



一、复杂度综述
1、什么是复杂度
软件设计的核心在于降低复杂性。
--《软件设计的哲学》
业界对于复杂度并没有统一的定义,斯坦福教授John Ousterhout从认知负担和工作量方面给出了一个复杂度量公式
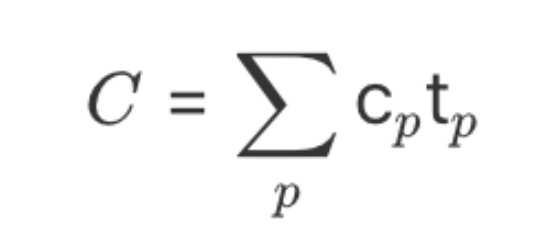
子模块的复杂度cp乘以该模块对应的开发时间权重值tp,累加后得到系统的整体复杂度C
这里的子模块复杂度cp是一个经验值
需要注意:如果一个子系统特别复杂,但是很少使用及修改,也不会对整体复杂度造成太大影响。例:spring框架内部代码较为复杂,但由于几乎不需要我们去变动,所以对系统的整体复杂度影响并不大
2、复杂度分类
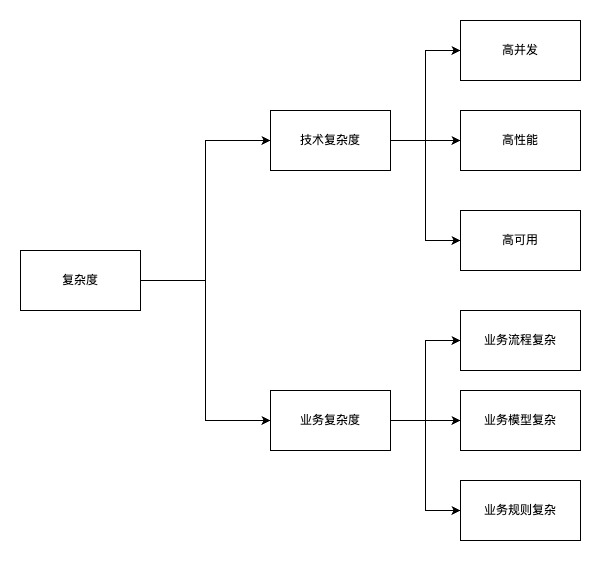
本文主要面向业务复杂度的治理
3、业务复杂度高的影响
(1)研发成本高。需要花费更多的时间去理解、维护代码;同样的需求,可能需要要修改更多的工程和类
(2)稳定性差。过高的业务复杂度,会导致系统难以理解甚至理解出现错漏,改动代码后极易出现“按下葫芦起了瓢”的问题
二、业务系统复杂度高的常见原因
1、业务系统模块多,关系复杂,互相依赖
比如一个电商业务,会包含商品、订单、采购、库存、财务等多个系统,系统之间有各种各样的依赖关系关系,如订单系统依赖库存充足才可以正常下单,采购依赖商品必须创建才可以发起采购;而系统内部又可以划分为多个子系统,如订单系统可以包含接单、营销、会员等各个子系统
