



上回书说到,客户提出了从K8S集群外访问clusterIP类型的service和后端pod的需求,攻城狮给出的架构方案在测试中发现了让人头秃的bug。经过一番深入分析终于找到了问题原因,那么是否有锦囊妙计可以助攻城狮攻克难关呢?且看我们的技术分享下篇!
既然费尽周折找到了访问失败的原因,接下来我们就要想办法解决这个问题。事实上只要想办法让pod跨节点给客户端回包时隐藏自己的IP,对外显示的是service的IP,就可以避免包被丢弃。原理上类似于SNAT(基于源IP的地址转换)。可以类比为没有公网IP的局域网设备有自己的内网IP,当访问公网时需要通过统一的公网出口,而此时外部看到的客户端IP是公网出口的IP,并不是局域网设备的内网IP。实现SNAT,我们首先会想到通过节点操作系统上的iptables规则。我们在pod所在节点node A上执行iptables-save命令,查看系统已有的iptables规则都有哪些。
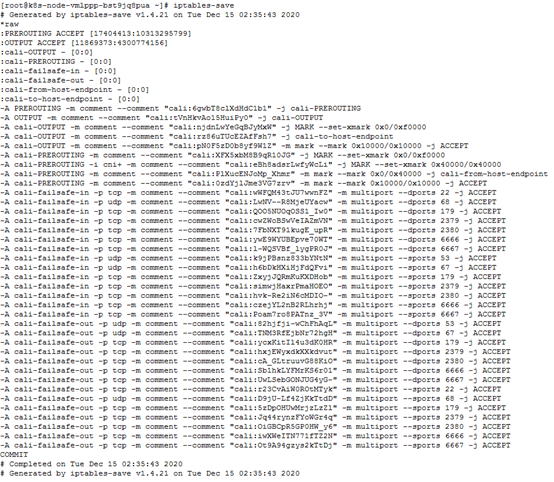
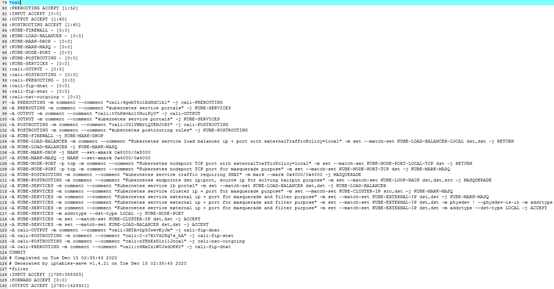
可以看到系统创建了近千条iptables规则,大多数与k8s有关。我们重点关注上图中的nat类型规则,发现了有如下几条引起了我们的注意:

- 首先看红框部分规则
-A KUBE-SERVICES -m comment --comment "Kubernetes service cluster ip + port for masquerade purpose" -m set --match-set KUBE-CLUSTER-IP src,dst -j KUBE-MARK-MASQ
该规则表示如果访问的源地址或者目的地址是cluster ip +端口,出于masquerade目的,将跳转至KUBE-MARK-MASQ链,masquerade也就是地址伪装的意思!在NAT转换中会用到地址伪装。接下来看蓝框部分规则
-A KUBE-MARK-MASQ -j MARK --set-xmark 0x4000/0x4000
该规则表示对于数据包打上需要做地址伪装的标记0x4000/0x4000。
- 最后看黄框部分规则
-A KUBE-POSTROUTING -m comment --comment "kubernetes service traffic requiring SNAT" -m mark --mark 0x4000/0x4000 -j MASQUERADE
该规则表示对于标记为0x4000/0x4000需要做SNAT的数据包,将跳转至MASQUERADE链进行地址伪装。
这三条规则所做的操作貌似正是我们需要iptables帮我们实现的,但是从之前的测试来看显然这三条规则并没有生效。这是为什么呢?是否是k8s的网络组件里有某个参数控制着是否会对访问clusterIP时的数据包进行SNAT?
这就要从负责service与pod之间网络代理转发的组件——kube-proxy的工作模式和参数进行研究了。我们已经知道service会对后端pod进行负载均衡和代理转发,要想实现该功能,依赖的是kube-proxy组件,从名称上可以看出这是一个代理性质的网络组件。它以pod形式运行在每个k8s节点上,当以service的clusterIP+端口方式访问时,通过iptables规则将请求转发至节点上对应的随机端口,之后请求由kube-proxy组件接手处理,通过kube-proxy内部的路由和调度算法,转发至相应的后端Pod。最初,kube-proxy的工作模式是userspace(用户空间代理)模式,kube-proxy进程在这一时期是一个真实的TCP/UDP代理,类似HA Proxy。由于该模式在1.2版本k8s开始已被iptables模式取代,在此不做赘述,有兴趣的童鞋可以自行研究下。
1.2版本引入的iptables模式作为kube-proxy的默认模式,kube-proxy本身不再起到代理的作用,而是通过创建和维护对应的iptables规则实现service到pod的流量转发。但是依赖iptables规则实现代理存在无法避免的缺陷,在集群中的service和pod大量增加后,iptables规则的数量也会急剧增加,会导致转发性能显著下降,极端情况下甚至会出现规则丢失的情况。
为了解决iptables模式的弊端,K8S在1.8版本开始引入IPVS(IP Virtual Server)模式。IPVS模式专门用于高性能负载均衡,使用更高效的hash表数据结构,为大型集群给出了更好的扩展性和性能。比iptables模式支持更复杂的负载均衡调度算法等。托管集群的kube-proxy正是使用了IPVS模式。
但是IPVS模式无法给与包过滤,地址伪装和SNAT等功能,所以在需要使用这些功能的场景下,IPVS还是要搭配iptables规则使用。等等,地址伪装和SNAT,这不正是我们之前在iptables规则中看到过的?这也就是说,iptables在不进行地址伪装和SNAT时,不会遵循相应的iptables规则,而一旦设置了某个参数开启地址伪装和SNAT,之前看到的iptables规则就会生效!于是我们到kubernetes官网查找kube-proxy的工作参数,有了令人激动的发现:

好一个蓦然回首!攻城狮的第六感告诉我们,--masquerade-all参数就是解决我们问题的关键!
我们决定测试开启下--masquerade-all这个参数。kube-proxy在集群中的每个节点上以pod形式运行,而kube-proxy的参数配置都以configmap形式挂载到pod上。我们执行kubectl get cm -n kube-system查看kube-proxy的configmap,如图所示:
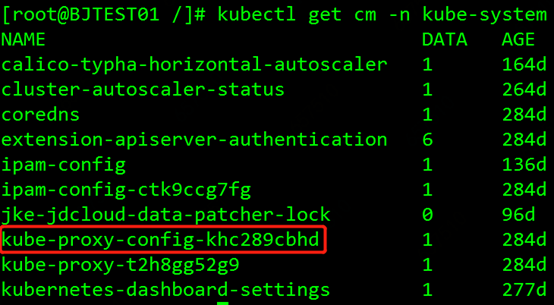
红框里的就是kube-proxy的配置configmap,执行kubectl edit cm kube-proxy-config-khc289cbhd -n kube-system编辑这个configmap,如图所示
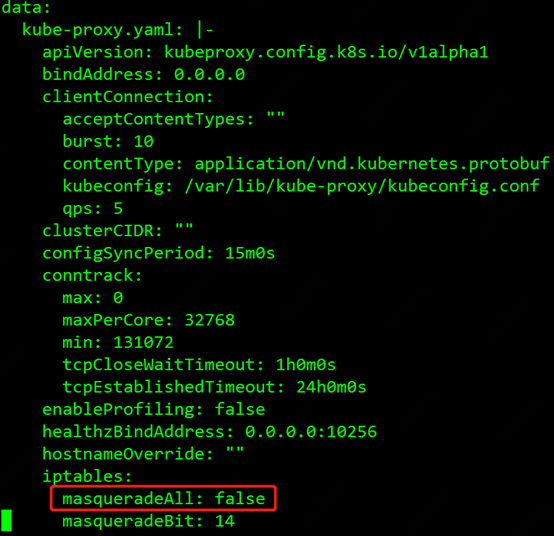
找到了masqueradeALL参数,默认是false,我们修改为true,然后保存修改。
要想使配置生效,需要逐一删除当前的kube-proxy pod,daemonset会自动重建pod,重建的pod会挂载修改过的configmap,masqueradeALL功能也就开启了。如图所示:
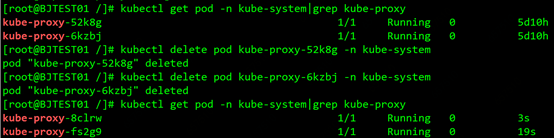
- 期待地搓手手
接下来激动人心的时刻到来了,我们将访问service的路由指向node B,然后在上海客户端上执行paping 10.0.58.158 -p 80观察测试结果(期待地搓手手):
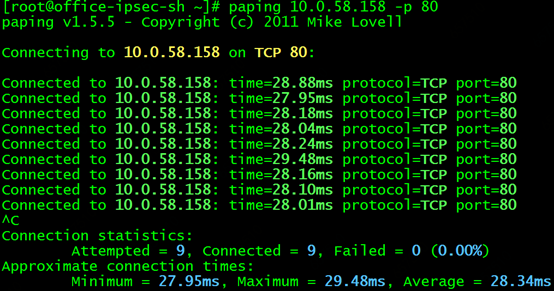
此情此景,不禁让攻城狮流下了欣喜的泪水……
再测试下curl http://10.0.58.158 同样可以成功!奥力给~
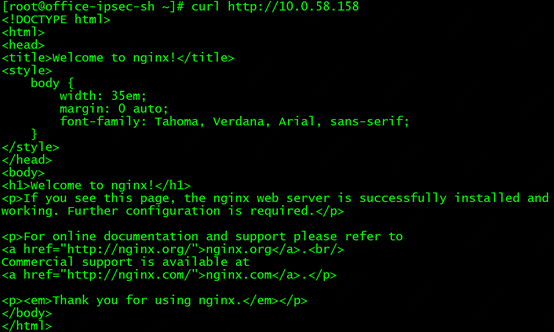
再测试下直接访问后端Pod,以及请求转发至pod所在节点,都没有问题。至此客户的需求终于卍解,长舒一口气!
虽然问题已经解决,但是我们的探究还没有结束。开启masqueradeALL参数后,service是如何对数据包做SNAT,避免了之前的丢包问题呢?还是通过抓包进行分析。
首先分析转发至pod不在的节点时的场景,客户端请求服务时,在pod所在节点对客户端IP进行抓包,没有抓到任何包。

