



背景介绍
目前质量团队正在积极建设和完善应用监控能力,旨在能及时发现并解决问题,为线上服务稳定性保驾护航。随着可观测性概念的逐渐普及,监控的建设也有了新的挑战和使命。本文将探讨在可观测性背景下,作为一个测试人员在质量保障中的一些思路和个人思考,以及为什么要区别于研发维度的可观测性,测试团队维度的可观测性建设又能为业务带来哪些价值。
一、了解可观测性
1.1 什么是可观测性
维基百科定义:
控制理论中的可观察性(observability)是指系统可以由其外部输出推断其其内部状态的程度。系统的可观察性和可控制性是数学上对偶的概念。可观察性最早是匈牙利裔工程师鲁道夫·卡尔曼针对线性动态系统提出的概念[1][2]。若以信号流图来看,若所有的内部状态都可以输出到输出信号,此系统即有可观察性。
在软件领域中,可观测性是从系统内部出发,基于白盒化的思路去监测系统内部的运行情况。其贯穿应用开发的整个生命周期,通过分析应用的指标、日志和链路等数据,构建完整的观测模型,从而实现故障诊断、根因分析和快速恢复。
Gartner将可观测性定义为软件和系统的一种特性,它允许管理员收集有关系统的外部和内部状态数据,以便他们回答有关其行为的问题。然后,I&O、DevOps、SRE、Support等团队可以利用这些数据来调查异常情况,参与可观察性驱动的开发,并提高系统性能和正常运行时间。虽然可观察性处于早期阶段,截至 2020 年只有不到 10% 的企业采用它,但 Gartner 预测,到 2024 年,30% 的基于云架构的公司将采用可观察性技术。
OpenTelemetry组织提出了可观测性依赖的三大“支柱”:
注:图片来源于网络
可观测性运作模式可看作是:观察-判断-优化-再观察
1.2 可观测性和监控的区别
从核心出发点来讲,传统的监控和可观测性,背后解决的是同样的问题:能及时、准确的掌握系统的运行状况,提升对系统运行的控制能力和故障处理能力。
- 监控(Monitoring):收集、分析和使用信息来观察一段时间内的运行进度,并且进行相应的决策管理的过程,监控侧重于观察特定指标。
- 可观测性(Observability):通过分析系统生成的数据理解推演出系统内部的状态,并提供数据、技术决策层面的支持。
从性能上看,监控和可观测性之间的区别可从以下四个方面进行区分:

注:图片来源于网络
监控是为了提高系统可观察性而执行的操作
可观测性:属于系统的一个属性,能有效的反应出系统的健康状况
1.3 可观测性和监控的联系

注:图片来源于网络
监控能够检测到系统中的错误,可以说是外部对业务应用系统的主动行为,而可观测性能够理解问题发生的原因,也就是说在增添了业务应用系统自身的要求的同时,还建立应用运行时产生的数据之间的关联。
二、质量保障目的
目标
- 实现对系统和应用的全面监控,能主动探测出系统运行健康状况。
- 快速定位和解决系统异常,能先于用户发现问题并能提供问题修复决策。
- 提供实时以及历史可对比数据反映出系统的运行状况,,支持技术决策。
范围
- 涵盖所有关键应用服务和基础设施。
- 包括应用、服务器、网络、数据库等,不局限于技术层面,更需要考虑业务数据层面。
三、质量保障思路
