



0 引言
本文介绍的音频驱动嘴型视频编辑,是AIGC生成领域中的一个垂直应用方向。在解决业务过程,调研近几年的技术实现路径并进行了创新,在Arxiv上发布一篇论文《JoyGen: Audio-Driven 3D Depth-Aware Talking-Face Video Editing》
项目主页: https://joy-mm.github.io/JoyGen/
论文链接: https://arxiv.org/abs/2501.01798
github链接: https://github.com/JOY-MM/JoyGen
对此感兴趣的小伙伴,欢迎一起交流学习,有相关需求的业务同学也可以聊聊,也辛苦给github项目点个⭐
1 摘要
近年来,说话人脸视频生成研究取得了显著进展。然而,在根据输入音频编辑唇部形状时,精确的音频嘴型同步和高品质视觉质量仍然是亟待解决的难题。本文提出了一种名为 JoyGen 的新颖两阶段框架,用于生成说话人脸视频,包括音频驱动的唇部动作生成和视觉外观合成。第一阶段中,利用3D重建模型和音频驱动的动作生成模型分别预测基于3DMM的身份系数和表情系数。随后,通过将音频特征与面部深度图相结合,为面部生成中的音频嘴型同步提供全面的监督信号。此外,我们构建了一个包含130小时高质量视频的中文说话人脸数据集。JoyGen 在开源的 HDTF 数据集和我们精心整理的数据集上进行训练。实验结果表明,我们的方法在音频嘴型同步和视觉质量方面均表现出色。
2 方法
整体流程图参考图1,上半部分为训练过程的pipeline,下半部分为推理过程的pipeline。
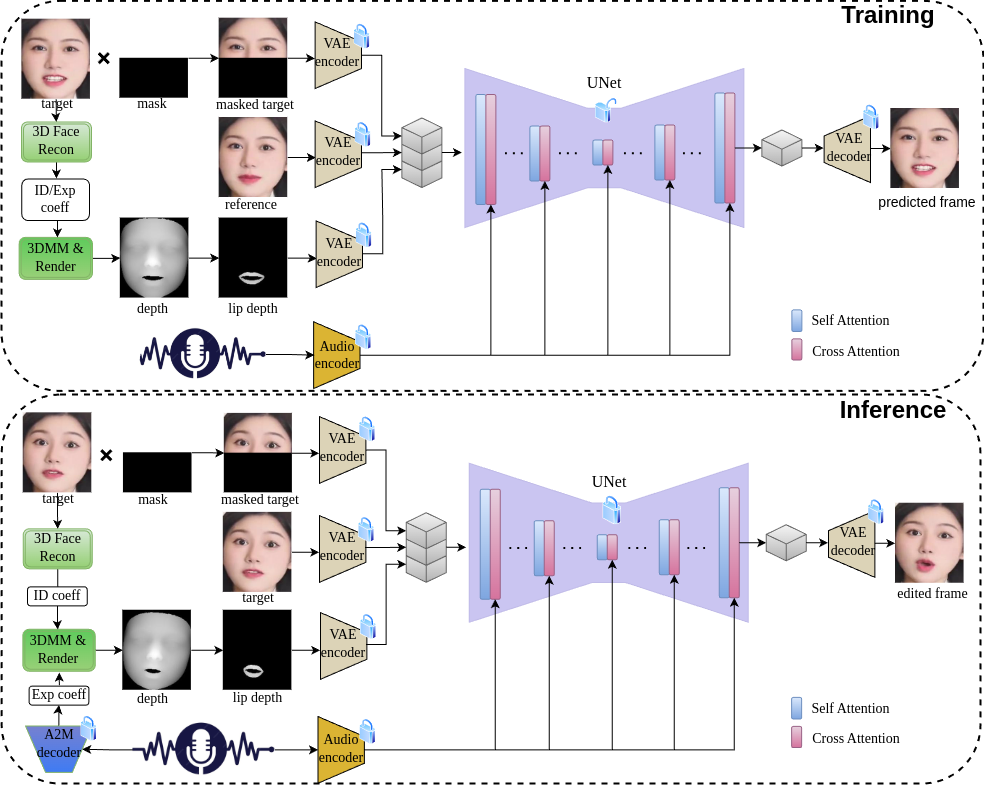
图1
2.1 三维可变形模型
V.Blanz等人在2003年提出了三维可变形模型3DMM,使用PCA描述三维人脸结构如下:
其中是3D面部的平均形状, 和 分别代表身份和表情正交基。系数和分别控制面部身份和表情。