2、代码晦涩,从代码中很难找到关键信息
如下边的业务处理代码,不点进具体的方法,根本不知道做了什么:
/**
* 处理业务逻辑
*/
public void handleBiz(){
step1();
step2();
step3();
}
再比如下边的业务处理代码,做了方法定义外的操作,开发者很容易遗漏重要信息
/**
* 转换对象方法
*/
public Po convert(Dto dto){
Po po=new Po();
po.field=dto.filed;
//更新操作,不应该放到转换方法里
mapper.update(po);
//调用rpc服务,不应该放到转换方法里
XXGateway.update(dto);
return po;
}
3、业务规则、流程变化多,变化频繁
大量的变化造成花在系统上的时间增多,提升了开发时间权重;
繁杂的业务规则写在代码中,难以理解、梳理
三、降低业务复杂度的方法
1、抽象分治,分解复杂度
(1)领域拆分
将与核心概念有关的内容抽取/合并,形成独立的领域
a、实体类的系统。映射到物理实体,比如商品中心、用户中心、地址服务等
b、流程类系统。映射到多个角色的串联协调工作,比如供应链上单,审核类系统等
c、计算任务类系统。映射到虚拟计算机类及数据处理,比如搜索排序、推荐计算等
供应链领域化拆分例子:
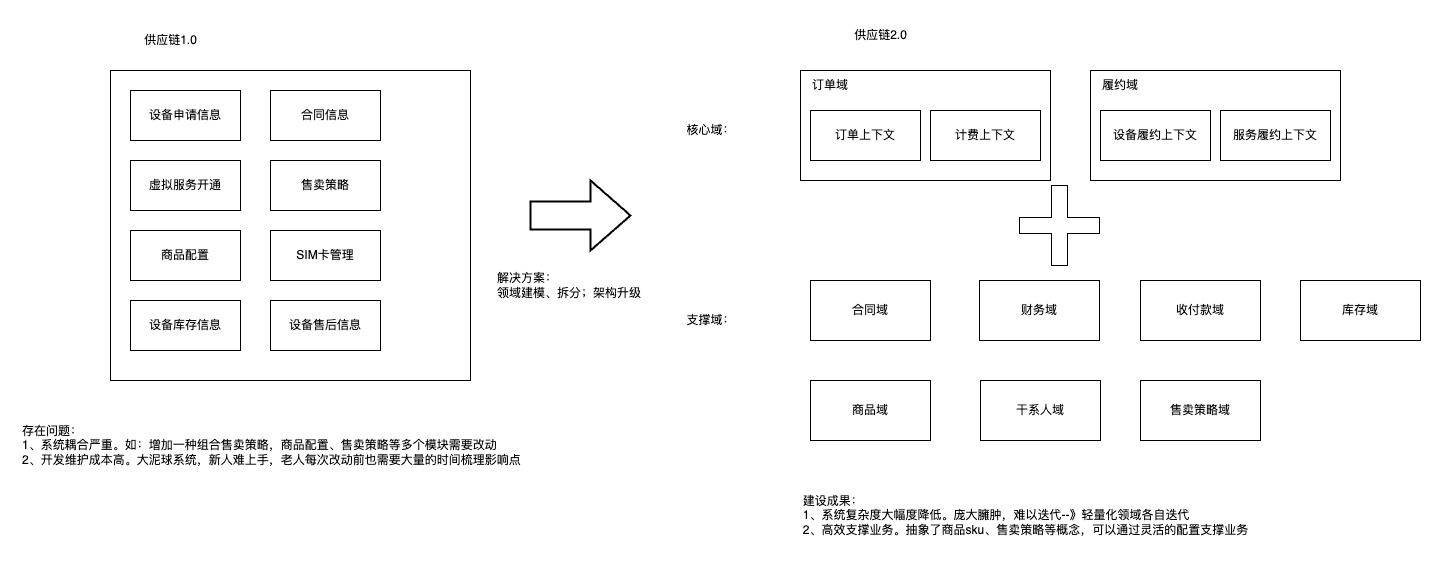
(2)领域之内拆分
