您好!
欢迎来到京东云开发者社区
登录
首页
博文
课程
大赛
工具
用户中心
开源
首页
博文
课程
大赛
工具
开源
更多
用户中心
开发者社区
>
博文
>
深入理解树状数组
分享
打开微信扫码分享
点击前往QQ分享
点击前往微博分享
点击复制链接
深入理解树状数组
wy****
2023-10-07
IP归属:北京
803浏览
#### 树状数组 树状数组(BIT, Binary Indexed Tree)是简洁优美的数据结构,它能在很少的代码量下支持 **单点修改** 和 **区间查询**,我们先以 `a[] {1, 2, 3, 4, 5, 6}` 数组为例建立树状数组看一下树状数组的样子: 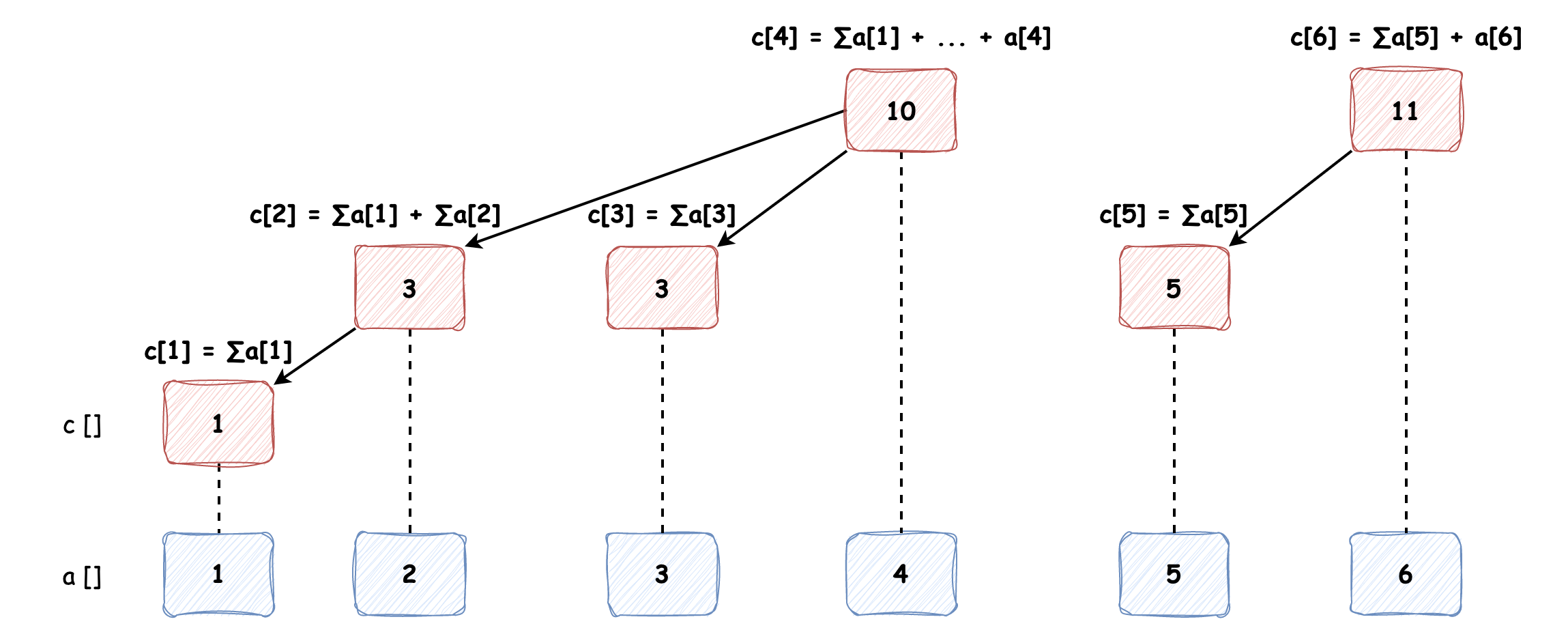 可以发现:不是所有节点都是连接在一起的,c\[1\], c\[2\], c\[3\], c\[4\] 和 c\[5\], c\[6\] 分别构成了两棵树;奇数索引位置的节点只管辖一个数组元素(我们例子中以 1 为起始索引)。那么这个树状数组是怎么计算和推导出来的呢? #### 管辖的区间 树状数组的每个元素会管辖多少个数组元素?也就是说每个元素的区间长度是多少?我们从上图中已经知道了奇数的树状数组元素只管辖一个元素,区间为 c\[x\] = \[x, x\],那么我们只需再研究下偶数元素管辖的区间长度即可。 * c\[y\] 所管辖的区间长度为 2<sup>k</sup> ,其中 k 为 y 的 2 进制表示中最低位 1 后面所有 0 的数量;c\[y\] 所管辖的区间为:\[y - 2<sup>k</sup> + 1, y\] 我们以 c\[4\] 为例,它管辖多少个元素呢?4 的 2 进制表示为 0100,最低位 1 后面 0 的数量为 2,即 k = 2,那么 2<sup>k</sup> = 2<sup>2</sup> = 4,所以它管辖的区间长度为 4,也就是 4 个数组元素,区间为 \[4 - 4 + 1, 4\] = \[1, 4\]。 #### 父节点是谁? 现在我们知道每个元素所管辖的区间范围了,那么我们怎么才能知道它的父节点是谁呢?就比如说我们现在得到了 c\[1\] 元素,我们想知道它的父节点,要怎么计算呢? * c\[x\] 的父节点为 c\[x + lowbit(x)\] 怎么回事?其中的 **lowbit(x)** 是什么东西?其实它的值和 2<sup>k</sup> 一致,**其中 k 为 x 的 2 进制表示中最低位 1 后面所有 0 的数量**,熟悉不熟悉?这个 lowbit(x) 和我们上文中计算该元素所管辖区间长度的值一致!这不就简单了! * lowbit(x) 的计算方法:lowbit(x) = x & -x 我们以计算 c\[2\] 为例,lowbit(2) = 2 & -2,其中 2 的 2 进制表示为 0010,-2 的 2 进行表示为 1110,它的计算方法为将 2 的所有非符号位二进制全部取反后再加 1,即 1101 + 1 = 1110,执行 & 运算后结果为 0010,十进制表示为 2,与 2<sup>1</sup> 值一致。lowbit 的计算用代码表示为: ```java int lowbit(int x) { return x & -x; } ``` 我们以 c\[1\] 节点为例计算下它的父节点是谁,lowbit(1) = 1 & -1 = 0001 & 1111 = 0001 = 1,那么它的父节点为 c\[1 + 1\] = c\[2\],与图上表示的一致。 --- 现在我们已经知道如何通过计算来创建树状数组了, 接下来我们要看下它的应用。 #### 区间查询 区间查询我们先讨论计算前 N 项和的方法,比如我们现在要查询前 6 项和,我们来看下它查询的过程: * 从 c\[6\] 开始找子节点,有 c\[6\] 管辖的区间为 \[5, 6\],那么再往下找需要找 c\[4\],它的区间为 \[1, 4\],计算这两个节点的和即可。 那么从 c\[6\] 跳到 c\[4\] 是如何计算出来的呢?