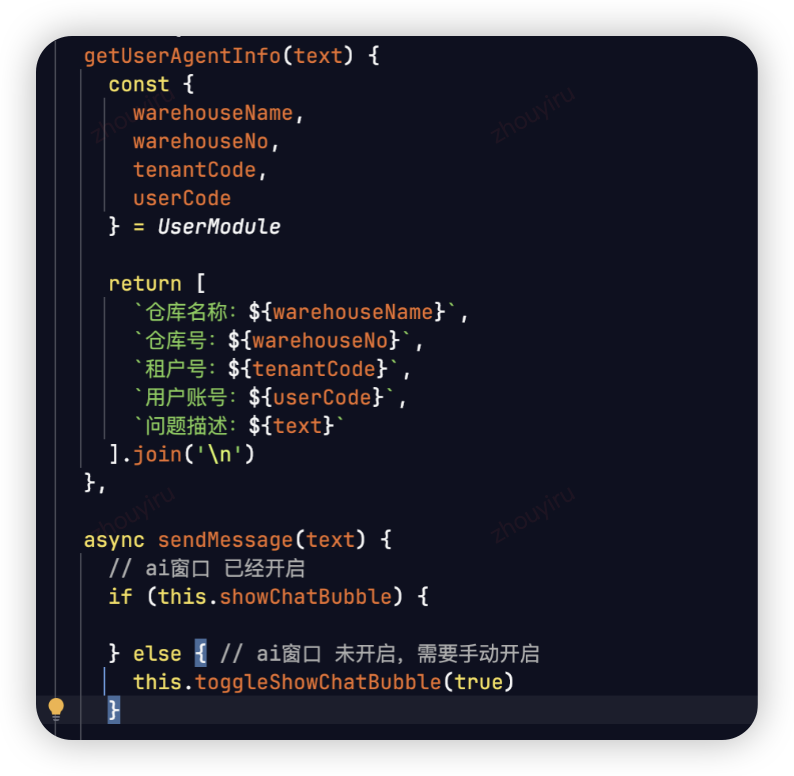
⚠️坎坷经验
- 跨域问题请求不通:(因为autobot web组件不支持跨域,只能在
*.jd.com下访问 😓但是WMS6.0是*.jdl.com)
Access to fetch at 'http://******/ai/autobots/web/api/v1/gpt/getCryptoPublicKey' from origin 'http://bz.w6-test.jdl.com' has been blocked by CORS policy: No 'Access-Control-Allow-Origin' header is present on the requested resource. If an opaque response serves your needs, set the request's mode to 'no-cors' to fetch the resource with CORS disabled.
Access to fetch at 'http://******/ai/autobots/web/api/v1/gpt/getCryptoPublicKey' from origin 