01、变与不变拆分。将不易变化的系统能力拆分出来,上层适配各种业务逻辑,底层提供稳定的能力单元。如营销领域,将优惠卡券这个不易变的内容作为一个子系统来设计
02、场景隔离。如B/C隔离,B端业务复杂度较高,流量较小,更注重数据建模、可配置、可扩展;C端业务复杂度低,但是流量较大,更注重高性能、高可用
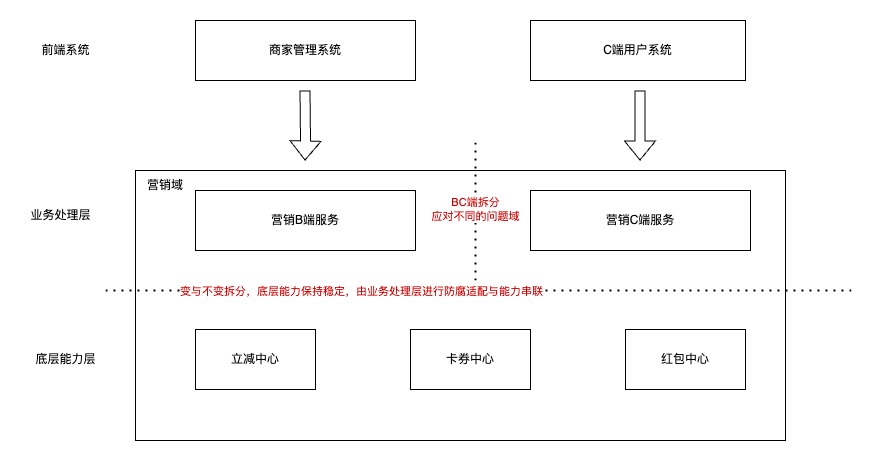
例:营销领域进行【变与不变拆分】+【场景BC隔离】例子:
背景:营销域即有面向商家的营销资质、营销活动管理,又有面向C端用户根据活动领红包、优惠券的高频业务
其中,B端业务逻辑较复杂但请求量小,C端业务逻辑较简单但请求量大
治理方案:【变与不变拆分】+【场景BC隔离】
建设营销B端服务。提供面向商家的营销活动管理,重心放在建设复杂的营销活动模型、处理复杂的业务流程;
建设C端用户系统,提供面向C端客户的领营销资产、消费影响资产服务,重心放在高并发、高可用建设;
建设底层营销资产管理服务。如卡券中心提供生成卡券、消费卡券、查询卡券等基础稳定的服务。相对不易变化,不需要经常迭代;
上层的服务根据不同的业务场景来决定把卡券发给谁、什么时候发、发多少,业务场景变化或者有新的场景时,经常需要迭代
拆分架构如下图:
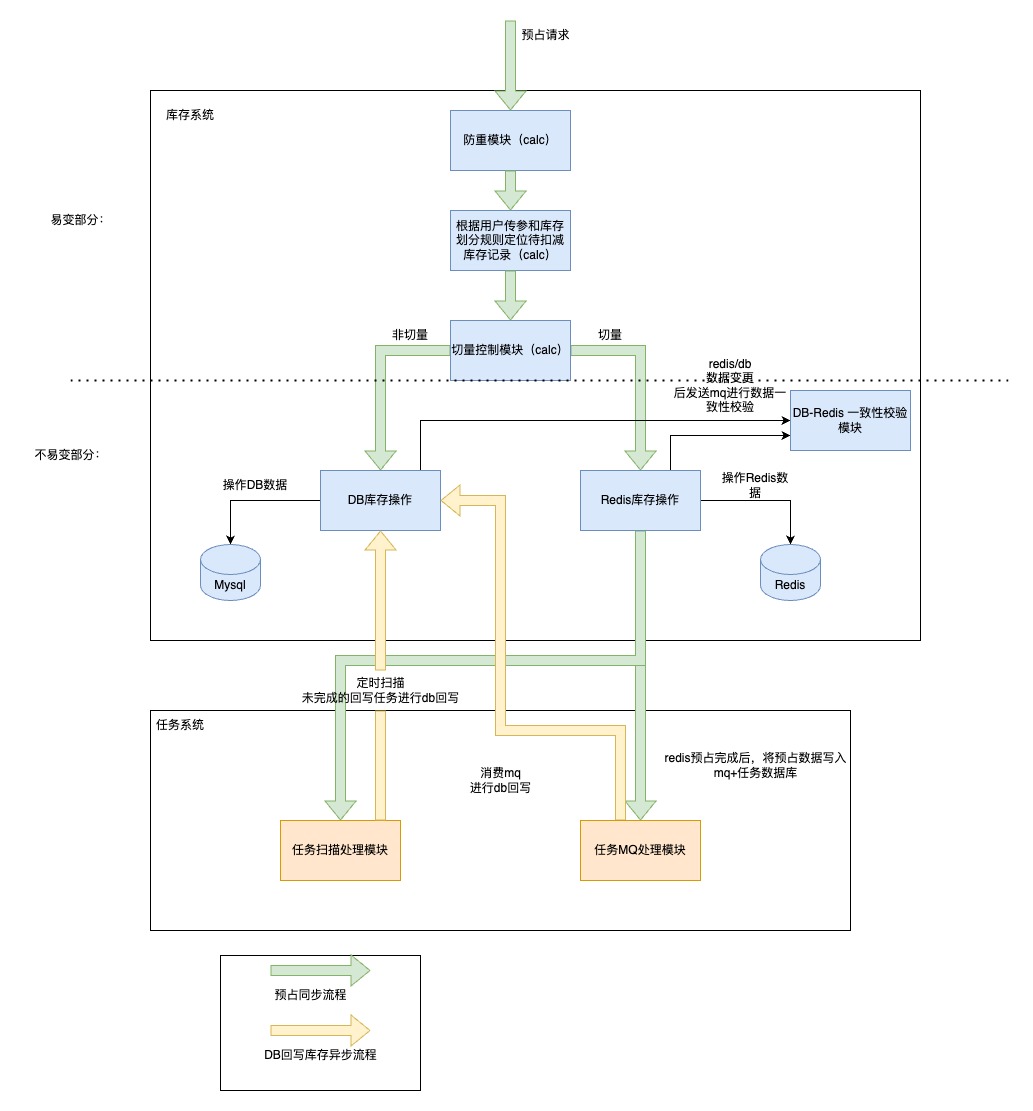
例:库存中心【变与不变拆分】例子
背景:
01、业务上。库存业务面向的业务场景较多,如采购加库存、销售扣库存,退货加库存等等;库存扣减逻辑也较复杂,如一个sku下多个渠道按照优先级扣减、一个sku有多个批次按照过期时间先后扣减等等;
02、技术上。为了提升性能,高频操作场景会先操作redis缓存,再异步同步DB数据
治理方案:抽象业务+变与不变拆分
库存操作业务可以抽象为:根据用户条件、库存划分规则定位到需要操作的库存记录,按照库存记录对库存进行操作
变与不变拆分: 01、DB库存操作、Redis库存操作建设为底层支撑能力,仅提供基础的库存加减能力,尽量保障其不变性,避免大幅度的改动影响所有业务 02、根据业务逻辑去定位库存,这部分相对来说变化比较频繁,由上游业务系统进行处理
库存架构如下图:
(3)子领域/系统 内部拆分
01、代码分层。确定每一层的分工;确定调用关系,不能跨层调用;如果下层能解决的复杂性问题,不要放到上层,如:外部接口调用失败重试,不能放到服务层
常用的贫血模型分层例子:
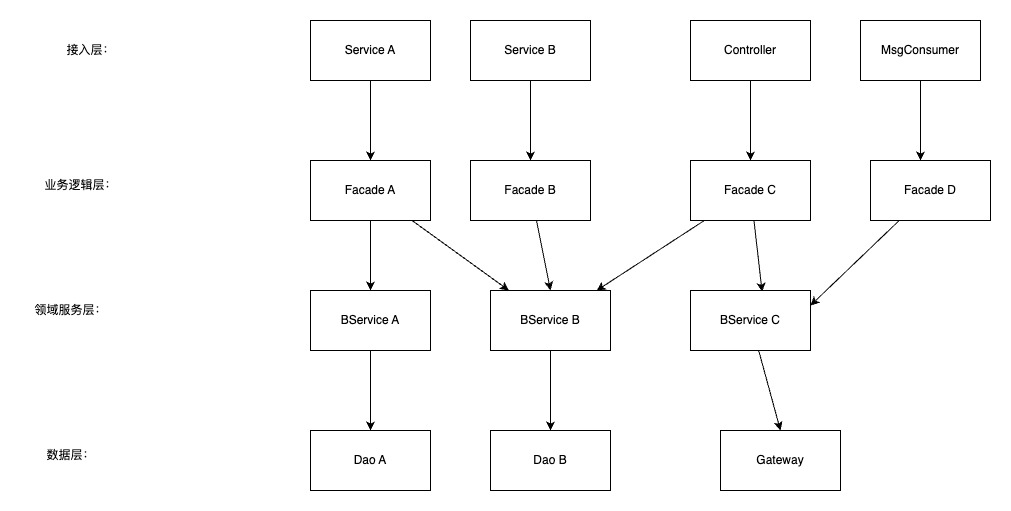
核心思路:关注点分离、能力复用。各层职责:
- 接入层:负责服务接入,包含日志打印、异常处理、参数检查、权限检查等接入层能力。该层不包含业务逻辑
@Override
public InsertDeptResponse insertDept(InsertDeptRequest request) {
//入参记录
log.error("insertDept request:{}",request);
