



前言
ClickHouse是俄罗斯著名搜索引擎公司Yandex开发的一款开源OLAP数据库,由于性能极其优异,即使数十亿上百亿的数据查询都可以秒出结果,因此得到了越来越多全球大厂的青睐。京东智联云基于原生ClickHouse的PaaS产品JCHDB近期发布,对于很多爱好数据库的小伙伴,这是一个很不错的学习平台,可以省去搭建环境的资源消耗和繁琐的配置。本文将从使用者的角度带着大家利用JCHDB来揭开ClickHouse的神秘面纱。
一、创建ClickHouse实例
1、在京东智联云创建ClickHouse非常简单,用户在控制台“云服务”->“数据库与缓存”下选择“分析型云数据库JCHDB”进入实例列表界面,点击“创建”按钮,进入下面界面:
这里我们选最新版本20.0.2.3,下面两个参数比较重要,一个是副本数,一个是分片数,这里我们分别选单副本,2分片,ClickHouse中还有一个分区的概念,这三个名词初学者很容易混淆,我们后面单独讲。
其他参数按照默认值即可,单击创建界面右边“立即购买”按钮即可开始创建实例。
2、几分钟后,控制台实例列表中可以看到创建成功的实例:
3、点击进入实例,可以看到产品提供的功能列表,目前支持查看实例信息,监控(空间/连接数/QPS等),账号管理,节点信息(zk各节点、shard各节点的cpu/内存/空间信息)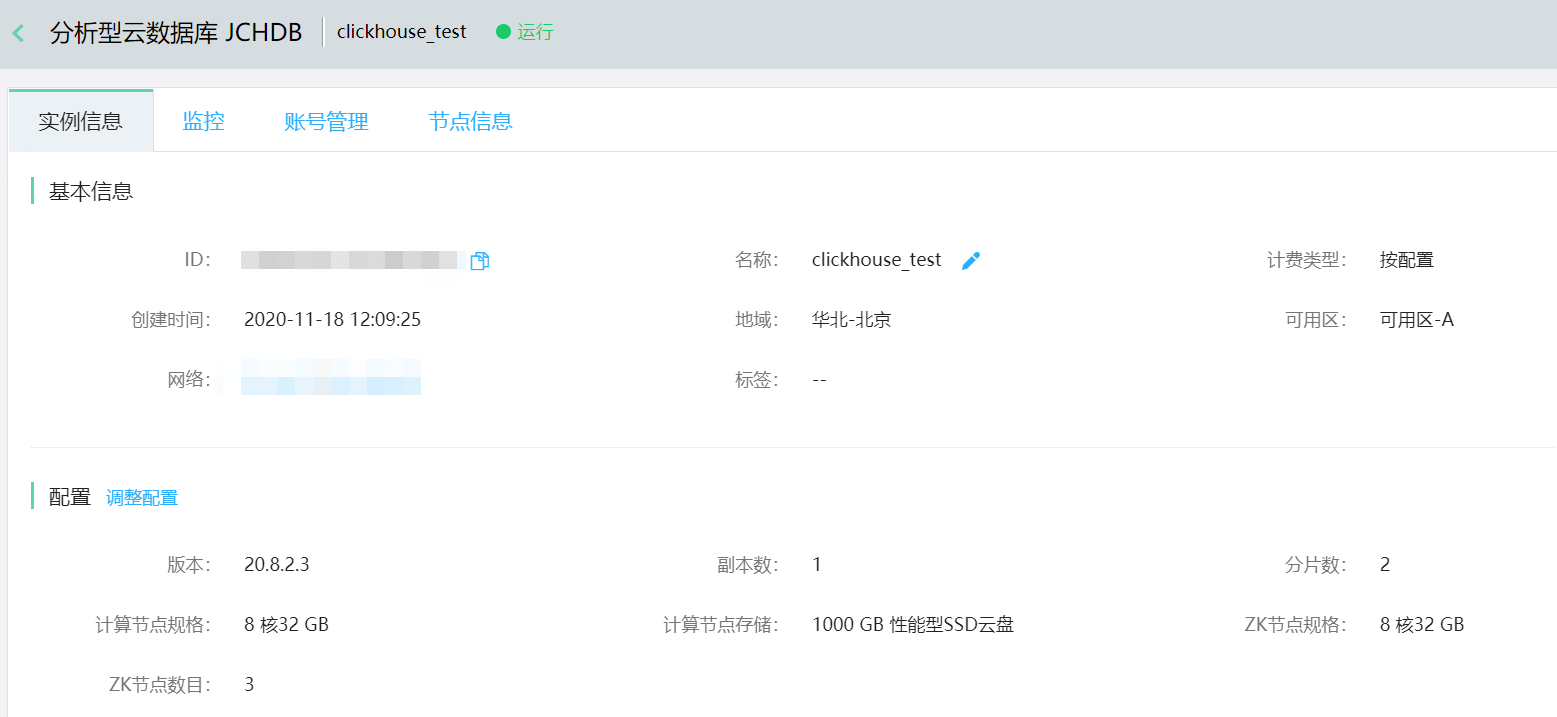
二、连接到ClickHouse
1、找一台内网云主机作为客户端,使用root按照下面步骤安装ClickHouse客户端:
yum install yum-utils
rpm --import https://repo.clickhouse.tech/CLICKHOUSE-KEY.GPG
yum-config-manager --add-repo https://repo.clickhouse.tech/rpm/stable/x86_64
yum install clickhouse-server clickhouse-client
(1)控制台创建数据库测试账号

(2)云主机上使用clickhouse-client命令连接到数据库,hostname和端口参考实例信息:


出现笑脸符号:)即成功登陆clickhouse,熟悉MySQL的同学可以尝试执行show databases/show
tables/show grants/show privileges命令看看,都可以正常执行,clickhouse对MySQL的很多命令都兼容。
三、高性能初体验
1. tcpH工具下载数git clone https://github.com/amosbird/ssb-dbgen.gitcd ssb-dbgenmake
2. 生成测试数据,其中c/l/p/s分别代表customer/lineorder/part/supplier四张测试相关的用户表/订单表/配件表/供应商表
$ ./dbgen -s 100 -T c $ ./dbgen -s 100 -T l $ ./dbgen -s 100 -T p $ ./dbgen -s 100 -T s
3.创建customer/lineorder/part/supplier四张表
CREATE TABLE customer
(
C_CUSTKEY UInt32,
C_NAME String,
C_ADDRESS String,
C_CITY LowCardinality(String),
C_NATION LowCardinality(String),
C_REGION LowCardinality(String),
C_PHONE String,
C_MKTSEGMENT LowCardinality(String)
)
ENGINE = MergeTree ORDER BY (C_CUSTKEY);
CREATE TABLE lineorder
(
LO_ORDERKEY UInt32,
LO_LINENUMBER UInt8,
LO_CUSTKEY UInt32,
LO_PARTKEY UInt32,
LO_SUPPKEY UInt32,
LO_ORDERDATE Date,
LO_ORDERPRIORITY LowCardinality(String),
LO_SHIPPRIORITY UInt8,
LO_QUANTITY UInt8,
