



1. 引言
时间序列预测(Time Series Forecasting)是供应链管理、能源调度、金融风控等领域的核心基础技术。随着数据规模和业务复杂度的提升,传统方法(如ARIMA、Prophet)及早期深度学习模型(LSTM、TCN)面临以下挑战:
- 复杂模式捕捉不足:传统模型依赖线性假设或局部时序建模,难以捕捉长周期依赖、多变量耦合等复杂时空关联。
- 零样本泛化能力弱:多数监督模型需针对单一场景重新训练,无法适应跨领域(如不同品类商品销量预测)的迁移需求。
近年来,大语言模型(LLM)的时序预测适配(如GPT4TS、TimesFM)逐渐成为热点,但尚未出现类似文本类大模型领域的突破性结果,主要原因包括:
- 数据集质量偏低:现有的时序公开数据集普遍存在数据量有限、规律性较强、可扩展性不足等问题,小模型即可有效压缩其规律,导致规模定律难以充分展现,模型在复杂场景上表现一般。
- 缺少有效的RLHF方案:RLHF技术在LLM的发展中起到了重要作用,相比SFT,它可以用更少的数据达到更好的效果,但是常用的RLHF框架并不适用于时序大模型。
2. 技术方案
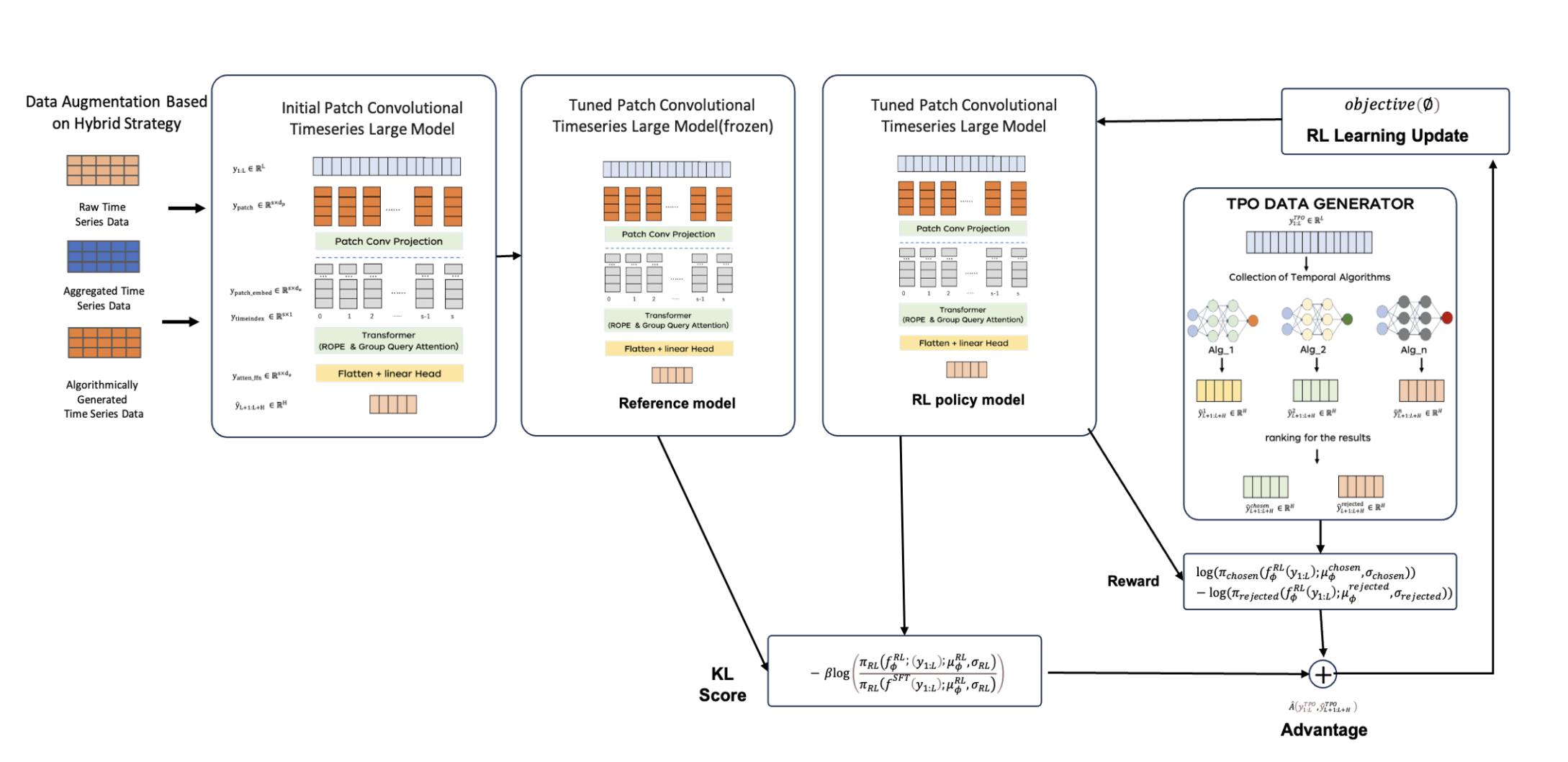
针对以上问题,供应链算法团队从0-1进行了时序大模型的训练探索,完成了业内首个十亿级纯时序大模型的训练,并在多个公开数据集上取得了SOTA。
在数据方面,我们引入了一个包含15亿样本的大规模高质量复杂数据集,并提出了时序切分、数据配比、合成数据集构造等时序训练集构建范式。
在模型方面,我们提出了一个通用的PCTLM模型,该模型通过Patch的方式对数据进行切割,并在Patch投影的过程中进行了改进,以捕捉跨Patch间的信息,并通过引入时间位置编码的分组注意力机制来训练大模型。
在垂类优化方面,我们首次提出了时间序列预测模型的RLHF方案。由于常用的RLHF框架并不适用于时序大模型,我们开发了一套适用于纯时序大模型的强化学习框架TPO。
2.1 数据集构建
