



1. 线程运行状态
1.1 total
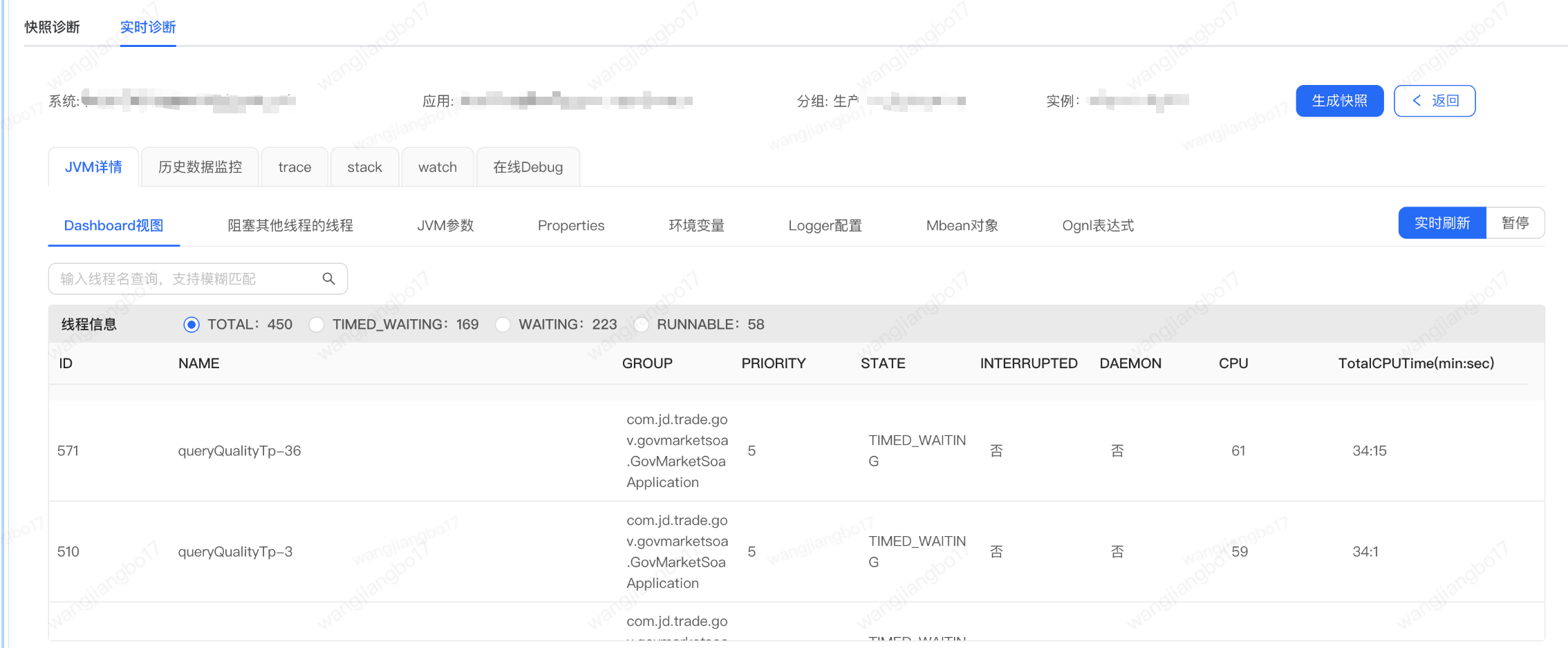
1.2 timed_waiting
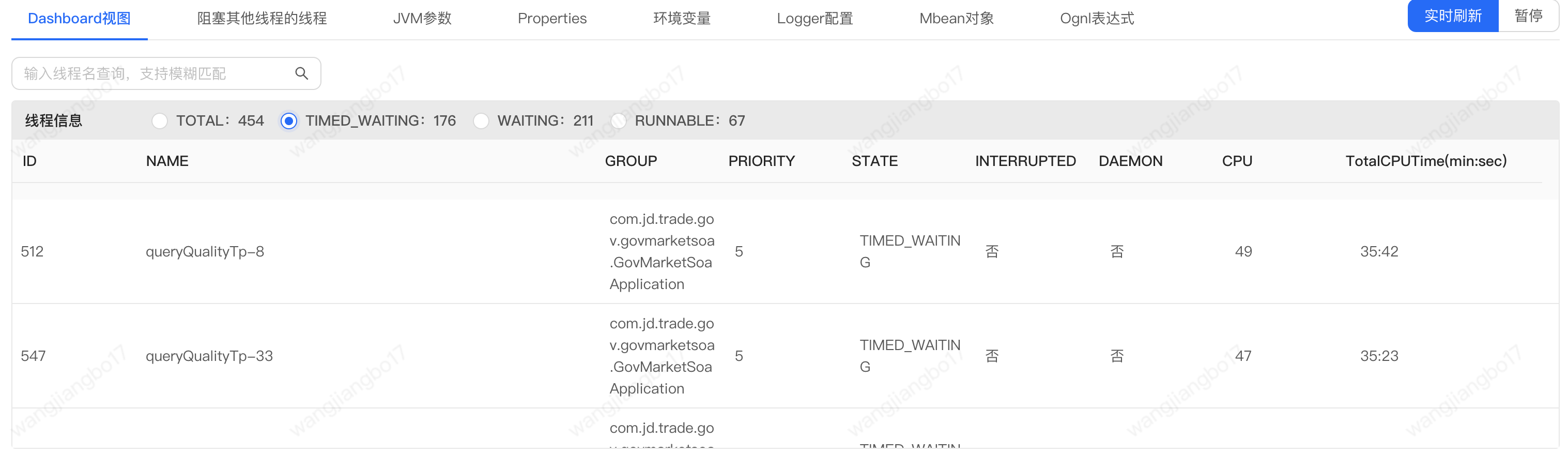
通过上图我们可以发现timed_waiting的topN线程都是查询国补资质的。
1.3 waiting
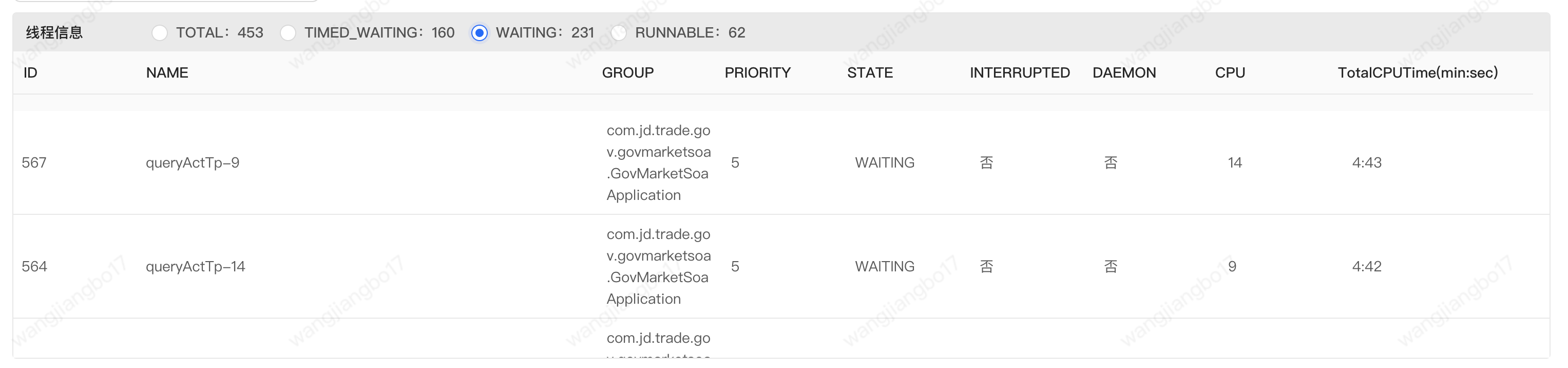

通过上图我们可以发现waiting的topN线程都是查询国补活动的。
1.4 线程分析
下面我们分析上述两种状态:
1. WAITING 状态
- 定义:当一个线程处于
WAITING状态时,它在等待另一个线程的特定操作(如通知或中断),并且不会继续执行。 - 触发条件:线程进入