LO_EXTENDEDPRICE UInt32,
LO_ORDTOTALPRICE UInt32,
LO_DISCOUNT UInt8,
LO_REVENUE UInt32,
LO_SUPPLYCOST UInt32,
LO_TAX UInt8,
LO_COMMITDATE Date,
LO_SHIPMODE LowCardinality(String)
)
ENGINE = MergeTree PARTITION BY toYear(LO_ORDERDATE) ORDER BY (LO_ORDERDATE, LO_ORDERKEY);
CREATE TABLE part
(
P_PARTKEY UInt32,
P_NAME String,
P_MFGR LowCardinality(String),
P_CATEGORY LowCardinality(String),
P_BRAND LowCardinality(String),
P_COLOR LowCardinality(String),
P_TYPE LowCardinality(String),
P_SIZE UInt8,
P_CONTAINER LowCardinality(String)
)
ENGINE = MergeTree ORDER BY P_PARTKEY;
CREATE TABLE supplier
(
S_SUPPKEY UInt32,
S_NAME String,
S_ADDRESS String,
S_CITY LowCardinality(String),
S_NATION LowCardinality(String),
S_REGION LowCardinality(String),
S_PHONE String
)
ENGINE = MergeTree ORDER BY S_SUPPKEY;
4.加载数据
$ clickhouse-client -h hostname -u --passowrd *** --query "INSERT INTO customer FORMAT CSV" < customer.tbl
$ clickhouse-client -h hostname -u --passowrd *** --query "INSERT INTO part FORMAT CSV" < part.tbl
$ clickhouse-client -h hostname -u --passowrd *** --query "INSERT INTO supplier FORMAT CSV" < supplier.tbl
$ clickhouse-client -h hostname -u --passowrd *** --query "INSERT INTO lineorder FORMAT CSV" < lineorder.tbl
5.将这些表关联,聚合成一个大表
SET max_memory_usage = 20000000000;
SET max_memory_usage = 20000000000, allow_experimental_multiple_joins_emulation = 1;
CREATE TABLE lineorder_flat
ENGINE = MergeTree
PARTITION BY toYear(LO_ORDERDATE)
ORDER BY (LO_ORDERDATE, LO_ORDERKEY) AS
SELECT l.*, c.*, s.*, p.*
FROM lineorder l
ANY INNER JOIN customer c ON (c.C_CUSTKEY = l.LO_CUSTKEY)
ANY INNER JOIN supplier s ON (s.S_SUPPKEY = l.LO_SUPPKEY)
ANY INNER JOIN part p ON (p.P_PARTKEY = l.LO_PARTKEY);
ALTER TABLE lineorder_flat DROP COLUMN C_CUSTKEY, DROP COLUMN S_SUPPKEY, DROP COLUMN P_PARTKEY;
6.终于到激动人心的时候,先看看聚合后的表有多少数据:
SELECT count(1)FROM lineorder_flat
┌───count(1)─┐
