



一、统计流程
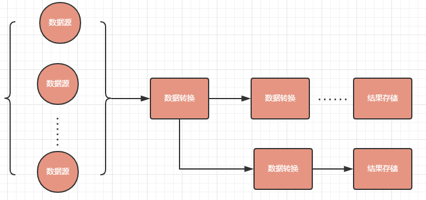
所有流计算统计的流程都是:
1、接入数据源
2、进行多次数据转换操作(过滤、拆分、聚合计算等)
3、计算结果的存储
其中数据源可以是多个、数据转换的节点处理完数据可以发送到一个和多个下一个节点继续处理数据
Flink程序构建的基本单元是stream和transformation(DataSet实质上也是stream)。stream是一个中间结果数据,transformation对数据的加工和操作,该操作以一个或多个stream为输入,计算输出一个或多个stream为结果,最后可以sink来存储数据。

包括数据源,每一次发射出来的数据结果都通过DataStream来传递给下一级继续处理
每一个Transformation要有2步:
1、处理数据
2、将处理完的数据发射出去
二、Flink的数据源
Flink提供数据源只需要实现SourceFunction接口即可。
SourceFunction有一个抽象实现类RichParallelSourceFunction
继承该实现类,实现3个方法,既可以自定义Source
public void open(Configuration parameters) //初始化时调用,可以初始化一些参数
public void run(SourceContext<T> ctx)//发送数据
在该方法里调用ctx的collect方法将数据发射出去。
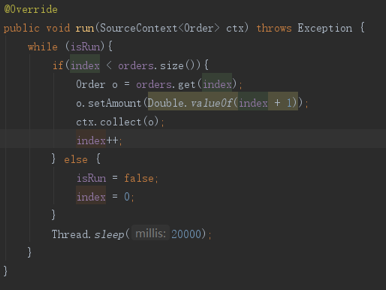
该例子中是每20秒发送出去一个Order类型的实体。
三、Flink的数据转换操作
Flink针对于不同的场景提供了不同的解决方案,减少了用户去关注处理过程中的效率问题。
常见的操作有下面这些:�“map”就是做一些映射,比如我们把两个字符串合并成一个字符串,把一个字符串拆成两个或者三个字符串。
“flatMap”类似于把一个记录拆分成两条、三条、甚至是四条记录,例如把一个字符串分割成一个字符数组。
“Filter”就类似于过滤。
“keyBy”就等效于SQL里的group by。
“aggregate”是一个聚合操作,如计数、求和、求平均等。
“reduce”就类似于MapReduce里的reduce。
“join”操作就有点类似于我们数据库里面的join。
“connect”实现把两个流连成一个流。
“repartition”是一个重新分区操作(还没研究)。
“project”操作就类似于SQL里面的snacks(还没研究)。
常见的操作有filter、map、flatMap、keyBy(分组)、aggregate(聚合)
具体的使用方式后面的例子中会体现。
三、窗口
流数据的计算可以把连续不断的数据按照一定的规则拆分成大量的片段,在片段内进行统计和计算。比如可以把一小时内的数据保存到一个小的数据库表里,然后对这部分数据进行计算和统计,而流计算只不过是实时进行的。
常见的窗口有:
1、以时间为单位的Time Window,例如:每1秒钟、每1个小时等
2、以数据的数量为单位的Count Window,例如:每一百个元素
Flink给我们提供了一些通用的时间窗口模型。
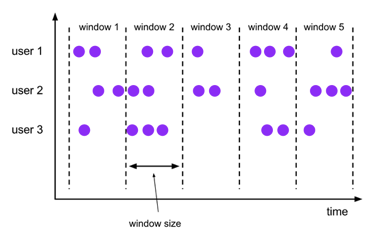
1、Tumbling Windows(不重叠的)
数据流中的每一条数据仅属于一个窗口。每一个都有固定的大小,同时窗口间彼此之间不会出现重叠的部分。如果指定一个大小为5分钟的tumbling窗口,那么每5分钟便会启动一个窗口,如下图所示:
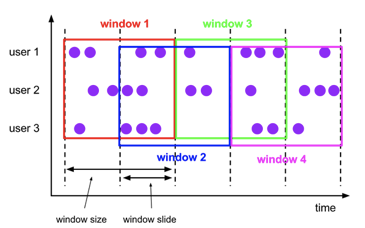
2、Sliding Windows(重叠的)
与Tumbling窗口不同的是,在构建Sliding窗口时不仅需要指定窗口大小,还会指定一个窗口滑动参数(window slide parameter)来确定窗口的开始位置。因此当窗口滑动参数小于窗口大小时,窗口之间可能会出现重复的区域。
例如,当你指定窗口大小为10分钟,滑动参数为5分钟时,如下图所示:
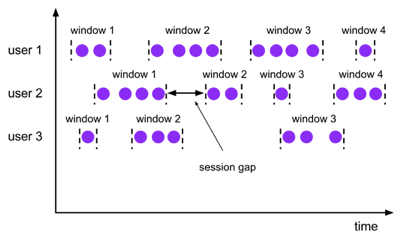
3、Session Windows (会话窗口)
当数据流中一段时间没有数据,则Session窗口会关闭。因此,Session Windows没有固定的大小,无法计算Session窗口的开始位置。
四、Flink中的时间概念
Flink中有3中不同的时间概念
- 处理时间 Processing Time指的是我们上面进行Transformation操作时,当时的系统时间。
- 事件时间 Event Time指的是业务发生时间,每一条业务记录上会携带一个时间戳,我们需要指定数据中那一个属性中获取。在按业务发生时间统计数据时,我们面临一个问题,当我们接收的数据的时间是无序的时候,我们什么时间去触发聚合计算,我们不可能无限制的等待。Flink引入了Watermark的概念,这个Watermark是添加在窗口上的,是告诉窗口我们最长等待的时间是多久,超过这个时间的数据就抛弃不再处理。
- 提取时间 Ingestion Time指的是数据进入Flink当时的系统时间。
五、订单统计的例子

