



前言
在电商平台中,优惠券功作为核心营销工具,承载着券推荐、领券、可用券品推荐、券使用的完整业务闭环。本文主要介绍权益中心优惠券功能模块的配置化能力架构设计,通过构建灵活的配置化平台,结合Aviator规则引擎和责任链模式实现券面展示、券跳转个性化逻辑、券动态归类的动态配置,为优惠券营销业务提供强有力的技术支撑。
1. 业务背景
1.1 优惠券业务背景
优惠券作为电商平台最重要的营销工具之一,直接影响用户转化率和平台GMV。在用户权益体系中,优惠券功能承载着以下关键业务价值:
- 用户拉新:通过新人专享券吸引新用户注册
- 用户留存:通过会员专享券提升用户粘性
- 促进转化:通过满减券、折扣券刺激用户消费
- 品类推广:通过品类券引导用户尝试新品类
- 活动营销:通过限时券配合大促活动(超级补贴等)
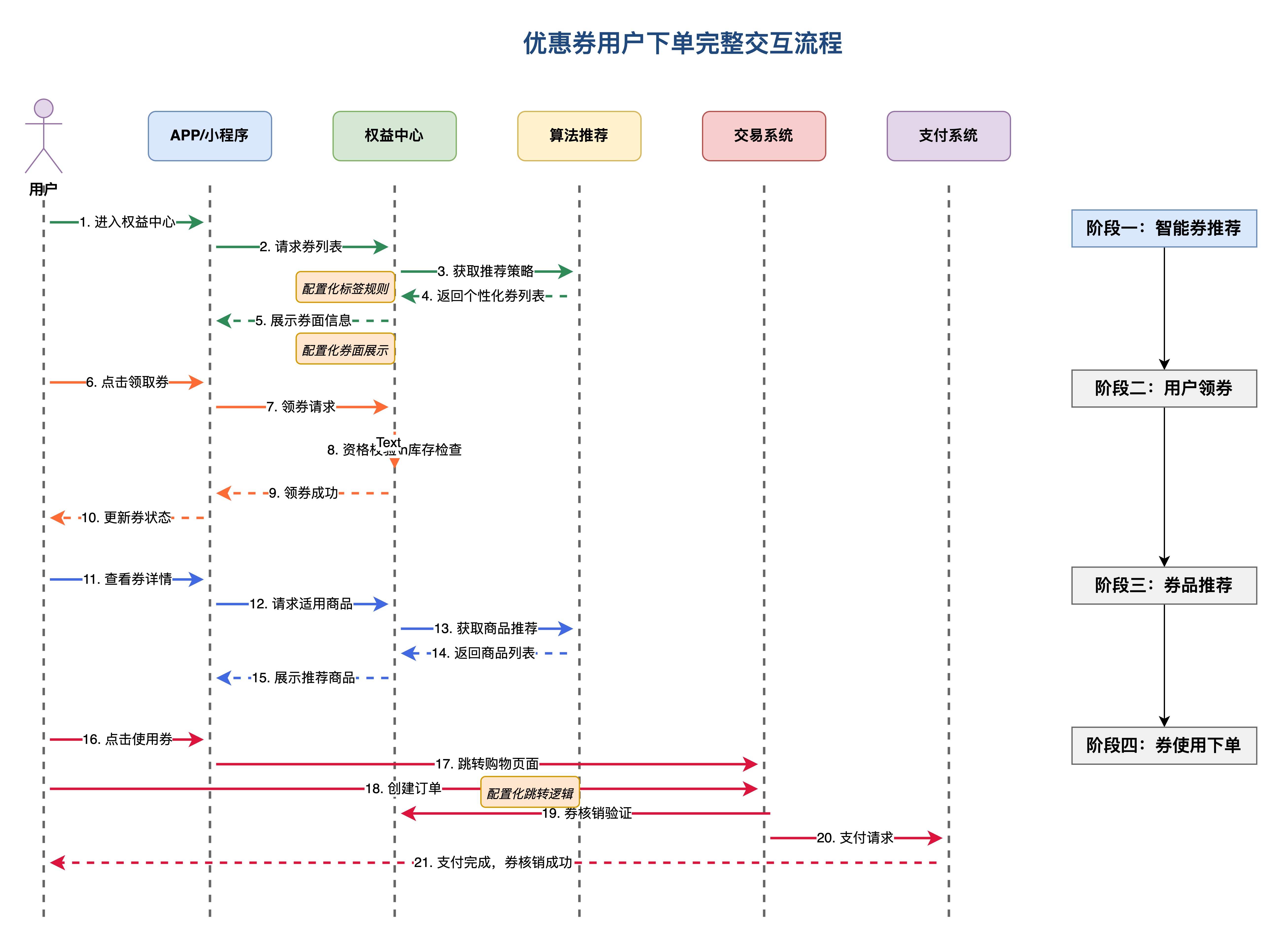
2. 权益中心-优惠券业务概述
优惠券业务目前基本是权益中心最重要的用户权益模块。大促期间优惠券模块流量占比超过半数,点击转化率处于较高水平,对整体交易转化贡献显著。
2.1 优惠券业务概述
优惠券作为电商平台的核心营销工具,贯穿用户购物生命周期的各个环节,对提升用户转化率和平台交易额(GMV)起着至关重要的作用。权益中心优惠券业务主要涵盖以下几个关键环节:
- 推券:基于智能推荐算法或特定营销活动,向用户精准推送合适的优惠券,如在大促活动页面发放核心优惠券。
- 领券:用户领取活动优惠券,领取跳转权益中心会承接优惠券发放。
- 券列表展示:为用户提供清晰、便捷的优惠券列表展示,推荐最适合的优惠券,并展示适用商品,引导用户使用优惠券。
