



1、背景
1.1 业务背景
近期在处理业务需求时,涉及储区储位的迁移工作。由于业务中存在“一品多储位、一储位多品”的复杂关系,且数据量较大,原由库存维护的储位数据需要整体迁移至履约团队进行统一管理。本次迁移的核心技术难点在于在有业务流量使用,不停机的数据库层面的数据迁移,如何保证数据一致性等。
1.2 数据迁移概述
随着业务的发展,系统重构与数据迁移几乎都会遇到。无论是分库分表、数据异构、老系统重构,还是大表结构变更,停机会影响业务,不停机数据迁移都是保障业务连续性的关键环节。尤其对于订单、商品、支付等有状态的核心数据,其一致性和可用性直接关系到公司业务的稳定运行。
数据迁移的常见场景包括:
- 分库分表
- 数据异构(如 MySQL → ES)
- 系统重构(新建表结构替换老系统)
- 大表结构变更
- 数据库迁移(同构或异构,如 MySQL → MySQL、MySQL → JED、MySQL → 大数据平台等)
1.3 技术选型与场景分析
根据迁移的同构/异构性质、数据量大小以及业务对停机的容忍度,可以选择不同的技术方案。
下表总结了常见场景的推荐方案及核心考量点:
数据迁移选型需综合考量数据库类型(同构/异构)、数据规模、一致性要求。
| 场景 | 推荐方案 |
| 同构、在线、大数据量 | 云服务DTS |
| 异构、在线、大数据量 | CDC组件 + 同步引擎 |
| 异构、定制化需求 | 自研程序 + Canal / Debezium |
| 复杂转换逻辑/非主流库 | ETL工具(Kettle、DataX) |
| 同构、小数据量、可停机 | 逻辑导出导入(mysqldump、pg_dump) |
方案如何选择采取
- 判断同构/异构
- 若为同构迁移(如 MySQL → MySQL),优先考虑数据库原生工具或云厂商的 DTS 服务。
- 若为异构迁移,则进入下一步。
- 评估业务场景与迁移目标
- 如果是上云场景,或在主流数据库之间迁移(如 Oracle → MySQL),强烈推荐使用云厂商的 DTS 服务,它能解决数据一致性、增量同步、切换可视化等绝大多数痛点。
- 如果数据转换逻辑非常复杂,或目标数据库为非主流存储,则应考虑 ETL 工具(如 Kettle)或自研方案,以获得最大的灵活性。
若不采取DTS,CDC的方式,结合业界常用技术组件,迁移过程中,借助消息队列或者binlog去做,避免侵入业务,降低复杂性。
%3B%7D%23mermaidchart-Nz-9M2%20.cluster%20rect%7Bfill%3A%23ffffde%3Bstroke%3A%23aaaa33%3Bstroke-width%3A1px%3B%7D%23mermaidchart-Nz-9M2%20.cluster%20text%7Bfill%3A%23333%3B%7D%23mermaidchart-Nz-9M2%20.cluster%20span%2C%23mermaidchart-Nz-9M2%20p%7Bcolor%3A%23333%3B%7D%23mermaidchart-Nz-9M2%20div.mermaidTooltip%7Bposition%3Aabsolute%3Btext-align%3Acenter%3Bmax-width%3A200px%3Bpadding%3A2px%3Bfont-family%3A%22trebuchet%20ms%22%2Cverdana%2Carial%2Csans-serif%3Bfont-size%3A12px%3Bbackground%3Ahsl(80%2C%20100%25%2C%2096.2745098039%25)%3Bborder%3A1px%20solid%20%23aaaa33%3Bborder-radius%3A2px%3Bpointer-events%3Anone%3Bz-index%3A100%3B%7D%23mermaidchart-Nz-9M2%20.flowchartTitleText%7Btext-anchor%3Amiddle%3Bfont-size%3A18px%3Bfill%3A%23333%3B%7D%23mermaidchart-Nz-9M2%20%3Aroot%7B--mermaid-font-family%3A%22trebuchet%20ms%22%2Cverdana%2Carial%2Csans-serif%3B%7D%23mermaidchart-Nz-9M2%20.source%26gt%3B*%7Bfill%3A%23e1f5fe!important%3Bstroke%3A%2301579b!important%3B%7D%23mermaidchart-Nz-9M2%20.source%20span%7Bfill%3A%23e1f5fe!important%3Bstroke%3A%2301579b!important%3B%7D%23mermaidchart-Nz-9M2%20.canal%26gt%3B*%7Bfill%3A%23fff3e0!important%3Bstroke%3A%23e65100!important%3B%7D%23mermaidchart-Nz-9M2%20.canal%20span%7Bfill%3A%23fff3e0!important%3Bstroke%3A%23e65100!important%3B%7D%23mermaidchart-Nz-9M2%20.kafka%26gt%3B*%7Bfill%3A%23f3e5f5!important%3Bstroke%3A%234a148c!important%3B%7D%23mermaidchart-Nz-9M2%20.kafka%20span%7Bfill%3A%23f3e5f5!important%3Bstroke%3A%234a148c!important%3B%7D%23mermaidchart-Nz-9M2%20.target%26gt%3B*%7Bfill%3A%23e8f5e8!important%3Bstroke%3A%231b5e20!important%3B%7D%23mermaidchart-Nz-9M2%20.target%20span%7Bfill%3A%23e8f5e8!important%3Bstroke%3A%231b5e20!important%3B%7D%3C%2Fstyle%3E%3Cg%3E%3Cmarker%20orient%3D%22auto%22%20markerHeight%3D%2212%22%20markerWidth%3D%2212%22%20markerUnits%3D%22userSpaceOnUse%22%20refY%3D%225%22%20refX%3D%226%22%20viewBox%3D%220%200%2010%2010%22%20class%3D%22marker%20flowchart%22%20id%3D%22mermaidchart-Nz-9M2_flowchart-pointEnd%22%3E%3Cpath%20style%3D%22stroke-width%3A%201%3B%20stroke-dasharray%3A%201%2C%200%3B%22%20class%3D%22arrowMarkerPath%22%20d%3D%22M%200%200%20L%2010%205%20L%200%2010%20z%22%3E%3C%2Fpath%3E%3C%2Fmarker%3E%3Cmarker%20orient%3D%22auto%22%20markerHeight%3D%2212%22%20markerWidth%3D%2212%22%20markerUnits%3D%22userSpaceOnUse%22%20refY%3D%225%22%20refX%3D%224.5%22%20viewBox%3D%220%200%2010%2010%22%20class%3D%22marker%20flowchart%22%20id%3D%22mermaidchart-Nz-9M2_flowchart-pointStart%22%3E%3Cpath%20style%3D%22stroke-width%3A%201%3B%20stroke-dasharray%3A%201%2C%200%3B%22%20class%3D%22arrowMarkerPath%22%20d%3D%22M%200%205%20L%2010%2010%20L%2010%200%20z%22%3E%3C%2Fpath%3E%3C%2Fmarker%3E%3Cmarker%20orient%3D%22auto%22%20markerHeight%3D%2211%22%20markerWidth%3D%2211%22%20markerUnits%3D%22userSpaceOnUse%22%20refY%3D%225%22%20refX%3D%2211%22%20viewBox%3D%220%200%2010%2010%22%20class%3D%22marker%20flowchart%22%20id%3D%22mermaidchart-Nz-9M2_flowchart-circleEnd%22%3E%3Ccircle%20style%3D%22stroke-width%3A%201%3B%20stroke-dasharray%3A%201%2C%200%3B%22%20class%3D%22arrowMarkerPath%22%20r%3D%225%22%20cy%3D%225%22%20cx%3D%225%22%3E%3C%2Fcircle%3E%3C%2Fmarker%3E%3Cmarker%20orient%3D%22auto%22%20markerHeight%3D%2211%22%20markerWidth%3D%2211%22%20markerUnits%3D%22userSpaceOnUse%22%20refY%3D%225%22%20refX%3D%22-1%22%20viewBox%3D%220%200%2010%2010%22%20class%3D%22marker%20flowchart%22%20id%3D%22mermaidchart-Nz-9M2_flowchart-circleStart%22%3E%3Ccircle%20style%3D%22stroke-width%3A%201%3B%20stroke-dasharray%3A%201%2C%200%3B%22%20class%3D%22arrowMarkerPath%22%20r%3D%225%22%20cy%3D%225%22%20cx%3D%225%22%3E%3C%2Fcircle%3E%3C%2Fmarker%3E%3Cmarker%20orient%3D%22auto%22%20markerHeight%3D%2211%22%20markerWidth%3D%2211%22%20markerUnits%3D%22userSpaceOnUse%22%20refY%3D%225.2%22%20refX%3D%2212%22%20viewBox%3D%220%200%2011%2011%22%20class%3D%22marker%20cross%20flowchart%22%20id%3D%22mermaidchart-Nz-9M2_flowchart-crossEnd%22%3E%3Cpath%20style%3D%22stroke-width%3A%202%3B%20stroke-dasharray%3A%201%2C%200%3B%22%20class%3D%22arrowMarkerPath%22%20d%3D%22M%201%2C1%20l%209%2C9%20M%2010%2C1%20l%20-9%2C9%22%3E%3C%2Fpath%3E%3C%2Fmarker%3E%3Cmarker%20orient%3D%22auto%22%20markerHeight%3D%2211%22%20markerWidth%3D%2211%22%20markerUnits%3D%22userSpaceOnUse%22%20refY%3D%225.2%22%20refX%3D%22-1%22%20viewBox%3D%220%200%2011%2011%22%20class%3D%22marker%20cross%20flowchart%22%20id%3D%22mermaidchart-Nz-9M2_flowchart-crossStart%22%3E%3Cpath%20style%3D%22stroke-width%3A%202%3B%20stroke-dasharray%3A%201%2C%200%3B%22%20class%3D%22arrowMarkerPath%22%20d%3D%22M%201%2C1%20l%209%2C9%20M%2010%2C1%20l%20-9%2C9%22%3E%3C%2Fpath%3E%3C%2Fmarker%3E%3Cg%20class%3D%22root%22%3E%3Cg%20class%3D%22clusters%22%3E%3Cg%20id%3D%22%E6%95%B0%E6%8D%AE%E7%9B%AE%E6%A0%87%22%20class%3D%22cluster%20default%20flowchart-label%22%3E%3Crect%20height%3D%22442.0928649902344%22%20width%3D%22110.85416793823242%22%20y%3D%220%22%20x%3D%22772.3854179382324%22%20ry%3D%220%22%20rx%3D%220%22%20style%3D%22%22%3E%3C%2Frect%3E%3Cg%20transform%3D%22translate(795.8125019073486%2C%200)%22%20class%3D%22cluster-label%22%3E%3CforeignObject%20height%3D%2226%22%20width%3D%2264%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22nodeLabel%22%3E%E6%95%B0%E6%8D%AE%E7%9B%AE%E6%A0%87%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20id%3D%22%E6%B6%88%E6%81%AF%E9%98%9F%E5%88%97%22%20class%3D%22cluster%20default%20flowchart-label%22%3E%3Crect%20height%3D%22379.1749496459961%22%20width%3D%22129%22%20y%3D%2227.778610229492188%22%20x%3D%22561.3854179382324%22%20ry%3D%220%22%20rx%3D%220%22%20style%3D%22%22%3E%3C%2Frect%3E%3Cg%20transform%3D%22translate(593.8854179382324%2C%2027.778610229492188)%22%20class%3D%22cluster-label%22%3E%3CforeignObject%20height%3D%2226%22%20width%3D%2264%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22nodeLabel%22%3E%E6%B6%88%E6%81%AF%E9%98%9F%E5%88%97%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20id%3D%22%E6%95%B0%E6%8D%AE%E9%87%87%E9%9B%86%22%20class%3D%22cluster%20default%20flowchart-label%22%3E%3Crect%20height%3D%22137%22%20width%3D%22140.5625%22%20y%3D%22165.70495414733887%22%20x%3D%22338.8229179382324%22%20ry%3D%220%22%20rx%3D%220%22%20style%3D%22%22%3E%3C%2Frect%3E%3Cg%20transform%3D%22translate(377.1041679382324%2C%20165.70495414733887)%22%20class%3D%22cluster-label%22%3E%3CforeignObject%20height%3D%2226%22%20width%3D%2264%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22nodeLabel%22%3E%E6%95%B0%E6%8D%AE%E9%87%87%E9%9B%86%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20id%3D%22%E6%95%B0%E6%8D%AE%E6%BA%90%22%20class%3D%22cluster%20default%20flowchart-label%22%3E%3Crect%20height%3D%22135.55722045898438%22%20width%3D%22288.8229179382324%22%20y%3D%22166.42634391784668%22%20x%3D%220%22%20ry%3D%220%22%20rx%3D%220%22%20style%3D%22%22%3E%3C%2Frect%3E%3Cg%20transform%3D%22translate(120.41145896911621%2C%20166.42634391784668)%22%20class%3D%22cluster-label%22%3E%3CforeignObject%20height%3D%2226%22%20width%3D%2248%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22nodeLabel%22%3E%E6%95%B0%E6%8D%AE%E6%BA%90%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20class%3D%22edgePaths%22%3E%3Cpath%20marker-end%3D%22url(%23mermaidchart-Nz-9M2_flowchart-pointEnd)%22%20style%3D%22fill%3Anone%3B%22%20class%3D%22edge-thickness-normal%20edge-pattern-solid%20flowchart-link%20LS-MySQL%20LE-BINLOG%22%20id%3D%22L-MySQL-BINLOG-0%22%20d%3D%22M85.854%2C234.205L90.021%2C234.205C94.188%2C234.205%2C102.521%2C234.205%2C109.971%2C234.205C117.421%2C234.205%2C123.988%2C234.205%2C127.271%2C234.205L130.554%2C234.205%22%3E%3C%2Fpath%3E%3Cpath%20marker-end%3D%22url(%23mermaidchart-Nz-9M2_flowchart-pointEnd)%22%20style%3D%22fill%3Anone%3B%22%20class%3D%22edge-thickness-normal%20