2.2 音频到嘴型运动
我们采用了一种流增强变分自编码器,可以高效且准确地学习从音频到面部动作的映射关系。鉴于3DMM面部网格由身份系数和表情系数所决定,因此在重建同一人的3D面部网格时,身份系数固定,3D面部网格的重建就仅依赖于表情系数。
2.3 面部深度图
单张人脸图像的身份系数和表情系数可以通过3DMM拟合方法获取,也可以直接通过神经网络预测。在本文中,我们采用 Deep3DFaceRecon 提出的方法,从单张图像中预测3DMM模型的身份和表情系数。在数据预处理阶段,利用预测的表情系数和身份系数生成3D面部网格,并通过渲染获取面部深度图。在推理阶段,由Real3DPortrait 训练的 A2M 模型预测的表情系数替代原始表情系数,以生成相应的面部深度图,如图1 推理pipeline所示。
2.4 编辑说话人脸
人脸编码 这一过程首先使用预训练的图像编码器将输入图像从像素空间映射到低维潜在空间。此降维操作显著降低了后续步骤的计算负担。
单步人脸合成 我们采用类似于MuseTalk的单次预测 UNet 架构。与从随机噪声开始的扩散模型不同,我们的方法基于当前视频帧(其嘴部区域被遮挡)进行预测,旨在生成与给定音频对齐的唇部动作。此策略简化了传统扩散模型中对全脸信息预测的复杂性。此外,通过使用额外的参考图像作为输入来提供可靠的面部上下文信息,从而增强目标对象面部信息生成的准确性。
基于人类直觉,音频信号与说话者面部动作(尤其是头部姿态变化和眨眼)的相关性往往较弱。本研究重点关注音频信号与唇部动作之间的直接关系。为了更好地建模由音频驱动的嘴部区域动态,我们引入了嘴部区域的深度信息,以加强音频信号与嘴部发声运动之间的对齐。
在这一阶段,采用单步预测的 UNet 方法,其输入包括被遮挡嘴部区域的目标帧、距离目标帧帧之外的随机参考帧、目标帧的唇部区域深度图 以及音频信号。在使用 VAE 对图像数据进行编码后,生成的特征分别标记为 、 和 ,而音频信号则通过 Whisper 编码为 。随后,将三个图像特征沿着 VAE 特征通道维度拼接,形成 UNet 结构的输入