常见的优秀基座大模型是以庞大丰富的预训练数据为支撑的,但是当前时序领域的公开数据集无法达到相同的量级水平。为了解决这一问题,我们通过混合京东自营销量时序数据、公开数据集和合成数据的配比数据,并通过质量过滤、去重、多样性排序和数据配比等方式整合基础数据,最终使用的预训练数据观测点量级大约为15亿样本,这也是目前时序领域最大的数据集。
基础数据
- 京东数据集:大部分的数据来自于京东的销量数据,我们收集京东食品、服装等多品类近3年来的基础销售数据,并且在不同的维度上进行时序的聚合,多品类和多维度的数据扩充了数据的丰富度和异构程度。数据大致包含12亿样本。
- 公开数据集:公开数据集部分,我们使用Monash时间序列数据库和TSLib数据库的训练数据合集,通过随机时间点切分来扩充训练样本。数据大致包含2000万样本。
- 合成数据集:合成数据部分,一方面我们使用京东数据集和公开数据集的单时序进行简单模型预测来作为合成数据,另一方面我们通过自定义趋势项、季节项和噪声项来生成合成数据。数据大致包含4亿样本。
数据清理
- 数据打标:我们对非公开数据集里的每一个样本进行时序标签的打标,例如时序长度、销量日均、0销量占比等表时序特征的统计量,从多个指标和角度来评估样本特点。
- 质量过滤:通过时序标签评估数据集里每一条时序的质量水平,并将时序长度过短、销量过于离散的数据剔除,最终提高数据集的质量水平。
- 去重:我们将数据随机分组,对组内时序进行聚类,随机保留类内样本的前N个。
- 多样性排序:根据时序标签,我们对整体数据进行重新排序,确保每个Batch内的数据尽可能包含不同时序特征的数据。
- 数据配比:我们设定不同的数据配比,例如在数据类型上,我们设置合成数据占比为20%,公开数据集占比为4%,京东数据占比为76%;在数据维度上,我们设置聚合时序数据的占比为30%,普通维度的数据为70%;以及其他维度的一些配比实验。
2.2 模型设计-PCTLM模型