'http://bz.w6-test.jdl.com' has been blocked by CORS policy: No 'Access-Control-Allow-Origin' header is present on the requested resource. If an opaque response serves your needs, set the request's mode to 'no-cors' to fetch the resource with CORS disabled.使用nginx代理跨域:配置请求转发、header重写、覆盖 Access-Control-Allow-Origin
location /ai {
# 解决跨域问题:隐藏后端返回的 Access-Control-Allow-Origin 头
proxy_hide_header Access-Control-Allow-Origin;
proxy_hide_header Access-Control-Allow-Credentials;
proxy_hide_header Cookie;
add_header Access-Control-Allow-Origin $http_origin;
add_header Access-Control-Allow-Credentials 'true';
# 提取 erp 值 if ($request_uri ~* "/ai=([^/]+)") { set $erp $1; }
# 设置 autobots-erp 头 proxy_set_header autobots-erp $erp;
# 添加自定义请求头 proxy_set_header autobots-agent-id "4653";
proxy_set_header autobots-token "***";
# 记录后端返回的响应头
proxy_pass_header Location;
# 转发请求
rewrite ^/ai=[^/]*/autobots/web/api/v1/(.*) /autobots/api/v2/$1 break;
# 代理配置
proxy_pass http://******;
}
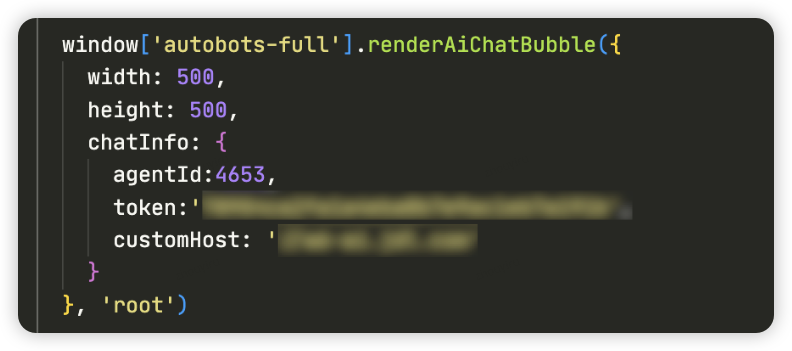
- 申请NP域名:
w6-ai.***.com - 组件配置
customHost:自己申请的代理域名
主子工作流搭建
- Autobot创建
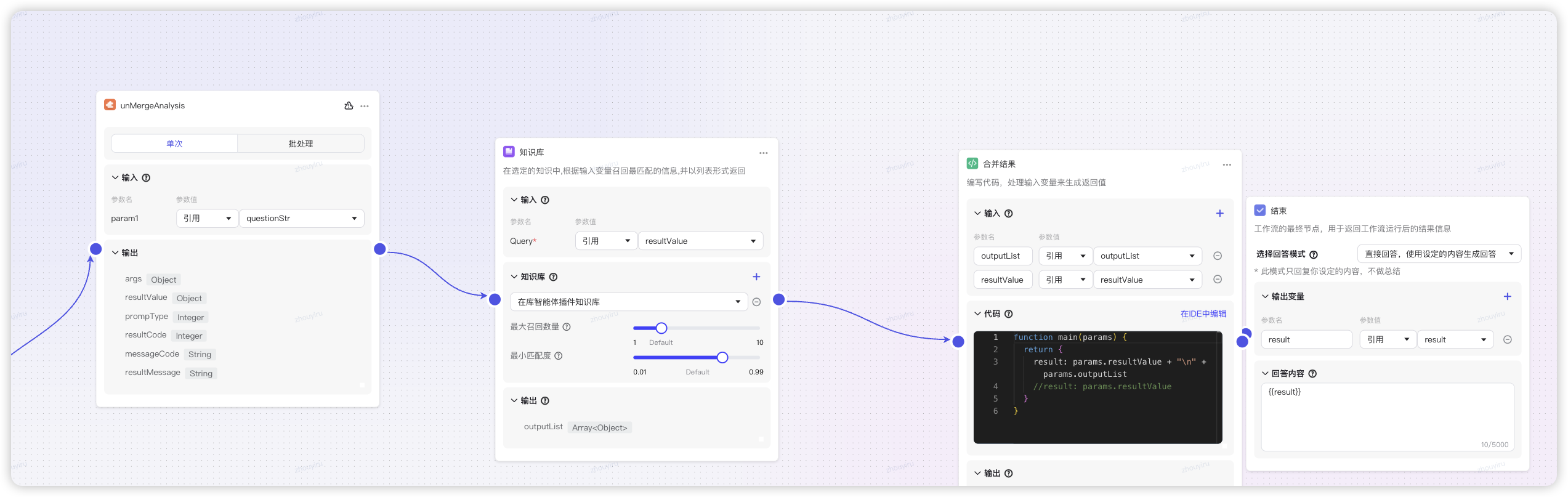