edge-pattern-solid%20flowchart-link%20LS-BINLOG%20LE-CANAL%22%20id%3D%22L-BINLOG-CANAL-0%22%20d%3D%22M263.823%2C234.205L267.99%2C234.205C272.156%2C234.205%2C280.49%2C234.205%2C288.823%2C234.205C297.156%2C234.205%2C305.49%2C234.205%2C313.823%2C234.205C322.156%2C234.205%2C330.49%2C234.205%2C337.94%2C234.205C345.39%2C234.205%2C351.956%2C234.205%2C355.24%2C234.205L358.523%2C234.205%22%3E%3C%2Fpath%3E%3Cpath%20marker-end%3D%22url(%23mermaidchart-Nz-9M2_flowchart-pointEnd)%22%20style%3D%22fill%3Anone%3B%22%20class%3D%22edge-thickness-normal%20edge-pattern-solid%20flowchart-link%20LS-CANAL%20LE-KAFKA%22%20id%3D%22L-CANAL-KAFKA-0%22%20d%3D%22M454.385%2C234.205L458.552%2C234.205C462.719%2C234.205%2C471.052%2C234.205%2C482.052%2C234.205C493.052%2C234.205%2C506.719%2C234.205%2C520.385%2C234.205C534.052%2C234.205%2C547.719%2C234.205%2C557.835%2C234.205C567.952%2C234.205%2C574.519%2C234.205%2C577.802%2C234.205L581.085%2C234.205%22%3E%3C%2Fpath%3E%3Cpath%20marker-end%3D%22url(%23mermaidchart-Nz-9M2_flowchart-pointEnd)%22%20style%3D%22fill%3Anone%3B%22%20class%3D%22edge-thickness-normal%20edge-pattern-solid%20flowchart-link%20LS-KAFKA%20LE-TARGET1%22%20id%3D%22L-KAFKA-TARGET1-0%22%20d%3D%22M638.869%2C200.705L647.455%2C178.551C656.041%2C156.396%2C673.213%2C112.087%2C688.633%2C89.933C704.052%2C67.779%2C717.719%2C67.779%2C731.385%2C67.779C745.052%2C67.779%2C758.719%2C67.779%2C768.835%2C67.779C778.952%2C67.779%2C785.519%2C67.779%2C788.802%2C67.779L792.085%2C67.779%22%3E%3C%2Fpath%3E%3Cpath%20marker-end%3D%22url(%23mermaidchart-Nz-9M2_flowchart-pointEnd)%22%20style%3D%22fill%3Anone%3B%22%20class%3D%22edge-thickness-normal%20edge-pattern-solid%20flowchart-link%20LS-KAFKA%20LE-TARGET2%22%20id%3D%22L-KAFKA-TARGET2-0%22%20d%3D%22M665.385%2C201.206L669.552%2C197.725C673.719%2C194.245%2C682.052%2C187.283%2C693.052%2C183.802C704.052%2C180.321%2C717.719%2C180.321%2C731.385%2C180.321C745.052%2C180.321%2C758.719%2C180.321%2C770.489%2C180.321C782.259%2C180.321%2C792.133%2C180.321%2C797.07%2C180.321L802.007%2C180.321%22%3E%3C%2Fpath%3E%3Cpath%20marker-end%3D%22url(%23mermaidchart-Nz-9M2_flowchart-pointEnd)%22%20style%3D%22fill%3Anone%3B%22%20class%3D%22edge-thickness-normal%20edge-pattern-solid%20flowchart-link%20LS-KAFKA%20LE-TARGET3%22%20id%3D%22L-KAFKA-TARGET3-0%22%20d%3D%22M665.385%2C267.204L669.552%2C270.685C673.719%2C274.165%2C682.052%2C281.127%2C693.052%2C284.608C704.052%2C288.089%2C717.719%2C288.089%2C731.385%2C288.089C745.052%2C288.089%2C758.719%2C288.089%2C771.301%2C288.089C783.883%2C288.089%2C795.38%2C288.089%2C801.128%2C288.089L806.877%2C288.089%22%3E%3C%2Fpath%3E%3Cpath%20marker-end%3D%22url(%23mermaidchart-Nz-9M2_flowchart-pointEnd)%22%20style%3D%22fill%3Anone%3B%22%20class%3D%22edge-thickness-normal%20edge-pattern-solid%20flowchart-link%20LS-KAFKA%20LE-TARGET_OTHER%22%20id%3D%22L-KAFKA-TARGET_OTHER-0%22%20d%3D%22M640.065%2C267.705L648.451%2C287.52C656.838%2C307.334%2C673.612%2C346.964%2C688.832%2C366.778C704.052%2C386.593%2C717.719%2C386.593%2C731.385%2C386.593C745.052%2C386.593%2C758.719%2C386.593%2C770.698%2C386.593C782.678%2C386.593%2C792.97%2C386.593%2C798.116%2C386.593L803.263%2C386.593%22%3E%3C%2Fpath%3E%3C%2Fg%3E%3Cg%20class%3D%22edgeLabels%22%3E%3Cg%20class%3D%22edgeLabel%22%3E%3Cg%20transform%3D%22translate(0%2C%200)%22%20class%3D%22label%22%3E%3CforeignObject%20height%3D%220%22%20width%3D%220%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22edgeLabel%22%3E%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20class%3D%22edgeLabel%22%3E%3Cg%20transform%3D%22translate(0%2C%200)%22%20class%3D%22label%22%3E%3CforeignObject%20height%3D%220%22%20width%3D%220%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22edgeLabel%22%3E%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(520.3854179382324%2C%20234.20495414733887)%22%20class%3D%22edgeLabel%22%3E%3Cg%20transform%3D%22translate(-16%2C%20-13)%22%20class%3D%22label%22%3E%3CforeignObject%20height%3D%2226%22%20width%3D%2232%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22edgeLabel%22%3E%E6%8E%A8%E9%80%81%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(731.3854179382324%2C%2067.77861022949219)%22%20class%3D%22edgeLabel%22%3E%3Cg%20transform%3D%22translate(-16%2C%20-13)%22%20class%3D%22label%22%3E%3CforeignObject%20height%3D%2226%22%20width%3D%2232%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22edgeLabel%22%3E%E5%90%8C%E6%AD%A5%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(731.3854179382324%2C%20180.32104301452637)%22%20class%3D%22edgeLabel%22%3E%3Cg%20transform%3D%22translate(-16%2C%20-13)%22%20class%3D%22label%22%3E%3CforeignObject%20height%3D%2226%22%20width%3D%2232%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22edgeLabel%22%3E%E5%90%8C%E6%AD%A5%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(731.3854179382324%2C%20288.08886528015137)%22%20class%3D%22edgeLabel%22%3E%3Cg%20transform%3D%22translate(-16%2C%20-13)%22%20class%3D%22label%22%3E%3CforeignObject%20height%3D%2226%22%20width%3D%2232%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22edgeLabel%22%3E%E5%90%8C%E6%AD%A5%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(731.3854179382324%2C%20386.5928649902344)%22%20class%3D%22edgeLabel%22%3E%3Cg%20transform%3D%22translate(-16%2C%20-13)%22%20class%3D%22label%22%3E%3CforeignObject%20height%3D%2226%22%20width%3D%2232%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22edgeLabel%22%3E%E5%90%8C%E6%AD%A5%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20class%3D%22nodes%22%3E%3Cg%20transform%3D%22translate(827.8125019073486%2C%2067.77861022949219)%22%20data-id%3D%22TARGET1%22%20data-node%3D%22true%22%20id%3D%22flowchart-TARGET1-761%22%20class%3D%22node%20default%20target%20flowchart-label%22%3E%3Cpath%20transform%3D%22translate(-30.42708396911621%2C-32.77861243575735)%22%20d%3D%22M%200%2C8.185741623838235%20a%2030.42708396911621%2C8.185741623838235%200%2C0%2C0%2060.85416793823242%200%20a%2030.42708396911621%2C8.185741623838235%200%2C0%2C0%20-60.85416793823242%200%20l%200%2C49.18574162383823%20a%2030.42708396911621%2C8.185741623838235%200%2C0%2C0%2060.85416793823242%200%20l%200%2C-49.18574162383823%22%20style%3D%22%22%3E%3C%2Fpath%3E%3Cg%20transform%3D%22translate(-22.92708396911621%2C%20-13)%22%20style%3D%22%22%20class%3D%22label%22%3E%3Crect%3E%3C%2Frect%3E%3CforeignObject%20height%3D%2226%22%20width%3D%2245.85416793823242%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22nodeLabel%22%3EMySQL%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(827.8125019073486%2C%20180.32104301452637)%22%20data-id%3D%22TARGET2%22%20data-node%3D%22true%22%20id%3D%22flowchart-TARGET2-762%22%20class%3D%22node%20default%20target%20flowchart-label%22%3E%3Cpath%20transform%3D%22translate(-20.50520896911621%2C-29.76382025768961)%22%20d%3D%22M%200%2C6.1758801717930725%20a%2020.50520896911621%2C6.1758801717930725%200%2C0%2C0%2041.01041793823242%200%20a%2020.50520896911621%2C6.1758801717930725%200%2C0%2C0%20-41.01041793823242%200%20l%200%2C47.175880171793075%20a%2020.50520896911621%2C6.1758801717930725%200%2C0%2C0%2041.01041793823242%200%20l%200%2C-47.175880171793075%22%20style%3D%22%22%3E%3C%2Fpath%3E%3Cg%20transform%3D%22translate(-13.005208969116211%2C%20-13)%22%20style%3D%22%22%20class%3D%22label%22%3E%3Crect%3E%3C%2Frect%3E%3CforeignObject%20height%3D%2226%22%20width%3D%2226.010417938232422%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22nodeLabel%22%3EJED%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(827.8125019073486%2C%20288.08886528015137)%22%20data-id%3D%22TARGET3%22%20data-node%3D%22true%22%20id%3D%22flowchart-TARGET3-763%22%20class%3D%22node%20default%20target%20flowchart-label%22%3E%3Cpath%20transform%3D%22translate(-15.635416984558105%2C-28.003999588775535)%22%20d%3D%22M%200%2C5.002666392517023%20a%2015.635416984558105%2C5.002666392517023%200%2C0%2C0%2031.27083396911621%200%20a%2015.635416984558105%2C5.002666392517023%200%2C0%2C0%20-31.27083396911621%200%20l%200%2C46.00266639251702%20a%2015.635416984558105%2C5.002666392517023%200%2C0%2C0%2031.27083396911621%200%20l%200%2C-46.00266639251702%22%20style%3D%22%22%3E%3C%2Fpath%3E%3Cg%20transform%3D%22translate(-8.135416984558105%2C%20-13)%22%20style%3D%22%22%20class%3D%22label%22%3E%3Crect%3E%3C%2Frect%3E%3CforeignObject%20height%3D%2226%22%20width%3D%2216.27083396911621%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22nodeLabel%22%3EES%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(827.8125019073486%2C%20386.5928649902344)%22%20data-id%3D%22TARGET_OTHER%22%20data-node%3D%22true%22%20id%3D%22flowchart-TARGET_OTHER-764%22%20class%3D%22node%20default%20target%20flowchart-label%22%3E%3Crect%20height%3D%2241%22%20width%3D%2238.5%22%20y%3D%22-20.5%22%20x%3D%22-19.25%22%20ry%3D%220%22%20rx%3D%220%22%20style%3D%22%22%20class%3D%22basic%20label-container%22%3E%3C%2Frect%3E%3Cg%20transform%3D%22translate(-11.75%2C%20-13)%22%20style%3D%22%22%20class%3D%22label%22%3E%3Crect%3E%3C%2Frect%3E%3CforeignObject%20height%3D%2226%22%20width%3D%2223.5%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22nodeLabel%22%3E....