上边提到了监控和可观测性的区别和联系,本文提到的质量保障思路是以业务监控作为基础底座,拓展数据可观测性的能力,旨在解决传统监控被动防御的缺点,结合可观测性下的采集、聚合、追踪提供问题定位、风险预测、系统决策的能力。
1. 监控基础底座
1.1 监控维度思考
监控是为了提高系统可观察性而执行的操作,通常我们建设的监控能力包含以下几个方面:
- 资源层监控:
- 对硬件、网络带宽等资源使用层面的监控。通常由运维侧主导。
- 服务稳定性:
- 服务或接口的可用性等,例如UMP监控。通常由研发侧主导。
- 业务功能监控:
- 重点关注系统对外提供的功能是否正常,测试需重点关注的部分
- 业务数据监控:
- 重点关注跟业务特性强相关的数据,根据数据正确性、数据走向趋势能间接的反映出系统健康度是否有下降或存在潜在风险
- 日志聚类监控:
- 统计学监控的思维,从日志聚合角度计算出系统整体、分接口的可用性。可用性低于预期或存在环比内大幅下降则可能是系统出现异常
1.2 测试团队重点建设监控项
由于资源层监控和服务稳定性监控一般会由运维或研发主导,为了避免重复造轮子,这里不做单独的讨论,只讨论从测试视角要重点建设的监控能力
1.2.1 业务功能监控
接口功能:从接口维度进行监控,监控核心接口功能是否正常,其中:
读接口:由于不涉及脏数据的产生,可直接在生产环境监控验证。
写接口:由于写接口可能会产生脏数据,在保险侧业务上禁止此种操作,而且即使使用测试账号也会产生于生产环境差异巨大的不真实数据,所以我们无法使用直接在生产环境直接操作写接口。这里想到的一个方案是【测试反哺】,具体思路为:用预发环境反哺生产验证。理论上预发环境版本号一定 >= 生产环境,预发环境由于新提测的内容导致监控探测失败,可看作是对历史功能的回归验证不通过,其中有两种情况:
1. 预期内失败:功能变更对接口产生的影响,这时需要同步修改监控内容
2. 非预期内失败:新提测内容,影响了原有的功能,可看作是提测的需求bug
而关于接口监控的场景,这里想到了一种引流监控的思路,即用真实的用户请求验证功能的正确性(替换关键信息,不暴露真实用户数据)。
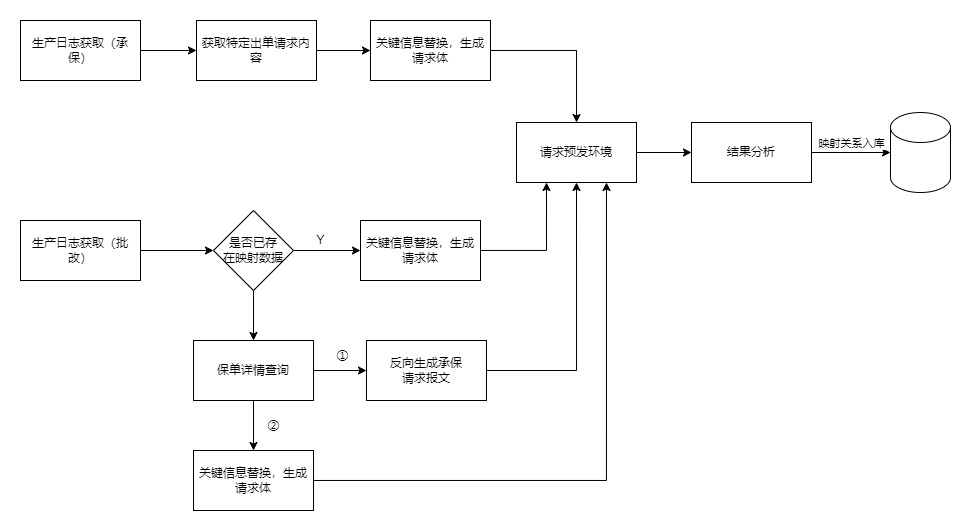
为什么要用引流做监控?
按照传统的接口监控方式,通常会写一个监控case然后周期性执行。这样写的弊端是高度依赖测试人员对业务的了解程度,也很难保障业务场景覆盖的完整性,而随着系统的迭代一个接口的功能场景可能会被扩展出很多,如果测试人员只了解其中的一个或某几个场景,按照习惯会添加这几个场景的监控case,但是不熟悉的场景可能就会一直缺少对应的监控。
场景覆盖:从用户可感知元素角度反推监控项case
这种思路比较像黑盒测试,即不关注具体的数据、业务处理流程,更贴近用户的真实操作,把自己想像成一个真实的用户,用户在使用产品的时候能看到什么,能操作哪些页面、按钮?这些操作背后对应的功能是什么,从视角上的可见反推到不可见的应用背后。
1.2.2 业务数据监控
业务数据是产品最终的价值体现,数据的有消息、正确性、健康性最终能反应出系统的稳定性。针对保险业务,我们其实可以做很多业务数据层面的监控,例如:
- 核心数据量(单量、保费等核心数据的实时性)
- 业务数据正确性的检查计算(例如保费=税+税后费用,出现不等则是错误数据)
- 核心数据走向趋势,当天退保比例高于某个阈值,或者环比高于某个阈值
......