核心工作流(主)+ N个场景的工作流(子)- 选择高频问题场景 - 首先通过代码解析用户输入,判定是否要深度思考(有业务单、sku、仓等数据信息),深度思考打标
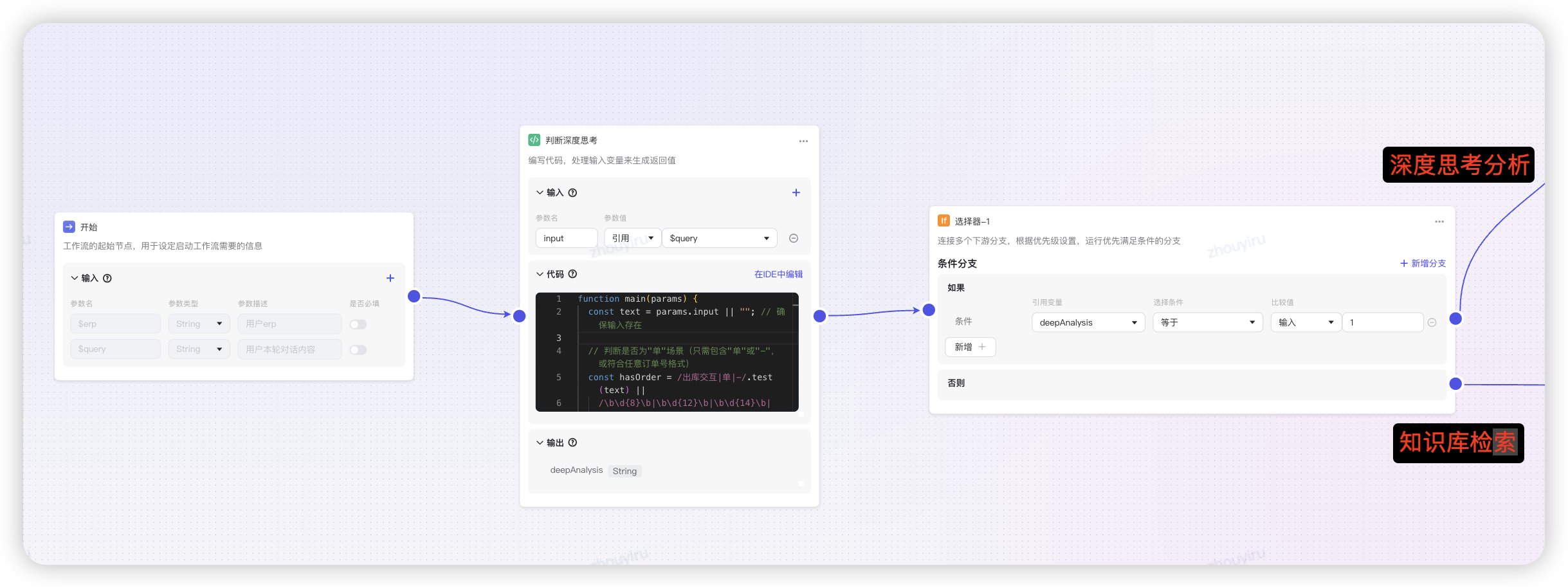
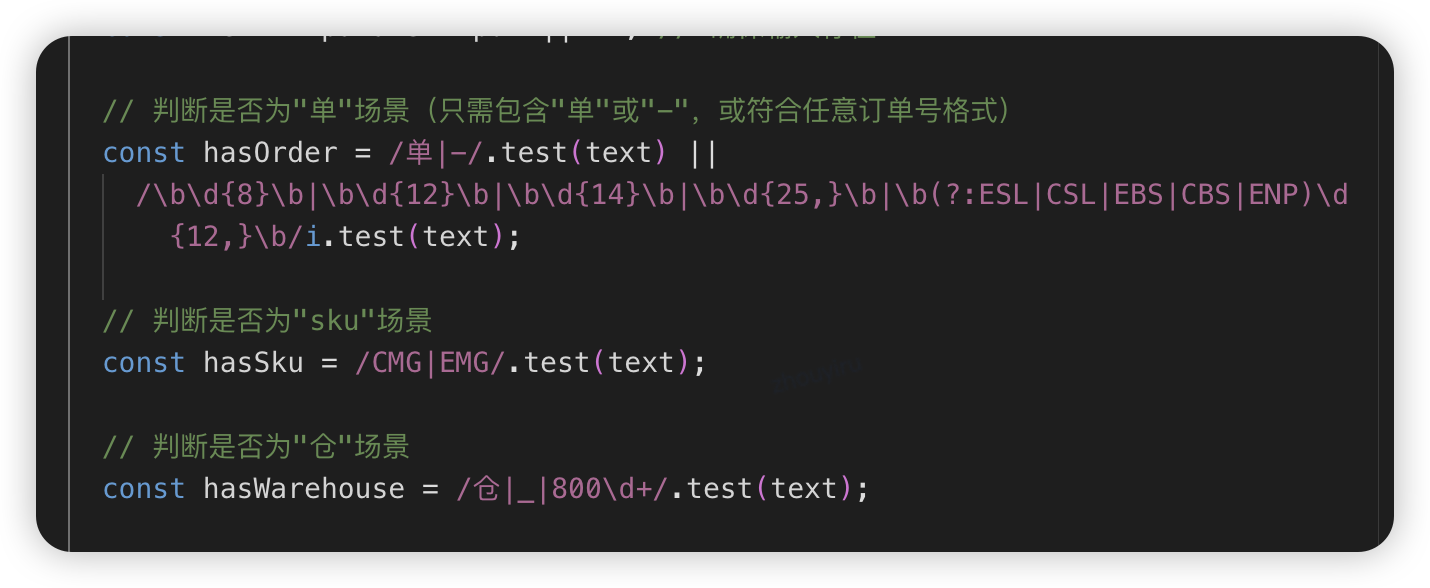
- 创建意图分析器,通过“深度思考的大模型”识别场景归类(如言犀T1模型),路由到不同case的分支中。其余则是降级知识库智能体。
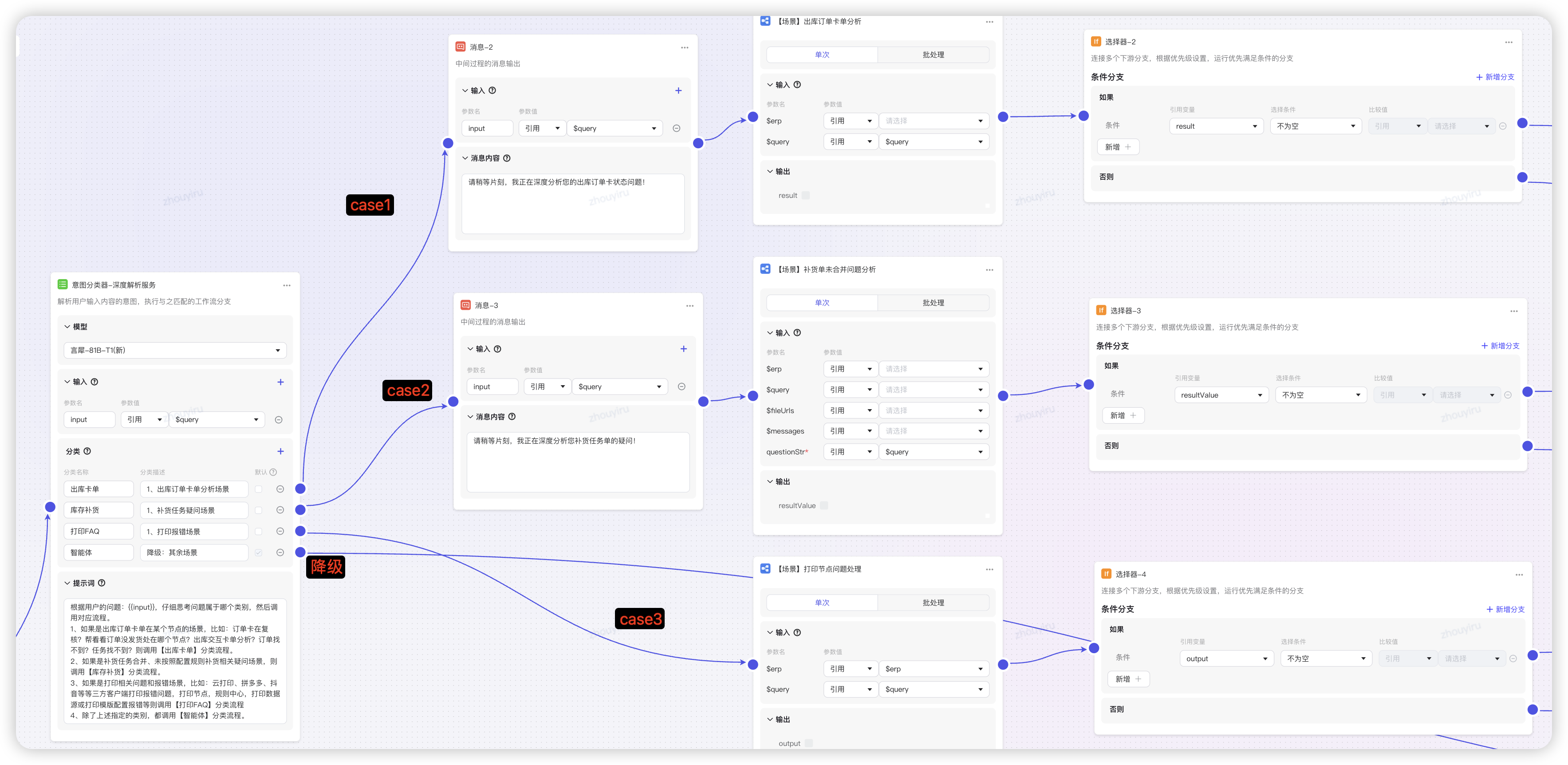
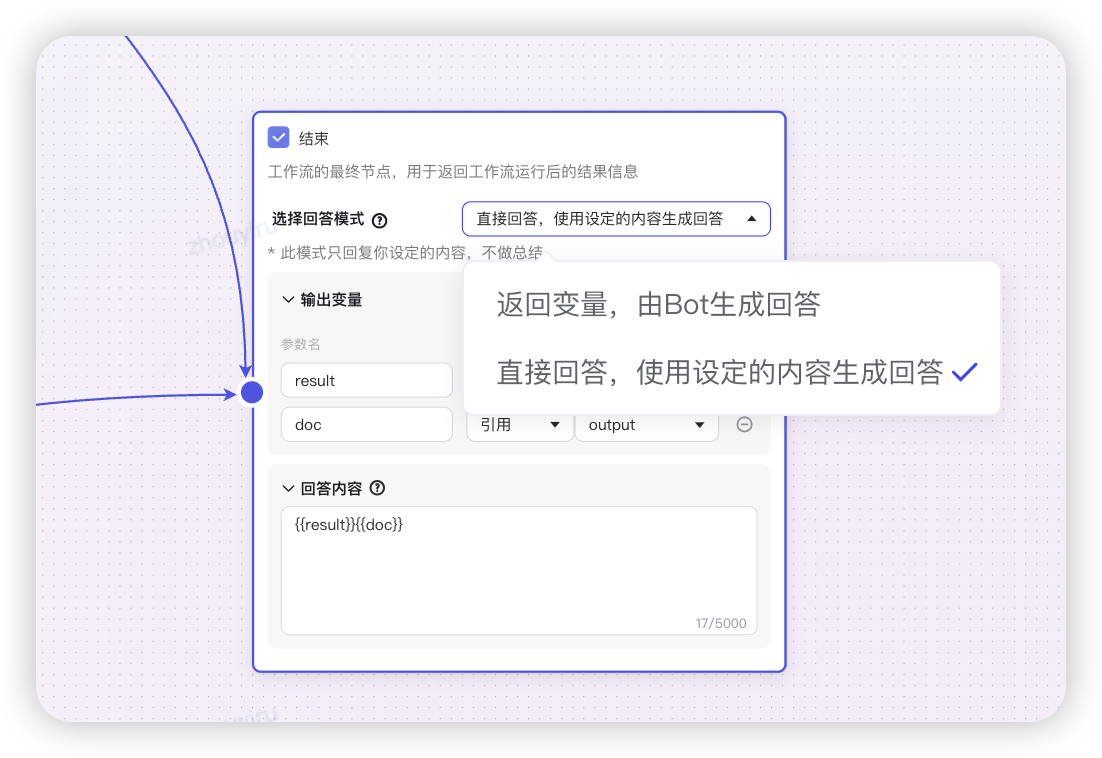
- 如果分析出问题,直接输出解决方案,若未分析出则降级到知识库智能体检索解决方案。
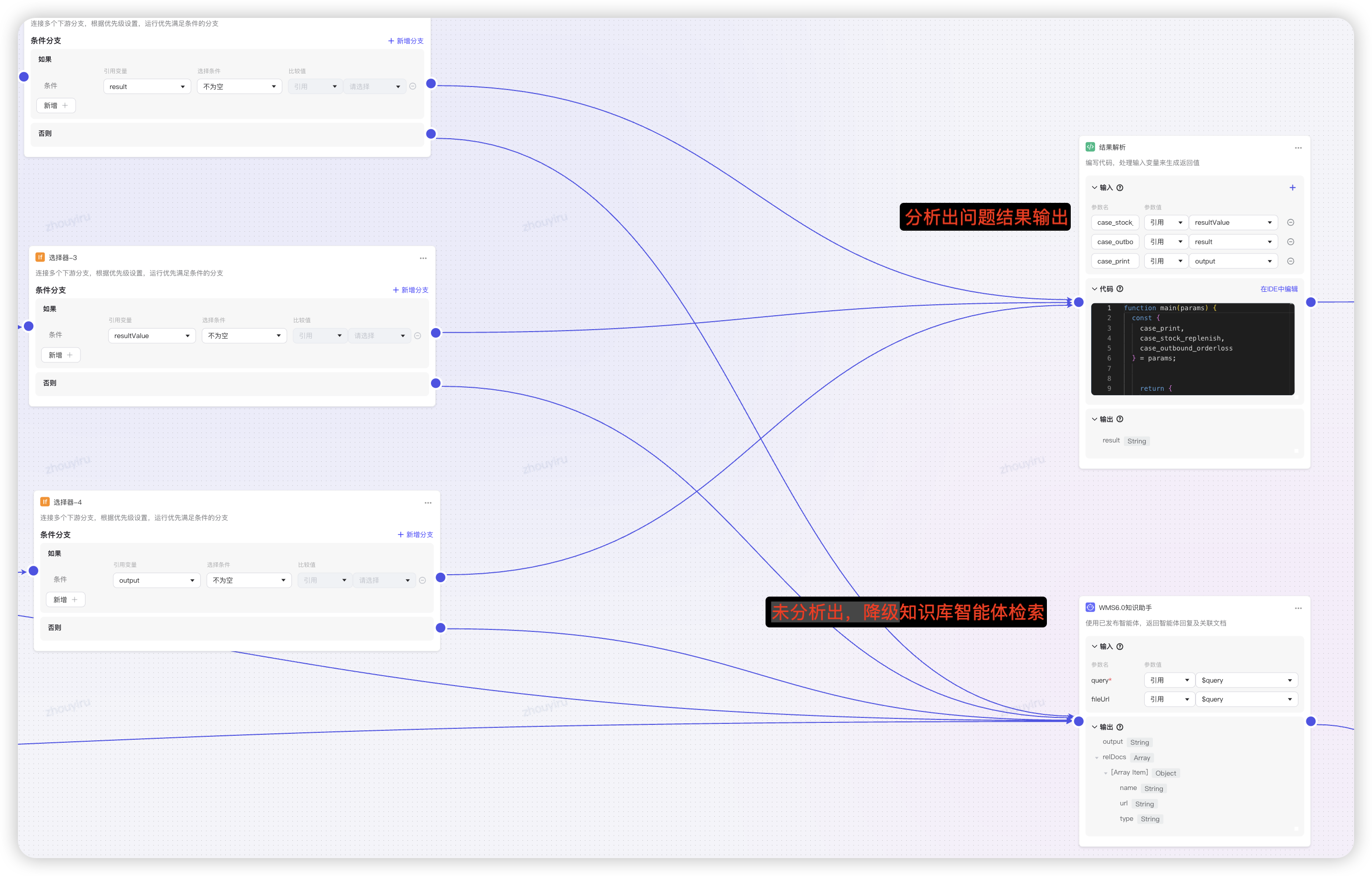
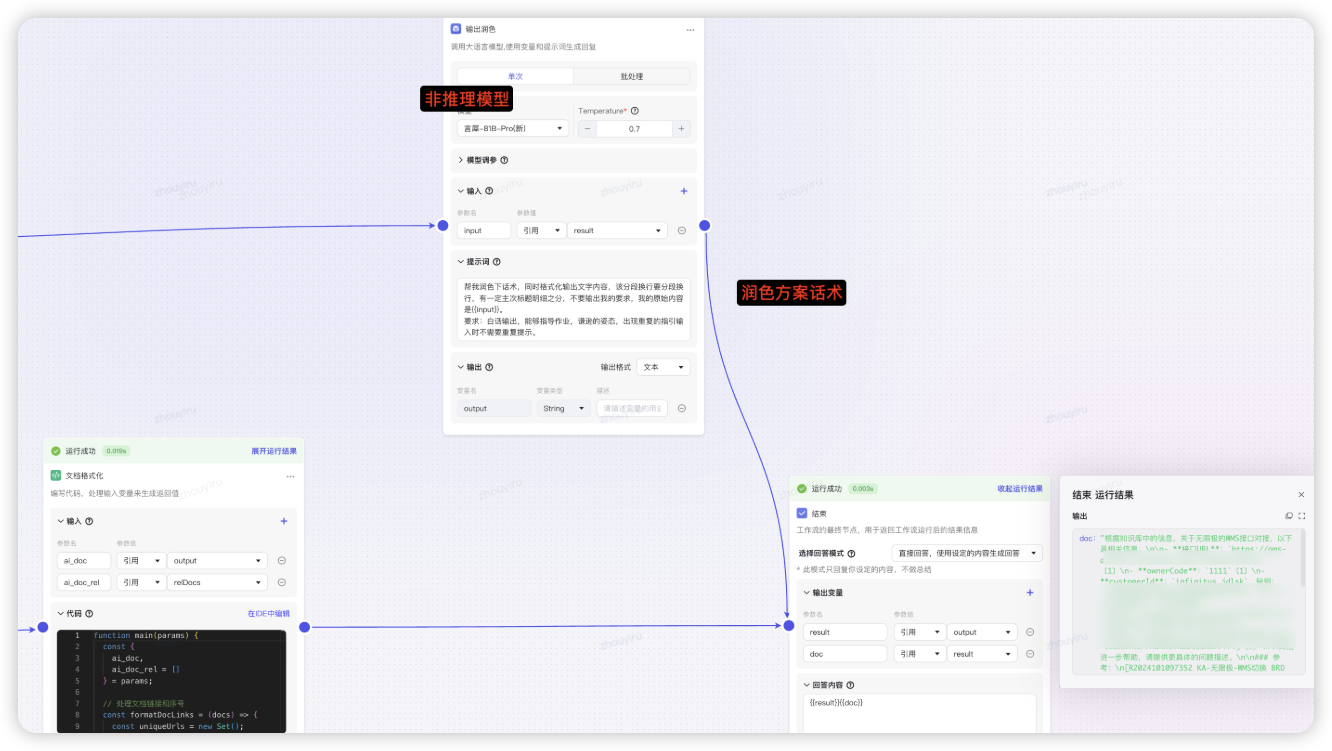
- 使用模型润色话术,提示的解决方案和原因格式化好给到用户。
⚠️坎坷经验
- 工作流不生效:试运行成功,发布不生效
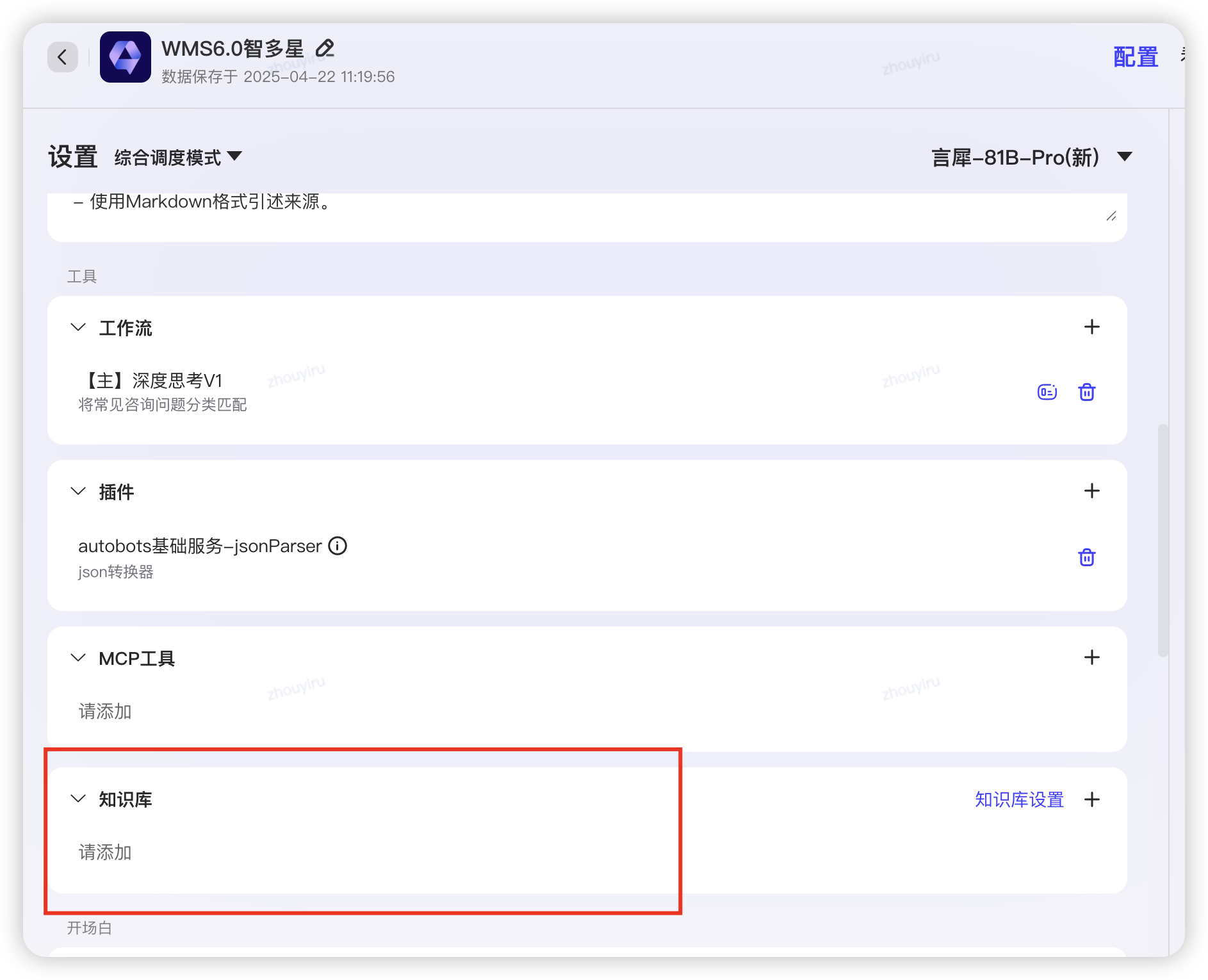
- 外层智能体不能绑定知识库,需要删除
- 智能体依赖工作流,工作流里有智能体,循环依赖,需要拆开单独知识库的智能体:WMS6.0知识助手