│ 1200075804 │
└────────────┘
1 rows in set. Elapsed: 0.012 sec.
12亿多,秒出结果,
7.再来个复杂的:
SELECT sum(LO_REVENUE), toYear(LO_ORDERDATE) AS year, P_BRAND
FROM lineorder_flat
WHERE (P_BRAND >= 'MFGR#2221') AND (P_BRAND <= 'MFGR#2228') AND (S_REGION = 'ASIA')
GROUP BY year, P_BRAND
ORDER BY year ASC, P_BRAND ASC
┌─sum(LO_REVENUE)─┬─year─┬─P_BRAND───┐
│ 132900698876 │ 1992 │ MFGR#2221 │
│ 130846528624 │ 1992 │ MFGR#2222 │
│ 133873545374 │ 1992 │ MFGR#2223 │
│ 128094383868 │ 1992 │ MFGR#2224 │
│ 131489118276 │ 1992 │ MFGR#2225 │
。。。。。。
└─────────────────┴──────┴───────────┘
56 rows in set. Elapsed: 3.918 sec. Processed 1.20 billion rows, 11.17 GB (306.31 million rows/s., 2.85 GB/s.)
最后一行的执行结果显示,SQL执行了3.918秒,处理了10亿多条数据,平均每秒3亿多行/2.85G的处理速度,这种性能大大超出了我们对数据库的传统认知。

上面例子中,在创建测试表时,发现建表sql最后有这么一个字句“ENGINE = MergeTree ORDER BY S_SUPPKEY”。和MySQL类似,ENGINE字句后面需要指定表的存储引擎,ClickHouse目前版本支持6大类20多种存储引擎,其中MergeTree是最重要的一种,类似于MySQL中的InnoDB,其他很多存储引擎都是继承于它。MergeTree从字面理解,是‘合并树’的意思,当MergeTree在写入一批数据时,数据会以数据片段的形式写入磁盘,为了避免片段过多,后台会有一个线程,定期合并这些数据片段,属于一个分区(partition)的片段会合并成一个新的片段,MergeTree的名称由此而来。
一个完整的MergeTree建表语法如下:
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [TTL expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [TTL expr2],
...
INDEX index_name1 expr1 TYPE type1(...) GRANULARITY value1,
INDEX index_name2 expr2 TYPE type2(...) GRANULARITY value2)
ENGINE = MergeTree()
ORDER BY expr
[PARTITION BY expr]
[PRIMARY KEY expr]
[SAMPLE BY expr]
[TTL expr [DELETE|TO DISK 'xxx'|TO VOLUME 'xxx'], ...]
[SETTINGS
name=value, ...]
·
·
·
·
·
create table ttl_table2(id
String,create_time DateTime,code String ) order by id TTL create_time +
interval 10 second;
·
看一个简单例子:
CREATE TABLE t2(
`id` UInt16,
`create_time` Date,
`comment` Nullable(String)
)
ENGINE = MergeTree()
PARTITION BY toYYYYMM(create_time)
PRIMARY KEY (id, create_time)
ORDER BY (id, create_time)
SETTINGS index_granularity = 8192
Ok.