我们可以通过 c\[6\] 区间的下界减 1 来得到,转换成公式表示即为 x - lowbit(x) = 6 - 2 = 4,当它跳到 c\[4\] 时发现已经满足求和条件,不再向下跳而结束查找,而且我们可以通过计算 4 - lowbit(4) = 4 - 4 = 0 ,可以发现当 x - lowbit(x) = 0 时为结束查找的条件。我们用代码来表示为: ```java int query(int x) { int res = 0; for (int i = x; i > 0; i -= lowbit(i)) { res += c[i]; } return res; } ``` 那么我们计算区间 \[3, 6\] 的和该如何计算呢?我们从图中可以发现,先计算出\[1, 6\] 和 \[1, 2\] 的和,再使用前者减去后者即为所得,用代码表示为: ```java int query(int left, int right) { return query(right) - query(left - 1); } ``` #### 单点修改 如果我们要修改 a\[x\] 的值,我们仅需要修改所有管辖了 a\[x\] 的 c\[y\] 即可,而 a\[x\] 可能会被多个 c\[y\] 管辖,这些所有的 c\[y\] 节点该如何确定呢?我们可以回头再去看看前面的树状数组配图,比如我们要修改 a\[1\] 的值,那么我们需要修改 c\[1\], c\[2\] 和 c\[4\] ,能不能发现它是在不断的 **跳父节点** 修改?所以,**如果我们要修改数组中某个元素的值,树状数组的更新则是不断地更新父节点值**。好,我们直接上代码吧: ```java // 将 index 索引处的值更新为 num void update(int index, int num) { a[index] = num; add(index, num - a[index]); } // 更新 c[index] 的值,变化差值为 val void add(int index, int val) { for (int i = index; i <= c.length; i += lowbit(i)) { c[i] += val; } } ``` #### 建树 好了,区间查询和单点修改我们都讲完了,但是从头到尾我们还没说过树状数组是怎么建立的呢。我们可以想一下,c 数组初始化时每个索引处的值都为 0,建树仅需要将 a 数组中所有值都在树状数组中执行单点修改即可: ```java public BinaryIndexedTree(int[] a) { this.a = a; this.c = new int[a.length + 1]; for (int i = 0; i < a.length; i++) { add(i + 1, a[i]); } } ``` 到这里我们基本上已经将树状数组讲解完毕了,它的全量代码如下: ```java public class BinaryIndexedTree { int[] a; int[] c; public BinaryIndexedTree(int[] a) { this.a = a; this.c = new int[a.length + 1]; for (int i = 0; i < a.length; i++) { add(i + 1, a[i]); } } // 将 index 索引处的值更新为 num void update(int index, int num) { a[index] = num; add(index, num - a[index]); } // 更新 c[index] 的值,变化差值为 val void add(int index, int val) { for (int i = index; i < c.length; i += lowbit(i)) { c[i] += val; } } int query(int left, int right) { return query(right) - query(left - 1); } // 查询前缀和的方法 int query(int x) { int res = 0; for (int i = x; i > 0; i -= lowbit(i)) { res += c[i]; } return res; } int lowbit(int