PCTLM(Patch Convolutional Timeseries Large Model)采用了一种基于(可重叠)Patch的方法,使用掩码编码器架构对时间序列进行建模。我们通过将输入划分为Patch,并将其投影到矢量表示中。为此,我们设计了一套基于卷积层的网络,通过通道和卷积核的方式捕捉跨Patch间的信息。此外,我们引入了具有时间位置编码的分组注意力机制,以实现时间序列的预测。
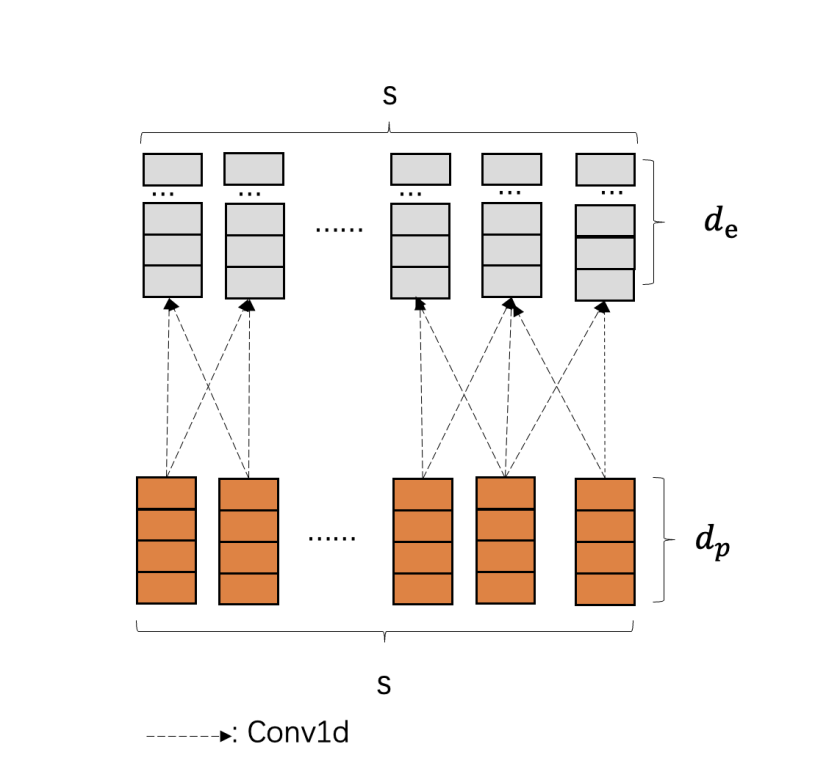
核心的 Transformer 模块是一个仅包含编码器的架构,结合了最近最先进的大型语言模型(LLM)架构中的各种改进。我们使用旋转位置编码(ROPE)对输入进行位置编码,并采用分组查询注意力(GQA)机制,以降低注意力计算的开销。
2.3 训练方案-RLHF
在文本大模型中,RL已经广泛用于大模型的微调中,从而使得文本大模型学习更多的偏好数据,增强文本模型的效果。
由于时序大模型的输入输出都是连续数值,这与文本处理有根本区别。此外,大多数纯时序模型通常采用均方误差(MSE)、分位数损失等方法,存在只能进行多步预测的情况(无法进行TD误差),并且无法输出预测值的概率(无法计算概率及KL散度等)。因此,常用的PPO、RLOO等强化学习框架无法直接应用于时序大模型的场景(时序概率预测模型除外)。在这种情况下,我们结合文本大模型的强化学习框架,提出了一套适用于纯时序大模型的强化学习框架——TPO(Timeseries Policy Optimization)。

输入:首先在输入上,输入上在RLHF数据集的原始时序输入上的基础上,增加好坏预测的pair对。我们的微调的偏好则是希望预测更加的贴近好预测。
预测概率化组件:由于大部分纯时序大模型输出的是确定性的预测,没有预测的概率,这样无法计算RL中KL散度,策略概率的损失,我们构建了一个公用的组件,适配所有的时序模型(不限于大模型),我们利用分布建模的方法,将时序的预测以及好坏的预测假设服从N(μ,1)的正态分布,对于均值的计算则直接利用输出的预测的均值则可以计算而成,这样可以快速输出预测的概率。