说明开启参数后,到后端pod的请求不再是以客户端IP发起的。
在转发节点对pod IP进行抓包可以抓到转发节点的service端口与pod之间的交互包
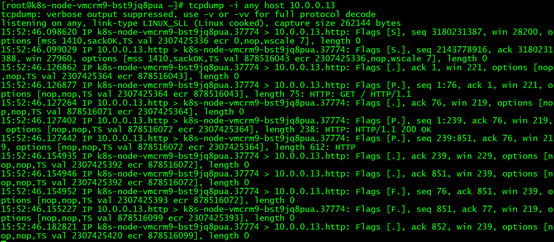
说明pod没有直接回包给客户端172.16.0.50。这样看来,相当于客户端和pod互相不知道彼此的存在,所有交互都通过service来转发。
再在转发节点对客户端进行抓包,包内容如下:

同时在pod所在节点对pod进行抓包,包内容如下:

可以看到转发节点收到序号708的curl请求包后,在pod所在节点收到了序号相同的请求包,只不过源目IP从172.16.0.50/10.0.58.158转换为了10.0.32.23/10.0.0.13。这里10.0.32.23是转发节点的内网IP,实际上就是节点上service对应的随机端口,所以可以理解为源目IP转换为了10.0.58.158/10.0.0.13。而回包时的流程相同,pod发出序号17178的包,转发节点将相同序号的包发给客户端,源目IP从10.0.0.13/10.0.58.158转换为了10.0.58.158/172.16.0.50
根据以上现象可以得知,service对客户端和后端都做了SNAT,可以理解为关闭了透传客户端源IP的负载均衡,即客户端和后端都不知道彼此的存在,只知道service的地址。该场景下的数据通路如下图:
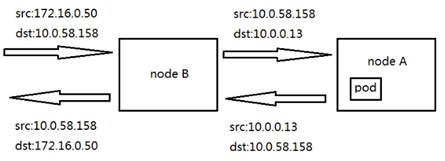
对Pod的请求不涉及SNAT转换,与masqueradeALL参数不开启时是一样的,因此我们不再做分析。
当客户端请求转发至pod所在节点时,service依然会进行SNAT转换,只不过这一过程均在节点内部完成。通过之前的分析我们也已经了解,客户端请求转发至pod所在节点时,是否进行SNAT对访问结果没有影响。
至此对于客户的需求,我们可以给出现阶段最优的方案。当然在生产环境,为了业务安全和稳定,还是不建议用户将clusterIP类型服务和pod直接暴露在集群之外。同时masqueradeALL参数开启后,对集群网络性能和其他功能是否有影响也没有经过测试验证,在生产环境开启的风险是未知的,还需要谨慎对待。通过解决客户需求的过程,我们对K8S集群的service和pod网络机制有了一定程度的了解,并了解了kube-proxy的masqueradeALL参数,对今后的学习和运维工作还是受益匪浅的。
在此感谢各位童鞋阅读,如果能够对大家有所帮助,欢迎点赞转发。
同时欢迎扫码关注京东云技术中台团队的公众号:云服务飞行团;更多精彩内容会持续放送!