x) { return x & -x; } } ``` --- #### 巨人的肩膀 * [树状数组(简单介绍)](https://blog.csdn.net/qq_40941722/article/details/104406126) * [负数的二进制表示方法(正数:原码、负数:补码)](https://www.cnblogs.com/andy-0212/p/10323502.html) * [树状数组](https://oi-wiki.org/ds/fenwick/) * [算法学习笔记(2) : 树状数组](https://zhuanlan.zhihu.com/p/93795692) * [维基百科 - 树状数组](https://zh.wikipedia.org/zh-cn/%E6%A0%91%E7%8A%B6%E6%95%B0%E7%BB%84) * [关于各类「区间和」问题如何选择解决方案(含模板)](https://leetcode.cn/problems/range-sum-query-mutable/solutions/632515/guan-yu-ge-lei-qu-jian-he-wen-ti-ru-he-x-41hv/) * [算法学习笔记(19): 离散化](https://zhuanlan.zhihu.com/p/112497527)
上一篇:分布式事务:XA和Seata的XA模式
下一篇:以效率为导向:用ChatGPT和HttpRunner实现敏捷自动化测试(二)
wy****
文章数
47
阅读量
43283
作者其他文章
01
用“分区”来面对超大数据集和超大吞吐量
1. 为什么要分区?分区(partitions) 也被称为 分片(sharding),通常采用对数据进行分区的方式来增加系统的 可伸缩性,以此来面对非常大的数据集或非常高的吞吐量,避免出现热点。分区通常和复制结合使用,使得每个分区的副本存储在多个节点上,保证数据副本的 高可用。如下图所示,如果数据库被分区,每个分区都有一个主库。不同分区的主库可能在不同的节点上,每个节点可能是某些分区的主库,同时是
01
深入理解分布式共识算法 Raft
“不可靠的网络”、“不稳定的时钟”和“节点的故障”都是在分布式系统中常见的问题,在文章开始前,我们先来看一下:如果在分布式系统中网络不可靠会发生什么样的问题。有以下 3 个服务构成的分布式集群,并在 server_1 中发生写请求变更 A = 1,“正常情况下” server_1 将 A 值同步给 server_2 和 server_3,保证集群的数据一致性:但是如果在数据变更时发生网络问题(延迟
01
缓存之美:从根上理解 ConcurrentHashMap
本文将详细介绍 ConcurrentHashMap 构造方法、添加值方法和扩容操作等源码实现。ConcurrentHashMap 是线程安全的哈希表,此哈希表的设计主要目的是在最小化更新操作对哈希表的占用,以保持并发可读性,次要目的是保持空间消耗与 HashMap 相同或更好,并支持利用多线程在空表上高效地插入初始值。在 Java 8 及之后的版本,使用 CAS 操作、 synchronized
01
缓存之美:万文详解 Caffeine 实现原理(上)
由于神灯社区最大字数限制,本文章将分为两篇,第二篇文章为缓存之美:万文详解 Caffeine 实现原理(下)文章将采用“总-分-总”的结构对配置固定大小元素驱逐策略的 Caffeine 缓存进行介绍,首先会讲解它的实现原理,在大家对它有一个概念之后再深入具体源码的细节之中,理解它的设计理念,从中能学习到用于统计元素访问频率的 Count-Min Sketch 数据结构、理解内存屏障和如何避免缓存伪
wy****
文章数
47
阅读量
43283
作者其他文章
01
用“分区”来面对超大数据集和超大吞吐量
01
深入理解分布式共识算法 Raft
01
缓存之美:从根上理解 ConcurrentHashMap
01
缓存之美:万文详解 Caffeine 实现原理(上)
添加企业微信
获取1V1专业服务
扫码关注
京东云开发者公众号




 wy****
wy**** 2023-10-07
2023-10-07 803浏览
803浏览






