您好!
欢迎来到京东云开发者社区
登录
首页
博文
课程
大赛
工具
用户中心
开源
首页
博文
课程
大赛
工具
开源
更多
用户中心
开发者社区
>
博文
>
凹凸技术揭秘 · Deco 智能代码 · 开启产研效率革命
分享
打开微信扫码分享
点击前往QQ分享
点击前往微博分享
点击复制链接
凹凸技术揭秘 · Deco 智能代码 · 开启产研效率革命
凹凸实验室
2021-01-05
IP归属:未知
7689浏览
前端
计算机编程
机器学习
## 1、背景介绍 近几年中台的兴起,团队围绕业务中台化这个场景,将我们已有的诸多能力进行解构、重组、积木化,希望能将拆解后的积木进行体系化地串联,从而达到降本增效的目的。 对于电商平台来说,每年都需要面临大量的大促活动页面需求,对于如何提高页面产出效率,大家都不约而同采用「页面可视化搭建」解决方案。对应的,我们也构建了「羚珑可视化页面搭建平台」。但近两年大促活动定制化需求井喷,平台有限的组件模块已无法满足产品运营需求,前端工程师也无法再用「复用」的思想简单地解决问题。当业务发展到一定程度,有限的人力以及冗长的开发流程更是无法满足蓬勃发展的业务需求。 我们需要「求变」,传统的人力密集型研发无法解决的问题,是否能用智能化的思想来解决呢?顺着这个方向,我们把目标瞄准了「前端智能化」,希望借助 AI 和机器学习的能力拓展前端能力圈,打通设计与研发的工作流程,实现规模化生产。 ## 2、项目介绍 Deco 智能代码项目是团队在「前端智能化」方向上的探索,我们尝试从设计稿生成代码(DesignToCode)这个切入点入手,对现有的设计到研发这一环节进行能力补全,进而提升产研效率。 在一个日常需求开发流程中,往往需要遵循固定的一套工作流程,产品提交需求 PRD,交互设计师根据 PRD 输出交互稿,再由视觉设计师输出产品视觉稿,接着再进入前端开发工作流。对于前端工程师来说,输入源是视觉稿 + PRD,输出结果是可上线的页面代码。 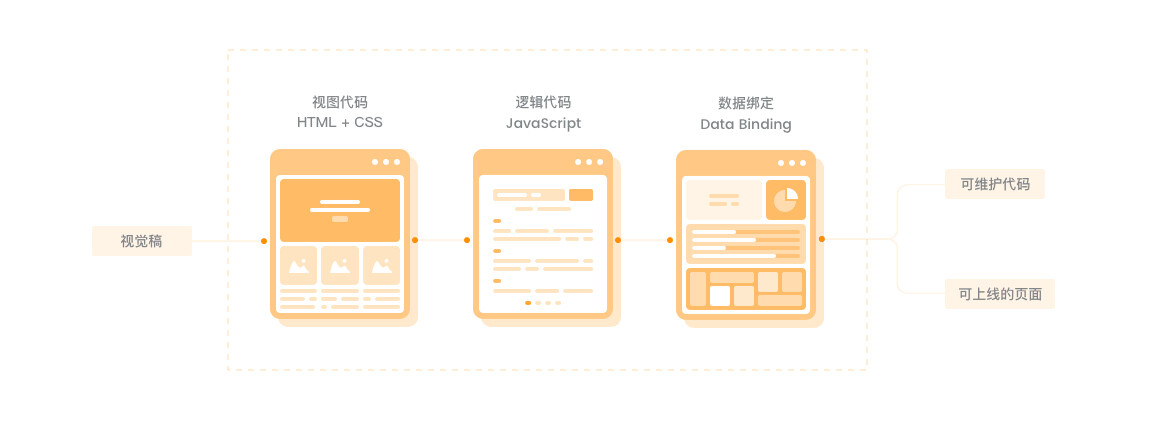 Deco 期望解决的是上述流程中,对于前端工程师而已相对低价值,以及可用复用思想处理的工作: * UI 视觉稿还原,即页面重构,编写 HTML + CSS; * 可复用的业务逻辑绑定; 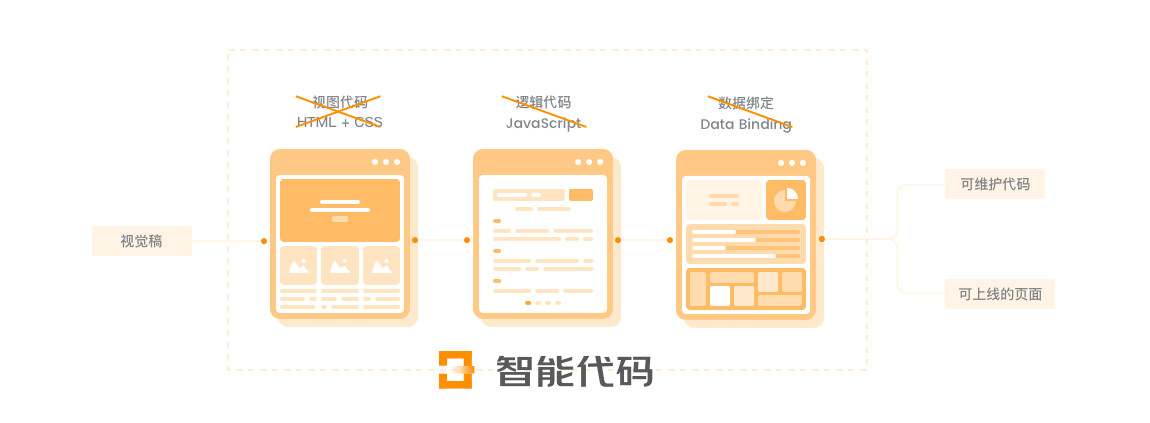 以「设计稿生成代码」为切入点,我们需要用智能化的解决方案来替代传统的人工页面重构(分析图层样式+切图等),期望能从视觉稿原始信息中提取结构化的数据描述,进而再与智能布局等算法结合,输出可维护的页面代码。 ## 3、技术方案 设计稿智能生成代码能力的核心是如何生成一份「结构化的数据描述」信息,这份数据称为 D2C Schema。 <div style="text-align: center;" > <img width="800" src="https://img12.360buyimg.com/img/s1920x1080_jfs/t1/161330/8/303/162801/5fed8bcaE5fc5d350/a4303b6d7968896a.jpg" /> </div> Deco 设计稿智能生成代码主要做了两件事情: 1. 从视觉稿中提取「结构化的数据描述」; 2. 将「结构化的数据描述」表达成代码; 本质上,Deco 智能代码是通过设计工具插件从视觉稿原始信息中提取结构化的数据描述(D2C Schema),然后结合规则系统、计算机视觉、智能布局、深度学习等技术对 D2C Schema 进行处理,转换为布局合理且语义化的 D2C Schema JSON 数据,最后再借助 DSL 解析器转换为多端代码。 