您好!
欢迎来到京东云开发者社区
登录
首页
博文
课程
大赛
工具
用户中心
开源
首页
博文
课程
大赛
工具
开源
更多
用户中心
开发者社区
>
博文
>
分布式事务:XA和Seata的XA模式
分享
打开微信扫码分享
点击前往QQ分享
点击前往微博分享
点击复制链接
分布式事务:XA和Seata的XA模式
wy****
2023-10-07
IP归属:北京
818浏览
上一篇内容[《从2PC和容错共识算法讨论zookeeper中的Create请求》](http://jagile.jd.com/shendeng/article/detail/15436)介绍了保证分布式事务提交的两阶段提交协议,而XA是针对两阶段提交提出的接口实现标准,本文则对XA进行介绍。 ### 1\. XA **XA (eXtended Architecture 扩展架构)** 是 **X/Open组织** 提出的 **跨异构技术实现两阶段提交** 的接口标准。 > 分布式事务包含两种类型:**数据库内部的分布式事务**,在这种情况下,所有参与事务的节点都运行相同的数据库软件;**异构分布式事务**,参与者由两种或两种以上的不同数据库软件组成。 它于 1991 年推出并得到了广泛的实现:许多传统关系数据库包括 PostgreSQL、MySQL、DB2、SQL Server 和 Oracle;消息代理包括 ActiveMQ、HornetQ、MSMQ 和 IBM MQ都支持 XA。它不是一个网络协议而是定义了 **事务管理器(Transaction Manager)、应用程序(Application Program)** 和 **资源管理器(Resource Manager)** 之间交互的 **CAPI(Common Application Programming Interface)** 接口标准,如下图所示,但是标准中并没有指明该如何实现,例如在Java EE中,XA使用的是 **Java事务API** (JTA, Java Transaction API)实现的。 > CAPI: 国际标准的通用应用交互接口。 