%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(625.8854179382324%2C%20234.20495414733887)%22%20data-id%3D%22KAFKA%22%20data-node%3D%22true%22%20id%3D%22flowchart-KAFKA-760%22%20class%3D%22node%20default%20kafka%20flowchart-label%22%3E%3Crect%20height%3D%2267%22%20width%3D%2279%22%20y%3D%22-33.5%22%20x%3D%22-39.5%22%20ry%3D%220%22%20rx%3D%220%22%20style%3D%22%22%20class%3D%22basic%20label-container%22%3E%3C%2Frect%3E%3Cg%20transform%3D%22translate(-32%2C%20-26)%22%20style%3D%22%22%20class%3D%22label%22%3E%3Crect%3E%3C%2Frect%3E%3CforeignObject%20height%3D%2252%22%20width%3D%2264%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22nodeLabel%22%3EKafka%3Cbr%2F%3E%E6%B6%88%E6%81%AF%E9%98%9F%E5%88%97%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(409.1041679382324%2C%20234.20495414733887)%22%20data-id%3D%22CANAL%22%20data-node%3D%22true%22%20id%3D%22flowchart-CANAL-759%22%20class%3D%22node%20default%20canal%20flowchart-label%22%3E%3Crect%20height%3D%2267%22%20width%3D%2290.5625%22%20y%3D%22-33.5%22%20x%3D%22-45.28125%22%20ry%3D%220%22%20rx%3D%220%22%20style%3D%22%22%20class%3D%22basic%20label-container%22%3E%3C%2Frect%3E%3Cg%20transform%3D%22translate(-37.78125%2C%20-26)%22%20style%3D%22%22%20class%3D%22label%22%3E%3Crect%3E%3C%2Frect%3E%3CforeignObject%20height%3D%2252%22%20width%3D%2275.5625%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22nodeLabel%22%3ECanal%3Cbr%2F%3E%E7%9B%91%E5%90%ACbinlog%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(55.42708396911621%2C%20234.20495414733887)%22%20data-id%3D%22MySQL%22%20data-node%3D%22true%22%20id%3D%22flowchart-MySQL-757%22%20class%3D%22node%20default%20source%20flowchart-label%22%3E%3Cpath%20transform%3D%22translate(-30.42708396911621%2C-32.77861243575735)%22%20d%3D%22M%200%2C8.185741623838235%20a%2030.42708396911621%2C8.185741623838235%200%2C0%2C0%2060.85416793823242%200%20a%2030.42708396911621%2C8.185741623838235%200%2C0%2C0%20-60.85416793823242%200%20l%200%2C49.18574162383823%20a%2030.42708396911621%2C8.185741623838235%200%2C0%2C0%2060.85416793823242%200%20l%200%2C-49.18574162383823%22%20style%3D%22%22%3E%3C%2Fpath%3E%3Cg%20transform%3D%22translate(-22.92708396911621%2C%20-13)%22%20style%3D%22%22%20class%3D%22label%22%3E%3Crect%3E%3C%2Frect%3E%3CforeignObject%20height%3D%2226%22%20width%3D%2245.85416793823242%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22nodeLabel%22%3EMySQL%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(199.83854293823242%2C%20234.20495414733887)%22%20data-id%3D%22BINLOG%22%20data-node%3D%22true%22%20id%3D%22flowchart-BINLOG-758%22%20class%3D%22node%20default%20source%20flowchart-label%22%3E%3Crect%20height%3D%2241%22%20width%3D%22127.96875%22%20y%3D%22-20.5%22%20x%3D%22-63.984375%22%20ry%3D%220%22%20rx%3D%220%22%20style%3D%22%22%20class%3D%22basic%20label-container%22%3E%3C%2Frect%3E%3Cg%20transform%3D%22translate(-56.484375%2C%20-13)%22%20style%3D%22%22%20class%3D%22label%22%3E%3Crect%3E%3C%2Frect%3E%3CforeignObject%20height%3D%2226%22%20width%3D%22112.96875%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22nodeLabel%22%3Ebinlog%3A%20row%E6%A0%BC%E5%BC%8F%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3C%2Fg%3E%3C%2Fg%3E%3C%2Fg%3E%3C%2Fsvg%3E)
1.4 数据迁移核心挑战
| 挑战维度 | 具体问题 | 影响程度 |
| 数据一致性 | 迁移过程中数据丢失或不一致 | 高 |
| 业务连续性 | 迁移导致服务停机 | 极高 |
| 数据量级 | 海量数据迁移时间窗口 | 中 |
| 关联关系 | 表之间的复杂的业务逻辑 | 高 |
| 回滚能力 | 出现问题如何快速恢复 | 极高 |
二、迁移方案总览
2.1 整体架构图
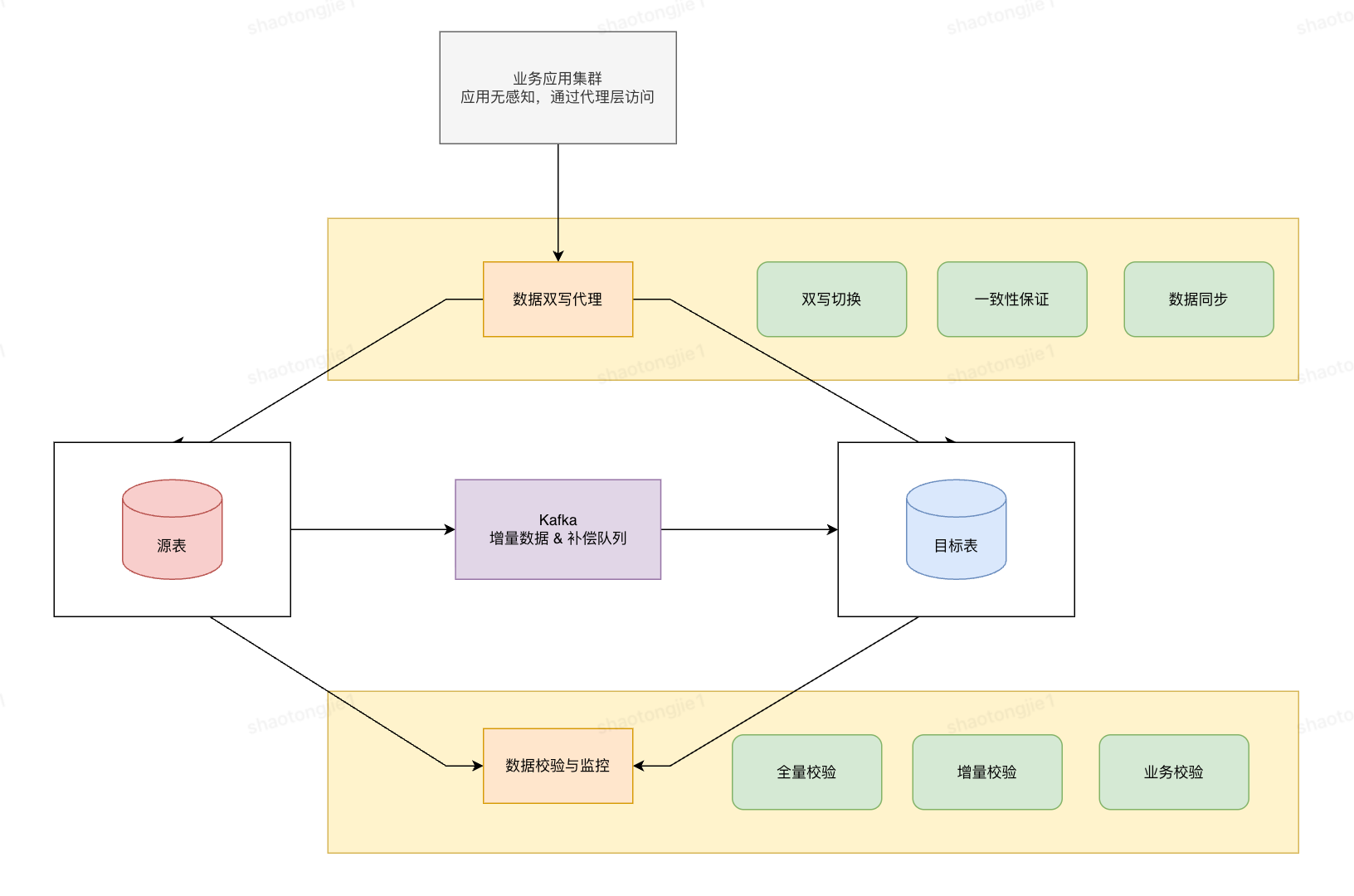
2.2 数据迁移过程
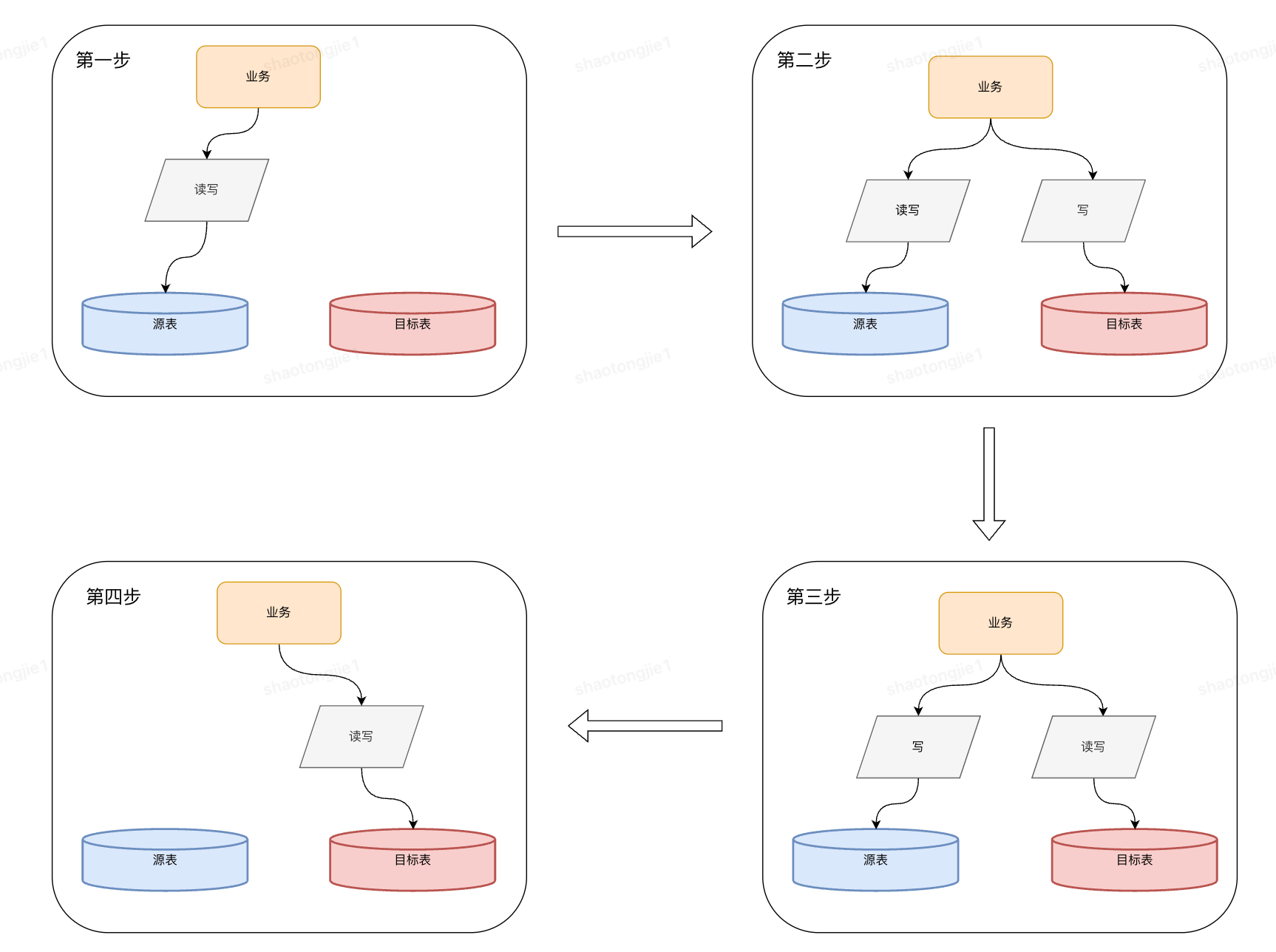
迁移过程概述:
- 初始化目标表:创建储区储位表。
- 存量迁移:用源表的数据初始化目标表。
- 存量数据校验:执行一次校验,并且修复数据,此时用源表数据修复目标表数据。
- 业务双写:业务代码开启双写,同时写目标表和源表,此时读源表,数据以源表为准。
- 增量校验:开启增量校验和数据修复,业务校验,保持一段时间。
- 切换双写顺序:此时读目标表,并且先写目标表,数据以目标表为准。
- 保持增量校验和数据修复。
- 切换为目标表单写,停掉源表写入,读写以目标表为准。
三、迁移实施方案
3.1 初始化目标表:创建储区储位表
CREATE TABLE `station_sku_cell` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`org_code` varchar(20) NOT NULL COMMENT '商家编码',
`station_id` bigint(20) NOT NULL COMMENT '中台门店id',
`sku_id` bigint(20) NOT NULL COMMENT '商品skuId',
`sku_name` varchar(200) NOT NULL DEFAULT '' COMMENT '商品名称',
`out_sku_id` varchar(50) DEFAULT NULL COMMENT '商家商品编号',
`upc` varchar(1024) DEFAULT NULL COMMENT '条形码',
`area_code` varchar(64) NOT NULL COMMENT '储区编码',
`cell_code` varchar(64) NOT NULL COMMENT '储位编码',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`create_pin` varchar(50) NOT NULL DEFAULT '' COMMENT '创建人',
`update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
`update_pin` varchar(50) NOT NULL DEFAULT '' COMMENT '更新人',
`sys_version` int(11) NOT NULL DEFAULT '0' COMMENT '版本号',
`yn` tinyint(4) NOT NULL DEFAULT '0' COMMENT '逻辑删除标示位',
`ts` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '时间戳',
PRIMARY KEY (`id`),
KEY `idx_org_station_cell` ( `org_code`,`station_id`,`cell_code`),
KEY `idx_org_station_sku` ( `org_code`,`station_id`,`sku_id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COMMENT='门店商品与储位关系表';
3.2 存量数据迁移
初始化表之后,怎么把源表数据导入源表数据呢,这里涉及到实时性,在低峰期的时候,通过调用的接口的同步目标表数据。如果不在低峰期,通过动态监控到MySQL的CPU,磁盘等,当cpu不高的时候写入,避免对业务产生影响。更新的时候,要注意避免旧的数据把新数据覆盖(比对版本号or更新时间)。
| 方案 | 实现方式 | 特点 |
| 方案一:历史备份 | 使用数据库现有备份文件恢复数据 | • 优点:对源系统无影响 • 缺点:数据可能不是最新的 |
| 方案二:源表导出 | 直接导出源表数据(SQL/CSV等格式) | • 优点:操作简单直接 • 缺点:可能影响源库性能 |
| 方案三:接口调用 | 通过业务接口,按商家、门店维度逐个获取并同步写入 | • 优点:数据实时性最好、业务逻辑完整、可按维度控制、便于问题排查、可灰度发布 • 缺点:速度相对较慢、对源系统有压力 |
部分核心代码展示
/**
* 同步储位信息
*
* @param orgCode 中台商家编码
* @param stationIds 门店ids
*/
ServiceResponse<Void> syncStationSkuCell(String orgCode, List<Integer> stationIds);
public void syncStationSkuCell(String orgCode, List<Integer> stationIds) {
long nextId = 0;
long size = 0;
while (true) {
logger.info("商品与储位关系-开始同步,nextId:{}, size:{}", nextId, size);
// 分页查询数据
List<StationSkuStock> stockList = stationSkuStockDao.selectByCellNotNullWithPagination(orgCode, stationIds, nextId);
if (CollectionUtils.isEmpty(stockList)) {
logger.info("商品与储位关系-同步完成");
return;
}
// 计算下一次 nextId
nextId = stockList.get(stockList.size() - 1).getId();
size += stockList.size();
// 构造待验证的记录列表
List<Map<String, Object>> checkRecords = stockList.stream()
.map(stock -> {
Map<String, Object> record = new HashMap<>();
record.put("orgCode", stock.getOrgCode());
record.put("stationId", stock.getStationId());
record.put("skuId", stock.getSkuId());
record.put("cellCode", stock.getChuWei());
return record;
})
.collect(Collectors.toList());
// 批量查询已存在的记录
List<StationSkuCell> existingRecords = stationSkuCellDao.batchCheckExists(checkRecords);
Set<String> existingKeys = new HashSet<>();
if (CollectionUtils.isNotEmpty(existingRecords)) {
// 构造已存在记录的 Set 用于快速比对
existingKeys = existingRecords.stream()
.map(record -> buildKey(record.getOrgCode(), record.getStationId(), record.getSkuId(), record.getCellCode()))
.collect(Collectors.toSet());
}
// 过滤掉已存在的记录
Set<String> finalExistingKeys = existingKeys;
List<StationSkuCell> needInsertCellList = stockList.stream()
.filter(stock -> !finalExistingKeys.contains(buildKey(stock.getOrgCode(), stock.getStationId(), stock.getSkuId(), stock.getChuWei())))
.map(stock -> {
StationSkuCell cell = new StationSkuCell();
cell.setOrgCode(stock.getOrgCode());
cell.setStationId(stock.getStationId());
cell.setSkuId(stock.getSkuId());
cell.setSkuName(stock.getSkuName());
cell.setOutSkuId(stock.getOutSkuId());
cell.setUpc(stock.getUpc());
if (StringUtils.isEmpty(stock.getChuQu())) {
StationCellInfo cellParam = new StationCellInfo();
cellParam.setStationId(stock.getStationId());
cellParam.setAreaCode(stock.getChuWei());
cellParam.setType(StationCellTypeEnum.CELL.getCode());
cellParam.setYn(false);
StationCellInfo stationCellInfo = stationCellInfoDao.getStationCellInfo(cellParam);
if (stationCellInfo != null) {
cell.setAreaCode(stationCellInfo.getBelongAreaCode());
} else {
cell.setAreaCode(stock.getChuWei());
}
} else {
cell.setAreaCode(stock.getChuQu());
}
cell.setCellCode(stock.getChuWei());
cell.setCreateTime(new Date());
cell.setCreatePin(Constant.WMS);
cell.setUpdateTime(new Date());
cell.setUpdatePin(Constant.WMS);
return cell;
})
.collect(Collectors.toList());
// 批量插入
if (CollectionUtils.isNotEmpty(needInsertCellList)) {
stationSkuCellDao.batchInsert(needInsertCellList);
}
}
3.3 存量数据校验
初始化数据完成后,建议立即进行数据校验与修复,主要原因如下:
- 备份数据滞后性:若使用历史备份(如昨天的备份),初始化后的目标库会缺失自备份以来的所有生产数据变更。
- 导出时间窗口:从数据导出到导入完成这段时间内,源库可能持续发生变更,导致目标库数据落后。
增量校验与修复方案
通过比对表的update_time字段进行增量数据同步:
- 校验逻辑:筛选目标表中
update_time晚于数据导出时间点的数据行。这些行代表在初始化窗口期内已发生变更,需要与源库对齐。 - 修复策略:直接用源表的对应行数据覆盖目标表。
3.4 业务开启双写,以源表为准
如何实现源表与目标表的数据双写?
