您好!
欢迎来到京东云开发者社区
登录
首页
博文
课程
大赛
工具
用户中心
开源
首页
博文
课程
大赛
工具
开源
更多
用户中心
开发者社区
>
博文
>
大促数据库压力激增,如何一眼定位 SQL 执行来源?
分享
打开微信扫码分享
点击前往QQ分享
点击前往微博分享
点击复制链接
大促数据库压力激增,如何一眼定位 SQL 执行来源?
wy****
2025-06-09
IP归属:北京
646浏览
你是否曾经遇到过这样的情况:在大促活动期间,用户访问量骤增,数据库的压力陡然加大,导致响应变慢甚至服务中断?更让人头疼的是,当你试图快速定位问题所在时,却发现难以确定究竟是哪个业务逻辑中的 SQL 语句成为了性能瓶颈。面对这样的困境,本篇文章提出了对 SQL 进行 “染色” 的方法来帮助大家 **一眼定位问题 SQL,而无需再在多处逻辑中辗转腾挪**。本文的思路主要受之前郭忠强老师发布的 [如何一眼定位SQL的代码来源:一款SQL染色标记的简易MyBatis插件](http://sd.jd.com/article/42942?shareId=53471&isHideShareButton=1) 文章启发,我在这个基础上对逻辑进行了简化,去除了一些无关的逻辑和工具类,并只对查询 SQL 进行染色,使这个插件“更轻”。此外,本文除了提供 Mybatis 拦截器的实现以外,还提供了针对 ibatis 框架实现拦截的方法,用于切入相对比较老的应用,希望对大家有所启发~ 在文章开展之前,我们先来了解一下什么是 SQL 染色:染色的含义是 **在 SQL 执行前,在 SQL 上进行注释打标,标记内容为这条 SQL 对应的是 Mapper 文件中的哪条 SQL 以及相关的方法执行堆栈**,如下为在 SGM 的 SQL 执行监控端能直接看到 SQL 染色信息: 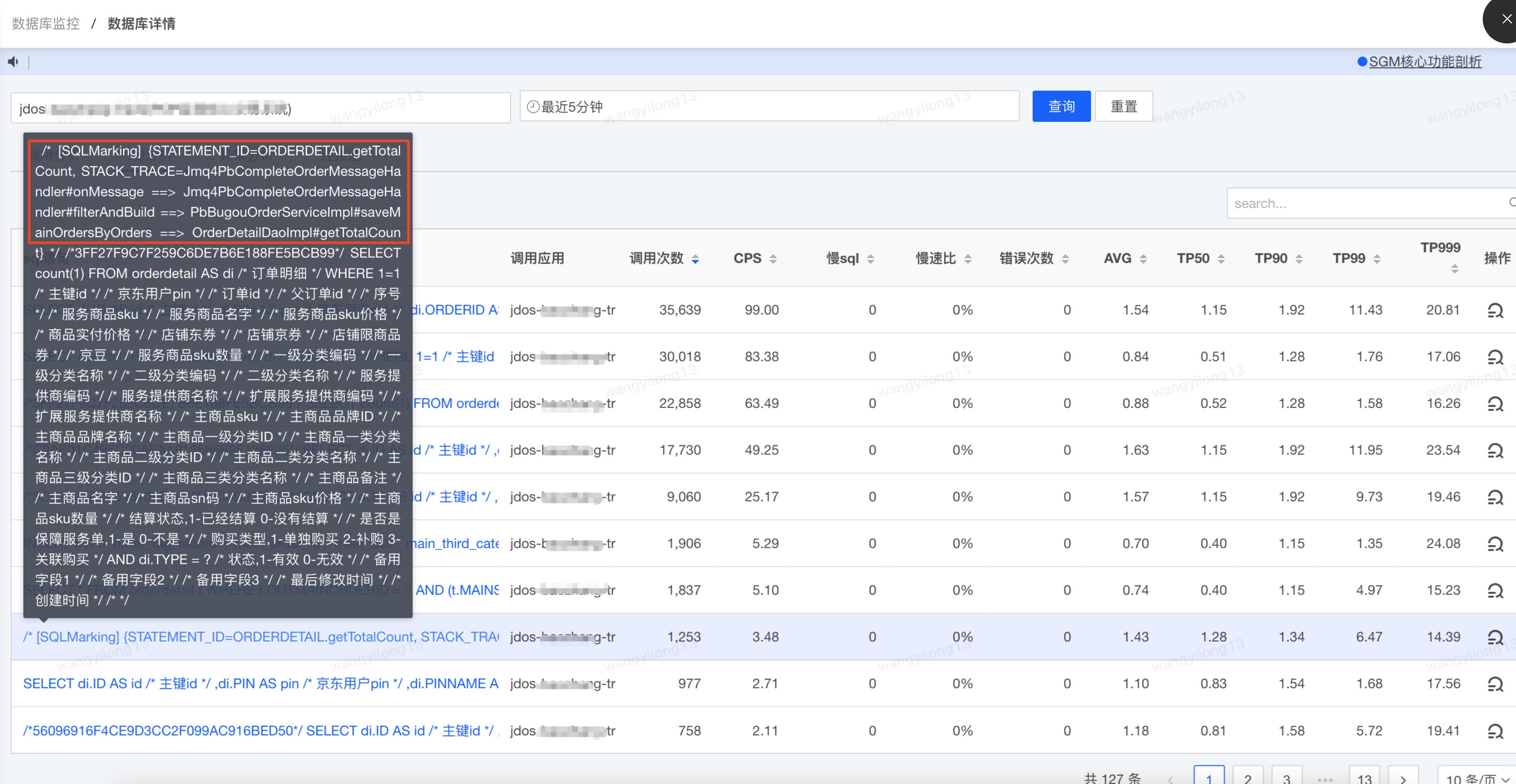 这样便能够非常轻松地看到到底是什么逻辑执行了哪段 SQL,并且经过实际生产性能验证,染色操作耗时在 0 ~ 1ms 左右: ```text [JSF-BZ-22000-366-T-20] INFO c.j.b.t.s.SqlExecutorInterceptor [67] - SQL 染色耗时:0ms [JSF-BZ-22000-366-T-20] INFO c.j.b.t.s.SqlExecutorInterceptor [67] - SQL 染色耗时:0ms [JSF-BZ-22000-366-T-20] INFO c.j.b.t.s.SqlExecutorInterceptor [67] - SQL 染色耗时:1ms [JSF-BZ-22000-366-T-20] INFO c.j.b.t.s.SqlExecutorInterceptor [67] - SQL 染色耗时:1ms [JSF-BZ-22000-366-T-20] INFO c.j.b.t.s.SqlExecutorInterceptor [67] - SQL 染色耗时:1ms [JSF-BZ-22000-366-T-20] INFO c.j.b.t.s.SqlExecutorInterceptor [67] - SQL 染色耗时:0ms [JSF-BZ-22000-366-T-20] INFO c.j.b.t.s.SqlExecutorInterceptor [67] - SQL 染色耗时:1ms [JSF-BZ-22000-366-T-20] INFO c.j.b.t.s.SqlExecutorInterceptor [67] - SQL 染色耗时:0ms [JSF-BZ-22000-366-T-20] INFO c.j.b.t.s.SqlExecutorInterceptor [67] - SQL 染色耗时:0ms [JSF-BZ-22000-366-T-20] INFO c.j.b.t.s.SqlExecutorInterceptor [67] - SQL 染色耗时:1ms ``` 现在我们已经对 SQL 染色有了基本的了解,下面将介绍两种实现染色的方式:**Mybatis 拦截器实现和基于 AspectJ 织入实现**。在接下来的内容中我会展示染色实现的源码信息,但是并不复杂,代码量只有百行,所以大家可以直接将文章中的代码逻辑复制到项目中实现即可。 ### 快速接入 SQL 染色 - **Mybatis 框架应用接入**:跳转 “全量源码” 小节,复制拦截器源码到应用中,并在 Mybatis 拦截器配置中添加该拦截器便可以生效,注意修改源码中 `com.your.package` 包路径为当前应用的有效包路径 - **非 Mybatis 框架应用接入**:参考 “基于 AspectJ 织入实现” 小节,通过对 SQL 执行相关 Jar 包进行拦截实现 ### Mybatis 拦截器实现 在展示具体实现前,我还是想通过给大家介绍原理的形式一步步将其实现,这样也能加深大家对 Mybatis 框架的理解,也欢迎大家阅读、订阅专栏 [由 Mybatis 源码畅谈软件设计](http://sd.jd.com/column/419?shareId=53471&isHideShareButton=1)。如果不想看实现原理,直接看实现的话请跳转 **全量源码** 小节。 #### 拦截器的作用范围 Mybatis 的拦截器不像 Spring 的 AOP 机制,它并不能在任意逻辑处进行切入。在 Mybatis 源码的 `Configuration` 类中,定义了它的拦截器的作用范围,即创建“四大处理器”时调用的 `pluginAll` 方法: ```java public class Configuration { // ... protected final InterceptorChain interceptorChain = new InterceptorChain(); public ParameterHandler newParameterHandler(MappedStatement mappedStatement, Object parameterObject, BoundSql boundSql) { ParameterHandler parameterHandler = mappedStatement.getLang().createParameterHandler(mappedStatement, parameterObject, boundSql); // 拦截器相关逻辑 return (ParameterHandler) interceptorChain.pluginAll(parameterHandler); } public ResultSetHandler newResultSetHandler(Executor executor, MappedStatement mappedStatement, RowBounds rowBounds, ParameterHandler parameterHandler, ResultHandler resultHandler, BoundSql boundSql) { ResultSetHandler resultSetHandler = new DefaultResultSetHandler(executor, mappedStatement, parameterHandler, resultHandler, boundSql, rowBounds); // 拦截器相关逻辑 return (ResultSetHandler) interceptorChain.pluginAll(resultSetHandler); } public StatementHandler newStatementHandler(Executor executor, MappedStatement mappedStatement, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) { StatementHandler statementHandler = new RoutingStatementHandler(executor, mappedStatement, parameterObject, rowBounds, resultHandler, boundSql); // 拦截器相关逻辑 return (StatementHandler) interceptorChain.pluginAll(statementHandler); } public Executor newExecutor(Transaction transaction, ExecutorType executorType) { executorType = executorType == null ? defaultExecutorType : executorType; // 创建具体的 Executor 实现类 Executor executor; if (ExecutorType.BATCH == executorType) { executor = new BatchExecutor(this, transaction); } else if (ExecutorType.REUSE == executorType) { executor = new ReuseExecutor(this, transaction); } else { executor = new SimpleExecutor(this, transaction); } if (cacheEnabled) { executor = new CachingExecutor(executor); } // 拦截器相关逻辑 return (Executor) interceptorChain.pluginAll(executor); } } ``` `pluginAll` 是让拦截器生效的逻辑,它具体是如何做的呢: ```java public class InterceptorChain { // 所有配置的拦截器 private final List<Interceptor> interceptors = new ArrayList<>(); public Object pluginAll(Object target) { for (Interceptor interceptor : interceptors) { // 注意 target 引用不断变化,会不断引用已经添加拦截器的对象 target = interceptor.plugin(target); } return target; } // ... } ``` `InterceptorChain` 实现非常简单,内部定义了集合来保存所有配置的拦截器,执行 `pluginAll` 方法时会遍历该集合,逐个调用 `Interceptor#plugin` 方法来 “不断地叠加拦截器”(`interceptor.plugin` 方法执行时,`target` 引用不断变更)。 > 注意这里使用到了 **责任链模式**,由 `InterceptorChain` 的命名中包含 `Chain` 也能联想到该模式,之后我们在使用责任链时也可以考虑在命名中增加 `Chain` 以增加可读性。`InterceptorChain` 将多个拦截器串联在一起,每个拦截器负责其特定的逻辑处理,并在执行完自己的逻辑后,调用下一个拦截器或目标方法,这样设计允许不同的拦截器之间的逻辑 **解耦**,同时提供了 **可扩展性**。 由此可知,拦截器的作用范围是 `ParameterHandler`, `ResultSetHandler`, `StatementHandler` 和 `Executor` 处理器(Handler),但是拦截它们又能实现什么效果呢? 要弄清楚这个问题,首先我们需要了解拦截器能够切入的粒度。在 Mybatis 框架中,定义拦截器时需要使用 `@Intercepts` 和 `@Signature` 注解来 **配置切入的方法**,如下所示: ```java @Intercepts({ @Signature(method = "prepare", type = StatementHandler.class, args = {Connection.class, Integer.class}) }) @Service public class SQLMarkingInterceptor implements Interceptor { // ... } ``` 每个拦截器切入的 **粒度是方法级别的** 的,比如在我们定义的这个拦截器中,切入的是 `StatementHandler#prepare` 方法,那么如果我们了解了四个处理器方法的作用是不是就能知道 Mybatis 拦截器所能实现的功能了?所以接下来我们简单了解一下它们的各个方法的作用: * `ParameterHandler`: 核心方法 `setParameters`,它的作用主要是将 Java 对象转换为 SQL 语句中的参数,并处理参数的设置和映射,所以拦截器切入它能 **对 SQL 执行的入参进行修改** ```java public interface ParameterHandler { Object getParameterObject(); void setParameters(PreparedStatement ps) throws SQLException; } ``` * `ResultSetHandler`: 负责将 SQL 查询返回的 `ResultSet` 结果集转换为 Java 对象,拦截器切入它的方法能 **对结果集进行处理** ```java public interface ResultSetHandler { /** * 处理 Statement 对象并返回结果对象 * * @param stmt SQL 语句执行后返回的 Statement 对象 * @return 映射后的结果对象列表 */ <E> List<E> handleResultSets(Statement stmt) throws SQLException; /** * 处理 Statement 对象并返回一个 Cursor 对象 * 它用于处理从数据库中获取的大量结果集,与传统的 List 或 Collection 不同,Cursor 提供了一种流式处理结果集的方式, * 这在处理大数据量时非常有用,因为它可以避免将所有数据加载到内存中 * * @param stmt SQL 语句执行后返回的 Statement 对象 * @return 游标对象,用于迭代结果集 */ <E> Cursor<E> handleCursorResultSets(Statement stmt) throws SQLException; /** * 处理存储过程的输出参数 * * @param cs 存储过程调用的 CallableStatement 对象 */ void handleOutputParameters(CallableStatement cs) throws SQLException; } ``` * `Executor`: 它的方法很多,概括来说它负责数据库操作,包括增删改查等基本的 SQL 操作、管理缓存和事务的提交与回滚,所以拦截器切入它主要是 **管理执行过程或事务** ```java public interface Executor { ResultHandler NO_RESULT_HANDLER = null; // 该方法用于执行更新操作(包括插入、更新和删除),它接受一个 `MappedStatement` 对象和更新参数,并返回受影响的行数 int update(MappedStatement ms, Object parameter) throws SQLException; // 该方法用于执行查询操作,接受 `MappedStatement` 对象(包含 SQL 语句的映射信息)、查询参数、分页信息、结果处理器等,并返回查询结果的列表 <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey cacheKey, BoundSql boundSql) throws SQLException; <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException; <E> Cursor<E> queryCursor(MappedStatement ms, Object parameter, RowBounds rowBounds) throws SQLException; // 该方法用于刷新批处理语句并返回批处理结果 List<BatchResult> flushStatements() throws SQLException; // 该方法用于提交事务,参数 `required` 表示是否必须提交事务 void commit(boolean required) throws SQLException; // 该方法用于回滚事务。参数 `required` 表示是否必须回滚事务 void rollback(boolean required) throws SQLException; // 该方法用于创建缓存键,缓存键用于标识缓存中的唯一查询结果 CacheKey createCacheKey(MappedStatement ms, Object parameterObject, RowBounds rowBounds, BoundSql boundSql); // 该方法用于检查某个查询结果是否已经缓存在本地 boolean isCached(MappedStatement ms, CacheKey key); // 该方法用于清空一级缓存 void clearLocalCache(); // 该方法用于延迟加载属性 void deferLoad(MappedStatement ms, MetaObject resultObject, String property, CacheKey key, Class<?> targetType); // 该方法用于获取当前的事务对象 Transaction getTransaction(); // 该方法用于关闭执行器。