



在京东,技术从不是冰冷的代码,而是连接消费者与美好生活的桥梁。
在京东零售,我用大模型赋能智能导购、搜索等电商场景,工作期间发表4篇顶会论文,提交专利8篇,并入选北京亦麒麟优秀人才。这些写进顶会论文的技术突破、藏在专利证书里的创新方案,都化作了消费者指尖上的流畅体验。
以下是我的故事,欢迎技术同仁们一起交流——
从校园步入职场后,我深刻体会到理论与实践的差异:学生时代我们往往会寻求"最优解",习惯于拿着技术这把“锤子”去寻找应用场景这颗“钉子”;而在工业界,特别是在京东电商这样复杂的业务环境下,我们更需要寻找"最适解"。
在实际工作中,我面临着诸多教科书上未曾提及的挑战:用户决策阶段的动态变化、电商生态健康与商业效率的平衡、亿级流量下的工程约束…这些复杂问题无法用现成的理论公式直接套用,但正是这些挑战让我感到无比兴奋。
登上顶会SIGIR的商品重排模型
京东主站搜索优化是我在京东的第一个项目,也让我真正体会到算法在工业界落地的独特魅力。在用户调研中我们发现,当消费者搜索某一商品时,传统算法会一股脑展现最畅销的几款,头部结果往往被少数爆款垄断,虽保证点击率却牺牲了长尾商品曝光。搜索排序的意义不是单纯提升点击率,而是精准适配用户决策阶段。
其实问题本质在于,用户搜索时其实处于不同的决策阶段。
在“逛”场景时,需求比较模糊,用户可能从泛化搜索“手机”快速收敛至“iPhone 15 256GB 蓝色”,也可能在“Switch→油烟机→婴儿车”的离散查询中展现多兴趣探索。
在“买”场景是,用户目标明确,需要精准结果缩短决策,如引导用户在搜索“iPhone 15 256GB 蓝色”时直接下单。
而既有的算法模型将多样性与准确性视为互斥目标,采用固定权重线性融合,导致两类指标难以协同优化。
我们在想:“能不能让算法像人类一样,动态理解用户意图?”