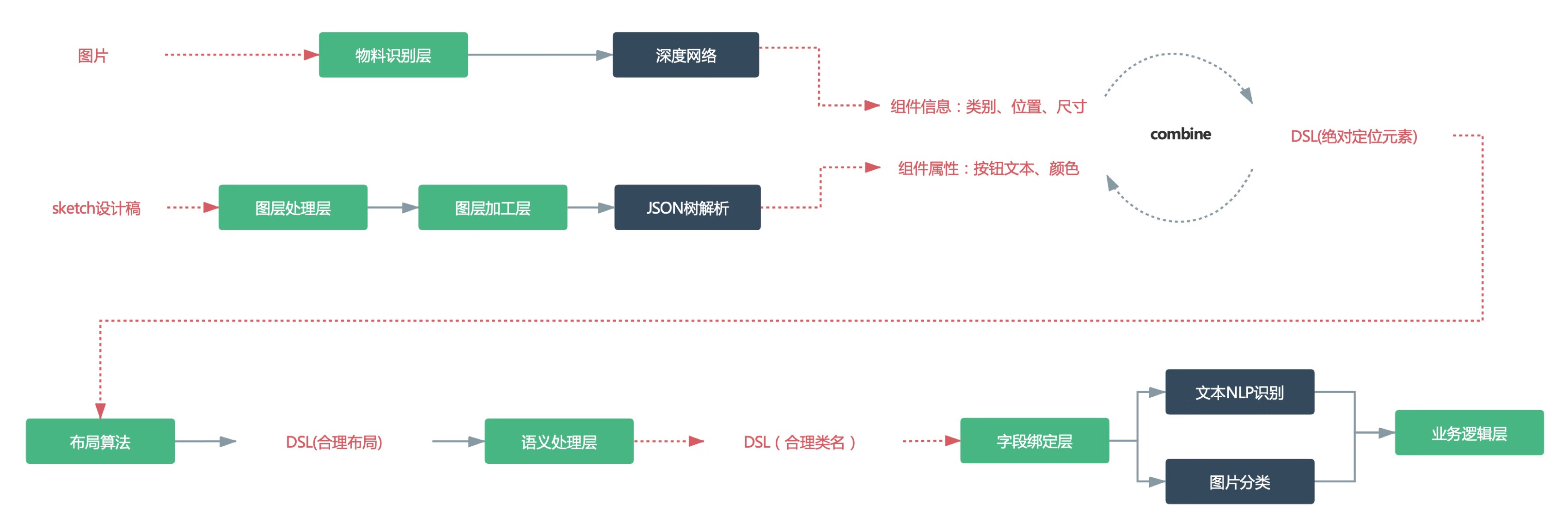 Deco 智能代码的核心链路构成了团队「前端智能化」探索的核心技术体系,围绕产研流程的体系化建设,结合 Cloud IDE、Taro 多端统一解决方案、设计研发资产平台,以及羚珑智能设计等能力,实现一个良性的产研闭环,为整体的工程链路降本提效。 ## 4、智能代码技术分层 Deco 智能代码核心链路现阶段主要包含组件识别、图层处理、布局算法以及语义化处理四大分层,下面会围绕这些细分的分层展开内部实现原理的剖析。 ### 4.1 组件识别层 组件识别层负责识别设计稿图片中的元素,包括业务组件识别、基础组件识别以及区块识别。 通过识别能力,输出设计稿中与现有组件库组件匹配的部分,进行组件推荐与复用,并辅助后续处理层处理,比如语义处理层等根据组件属性进行语义化命名,提高生成代码的可用性。 #### 4.1.1 组件识别 组件识别层借助了AI能力,使用深度学习目标检测算法来进行识别,输入设计稿导出的图片,输出图片中的组件类别及组件位置。 <div style="text-align: center;" > <img width="800" src="https://img12.360buyimg.com/img/s1301x1160_jfs/t1/155620/32/3513/300950/5fed8f0aE683fea36/fbd78d06ce64c921.jpg" /> </div> #### 4.1.2 数据集 数据集是使用深度学习处理问题的大头,我们汇集了羚珑平台活动页数据、大促会场设计稿以及Relay平台数据,构建了含有2w+样本的组件识别数据集。其中,引入了自动化标注,通过对使用组件搭建的羚珑页面进行Dom结构解析,获得绝对精准的标注数据,减少人工标注成本。 <div style="text-align: center;" > <img width="600" src="https://img12.360buyimg.com/img/s1194x549_jfs/t1/164331/36/210/54651/5fed8f72E5012ba90/abe749711b40888b.png" /> </div> 为了进一步地丰富数据集,解决组件之间数量不均衡的问题,采用了自动化样本生成方案,基于Quark 官方业务组件库以及大促会场沉淀的 jdcop 大促原子组件库,支持十类样本生成。采用组件模版搭配随机属性的方式,由组件组成完整的页面,并在导出的过程中自动进行标注。 #### 4.1.3 区块识别 移动端设计稿大部分高宽比过长,有达到 10:1 以上的,且分布不均,不利于目标检测识别,由此,首先将页面划分为区块,区块识别算法基于传统图像处理流程,使用边缘检测以及漫水填充算法获得连通区域,设置过滤阈值留下楼层大小的识别框。 <div style="text-align: center;" > <img width="300" src="https://img12.360buyimg.com/img/s592x835_jfs/t1/156017/39/3504/40455/5fed8f71Ee3aa9831/aa987f8dee9e2bb8.png" /> </div> 区块识别算法应用于图层处理层自动成组,优化图层的嵌套结构,助力于布局算法产生更合理的组件结构树。 此外,将未识别区域自动划分为新楼层。