两大实现方向对比:
| 方案类型 | 实现方式 | 优缺点 | 可行性 |
| 侵入式方案 | 直接修改业务代码,在写完源表后增加写目标表的逻辑 | • 缺点:工作量大、需排查所有业务代码、测试成本高、容易出错 | ❌ 不可行/代价高 |
| 非侵入式方案 | 通过数据库中间件/ORM框架的AOP机制实现 | • 优点:对业务代码无侵入、统一管控、易于维护 | ✅ 推荐采用 |
推荐非侵入式方案:
总结:采用非侵入式方案,通过ORM框架的AOP机制拦截数据变更操作,在不修改业务代码的前提下实现双写。
另外,双写可能出现的问题,
- 写目标表成功,写入源表失败,放到死信队列
- 写目标表失败,写源表成功,放到死信队列
结合业务不追求强一致性的时候,通过最终一致性去修复数据。
3.5 增量校验:开启增量校验和数据修复,业务校验,保持一段时间。
增量校验在保持双写持续进行的同时,对最新变更的数据进行实时或准实时的一致性验证,一旦发现数据不一致,立即触发自动修复机制。
方式1️⃣:利用更新时间戳
- 利用更新时间戳的思路很简单,就是定时查询每一张表,然后根据更新时间戳来判断某一行数据有没有发生变化。
// 记录上一次同步的最大时间戳
Timestamp lastTime = getLastSyncTime(); // 从数据库或缓存中读取
while (true) {
try {
// 1. 查询自上次同步以来发生过变更的数据
// SELECT * FROM source_table WHERE update_time >= ? ORDER BY update_time ASC
List<Row> updatedRows = sourceDao.findUpdatedRows(lastTime);
// 2. 遍历每一条变更的数据
for (Row sourceRow : updatedRows) {
// 3. 根据主键在目标库中查找对应数据
Object primaryKey = sourceRow.getId(); // 获取主键值
Row targetRow = targetDao.findById(primaryKey);
// 4. 比较源数据和目标数据是否一致
if (!isEquals(sourceRow, targetRow)) {
// 5. 如果不一致,执行修复
if (targetRow == null) {
// 目标库没有这条数据 -> 插入
targetDao.insert(sourceRow);
} else {
// 目标库有数据但内容不一致 -> 更新
targetDao.update(sourceRow);
}
log.info("修复数据: id={}", primaryKey);
}
}
// 6. 更新下一次查询的起始时间戳
if (!updatedRows.isEmpty()) {
// 取本次查询到的所有数据中最大的更新时间
Timestamp maxUpdateTime = updatedRows.stream()
.map(Row::getUpdateTime)
.max(Timestamp::compareTo)
.get();
lastTime = maxUpdateTime;
saveLastSyncTime(lastTime); // 持久化记录
}
// 7. 暂停1秒,避免对数据库造成过大压力
Thread.sleep(1000);
} catch (Exception e) {
log.error("同步过程发生异常", e);
// 异常处理:可以等待一段时间后重试
try {
Thread.sleep(5000);
} catch (InterruptedException ie) {
Thread.currentThread().interrupt();
break;
}
}
}
// 比较两个Row是否相等
boolean isEquals(Row source, Row target) {
if (source == null && target == null) return true;
if (source == null || target == null) return false;
// 比较关键字段(排除update_time等可能自动更新的字段)
return Objects.equals(source.getId(), target.getId())
&& Objects.equals(source.getName(), target.getName())
&& Objects.equals(source.getStatus(), target.getStatus())
// ... 其他需要比较的字段
;
}
方式2️⃣:通过binlog校验(推荐)
基于行的 binlog 模式,监听 binlog 的方案,用主键同时查询源表和目标表的当前状态进行比对,确保基于最新数据做决策,不一致时用源表覆盖目标表
%3B%7D%23mermaidchart-F5kyVU%20.cluster%20rect%7Bfill%3A%23ffffde%3Bstroke%3A%23aaaa33%3Bstroke-width%3A1px%3B%7D%23mermaidchart-F5kyVU%20.cluster%20text%7Bfill%3A%23333%3B%7D%23mermaidchart-F5kyVU%20.cluster%20span%2C%23mermaidchart-F5kyVU%20p%7Bcolor%3A%23333%3B%7D%23mermaidchart-F5kyVU%20div.mermaidTooltip%7Bposition%3Aabsolute%3Btext-align%3Acenter%3Bmax-width%3A200px%3Bpadding%3A2px%3Bfont-family%3A%22trebuchet%20ms%22%2Cverdana%2Carial%2Csans-serif%3Bfont-size%3A12px%3Bbackground%3Ahsl(80%2C%20100%25%2C%2096.2745098039%25)%3Bborder%3A1px%20solid%20%23aaaa33%3Bborder-radius%3A2px%3Bpointer-events%3Anone%3Bz-index%3A100%3B%7D%23mermaidchart-F5kyVU%20.flowchartTitleText%7Btext-anchor%3Amiddle%3Bfont-size%3A18px%3Bfill%3A%23333%3B%7D%23mermaidchart-F5kyVU%20%3Aroot%7B--mermaid-font-family%3A%22trebuchet%20ms%22%2Cverdana%2Carial%2Csans-serif%3B%7D%23mermaidchart-F5kyVU%20.mysql%26gt%3B*%7Bfill%3A%23ffcccc!important%3Bstroke%3A%23ff0000!important%3Bstroke-width%3A2px!important%3B%7D%23mermaidchart-F5kyVU%20.mysql%20span%7Bfill%3A%23ffcccc!important%3Bstroke%3A%23ff0000!important%3Bstroke-width%3A2px!important%3B%7D%23mermaidchart-F5kyVU%20.event%26gt%3B*%7Bfill%3A%23fff3e0!important%3Bstroke%3A%23ff9900!important%3Bstroke-width%3A2px!important%3B%7D%23mermaidchart-F5kyVU%20.event%20span%7Bfill%3A%23fff3e0!important%3Bstroke%3A%23ff9900!important%3Bstroke-width%3A2px!important%3B%7D%23mermaidchart-F5kyVU%20.query%26gt%3B*%7Bfill%3A%23e1f5fe!important%3Bstroke%3A%2301579b!important%3Bstroke-width%3A2px!important%3B%7D%23mermaidchart-F5kyVU%20.query%20span%7Bfill%3A%23e1f5fe!important%3Bstroke%3A%2301579b!important%3Bstroke-width%3A2px!important%3B%7D%23mermaidchart-F5kyVU%20.compare%26gt%3B*%7Bfill%3A%23e8f5e8!important%3Bstroke%3A%231b5e20!important%3Bstroke-width%3A2px!important%3B%7D%23mermaidchart-F5kyVU%20.compare%20span%7Bfill%3A%23e8f5e8!important%3Bstroke%3A%231b5e20!important%3Bstroke-width%3A2px!important%3B%7D%23mermaidchart-F5kyVU%20.repair%26gt%3B*%7Bfill%3A%23f3e5f5!important%3Bstroke%3A%234a148c!important%3Bstroke-width%3A2px!important%3B%7D%23mermaidchart-F5kyVU%20.repair%20span%7Bfill%3A%23f3e5f5!important%3Bstroke%3A%234a148c!important%3Bstroke-width%3A2px!important%3B%7D%23mermaidchart-F5kyVU%20.log%26gt%3B*%7Bfill%3A%23fff0f0!important%3Bstroke%3A%23b71c1c!important%3Bstroke-width%3A2px!important%3B%7D%23mermaidchart-F5kyVU%20.log%20span%7Bfill%3A%23fff0f0!important%3Bstroke%3A%23b71c1c!important%3Bstroke-width%3A2px!important%3B%7D%3C%2Fstyle%3E%3Cg%3E%3Cmarker%20orient%3D%22auto%22%20markerHeight%3D%2212%22%20markerWidth%3D%2212%22%20markerUnits%3D%22userSpaceOnUse%22%20refY%3D%225%22%20refX%3D%226%22%20viewBox%3D%220%200%2010%2010%22%20class%3D%22marker%20flowchart%22%20id%3D%22mermaidchart-F5kyVU_flowchart-pointEnd%22%3E%3Cpath%20style%3D%22stroke-width%3A%201%3B%20stroke-dasharray%3A%201%2C%200%3B%22%20class%3D%22arrowMarkerPath%22%20d%3D%22M%200%200%20L%2010%205%20L%200%2010%20z%22%3E%3C%2Fpath%3E%3C%2Fmarker%3E%3Cmarker%20orient%3D%22auto%22%20markerHeight%3D%2212%22%20markerWidth%3D%2212%22%20markerUnits%3D%22userSpaceOnUse%22%20refY%3D%225%22%20refX%3D%224.5%22%20viewBox%3D%220%200%2010%2010%22%20class%3D%22marker%20flowchart%22%20id%3D%22mermaidchart-F5kyVU_flowchart-pointStart%22%3E%3Cpath%20style%3D%22stroke-width%3A%201%3B%20stroke-dasharray%3A%201%2C%200%3B%22%20class%3D%22arrowMarkerPath%22%20d%3D%22M%200%205%20L%2010%2010%20L%2010%200%20z%22%3E%3C%2Fpath%3E%3C%2Fmarker%3E%3Cmarker%20orient%3D%22auto%22%20markerHeight%3D%2211%22%20markerWidth%3D%2211%22%20markerUnits%3D%22userSpaceOnUse%22%20refY%3D%225%22%20refX%3D%2211%22%20viewBox%3D%220%200%2010%2010%22%20class%3D%22marker%20flowchart%22%20id%3D%22mermaidchart-F5kyVU_flowchart-circleEnd%22%3E%3Ccircle%20style%3D%22stroke-width%3A%201%3B%20stroke-dasharray%3A%201%2C%200%3B%22%20class%3D%22arrowMarkerPath%22%20r%3D%225%22%20cy%3D%225%22%20cx%3D%225%22%3E%3C%2Fcircle%3E%3C%2Fmarker%3E%3Cmarker%20orient%3D%22auto%22%20markerHeight%3D%2211%22%20markerWidth%3D%2211%22%20markerUnits%3D%22userSpaceOnUse%22%20refY%3D%225%22%20refX%3D%22-1%22%20viewBox%3D%220%200%2010%2010%22%20class%3D%22marker%20flowchart%22%20id%3D%22mermaidchart-F5kyVU_flowchart-circleStart%22%3E%3Ccircle%20style%3D%22stroke-width%3A%201%3B%20stroke-dasharray%3A%201%2C%200%3B%22%20class%3D%22arrowMarkerPath%22%20r%3D%225%22%20cy%3D%225%22%20cx%3D%225%22%3E%3C%2Fcircle%3E%3C%2Fmarker%3E%3Cmarker%20orient%3D%22auto%22%20markerHeight%3D%2211%22%20markerWidth%3D%2211%22%20markerUnits%3D%22userSpaceOnUse%22%20refY%3D%225.2%22%20refX%3D%2212%22%20viewBox%3D%220%200%2011%2011%22%20class%3D%22marker%20cross%20flowchart%22%20id%3D%22mermaidchart-F5kyVU_flowchart-crossEnd%22%3E%3Cpath%20style%3D%22stroke-width%3A%202%3B%20stroke-dasharray%3A%201%2C%200%3B%22%20class%3D%22arrowMarkerPath%22%20d%3D%22M%201%2C1%20l%209%2C9%20M%2010%2C1%20l%20-9%2C9%22%3E%3C%2Fpath%3E%3C%2Fmarker%3E%3Cmarker%20orient%3D%22auto%22%20markerHeight%3D%2211%22%20markerWidth%3D%2211%22%20markerUnits%3D%22userSpaceOnUse%22%20refY%3D%225.2%22%20refX%3D%22-1%22%20viewBox%3D%220%200%2011%2011%22%20class%3D%22marker%20cross%20flowchart%22%20id%3D%22mermaidchart-F5kyVU_flowchart-crossStart%22%3E%3Cpath%20style%3D%22stroke-width%3A%202%3B%20stroke-dasharray%3A%201%2C%200%3B%22%20class%3D%22arrowMarkerPath%22%20d%3D%22M%201%2C1%20l%209%2C9%20M%2010%2C1%20l%20-9%2C9%22%3E%3C%2Fpath%3E%3C%2Fmarker%3E%3Cg%20class%3D%22root%22%3E%3Cg%20class%3D%22clusters%22%3E%3Cg%20id%3D%22Phase5%22%20class%3D%22cluster%20default%20flowchart-label%22%3E%3Crect%20height%3D%22495%22%20width%3D%22474.1979122161865%22%20y%3D%221508%22%20x%3D%220%22%20ry%3D%220%22%20rx%3D%220%22%20style%3D%22%22%3E%3C%2Frect%3E%3Cg%20transform%3D%22translate(173.09895610809326%2C%201508)%22%20class%3D%22cluster-label%22%3E%3CforeignObject%20height%3D%2226%22%20width%3D%22128%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22nodeLabel%22%3E%E9%98%B6%E6%AE%B5%E4%BA%94%EF%BC%9A%E6%95%B0%E6%8D%AE%E4%BF%AE%E5%A4%8D%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20id%3D%22Phase4%22%20class%3D%22cluster%20default%20flowchart-label%22%3E%3Crect%20height%3D%22371%22%20width%3D%22497.67187309265137%22%20y%3D%221087%22%20x%3D%22103.77603912353516%22%20ry%3D%220%22%20rx%3D%220%22%20style%3D%22%22%3E%3C%2Frect%3E%3Cg%20transform%3D%22translate(288.61197566986084%2C%201087)%22%20class%3D%22cluster-label%22%3E%3CforeignObject%20height%3D%2226%22%20width%3D%22128%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22nodeLabel%22%3E%E9%98%B6%E6%AE%B5%E5%9B%9B%EF%BC%9A%E6%95%B0%E6%8D%AE%E6%AF%94%E5%AF%B9%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20id%3D%22Phase3%22%20class%3D%22cluster%20default%20flowchart-label%22%3E%3Crect%20height%3D%22208%22%20width%3D%22422%22%20y%3D%22829%22%20x%3D%22109.59635543823242%22%20ry%3D%220%22%20rx%3D%220%22%20style%3D%22%22%3E%3C%2Frect%3E%3Cg%20transform%3D%22translate(256.5963554382324%2C%20829)%22%20class%3D%22cluster-label%22%3E%3CforeignObject%20height%3D%2226%22%20width%3D%22128%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22nodeLabel%22%3E%E9%98%B6%E6%AE%B5%E4%B8%89%EF%BC%9A%E5%8F%8C%E8%A1%A8%E6%9F%A5%E8%AF%A2%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20id%3D%22Phase2%22%20class%3D%22cluster%20default%20flowchart-label%22%3E%3Crect%20height%3D%22208%22%20width%3D%22379.25%22%20y%3D%22571%22%20x%3D%22125.77603912353516%22%20ry%3D%220%22%20rx%3D%220%22%20style%3D%22%22%3E%3C%2Frect%3E%3Cg%20transform%3D%22translate(251.40103912353516%2C%20571)%22%20class%3D%22cluster-label%22%3E%3CforeignObject%20height%3D%2226%22%20width%3D%22128%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22nodeLabel%22%3E%E9%98%B6%E6%AE%B5%E4%BA%8C%EF%BC%9A%E8%A7%A6%E5%8F%91%E5%A4%84%E7%90%86%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20id%3D%22Phase1%22%20class%3D%22cluster%20default%20flowchart-label%22%3E%3Crect%20height%3D%22521%22%20width%3D%22417.25%22%20y%3D%220%22%20x%3D%22152.52603912353516%22%20ry%3D%220%22%20rx%3D%220%22%20style%3D%22%22%3E%3C%2Frect%3E%3Cg%20transform%3D%22translate