- 优惠券使用:用户在下单时使用优惠券,同时优化跳转逻辑,引导用户到合适的落地页,提高用户的购买转化率。
3. 权益中心优惠券配置化能力架构设计
3.1. 券列表为什么必须做配置化架构设计?
在电商大促的“战场”上,优惠券不仅仅是减免工具,更是触达用户的核心营销载体。随着业务的不断生长,我们面临着以下问题。
营销个性化诉求
早期的优惠券展示逻辑是硬编码的。但现在的业务方(如 PLUS 会员、生鲜、超市、秒送等)对券面 UI 有着差异化表达诉求:
- 差异化文案 :一张满减或者折扣券,对 PLUS 会员要展示“PLUS 专享 | 满100减10”。
- 动态跳转 :点击券面,有的需要跳兜底页,有的需要跳特定的活动落地页,甚至需要做端屏蔽。
- 角标与标签 :运费券需要打“免运费”标,助农券需要打“助农”标,且这些标签的优先级在大促期间会随时调整。
研发效能与市场响应速度的矛盾
- 硬编码的噩梦 :每次新增一个营销活动,开发就需要改代码、提测、走发布流程。
- “分钟级”运营响应 :大促期间,运营策略瞬息万变。需要配合业务大促期间跟进调整券面或者跳转活动会场。传统的“提需求 -> 开发 -> 上线”流程完全无法满足这种实效性。
代码腐化与维护成本的指数级上升
- “屎山”代码 :随着业务规则的不断累加,核心逻辑代码中充斥着成百上千行的 if-else 判断。这种“面条式代码”不仅可读性极差,而且逻辑耦合严重,牵一发而动全身。
- 回归难 :修改一个小小的文案展示逻辑,可能需要回归测试整个优惠券列表功能,以确保不会影响到其他几十种券的展示。
- 易形成技术债 :复杂的硬编码逻辑让其他开发人员望而生畏,不敢轻易改动,导致技术债务越积越重,最终形成一个谁都不敢碰的“黑盒”。