0 rows in set. Elapsed: 0.010 sec.
insert into t2 values(0, '2020-03-20', null);
insert into t2 values(0, '2020-03-20', null);
insert into t2 values(1, '2020-03-21', null);
insert into t2 values(1, '2020-03-21', null);
insert into t2 values(2, '2020-03-22', null);
insert into t2 values(2, '2020-03-23', null);
insert into t2 values(2, '2020-03-24', null);
SELECT *FROM t2
┌─id─┬─create_time─┬─comment─┐
│ 0 │ 2020-03-20 │ ᴺᵁᴸᴸ │
│ 0 │ 2020-03-20 │ ᴺᵁᴸᴸ │
│ 1 │ 2020-03-21 │ ᴺᵁᴸᴸ │
│ 1 │ 2020-03-21 │ ᴺᵁᴸᴸ │
│ 2 │ 2020-03-22 │ ᴺᵁᴸᴸ │
└────┴─────────────┴─────────┘
┌─id─┬─create_time─┬─comment─┐
│ 2 │ 2020-03-23 │ ᴺᵁᴸᴸ │
└────┴─────────────┴─────────┘
┌─id─┬─create_time─┬─comment─┐
│ 2 │ 2020-03-24 │ ᴺᵁᴸᴸ │
└────┴─────────────┴─────────┘
7 rows in set. Elapsed: 0.003
sec.
alter table t2 modify ttl create_time+interval 10 second;
Ok.0 rows in set. Elapsed: 0.012 sec.
10s以后。。。
select * from t2;Ok.0 rows in set. Elapsed: 0.003 sec.
显然,数据符合我们的预期,10s后所有数据都过期,结果为空。
五、MergeTree家族
上面例子中,我们发现MergeTree和其他数据库一个重要的区别是主键可以重复,这在一些场景下可能无法接受。ClickHouse提供了ReplacingMergeTree来解决此类问题。除此之外,ClickHouse还提供了一些其他MergeTree的衍生存储引擎,用来解决一些特殊场景下的存储和性能需求。最常见的包括如下几类:
- ReplacingMergeTree
- SummingMergeTree
- AggregatingMergeTree
- CollapsingMergeTree
- VersionedCollapsingMergeTree
ReplacingMergeTree,指的是如果有记录主键重复,新记录将会替换掉旧记录,类似于MySQL的replace into语句。看下面例子:
CREATE TABLE t_replace
(
`id` UInt16,
`create_time` Date,
`comment` Nullable(String)
)
ENGINE = ReplacingMergeTree()
PARTITION BY toYYYYMM(create_time)
PRIMARY KEY (id, create_time)
ORDER BY (id, create_time)
SETTINGS index_granularity = 8192
Ok.
0 rows in set. Elapsed: 0.008 sec.
insert into t_replace values(0, '2020-03-20', 1);
insert into t_replace values(0, '2020-03-20', 2);
insert into t_replace values(1, '2020-03-21', 1);
insert into t_replace values(1, '2020-03-21', 2);
insert into t_replace values(2, '2020-03-22', null);
insert into t_replace values(2, '2020-03-23', null);
insert into t_replace values(2, '2020-03-24', null);
SELECT *FROM t_replace
┌─id─┬─create_time─┬─comment─┐
│ 0 │ 2020-03-20 │ 2 │
│ 1 │ 2020-03-21 │ 2 │
│ 2 │ 2020-03-22 │ ᴺᵁᴸᴸ │
│ 2 │ 2020-03-23 │ ᴺᵁᴸᴸ │
│ 2 │ 2020-03-24 │ ᴺᵁᴸᴸ │
└────┴─────────────┴─────────┘
5 rows in set. Elapsed: 0.003 sec.
显然,重复的记录只保留了最新两条,符合预期,需要注意的是,有时候会看到表里的数据并未去重,这是因为MergeTree的合并程序需要一段时间才会进行,此时需要手工执行以下优化命令,强制触发文件的合并:
optimize table t_replace;
或
optimize table t_replace final;
由于后台合并进程时间无法估算,且optimize命令在大数据量时较消耗资源,建议查询唯一值的时候还是通过distinct或group by命令去重比较保险。
SummingMergeTree,顾名思义,这个存储引擎用来做sum汇总。经常有这样的场景,需要记录各种明细,但不需要查询明细,而只需要关注明细在某个维度上的汇总。在MergeTree的基础上做group和sum虽然也可以达到类似需求,但在存储和查询开销上都有额外的消耗,SummingMergeTree就是为此而创建的。
--创建SummingMergeTree测试表:
CREATE TABLE t_sum
(
`key` UInt32,
`value` UInt32
)
ENGINE = SummingMergeTree()
ORDER BY key
Ok.