(297.15103912353516%2C%200)%22%20class%3D%22cluster-label%22%3E%3CforeignObject%20height%3D%2226%22%20width%3D%22128%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22nodeLabel%22%3E%E9%98%B6%E6%AE%B5%E4%B8%80%EF%BC%9A%E4%BA%8B%E4%BB%B6%E7%9B%91%E5%90%AC%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20class%3D%22edgePaths%22%3E%3Cpath%20marker-end%3D%22url(%23mermaidchart-F5kyVU_flowchart-pointEnd)%22%20style%3D%22fill%3Anone%3B%22%20class%3D%22edge-thickness-normal%20edge-pattern-solid%20flowchart-link%20LS-A%20LE-B%22%20id%3D%22L-A-B-0%22%20d%3D%22M366.276%2C92L366.276%2C98.333C366.276%2C104.667%2C366.276%2C117.333%2C366.276%2C129.117C366.276%2C140.9%2C366.276%2C151.8%2C366.276%2C157.25L366.276%2C162.7%22%3E%3C%2Fpath%3E%3Cpath%20marker-end%3D%22url(%23mermaidchart-F5kyVU_flowchart-pointEnd)%22%20style%3D%22fill%3Anone%3B%22%20class%3D%22edge-thickness-normal%20edge-pattern-solid%20flowchart-link%20LS-B%20LE-C%22%20id%3D%22L-B-C-0%22%20d%3D%22M366.276%2C209L366.276%2C213.167C366.276%2C217.333%2C366.276%2C225.667%2C366.342%2C233.2C366.408%2C240.734%2C366.54%2C247.467%2C366.606%2C250.834L366.672%2C254.201%22%3E%3C%2Fpath%3E%3Cpath%20marker-end%3D%22url(%23mermaidchart-F5kyVU_flowchart-pointEnd)%22%20style%3D%22fill%3Anone%3B%22%20class%3D%22edge-thickness-normal%20edge-pattern-solid%20flowchart-link%20LS-C%20LE-D1%22%20id%3D%22L-C-D1-0%22%20d%3D%22M331.56%2C344.284L314.138%2C356.403C296.715%2C368.523%2C261.871%2C392.761%2C244.448%2C410.331C227.026%2C427.9%2C227.026%2C438.8%2C227.026%2C444.25L227.026%2C449.7%22%3E%3C%2Fpath%3E%3Cpath%20marker-end%3D%22url(%23mermaidchart-F5kyVU_flowchart-pointEnd)%22%20style%3D%22fill%3Anone%3B%22%20class%3D%22edge-thickness-normal%20edge-pattern-solid%20flowchart-link%20LS-C%20LE-D2%22%20id%3D%22L-C-D2-0%22%20d%3D%22M361.095%2C373.819L360.25%2C381.016C359.405%2C388.212%2C357.716%2C402.606%2C356.871%2C415.253C356.026%2C427.9%2C356.026%2C438.8%2C356.026%2C444.25L356.026%2C449.7%22%3E%3C%2Fpath%3E%3Cpath%20marker-end%3D%22url(%23mermaidchart-F5kyVU_flowchart-pointEnd)%22%20style%3D%22fill%3Anone%3B%22%20class%3D%22edge-thickness-normal%20edge-pattern-solid%20flowchart-link%20LS-C%20LE-D3%22%20id%3D%22L-C-D3-0%22%20d%3D%22M399.648%2C346.628L413.878%2C358.357C428.107%2C370.085%2C456.567%2C393.543%2C470.796%2C410.721C485.026%2C427.9%2C485.026%2C438.8%2C485.026%2C444.25L485.026%2C449.7%22%3E%3C%2Fpath%3E%3Cpath%20marker-end%3D%22url(%23mermaidchart-F5kyVU_flowchart-pointEnd)%22%20style%3D%22fill%3Anone%3B%22%20class%3D%22edge-thickness-normal%20edge-pattern-solid%20flowchart-link%20LS-D1%20LE-E%22%20id%3D%22L-D1-E-0%22%20d%3D%22M227.026%2C496L227.026%2C500.167C227.026%2C504.333%2C227.026%2C512.667%2C227.026%2C521C227.026%2C529.333%2C227.026%2C537.667%2C227.026%2C546C227.026%2C554.333%2C227.026%2C562.667%2C232.211%2C570.491C237.396%2C578.315%2C247.765%2C585.63%2C252.95%2C589.287L258.135%2C592.945%22%3E%3C%2Fpath%3E%3Cpath%20marker-end%3D%22url(%23mermaidchart-F5kyVU_flowchart-pointEnd)%22%20style%3D%22fill%3Anone%3B%22%20class%3D%22edge-thickness-normal%20edge-pattern-solid%20flowchart-link%20LS-D2%20LE-E%22%20id%3D%22L-D2-E-0%22%20d%3D%22M356.026%2C496L356.026%2C500.167C356.026%2C504.333%2C356.026%2C512.667%2C356.026%2C521C356.026%2C529.333%2C356.026%2C537.667%2C356.026%2C546C356.026%2C554.333%2C356.026%2C562.667%2C350.841%2C570.491C345.656%2C578.315%2C335.287%2C585.63%2C330.102%2C589.287L324.917%2C592.945%22%3E%3C%2Fpath%3E%3Cpath%20marker-end%3D%22url(%23mermaidchart-F5kyVU_flowchart-pointEnd)%22%20style%3D%22fill%3Anone%3B%22%20class%3D%22edge-thickness-normal%20edge-pattern-solid%20flowchart-link%20LS-D3%20LE-E%22%20id%3D%22L-D3-E-0%22%20d%3D%22M485.026%2C496L485.026%2C500.167C485.026%2C504.333%2C485.026%2C512.667%2C485.026%2C521C485.026%2C529.333%2C485.026%2C537.667%2C485.026%2C546C485.026%2C554.333%2C485.026%2C562.667%2C461.408%2C572.387C437.791%2C582.107%2C390.556%2C593.214%2C366.938%2C598.767L343.321%2C604.321%22%3E%3C%2Fpath%3E%3Cpath%20marker-end%3D%22url(%23mermaidchart-F5kyVU_flowchart-pointEnd)%22%20style%3D%22fill%3Anone%3B%22%20class%3D%22edge-thickness-normal%20edge-pattern-solid%20flowchart-link%20LS-E%20LE-F%22%20id%3D%22L-E-F-0%22%20d%3D%22M291.526%2C637L291.526%2C641.167C291.526%2C645.333%2C291.526%2C653.667%2C291.526%2C661.117C291.526%2C668.567%2C291.526%2C675.133%2C291.526%2C678.417L291.526%2C681.7%22%3E%3C%2Fpath%3E%3Cpath%20marker-end%3D%22url(%23mermaidchart-F5kyVU_flowchart-pointEnd)%22%20style%3D%22fill%3Anone%3B%22%20class%3D%22edge-thickness-normal%20edge-pattern-solid%20flowchart-link%20LS-F%20LE-G1%22%20id%3D%22L-F-G1-0%22%20d%3D%22M248.331%2C754L242.959%2C758.167C237.586%2C762.333%2C226.841%2C770.667%2C221.469%2C779C216.096%2C787.333%2C216.096%2C795.667%2C216.096%2C804C216.096%2C812.333%2C216.096%2C820.667%2C216.096%2C828.117C216.096%2C835.567%2C216.096%2C842.133%2C216.096%2C845.417L216.096%2C848.7%22%3E%3C%2Fpath%3E%3Cpath%20marker-end%3D%22url(%23mermaidchart-F5kyVU_flowchart-pointEnd)%22%20style%3D%22fill%3Anone%3B%22%20class%3D%22edge-thickness-normal%20edge-pattern-solid%20flowchart-link%20LS-F%20LE-G2%22%20id%3D%22L-F-G2-0%22%20d%3D%22M347.026%2C746.356L358.704%2C751.797C370.383%2C757.237%2C393.74%2C768.119%2C405.418%2C777.726C417.096%2C787.333%2C417.096%2C795.667%2C417.096%2C804C417.096%2C812.333%2C417.096%2C820.667%2C417.096%2C828.117C417.096%2C835.567%2C417.096%2C842.133%2C417.096%2C845.417L417.096%2C848.7%22%3E%3C%2Fpath%3E%3Cpath%20marker-end%3D%22url(%23mermaidchart-F5kyVU_flowchart-pointEnd)%22%20style%3D%22fill%3Anone%3B%22%20class%3D%22edge-thickness-normal%20edge-pattern-solid%20flowchart-link%20LS-G1%20LE-H%22%20id%3D%22L-G1-H-0%22%20d%3D%22M216.096%2C921L216.096%2C925.167C216.096%2C929.333%2C216.096%2C937.667%2C216.096%2C945.117C216.096%2C952.567%2C216.096%2C959.133%2C216.096%2C962.417L216.096%2C965.7%22%3E%3C%2Fpath%3E%3Cpath%20marker-end%3D%22url(%23mermaidchart-F5kyVU_flowchart-pointEnd)%22%20style%3D%22fill%3Anone%3B%22%20class%3D%22edge-thickness-normal%20edge-pattern-solid%20flowchart-link%20LS-G2%20LE-I%22%20id%3D%22L-G2-I-0%22%20d%3D%22M417.096%2C921L417.096%2C925.167C417.096%2C929.333%2C417.096%2C937.667%2C417.096%2C945.117C417.096%2C952.567%2C417.096%2C959.133%2C417.096%2C962.417L417.096%2C965.7%22%3E%3C%2Fpath%3E%3Cpath%20marker-end%3D%22url(%23mermaidchart-F5kyVU_flowchart-pointEnd)%22%20style%3D%22fill%3Anone%3B%22%20class%3D%22edge-thickness-normal%20edge-pattern-solid%20flowchart-link%20LS-H%20LE-J%22%20id%3D%22L-H-J-0%22%20d%3D%22M216.096%2C1012L216.096%2C1016.167C216.096%2C1020.333%2C216.096%2C1028.667%2C216.096%2C1037C216.096%2C1045.333%2C216.096%2C1053.667%2C216.096%2C1062C216.096%2C1070.333%2C216.096%2C1078.667%2C222.356%2C1092.254C228.615%2C1105.842%2C241.135%2C1124.683%2C247.394%2C1134.104L253.654%2C1143.525%22%3E%3C%2Fpath%3E%3Cpath%20marker-end%3D%22url(%23mermaidchart-F5kyVU_flowchart-pointEnd)%22%20style%3D%22fill%3Anone%3B%22%20class%3D%22edge-thickness-normal%20edge-pattern-solid%20flowchart-link%20LS-I%20LE-J%22%20id%3D%22L-I-J-0%22%20d%3D%22M417.096%2C1012L417.096%2C1016.167C417.096%2C1020.333%2C417.096%2C1028.667%2C417.096%2C1037C417.096%2C1045.333%2C417.096%2C1053.667%2C417.096%2C1062C417.096%2C1070.333%2C417.096%2C1078.667%2C404.676%2C1094.26C392.256%2C1109.854%2C367.416%2C1132.707%2C354.996%2C1144.134L342.576%2C1155.561%22%3E%3C%2Fpath%3E%3Cpath%20marker-end%3D%22url(%23mermaidchart-F5kyVU_flowchart-pointEnd)%22%20style%3D%22fill%3Anone%3B%22%20class%3D%22edge-thickness-normal%20edge-pattern-solid%20flowchart-link%20LS-J%20LE-K%22%20id%3D%22L-J-K-0%22%20d%3D%22M346.74%2C1235.786L371.317%2C1251.155C395.893%2C1266.524%2C445.045%2C1297.262%2C469.622%2C1318.081C494.198%2C1338.9%2C494.198%2C1349.8%2C494.198%2C1355.25L494.198%2C1360.7%22%3E%3C%2Fpath%3E%3Cpath%20marker-end%3D%22url(%23mermaidchart-F5kyVU_flowchart-pointEnd)%22%20style%3D%22fill%3Anone%3B%22%20class%3D%22edge-thickness-normal%20edge-pattern-solid%20flowchart-link%20LS-J%20LE-L%22%20id%3D%22L-J-L-0%22%20d%3D%22M258.863%2C1257.337L251.735%2C1269.114C244.607%2C1280.891%2C230.352%2C1304.446%2C223.224%2C1323.839C216.096%2C1343.233%2C216.096%2C1358.467%2C216.096%2C1366.083L216.096%2C1373.7%22%3E%3C%2Fpath%3E%3Cpath%20marker-end%3D%22url(%23mermaidchart-F5kyVU_flowchart-pointEnd)%22%20style%3D%22fill%3Anone%3B%22%20class%3D%22edge-thickness-normal%20edge-pattern-solid%20flowchart-link%20LS-L%20LE-M%22%20id%3D%22L-L-M-0%22%20d%3D%22M216.096%2C1420L216.096%2C1426.333C216.096%2C1432.667%2C216.096%2C1445.333%2C216.096%2C1455.833C216.096%2C1466.333%2C216.096%2C1474.667%2C216.096%2C1483C216.096%2C1491.333%2C216.096%2C1499.667%2C216.096%2C1507.117C216.096%2C1514.567%2C216.096%2C1521.133%2C216.096%2C1524.417L216.096%2C1527.7%22%3E%3C%2Fpath%3E%3Cpath%20marker-end%3D%22url(%23mermaidchart-F5kyVU_flowchart-pointEnd)%22%20style%3D%22fill%3Anone%3B%22%20class%3D%22edge-thickness-normal%20edge-pattern-solid%20flowchart-link%20LS-M%20LE-N%22%20id%3D%22L-M-N-0%22%20d%3D%22M216.096%2C1600L216.096%2C1604.167C216.096%2C1608.333%2C216.096%2C1616.667%2C216.162%2C1624.2C216.228%2C1631.734%2C216.36%2C1638.467%2C216.426%2C1641.834L216.492%2C1645.201%22%3E%3C%2Fpath%3E%3Cpath%20marker-end%3D%22url(%23mermaidchart-F5kyVU_flowchart-pointEnd)%22%20style%3D%22fill%3Anone%3B%22%20class%3D%22edge-thickness-normal%20edge-pattern-solid%20flowchart-link%20LS-N%20LE-O%22%20id%3D%22L-N-O-0%22%20d%3D%22M182.456%2C1736.36L166.5%2C1748.3C150.544%2C1760.24%2C118.631%2C1784.12%2C102.675%2C1801.51C86.719%2C1818.9%2C86.719%2C1829.8%2C86.719%2C1835.25L86.719%2C1840.7%22%3E%3C%2Fpath%3E%3Cpath%20marker-end%3D%22url(%23mermaidchart-F5kyVU_flowchart-pointEnd)%22%20style%3D%22fill%3Anone%3B%22%20class%3D%22edge-thickness-normal%20edge-pattern-solid%20flowchart-link%20LS-N%20LE-P%22%20id%3D%22L-N-P-0%22%20d%3D%22M226.548%2C1760.548L228.054%2C1768.457C229.56%2C1776.365%2C232.572%2C1792.183%2C234.077%2C1805.541C235.583%2C1818.9%2C235.583%2C1829.8%2C235.583%2C1835.25L235.583%2C1840.7%22%3E%3C%2Fpath%3E%3Cpath%20marker-end%3D%22url(%23mermaidchart-F5kyVU_flowchart-pointEnd)%22%20style%3D%22fill%3Anone%3B%22%20class%3D%22edge-thickness-normal%20edge-pattern-solid%20flowchart-link%20LS-N%20LE-Q%22%20id%3D%22L-N-Q-0%22%20d%3D%22M254.687%2C1732.41L276.65%2C1745.008C298.614%2C1757