复杂的优惠券实体属性
在做配置化能力架构之前,我们先简单认识下优惠券。优惠券的信息主要会包含什么呢?优惠券的本质是营销活动。 既然是活动,简单来说活动就会有活动时间,数量,活动力度(满减,折扣),活动规则(限品类,限平台,领券规则)。
优惠券既然是营销属性,就充斥着各种业务属性标签,这些规则匹配放到代码中,我们和券体系就变成了重耦合,券体系新增某个属性枚举或者下线某个属性,权益中心券列表服务都得跟着做出改动,这对于2个独立系统来说,会变成一个灾难。
核心字段释义:
couponId: 优惠券id。(领取后生成)
batchId: 券批次id,随活动创建,1个券批次包含券数量设置。
state:券状态(可用,过期,失效,删除)
createTime:用户领取时间
endTime: 券过期时间(过期绝对时间)
extInfo: 业务扩展字段; 涉及很多枚举。
quota: 最低消费金额可用
............结论 :我们需要一套“运营配置即生效” 的系统,将 “业务规则” 从 “代码逻辑”中彻底剥离,把控制权交还给业务方。
3.2 配置化架构总览
为了解决传统架构的痛点,我们采用配置即代码的理念,引入Aviator规则引擎,设计了一套完整的配置化能力架构。 权益中心优惠券配置化能力如下图所示:
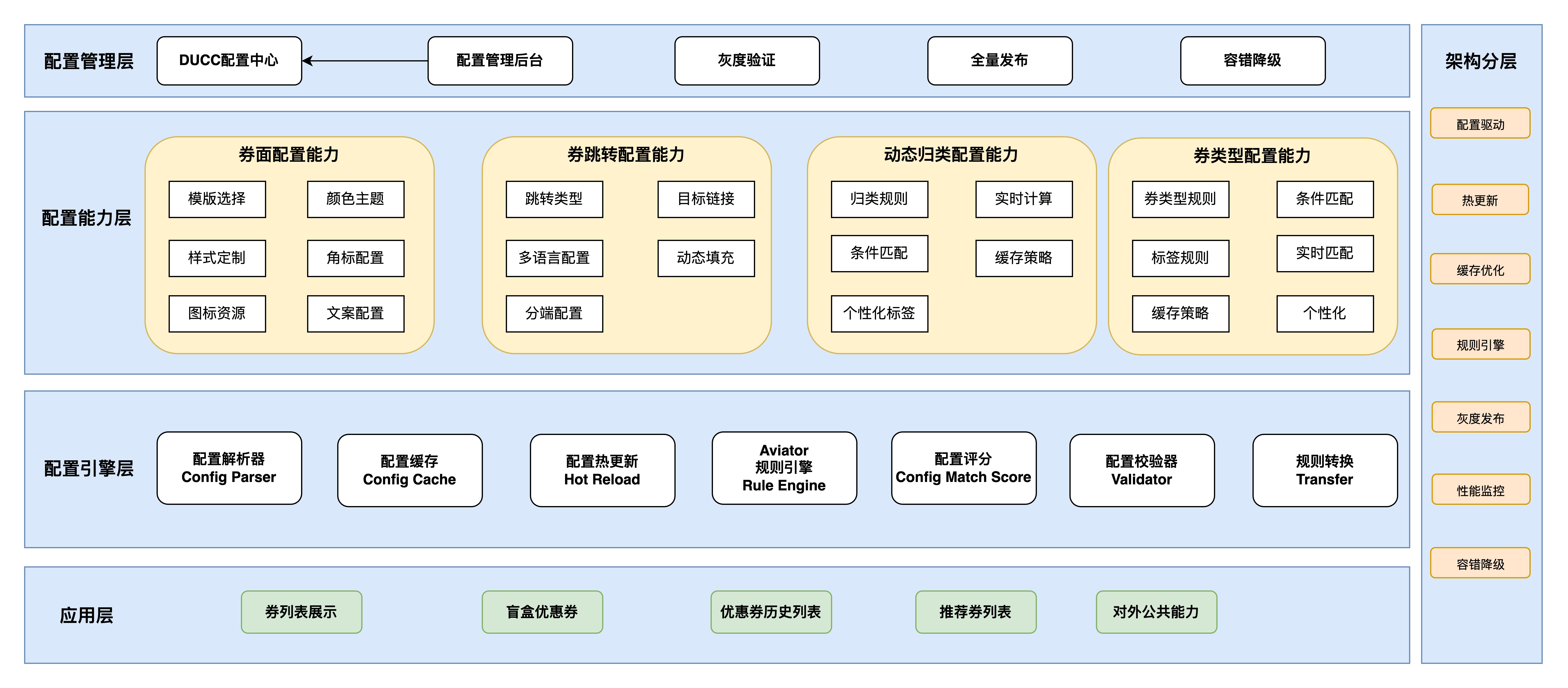
该架构分为四个核心层次:
- 配置管理层:提供配置的创建、修改、发布、监控能力
- 配置类型层:定义券面配置、跳转配置、标签配置、类型配置四大类型