1.2.3 日志聚类监控
跟业务数据的重要性一样,通过日志也能间接的反应出系统运行的稳定性状况,由于对日志进行聚类监控本身依赖应用日志的规范性,所以这里非为短期内可落地和长期改造的两个思路。
短期:
特点:不依赖研发测改造,可以根据现有日志聚类出报错类型。
监控逻辑:根据固定阈值触发报警。举例:如果某一个错误类型批量出现超过设定的阈值,需要报警。
这种监控最大的问题在于阈值设定的不合理会产生漏报或批量的误报。
所以需要一段时间的试错,前期阈值设定的保守一些,用一段时间的数据评估出一个相对合理的阈值,同时由于数据的积累,后续的报警策略也可以摆脱单独的固定阈值方式,使用阈值+趋势分析的策略进行报警。
引申价值:近一周或一个月内报错数量统计对比,如果某天报错突然增多,则预示可能存在风险(百分比上涨监控)。
报警Demo:【警告】10min内 {投保年龄错误} 类型报错数量超过100,大于设定阈值90,请排查系统是否有异常!
长期:
特点:依赖研发规范日志打印(一个请求至少需要有开始和结束的打印)
监控逻辑:全量拉取生产日志进行日志清洗和计算,统计应用可用性
应用可用性 = (时间段内的全量流量 - 时间段内的报错流量) / 时间段内的全量流量
引申价值:由此可计算出天级可用性、小时级可用性、10min级可用性。同时规范的logid可以作为入口系统出现异常时,向下追踪的依据。
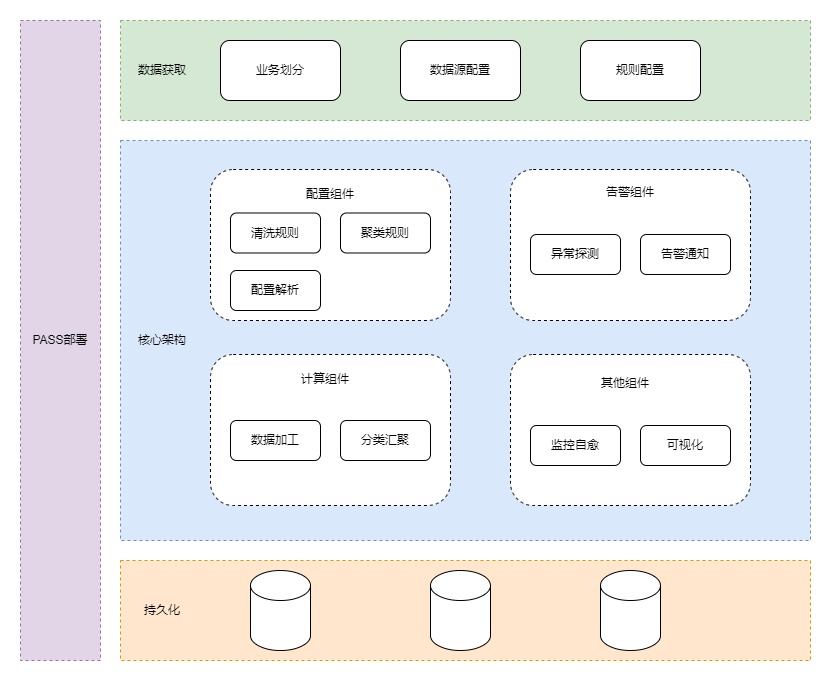
2. 可观测性维度思考
集团的PFinder (problem finder) 是UMP团队打造的新一代APM(应用性能追踪)系统,非常贴合可观测性的概念,目前研发团队也在陆续的将应用接入到PFinder。
那为什么测试团队要做区别于研发维度的可观测性?又该如何去做?