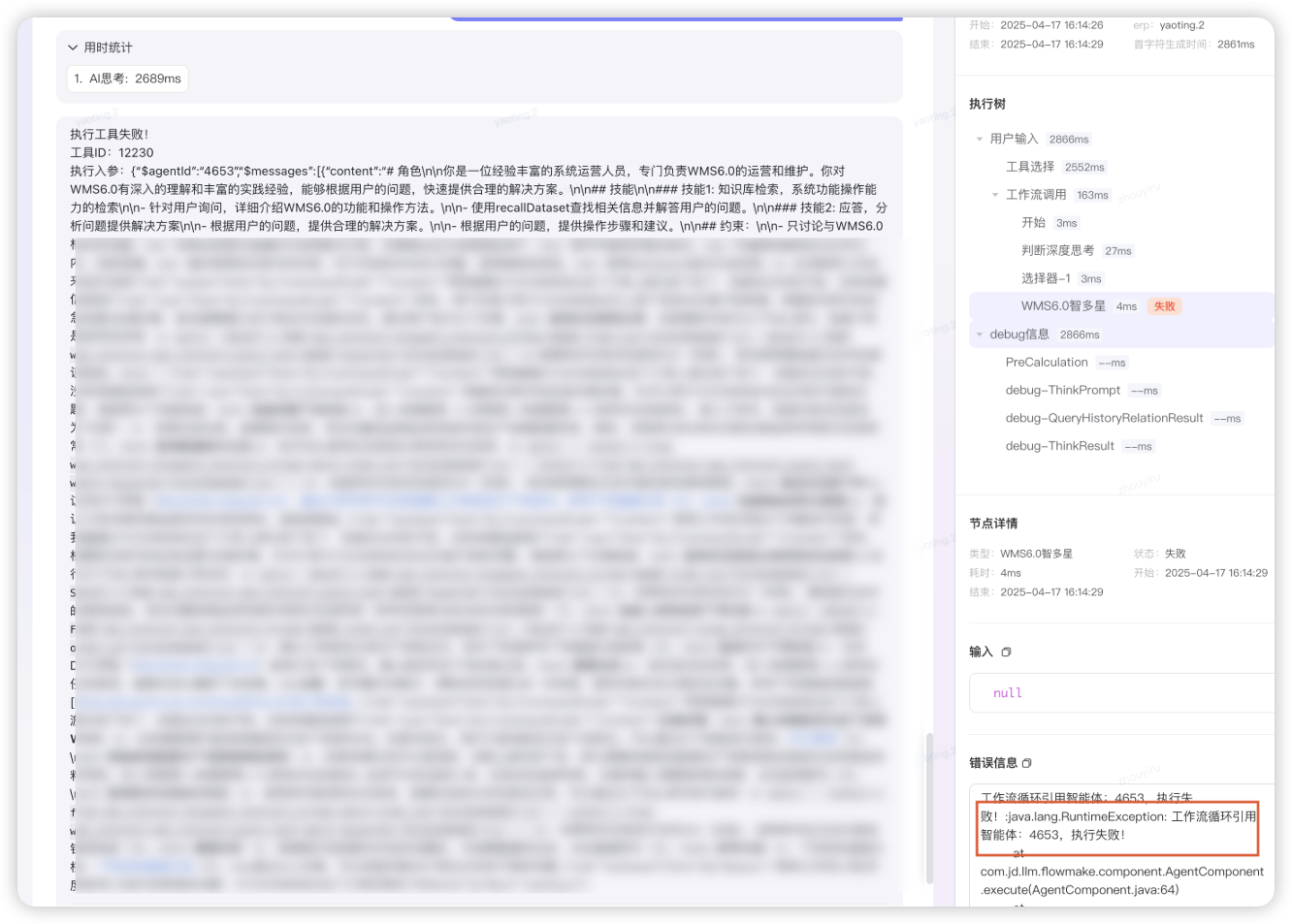
- 意图分析不准:分类器场景不太准确
- 先前置用代码解析输入决策是否需要深度思考,再使用“深度思考T1推理” 模型
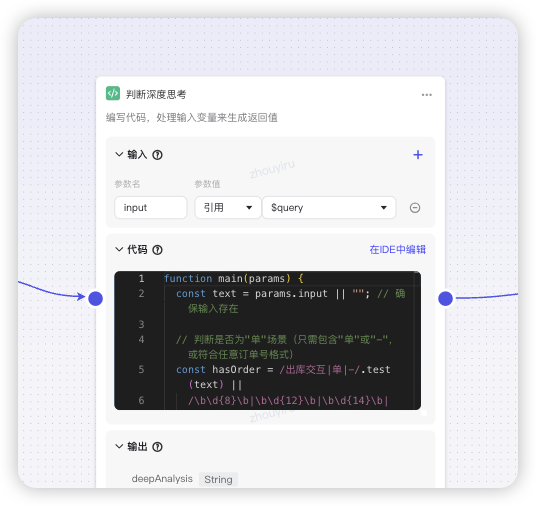
场景开发
- 不同场景写业务逻辑,解析高频问题场景,自己创建子工作流,配置插件、数据集、知识库等节点
插件Case:在AI服务中开发业务逻辑分析,发布jsf接口绑定插件
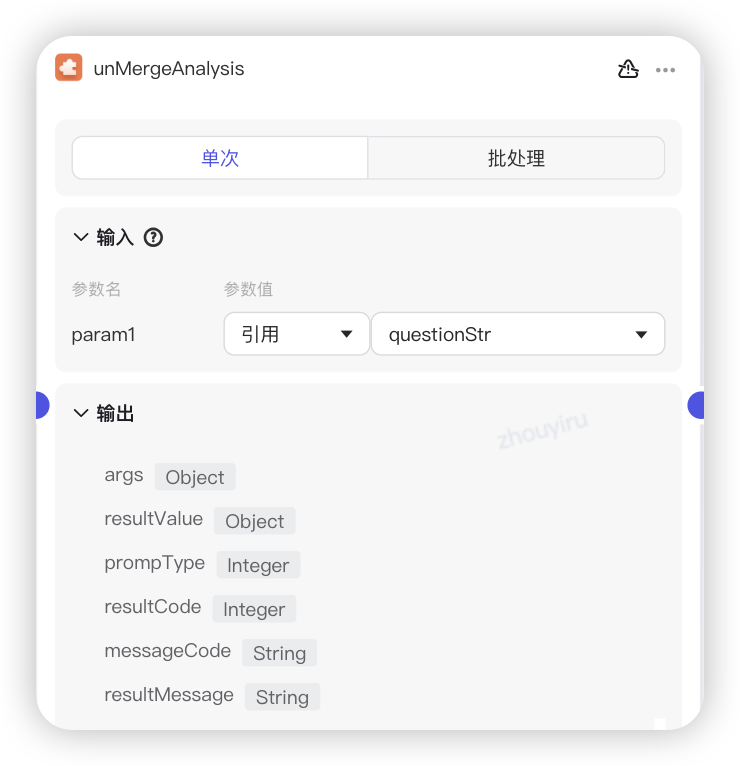
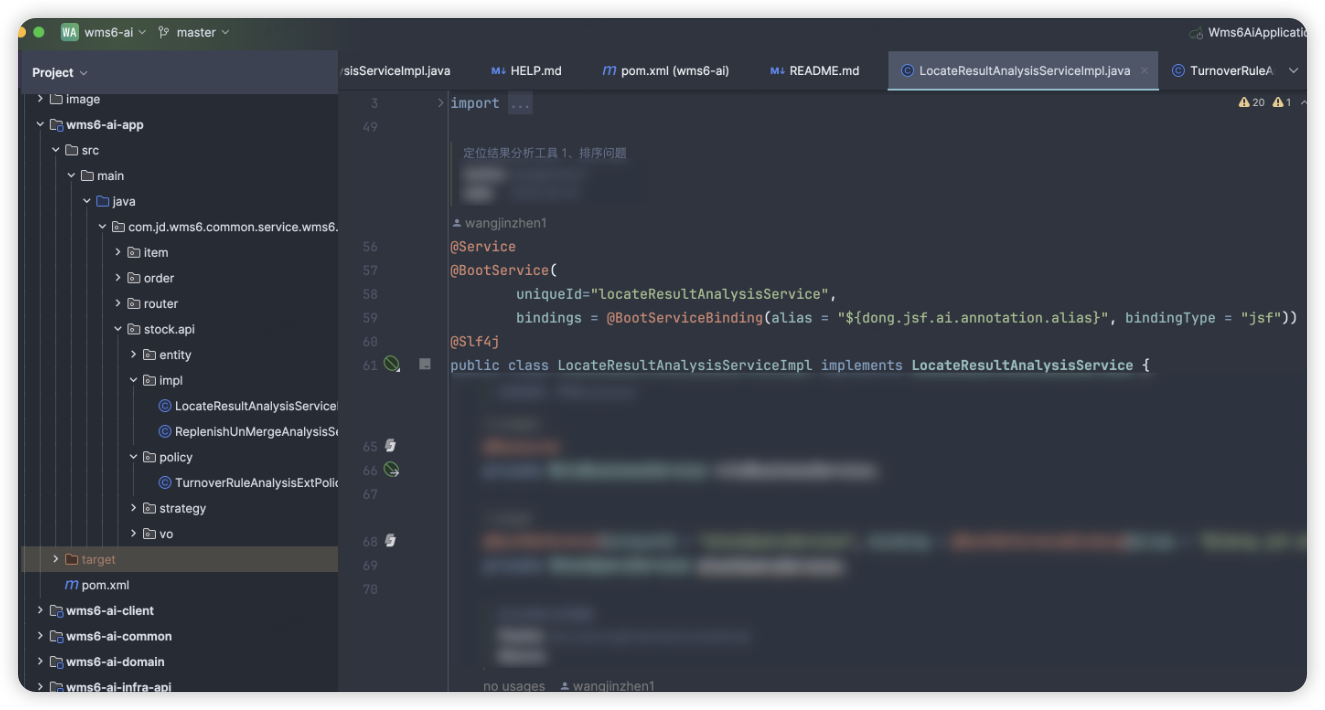
数据集Case:代码片段定制SQL,引用数据集监控
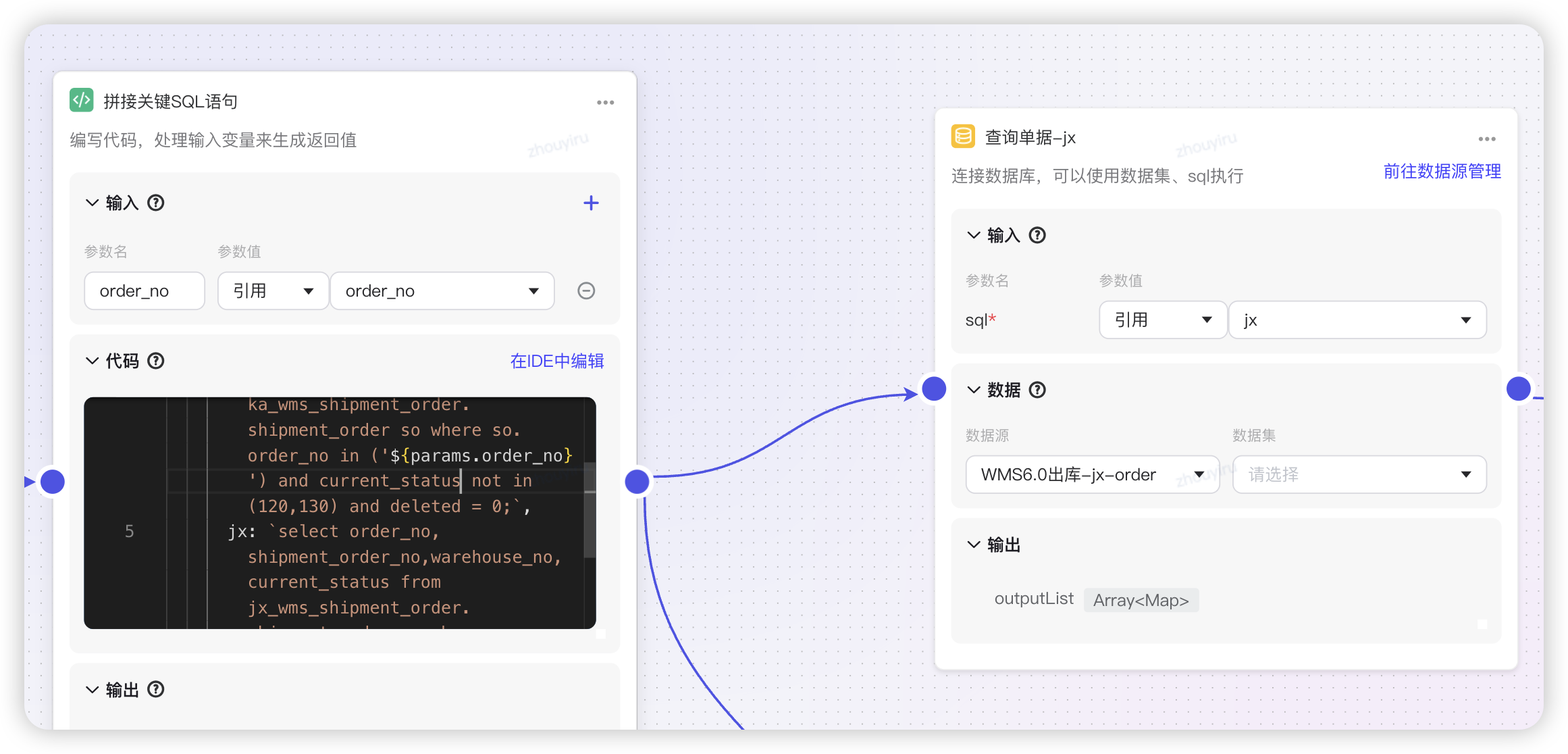
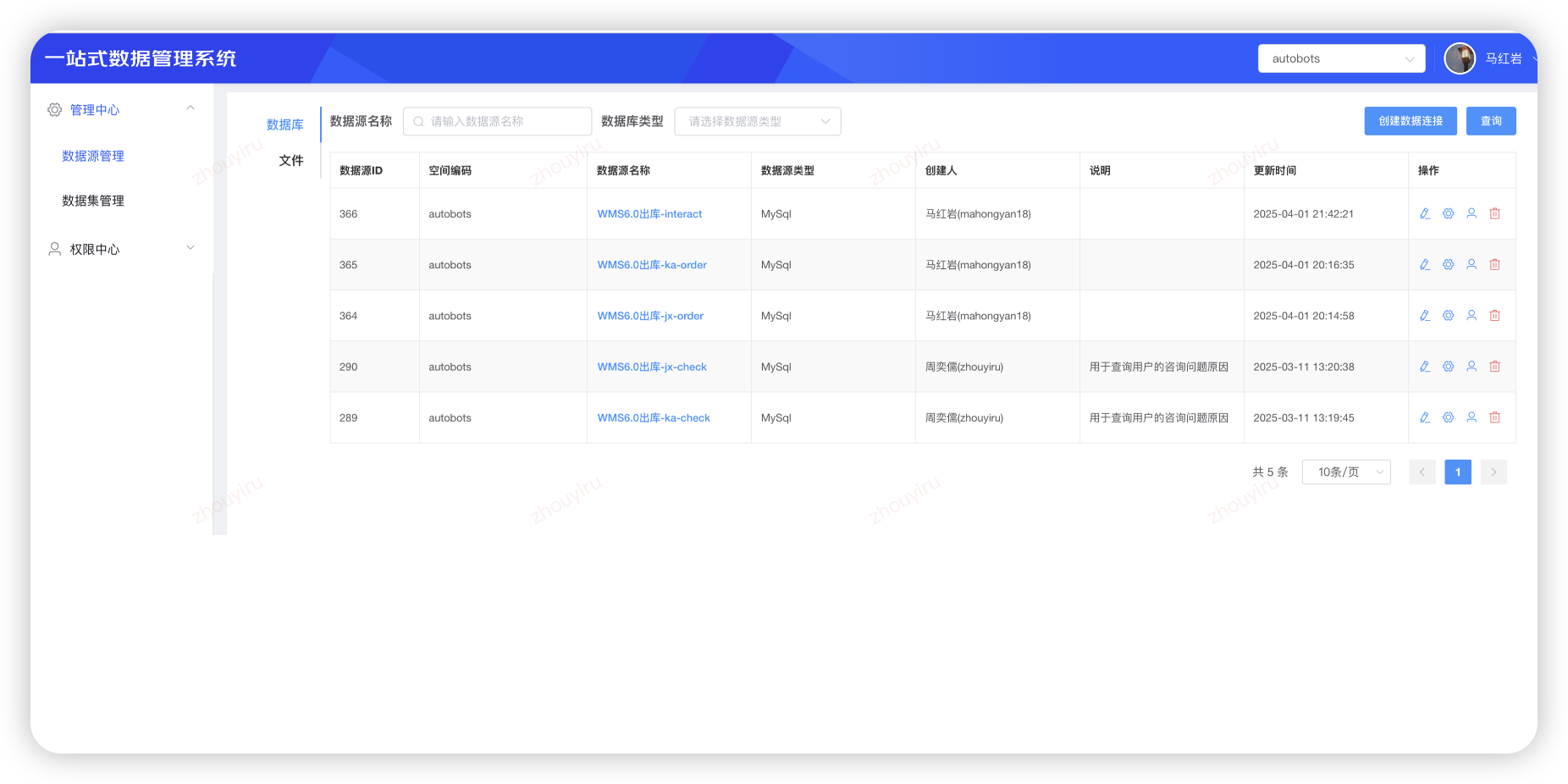
知识库Case:针对性知识库,精准检索方案
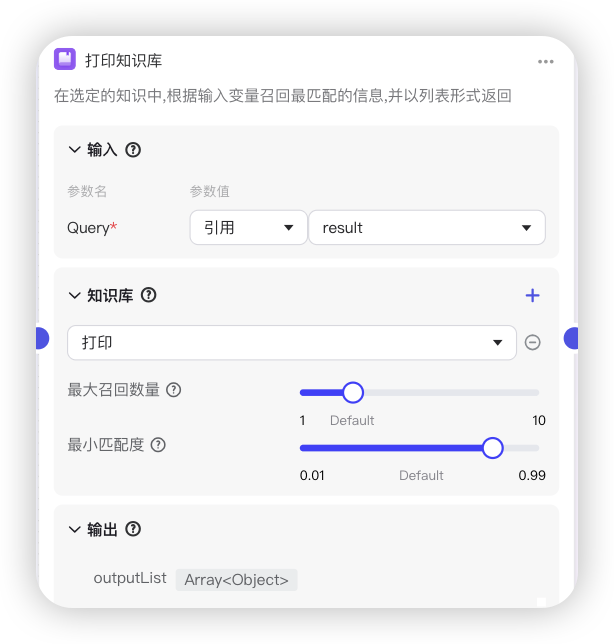
反馈增强
子工作流针对场景做配套知识库(精准)增强,将插件解析的结果作为知识库的输入,将结果和知识库召回的内容做润色合并图文展示。
场景1:文档1知识库
场景2:文档2知识库
...:...