- 配置引擎层:负责配置的解析、缓存、热更新、匹配度排序
- 应用层:各业务系统通过配置引擎匹配配置信息
3.2.1 配置管理层设计
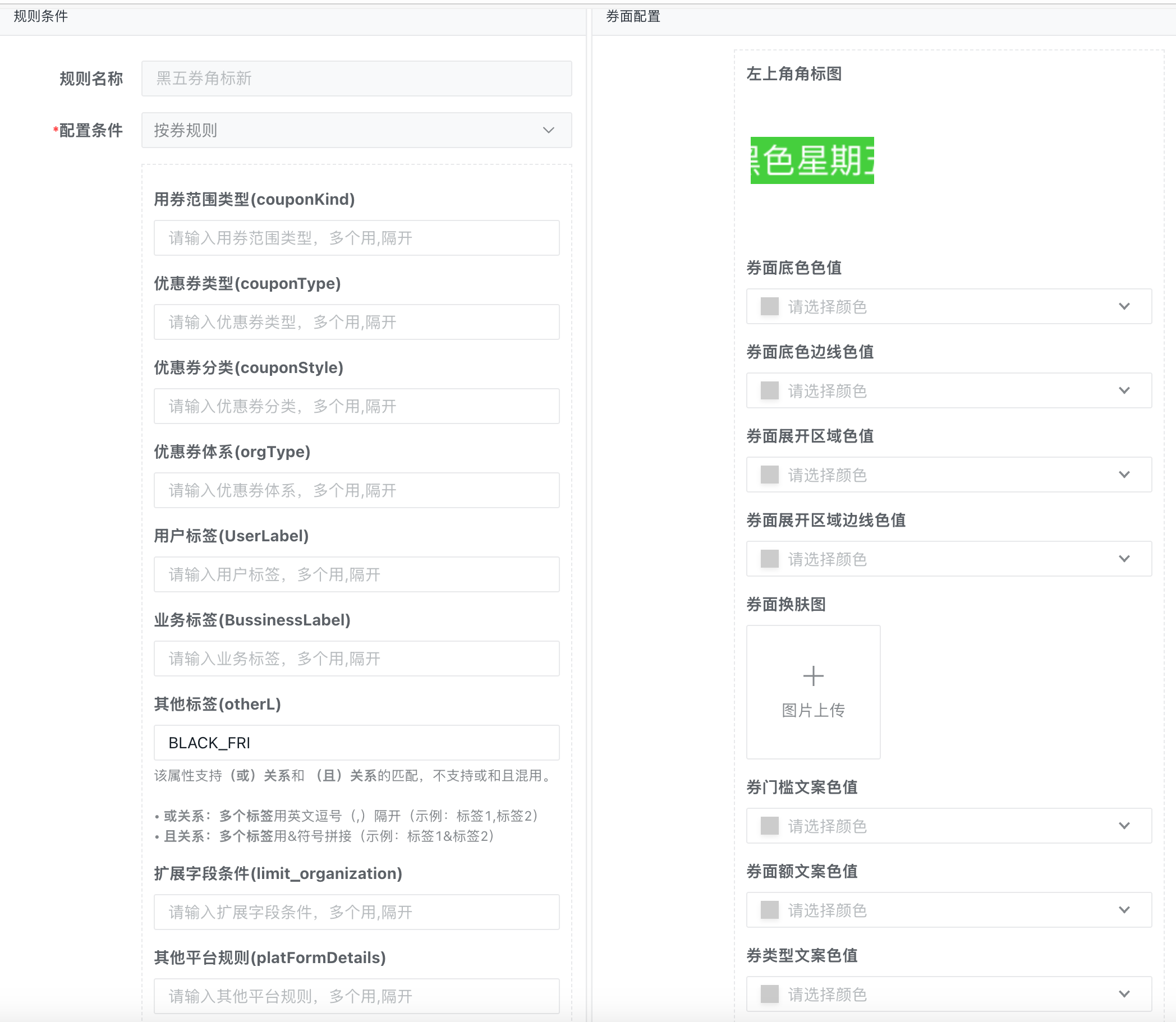
规则配置后台管理
规则配置后管主要负责提供常见券属性可视化的配置管理界面。
| 券面配置维度 | 券跳转配置维度 |
|---|---|
| ·模板选择:支持券规则,券批次,关键词匹配模式。 ·样式定制:背景色、边框、字体等样式自定义 ·文案配置:标题、副标题、使用说明等文案 ·图标资源:券类型图标 ·颜色主题:支持品牌色、节日色等主题色 ·角标设置:限时、热门、推荐等角标配置 | ·模板选择:支持券规则,券批次,关键词匹配模式。 ·跳转类型:H5页面、小程序、APP页面、外部链接 ·目标链接:具体的跳转URL或页面标识 ·动态参数:券ID、用户ID等动态模版参数 |
| 优惠券券面配置后管 | 优惠券跳转配置后管 |
|---|---|
 | 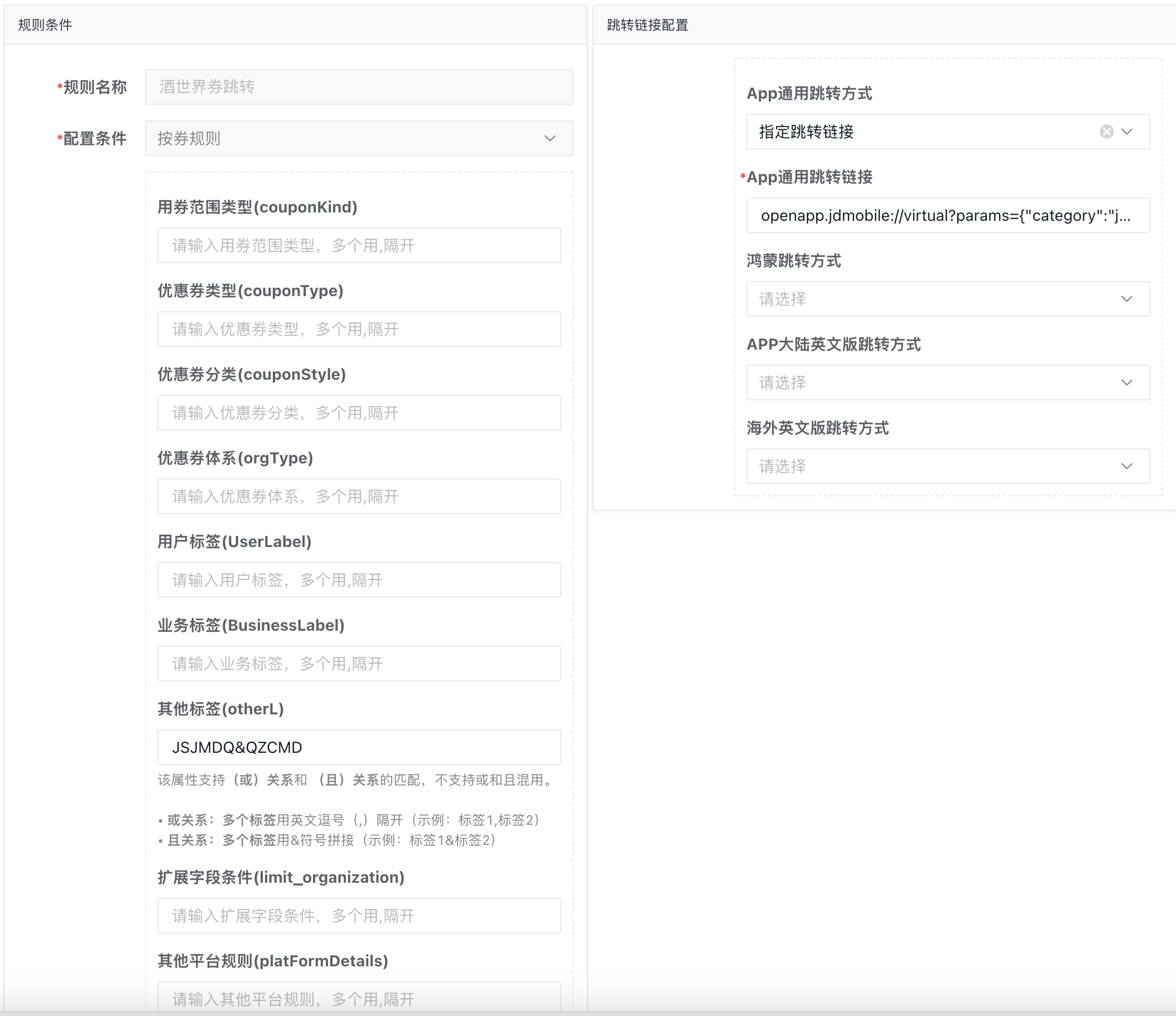 |
规则配置发布同步
后管规则保存后,需要经过预发验证----》白名单验证-----》全量发布,规则才会全量生效。点击保存后管规则会将配置数据转换为JSON 结果数据保存到数据库,点击发布功能按钮,以规则id维度,将规则详情同步发布到ducc。
应用服务通过ducc监听机制,监听规则变更,规则解析引擎会将规则JSON,转换为规则脚本进行编译缓存。再通过规则权重打分。 对所有规则脚本进行打分赋分,按照score从高到低进行排序。 打分排序的目的是确保高优规则能够优先匹配。