WAITING状态的常见情况包括:
调用 Object.wait() 方法:线程在等待某个对象的监视器(锁)被其他线程通知。
调用 Thread.join() 方法:等待另一个线程完成。
调用 LockSupport.park() 方法:线程被阻塞,直到它被其他线程唤醒。
- 恢复:线程在
WAITING状态下将一直保持此状态,直到其他线程调用notify()或notifyAll()(对于Object.wait()),或者被中断。
2. TIMED_WAITING 状态
- 定义:当一个线程处于
TIMED_WAITING状态时,它在等待某个条件的发生,但它会在指定的时间后自动返回。 - 触发条件:线程进入
TIMED_WAITING状态的常见情况包括:
调用 Thread.sleep(milliseconds):线程休眠指定的毫秒数。
调用 Object.wait(milliseconds):线程在等待某个对象的监视器(锁),并且在指定的时间内等待。
调用 Thread.join(milliseconds):等待另一个线程完成,但有时间限制。
调用 LockSupport.parkNanos() 或 LockSupport.parkUntil()。
- 恢复:线程在
TIMED_WAITING状态下会在指定的时间结束后自动恢复,或者在其他线程调用notify()或notifyAll()时恢复。
| 状态 | 描述 | 触发条件 | 恢复方式 |
|----------------|------------------------------------------|---------------------------------------------|--------------------------------------------|
| **WAITING** | 线程等待另一个线程的特定操作,不会继续执行 | `Object.wait()`, `Thread.join()`, `LockSupport.park()` | 其他线程调用 `notify()`/`notifyAll()` 或被中断 |
| **TIMED_WAITING** | 线程等待某个条件的发生,但有时间限制 | `Thread.sleep(milliseconds)`, `Object.wait(milliseconds)`, `Thread.join(milliseconds)` | 超过指定时间后自动恢复,或其他线程调用 `notify()`/`notifyAll()` |下面我们结合实际代码情况分析:

上文中 queryActTp 为 getActivityInfo 执行并发任务,其中包含两个子任务、 queryQualityTp 为 getQualityInfo 执行并发任务,其中五个子任务。同时将这俩任务放到queryActAndQualityTp中并行。
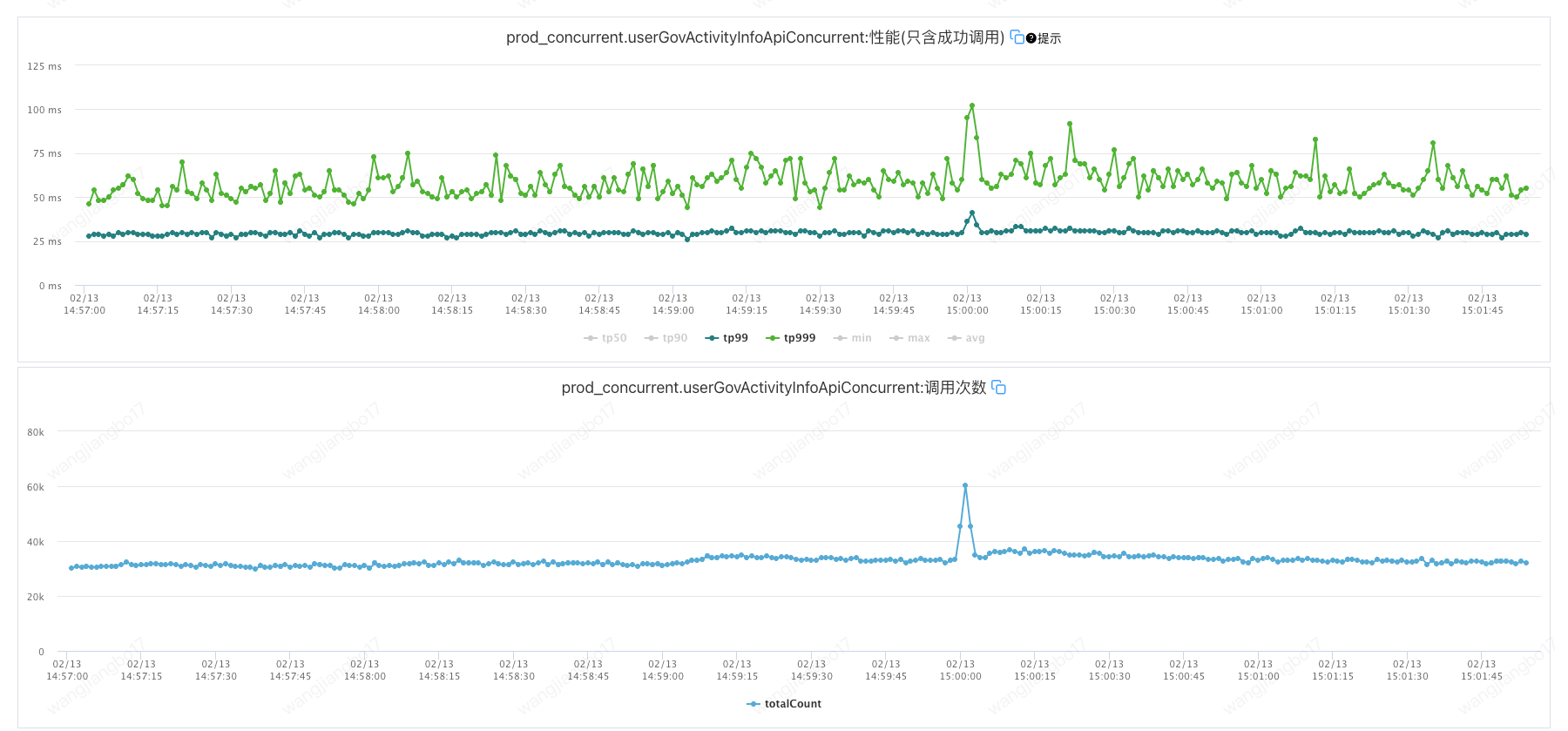
getActivityInfo所在的秒级监控如下:
getQualityInfo所在的秒级监控如下;