.607%2C342.541%2C1782.803%2C364.505%2C1800.852C386.469%2C1818.9%2C386.469%2C1829.8%2C386.469%2C1835.25L386.469%2C1840.7%22%3E%3C%2Fpath%3E%3Cpath%20marker-end%3D%22url(%23mermaidchart-F5kyVU_flowchart-pointEnd)%22%20style%3D%22fill%3Anone%3B%22%20class%3D%22edge-thickness-normal%20edge-pattern-solid%20flowchart-link%20LS-O%20LE-R%22%20id%3D%22L-O-R-0%22%20d%3D%22M86.719%2C1887L86.719%2C1891.167C86.719%2C1895.333%2C86.719%2C1903.667%2C98.198%2C1911.871C109.678%2C1920.074%2C132.637%2C1928.149%2C144.117%2C1932.186L155.597%2C1936.223%22%3E%3C%2Fpath%3E%3Cpath%20marker-end%3D%22url(%23mermaidchart-F5kyVU_flowchart-pointEnd)%22%20style%3D%22fill%3Anone%3B%22%20class%3D%22edge-thickness-normal%20edge-pattern-solid%20flowchart-link%20LS-P%20LE-R%22%20id%3D%22L-P-R-0%22%20d%3D%22M235.583%2C1887L235.583%2C1891.167C235.583%2C1895.333%2C235.583%2C1903.667%2C234.147%2C1911.188C232.71%2C1918.709%2C229.836%2C1925.419%2C228.4%2C1928.773L226.963%2C1932.128%22%3E%3C%2Fpath%3E%3Cpath%20marker-end%3D%22url(%23mermaidchart-F5kyVU_flowchart-pointEnd)%22%20style%3D%22fill%3Anone%3B%22%20class%3D%22edge-thickness-normal%20edge-pattern-solid%20flowchart-link%20LS-Q%20LE-R%22%20id%3D%22L-Q-R-0%22%20d%3D%22M386.469%2C1887L386.469%2C1891.167C386.469%2C1895.333%2C386.469%2C1903.667%2C368.177%2C1912.718C349.885%2C1921.77%2C313.301%2C1931.54%2C295.009%2C1936.425L276.717%2C1941.311%22%3E%3C%2Fpath%3E%3Cpath%20marker-end%3D%22url(%23mermaidchart-F5kyVU_flowchart-pointEnd)%22%20style%3D%22fill%3Anone%3B%22%20class%3D%22edge-thickness-normal%20edge-pattern-solid%20flowchart-link%20LS-R%20LE-S%22%20id%3D%22L-R-S-0%22%20d%3D%22M216.096%2C1978L216.096%2C1982.167C216.096%2C1986.333%2C216.096%2C1994.667%2C216.096%2C2003C216.096%2C2011.333%2C216.096%2C2019.667%2C228.393%2C2028.893C240.689%2C2038.119%2C265.282%2C2048.237%2C277.578%2C2053.297L289.875%2C2058.356%22%3E%3C%2Fpath%3E%3Cpath%20marker-end%3D%22url(%23mermaidchart-F5kyVU_flowchart-pointEnd)%22%20style%3D%22fill%3Anone%3B%22%20class%3D%22edge-thickness-normal%20edge-pattern-solid%20flowchart-link%20LS-K%20LE-S%22%20id%3D%22L-K-S-0%22%20d%3D%22M494.198%2C1433L494.198%2C1437.167C494.198%2C1441.333%2C494.198%2C1449.667%2C494.198%2C1458C494.198%2C1466.333%2C494.198%2C1474.667%2C494.198%2C1483C494.198%2C1491.333%2C494.198%2C1499.667%2C494.198%2C1513.583C494.198%2C1527.5%2C494.198%2C1547%2C494.198%2C1566.5C494.198%2C1586%2C494.198%2C1605.5%2C494.198%2C1629.417C494.198%2C1653.333%2C494.198%2C1681.667%2C494.198%2C1712.167C494.198%2C1742.667%2C494.198%2C1775.333%2C494.198%2C1801.417C494.198%2C1827.5%2C494.198%2C1847%2C494.198%2C1864.333C494.198%2C1881.667%2C494.198%2C1896.833%2C494.198%2C1912C494.198%2C1927.167%2C494.198%2C1942.333%2C494.198%2C1957.5C494.198%2C1972.667%2C494.198%2C1987.833%2C494.198%2C1999.583C494.198%2C2011.333%2C494.198%2C2019.667%2C482.939%2C2028.679C471.68%2C2037.692%2C449.162%2C2047.383%2C437.903%2C2052.229L426.644%2C2057.075%22%3E%3C%2Fpath%3E%3C%2Fg%3E%3Cg%20class%3D%22edgeLabels%22%3E%3Cg%20transform%3D%22translate(366.27603912353516%2C%20130)%22%20class%3D%22edgeLabel%22%3E%3Cg%20transform%3D%22translate(-32%2C%20-13)%22%20class%3D%22label%22%3E%3CforeignObject%20height%3D%2226%22%20width%3D%2264%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22edgeLabel%22%3E%E5%AE%9E%E6%97%B6%E7%9B%91%E5%90%AC%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20class%3D%22edgeLabel%22%3E%3Cg%20transform%3D%22translate(0%2C%200)%22%20class%3D%22label%22%3E%3CforeignObject%20height%3D%220%22%20width%3D%220%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22edgeLabel%22%3E%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(227.02603912353516%2C%20417)%22%20class%3D%22edgeLabel%22%3E%3Cg%20transform%3D%22translate(-24.4375%2C%20-13)%22%20class%3D%22label%22%3E%3CforeignObject%20height%3D%2226%22%20width%3D%2248.875%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22edgeLabel%22%3EINSERT%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(356.02603912353516%2C%20417)%22%20class%3D%22edgeLabel%22%3E%3Cg%20transform%3D%22translate(-27.42708396911621%2C%20-13)%22%20class%3D%22label%22%3E%3CforeignObject%20height%3D%2226%22%20width%3D%2254.85416793823242%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22edgeLabel%22%3EUPDATE%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(485.02603912353516%2C%20417)%22%20class%3D%22edgeLabel%22%3E%3Cg%20transform%3D%22translate(-26.45833396911621%2C%20-13)%22%20class%3D%22label%22%3E%3CforeignObject%20height%3D%2226%22%20width%3D%2252.91666793823242%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22edgeLabel%22%3EDELETE%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20class%3D%22edgeLabel%22%3E%3Cg%20transform%3D%22translate(0%2C%200)%22%20class%3D%22label%22%3E%3CforeignObject%20height%3D%220%22%20width%3D%220%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22edgeLabel%22%3E%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20class%3D%22edgeLabel%22%3E%3Cg%20transform%3D%22translate(0%2C%200)%22%20class%3D%22label%22%3E%3CforeignObject%20height%3D%220%22%20width%3D%220%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22edgeLabel%22%3E%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20class%3D%22edgeLabel%22%3E%3Cg%20transform%3D%22translate(0%2C%200)%22%20class%3D%22label%22%3E%3CforeignObject%20height%3D%220%22%20width%3D%220%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22edgeLabel%22%3E%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20class%3D%22edgeLabel%22%3E%3Cg%20transform%3D%22translate(0%2C%200)%22%20class%3D%22label%22%3E%3CforeignObject%20height%3D%220%22%20width%3D%220%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22edgeLabel%22%3E%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20class%3D%22edgeLabel%22%3E%3Cg%20transform%3D%22translate(0%2C%200)%22%20class%3D%22label%22%3E%3CforeignObject%20height%3D%220%22%20width%3D%220%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22edgeLabel%22%3E%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20class%3D%22edgeLabel%22%3E%3Cg%20transform%3D%22translate(0%2C%200)%22%20class%3D%22label%22%3E%3CforeignObject%20height%3D%220%22%20width%3D%220%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22edgeLabel%22%3E%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20class%3D%22edgeLabel%22%3E%3Cg%20transform%3D%22translate(0%2C%200)%22%20class%3D%22label%22%3E%3CforeignObject%20height%3D%220%22%20width%3D%220%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22edgeLabel%22%3E%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20class%3D%22edgeLabel%22%3E%3Cg%20transform%3D%22translate(0%2C%200)%22%20class%3D%22label%22%3E%3CforeignObject%20height%3D%220%22%20width%3D%220%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22edgeLabel%22%3E%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20class%3D%22edgeLabel%22%3E%3Cg%20transform%3D%22translate(0%2C%200)%22%20class%3D%22label%22%3E%3CforeignObject%20height%3D%220%22%20width%3D%220%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22edgeLabel%22%3E%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20class%3D%22edgeLabel%22%3E%3Cg%20transform%3D%22translate(0%2C%200)%22%20class%3D%22label%22%3E%3CforeignObject%20height%3D%220%22%20width%3D%220%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22edgeLabel%22%3E%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(494.1979122161865%2C%201328)%22%20class%3D%22edgeLabel%22%3E%3Cg%20transform%3D%22translate(-16%2C%20-13)%22%20class%3D%22label%22%3E%3CforeignObject%20height%3D%2226%22%20width%3D%2232%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22edgeLabel%22%3E%E4%B8%80%E8%87%B4%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(216.09635543823242%2C%201328)%22%20class%3D%22edgeLabel%22%3E%3Cg%20transform%3D%22translate(-24%2C%20-13)%22%20class%3D%22label%22%3E%3CforeignObject%20height%3D%2226%22%20width%3D%2248%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22edgeLabel%22%3E%E4%B8%8D%E4%B8%80%E8%87%B4%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20class%3D%22edgeLabel%22%3E%3Cg%20transform%3D%22translate(0%2C%200)%22%20class%3D%22label%22%3E%3CforeignObject%20height%3D%220%22%20width%3D%220%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22edgeLabel%22%3E%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20class%3D%22edgeLabel%22%3E%3Cg%20transform%3D%22translate(0%2C%200)%22%20class%3D%22label%22%3E%3CforeignObject%20height%3D%220%22%20width%3D%220%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22edgeLabel%22%3E%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(86.71875%2C%201808)%22%20class%3D%22edgeLabel%22%3E%3Cg%20transform%3D%22translate(-32%2C%20-13)%22%20class%3D%22label%22%3E%3CforeignObject%20height%3D%2226%22%20width%3D%2264%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22edgeLabel%22%3E%E7%9B%AE%E6%A0%87%E7%BC%BA%E5%A4%B1%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(235.58333206176758%2C%201808)%22%20class%3D%22edgeLabel%22%3E%3Cg%20transform%3D%22translate(-40%2C%20-13)%22%20class%3D%22label%22%3E%3CforeignObject%20height%3D%2226%22%20width%3D%2280%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22edgeLabel%22%3E%E6%95%B0%E6%8D%AE%E4%B8%8D%E4%B8%80%E8%87%B4%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(386.46874618530273%2C%201808)%22%20class%3D%22edgeLabel%22%3E%3Cg%20transform%3D%22translate(-32%2C%20-13)%22%20class%3D%22label%22%3E%3CforeignObject%20height%3D%2226%22%20width%3D%2264%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22edgeLabel%22%3E%E7%9B%AE%E6%A0%87%E5%A4%9A%E4%BD%99%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20class%3D%22edgeLabel%22%3E%3Cg%20transform%3D%22translate(0%2C%200)%22%20class%3D%22label%22%3E%3CforeignObject%20height%3D%220%22%20width%3D%220%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22edgeLabel%22%3E%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20class%3D%22edgeLabel%22%3E%3Cg%20transform%3D%22translate(0%2C%200)%22%20class%3D%22label%22%3E%3CforeignObject%20height%3D%220%22%20width%3D%220%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22edgeLabel%22%3E%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20class%3D%22edgeLabel%22%3E%3Cg%