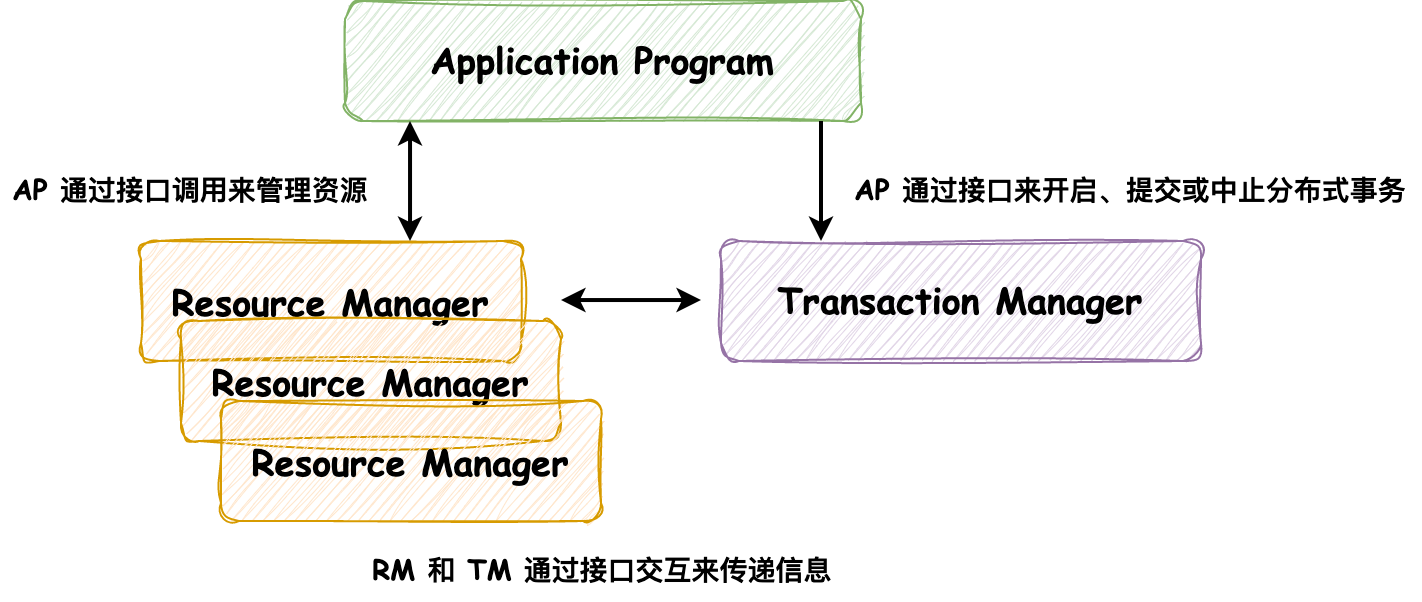 其中三个组件的职责如下: 应用程序(Application Program):负责定义事务的开启、提交或中止,并能够访问事务内的资源(数据库等) 资源管理器(Resource Manager):负责对资源进行管理,相当于两阶段提交中的参与者,能够与事务管理器通过接口交互来传递必要的事务信息 事务管理器(Transaction Manager):负责管理全局事务,分配事务ID,监控事务的执行进度,并负责事务的开启、提交和回滚等,相当于两阶段提交中的协调者 XA同样也分为 **准备阶段** 和 **提交阶段**,它对分布式事务管理的流程如下 * **准备阶段**:AP与TM交互,开启一个 **全局分布式事务**,并发送请求到每个RM,执行数据变更逻辑,此时每个RM会向TM发送请求注册 **分支事务**,在执行完业务逻辑后报告准备提交的状态(事务执行完未提交),之后AP会根据RM的响应在 **提交阶段** 做出反馈 * **提交阶段**:如果所有的RM都回复“是”,表示它们已经准备好提交,那么AP会在该阶段向TM发出提交请求,分布式事务提交;否则,AP会向TM发出中止请求,分布式事务回滚 ### 2\. Seata的XA的模式 Seata中有三个角色 **事务管理器(Transaction Manager)**、**资源管理器(Resource Manager)** 和 **事务协调者(Transaction Coordinator)**。在XA模式下,利用事务资源(数据库、消息服务等)对XA协议的支持,来对分布式事务进行管理。 但是,在Seata中三个角色的定义与XA协议标准中角色的定义有所区别:事务管理器(Transaction Manager)应该对应XA协议中的应用程序(Application Program);事务协调者(Transaction Coordinator)对应XA协议中的事务管理器(Transaction Manager)。我认为它们只是在命名上的区别,为了上下文各名词的统一,避免发生因名词不一致而理解混淆的问题,决定以XA标准协议中的定义进行讲解,**特此强调**。 下图是Seata管理分布式事务的流程图,与第一小节中所述事务流程相同,不再赘述。 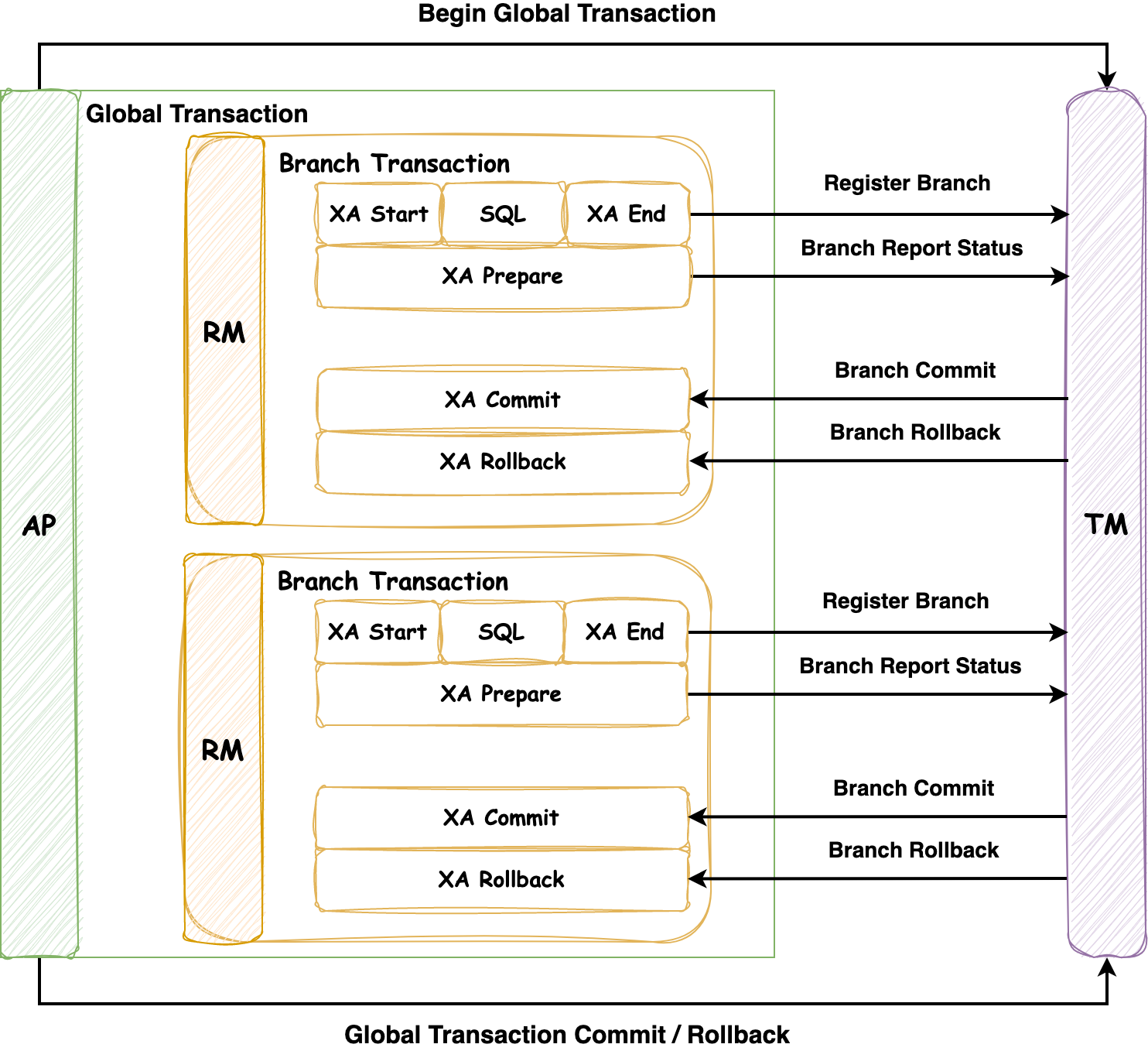 #### 2.1 XA模式实战分析 有了理论基础,我们以商城系统为例进行简单地演示:订单、商品和购物车分别为三个微服务系统,在执行 **下单流程** 时会修改商品库存,生成订单和删除购物车中的商品,业务流程代码如下,注意其中包含事务异常回滚的代码 ```java @GlobalTransactional @Transactional(rollbackFor = Exception.class) public void saveOrder(OrderSaveParam orderSaveParam) { // 参数校验等必要操作 // ... // 校验商品库存和上架状态 checkGoodsStatusAndStock(goodsList, goodsCountMap); // 修改库存 reduceGoodsCount(goodsCountMap); // 生成订单 saveOrder(goodsList, goodsCountMap, orderSaveParam.getAddressId()); // 删除购物车中商品 shoppingCartService.deleteShoppingCartItem(orderSaveParam.getCartItemIds(), SecurityConstants.INNER); // 异常回滚事务 int i = 1 / 0; } ``` 分布式事务执行的 **准备阶段**,流程图如下 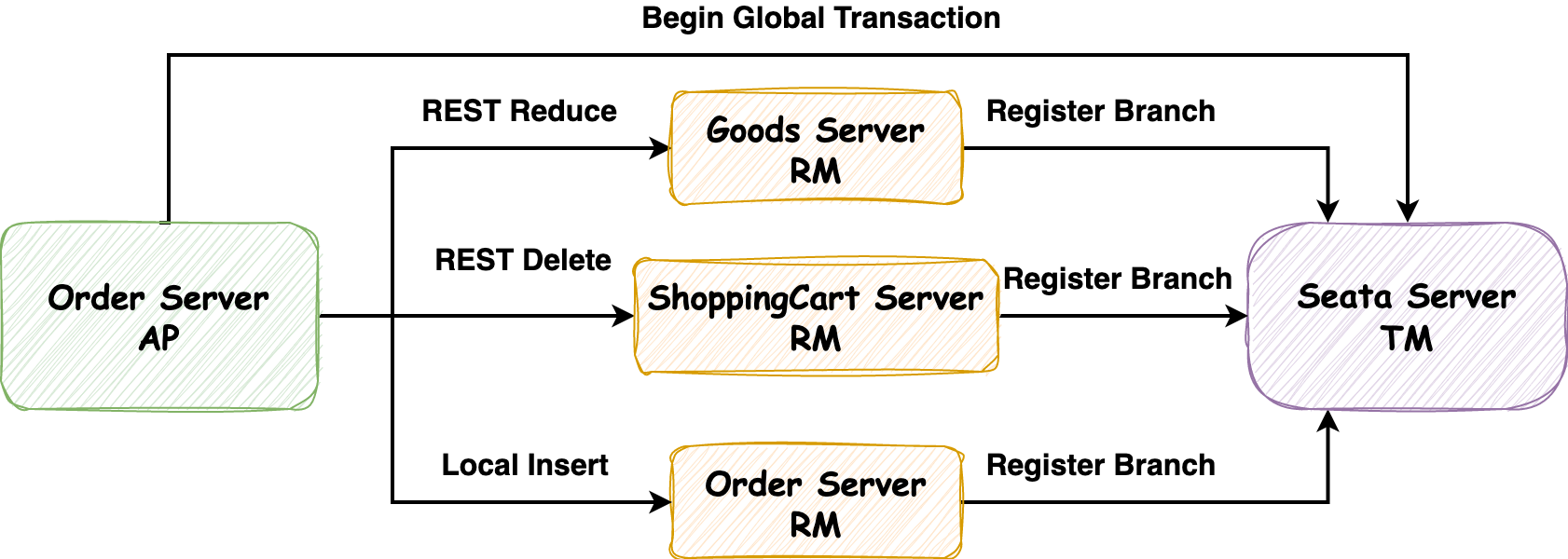 1. Order Server 在创建订单之前,会向 Seata Server(TM) 注册全局事务,并分配事务ID,对应的控制台日志如下 ```bash 2023-06-17 22:07:06.479 INFO 74703 --- [io-29009-exec-2] i.seata.tm.api.DefaultGlobalTransaction : Begin new global transaction [127.0.0.1:8091:36427221250506976] ``` 2. Order Server REST调用 Goods Server 扣减商品数量,Goods Server 在执行数据修改逻辑前会向 Seata Server 注册分支事务,执行完业务逻辑后,并不执行事务提交 3. Order Server REST调用 ShoppingCart Server 删除购物车中的商品,ShoppingCart Server 在执行数据修改逻辑前会向 Seata Server 注册分支事务,执行完业务逻辑后,同样不执行事务提交 4. Order Server 本地执行生成订单和其他逻辑 接下来是分布式事务执行的 **提交阶段**,因生成订单中代码逻辑抛出异常,所以该分布式事务会回滚,OrderServer中对应日志如下 ```bash 2023-06-17 22:07:07.029 INFO 74703 --- [io-29009-exec-2] i.s.rm.datasource.xa.ConnectionProxyXA : 127.0.0.1:8091:36427221250506976-36427221250506978 was rollbacked 2023-06-17 22:07:07.220 INFO 74703 --- [io-29009-exec-2] i.seata.tm.api.DefaultGlobalTransaction : Suspending current transaction, xid = 127.0.0.1:8091:36427221250506976 2023-06-17 22:07:07.220 INFO 74703 --- [io-29009-exec-2] i.seata.tm.api.DefaultGlobalTransaction : [127.0.0.1:8091:36427221250506976] rollback status: Rollbacked ``` 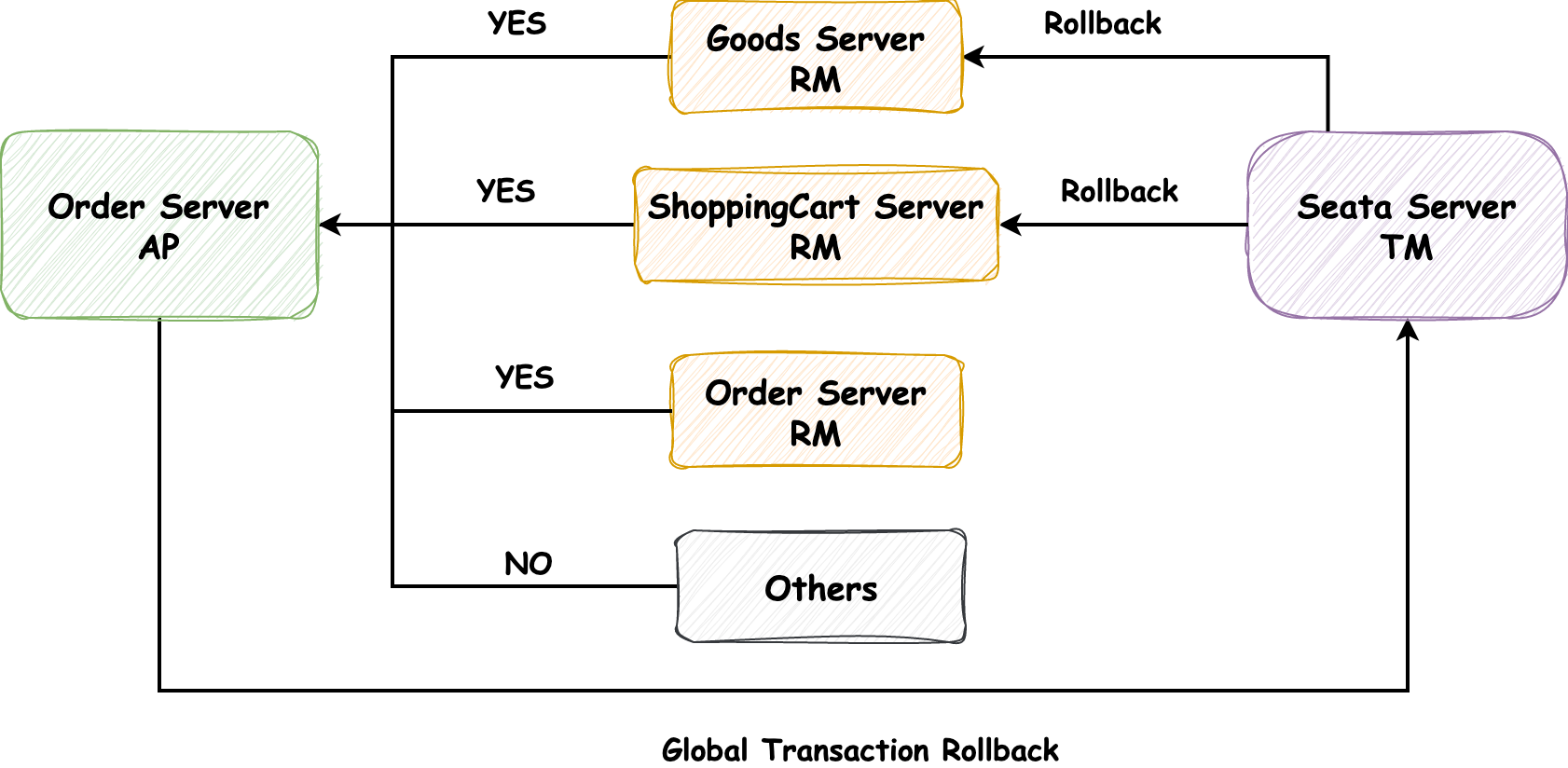 1. Order Server 向 Seata Server 发送 **中止请求**,随后 Seata Server 向 Goods Server 和 ShoppingCart Server 发送 **事务回滚请求** 2. Goods Server 和 ShoppingCart Server 收到事务回滚请求后,将各自注册的分支事务回滚,最终全局分布式事务回滚,以**保证数据的一致性**。Goods Server 分支事务回滚对应的日志如下,可以发现**分支事务的ID为全局事务ID-分支ID**,并显示PhaseTwo\_Rollbacked 在阶段二回滚 ```bash 2023-06-17 22:07:07.081 INFO 74680 --- [h_RMROLE_1_4_24] i.s.c.r.p.c.RmBranchRollbackProcessor : rm handle branch rollback