通过固定高度限制,临近区块组合为一个更大粒度的区块,达到将不等高度的设计稿划分为高度相差不大的几个区域的效果,再投入目标检测网络进行识别。 ### 4.2 图层处理层 图层处理层主要将设计稿中的图层进行分离、合并、提取元信息,同时结合组件识别层智能成组、分类,导出第一份 Deco Schema DSL。Deco 工作流就像软件工程里的管道与过滤器设计模式,设计稿就是管道的入参,管道中的流就是每一阶段生成的 DSL,管道的输出是一份语义化代码。 <div style="text-align: center;" > <img width="900" src="https://img12.360buyimg.com/img/s1337x423_jfs/t1/152313/16/12717/101193/5fed8f72E0ba12f0d/3c306f3917d5c6f1.jpg" /> </div> 图层处理层通过借助组件识别层的 AI 能力,智能识别设计稿每个区块,将区块内的图层信息合成一个组,再通过区块匹配算法自动匹配区块与图层,实现了设计稿的自动成组,成组数据有利于布局算法判断区块的层级信息和父子关系。 <div style="text-align: center;" > <img width="800" src="https://img12.360buyimg.com/img/s2036x1748_jfs/t1/163597/18/209/1757805/5fed9002E2bf2f58d/9873efb898135b9d.png" /> </div> 一份 Sketch 文稿是由若干图层元信息(分为 Document 和 Pages 等)和资源文件(主要是图片)组成的一个压缩文档(文件后缀为“.sketch”),我们通过对图层元信息进行加工处理后得到一份供布局算法服务处理的 DSL。 通过开发 Sketch 插件,使用 Sketch 提供的 API 能够帮助我们去操作 Sketch 里的文稿,拿到图层信息后,对这些数据加工、筛选等处理。图层信息的处理主要是分为两层: 1. 设计稿加工层: 1. 复制出一份原样的设计稿,在这份复制的设计稿上进行各种加工的操作; 2. Symbol 解耦,将文稿中的 Symbols 解耦为实际的图层组; 3. 筛选不可见图层,过滤掉设计师隐藏的图层以及空图层组; 4. 图层合并,将一些特殊的图层或图层组合并,并转为图片; 5. 蒙层处理,蒙层下的图片如果超出蒙层范围需要裁剪,同时蒙层下的图层位置和宽高信息需要重置。 2. 图层信息处理层: 1. 提取图层中有用的信息,比如样式处理、文字拆分、图层层级等; 2. 图层信息的转化,比如将图片的 base64 位字符串数据转为 CDN 图片地址; 3. 无用图层检测,将一些无样式或透明样式的图层去除; 4. 图层打平处理,将图层数据由树状的层级打平为一维的结构; 5. 成组信息筛选,将未成组的数据通过比对位置和大小将其归类到已成组的数据中。 下图是对图层信息的处理流程: <div style="text-align: center;" > <img width="800" src="https://img12.360buyimg.com/img/s1337x644_jfs/t1/157558/3/877/272492/5fed8f71E2ab26855/a9684747e1ffa99f.jpg" /> </div> 除了对图层信息的基础处理之外,我们建立了一系列的数据导出的优化规则,用于增加布局以及语义的合理性。