0 rows in set. Elapsed: 0.010 sec.
--插入3条记录
insert into t_sum values(1,1),(1,2),(2,3);
Ok.
3 rows in set. Elapsed: 0.008 sec.
--后台合并前
select * from t_sum;
SELECT *FROM t_sum
┌─key─┬─value─┐
│ 1 │ 1 │
│ 1 │ 2 │
│ 2 │ 3 │
└─────┴───────┘
3 rows in set. Elapsed: 0.003 sec.
--
OPTIMIZE TABLE t_sum FINAL
Ok.
0 rows in set. Elapsed: 0.003 sec.
select * from t_sum;
SELECT *FROM t_sum
┌─key─┬─value─┐
│ 1 │ 3 │
│ 2 │ 3 │
└─────┴───────┘
2 rows in set. Elapsed: 0.003 sec.
--为了保证统计正确,数据仍然需要做聚合
SELECT key, sum(value) FROM t_sum GROUP BY key;
SELECT key, sum(value)FROM t_sumGROUP BY key
┌─key─┬─sum(value)─┐
│ 2 │ 3 │
│ 1 │ 3 │
└─────┴────────────┘
2 rows in set. Elapsed: 0.004 sec.
需要注意的是,进行聚合的条件是order by后面字段,聚合所有非主键的数值类型字段,如果指定了分区,在聚合仅仅限于分区内部。
AggregatingMergeTree,和SummingMergeTree非常类似,也是进行预聚合后统计。区别在于使用的范围更广,而不仅仅使用sum函数。这种存储引擎更多的在物化视图上使用,如下例:
--创建基础表
CREATE TABLE t_agg_basic
(
`id` String,
`name` String,
`value` UInt32
)
ENGINE = MergeTree()
ORDER BY id
Ok.
0 rows in set. Elapsed: 0.008 sec.
--创建物化视图
CREATE MATERIALIZED VIEW t_agg_view
ENGINE = AggregatingMergeTree()
PARTITION BY name
ORDER BY (id, name)
AS
SELECT id, name, sum(value) AS sum_value, avg(value) AS avg_value
FROM t_agg_basic
GROUP BY id, name
Ok.
0 rows in set. Elapsed: 0.011 sec.
--基础表插入明细数据
insert into table t_agg_basic values('001','bj',10),('001','bj',20),('002','sh',30),('002','sh',40);
INSERT INTO t_agg_basic VALUES
Ok.
4 rows in set. Elapsed: 0.005 sec.
--物化视图自动聚合SELECT *FROM t_agg_view
┌─id──┬─name─┬─sum_value─┬─avg_value─┐
│ 002 │ sh │ 70 │ 35 │
└─────┴──────┴───────────┴───────────┘
┌─id──┬─name─┬─sum_value─┬─avg_value─┐
│ 001 │ bj │ 30 │ 15 │
└─────┴──────┴───────────┴───────────┘
2 rows in set. Elapsed: 0.004 sec.
其他几种存储引擎,CollapsingMergeTree/VersionedCollapsingMergeTree来消除ReplacingMergeTree的限制,使用场景相对较少,由于篇幅所限,这里不再举例。
六、分区/分片/副本的区别
分区:将表按照分区键在逻辑上分成多个数据段,后台文件合并时,同一个分区的数据段将合并成新的数据段。和MySQL等关系数据库的分区概念类似,通过分区可以在查询和运维方面提供很多方便。前例创建表时指定partition关键字即可创建分区表。
分片:将表中的数据按照一定的规则拆分为多个部分,每个部分的数据均存储在不同的计算节点上,每个计算节点上的数据称为一个分片。
副本:对于Replicated
MergeTree 系列复制表,可以设置每个表有多份完全一样的数据存放在不同的计算节点上,每一份数据都是完整的,并且称为一个副本。
分片和副本信息可以通过查询system.clusters获取详细信息。下面SQL显示了我们测试集群的详细信息:
select * from system.clusters;
SELECT *FROM system.clusters
┌─cluster─┬─shard_num─┬─shard_weight─┬─replica_num─┬─host_name─────────────┬─host_address─┬─port─┬─is_local─┬─user────┬─default_database─┬─errors_count─┬─estimated_recovery_time─┐
│ default │ 1 │ 1 │ 1 │ chi-ck-ew1skhn4ep-0-0 │ 11.32.0.154 │ 9000 │ 0 │ default │ │ 0 │ 0 │
│ default │ 2 │ 1 │ 1 │ chi-ck-ew1skhn4ep-1-0 │ 127.0.0.1 │ 9000 │ 1 │ default │ │ 0 │ 0 │
└─────────┴───────────┴──────────────┴─────────────┴───────────────────────┴──────────────┴──────┴──────────┴─────────┴──────────────────┴──────────────┴─────────────────────────┘
2 rows in set. Elapsed: 0.005 sec.