避免重复造轮子!作为测试人员应该对系统的功能是否可用、业务数据是否正确有高度的敏感性。测试团队的可观测行建设与监控紧密结合。通过配合监控建设,结合可观测性给出系统诊断、分析、定位的能力。
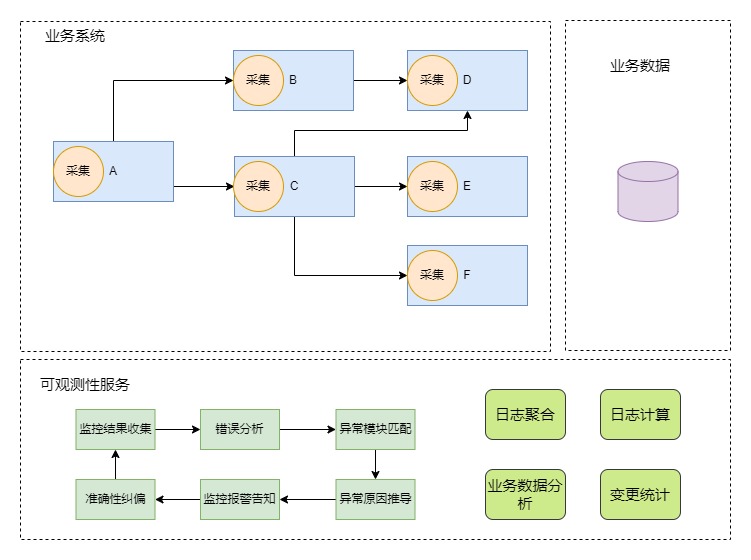
2.1 模块级可观测性
模块及的可观测性用来检测单系统、单模块的系统稳定性,主要提供核心数据的趋势分析参考,理想状态能实现以下类型的警告信息
报警Demo:【可疑】核心数据xxx从【xxxx-xx-xx】服务上线后,出现连续x天数据下降,请相关注是否存在异常。
2.2 系统级可观测性
根据日志采集系统,聚合出当前模块、下游模块的数据流走向。当任何一个模块的监控项出现报警时,能及时通知并且能携带出一定的问题排查和定位结论。同时能进行不同系统之间的数据核对。
联动报警
可观测性具有系统及观测的特点,也就是说它能更全局的看到到整个系统不同模块的状态,所以应该具备很强的模块联动性。
通常在一个业务系统中,叶子节点的异常会导致上游服务的异常。例如应用A 调用 应用B完成业务处理,当应用B发送异常时,会影响到应用A,传统的监控方式是对各自的应用做监控,此时如果应用B本身的监控不完善,很难第一时间排查出问题的根因,甚至在应用B监控完善的情况下,如果AB信息没有及时共享,也很难第一时间定位问题。在这种情况下建设联动报警的能力,除了能发现上游服务的问题,还能引申联动探测出子模块的异常,可以有效缩短问题定位和修复的时间。
具体思路为:当上游应用发生异常时,可尝试向下游子模块进行探测,在报警信息中汇总出所有发现异常的模块信息,给问题定位人员提供直观的排查方向。
故障定位
在具有联动报警能力的基础上,报警信息中可提供更准确的故障内容
举例:应用A 调用 应用B完成业务处理,某次B应用上线后A应用某些功能不可用
报警Demo:【错误】应用A XXX功能异常,本服务数据、日志计算未发现明显异常,下游应用B探测出可疑异常日志{日志关键信息},下游应用最近上线日期为【xxxx-xx-xx】,请及时排查。
数据分析
多系统之间的业务交互最终表现在数据流上,在具备了系统应用间的联动能力以后,可以对关键数据进行核对或者分析转化率
数据核对可以提供不同系统间数据一致性的校验
数据转化可以看出同一笔数据在不同系统间的流动,可以引申出一些业务敏感数据的对比等
2.3 感知及展示
不论是监控还是可观测性,都需要通知和展示,这部分计划结合最近在做的业务监控大屏做展示,后续再提供一个通用的报警服务,提供邮件、消息、语音的多通道报警能力。