20transform%3D%22translate(0%2C%200)%22%20class%3D%22label%22%3E%3CforeignObject%20height%3D%220%22%20width%3D%220%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22edgeLabel%22%3E%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20class%3D%22edgeLabel%22%3E%3Cg%20transform%3D%22translate(0%2C%200)%22%20class%3D%22label%22%3E%3CforeignObject%20height%3D%220%22%20width%3D%220%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22edgeLabel%22%3E%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20class%3D%22edgeLabel%22%3E%3Cg%20transform%3D%22translate(0%2C%200)%22%20class%3D%22label%22%3E%3CforeignObject%20height%3D%220%22%20width%3D%220%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22edgeLabel%22%3E%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20class%3D%22nodes%22%3E%3Cg%20transform%3D%22translate(216.09635543823242%2C%201566.5)%22%20data-id%3D%22M%22%20data-node%3D%22true%22%20id%3D%22flowchart-M-881%22%20class%3D%22node%20default%20repair%20flowchart-label%22%3E%3Crect%20height%3D%2267%22%20width%3D%2295%22%20y%3D%22-33.5%22%20x%3D%22-47.5%22%20ry%3D%220%22%20rx%3D%220%22%20style%3D%22%22%20class%3D%22basic%20label-container%22%3E%3C%2Frect%3E%3Cg%20transform%3D%22translate(-40%2C%20-26)%22%20style%3D%22%22%20class%3D%22label%22%3E%3Crect%3E%3C%2Frect%3E%3CforeignObject%20height%3D%2252%22%20width%3D%2280%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22nodeLabel%22%3E%E7%94%A8%E6%BA%90%E8%A1%A8%E6%95%B0%E6%8D%AE%3Cbr%2F%3E%E8%A6%86%E7%9B%96%E7%9B%AE%E6%A0%87%E8%A1%A8%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(216.09635543823242%2C%201710)%22%20data-id%3D%22N%22%20data-node%3D%22true%22%20id%3D%22flowchart-N-883%22%20class%3D%22node%20default%20repair%20flowchart-label%22%3E%3Cpolygon%20style%3D%22%22%20transform%3D%22translate(-60%2C60)%22%20class%3D%22label-container%22%20points%3D%2260%2C0%20120%2C-60%2060%2C-120%200%2C-60%22%3E%3C%2Fpolygon%3E%3Cg%20transform%3D%22translate(-32%2C%20-13)%22%20style%3D%22%22%20class%3D%22label%22%3E%3Crect%3E%3C%2Frect%3E%3CforeignObject%20height%3D%2226%22%20width%3D%2264%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22nodeLabel%22%3E%E6%93%8D%E4%BD%9C%E7%B1%BB%E5%9E%8B%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(86.71875%2C%201866.5)%22%20data-id%3D%22O%22%20data-node%3D%22true%22%20id%3D%22flowchart-O-885%22%20class%3D%22node%20default%20repair%20flowchart-label%22%3E%3Crect%20height%3D%2241%22%20width%3D%2295.875%22%20y%3D%22-20.5%22%20x%3D%22-47.9375%22%20ry%3D%220%22%20rx%3D%220%22%20style%3D%22%22%20class%3D%22basic%20label-container%22%3E%3C%2Frect%3E%3Cg%20transform%3D%22translate(-40.4375%2C%20-13)%22%20style%3D%22%22%20class%3D%22label%22%3E%3Crect%3E%3C%2Frect%3E%3CforeignObject%20height%3D%2226%22%20width%3D%2280.875%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22nodeLabel%22%3E%E6%89%A7%E8%A1%8CINSERT%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(235.58333206176758%2C%201866.5)%22%20data-id%3D%22P%22%20data-node%3D%22true%22%20id%3D%22flowchart-P-887%22%20class%3D%22node%20default%20repair%20flowchart-label%22%3E%3Crect%20height%3D%2241%22%20width%3D%22101.85417175292969%22%20y%3D%22-20.5%22%20x%3D%22-50.927085876464844%22%20ry%3D%220%22%20rx%3D%220%22%20style%3D%22%22%20class%3D%22basic%20label-container%22%3E%3C%2Frect%3E%3Cg%20transform%3D%22translate(-43.427085876464844%2C%20-13)%22%20style%3D%22%22%20class%3D%22label%22%3E%3Crect%3E%3C%2Frect%3E%3CforeignObject%20height%3D%2226%22%20width%3D%2286.85417175292969%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22nodeLabel%22%3E%E6%89%A7%E8%A1%8CUPDATE%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(386.46874618530273%2C%201866.5)%22%20data-id%3D%22Q%22%20data-node%3D%22true%22%20id%3D%22flowchart-Q-889%22%20class%3D%22node%20default%20repair%20flowchart-label%22%3E%3Crect%20height%3D%2241%22%20width%3D%2299.91667175292969%22%20y%3D%22-20.5%22%20x%3D%22-49.958335876464844%22%20ry%3D%220%22%20rx%3D%220%22%20style%3D%22%22%20class%3D%22basic%20label-container%22%3E%3C%2Frect%3E%3Cg%20transform%3D%22translate(-42.458335876464844%2C%20-13)%22%20style%3D%22%22%20class%3D%22label%22%3E%3Crect%3E%3C%2Frect%3E%3CforeignObject%20height%3D%2226%22%20width%3D%2284.91667175292969%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22nodeLabel%22%3E%E6%89%A7%E8%A1%8CDELETE%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(216.09635543823242%2C%201957.5)%22%20data-id%3D%22R%22%20data-node%3D%22true%22%20id%3D%22flowchart-R-891%22%20class%3D%22node%20default%20log%20flowchart-label%22%3E%3Crect%20height%3D%2241%22%20width%3D%22111%22%20y%3D%22-20.5%22%20x%3D%22-55.5%22%20ry%3D%220%22%20rx%3D%220%22%20style%3D%22%22%20class%3D%22basic%20label-container%22%3E%3C%2Frect%3E%3Cg%20transform%3D%22translate(-48%2C%20-13)%22%20style%3D%22%22%20class%3D%22label%22%3E%3Crect%3E%3C%2Frect%3E%3CforeignObject%20height%3D%2226%22%20width%3D%2296%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22nodeLabel%22%3E%E8%AE%B0%E5%BD%95%E4%BF%AE%E5%A4%8D%E6%97%A5%E5%BF%97%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(291.52603912353516%2C%201201)%22%20data-id%3D%22J%22%20data-node%3D%22true%22%20id%3D%22flowchart-J-873%22%20class%3D%22node%20default%20compare%20flowchart-label%22%3E%3Cpolygon%20style%3D%22%22%20transform%3D%22translate(-89%2C89)%22%20class%3D%22label-container%22%20points%3D%2289%2C0%20178%2C-89%2089%2C-178%200%2C-89%22%3E%3C%2Fpolygon%3E%3Cg%20transform%3D%22translate(-48%2C%20-26)%22%20style%3D%22%22%20class%3D%22label%22%3E%3Crect%3E%3C%2Frect%3E%3CforeignObject%20height%3D%2252%22%20width%3D%2296%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22nodeLabel%22%3E%E6%95%B0%E6%8D%AE%E6%AF%94%E5%AF%B9%3Cbr%2F%3E%E5%9F%BA%E4%BA%8E%E6%9C%80%E6%96%B0%E7%8A%B6%E6%80%81%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(494.1979122161865%2C%201399.5)%22%20data-id%3D%22K%22%20data-node%3D%22true%22%20id%3D%22flowchart-K-877%22%20class%3D%22node%20default%20compare%20flowchart-label%22%3E%3Crect%20height%3D%2267%22%20width%3D%22111%22%20y%3D%22-33.5%22%20x%3D%22-55.5%22%20ry%3D%220%22%20rx%3D%220%22%20style%3D%22%22%20class%3D%22basic%20label-container%22%3E%3C%2Frect%3E%3Cg%20transform%3D%22translate(-48%2C%20-26)%22%20style%3D%22%22%20class%3D%22label%22%3E%3Crect%3E%3C%2Frect%3E%3CforeignObject%20height%3D%2252%22%20width%3D%2296%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22nodeLabel%22%3E%E8%AE%B0%E5%BD%95%E6%A0%A1%E9%AA%8C%E9%80%9A%E8%BF%87%3Cbr%2F%3E%E6%97%A0%E9%9C%80%E5%A4%84%E7%90%86%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(216.09635543823242%2C%201399.5)%22%20data-id%3D%22L%22%20data-node%3D%22true%22%20id%3D%22flowchart-L-879%22%20class%3D%22node%20default%20repair%20flowchart-label%22%3E%3Crect%20height%3D%2241%22%20width%3D%22111%22%20y%3D%22-20.5%22%20x%3D%22-55.5%22%20ry%3D%220%22%20rx%3D%220%22%20style%3D%22%22%20class%3D%22basic%20label-container%22%3E%3C%2Frect%3E%3Cg%20transform%3D%22translate(-48%2C%20-13)%22%20style%3D%22%22%20class%3D%22label%22%3E%3Crect%3E%3C%2Frect%3E%3CforeignObject%20height%3D%2226%22%20width%3D%2296%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22nodeLabel%22%3E%E8%A7%A6%E5%8F%91%E4%BF%AE%E5%A4%8D%E6%B5%81%E7%A8%8B%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(216.09635543823242%2C%20887.5)%22%20data-id%3D%22G1%22%20data-node%3D%22true%22%20id%3D%22flowchart-G1-865%22%20class%3D%22node%20default%20query%20flowchart-label%22%3E%3Crect%20height%3D%2267%22%20width%3D%22132.7291717529297%22%20y%3D%22-33.5%22%20x%3D%22-66.36458587646484%22%20ry%3D%220%22%20rx%3D%220%22%20style%3D%22%22%20class%3D%22basic%20label-container%22%3E%3C%2Frect%3E%3Cg%20transform%3D%22translate(-58.864585876464844%2C%20-26)%22%20style%3D%22%22%20class%3D%22label%22%3E%3Crect%3E%3C%2Frect%3E%3CforeignObject%20height%3D%2252%22%20width%3D%22117.72917175292969%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22nodeLabel%22%3E%E6%9F%A5%E8%AF%A2%E6%BA%90%E8%A1%A8%3Cbr%2F%3Eget%20current%20data%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(417.0963554382324%2C%20887.5)%22%20data-id%3D%22G2%22%20data-node%3D%22true%22%20id%3D%22flowchart-G2-867%22%20class%3D%22node%20default%20query%20flowchart-label%22%3E%3Crect%20height%3D%2267%22%20width%3D%22132.7291717529297%22%20y%3D%22-33.5%22%20x%3D%22-66.36458587646484%22%20ry%3D%220%22%20rx%3D%220%22%20style%3D%22%22%20class%3D%22basic%20label-container%22%3E%3C%2Frect%3E%3Cg%20transform%3D%22translate(-58.864585876464844%2C%20-26)%22%20style%3D%22%22%20class%3D%22label%22%3E%3Crect%3E%3C%2Frect%3E%3CforeignObject%20height%3D%2252%22%20width%3D%22117.72917175292969%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22nodeLabel%22%3E%E6%9F%A5%E8%AF%A2%E7%9B%AE%E6%A0%87%E8%A1%A8%3Cbr%2F%3Eget%20current%20data%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(216.09635543823242%2C%20991.5)%22%20data-id%3D%22H%22%20data-node%3D%22true%22%20id%3D%22flowchart-H-869%22%20class%3D%22node%20default%20query%20flowchart-label%22%3E%3Crect%20height%3D%2241%22%20width%3D%22143%22%20y%3D%22-20.5%22%20x%3D%22-71.5%22%20ry%3D%220%22%20rx%3D%220%22%20style%3D%22%22%20class%3D%22basic%20label-container%22%3E%3C%2Frect%3E%3Cg%20transform%3D%22translate(-64%2C%20-13)%22%20style%3D%22%22%20class%3D%22label%22%3E%3Crect%3E%3C%2Frect%3E%3CforeignObject%20height%3D%2226%22%20width%3D%22128%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22nodeLabel%22%3E%E8%8E%B7%E5%8F%96%E6%BA%90%E8%A1%A8%E5%BD%93%E5%89%8D%E6%95%B0%E6%8D%AE%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(417.0963554382324%2C%20991.5)%22%20data-id%3D%22I%22%20data-node%3D%22true%22%20id%3D%22flowchart-I-871%22%20class%3D%22node%20default%20query%20flowchart-label%22%3E%3Crect%20height%3D%2241%22%20width%3D%22159%22%20y%3D%22-20.5%22%20x%3D%22-79.5%22%20ry%3D%220%22%20rx%3D%220%22%20style%3D%22%22%20class%3D%22basic%20label-container%22%3E%3C%2Frect%3E%3Cg%20transform%3D%22translate(-72%2C%20-13)%22%20style%3D%22%22%20class%3D%22label%22%3E%3Crect%3E%3C%2Frect%3E%3CforeignObject%20height%3D%2226%22%20width%3D%22144%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22nodeLabel%22%3E%E8%8E%B7%E5%8F%96%E7%9B%AE%E6%A0%87%E8%A1%A8%E5%BD%93%E5%89%8D%E6%