



前情提要:
最近新接了一个需求,需要去创建两张表,其中有一张表需要根据业务id和业务类型建立唯一索引,对数据唯一性进行约束。
因为涉及到业务嘛,表结构就进行缩略了
表结构示例如下:
CREATE TABLE `example_table` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增主键',
`business_id` bigint(20) unsigned NOT NULL COMMENT '业务ID',
`business_type` tinyint(3) unsigned NOT NULL COMMENT '业务类型,',
`del` tinyint(1) unsigned DEFAULT '0' COMMENT '删除标识,0表示未删除,1表示删除',
`creator` varchar(50) NOT NULL COMMENT '创建人PIN',
`modify_date` datetime DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
`create_date` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_business_id_and_type` (`business_id`,`business_type`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8mb4 COMMENT='示例表'既然表建立好,那么就是发挥我们编码能力的时候了...此处省略一堆编码时间。
编码结束,自测结束,信心满满的找前端同学进行联调。
因为联调嘛,mock了很多同样的business_id和bussiness_type的数据,结果到了数据库,因为唯一索引的约束,报了一堆错误,插入都失败了。
终于调整了一下mock数据,插入成功了。
但是发生了一个比较神奇的现象

 主键不是连续自增的了~~ 中间丢失的自增主键去哪了??
主键不是连续自增的了~~ 中间丢失的自增主键去哪了??
关于自增主键
自增主键是我们在设计数据库表结构时经常使用的主键生成策略,主键的生成可以完全依赖数据库,在新增数据的时候,我们只需要将主键设置为null,0或者不设置该字段,数据库就会为我们自动生成一个主键值。
首先,我们要知道 自增主键保存在哪里~
不同的引擎对于自增值的保存策略不同
1.MyISAM引擎的自增值保存在数据文件中
2.InnoDB引擎的自增值,在MySQL5.7及之前的版本,自增值保存在内存里,并没有持久化。每次重启后,第一次打开表的时候,都会去找自增值的最大值max(id),然后将max(id)+步长(建表语句中的指定步长)作为这个表当前的自增值。在MySQL8.0版本,将自增值的变更记录在了redo log中,重启的时候依靠redo log恢复重启之前的值。
了解了自增主键的保存机制,再了解一下主键这个"自增"逻辑~
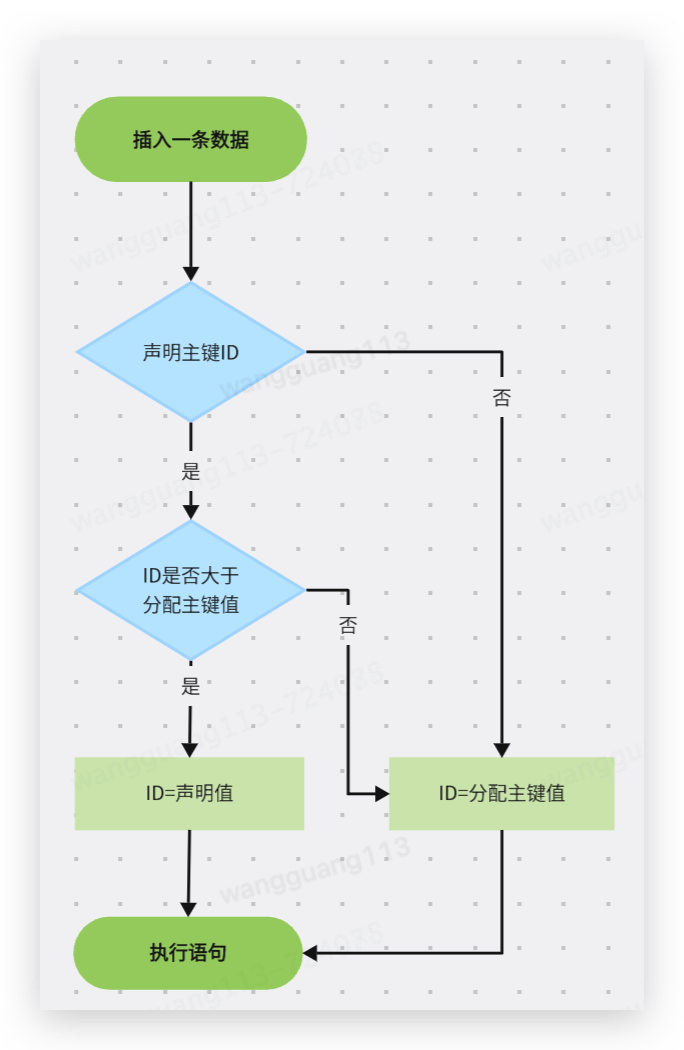
插入一条语句分配自增主键id值的流程如图所示。
自增主键不连续的情况
细心的小伙伴一定发现了~咦,这个ID=声明值的话,ID就可以能被随意指定了,那么ID就可能存在不是自增的情况了!