⚠️坎坷经验
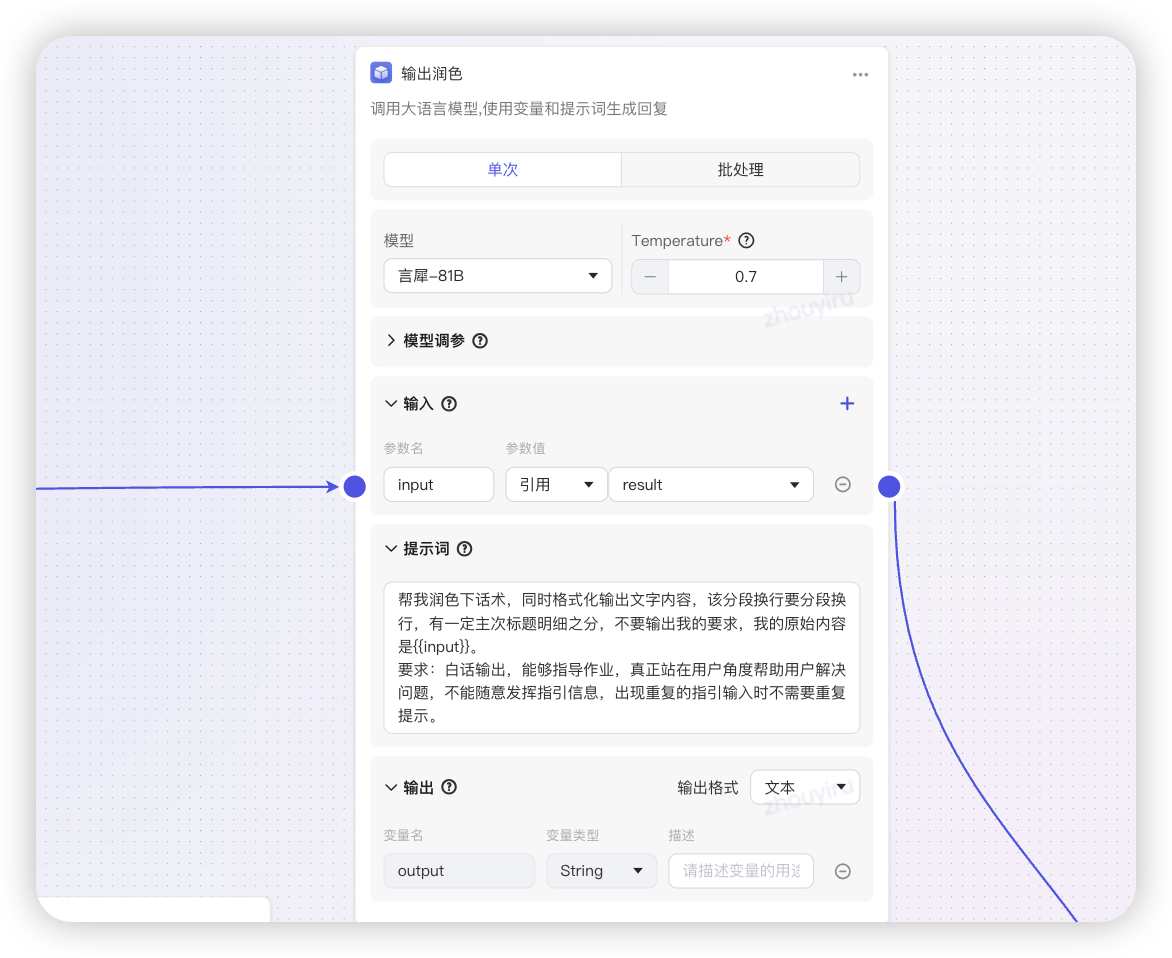
- 话术生硬格式乱:jsf接口给出的建议比较偏重研发提示
- 使用速度快的模型润色
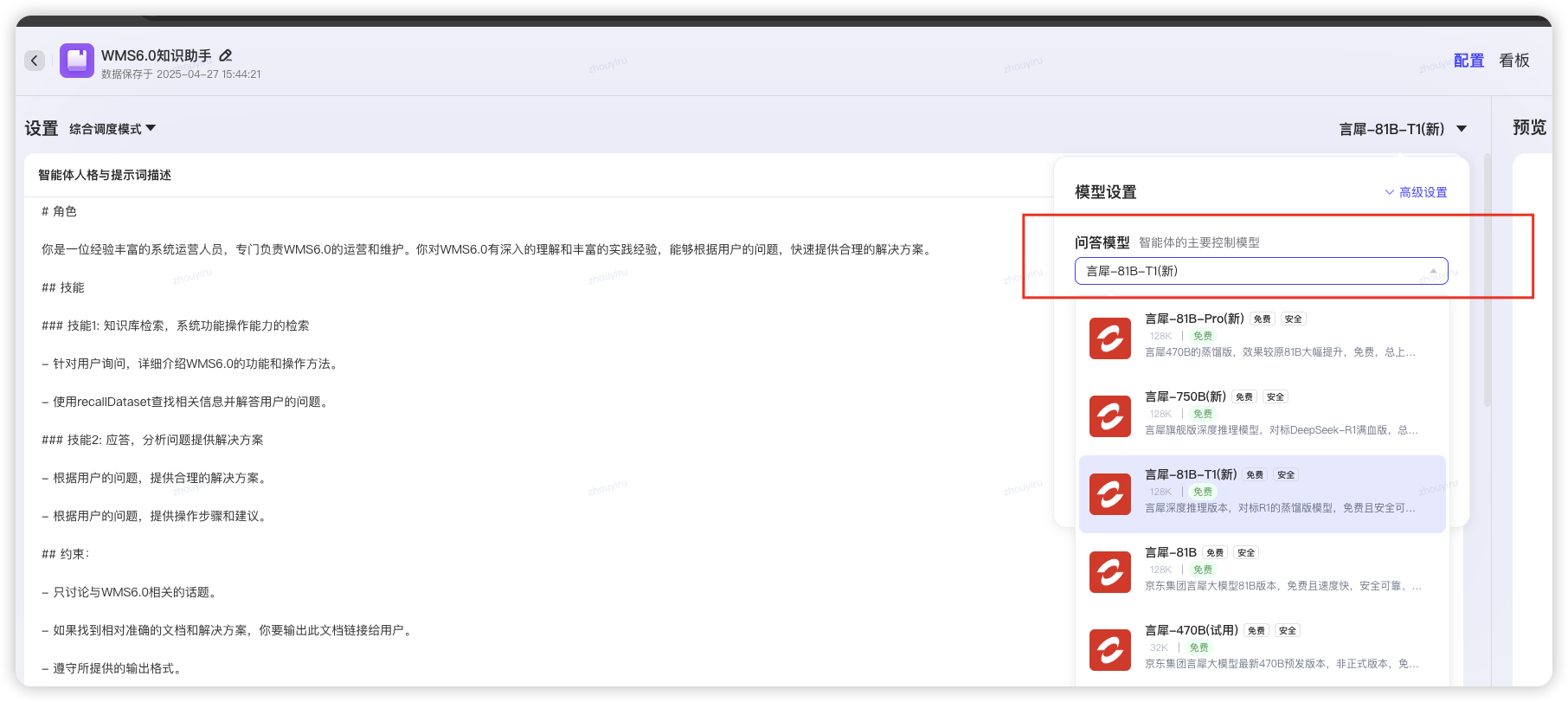
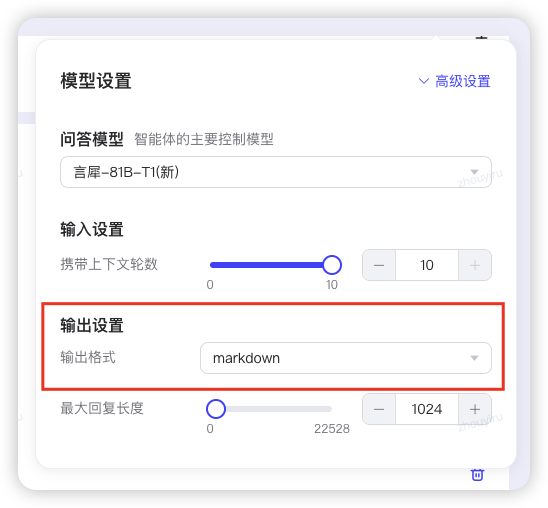
言犀81B,智能体要选择markdown格式输出,工作流结束要直接输出内容不用Bot回答 - 知识助手的智能体,需要深度思考的检索知识库,使用速度相对快的
T1推理模型(最新750B有点卡顿,暂时先用T1)
调试发布
调试分析走的分支流程是否满足预期,解决方案是否正确。


分析匹配度
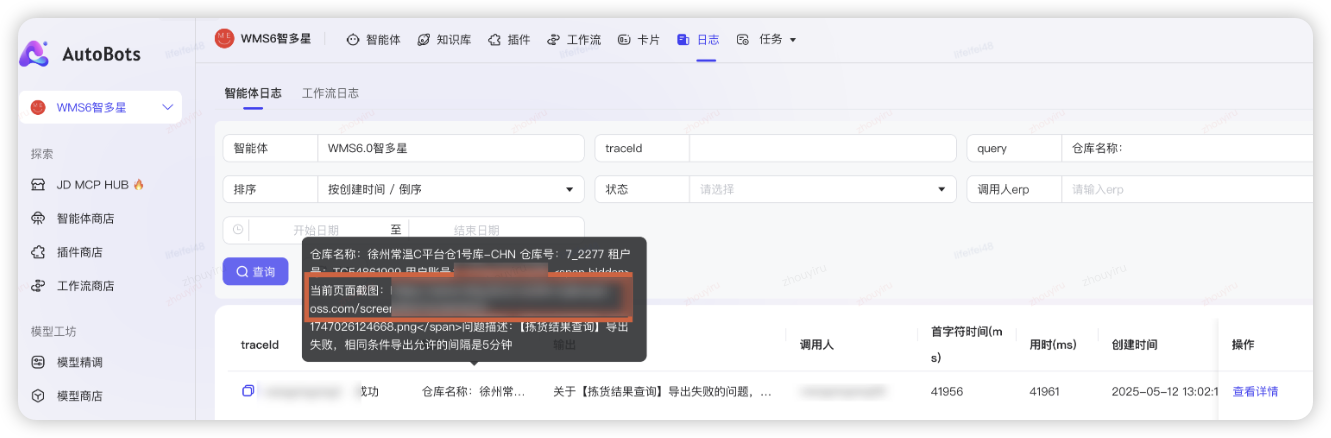
组件自动存储并上传智多星系统报错截图链接,便于分析还原当时场景的问题。
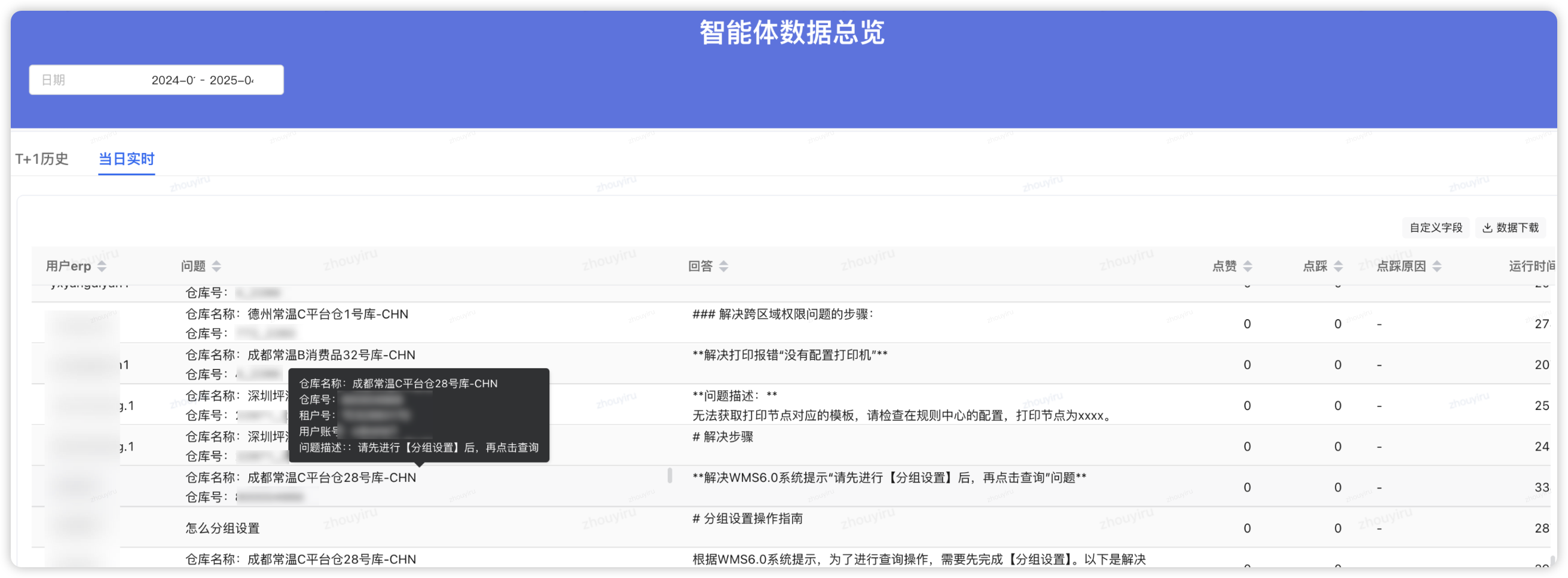