参数 `forceRollback` 表示是否在关闭时强制回滚事务 void close(boolean forceRollback); boolean isClosed(); // 该方法用于设置执行器的包装器 void setExecutorWrapper(Executor executor); } ``` * `StatementHandler`: 它的主要职责是准备(`prepare`)、“承接”封装 SQL 执行参数的逻辑,执行SQL(`update`/`query`)和“承接”处理结果集的逻辑,这里描述成“承接”的意思是这两部分职责并不是由它处理,而是分别由 `ParameterHandler` 和 `ResultSetHandler` 完成,所以拦截器切入它主要是 **在准备和执行阶段对 SQL 进行加工等** ```java public interface StatementHandler { Statement prepare(Connection connection, Integer transactionTimeout) throws SQLException; void parameterize(Statement statement) throws SQLException; void batch(Statement statement) throws SQLException; int update(Statement statement) throws SQLException; <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException; <E> Cursor<E> queryCursor(Statement statement) throws SQLException; BoundSql getBoundSql(); ParameterHandler getParameterHandler(); } ``` 为了加深大家对这四个处理器的理解,了解它在查询 SQL 执行时作用的时机,我们来看一下查询 SQL 执行时的流程图: 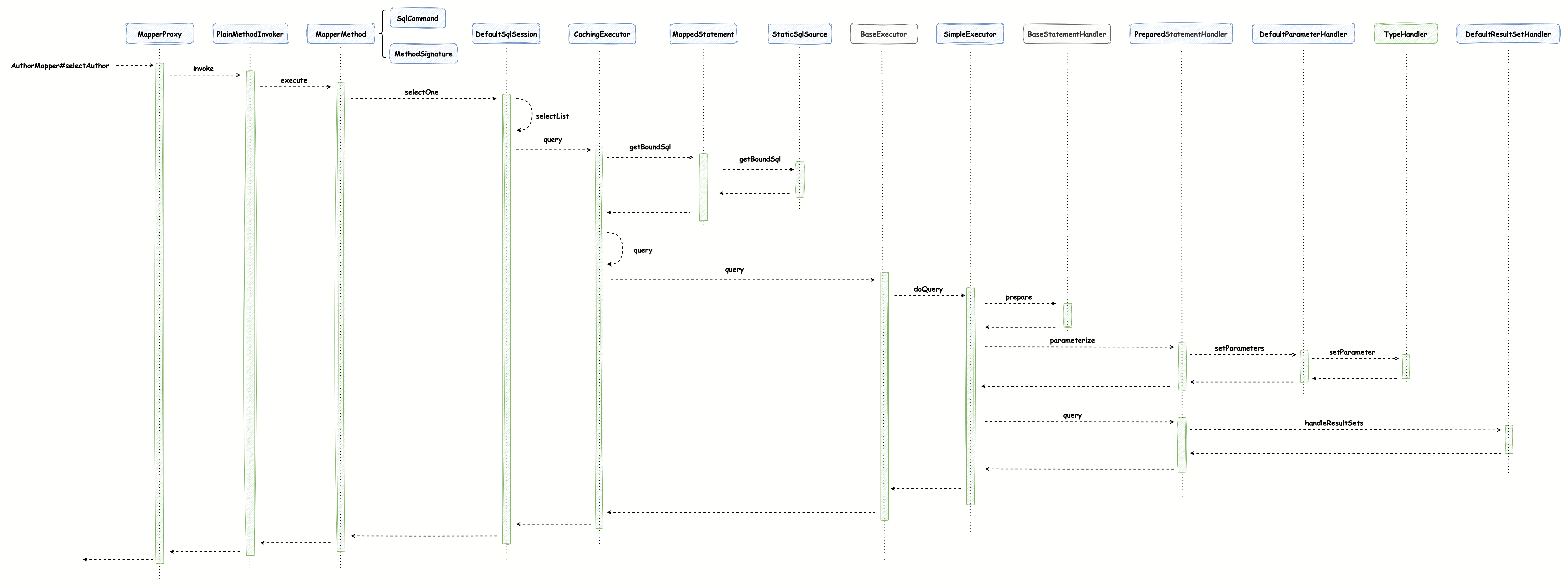 每个声明 SQL 查询语句的 Mapper 接口都会被 `MapperProxy` 代理,接口中每个方法都会被定义为 `MapperMethod` 对象,借助 `PlainMethodInvoker` 执行(动态代理模式和策略模式),`MapperMethod` 中组合了 `SqlCommand` 和 `MethodSignature`,`SqlCommand` 对象很重要,它的 `SqlCommand#name` 字段记录的是 `MappedStatement` 对象的 ID 值(eg: org.apache.ibatis.domain.blog.mappers.AuthorMapper.selectAuthor),根据它来获取唯一的 `MappedStatement`(每个 `MappedStatement` 对象对应 XML 映射文件中一个 `<select>`, `<insert>`, `<update>`, 或 `<delete>` 标签定义),`SqlCommand#type` 字段用来标记 SQL 的类型。当方法被执行时,会先调用 `SqlSession` 中的查询方法 `DefaultSqlSession#selectOne`,接着由 **执行器** `Executor` 去承接,默认类型是 `CachingExecutor`,注意在这里它会调用 `MappedStatement#getBoundSql` 方法获取 `BoundSql` 对象,这个对象实际上最终都是在 `StaticSqlSource#getBoundSql` 方法中获取的,也就是说 **此时我们定义在 Mapper 文件中的 SQL 此时已经被解析、处理好了(动态标签等内容均已被处理)**,保存在了 `BoundSql` 对象中。此时,要执行的 SQL 已经准备好了,它会接着调用 **SQL 处理器** 的 `StatementHandler#prepare` 方法创建与数据库交互的 `Statement` 对象,其中记录了要执行的 SQL 信息 ,而封装 SQL 的执行参数则由 **参数处理器** `DefaultParameterHandler` 和 `TypeHandler` 完成,`ResultSet` 结果的处理:将数据库中数据转换成所需要的 Java 对象由 **结果处理器** `DefaultResultSetHandler` 完成。 现在我们对拦截器的原理和查询 SQL 的执行流程已经有了基本的了解,回过头来再想一下我们的需求:“使用 Mybatis 的拦截器在 SQL 执行前进行打标”,那么我们该选择哪个方法作为切入点更合适呢? 理论上来说在 `Executor`, `StatementHandler` 和 `ParameterHandler` 相关的方法中切入都可以,但实际上我们还要多考虑一步:`ParameterHandler` 是用来处理参数相关的,在这里切入一般我们是要对入参 SQL 的入参进行处理,所以不选择这里避免为后续同学维护时增加理解成本;`Executor` “有时不是很合适”,它其中有两个 `query` 方法,先被执行的方法,**对应图中 `CacheExecutor` 左侧的直线 `query` 方法**:`Executor#query(MappedStatement, Object, RowBounds, ResultHandler)`,在方法中它会去调用 `MappedStatement#getBoundSql` 方法获取 `BoundSql` 对象 **完成 SQL 的处理和解析**,处理和解析后的 `BoundSql` 对象是我们需要进行拦截处理的,随后 **在该方法内部** 调用另一个 `query` 方法:`Executor#query(MappedStatement, Object, RowBounds, ResultHandler, CacheKey, BoundSql)`,**对应图中 `CacheExecutor` 右侧的曲线 `query` 方法**,它会将 `BoundSql` 作为入参去执行查询逻辑,结合本次需求,选择后者切入是合适的,因为它有 `BoundSql` 入参,对这个入参进行打标即可,我们来看一下 `CachingExecutor` 的源码: ```java public class CachingExecutor implements Executor { private final Executor delegate; // 先调用 @Override public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException { BoundSql boundSql = ms.getBoundSql(parameterObject); CacheKey key = createCacheKey(ms, parameterObject, rowBounds, boundSql); // 在方法内部调用 return query(ms, parameterObject, rowBounds, resultHandler, key, boundSql); } @Override public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException { // 二级缓存相关逻辑 Cache cache = ms.getCache(); if (cache != null) { flushCacheIfRequired(ms); if (ms.isUseCache() && resultHandler == null) { ensureNoOutParams(ms, boundSql); @SuppressWarnings("unchecked") List<E> list = (List<E>) tcm.getObject(cache, key); if (list == null) { // 执行查询逻辑(被拦截) list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql); tcm.putObject(cache, key, list); } return list; } } // 执行查询逻辑(被拦截) return delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql); } } ``` 它使用了静态代理模式,其中封装的 `Executor` 实现类型为 `SimpleExecutor`,在注释中标记了“被拦截”处的方法会让拦截器生效。那么前文中为什么要说它“有时不是很合适”呢?我们来看一种情况,将 Mybatis 配置中的 `cacheEnable` 置为 false,那么在创建执行器时实际类型不是 `CachingExecutor` 而是 `SimpleExecutor`,如下源码所示: ```java public class Configuration { public Executor newExecutor(Transaction transaction, ExecutorType executorType) { executorType = executorType == null ? defaultExecutorType : executorType; // 创建具体的 Executor 实现类 Executor executor; if (ExecutorType.BATCH == executorType) { executor = new BatchExecutor(this, transaction); } else if (ExecutorType.REUSE == executorType) { executor = new ReuseExecutor(this, transaction); } else { executor = new SimpleExecutor(this, transaction); } // false 不走这段逻辑 if (cacheEnabled) { executor = new CachingExecutor(executor); } // 拦截器相关逻辑 return (Executor) interceptorChain.pluginAll(executor); } } ``` 当有 SELECT 查询语句被执行时,它会直接调用到 `BaseExecutor#query` 方法中,在方法内部调用另一个需要被拦截的 `query` 方法,如下所示: ```java public abstract class BaseExecutor implements Executor { public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException { BoundSql boundSql = ms.getBoundSql(parameter); // cache key 缓存操作 CacheKey key = createCacheKey(ms, parameter, rowBounds, boundSql); // 需要拦截的 return query(ms, parameter, rowBounds, resultHandler, key, boundSql); } @SuppressWarnings("unchecked") @Override public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException { // ... } } ``` **由于该方法是在方法内部被调用的,所以无法使拦截器生效**(动态代理),这也是说它“有时不是很合适”的原因所在。因为存在这种情况,我们现在也只能选择 `StatementHandler` 作为切入点了,那么是选择切入 `StatementHandler#prepare` 方法还是 `StatementHandler#query` 方法呢? ```java public class SimpleExecutor extends BaseExecutor { public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException { Statement stmt = null; try { Configuration configuration = ms.getConfiguration(); // 创建 StatementHandler StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql); // 准备 Statement,其中会调用 StatementHandler#prepare 方法 stmt = prepareStatement(handler, ms.getStatementLog()); // 由 StatementHandler 执行 query 方法 return handler.query(stmt, resultHandler); } finally { closeStatement(stmt); } } } ``` 根据源码,要被执行打标的 `BoundSql` 对象会在调用 `StatementHandler#prepare` 方法前会将 `BoundSql` 对象封装在 `StatementHandler` 中,如果选择切入 `StatementHandler#prepare` 方法,那么在该方法执行前在 `StatementHandler` 中拿到 `BoundSql` 对象进行修改便能实现我们的需求;如果选择切入 `StatementHandler#query` 方法,同样是需要在该方法执行前想办法获取到 `BoundSql` 对象,但是由于此时 SQL 信息已经被保存在了即将与数据库交互的 `Statement` 对象中,它的实现类有很多,比如常见的 `PreparedStatement`,在其中获取 SQL 字符串相对复杂,所有还是选择 `StatementHandler#prepare` 方法作为切点相对容易。 #### 拦截器的定义和源码解析 接下来我们来对拦截器进行实现,首先我们先对拦截器的切入点进行定义: ```java @Intercepts({ @Signature(method = "prepare", type = StatementHandler.class, args = {Connection.class, Integer.class}) }) public class SQLMarkingInterceptor implements Interceptor { @Override public Object intercept(Invocation invocation) throws Throwable { // ... } } ``` 接着来实现其中的逻辑: ```java @Intercepts({ @Signature(method = "prepare", type = StatementHandler.class, args = {Connection.class, Integer.class}) }) public class SQLMarkingInterceptor implements Interceptor { private static final Log log = LogFactory.getLog(SQLMarkingInterceptor.class); @Override public Object intercept(Invocation invocation) throws Throwable { try { // 1. 找到 StatementHandler(SQL 执行时,StatementHandler 的实际类型为 RoutingStatementHandler) RoutingStatementHandler routingStatementHandler = getRoutingStatementHandler(invocation.getTarget()); if (routingStatementHandler != null) { // 其中 delegate 是实际类型的 StatementHandler (静态代理模式),获取到实际的 StatementHandler StatementHandler delegate = getFieldValue( RoutingStatementHandler.class, routingStatementHandler, "delegate", StatementHandler.class ); // 2. 找到 StatementHandler 之后便能拿到 SQL 相关信息,现在对 SQL 信息打标即可 marking(delegate); } } catch (Exception e) { log.error(e.getMessage(), e); } return invocation.proceed(); } } ``` 将自定义的逻辑添加上了 `try-catch`,避免异常影响正常业务的执行。在主要逻辑中,需要先在 `Invocation` 中找到 `StatementHandler` 的实际被代理的对象,它被封装在了 `RoutingStatementHandler` 中,随后在 `StatementHandler` 中获取到 `BoundSql` 对象,对 SQL 进行打标即可(`marking` 方法)。 ##### 获取 StatementHandler 拦截 `StatementHandler` 为什么要获取的是 `RoutingStatementHandler` 类型呢?我们回到拦截器拦截 `StatementHandler` 生效的源码: ```java public class Configuration { // ... protected final InterceptorChain interceptorChain = new InterceptorChain(); public StatementHandler newStatementHandler(Executor executor, MappedStatement mappedStatement, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) { // 可以发现拦截器实际针对的是类型便是 RoutingStatementHandler StatementHandler statementHandler = new RoutingStatementHandler(executor, mappedStatement, parameterObject, rowBounds, resultHandler, boundSql); // 拦截器相关逻辑 return (StatementHandler) interceptorChain.pluginAll(statementHandler); } } ``` 我们可以发现拦截器在生效时,针对的是 `RoutingStatementHandler` 类型,所以我们要获取该类型,如下源码: ```java public class SQLMarkingInterceptor implements Interceptor { private RoutingStatementHandler getRoutingStatementHandler(Object target) throws NoSuchFieldException, IllegalAccessException { // 如果被代理,那么一直找到具体被代理的对象 while (Proxy.isProxyClass(target.getClass())) { target = Proxy.getInvocationHandler(target); } while (target instanceof Plugin) { Plugin plugin = (Plugin) target; target = getFieldValue(Plugin.class, plugin, "target", Object.class); } // 找到了 RoutingStatementHandler if (target instanceof RoutingStatementHandler) { return (RoutingStatementHandler) target; } return null; } } ``` 源码中前两步为处理代理关系的逻辑,因为 `RoutingStatementHandler` 可能被代理,需要获取到实际的被代理对象,找到之后返回即可。