是的,这其实就是第一种自增主键不连续的情况。
第二种不连续的情况就是我们在联调中遇到的问题了
简单来做个测试,目前数据就像一开始的图一样,id自增到了24,下一个插入的应该是25,那么执行一条sql
insert into example_table values (null,111,1,0,'mock',now(),now());
插入成功了一条数据,主键是连续自增的。
那么我们模拟一条错误的sql呢(`creator`字段指定错类型)~:
insert into example_table values (null,112,1,0,mock,now(),now());果然,执行sql 的时候报出异常:

继续执行一条正确的正常的sql,插入结果:

主键还是连续自增的。这个发生错误为什么自增主键还是连续的呢。我们模拟一下之前联调遇到的情况,插入一条 sql:
insert into example_table values (null,112,1,0,'mock',now(),now());因为id=26的数据buiness_id和bussiness_type 跟新插入的这条数据一样,那么肯定会因为唯一索引插入不成功,果然,执行结果如下:

那么,我们修改一下sql继续插入呢?
insert into example_table values (null,113,1,0,'mock',now(),now())
主键发生了"断代",27的主键跑丢了...
明明都是sql插入的时候错误,为什么结果会有差异呢,有的时候主键会丢失,有的时候主键不会丢失呢,想要弄明白这个问题,就需要先明白一下一条sql的执行过程:
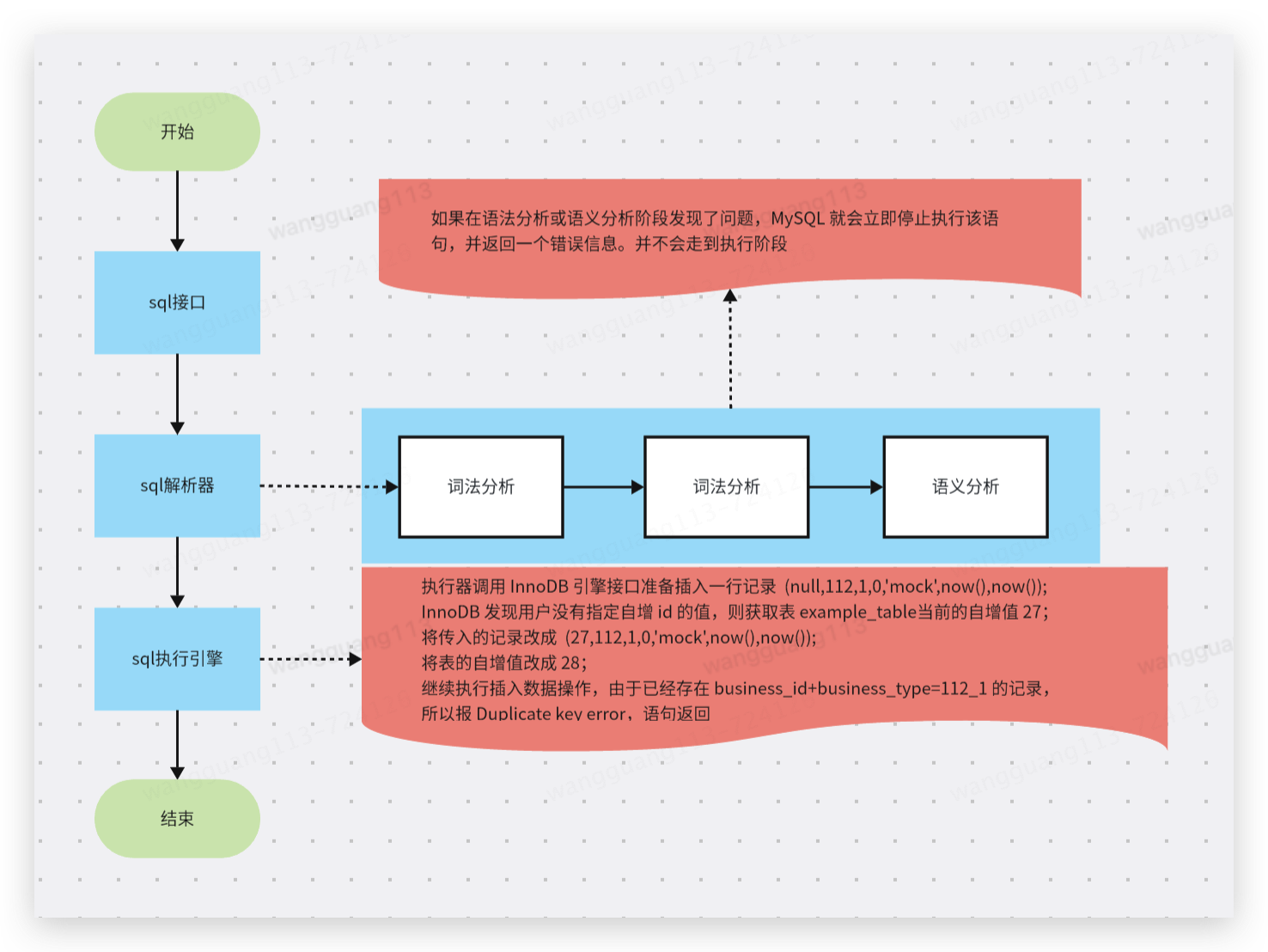
这里只是针对本文需要关注的点(相信小伙伴对这个执行过程肯定也是非常了解的😏)
所以说 主键有没有丢失的核心关键就是有没有走到 执行引擎有没有去分配主键。一旦走到了分配主键就不会进行回滚。
既然一旦分配了主键就不会回滚,那是不是事务回滚之后主键也不会回滚至之前的值呢?
第三种就是这样,事务回滚也会导致主键“丢失”:
举个栗子:
insert into example_table values (null,114,1,0,'mock',now(),now());
回滚这条语句。并继续执行上面那条语句

29这个id就“丢失”了。
有好奇的小伙伴就会问了,问什么mysql-innodb不提供一种回滚主键id的机制呢?
我理解的是,1、没有必要 ;2、影响性能;