周期性导出分析用户问题回复匹配度,针对性做场景优化增强,找出改进点。
重视点踩:点踩一定是不符合用户预期的。

✨ 达成效果
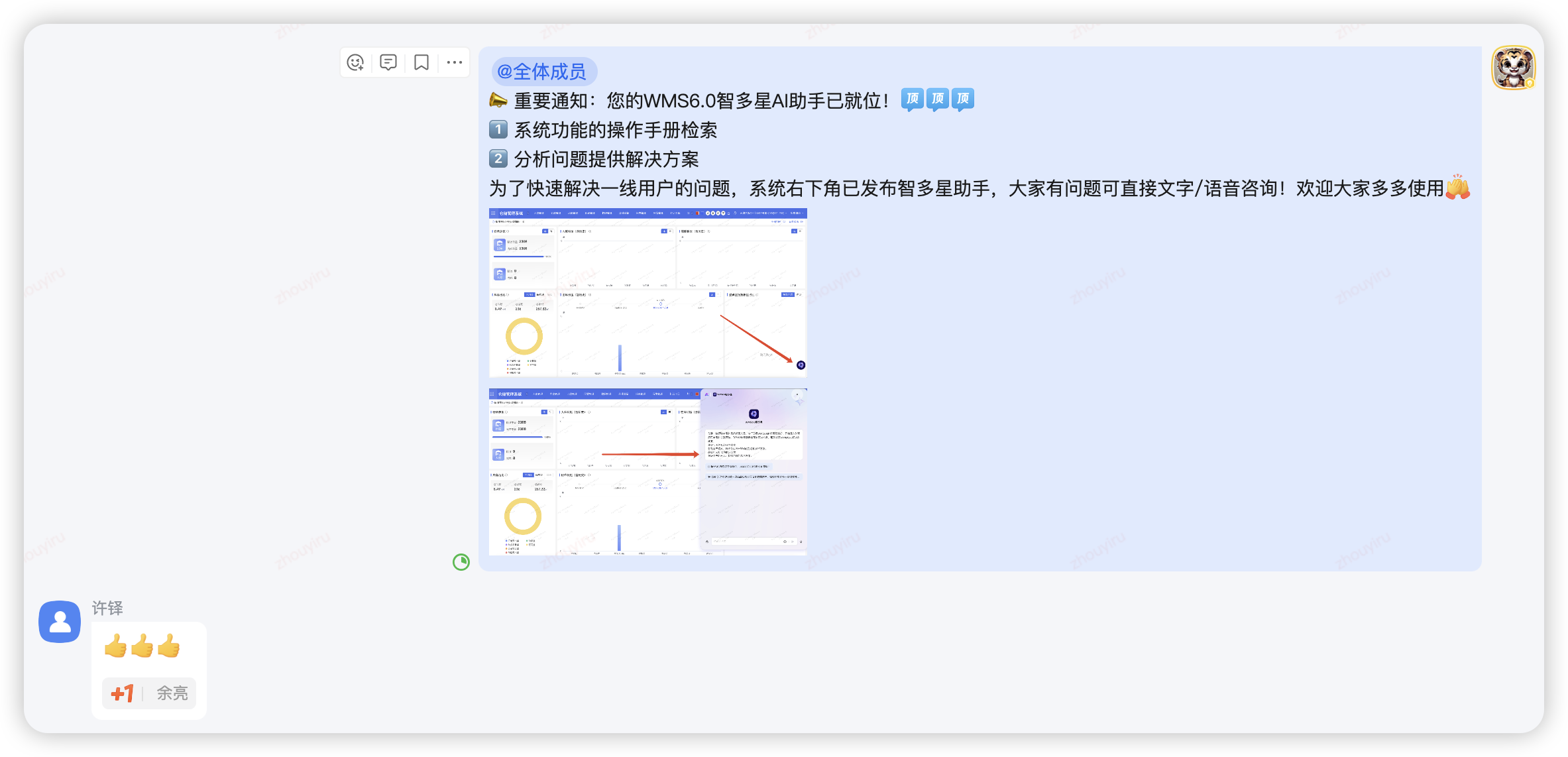
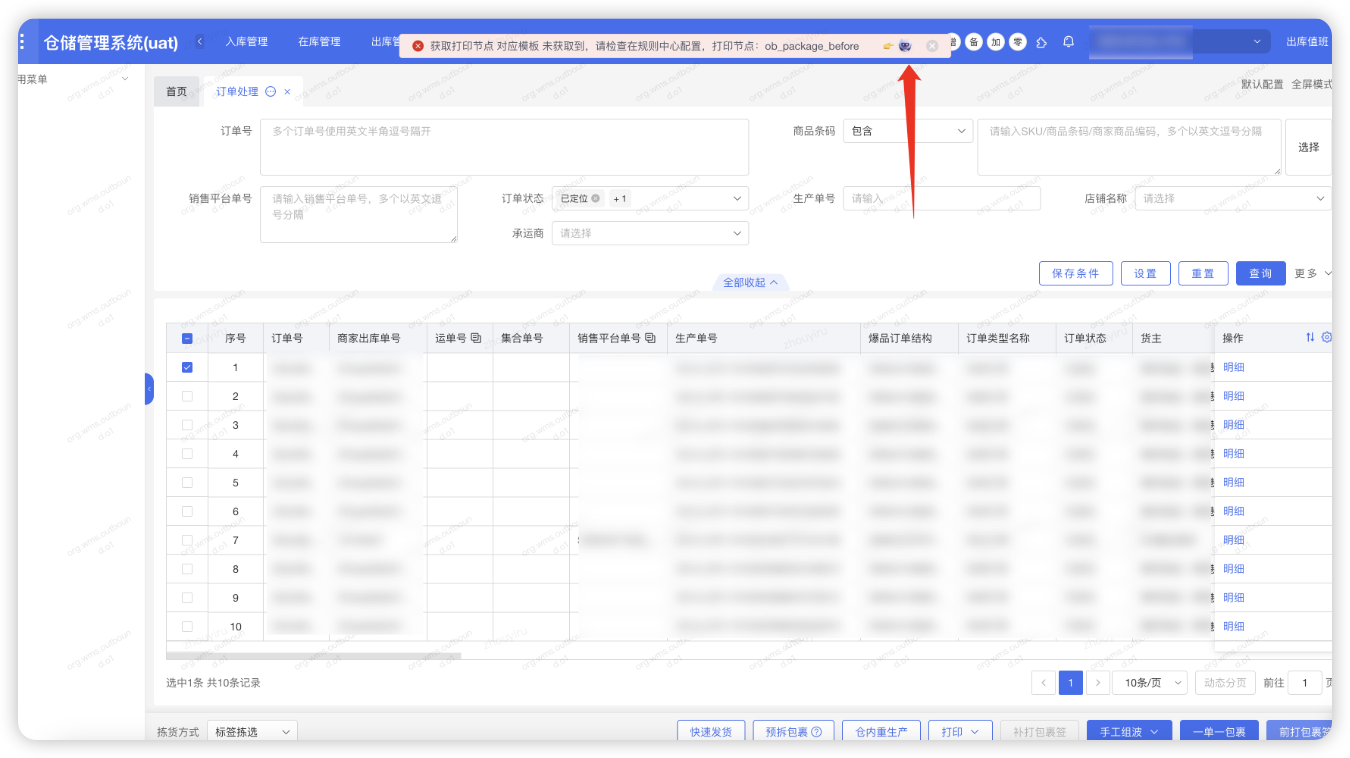
WMS6.0悬浮AI助手,异常一键式反馈,图文输出解决方案
6.0系统异常报错一键式带入
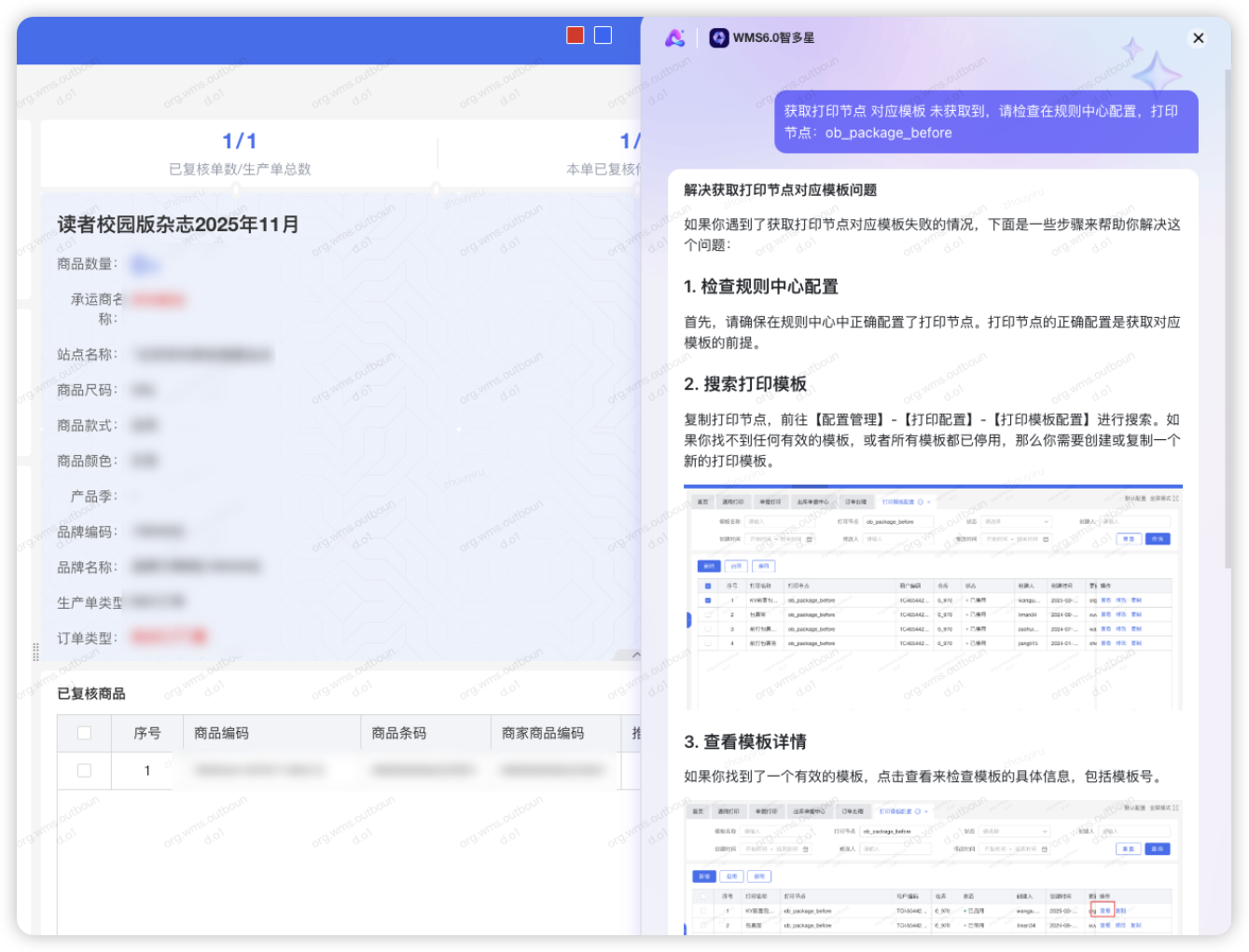
获取打印节点 对应模板 未获取到,请检查在规则中心配置,打印节点:*
报错带入,深度思考解决方案,给出操作步骤和截图,图文反馈。
场景化深度思考,针对生产数据咨询的精准问题定位和指引增强
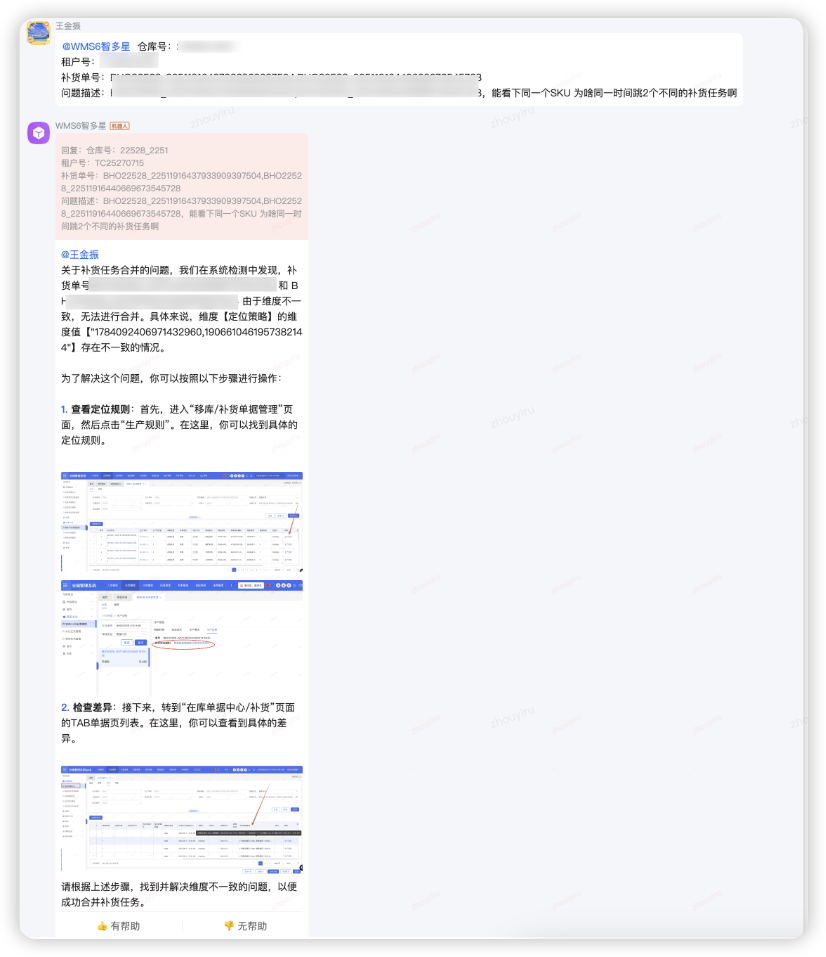
IT拉群提问@WMS6智多星
仓库号:****** 租户号:****** 问题描述:BHO22528_******,BHO22528_******,能看下同一个SKU 为啥同一时间跳2个不同的补货任务啊