比如在一些大促设计稿上,复杂背景图的设计可能是在一个图层组下由若干个矢量图形组成(如下图),如果原封不动地将这些图层导出,会给布局带来很多复杂度和不确定性。 <div style="text-align: center;" > <img width="700" src="https://img12.360buyimg.com/img/s1896x962_jfs/t1/155724/18/3463/745446/5fed98aaEcef60f1b/d457b5f93367a016.png" /> </div> 在合图的这一流程中,针对一个图层组下所有图层都是矢量图形的情况,我们会将它合成为一张图片,这样会大大减轻布局的困难度。最终合图效果如下图: <div style="text-align: center;" > <img width="600" src="https://img12.360buyimg.com/img/s714x132_jfs/t1/169771/39/193/42951/5fed98a9E26e6760d/531f806f0bd5fa80.png" /> </div> 当然,上面提到的这些优化规则并不能满足所有的情况,毕竟设计师是自由的。为了提高布局和语义的合理性,我们对入参的设计稿提了一些规范协议供设计师以及开发者使用。 ### 4.3 布局算法层 #### 4.3.1 为什么需要布局算法 布局算法是建立在输入源符合 Deco Schema 规范的数据,该数据规范可以通过 Deco Sketch 插件对视觉高进行处理,最终会导出设计元素信息。 经过 Deco Sketch 插件导出的元素数据,都是以左上角 (0, 0) 为坐标原点坐标的绝对定位为基础的元素信息,并且在一般情况下(无主动编组、无AI识别等等情况 )元素都是扁平化的,也就是元素间没有从属关系。 <div style="text-align: center;" > <img width="400" src="https://img12.360buyimg.com/img/s443x377_jfs/t1/169791/20/210/12060/5fed9913E7767b7ba/ef64707e24e847c8.png" /> </div> 在前端开发过程中,绝对定位布局无论是扩展性、可读性都达不到开发要求,那么如果不解决,就成为 一次性代码 。因此,需要布局算法来提高生成代码的扩展性、可读性,供后续二次开发使用。 #### 4.3.2 布局层核心算法 布局算法层的设计包含三大层:数据结构转换层、布局推导层、样式计算层。 <div style="text-align: center;" > <img width="600" src="https://img12.360buyimg.com/img/s609x588_jfs/t1/171357/38/226/85335/5fed9913E71b38017/739bb6e8d89ca65a.jpg" /> </div> ##### 4.3.2.1 数据转换层 数据结构转换层是将 Deco Schema JSON 数据转换为类似 DOM 树的结构,可以进行节点插入、删除、查找操作。 下面是 LayoutNode 基本数据结构: ``` LayoutNode { ...省略节点属性 ...