InsertDeptResponse response=null;
String umpKey = XXX;
Profiler.registerInfo(umpKey, true, true);
try{
//校验入参,如果校验不通过,checkParam方法会抛出参数校验不通过异常
checkParam(request);
//权限校验,如果校验不通过,checkAuth方法会抛出权限校验不通过异常
checkAuth();
//业务逻辑处理,内部可能会抛出影响可用性的异常和不影响可用性的异常
response=XXFacade.insertDept(request);
}catch(BizRuntimeException ce){
//不影响可用性的异常
log.error("XXX");
//组装返回值
response=XXX;
}catch (Exception e) {
//影响可用性的异常
log.error("XXX");
//组装返回值
response=XXX;
Profiler.functionError(info);
}
log.error("insertDept response:{}",response);
Profiler.registerInfoEnd(info);
return response;
}
- 业务逻辑层:整体负责接口中的业务逻辑处理。主要进行各领域间的逻辑串联、数据处理
- 领域服务层:以某个核心概念为核心组件领域服务,如权限服务,将该领域相关能力进行收口,提供给上层可复用的能力
- 数据层:负责与数据库或者外部服务进行数据交互
02、自上而下的结构化分解。使用金字塔原理,将复杂逻辑进行结构化自上而下分解
例:供应链业务二维码牌安装服务治理
背景:供应链业务中,二维码牌安装服务流程特别复杂,理解与修改都很困难;流程中用到很多数据,在不同方法中被重复获取
治理方案:结构化抽象、分解业务流程
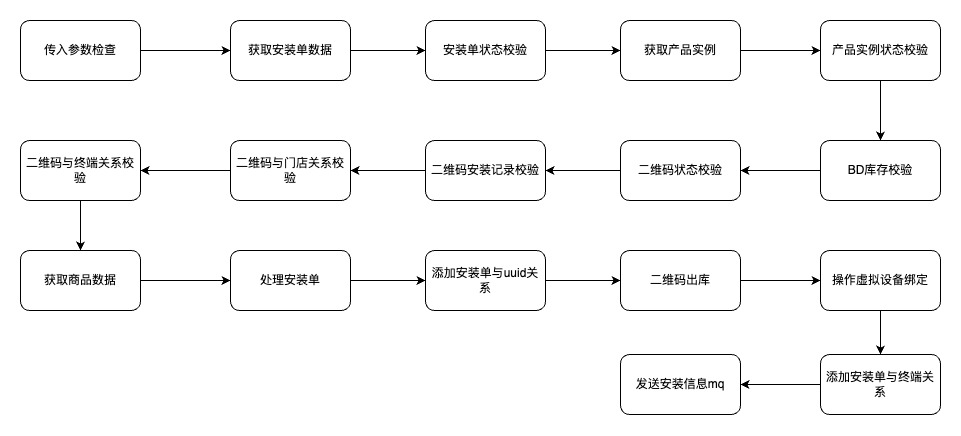
结构化分解后的流程:
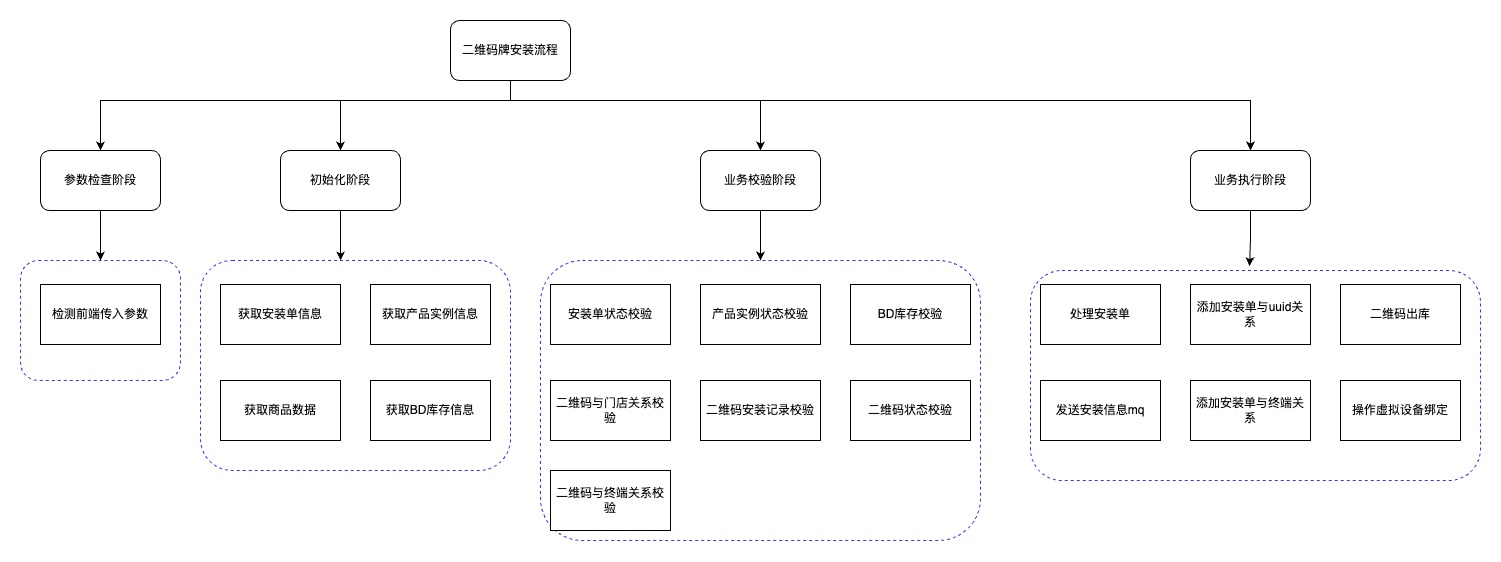
拆分后主方法伪代码:
public void setUp(){
//参数检查阶段
paramCheck();
//初始化阶段
initData();
//业务校验阶段
businessCheck();
//业务执行阶段
businessExecute();
}
(4)方法逻辑拆分。职责单一、命名准确
方法随意命名,尤其是做了与命名无关的事情,会极大的增加复杂度,影响阅读者对代码逻辑的理解
(5)系统合并
如果多个系统逻辑上耦合严重,改了一个模块,另一些基本都要变动,考虑将这些系统合并
2、添加注释,使代码易懂
(1)代码思路要通过注释/自注释标识出来
例:redis模式的库存操作,在处理逻辑主方法中,较为清晰的标注了每一步核心逻辑
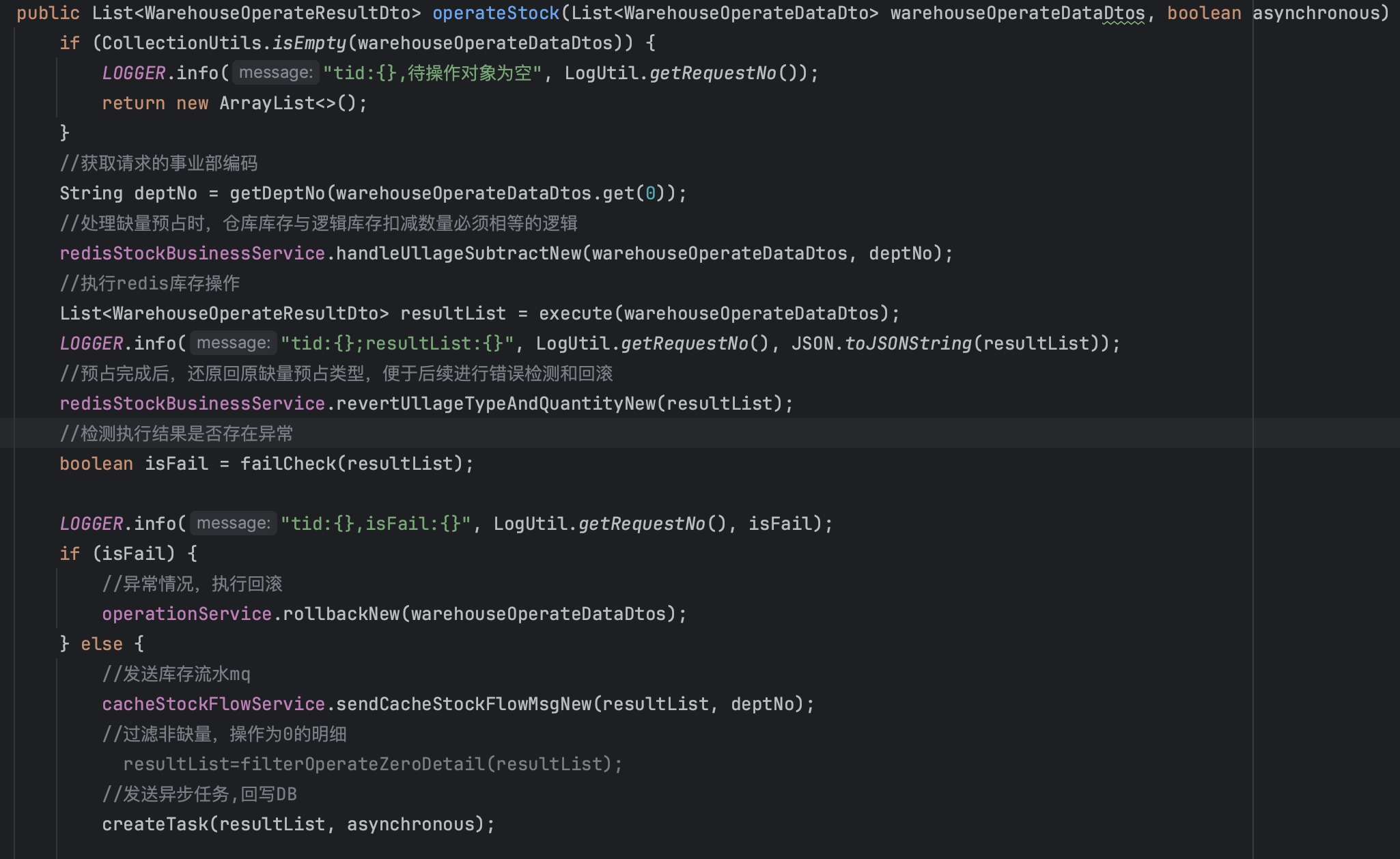