那么后续为什么还要获取到 `RoutingStatementHandler` 中的被代理对象呢?我们还需要再回到 Mybatis 的源码中: ```java public class RoutingStatementHandler implements StatementHandler { // 代理对象 private final StatementHandler delegate; public RoutingStatementHandler(Executor executor, MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) { // 在调用构造方法时,根据 statementType 字段为代理对象 delegate 赋值,那么这样便实现了复杂度隐藏,只由代理对象去帮忙路由具体的实现即可 switch (ms.getStatementType()) { case STATEMENT: delegate = new SimpleStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql); break; case PREPARED: delegate = new PreparedStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql); break; case CALLABLE: delegate = new CallableStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql); break; default: throw new ExecutorException("Unknown statement type: " + ms.getStatementType()); } } } ``` `RoutingStatementHandler` 使用了静态代理模式,实际的类型被赋值到了 `delegate` 字段中,我们需要在这个对象中获取到 `BoundSql` 对象,获取 `delegate` 对象则通过反射来完成。 ##### 染色打标 marking 现在我们已经获取到了 `StatementHandler delegate` 对象,我们可以 SQL 进行打标了,但在打标之前我们需要先思考下要打标的内容是什么: 1. 要清楚的知道被执行的 SQL 是定义在 Mapper 中的哪条:声明在 Mapper 中各个方法的唯一ID,也就是 StatementId 2. 要清楚的知道这条 SQL 被执行时,有哪些相关方法被执行了:方法的调用栈 根据我们所需去找相关的内容就好了,以下是源码,需要注意的是由于所有类型的 SQL 都会执行到 `prepare` 方法,但我们只对 SELECT 语句进行打标,所以需要添加逻辑判断: ```java public class SQLMarkingInterceptor implements Interceptor { private void marking(StatementHandler delegate) throws NoSuchFieldException, IllegalAccessException { BoundSql boundSql = delegate.getBoundSql(); // 实际的 SQL String sql = boundSql.getSql().trim(); // 只对 select 打标 if (StringUtils.containsIgnoreCase(sql, "select")) { // 获取其基类中的 MappedStatement 即定义的 SQL 声明对象,获取它的 ID 值表示它是哪条 SQL MappedStatement mappedStatement = getFieldValue( BaseStatementHandler.class, delegate, "mappedStatement", MappedStatement.class ); String mappedStatementId = mappedStatement.getId(); // 方法调用栈 String trace = trace(); // 按顺序创建打标的内容 LinkedHashMap<String, Object> markingMap = new LinkedHashMap<>(); markingMap.put("STATEMENT_ID", mappedStatementId); markingMap.put("STACK_TRACE", trace); String marking = "[SQLMarking] ".concat(markingMap.toString()); // 打标 sql = String.format(" /* %s */ %s", marking, sql); // 反射更新 Field field = getField(BoundSql.class, "sql"); field.set(boundSql, sql); } } } ``` 执行打标的逻辑是修改 `BoundSql` 对象,将其中的 `sql` 字段用打标后的 SQL 替换掉。获取方法调用栈的逻辑我们具体来看一下,其实并不复杂,在全量堆栈信息中将不需要关注的堆栈排除掉,需要注意将 `!className.startsWith("com.your.package")` 修改成有效的路径判断: ```java public class SQLMarkingInterceptor implements Interceptor { private String trace() { // 全量调用栈 StackTraceElement[] stackTraceArray = Thread.currentThread().getStackTrace(); if (stackTraceArray.length <= 2) { return EMPTY; } LinkedList<String> methodInfoList = new LinkedList<>(); for (int i = stackTraceArray.length - 1 - DEFAULT_INDEX; i >= DEFAULT_INDEX; i--) { StackTraceElement stackTraceElement = stackTraceArray[i]; // 排除掉不想看到的内容 String className = stackTraceElement.getClassName(); if (!className.startsWith("com.your.package") || className.contains("FastClassBySpringCGLIB") || className.contains("EnhancerBySpringCGLIB") || stackTraceElement.getMethodName().contains("lambda$") ) { continue; } // 过滤拦截器相关 if (className.contains("Interceptor") || className.contains("Aspect")) { continue; } // 只拼接类和方法,不拼接文件名和行号 String methodInfo = String.format("%s#%s", className.substring(className.lastIndexOf('.') + 1), stackTraceElement.getMethodName() ); methodInfoList.add(methodInfo); } if (methodInfoList.isEmpty()) { return EMPTY; } // 格式化结果 StringJoiner stringJoiner = new StringJoiner(" ==> "); for (String method : methodInfoList) { stringJoiner.add(method); } return stringJoiner.toString(); } } ``` 以上便完成了 SQL “染色” 拦截器的实现,将其添加到 mybatis 相关的拦截器配置中就可以生效了。 #### 全量源码 ```java import com.jd.laf.config.spring.annotation.LafValue; import lombok.extern.slf4j.Slf4j; import org.apache.commons.lang3.StringUtils; import org.apache.ibatis.executor.statement.BaseStatementHandler; import org.apache.ibatis.executor.statement.RoutingStatementHandler; import org.apache.ibatis.executor.statement.StatementHandler; import org.apache.ibatis.mapping.BoundSql; import org.apache.ibatis.mapping.MappedStatement; import org.apache.ibatis.plugin.*; import org.springframework.stereotype.Service; import java.lang.reflect.Field; import java.lang.reflect.Proxy; import java.sql.Connection; import java.util.*; import java.util.concurrent.ConcurrentHashMap; import static org.apache.commons.lang3.StringUtils.EMPTY; @Slf4j @Service @Intercepts({ @Signature(method = "prepare", type = StatementHandler.class, args = {Connection.class, Integer.class}) }) public class SQLMarkingInterceptor implements Interceptor { /** * 默认线程栈数组下标 */ private static final int DEFAULT_INDEX = 2; /** * 是否开启SQL染色标记 */ @LafValue("sql.marking.enable") private boolean enabled; private static final Map<String, Field> FIELD_CACHE = new ConcurrentHashMap<>(); @Override public Object intercept(Invocation invocation) throws Throwable { if (!enabled) { return invocation.proceed(); } try { // 1. 找到 StatementHandler(SQL 执行时,StatementHandler 的实际类型为 RoutingStatementHandler) RoutingStatementHandler routingStatementHandler = getRoutingStatementHandler(invocation.getTarget()); if (routingStatementHandler != null) { // 其中 delegate 是实际类型的 StatementHandler (静态代理模式),获取到实际的 StatementHandler StatementHandler delegate = getFieldValue( RoutingStatementHandler.class, routingStatementHandler, "delegate", StatementHandler.class ); // 2. 找到 StatementHandler 之后便能拿到 SQL 相关信息,现在对 SQL 信息打标即可 marking(delegate); } } catch (Exception e) { log.error(e.getMessage(), e); } return invocation.proceed(); } private RoutingStatementHandler getRoutingStatementHandler(Object target) throws NoSuchFieldException, IllegalAccessException { // 如果被代理,那么一直找到具体被代理的对象 while (Proxy.isProxyClass(target.getClass())) { target = Proxy.getInvocationHandler(target); } while (target instanceof Plugin) { Plugin plugin = (Plugin) target; target = getFieldValue(Plugin.class, plugin, "target", Object.class); } // 找到了 RoutingStatementHandler if (target instanceof RoutingStatementHandler) { return (RoutingStatementHandler) target; } return null; } /** * 打标 * 1. 要清楚的知道被执行的 SQL 是定义在 Mapper 中的哪条 * 2. 要清楚的知道这条 SQL 被执行时方法的调用栈 */ private void marking(StatementHandler delegate) throws NoSuchFieldException, IllegalAccessException { BoundSql boundSql = delegate.getBoundSql(); // 实际的 SQL String sql = boundSql.getSql().trim(); // 只对 select 打标 if (StringUtils.containsIgnoreCase(sql, "select")) { // 获取其基类中的 MappedStatement 即定义的 SQL 声明对象,获取它的 ID 值表示它是哪条 SQL MappedStatement mappedStatement = getFieldValue( BaseStatementHandler.class, delegate, "mappedStatement", MappedStatement.class ); String mappedStatementId = mappedStatement.getId(); // 方法调用栈 String trace = trace(); // 按顺序创建打标的内容 LinkedHashMap<String, Object> markingMap = new LinkedHashMap<>(); markingMap.put("STATEMENT_ID", mappedStatementId); markingMap.put("STACK_TRACE", trace); String marking = "[SQLMarking] ".concat(markingMap.toString()); // 打标 sql = String.format(" /* %s */ %s", marking, sql); // 反射更新 Field field = getField(BoundSql.class, "sql"); field.set(boundSql, sql); } } /** * 获取某类型 clazz 某对象 object 下某字段 fieldName 的值 fieldClass */ private <T> T getFieldValue(Class<?