



一、背景介绍
上一篇文章介绍了CDP中,面对单个标签或群体数十亿的数据如何存储CDP技术系列(一):使用bitmap存储数十亿用户的标签或群体
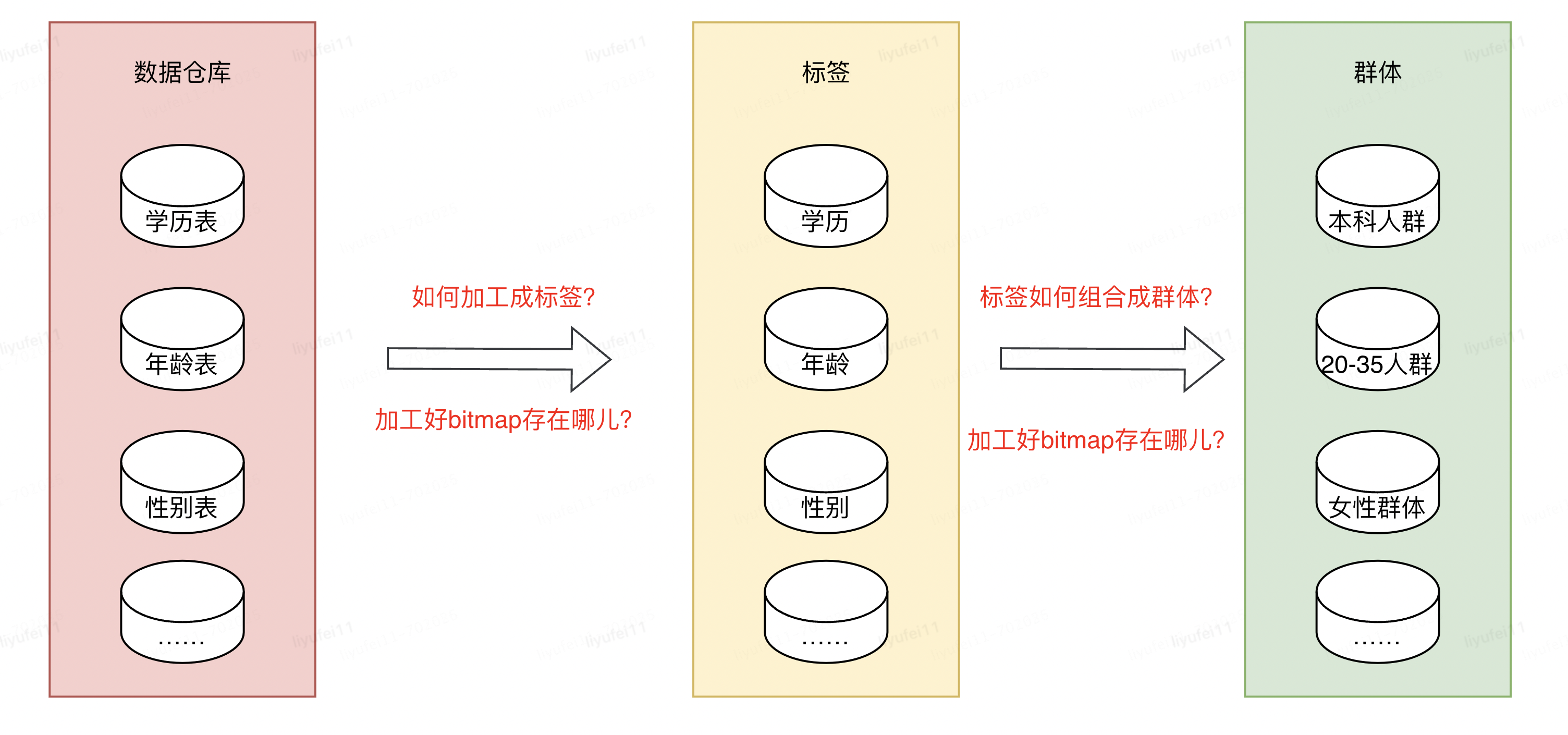
我们都知道数据仓库的概念,它的里边存储了我们所有的数据,其中就包含了标签或群体所依赖的数据,但是这些数据并不能直接拿来使用,想要变成业务需要的标签或群体数据,还需要进行加工。
数据工程师将数仓里的原始数据,经过一些列的数据作业加工成业务用户需要的源表,比如性别表,学历表,年龄表,购买行为表等等。
有了这些相对规整的源表,接下来就是如何利用这些表,去组合成我们需要的群体,然后通过群体再去做营销,推广等。
本篇要讨论的主要就是使用什么方式快速圈选出人群。
二、问题描述
上文已经讲到有了标签的存储方式和源表,并且当前CDP平台已经有几千+标签,2W+群体,这其中涉及到的源表会非常多且大。
我们遇到的第一个问题,是如何将这么多张源表,加工成对应标签的bitmap?