(2)注释应当能提供代码之外额外的信息
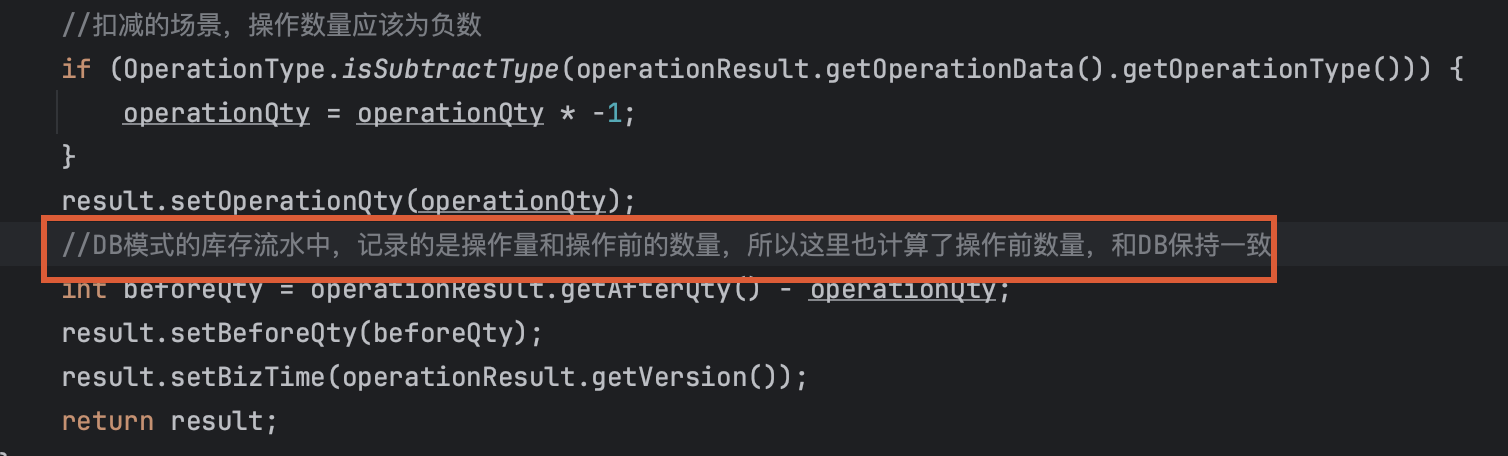
重视What和Why,而不只是代码是如何实现的(How)
01、一些不那么直观的代码,可以附上原因
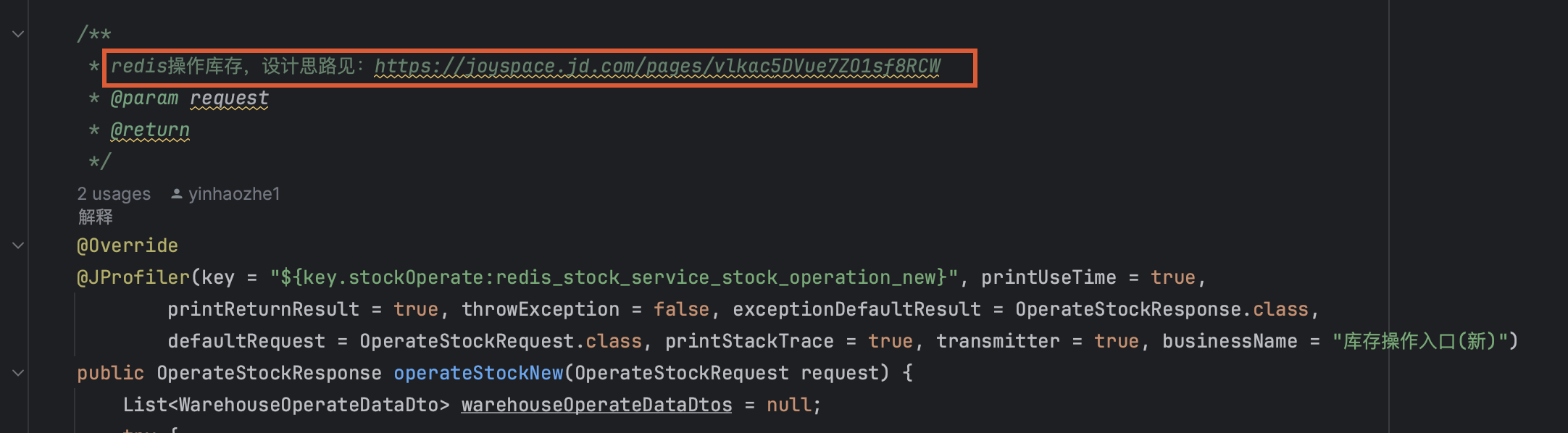
02、设计思路,特别复杂的,可以考虑贴上设计方案的地址
3、配置化
(1)业务对象可配置
业务中用到的同类型对象特别多,使用硬编码方式维护困难时,可以考虑抽象出可配置化的对象配置中心
如:商品中心,将商品抽象为sku,并提供名称、价格、重量等可配置的属性
(2)业务规则可配置
业务中规则部分特别复杂,可以考虑抽象出可配置化的规则配置中心
如:售卖策略配置,某sku在某业务线+某业务场景中,必须搭配某种前置sku,以XX价格进行售卖
业界有多种开源规则引擎,如Aviator、Drools、QLExpress等,不同的规则引擎在功能、性能、学习维护成本上有一定差异,需要根据自己的业务场景来进行选型
业务规则配置例子:
背景:物流能力中心项目中,要计算不同的仓类型、不同的资源类型(人员、场地、物资、车辆等)、不同履约时效的履约能力,每种场景接入的参数都不一样,计算工时也不一样,算法还经常需要调整,如果使用硬编码的方式,要对几十种业务组合编写业务逻辑,工作量大,维护困难
方案:引入规则引擎,实现业务规则可配置,提升开发、维护人效