而音频特征则是通过交叉注意力机制与图像特征进行交互。
人脸解码 在潜在空间中完成单步预测后,生成的潜在表示通过解码器解码回图像空间,从而生成输出图像。
3 数据集
目前大多数公开可用的说话人脸数据集主要集中于英语场景。为了促进中文场景中的应用,我们构建了一个高清中文说话人脸数据集,该数据集包含中文语言的视频。为确保数据集的质量,我们实施了严格的人工筛选和审查流程。视频来源于B站和抖音平台,并将播放质量提升至可用的最高分辨率。筛选标准包括:(1) 每个账号仅选取一个视频以保证多样性;(2) 每个视频中仅有一个可见人脸;(3) 音频与说话者身份一致;(4) 嘴部区域或牙齿清晰可见;(5) 音频为中文且无显著背景音乐或噪声干扰。
最终数据集包含约1.1k个视频,视频时长从46秒到52分钟不等,总时长约为130小时。我们对数据集进行了全面的统计分析,包括视频时长、帧率、性别分布及人脸尺寸等,如图2 所示。
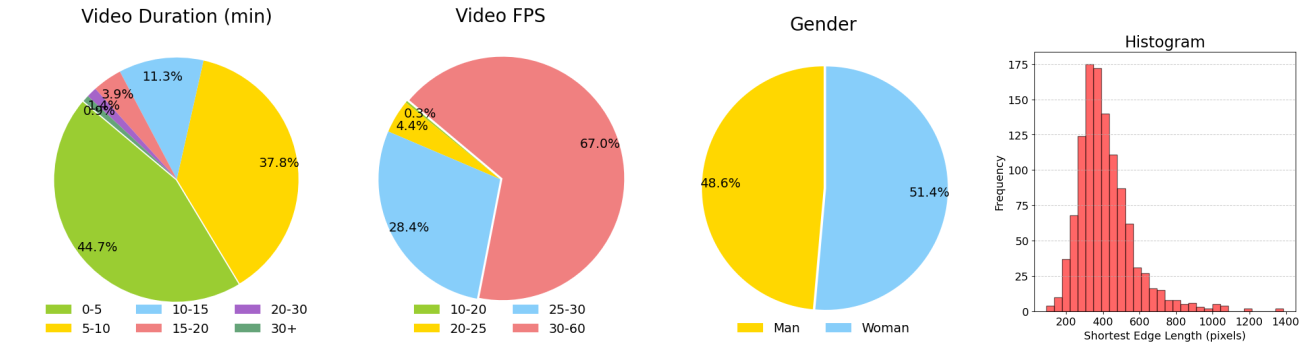
图 2
4 训练细节
损失函数 由于潜在空间的分辨率相对较低,难以捕捉面部的细节信息,我们在潜在空间和图像空间中都采用了L1损失函数。 用于度量真实帧和预测帧的VAE编码特征之间的L1距离,而 用于计算两者在归一化图像域中的L1距离。
深度信息选取 我们采用Deep3DFaceRecon中的3D人脸重建方法,从视频帧中预测身份系数和表情系数。由于仅对人脸的下半部分进行预测,因此面部深度图中仅保留嘴部区域的深度信息,而其他区域的深度值均设置为零。本文中嘴部区域的定义基于Mediapipe 提供的80个关键点。在实际操作中,音频驱动的3D人脸网格有时会出现嘴部区域与真实面部不对齐的情况。