process:xid=127.0.0.1:8091:36427221250506976,branchId=36427221250506986,branchType=XA,resourceId=jdbc:mysql://127.0.0.1:3306/fy_mall_goods,applicationData=null 2023-06-17 22:07:07.081 INFO 74680 --- [h_RMROLE_1_4_24] io.seata.rm.AbstractRMHandler : Branch Rollbacking: 127.0.0.1:8091:36427221250506976 36427221250506986 jdbc:mysql://127.0.0.1:3306/fy_mall_goods 2023-06-17 22:07:07.096 INFO 74680 --- [h_RMROLE_1_4_24] i.s.rm.datasource.xa.ResourceManagerXA : 127.0.0.1:8091:36427221250506976-36427221250506986 was rollbacked 2023-06-17 22:07:07.096 INFO 74680 --- [h_RMROLE_1_4_24] io.seata.rm.AbstractRMHandler : Branch Rollbacked result: PhaseTwo_Rollbacked ``` > 注:如果有朋友想试试Seata的XA模式,可以参考示例代码仓库FangYuan33[/book-spring-cloud](https://github.com/FangYuan33/book-spring-cloud),对应的方法入口为 `/saveOrder` ### 3\. 对XA的思考 XA能够保持多个参与者数据相互一致,但是同时也引入了比较**严重的运维问题**。 因为如果协调者宕机,那么其中已经 **准备但未提交事务** 的所有参与者都会被阻塞。被阻塞的根本是 **锁**,例如在读已提交隔离级别上,数据库事务通常会获取到待修改行数据的 **行级排他锁** 来防止脏写。在分布式事务提交或中止前,参与者数据库不能释放这些锁,因此协调者宕机多久,这些锁就要持有多久(在没有认为干预的情况下)。这些锁被持有的期间,导致其他事务不能修改这些数据(根据数据库的不同,读取操作也可能被阻塞),所以这些数据相关的业务都会被阻塞,导致应用大面积的不可用,直至 **存疑事务** 被解决(提交/中止)。 