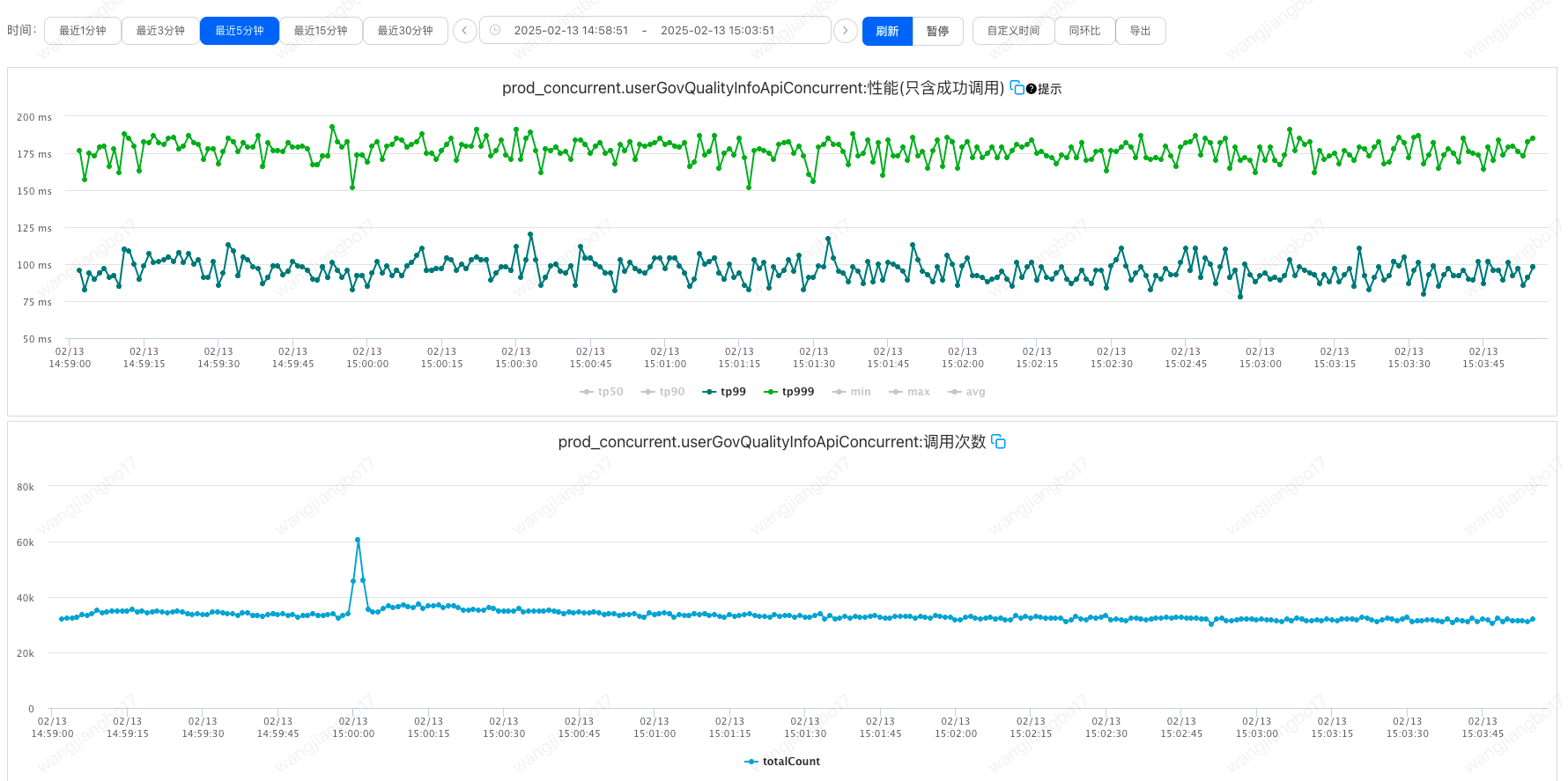
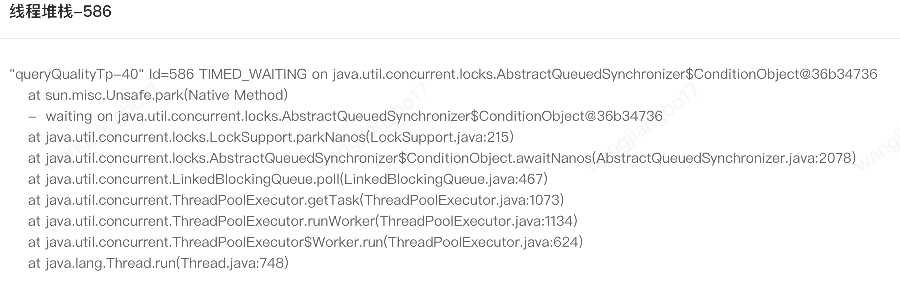
上文中同样的调用方式,但是出现了两种线程状态,理论上应该都是TIMED_WAITING。针对queryActTp我们可以发现堆栈信息中也是LockSupport.park而不是LockSupport.parkNanos。具体原因有待进一步分析。
上述代码中还有一个问题就是A线程池中又并行调用了B、C线程池,在大流量情况下,CPU频繁切换也会造成一定的CPU压力,我们改写这块逻辑用一个线程池实现活动和资质的并发查询。鉴于改动较大,本次先不动。
2. 火焰图分析

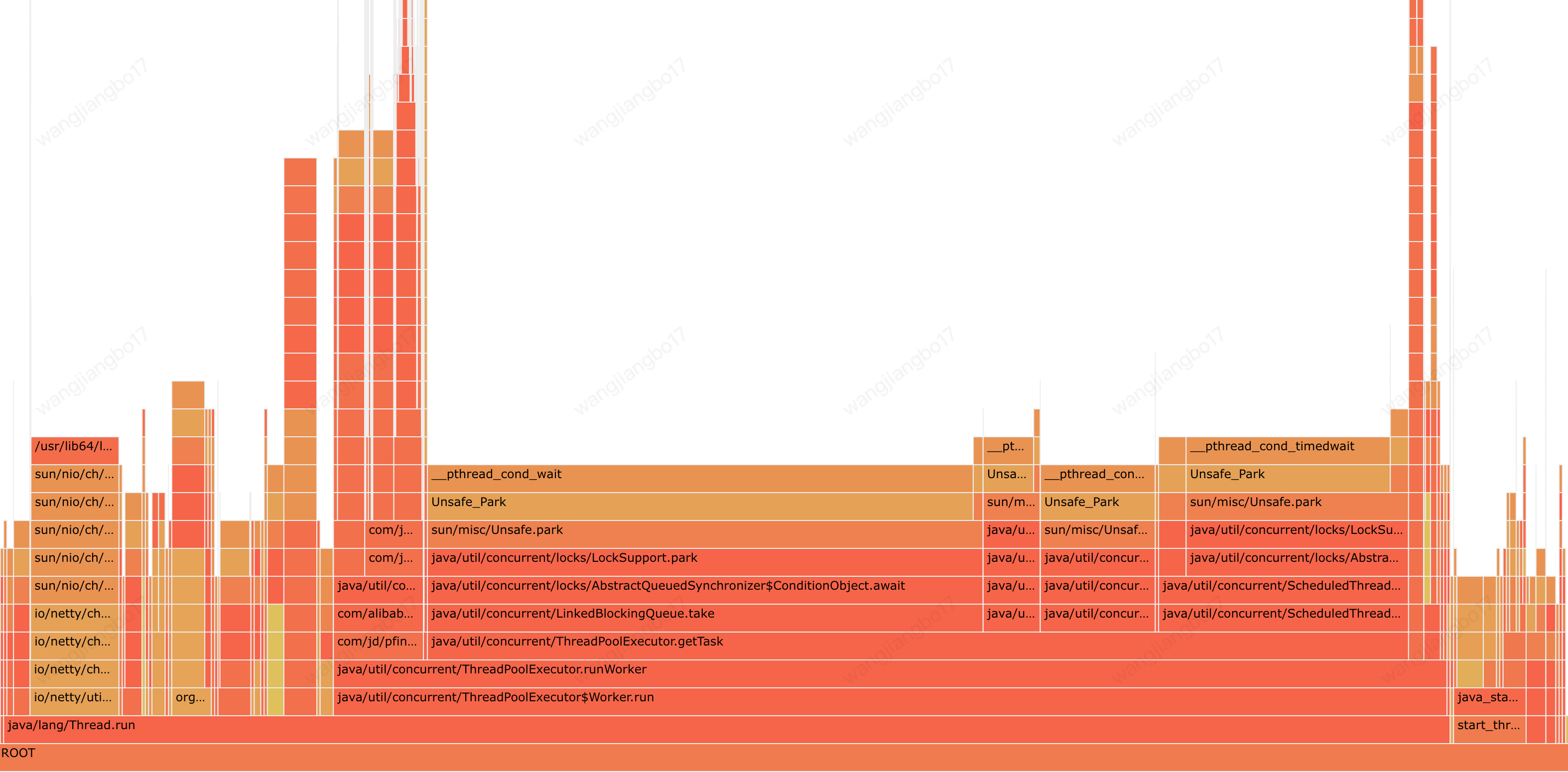