为了在推理过程中改进预测嘴部深度信息与原始面部图像之间的空间对齐性,在训练时对嘴部区域的深度信息应用了随机位移扰动,旨在减少音频驱动唇部运动生成过程中的对齐误差。此外,我们将嘴部深度图序列视为一种强监督信号。因此,在训练过程中,有50%的情况下随机忽略深度信息,以便模型能够充分利用音频特征,更有效地学习音频信号与嘴部运动之间的关系。
5 实验
5.1 数据预处理
实验中使用的训练集包括开源的HDTF数据集和我们整理的数据集。在数据预处理过程中,我们首先对视频进行分段,仅保留包含单张人脸的片段,剔除无脸或多人脸的部分。随后,我们使用MTCNN检测器提取五个面部关键点,作为深度3D重建模型的输入,以预测3DMM系数。最后,我们使用DWPose提取面部边界框,用于裁剪面部区域和对应深度图。对于较长的视频,我们以每秒25帧的速率提取帧,并随机选择10,000帧,以确保模型的泛化能力。
5.2 实验设置
实现细节 我们的模型从零开始训练,使用8块NVIDIA H800 GPU,耗时一天完成训练。所有输入图像均调整为256x256的分辨率。Batchsize大小设置为128,梯度累计步长为1。优化器采用Adam,学习率为。潜在特征空间和像素空间的损失权重分别设置为和。
评价指标 由于缺乏真实的说话人脸视频作为对比,我们使用FID评估生成视频的视觉质量。为了评估唇部运动与音频的同步性,我们使用Wav2Lip中提出的LSE-C和LSE-D指标。根据Wav2Lip中描述的无配对评估设置,我们从不同视频中分别选择一个视频片段和一个音频片段进行合成。对于HDTF数据集和我们收集的数据集,我们分别生成约500和900对音视频,每对音视频的时长约为10秒。
基线模型 在我们的定量对比实验中,我们选择了几个开源实现作为比较,包括Wav2Lip和MuseTalk。我们修改了Wav2Lip的代码,先重新训练唇部同步专家模型,然后训练生成模型。为了获得更好的结果,我们参考了MuseTalk,重新实现了生成说话人脸视频的训练代码。对上述两个数据集进行了对比实验。