(3)业务流程可配置
如果不同的业务场景,需要不同的执行流程,可以考虑引入流程配置框架,如:一些业务场景,流程执行顺序为A-->B-->C,另外一些业务场景执行顺序为C-->B-->A,还有一些业务场景执行顺序为B-->A-->C。
注:流程配置框架相对比较复杂,更适合平台/中台建设,其他场景建议谨慎评估后再引入
流程配置框架的核心:流程编排+能力复用(插件化),前提是流程抽象➕流程标准化
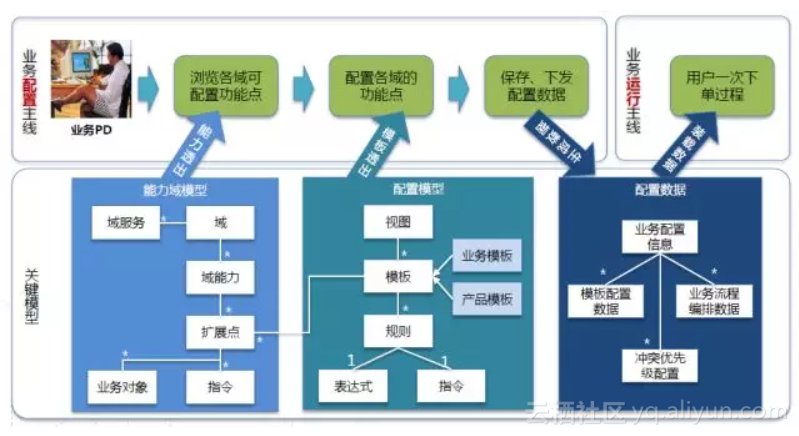
业界流程编排框架:阿里TMF、美团BPF、京东物流batrix
TMF2.0 配置流程:
4、使用规范降低复杂度
本质上,是做好约定,简化思考。如:一个类命名为OrderDao,不需要看代码,就可以很清晰的知道这是一个订单数据处理的类
(1)代码规范
如接口、类、方法等的命名
(2)架构层级规范
系统分层级。上层调用底层,避免底层直接调用上层,同层级尽量避免互相调用
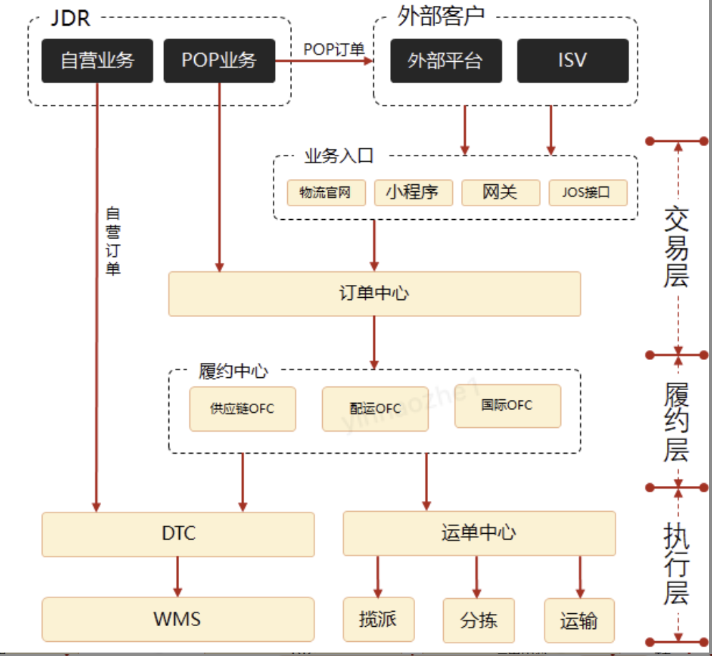
例:物流百川三层架构,定义了系统层级,使系统交互有序
四、业务复杂度优化重构原则
1、小步快跑。每个迭代要能独立交付,保障每次迭代充分验证,更快看到重构效果
2、先写后读。通过双写,验证新模型的可行性;通过数据一致性校验后,再逐步迁移读接口
3、先轻后重。先做简单逻辑再做复杂逻辑。先迁移轻业务,有了经验后,再去迁移更复杂的重业务