优势函数:由于我们的时序大模型是直接输出的多步预测,所以RL阶段我们避免采用TD-ERROR的方式,由此我们借鉴了REINFORCE类似的思想,优势函数的增益来源于与基线奖赏的差值,整体的在RL模型偏离原SFT模型不多的情况下,预测更加贴近好预测,而与基线奖赏的增益越大,则得到更大的优势。
时序损失:在原始RL的目标中,增加了一项预训练的损失,这一项主要是为了保持在标准 NLP 任务上的性能,让它不要“忘本”。而对于时序大模型来说,MSE是时序任务性能的最好评估指标之一,所以增加一部分MSE的损失,提升在微调时时序预测的能力,在MSE的构建时,我们不仅看预测与好预测的差距,同时也看与坏预测的方式,在实验中表明,这种方式可以显著改善模型微调过拟合。
3. 模型效果
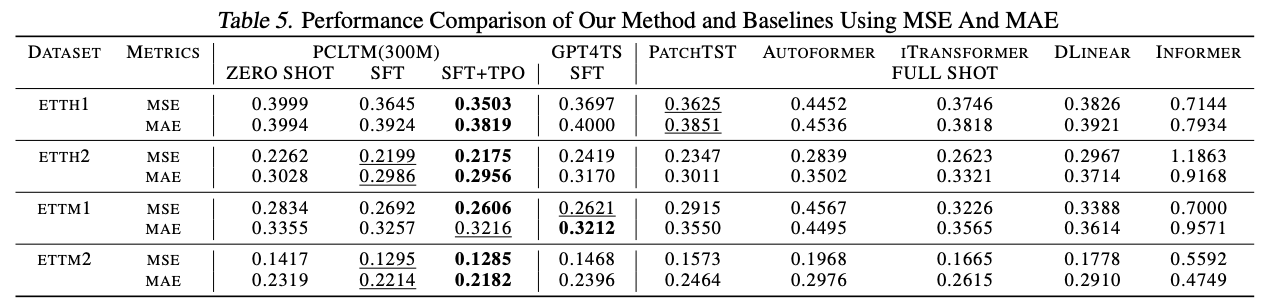
在公开数据集上,我们比较了当前表现较优的微调时序大模型的效果(GPT4TS),以及5种当前比较领先的full shot的时序深度学习方法(patchtst、autoformer、itransformer、DLinear、Informer)。经过SFT+TPO的PCTLM模型在大部分公开数据集上均可取得SOTA的效果。(粗体为效果最优模型,评估指标为MAE,越小越好)
4. 结论
本文提出了一个全新的时间序列大模型训练的流程(PCTLM+SFT+TPO),其中PCTLM是一个通用的基础时序大模型,其最大的尺寸也是迄今为止的首个十亿级纯时序大模型,其零样本性能优于目前行业内最先进微调大模型GPT4TS以及全监督预测模型在各种时间序列数据上的准确性。另外我们首次提出了时间序列预测模型的RLHF方案,我们开发了一套适用于纯时序大模型的强化学习框架TPO,在时间序列场景里,该框架在性能及效果上均优于目前最先进的RLHF框架(PPO、RLOO等)。并且由于我们提出的时序大模型的优异表现,我们已经将自研时序大模型在京东供应链系统部署上线,并且取得了卓越的表现,目前在2万个SKU采用时序大模型输出预测进行自动化补货,预测准确率相较于线上大幅提升。
更多的论文细节可参考:https://arxiv.org/abs/2501.15942