第二个问题,加工好这些bitmap文件之后,存储在什么地方才能方便后续的使用?
第三个问题,存储好这些标签的bitmap之后,如何快速的进行组合计算,加工成用户需要的群体?
比如我有三个标签:学历,年龄和性别,如何圈出:具有本科学历的,年龄在20到35岁之间的女性群体。
三、解决方案
1)ClickHouse简介
针对以上问题,我们使用了ClickHouse(以下简称CK),一个由俄罗斯Yandex在2016年年开源的⾼性能分析型SQL数据库,是一个用于联机分析处理(OLAP)的列式数据库管理系统(columnar DBMS)。
它具有以下特点:
1、完备的数据库管理功能,包括DML(数据操作语言)、DDL(数据定义语言)、权限控制、数据备份与恢复、分布式计算和管理。
2、列式存储与数据压缩: 数据按列存储,在按列聚合的场景下,可有效减少查询时所需扫描的数据量。同时,按列存储数据对数据压缩有天然的友好性(列数据的同类性),降低网络传输和磁盘 IO 的压力。
3、关系模型与SQL: ClickHouse使用关系模型描述数据并提供了传统数据库的概念(数据库、表、视图和函数等)。与此同时,使用标准SQL作为查询语言,使得它更容易理解和学习,并轻松与第三方系统集成。
4、数据分片与分布式查询: 将数据横向切分,分布到集群内各个服务器节点进行存储。与此同时,可将数据的查询计算下推至各个节点并行执行,提高查询速度。
更多特性可查看官方文档:https://clickhouse.com/docs/zh/introduction/distinctive-features
还可以查看同事的这篇文章:京东科技百亿级用户画像平台的探索和实践,这一次全部都讲清楚了
除了上文CK的特性之外,它还具有分析数据高性能,开发流程简便,开源社区活跃度高,并且支持压缩位图等优势。
有了这些之后,就可以利用它的这些特性和优势,来解决上文提出的问题。
2)解决数据存储问题
针对数据存储问题,其实包含两个方面:一个是源数据的存储,另一个是标签群体bitmap的数据存储。
由上文可以看出,当前数据源表存储在数仓中,但是处在它之上的查询和管理工具,比如hive,spark,presto等,并不能满足我们的计算需求。行式存储示例:
| Row | user_id | 学历 | 年龄 | 性别 |
| #0 | id1 | 本科 | 24 | 女 |
| #1 | id2 | 本科 | 25 | 男 |
| #2 | id3 | 硕士 | 26 | 女 |
| #3 | id4 | 硕士 | 27 | 男 |
CK在列式存储与数据压缩方面的优势是我们选择它的原因,它被设计成可以工作在传统磁盘上,能提供每GB更低的存储成本,并且如果可以使用SSD和内存,它也会合理的利用这些资源。列式存储示例:
| Row: | #0 | #1 | #2 | #3 |
| user_id | id1 | id2 | id3 | id4 |
| 学历 | 本科 | 本科 | 硕士 | 硕士 |
| 年龄 | 20-24 | 20-24 | 25-28 | 25-28 |
| 性别 | 女 | 男 | 女 | 男 |
| offset | 1 | 2 | 3 | 4 |
为什么列式存储查询更有效率,主要包含以下方面:
- 针对分析类查询,通常只需要读取表的一小部分列。在列式数据库中可以只读取需要的数据。
- 由于数据总是打包成批量读取的,所以压缩是非常容易的。同时数据按列分别存储这也更容易压缩。这进一步降低了I/O的体量。
- 由于I/O的降低,这将帮助更多的数据被系统缓存。
- 由于执行一个查询需要处理大量的行,因此在整个向量上执行所有操作将比在每一行上执行所有操作更加高效。
针对第二个问题bitmap数据存储,CK本身并没有这种类型,而是通过参数化的数据类型AggregateFunction(name, types_of_arguments…)来实现,建表示例:
CREATE
TABLE cdp.tag ON CLUSTER DEFAULT
(
`code` String,
`value` String,
`version` String,
`offset_bitmap` AggregateFunction(groupBitmap, UInt64)
)
ENGINE = ReplicatedMergeTree
(
'/clickhouse/tables/cdp/{shard}/group_1',
'{replica}'
)
PARTITION BY(code)
ORDER BY(code)
SETTINGS storage_policy = 'default',
use_minimalistic_part_header_in_zookeeper = 1,
index_granularity = 8192;
这样,源数据和加工后的bitmap都可以存储在CK中,当然,数据由数仓推送到CK中还需要数据管道提供支持。
3)解决bitmap加工问题