可以看出:我们集群的名称为default;有两个分片,分片号分别为1和2;单副本,这里单副本的概念其实是没有副本,两个分片都是单个实例。
在测试过程中,经常发现每次连接到不同的shard节点,创建的表在下一次连接后经常就看不见了,这是因为我们创建的表是本地表(local表),只在本地保存。但对应用来说更希望创建表时,每个节点都能同时创建完成,对外可以看到的是一个统一的表,此时,就需要用到ClickHouse的分布式引擎,也称为Distributed。
分布式引擎,本身不存储数据,但可以在多个服务器上进行分布式查询,类似于分库分表中间件。读是自动并行的。读取时,远程服务器表的索引(如果存在)会被使用。下例中我们首先利用ClickHouse的ReplicatedMergeTree在各个节点创建表结构,然后创建分布式引擎,来获取一个完整的数据结果。
--连接到任何一个shard节点执行下面建表命令:
CREATE TABLE log_test2 ON CLUSTER default
( `ts` DateTime, `uid` UInt32, `biz` String)
ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/log_test2', '{replica}')
PARTITION BY toYYYYMMDD(ts)
ORDER BY ts
SETTINGS index_granularity = 8192
┌─host──────────────────┬─port─┬─status─┬─error─┬─num_hosts_remaining─┬─num_hosts_active─┐
│ chi-ck-ew1skhn4ep-1-0 │ 9000 │ 0 │ │ 1 │ 0 │
│ chi-ck-ew1skhn4ep-0-0 │ 9000 │ 0 │ │ 0 │ 0 │
└───────────────────────┴──────┴────────┴───────┴─────────────────────┴──────────────────┘
2 rows in set. Elapsed: 0.119 sec.
--分别连接到不同的shard节点(通过hostname()看是否为同一个节点),分别插入下面两条数据
--shard1:SELECT hostname()
┌─hostname()──────────────────────┐
│ chi-ck-ew1skhn4ep-default-1-0-0 │
└─────────────────────────────────┘
1 rows in set. Elapsed: 0.003 sec.
--插入数据
insert into log_test2 values(now(),1,1);
INSERT INTO log_test2 VALUES
Ok.
1 rows in set. Elapsed: 0.011 sec.
--查询数据
SELECT *FROM log_test2
┌──────────────────ts─┬─uid─┬─biz─┐
│ 2020-11-25 20:09:12 │ 1 │ 1
│└─────────────────────┴─────┴─────┘
1 rows in set. Elapsed: 0.003 sec.
--shard2:SELECT hostname()
┌─hostname()──────────────────────┐
│ chi-ck-ew1skhn4ep-default-0-0-0 │
└─────────────────────────────────┘
1 rows in set. Elapsed: 0.003 sec.
--插入数据
insert into log_test2 values(now(),2,2);
INSERT INTO log_test2 VALUES
Ok.
1 rows in set. Elapsed: 0.012 sec.
--查询数据
SELECT *FROM log_test2
┌──────────────────ts─┬─uid─┬─biz─┐
│ 2020-11-25 20:10:57 │ 2 │ 2 │
└─────────────────────┴─────┴─────┘
1 rows in set. Elapsed: 0.004 sec.
--创建分布式引擎:
CREATE TABLE log_test_all ON CLUSTER default
( `ts` DateTime, `uid` UInt32, `biz` String)
ENGINE = Distributed(default, default, log_test2, uid)
┌─host──────────────────┬─port─┬─status─┬─error─┬─num_hosts_remaining─┬─num_hosts_active─┐
│ chi-ck-ew1skhn4ep-0-0 │ 9000 │ 0 │ │ 1 │ 0 │
│ chi-ck-ew1skhn4ep-1-0 │ 9000 │ 0 │ │ 0 │ 0 │
└───────────────────────┴──────┴────────┴───────┴─────────────────────┴──────────────────┘
2 rows in set. Elapsed: 0.114 sec.