部分节点方法 appendChild (child) {} prependChild (child) {} insertAfter (insertedChild, afterChild) {} insertBefore (insertedChild, beforeChild) {} replaceChild (newChild, replacedChild) {} removeChild (child) {} get x () {} get y () {} get width () {} get height () {} get offsetLeft () {} get offsetTop () {} get previousSibling () {} get nextSibling () {} intersect (node) {} contains (node) {} disjoint (node) {} tangent (node) {} hitTest (node) { ... } ``` ##### 4.3.2.2 布局推导层 布局推导层则是进行行列分割推导,总体上包含:空间布局算法、投影布局算法、背景图布局算法、特征检测布局算法、坐标推导算法、背景图层及冗余图层检测算法等等。 <div style="text-align: center;" > <img width="500" src="https://img12.360buyimg.com/img/s801x444_jfs/t1/164092/36/228/85278/5fed9913Ee1d027c8/df7337312d3cd820.jpg" /> <span style="color: #888; font-size: 0.9em;">空间布局算法</span> </div> <div style="text-align: center;" > <img width="500" src="https://img12.360buyimg.com/img/s510x296_jfs/t1/166468/16/224/48801/5fed9913E97706fe1/d3fab3b55e7f022a.jpg" /> <span style="color: #888; font-size: 0.9em;">投影布局算法</span> </div> <br /> 其中特征检测包括标题、列表、Tab 等等一些列常见的布局检测。 ##### 4.3.2.3 样式计算层 样式计算层,是对经过布局推导层得到的结果进行一系列的计算,而 Deoc 样式大部分布局采用 Flexbox,有些特殊情况需要使用绝对定位。在布局推导之后,Layout 结构已经有了明晰的层级关系及相邻关系。 基于层级关系,可以通过坐标计算得出 Flexbox 主轴、侧轴;基于相邻关系,可以计算出相邻之间的 margin 等等样式。 ### 4.4 语义化层 当设计稿数据经过布局算法处理后我们就能获得结构较为良好的代码,但此时我们会发现由于节点元素缺乏相应的语义化类名,代码依然不具备很好地可读性。为了最终能得到可以二次开发的代码,我们需要在布局算法层之后加入语义化处理层来让代码拥有良好的语义性。 语义化层首要解决的问题就是如何为元素节点加上具有语义化的类名。 为了实现这一目标,我们可以先回顾一下在我们开发的时候是如何给元素节点加上类名的,以如下的单个商品图为例。 <div style="text-align: center;" > <img width="180" src="https://img12.360buyimg.com/img/s234x418_jfs/t1/151730/40/12814/49284/5fed997cEb8b7a43b/7211720bcc3dd8c5.png" /> </div> 上图是一个商品图的示例,我们会通过图片、价格、图片下方文案等因素来判断出这是一个商品,然后我们就可以给这一个区域赋予类名 goods ,而区域内的节点,比如图片可以赋予类名 goods_pic ,图片下方文案可以赋予类名 goods_tit ,价格可以赋予类名 price ,这就是我们为元素节点添加类名的一般逻辑。 可以看出,通常我们去确定一个区域,一个组件的语义时,我们需要依据区域内节点的语义组合才能进行判定,比如上面的商品组件,需要依靠内部的图片、价格、文案等元素才能确定语义,从而确定类名。因此,语义化的处理方式,就是从容器元素的子节点出发,先确定子节点的语义,然后再推断出容器元素的语义,一层层往上进行推断,最终推断出整棵节点树完整的语义。 在语义化层,我们主要的处理对象就是经过布局算法层处理后的 JSON Schema 数据,我们称之为布局树,此时布局树已经具备了良好的结构,我们可以对它进行语义化推断操作。推断的流程就是从树的叶子节点出发,一层层向上冒泡到枝节点,最后再冒泡到根节点。 <div style="text-align: center;" > <img width="800" src="https://img12.360buyimg.com/img/s1734x1266_jfs/t1/155564/31/3555/279527/5fed997cE2facb891/f69f97899b664218.png" /> </div> 目前我们进行推断的依据主要是节点的位置、样式、大小、兄弟节点等因素,同时会结合不同节点的类型,组合一些智能化手段进行辅助推断。例如,最小叶子节点一般可能为图片、文本两种类型,针对文本我们可以通过 NLP 的方式去分析文本的词性、语义;针对部分图片,我们可以使用图片分类或识别的方式确定图片分类或者提取图片上的关键信息进行图片的语义判定。 为了确定每个节点的语义,我们需要组合一系列的规则对现有的事实(样式、位置等信息)进行推理,而同时,经过一些规则推理后又会得到新的事实,又需要经过其他规则推理之后才能得到最后确定的结果。所以,这是一个基于规则推理的推理系统,我们可以通过实现一个正向链的推理引擎,来帮助我们进行推理决策。 <div style="text-align: center;" > <img width="800" src="https://img12.360buyimg.com/img/s2038x886_jfs/t1/151580/21/12727/133368/5fed997cE5f52d2df/c6344c1d9ea40e82.png" /> </div> 例如,推断上述商品组件的过程,首先我们先找到具备价格因素的文本节点,命名为 price ,然后我们找到 price 附近,在树中所处层级相近的图片节点,并且该图片节点符合商品图大小的要求,这样我们就能基本确定同时包含价格和符合商品图特征的容器为商品容器,再根据容器中元素个数,图片附近是否有一段文本,以及对文本的 NER 分析,我们就能确定这段文本是否是商品名,从而确定其语义化类名。 在整个语义化层中,上述的判定规则只是冰山一角,我们结合整个电商场景,分析了大量设计稿与线上案例后总结了大量的判定规则来帮助我们进行合理化语义命名,同时在语义化过程中采用 NLP 分析、图片分类及识别等 AI 手段,我们将在后续专门撰写相关文章为大家进行具体介绍。 当然,得到节点类名只是语义化先阶段初步的成果,在未来我们将持续挖掘语义化,为后续字段逻辑绑定等实现打下坚实基础。 ## 5、阶段性成果 目前,在组件识别层、图层处理层、布局算法层和语义化层这四大核心模块我们已经去取得了关键性突破,已经可以实现对 Sketch 设计稿进行分析,将其转化成结构良好,具备语义化的,可以二次开发的代码,初步实现了设计稿到代码还原重构的阶段。 我们已经在大量的电商大促设计稿上进行测试,布局还原程度可达 90% 以上,而最终产出的代码可用率可以达到 80%,我们已经推动在部分内部业务中尝试进行使用。 ## 6、未来展望 未来,在上述核心模块完善的同时,我们将加入线上可视化编辑器,允许开发者对生成的代码进行人工干预调整,从而得到更好的代码,同时我们也将探索加入字段绑定和逻辑绑定的功能,让代码可以具备业务逻辑,让 Deco 具备 T3 左右工程师的水平,进一步提升产研的效率。 Deco 是一粒种子,也许它此时刚刚发芽,但我们对它期许颇多,我们希望通过 Deco 来探索前端智能化的道路,探索 AI 与前端结合的各种可能性,更重要的是,我们希望能够通过 Deco 开启产研的效率革命,在各种前端工程化、平台、方法论趋于完善的当下,探索为业务降本增效的另一种方式。 Deco 的未来,值得期待。 欢迎关注我们,我们的「凹凸技术揭秘」系列文章持续发布中。 - 1.[《凹凸实验室的过去与未来》](https://developer.jdcloud.com/article/1381) - 2.[《凹凸技术揭秘·羚珑智能设计平台·逐梦设计数智化》](https://developer.jdcloud.com/article/1382) - 3.《凹凸技术揭秘 · Deco 智能代码 · 开启产研效率革命》
原创文章,需联系作者,授权转载
上一篇:安全 | 四张图读懂等级保护2.0
下一篇:凹凸技术揭秘·羚珑页面可视化·成长蜕变之路
相关文章
前端十年回顾 | 漫画前端的前世今生
Taro小程序跨端开发入门实战
【技术干货】企业级扫描平台EOS关于JS扫描落地与实践!
凹凸实验室
文章数
7
阅读量
27005
作者其他文章
01
凹凸技术揭秘 · Deco 智能代码 · 开启产研效率革命
Deco 智能代码是凹凸实验室打造的设计稿一键生成多端代码解决方案,专注于产研效率革命
01
凹凸技术揭秘·羚珑页面可视化·成长蜕变之路
羚珑智能页面设计引擎是一款全场景通用页面可视化搭建解决方案,专注于泛零售领域的设计
01
凹凸实验室的过去与未来
凹凸实验室隶属于京东零售用户体验设计部(JDC),成立于 2015 年秋冬之交,诞生自深圳前海之滨,至今已走过 5 个年头,5 年的时光穿梭而过,凹凸实验室也不断发展壮大,从曾经专注前端的团队成长为如今涵盖前后端、全栈、算法、测试各类方向的全能型研发团队,工作模式也从传统的人力密集型研发转向创新型平台体系化研发,如今,凹凸的各类技术输出与沉淀在业界影响深远。
01
凹凸技术揭秘·羚珑智能设计平台·逐梦设计数智化
羚珑智能设计平台是由京东零售集团[用户体验设计部](jdrd.jd.com)打造的在线设计设计服务平台,专注于泛零售领域的设计,帮助客户解决日常经营过程中所碰到的各类设计需求,例如商品上新时的商品主图视频、各种节日大促时的商品主图更新,还有直播带货场景时所需要的各种设计物料等等。
最新回复
丨
点赞排行
共0条评论
凹凸实验室
文章数
7
阅读量
27005
作者其他文章
01
凹凸技术揭秘·羚珑页面可视化·成长蜕变之路
01
凹凸实验室的过去与未来
01
凹凸技术揭秘·羚珑智能设计平台·逐梦设计数智化
添加企业微信
获取1V1专业服务
扫码关注
京东云开发者公众号