> clazz, Object object, String fieldName, Class<T> fieldClass) throws NoSuchFieldException, IllegalAccessException { // 获取到目标类的字段 Field field = getField(clazz, fieldName); return fieldClass.cast(field.get(object)); } private String trace() { StackTraceElement[] stackTraceArray = Thread.currentThread().getStackTrace(); if (stackTraceArray.length <= DEFAULT_INDEX) { return EMPTY; } LinkedList<String> methodInfoList = new LinkedList<>(); for (int i = stackTraceArray.length - 1 - DEFAULT_INDEX; i >= DEFAULT_INDEX; i--) { StackTraceElement stackTraceElement = stackTraceArray[i]; String className = stackTraceElement.getClassName(); if (!className.startsWith("com.your.package") || className.contains("FastClassBySpringCGLIB") || className.contains("EnhancerBySpringCGLIB") || stackTraceElement.getMethodName().contains("lambda$") ) { continue; } // 过滤拦截器相关 if (className.contains("Interceptor") || className.contains("Aspect")) { continue; } // 只拼接类和方法,不拼接文件名和行号 String methodInfo = String.format("%s#%s", className.substring(className.lastIndexOf('.') + 1), stackTraceElement.getMethodName() ); methodInfoList.add(methodInfo); } if (methodInfoList.isEmpty()) { return EMPTY; } // 格式化结果 StringJoiner stringJoiner = new StringJoiner(" ==> "); for (String method : methodInfoList) { stringJoiner.add(method); } return stringJoiner.toString(); } private Field getField(Class<?> clazz, String fieldName) throws NoSuchFieldException { Field field; String cacheKey = String.format("%s.%s", clazz.getName(), fieldName); if (FIELD_CACHE.containsKey(cacheKey)) { field = FIELD_CACHE.get(cacheKey); } else { field = clazz.getDeclaredField(fieldName); field.setAccessible(true); FIELD_CACHE.put(cacheKey, field); } return field; } } ``` ### 基于 AspectJ 织入实现 这种方法主要用于在未使用 Mybatis 框架的系统中,**基于 AspectJ 实现对 Maven 依赖中 Jar 包类的织入**,完成 SQL 染色打标的操作。同时,这种方法并不限于此,大家可以借鉴这种方法用于其他 Jar 包的织入,而不局限于 Spring 提供的 AOP 机制,毕竟 Spring 的 AOP 只能对 Bean 进行织入。所以在本小节中,更注重方法的介绍。 #### 添加依赖和配置插件 借助 AspectJ 在 **编译期** 实现对 Maven 依赖中 Jar 包类的织入,这与运行时织入(如 Spring AOP 使用的代理机制)不同,编译期织入是在生成的字节码中直接包含切面逻辑,生成的类文件已经包含了切面代码。 首先,需要先添加依赖: ```xml <dependency> <groupId>org.aspectj</groupId> <artifactId>aspectjrt</artifactId> <version>1.8.13</version> </dependency> ``` 并且在 Maven 的 `plugins` 标签下添加 `aspectj-maven-plugin` 插件配置,否则无法实现在编译期织入: ```xml <plugin> <groupId>org.codehaus.mojo</groupId> <artifactId>aspectj-maven-plugin</artifactId> <version>1.11</version> <configuration> <!-- 解决与 Lombok 的冲突 --> <forceAjcCompile>true</forceAjcCompile> <sources/> <weaveDirectories> <weaveDirectory>${project.build.directory}/classes</weaveDirectory> </weaveDirectories> <!-- JDK版本 --> <complianceLevel>1.8</complianceLevel> <source>1.8</source> <target>1.8</target> <!-- 展示织入信息 --> <showWeaveInfo>true</showWeaveInfo> <encoding>UTF-8</encoding> <!-- 重点!配置要织入的 maven 依赖 --> <weaveDependencies> <weaveDependency> <groupId>org.apache.ibatis</groupId> <artifactId>ibatis-sqlmap</artifactId> </weaveDependency> </weaveDependencies> </configuration> <executions> <execution> <goals> <goal>compile</goal> </goals> </execution> </executions> </plugin> ``` 解决与 Lombok 的冲突配置内容不再解释,详细请看 [CSDN: AspectJ和lombok](https://blog.csdn.net/zq1994520/article/details/108095574)。重点需要关注的配置内容是 `weaveDependency` 标签:配置织入依赖(详细可参见 [Maven: aspectj-maven-plugin 官方文档](https://www.mojohaus.org/aspectj-maven-plugin/examples/weaveJars.html)),也就是说如果我们想对 `SqlExecutor` 进行织入,那么需要将它对应的 Maven 依赖添加到这个标签下才能生效,否则无法完成织入。 完成以上内容之后,现在去实现对应的拦截器即可。 #### 拦截器实现 拦截器的实现原理非常简单,要织入的方法是 `com.ibatis.sqlmap.engine.execution.SqlExecutor#executeQuery`,这个方法的签名如下: ```java public void executeQuery(StatementScope statementScope, Connection conn, String sql, Object[] parameters, int skipResults, int maxResults, RowHandlerCallback callback) throws SQLException; ``` 根据我们的诉求:在 SQL 执行前对 SQL 进行染色打标,那么可以直接在这个方法的第三个参数 `String sql` 上打标,以下是拦截器的实现: ```java @Slf4j @Aspect public class SqlExecutorInterceptor { private static final int DEFAULT_INDEX = 2; @Around("execution(* com.ibatis.sqlmap.engine.execution.SqlExecutor.executeQuery(..))") public Object aroundExecuteQuery(ProceedingJoinPoint joinPoint) throws Throwable { // 获取方法参数 Object[] args = joinPoint.getArgs(); String sqlTemplate = ""; Object arg2 = args[2]; if (arg2 instanceof String) { // 实际的 SQL sqlTemplate = (String) arg2; } if (StringUtils.containsIgnoreCase(sqlTemplate, "select")) { try { // SQL 声明的 ID String mappedStatementId = ""; Object arg0 = args[0]; if (arg0 instanceof StatementScope) { StatementScope statementScope = (StatementScope) arg0; MappedStatement statement = statementScope.getStatement(); if (statement != null) { mappedStatementId = statement.getId(); } } // 方法调用栈 String trace = trace(); // 按顺序创建打标的内容 LinkedHashMap<String, Object> markingMap = new LinkedHashMap<>(); markingMap.put("STATEMENT_ID", mappedStatementId); markingMap.put("STACK_TRACE", trace); String marking = "[SQLMarking] ".concat(markingMap.toString()); // 先打标后SQL,避免有些平台展示SQL时进行尾部截断,而看不到染色信息 String markingSql = String.format(" /* %s */ %s", marking, sqlTemplate); args[2] = markingSql; } catch (Exception e) { // 发生异常的话恢复最原始 SQL 保证执行 args[2] = sqlTemplate; log.error(e.getMessage(), e); } } // 正常执行逻辑 return joinPoint.proceed(args); } } ``` 逻辑上非常简单,获取了 `MappedStatementId` 和线程的执行堆栈以注释的形式标记在 SELECT 语句前,注意如果大家要 **对 INSERT 语句进行打标时,需要将标记打在 SQL 的最后**,因为部分插件如 `InsertStatementParser` 会识别 INSERT,如果注释在前,INSERT 识别会有误报错。 #### 验证织入 完成以上工作后,我们需要验证拦截器是否织入成功,因为织入是在编译期完成的,所以执行以下 Maven 编译命令即可: ```shell mvn clean compile ``` 在控制台中可以发现如下日志信息提示织入成功: ```xml [INFO] --- aspectj-maven-plugin:1.11:compile (default) @ --- [INFO] Showing AJC message detail for messages of types: [error, warning, fail] [INFO] Join point 'method-execution(void com.ibatis.sqlmap.engine.execution.SqlExecutor.executeQuery(com.ibatis.sqlmap.engine.scope.StatementScope, java.sql.Connection, java.lang.String, java.lang.Object[], int, int, com.ibatis.sqlmap.engine.mapping.statement.RowHandlerCallback))' in Type 'com.ibatis.sqlmap.engine.execution.SqlExecutor' (SqlExecutor.java:163) advised by around advice from 'com.your.package.sqlmarking.SqlExecutorInterceptor' (SqlExecutorInterceptor.class(from SqlExecutorInterceptor.java)) ``` 并且在相应的 `target/classes` 目录下的 `SqlExecutor.class` 文件中也能发现被织入的逻辑: ```java public class SqlExecutor { public void executeQuery(StatementScope statementScope, Connection conn, String sql, Object[] parameters, int skipResults, int maxResults, RowHandlerCallback callback) throws SQLException { JoinPoint.StaticPart var10000 = ajc$tjp_0; Object[] var24 = new Object[]{statementScope, conn, sql, parameters, Conversions.intObject(skipResults), Conversions.intObject(maxResults), callback}; JoinPoint var23 = Factory.makeJP(var10000, this, this, var24); SqlExecutorInterceptor var26 = SqlExecutorInterceptor.aspectOf(); Object[] var25 = new Object[]{this, statementScope, conn, sql, parameters, Conversions.intObject(skipResults), Conversions.intObject(maxResults), callback, var23}; var26.aroundExecuteQuery((new SqlExecutor$AjcClosure1(var25)).linkClosureAndJoinPoint(69648)); } } ``` 以上,大功告成。 --- ### 巨人的肩膀 - [神灯专栏:《由 Mybatis 源码畅谈软件设计》](http://sd.jd.com/column/419?shareId=53471&isHideShareButton=1) - [神灯:如何一眼定位SQL的代码来源:一款SQL染色标记的简易MyBatis插件](http://sd.jd.com/article/42942?shareId=53471&isHideShareButton=1) - [腾讯云-开发者社区:从一个Aspectj织入失效问题的解决说起](https://cloud.tencent.com/developer/article/2111135) - [CSDN: aspectj-maven-plugin 插件使用](https://blog.csdn.net/mamamalululu00000000/article/details/111264804) - [Maven: aspectj-maven-plugin 官方文档](https://www.mojohaus.org/aspectj-maven-plugin/examples/weaveJars.html) - [CSDN: AspectJ和lombok](https://blog.csdn.net/zq1994520/article/details/108095574)
上一篇:AIGC视频生成—音频驱动嘴型编辑技术
下一篇:JDK从8升级到21的问题集
wy****
文章数
47
阅读量
38514
作者其他文章
01
用“分区”来面对超大数据集和超大吞吐量
1. 为什么要分区?分区(partitions) 也被称为 分片(sharding),通常采用对数据进行分区的方式来增加系统的 可伸缩性,以此来面对非常大的数据集或非常高的吞吐量,避免出现热点。分区通常和复制结合使用,使得每个分区的副本存储在多个节点上,保证数据副本的 高可用。如下图所示,如果数据库被分区,每个分区都有一个主库。不同分区的主库可能在不同的节点上,每个节点可能是某些分区的主库,同时是
01
深入理解分布式共识算法 Raft
“不可靠的网络”、“不稳定的时钟”和“节点的故障”都是在分布式系统中常见的问题,在文章开始前,我们先来看一下:如果在分布式系统中网络不可靠会发生什么样的问题。有以下 3 个服务构成的分布式集群,并在 server_1 中发生写请求变更 A = 1,“正常情况下” server_1 将 A 值同步给 server_2 和 server_3,保证集群的数据一致性:但是如果在数据变更时发生网络问题(延迟
01
缓存之美:从根上理解 ConcurrentHashMap
本文将详细介绍 ConcurrentHashMap 构造方法、添加值方法和扩容操作等源码实现。ConcurrentHashMap 是线程安全的哈希表,此哈希表的设计主要目的是在最小化更新操作对哈希表的占用,以保持并发可读性,次要目的是保持空间消耗与 HashMap 相同或更好,并支持利用多线程在空表上高效地插入初始值。在 Java 8 及之后的版本,使用 CAS 操作、 synchronized
01
缓存之美:万文详解 Caffeine 实现原理(上)
由于神灯社区最大字数限制,本文章将分为两篇,第二篇文章为缓存之美:万文详解 Caffeine 实现原理(下)文章将采用“总-分-总”的结构对配置固定大小元素驱逐策略的 Caffeine 缓存进行介绍,首先会讲解它的实现原理,在大家对它有一个概念之后再深入具体源码的细节之中,理解它的设计理念,从中能学习到用于统计元素访问频率的 Count-Min Sketch 数据结构、理解内存屏障和如何避免缓存伪
wy****
文章数
47
阅读量
38514
作者其他文章
01
用“分区”来面对超大数据集和超大吞吐量
01
深入理解分布式共识算法 Raft
01
缓存之美:从根上理解 ConcurrentHashMap
01
缓存之美:万文详解 Caffeine 实现原理(上)
添加企业微信
获取1V1专业服务
扫码关注
京东云开发者公众号




 wy****
wy**** 2025-06-09
2025-06-09 646浏览
646浏览