95%B0%E6%8D%AE%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(291.52603912353516%2C%20616.5)%22%20data-id%3D%22E%22%20data-node%3D%22true%22%20id%3D%22flowchart-E-857%22%20class%3D%22node%20default%20query%20flowchart-label%22%3E%3Crect%20height%3D%2241%22%20width%3D%2293.27083587646484%22%20y%3D%22-20.5%22%20x%3D%22-46.63541793823242%22%20ry%3D%220%22%20rx%3D%220%22%20style%3D%22%22%20class%3D%22basic%20label-container%22%3E%3C%2Frect%3E%3Cg%20transform%3D%22translate(-39.13541793823242%2C%20-13)%22%20style%3D%22%22%20class%3D%22label%22%3E%3Crect%3E%3C%2Frect%3E%3CforeignObject%20height%3D%2226%22%20width%3D%2278.27083587646484%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22nodeLabel%22%3E%E6%8F%90%E5%8F%96%E4%B8%BB%E9%94%AEID%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(291.52603912353516%2C%20720.5)%22%20data-id%3D%22F%22%20data-node%3D%22true%22%20id%3D%22flowchart-F-863%22%20class%3D%22node%20default%20query%20flowchart-label%22%3E%3Crect%20height%3D%2267%22%20width%3D%22111%22%20y%3D%22-33.5%22%20x%3D%22-55.5%22%20ry%3D%220%22%20rx%3D%220%22%20style%3D%22%22%20class%3D%22basic%20label-container%22%3E%3C%2Frect%3E%3Cg%20transform%3D%22translate(-48%2C%20-26)%22%20style%3D%22%22%20class%3D%22label%22%3E%3Crect%3E%3C%2Frect%3E%3CforeignObject%20height%3D%2252%22%20width%3D%2296%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22nodeLabel%22%3E%E6%A0%B9%E6%8D%AE%E4%B8%BB%E9%94%AE%3Cbr%2F%3E%E5%90%8C%E6%97%B6%E5%8F%91%E8%B5%B7%E6%9F%A5%E8%AF%A2%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(366.27603912353516%2C%20188.5)%22%20data-id%3D%22B%22%20data-node%3D%22true%22%20id%3D%22flowchart-B-847%22%20class%3D%22node%20default%20event%20flowchart-label%22%3E%3Crect%20height%3D%2241%22%20width%3D%22111%22%20y%3D%22-20.5%22%20x%3D%22-55.5%22%20ry%3D%220%22%20rx%3D%220%22%20style%3D%22%22%20class%3D%22basic%20label-container%22%3E%3C%2Frect%3E%3Cg%20transform%3D%22translate(-48%2C%20-13)%22%20style%3D%22%22%20class%3D%22label%22%3E%3Crect%3E%3C%2Frect%3E%3CforeignObject%20height%3D%2226%22%20width%3D%2296%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22nodeLabel%22%3E%E6%8D%95%E8%8E%B7%E5%8F%98%E6%9B%B4%E4%BA%8B%E4%BB%B6%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(366.27603912353516%2C%2058.5)%22%20data-id%3D%22A%22%20data-node%3D%22true%22%20id%3D%22flowchart-A-846%22%20class%3D%22node%20default%20mysql%20flowchart-label%22%3E%3Crect%20height%3D%2267%22%20width%3D%22108.78125%22%20y%3D%22-33.5%22%20x%3D%22-54.390625%22%20ry%3D%220%22%20rx%3D%220%22%20style%3D%22%22%20class%3D%22basic%20label-container%22%3E%3C%2Frect%3E%3Cg%20transform%3D%22translate(-46.890625%2C%20-26)%22%20style%3D%22%22%20class%3D%22label%22%3E%3Crect%3E%3C%2Frect%3E%3CforeignObject%20height%3D%2252%22%20width%3D%2293.78125%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22nodeLabel%22%3EMySQL%20Binlog%3Cbr%2F%3ERow%E6%A0%BC%E5%BC%8F%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(366.27603912353516%2C%20319)%22%20data-id%3D%22C%22%20data-node%3D%22true%22%20id%3D%22flowchart-C-849%22%20class%3D%22node%20default%20event%20flowchart-label%22%3E%3Cpolygon%20style%3D%22%22%20transform%3D%22translate(-60%2C60)%22%20class%3D%22label-container%22%20points%3D%2260%2C0%20120%2C-60%2060%2C-120%200%2C-60%22%3E%3C%2Fpolygon%3E%3Cg%20transform%3D%22translate(-32%2C%20-13)%22%20style%3D%22%22%20class%3D%22label%22%3E%3Crect%3E%3C%2Frect%3E%3CforeignObject%20height%3D%2226%22%20width%3D%2264%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22nodeLabel%22%3E%E4%BA%8B%E4%BB%B6%E7%B1%BB%E5%9E%8B%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(227.02603912353516%2C%20475.5)%22%20data-id%3D%22D1%22%20data-node%3D%22true%22%20id%3D%22flowchart-D1-851%22%20class%3D%22node%20default%20event%20flowchart-label%22%3E%3Crect%20height%3D%2241%22%20width%3D%2279%22%20y%3D%22-20.5%22%20x%3D%22-39.5%22%20ry%3D%220%22%20rx%3D%220%22%20style%3D%22%22%20class%3D%22basic%20label-container%22%3E%3C%2Frect%3E%3Cg%20transform%3D%22translate(-32%2C%20-13)%22%20style%3D%22%22%20class%3D%22label%22%3E%3Crect%3E%3C%2Frect%3E%3CforeignObject%20height%3D%2226%22%20width%3D%2264%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22nodeLabel%22%3E%E6%8F%92%E5%85%A5%E4%BA%8B%E4%BB%B6%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(356.02603912353516%2C%20475.5)%22%20data-id%3D%22D2%22%20data-node%3D%22true%22%20id%3D%22flowchart-D2-853%22%20class%3D%22node%20default%20event%20flowchart-label%22%3E%3Crect%20height%3D%2241%22%20width%3D%2279%22%20y%3D%22-20.5%22%20x%3D%22-39.5%22%20ry%3D%220%22%20rx%3D%220%22%20style%3D%22%22%20class%3D%22basic%20label-container%22%3E%3C%2Frect%3E%3Cg%20transform%3D%22translate(-32%2C%20-13)%22%20style%3D%22%22%20class%3D%22label%22%3E%3Crect%3E%3C%2Frect%3E%3CforeignObject%20height%3D%2226%22%20width%3D%2264%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22nodeLabel%22%3E%E6%9B%B4%E6%96%B0%E4%BA%8B%E4%BB%B6%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(485.02603912353516%2C%20475.5)%22%20data-id%3D%22D3%22%20data-node%3D%22true%22%20id%3D%22flowchart-D3-855%22%20class%3D%22node%20default%20event%20flowchart-label%22%3E%3Crect%20height%3D%2241%22%20width%3D%2279%22%20y%3D%22-20.5%22%20x%3D%22-39.5%22%20ry%3D%220%22%20rx%3D%220%22%20style%3D%22%22%20class%3D%22basic%20label-container%22%3E%3C%2Frect%3E%3Cg%20transform%3D%22translate(-32%2C%20-13)%22%20style%3D%22%22%20class%3D%22label%22%3E%3Crect%3E%3C%2Frect%3E%3CforeignObject%20height%3D%2226%22%20width%3D%2264%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22nodeLabel%22%3E%E5%88%A0%E9%99%A4%E4%BA%8B%E4%BB%B6%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(690.125%2C%2058.5)%22%20data-id%3D%22title%22%20data-node%3D%22true%22%20id%3D%22flowchart-title-845%22%20class%3D%22node%20default%20default%20flowchart-label%22%3E%3Crect%20height%3D%2267%22%20width%3D%22170.6979217529297%22%20y%3D%22-33.5%22%20x%3D%22-85.34896087646484%22%20ry%3D%220%22%20rx%3D%220%22%20style%3D%22%22%20class%3D%22basic%20label-container%22%3E%3C%2Frect%3E%3Cg%20transform%3D%22translate(-77.84896087646484%2C%20-26)%22%20style%3D%22%22%20class%3D%22label%22%3E%3Crect%3E%3C%2Frect%3E%3CforeignObject%20height%3D%2252%22%20width%3D%22155.6979217529297%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22nodeLabel%22%3EBinlog%E8%A7%A6%E5%8F%91%E5%BC%8F%E6%A0%A1%E9%AA%8C%E6%96%B9%E6%A1%88%3Cbr%2F%3E%E5%9F%BA%E4%BA%8E%E4%B8%BB%E9%94%AE%E7%9A%84%E5%8F%8C%E8%A1%A8%E6%AF%94%E5%AF%B9%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%20transform%3D%22translate(358.27603912353516%2C%202086.5)%22%20data-id%3D%22S%22%20data-node%3D%22true%22%20id%3D%22flowchart-S-897%22%20class%3D%22node%20default%20log%20flowchart-label%22%3E%3Crect%20height%3D%2267%22%20width%3D%22127%22%20y%3D%22-33.5%22%20x%3D%22-63.5%22%20ry%3D%220%22%20rx%3D%220%22%20style%3D%22%22%20class%3D%22basic%20label-container%22%3E%3C%2Frect%3E%3Cg%20transform%3D%22translate(-56%2C%20-26)%22%20style%3D%22%22%20class%3D%22label%22%3E%3Crect%3E%3C%2Frect%3E%3CforeignObject%20height%3D%2252%22%20width%3D%22112%22%3E%3Cdiv%20style%3D%22display%3A%20inline-block%3B%20white-space%3A%20nowrap%3B%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F1999%2Fxhtml%22%3E%3Cspan%20class%3D%22nodeLabel%22%3E%E6%A0%A1%E9%AA%8C%E4%BF%AE%E5%A4%8D%E5%AE%8C%E6%88%90%3Cbr%2F%3E%E6%9C%80%E7%BB%88%E4%B8%80%E8%87%B4%E6%80%A7%E8%BE%BE%E6%88%90%3C%2Fspan%3E%3C%2Fdiv%3E%3C%2FforeignObject%3E%3C%2Fg%3E%3C%2Fg%3E%3C%2Fg%3E%3C%2Fg%3E%3C%2Fg%3E%3C%2Fsvg%3E)
执行步骤概述:
1. 监听 Binlog
↓
2. 收到变更事件(INSERT/UPDATE/DELETE)
↓
3. 从事件中提取主键 ID
↓
4. 根据主键同时查询源表和目标表
↓
5. 比对两表数据
↓
6. 发现不一致 → 用源表数据修复目标表
↓
7. 记录校验结果和修复日志
📝 伪代码实现
// 1. 初始化 Binlog 监听器
binlogListener = new BinlogListener()
// 2. 注册事件处理器
binlogListener.onEvent((event) -> {
// 提取事件中的主键
rowId = event.getPrimaryKey()
tableName = event.getTableName()
// 3. 根据主键查询源表和目标表
sourceRow = querySourceById(tableName, rowId)
targetRow = queryTargetById(tableName, rowId)
// 4. 数据比对
if (!compareData(sourceRow, targetRow)) {
// 5. 发现不一致,用源表修复目标表
repairTarget(tableName, sourceRow)
// 6. 记录修复日志
logRepair(tableName, rowId)
}
})
// 7. 启动监听
binlogListener.start()
方案3️⃣:对源表和目标表的 Binlog进行校验
你可能会想到一个更“聪明”的方案:既然源表和目标表都有 Binlog,那为什么不直接比较两者的 Binlog 呢?如果 Binlog 不一致,不就说明目标表出问题了吗?
理论上可行,但实践中存在两个问题:
1. 时间差问题(双写延迟)
- 同一笔数据变更,源表和目标表的 Binlog到达时间可能相差很大
- 你可能先收到源表的 Binlog,过了很久才收到目标表的;也可能反过来
- 这意味着你必须缓存其中一端的 Binlog,等待另一端的 Binlog 到达后才能进行比较,大大增加了系统复杂度
2. 顺序乱序问题(并发写入)
- 如果对同一行数据连续进行两次更新,Binlog 的接收顺序可能与产生顺序不一致
- 例如:你可能先收到源表第一次更新的 Binlog,后收到目标表第二次更新的 Binlog
- 要解决这个问题,你必须引入消息队列等组件对 Binlog 进行排序,确保消费顺序与产生顺序完全一致
结论:不可取。虽然这个方案能减少对数据库的直接查询压力,但它引入了极高的系统复杂度:
- 需要处理时间差 → 引入缓存机制
- 需要保证顺序 → 引入消息队列排序
- 整体架构变得臃肿且难以维护
3.6 切换双写顺序,此时读目标表,并且先写目标表,数据以目标表为准。
采用的是灰度可回滚的双写策略。
我们将双写顺序配置为‘先目标后源’,但这不是一刀切的,而是按流量灰度逐步推进。
同时,我们始终保持增量校验和自动修复在后台运行。
这套机制的核心价值在于:
第一,可回滚——发现问题能立即切回安全模式;
第二,可灰度——风险可控地逐步放量;
第三,自愈能力——即使出现不一致,校验修复也能自动处理。
这就好比给迁移过程上了‘双保险’,既保证了探索新架构的勇气,又留好了退路。
四、回滚方案设计
4.1 什么情况下需要回滚?
迁移过程中可能遇到各类突发问题:
- 数据不一致率飙升:超出预期阈值
- 目标库性能瓶颈:写入延迟过大,拖累业务
- 业务反馈异常:用户侧出现错误或数据错乱
- 系统资源过载:CPU、IOPS 达到极限
此时,能够快速、无损地将流量切回原架构,是保护业务的首要任务。
4.2 可回滚的核心设计:双写顺序切换,ducc配置
我们的方案支持动态切换双写顺序,通过ducc配置无需重启应用:
| 模式 | 写入顺序 | 读取来源 | 适用场景 |
| 阶段一 | 先源表,后目标表 | 读源表 | 迁移初期、发现问题时快速回滚 |
| 阶段二 | 先目标表,后源表 | 读目标表 | 灰度验证、逐步放量 |
切换原理:双写代理层通过 AOP 拦截所有数据变更操作,根据配置中心的开关决定执行顺序。该开关支持灰度粒度(按商家、门店、流量百分比),可精细控制切换范围。
回滚后处理
- 增量校验:即使回滚,校验服务仍基于 Binlog 实时比对,发现不一致则用源表修复目标表
- 死信队列补偿:回滚前可能已有部分数据写入目标表,通过补偿任务最终对齐
4.3 灰度切换策略
为避免“一刀切”风险,我们采用**灰度放量**策略:
1. 1% 灰度:选择少量商家/门店开启“先目标后源”模式
2. 观察期:持续校验 1-2天,确认无误
3. 商家门店逐步放大:5% → 20% → 50% → 100%
五、监控与告警体系
5.1 核心监控指标
| 维度 | 指标 | 说明 | 阈值建议 |
| 数据一致性 | 实时校验不一致数 | 每分钟发现的不一致行数 | >10 告警 |
| 双写性能 | 双写平均耗时 | 源表和目标表写入总耗时 | 基线+50% 告警 |
| 死信队列积压 | 补偿队列未处理消息数 | >3 告警 | |
| 双写失败率 | 任一表写入失败的比例 | >1% 告警 | |
| 系统资源 | 源/目标库 CPU | 数据库 CPU 使用率 | >80% 告警 |
| 业务影响 | 核心接口 RT | 业务接口响应时间 | 基线+30% 告警 |
| 错误率 | 业务请求错误比例 | >0.5% 告警 |
5.2 告警策略
P0 级告警(立即处理):
- 数据不一致数持续增长且修复失败
- 双写失败率 > 5%
- 核心业务接口错误率 > 2%
- 触发自动回滚 or 京me通知相关人员
P1 级告警(当日处理):
- 死信队列积压 > 3,需要修复数据
- 数据库 CPU > 85%,需要暂停写入
六、总结
本文围绕储区储位数据迁移,提出了一套可灰度、可观测、可回滚、自愈性的不停机迁移方案。
核心设计包括:双写顺序,回滚设计;增量校验、死信队列补偿异常等实现业务无感知恢复。
该方案不仅适用于MySQL异构宽表迁移,还可推广至同构数据库迁移、异构数据同步、分库分表、大表变更及系统重构等场景。
以上仅为个人实践总结,如有不妥之处,欢迎批评指正,共同探讨更优方案。