理论上,如果协调者崩溃并重新启动,它应该从日志中恢复事务的状态,并解决现存的疑虑事务,但是在实际生产中,仍然会有疑虑事务的出现(可能是事务日志被破坏)。也许你可能会考虑将相关应用的数据库服务器重启,但是在2PC正确的实现中,为了 **原子性** 的保证,**重启后也必须持有存疑事务的锁**。那么这样 **唯一的解决方案** 是让管理员手动提交还是回滚事务,这是引入运维问题的所在。不过,许多XA事务的实现都有一个叫做 **启发式决策** 的逃生出口,允许参与者单方面决定提交或放弃一个存疑事务,而无需等待协调者的决定,但是这也正是避免灾难性情况的手段,而不是为了日常的使用,因为这种方式有可能会破坏事务的原子性。 所以,协调者的 **高可用** 是需要我们考虑的问题,它本身也是一种数据库(保存了事务的结果),需要像其他应用数据库服务一样被认真的对待。 --- ### 巨人的肩膀 * 《数据密集型应用系统设计》:第九章 一致性与共识 * [百度百科:XA](https://baike.baidu.com/item/XA/6370881) * [分布式事务之XA方案(Seata实现)](http://www.fblinux.com/?p=2452) * [浅尝分布式事务](https://blog.csdn.net/cxl0921/article/details/76744751) * [Seata官方文档](https://seata.io/zh-cn/docs/dev/mode/xa-mode.html) * [MySQL 中基于 XA 实现的分布式事务](https://blog.csdn.net/wr_java/article/details/120343919) * [还不会分布式事务,seata xa模式入门实战送上](https://blog.csdn.net/w1014074794/article/details/115375716) * 原文收录:[GitHub-Enthusiasm](https://github.com/FangYuan33/enthusiasm)
上一篇:OpenJDK17-JVM源码阅读-ZGC-并发标记
下一篇:深入理解树状数组
wy****
文章数
47
阅读量
43295
作者其他文章
01
用“分区”来面对超大数据集和超大吞吐量