自增主键锁并不是一个事务锁,而是每次申请完就马上释放,以便允许别的事务再申请。但在MySQL5.0版本的时候,自增锁的范围是语句级别。也就是说,如果一个语句申请了一个表自增锁,这个锁会等语句执行结束以后才释放。MySQL5.1.22版本引入了一个新策略,新增参数innodb_autoinc_lock_mode,默认值是1。
1.这个参数设置为0:表示采用之前MySQL5.0版本的策略,即语句执行结束后才释放锁。
2.这个参数设置为1:普通insert语句,自增锁在申请之后就马上释放。批量插入数据的语句,自增锁还是要等语句结束后才被释放。
3.这个参数设置为2:所有的申请自增主键的动作都是申请后就释放锁。
我们假设一个场景主键id是可以回滚的,根据上面的自增主键锁的规则。事务A申请了一个自增主键id=29,事务B申请了一个自增主键id=30,在申请了之后就会被释放,如果这个时候事务A进行了回滚,事务B执行完毕,这个时候就需要将id回滚到29,但是id30已经存在表中了。那么肯定会需要一个类似现在的redolog,undolog的"存储单元"去存储主键id的分配情况,如果再有一个事务C过来申请主键id,这个时候就会出现很多种情况去考虑,1:我要申请的主键id是否已经分配出去了。如果已经没有还好,如果有的话,需要去找到一个允许我插入的最小的id(这个最小的成本就会比目前直接选择最大的id性能要查很多。)2:我是批量插入,我需要申请一批id,这种情况想想就很抓马,因为这一批次中的id可能存在多个已经存在的情况。
而且就算主键id可以回滚,那么我插入数据的顺序,跟id的大小就存在悖论关系了,在业务层面就不能根据id去做一些判断了,这也无疑增加了业务层面的复杂性。所以主键id是可以回滚是一个ROI极低的方案了。
在上面的说到的自增主键的分配策略也可以想到:
第四种不连续的情况:批量申请的主键id,如果出现没有使用完,或者批量插入出现问题导致的主键id不连续。
当然这里说的批量插入不是
insert into example_table values (null,111,1,0,'mock',now(),now()),(null,112,1,0,'mock',now(),now());这样的语句,因为这种语句在sql解析的时候就可以明确需要插入多少条目,id也就会直接进行分配到具体的条目。
但是对于 insert...select 这种批量插入语句,因为大部分都是执行多表操作,所以实际操作的条数是不可确定的。
在进行分配主键id的时候,会有一个策略:
- 语句执行过程中,第一次申请自增 id,会分配 1 个;
- 1 个用完以后,这个语句第二次申请自增 id,会分配 2 个;