深度分析了补货单号未合并的业务逻辑原因,并给出解决步骤,有图片指引。
一线直接咨询WMS6-AI助手
帮我看看*****这个订单上游已经下发了,但是在仓内找不到,卡在哪里了?
深度分析了出库订单的数据状态,以及卡在哪个环节如何处理。


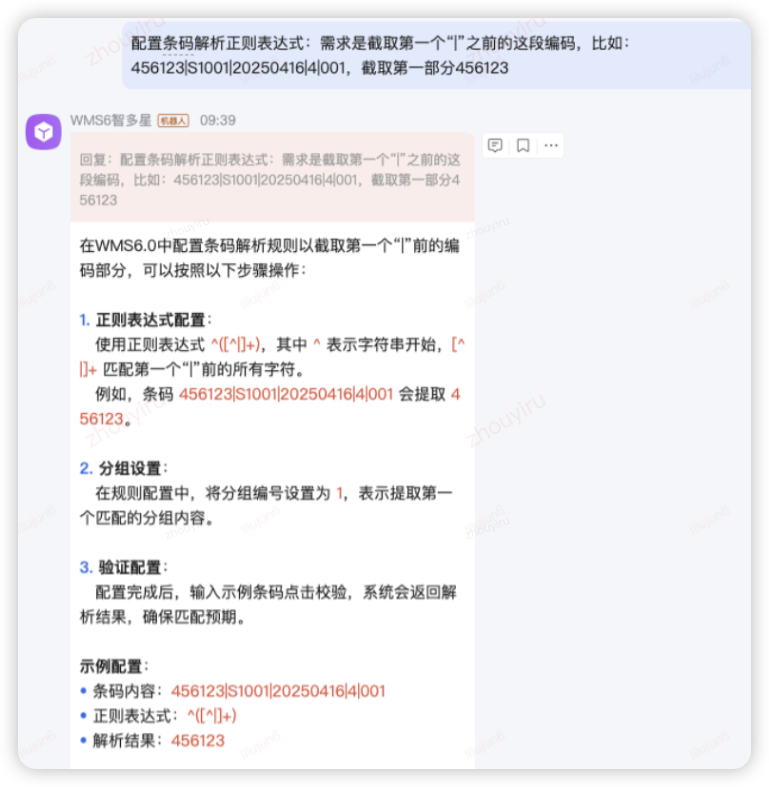
京ME协助业务完成系统配置
条码解析规则的正则表达式很灵活,但是配置略微有难度,可以直接咨询帮助配置的案例。
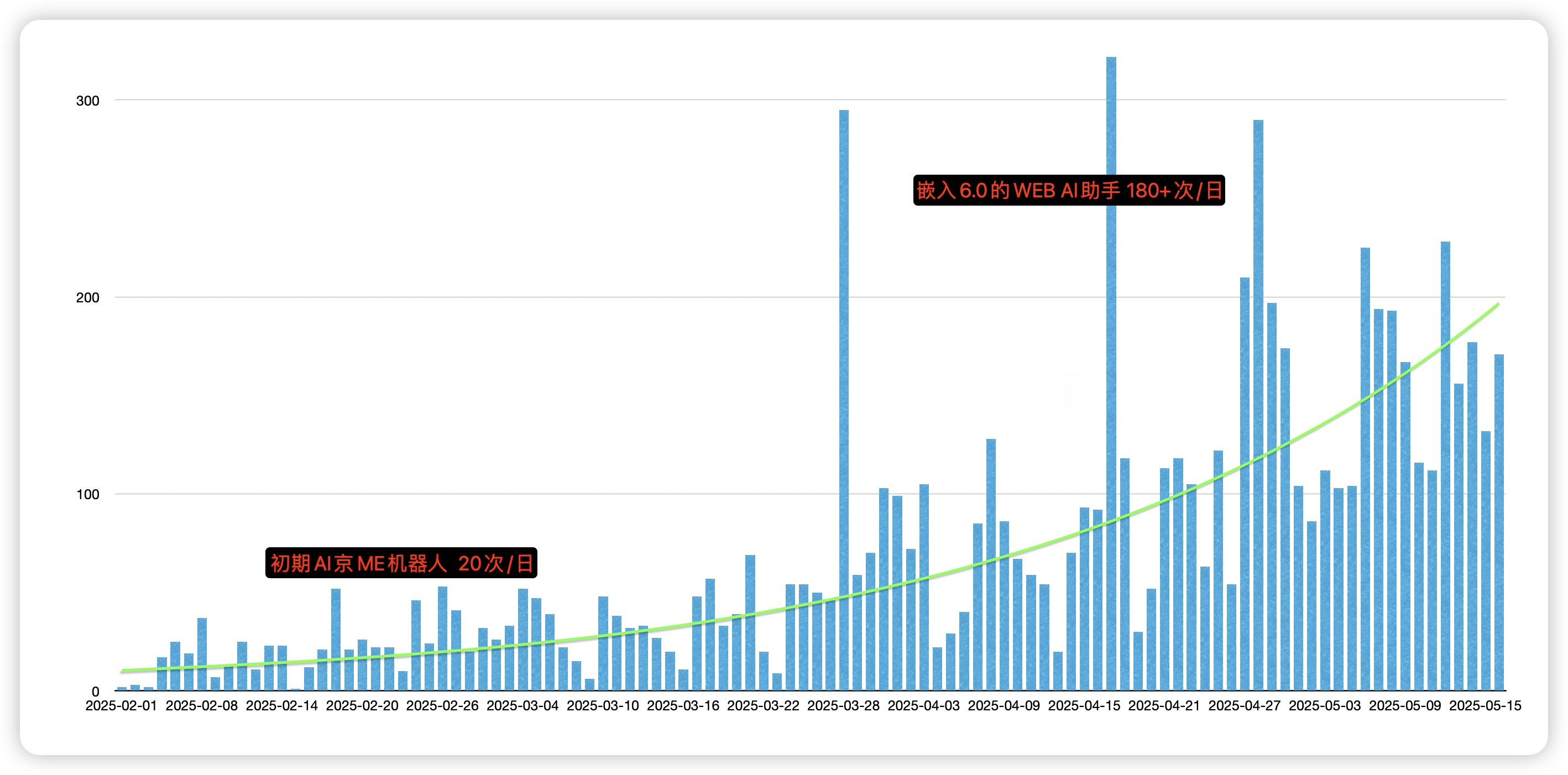
用户流量翻倍上涨,期待提升对用户的有效采纳率
上线之后的用户流量趋势,前期机器人平均20/日,在AI助手嵌入6.0系统上线当天暴增,后面平均160+/日,翻了8倍流量,目前不断上升趋势。当前智多星帮助2000多用户,1w+次回复。也持续观察对用户反馈的有效性,和研发运维值班的工单率。