5.3 实验结果
5.3.1 定量结果
HDTF数据集上的比较 表1展示了HDTF数据集上的定量评估结果,表明我们提出的DeepTalkFace方法在所有指标上均优于其他方法。此外,图3中显示了每种方法的LSE-D和LSE-C分数的分布曲线,进一步证明了JoyGen的卓越性能。
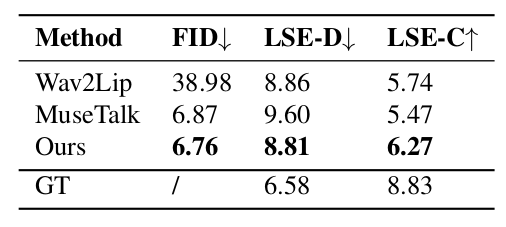
表 1
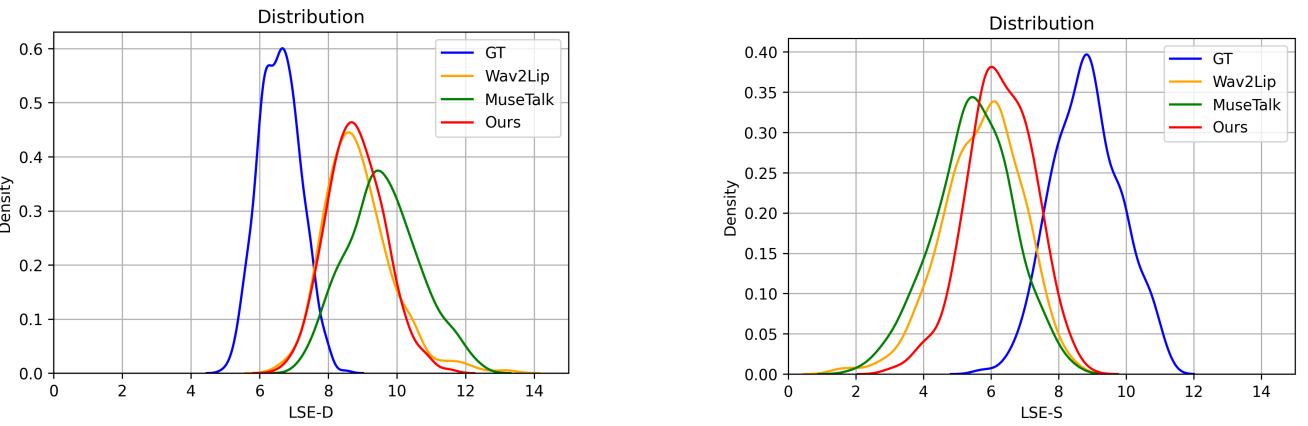
图 3
在我们收集的数据集上比较 我们进一步在我们收集的数据集上评估了所提出的JoyGen方法和其他方法。如表2所示,JoyGen的FID得分最低,为3.19,表明与现有方法相比,在视觉质量上有显著改善。此外,我们的方法在唇音同步上表现出色,LSE-D和LSE-C得分与该数据集的真实值非常接近。图4中展示了每种方法的LSE-D和LSE-C分数分布曲线,进一步证明了JoyGen在同步性能方面的优越性。
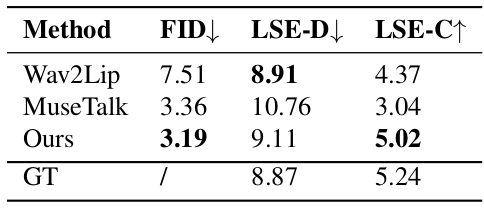
表 2
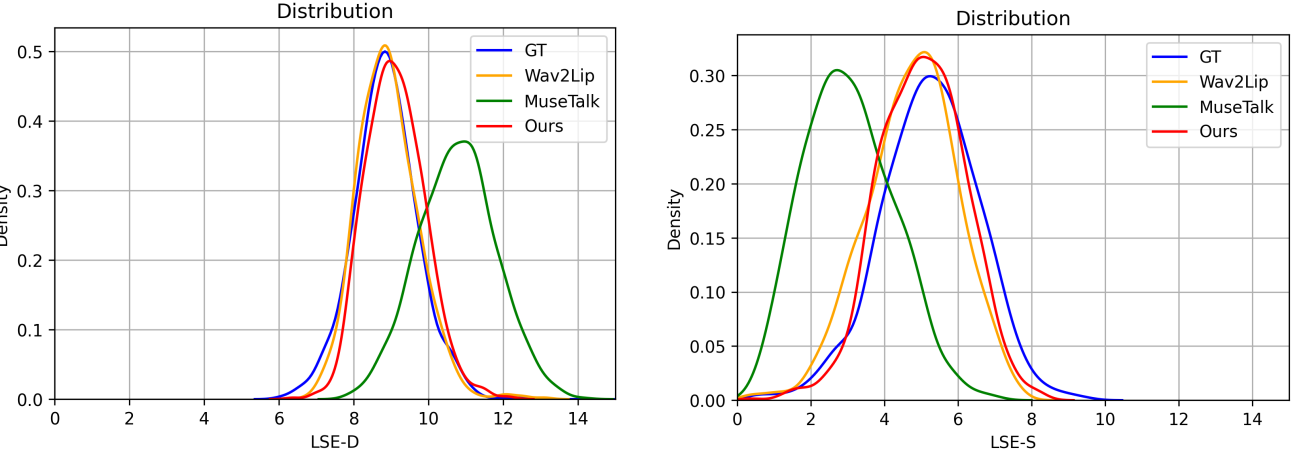
图4
5.3.2 定性结果
为了更直观地评估唇形同步和视觉质量,我们进行了几种方法的直观比较分析。图5展示了每个生成视频中的唇部动态以及参考驱动视频。每一列包含视频中的六个连续帧。我们的方法在视频质量和唇部运动精确度上表现更优。在左侧的驱动视频中,嘴唇从张开到闭合再到张开;而在右侧,它从闭合到张开。只有我们的方法保持了与驱动视频一致的唇形对齐。尽管基于Wav2Lip的视频在LSE-D和LSE-C得分上更好,但Wav2Lip往往会生成模糊的嘴部区域。
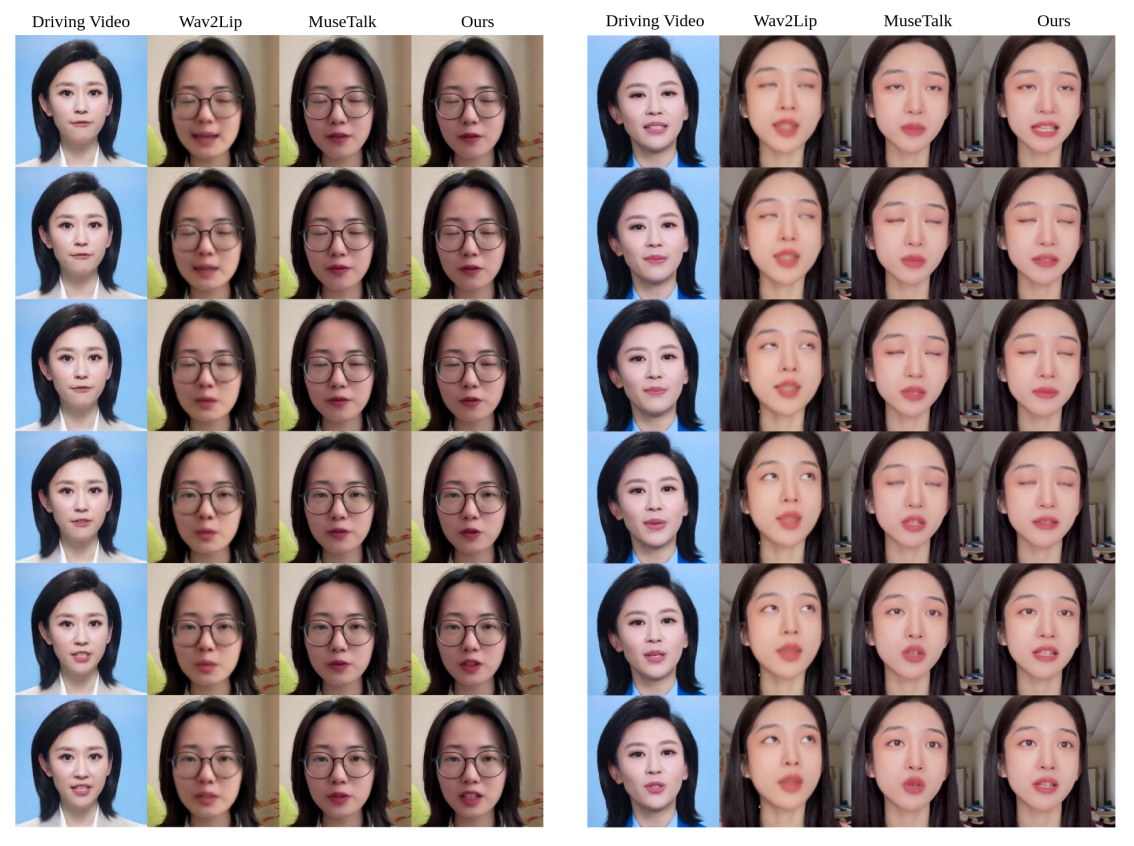
图 5
6 结束
最后感谢大家看完这篇文章,也欢迎大家一起交流学习,共同讨论AIGC未来发展。