源数据和准备好之后,则是如何将源表的数据加工成标签的bitmap,这方面CK拥有非常多的bitmap函数支持,可以参考:https://clickhouse.com/docs/en/sql-reference/functions/bitmap-functions
在上文的列式存储表数据中,多了一行id对应的offset,这些offset可以在数据推送过程中写入。假设表名为tag.source,如果想生成三个标签的bitmap,则可参考如下语句:
# 学历标签
INSERT INTO cdp.tag_bitmap1
SELECT
'tag_education' AS code,
value AS value,
'version1' AS version,
groupBitmapState(offset) AS offset_bitmap
FROM
tag.source
WHERE
value IN('本科','硕士')
GROUP BY
code,
value
# 年龄标签
INSERT INTO cdp.tag_bitmap2
SELECT
'tag_age' AS code,
value AS value,
'version2' AS version,
groupBitmapState(offset) AS offset_bitmap
FROM
tag.source
WHERE
value IN('20-24','25-28')
GROUP BY
code,
value
# 性别标签
INSERT INTO cdp.tag_bitmap3
SELECT
'tag_gender' AS code,
value AS value,
'version3' AS version,
groupBitmapState(offset) AS offset_bitmap
FROM
tag.source
WHERE
value IN('男','女')
GROUP BY
code,
value
有了三个标签之后,即可计算出上文中想创建的,本科学历的20-35岁的女性群体:
WITH
(
SELECT
groupBitmapOrStateOrDefault(offset_bitmap)
FROM
(
SELECT offset_bitmap FROM cdp.tag_bitmap1 WHERE value IN ('本科')
)
) AS `bitmap1`,
(
SELECT
groupBitmapOrStateOrDefault(offset_bitmap)
FROM
(
SELECT offset_bitmap FROM cdp.tag_bitmap2 WHERE value IN('20-24', '25-28')
)
) AS `bitmap2`,
(
SELECT
groupBitmapOrStateOrDefault(offset_bitmap)
FROM
(
SELECT offset_bitmap FROM cdp.tag_bitmap3 WHERE value IN('女')
)
) AS `bitmap3`
SELECT bitmapAnd(bitmapAnd(`bitmap1`, `bitmap2`), `bitmap3`) AS bitmap
4)解决快速加工问题
解决了数据存储和加工问题之后,还有一个待考虑的问题,源表中的数据量过大,导致出现bitmap加工耗时过长,甚至出现加工超时的情况。
为了应对这个问题,可以采用分布式多分片的方式部署CK,每个分片保证至少有2个主备节点,来达到高性能、高可用。分片和节点之间通过Zookeeper来保存元数据,以及互相通信。这样CK本身是对Zookeeper强依赖的,所以还需要部署一个3节点的高可用Zookeeper集群。

集群的配置可以在系统表system.clusters中查询:

上文CK部署架构图中引入了分布式表和本地表:
分布式表:是逻辑上的表、可以理解为视图。比如要查一张表的全量数据,可以查询分布式表,在执行时请求会分发到每一个节点,等所有节点都执行结束,再在某一个节点上汇总到一起,因此会对单节点造成压力。
本地表:每个节点的实际存储数据的表,本地表每个节点都要创建,CK通常是会按自己的策略把数据平均写到每一个节点的本地表,本地数据本地计算,最后再把所有节点的结果汇总到一起。
由于使用分布式表可能造成单节点的压力,所以我们可以在应用里,通过JDBC在每个节点执行SQL得到想要的结果后,再在应用内进行聚合。不过,要注意的是像平均值这样的计算,只能是通过先求SUM再求COUNT来实现,直接使用平均值函数会得到错误的结果。
四、现状及展望
当前CDP中所有的标签和群体最新版本均存储在CK中,也就是说所有的标签和群体的组合默认使用的均是最新版本。
这其实也是为什么经常有用户问,我的群体之前加工成功,今天加工失败了,还能用吗?答案是肯定的,就是因为我们默认使用的是群体加工成功的最新版本。
参考文章:京东科技百亿级用户画像平台的探索和实践,这一次全部都讲清楚了
中文CK文档:https://clickhouse.com/docs/zh
英文CK文档:https://clickhouse.com/docs/en/intro