第四步:设置时间戳和Watermarks
DataStream<Order> marksSource = vilidatedSource
.assignTimestampsAndWatermarks(
new BoundedOutOfOrdernessTimestampExtractor<Order>(Time.minutes(1)){
@Override
public long extractTimestamp(Order o) {
return o.getTimestamp().getTime();
}
});
前面已经设置了使用EventTime来处理数据,那么在进行时间窗口计算前必须给数据分配获取时间戳的字段,这里设置了Order的timestamp字段为EventTime,同时这里也设置了一个1分钟的Watermarks,表示最多等待1分钟,业务发生时间超过系统时间1分钟的数据都不进行统计。
第五步:数据分组
KeyedStream<Order, Tuple> keyedStream =
marksSource.keyBy("biz");//先以biz来Group
这里设置了以Order中biz字段进行分组,这就意味着所有biz相同的数据会进入到同一个时间窗口中进行计算。
第六步:指定时间窗口、聚合计算
DataStream<List<Tuple2<String, String>>> results = keyedStream
.window(TumblingEventTimeWindows.of(Time.minutes(1)))
.aggregate(new OrderSumAggregator()).setParallelism(1);
这里设置了一个以1分钟为单位的不重叠的TumblingEventTimeWindow。
然后使用OrderSumAggregator来进行聚合计算。
需要注意的是如果最前面设置的是使用ProcessTime来处理数据,这里的窗口就会变成TumblingProcessTimeWinwow,前后必须一一对应,之前就因为前后不对应,统计结果不正确一直招不到原因。
六、聚合计算
上面例子中比较核心的部分就是聚合计算,也就是我们的OrderSumAggregator
聚合计算我们只需要实现Flink给我们提供的AggregateFunction接口,重写其方法即可。
ACC createAccumulator();//创建一个数据统计的容器,提供给后续操作使用。
ACC add(IN in, ACC acc);//每个元素被添加进窗口的时候调用。
第一个参数是添加进窗口的元素,第二个参数是统计的容器(上面创建的那个)。
OUT getResult(ACC acc);//窗口统计事件触发时调用来返回出统计的结果。
ACC merge(ACC acc1, ACC acc2);//只有在当窗口合并的时候调用,合并2个容器
其中这个容器根据情况也可以是在内存里提供,也可以是在其他存储设备中提供。
通过上面的例子我们就实现了按照业务时间来统计每分钟内的订单数量,订单最多可以延迟1分钟上报。
但是我们为了等待1分钟内上报的数据,造成了数据会延迟1分钟进行统计,例如8点02分我们才能统计到8点到8点01分上报的数据。
为了解决这个问题,我们可以给window再增加一个自定义的统计触发器,这个触发器可以在整点触发统计事件(也就是调用上面的getResults方法),这样就达到了8点到8点01分这个时间段的数据,在8点01分统计一次,在8点02分再重新统计一次(加上后面1分钟上报的数据)。