--查看分布式表:
select * from log_test_all;
SELECT *FROM log_test_all
┌──────────────────ts─┬─uid─┬─biz─┐
│ 2020-11-25 20:09:12 │ 1 │ 1 │
└─────────────────────┴─────┴─────┘
┌──────────────────ts─┬─uid─┬─biz─┐
│ 2020-11-25 20:10:57 │ 2 │ 2 │
└─────────────────────┴─────┴─────┘
2 rows in set. Elapsed: 0.007 sec.
--往分布式表中插入数据,此时新数据会按照指定的key进行hash计算后路由到对应节点:
select * from log_test_all;
SELECT *FROM log_test_all
┌──────────────────ts─┬─uid─┬─biz─┐
│ 2020-11-25 20:09:12 │ 1 │ 1 │
└─────────────────────┴─────┴─────┘
┌──────────────────ts─┬─uid─┬─biz─┐
│ 2020-11-25 20:19:33 │ 5 │ 5 │
└─────────────────────┴─────┴─────┘
┌──────────────────ts─┬─uid─┬─biz─┐
│ 2020-11-25 20:19:09 │ 3 │ 3 │
└─────────────────────┴─────┴─────┘
┌──────────────────ts─┬─uid─┬─biz─┐
│ 2020-11-25 20:19:45 │ 6 │ 6 │
└─────────────────────┴─────┴─────┘
┌──────────────────ts─┬─uid─┬─biz─┐
│ 2020-11-25 20:19:24 │ 4 │ 4 │
└─────────────────────┴─────┴─────┘
┌──────────────────ts─┬─uid─┬─biz─┐
│ 2020-11-25 20:10:57 │ 2 │ 2 │
└─────────────────────┴─────┴─────┘
6 rows in set. Elapsed: 0.009 sec.
--shard1查询
select * from log_test2;
SELECT *FROM log_test2
┌──────────────────ts─┬─uid─┬─biz─┐
│ 2020-11-25 20:19:33 │ 5 │ 5 │
└─────────────────────┴─────┴─────┘
┌──────────────────ts─┬─uid─┬─biz─┐
│ 2020-11-25 20:19:09 │ 3 │ 3 │
└─────────────────────┴─────┴─────┘
┌──────────────────ts─┬─uid─┬─biz─┐
│ 2020-11-25 20:09:12 │ 1 │ 1 │
└─────────────────────┴─────┴─────┘
3 rows in set. Elapsed: 0.004 sec.
--shard2查询:
select * from log_test2;
SELECT *FROM log_test2
┌──────────────────ts─┬─uid─┬─biz─┐
│ 2020-11-25 20:19:45 │ 6 │ 6 │
└─────────────────────┴─────┴─────┘
┌──────────────────ts─┬─uid─┬─biz─┐
│ 2020-11-25 20:19:24 │ 4 │ 4 │
└─────────────────────┴─────┴─────┘
┌──────────────────ts─┬─uid─┬─biz─┐
│ 2020-11-25 20:10:57 │ 2 │ 2 │
└─────────────────────┴─────┴─────┘
3 rows in set. Elapsed: 0.004 sec.
可以看出,数据通过分布式表准确的进行了数据的路由分发和查询汇总。
八、一点感悟
ClickHouse是近些年OLAP领域突显的一批黑马,它最大的特点就是快,快的原因很多,比如大量使用并行/列存/向量化/压缩/稀疏索引等各种常见技术外,更多是一些设计思想上的创新,比如一个字符串搜素算法,会按照字符串的使用场景来使用不同的算法;对于普通的去重计数函数,会根据字符串的大小来选择不同的算法;类似的优化在ClickHouse中使用非常普遍。
本文只是介绍了一些ClickHouse的基本概念和一些初级用法,真正要用到生产环境,还要很多细节需要查阅文档并充分测试后进行。
在此感谢各位童鞋阅读,如果能够对大家有所帮助,欢迎点赞转发。
同时欢迎扫码关注京东云技术中台团队的公众号:云服务飞行团;更多精彩内容会持续放送!