传统方法难以捕捉动态用户偏好的动态变化趋势,因此我们决定在模型中引入分布建模来捕捉这种动态性,并提出了名为PODM-MI的重排框架。
第一层用高斯分布建模用户偏好,当用户搜索"连衣裙→碎花连衣裙→蓝色碎花连衣裙"时,协方差持续缩小,则调高准确性权重;当用户搜索"手机→Switch→油烟机"时,则意味协方差增大,需要调高多样性系数。
第二层引入互信息下界优化,让排序结果的多样性与用户偏好高度相关,展现关联商品,避免无关结果。通过互信息最大化实现动态平衡。实现平衡后,商品既不会全是爆款,也不会杂乱无章,而是"用户可能感兴趣的新选择"。
第三层设计效用矩阵融合模块,可以在排序过程中动态调整商品与多样性趋势之间的相对重要程度。
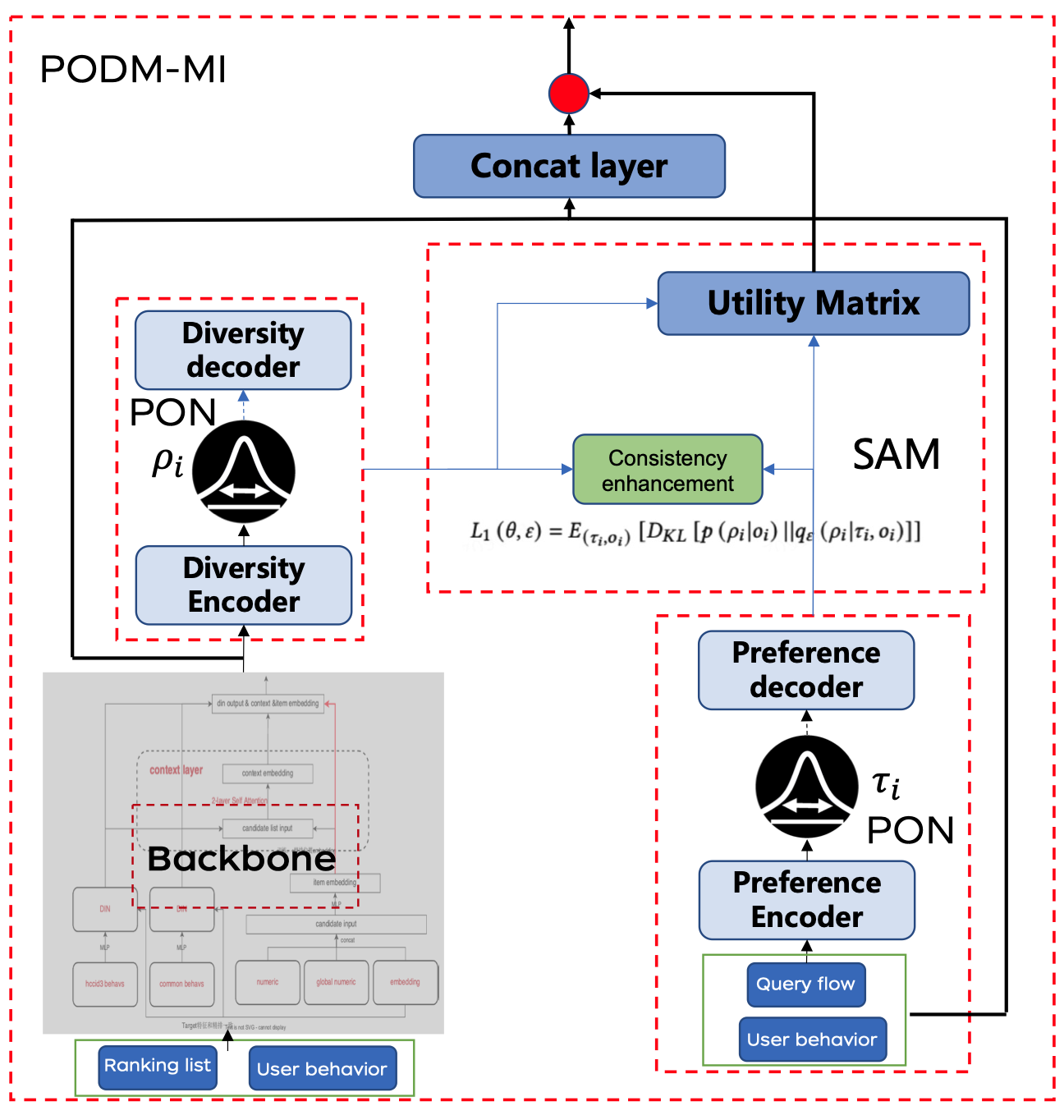
实践证明,这个新方案在业务指标UCVR上取得显著效果,年化订单增量超千万。我们的研究也入选了顶会SIGIR 2024。但说实话,能解决亿级商品匹配的实际问题,让消费者能更快选到心仪的商品,比论文中稿更让人振奋得多。
真正的技术价值在于能否用系统性的解决方案弥合业务需求与技术能力之间的鸿沟。就像木匠不会仅因锤子精巧而骄傲,而在于用合适的工具造出坚固的房屋。技术远见也并非是简单的追逐热点,是立足于业务本质,深入理解业务需求,主动识别那些能为业务带来长期价值的新技术趋势。
发现业界首个技术瓶颈
随着对业务场景的理解不断深入,在团队创新文化氛围下,我们开始尝试突破常规的技术思路。
现在生成式搜索推荐技术正在重塑电商行业的交互范式。我们在推进TIGER方法实践过程中,会为百亿商品基于RQ-VAE来构建语义标识符(SID)。而在构建SID过程中,发现一个奇特现象:
商品的SID编码呈现出"两头宽中间窄"的沙漏形状,两头的商品编码均匀分布在不同区域,而中间层却异常集中。这导致码表可用率异常低,且模型训练难度更大,模型上限被死死卡住,制约着数亿商品的高效匹配。