2.1 wait线程
2.2 锁性能

2.3 CPU采样
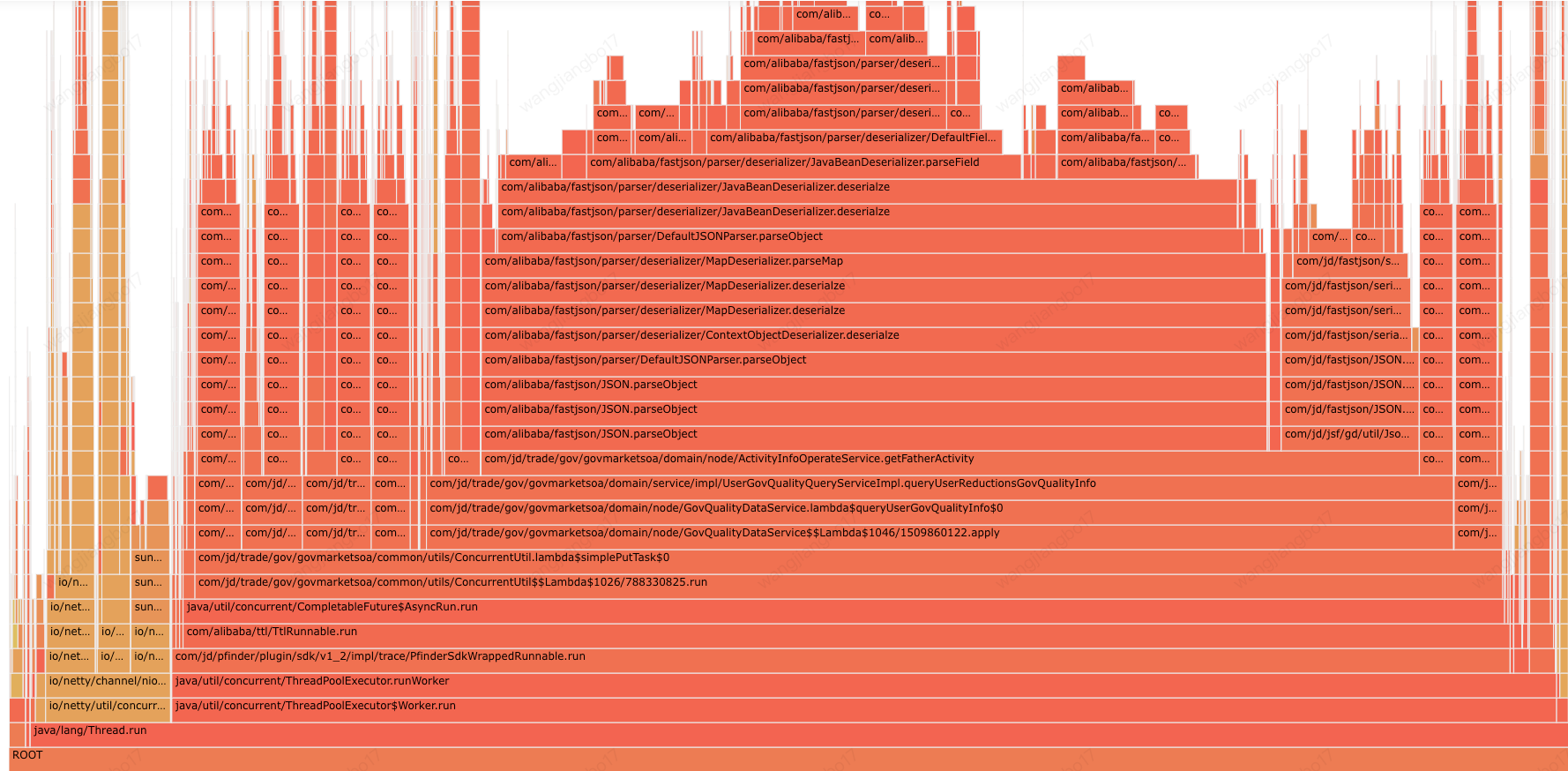
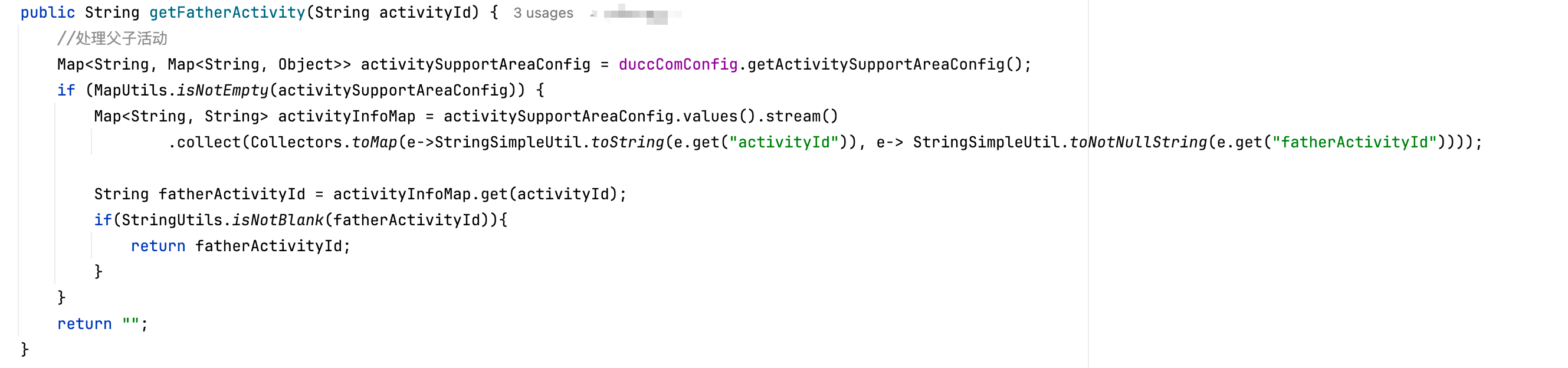
2.3.1 getFatherActivity分析

Q1:调用场景:循环中调用getFatherActivity
Q2:查看配置数据,json格式化后50000字符,大对象的反序列化
Q3:使用new ArrayList() 创建新对象
Q4:分组后只用了对象中的第一个元素,这里用toMap更佳
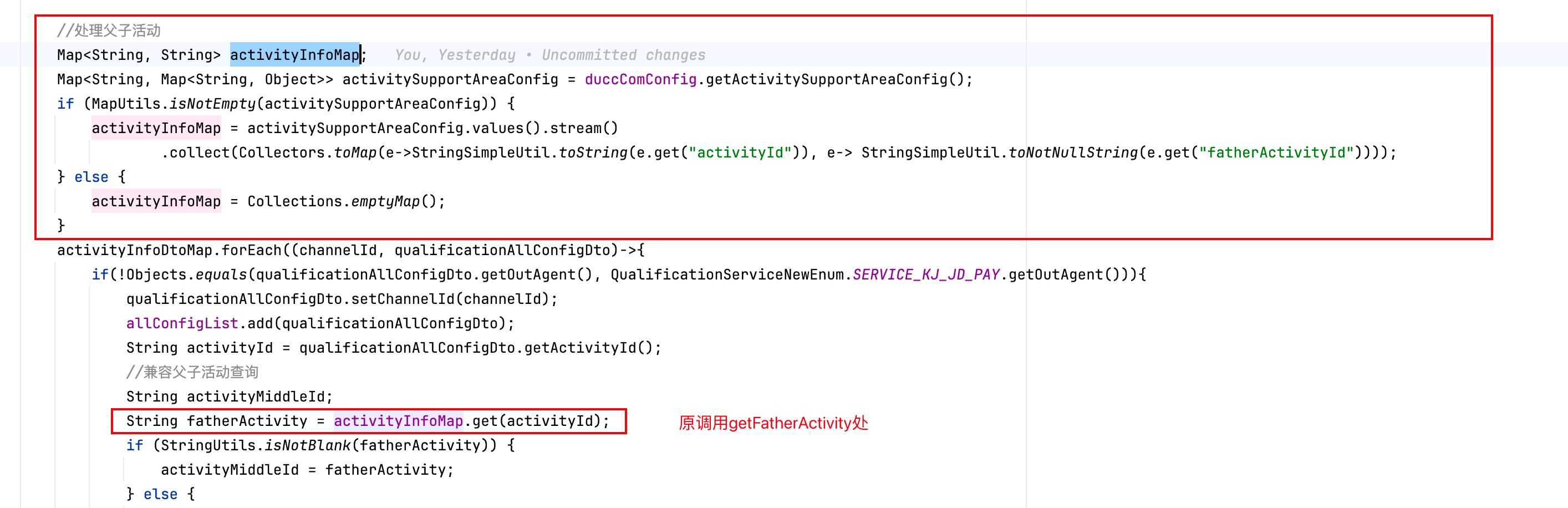
优化1:
我们可以发现上文在循环中还是会存在多次的stream调用,继而将toMap逻辑提到循环外,如下:
其他方法确实占用CPU较高,这里先不处理。
下文再优化一项获取并发线程执行结果的工具类:

1、 allOf异常后,取消所有线程的继续执行。这么做为了防止有些线程超时后仍在执行,浪费部分CPU资源,线上发现确实存在较多的超时情况。
2、 这里的异常日志较多,根据异常类型进行区分,去掉没用的堆栈日志。并发线程中所有的等待统一都使用了上文的方法,前文中的queryActTp处于WAITING状态可能也是执行没取消导致,修改部署后再观察分析。同样的调用方式 queryQualityTp 处于Timed_waiting状态可能与一次父任务中子任务的执行耗时有关,见上文监控,活动和资质相差较大,具体原因有待进一步分析。