- 2 个用完以后,还是这个语句,第三次申请自增 id,会分配 4 个;
- 依此类推,同一个语句去申请自增 id,每次申请到的自增 id 个数都是上一次的两倍。
create table `example_table_2` like `example_table`;
#使用批量插入语句 从example_table中读取数据, 往example_table_2中插入数据
insert into example_table_2 select null, business_id, business_type, del, creator, modify_date, create_date from example_table;这个时候的执行结果如图:
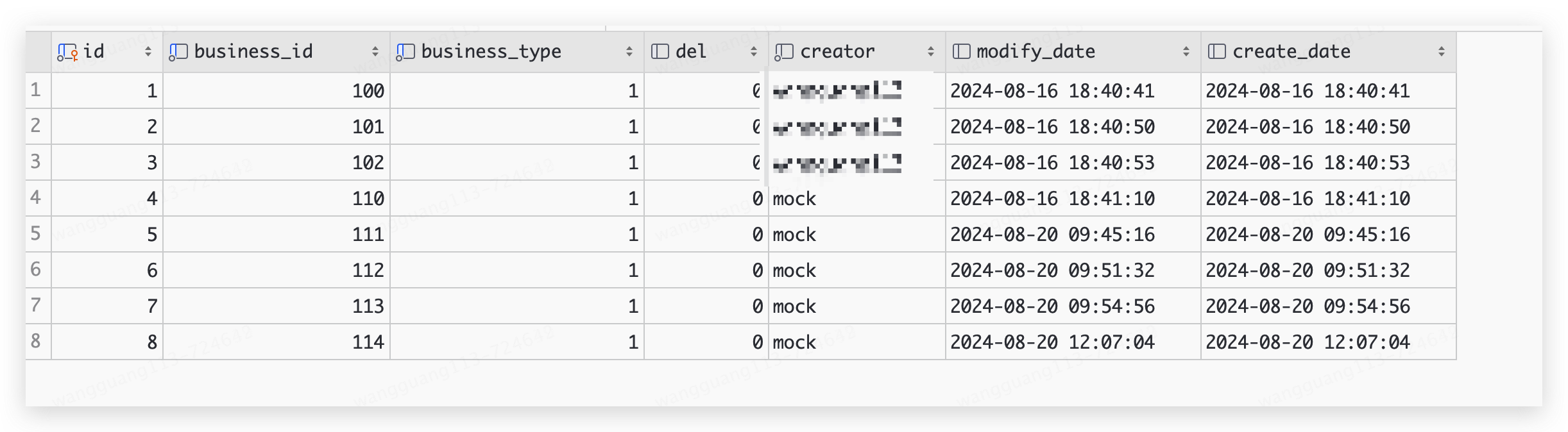
那么按照预期 第一次分配id=1,第二次分配id是[2,3],第三次分配id区间是[4,7],第四次分配区间是[8,15],那么执行下面语句:
#插入一条数据 预期主键id应该是16
insert into example_table_2 values (null,200,1,0,'mock',now(),now());
果然执行结果符合预期结果。
这个语句在实际业务中使用的很少,mysql在这个语句里面还是有很多设计的,大家可以看看官方文档详细的了解一下
https://dev.mysql.com/doc/refman/8.0/en/insert-select.html
还有一种情况是主键id设置的步长不为1
这种情况一般都是发生在表的设计初期,所以出现不自增的话也是符合预期的。
写在最后
MySQL是作为大家都经常接触的DB,相信大家都会有一定的认知,自增主键不连续大家肯定也遇到过,这次在联调过程中遇到这个情况,在跟别的小伙伴分享的时候,突然就想写一篇文章,文章里面如果有不正确或者不准确的地方也欢迎大家斧正~说实话,作为一名交易端的研发人员,业务开发任务压力真的蛮大的,我也迷茫过,如何在这个过程中成长,珍惜我们遇到的问题,将遇到的问题记录在册,深追问题,你会发现有很多问题其实真的是因为我们某些知识的薄弱点造成的。然后将我们觉得值得分享的利用碎片时间整理成文章分享出来,其实这篇文章从我开始写到到最后成稿也历时11天之久,但是不管怎么样,只要我们从中有收获就可以了~最后,希望大家都可以成为自己心目中的技术达人。
To enjoy is to be young,To enjoy is to be your own goal!