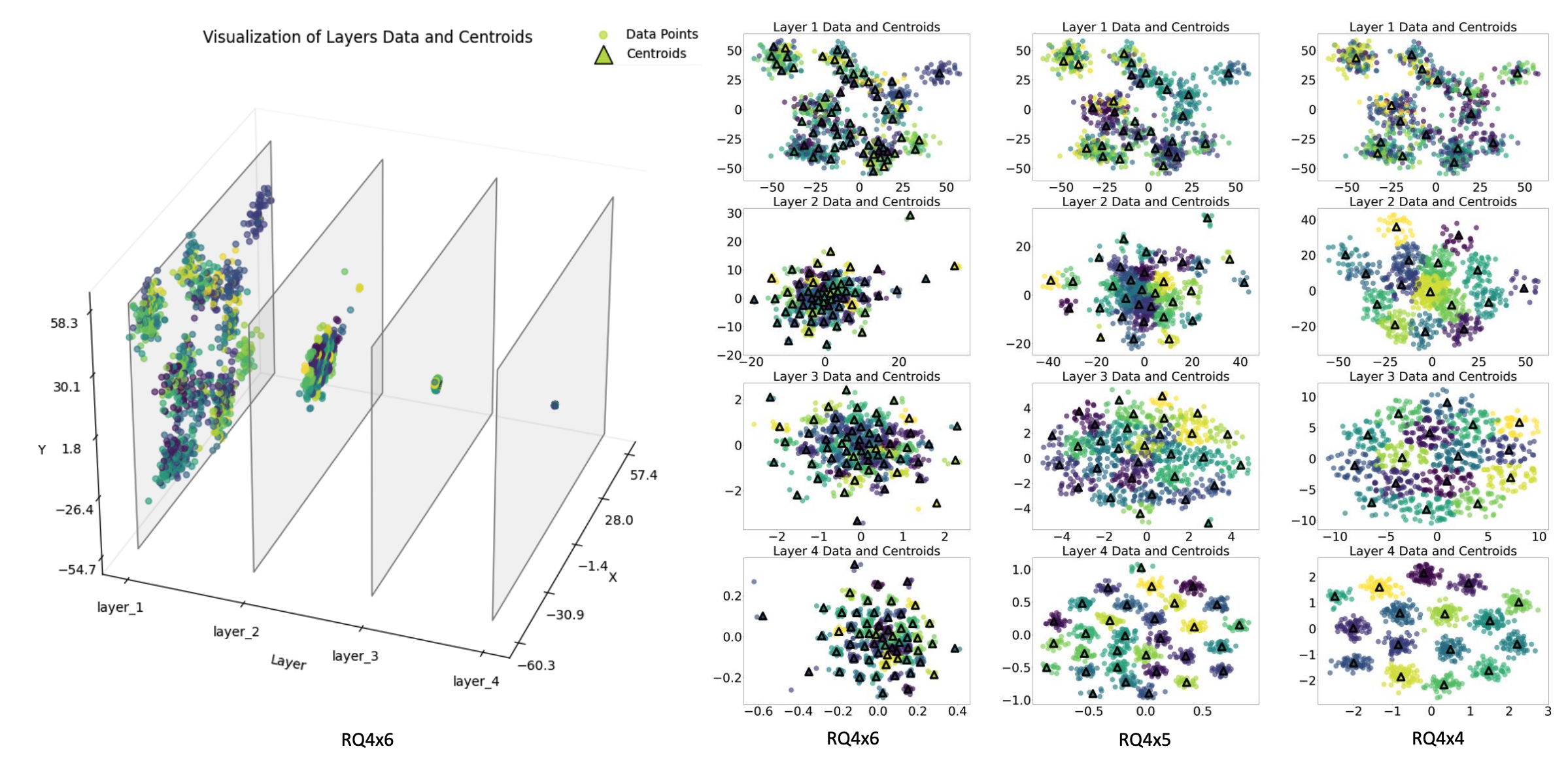
我们对此进行了分析,问题的根源在于RQVAE方法本身的特性。具体来说:第一层对原始商品特征进行粗粒度聚类,此时数据分布相对均匀;第二层处理的残差信息呈现明显极化——多数数据都靠近聚类中心,而少数数据则偏离较远,形成了明显的长尾现象;第三层再次对残差进行聚类,数据分布重新趋于均匀。而本身存在长尾数据分布的电商场景,进一步放大了这种沙漏效应。
经过反复验证,我们确认这个现象是业内首次被系统发现的技术瓶颈,这也是一次真正的从0到1的创新突破。到现在我都还记得当初那种如发现新大陆般的兴奋与悸动,像是探索到了生成式搜推的上限,更打开了一扇预见未来业务形态的窗口。
我们从分布角度提出了两种轻量化解决方案。第一种方案是直接移除中间层的瓶颈节点,在完整生成所有层级的SID后进行第二层节点的移除,移除瓶颈节点,解决长尾集中问题。第二种,我们引入自适应阈值策略,动态地剔除第二层中过于集中的高频节点,保持了整体数据分布的稳定性,有效缓解了“沙漏效应”带来的路径稀疏问题。实验表明,通过这两种方案,合理地移除一定比例的高频节点后,模型离线召回率有显著提升,让用户能更快发现想要的商品。
每当回顾这个发现过程,我都能感受到技术创新最纯粹的魔力——在已知与未知的边界上,用严谨、务实的精神开拓出新的可能。那些学生时代一知半解的技术概念,在日复一日的工程实践中逐渐变得逐渐清晰;不同技术间的关联,也在解决实际业务问题中建立起有机联系,整个技术版图呈现出前所未有的完整面貌。
此刻,是我加入京东的第3年。
那些藏在代码里的画像优化、逻辑迭代、精准匹配,都是京东零售技术人写给用户的情书:"虽然我不知道屏幕外的你是谁,但我想让你购物时,更高效、更快乐。”
这些微小的体验优化,汇聚起来,就是技术让生活更美好的力量。