1. 为什么要分区?分区(partitions) 也被称为 分片(sharding),通常采用对数据进行分区的方式来增加系统的 可伸缩性,以此来面对非常大的数据集或非常高的吞吐量,避免出现热点。分区通常和复制结合使用,使得每个分区的副本存储在多个节点上,保证数据副本的 高可用。如下图所示,如果数据库被分区,每个分区都有一个主库。不同分区的主库可能在不同的节点上,每个节点可能是某些分区的主库,同时是
01
深入理解分布式共识算法 Raft
“不可靠的网络”、“不稳定的时钟”和“节点的故障”都是在分布式系统中常见的问题,在文章开始前,我们先来看一下:如果在分布式系统中网络不可靠会发生什么样的问题。有以下 3 个服务构成的分布式集群,并在 server_1 中发生写请求变更 A = 1,“正常情况下” server_1 将 A 值同步给 server_2 和 server_3,保证集群的数据一致性:但是如果在数据变更时发生网络问题(延迟
01
缓存之美:从根上理解 ConcurrentHashMap
本文将详细介绍 ConcurrentHashMap 构造方法、添加值方法和扩容操作等源码实现。ConcurrentHashMap 是线程安全的哈希表,此哈希表的设计主要目的是在最小化更新操作对哈希表的占用,以保持并发可读性,次要目的是保持空间消耗与 HashMap 相同或更好,并支持利用多线程在空表上高效地插入初始值。在 Java 8 及之后的版本,使用 CAS 操作、 synchronized
01
缓存之美:万文详解 Caffeine 实现原理(上)
由于神灯社区最大字数限制,本文章将分为两篇,第二篇文章为缓存之美:万文详解 Caffeine 实现原理(下)文章将采用“总-分-总”的结构对配置固定大小元素驱逐策略的 Caffeine 缓存进行介绍,首先会讲解它的实现原理,在大家对它有一个概念之后再深入具体源码的细节之中,理解它的设计理念,从中能学习到用于统计元素访问频率的 Count-Min Sketch 数据结构、理解内存屏障和如何避免缓存伪
wy****
文章数
47
阅读量
43295
作者其他文章
01
用“分区”来面对超大数据集和超大吞吐量
01
深入理解分布式共识算法 Raft
01
缓存之美:从根上理解 ConcurrentHashMap
01
缓存之美:万文详解 Caffeine 实现原理(上)
添加企业微信
获取1V1专业服务
扫码关注
京东云开发者公众号




 wy****
wy**** 2023-10-07
2023-10-07 818浏览
818浏览