%3C%2Ftspan%3E%3C%2Ftext%3E%3C%2Fg%3E%3Cg%3E%3Crect%20class%3D%22actor%20actor-bottom%22%20ry%3D%223%22%20rx%3D%223%22%20name%3D%22Aviator%22%20height%3D%2265%22%20width%3D%22184%22%20stroke%3D%22%23666%22%20fill%3D%22%23eaeaea%22%20y%3D%221329%22%20x%3D%221310.5%22%3E%3C%2Frect%3E%3Ctext%20style%3D%22text-anchor%3A%20middle%3B%20font-size%3A%2016px%3B%20font-weight%3A%20400%3B%22%20class%3D%22actor%22%20alignment-baseline%3D%22central%22%20dominant-baseline%3D%22central%22%20y%3D%221361.5%22%20x%3D%221402.5%22%3E%3Ctspan%20dy%3D%220%22%20x%3D%221402.5%22%3EAviatorEvaluator(%E5%BC%95%E6%93%8E)%3C%2Ftspan%3E%3C%2Ftext%3E%3C%2Fg%3E%3Cg%3E%3Crect%20class%3D%22actor%20actor-bottom%22%20ry%3D%223%22%20rx%3D%223%22%20name%3D%22Service%22%20height%3D%2265%22%20width%3D%22261%22%20stroke%3D%22%23666%22%20fill%3D%22%23eaeaea%22%20y%3D%221329%22%20x%3D%22818%22%3E%3C%2Frect%3E%3Ctext%20style%3D%22text-anchor%3A%20middle%3B%20font-size%3A%2016px%3B%20font-weight%3A%20400%3B%22%20class%3D%22actor%22%20alignment-baseline%3D%22central%22%20dominant-baseline%3D%22central%22%20y%3D%221361.5%22%20x%3D%22948.5%22%3E%3Ctspan%20dy%3D%220%22%20x%3D%22948.5%22%3EMyCouponRuleService(%E5%BA%94%E7%94%A8%E6%9C%8D%E5%8A%A1)%3C%2Ftspan%3E%3C%2Ftext%3E%3C%2Fg%3E%3Cg%3E%3Crect%20class%3D%22actor%20actor-bottom%22%20ry%3D%223%22%20rx%3D%223%22%20name%3D%22Ducc%22%20height%3D%2265%22%20width%3D%22150%22%20stroke%3D%22%23666%22%20fill%3D%22%23eaeaea%22%20y%3D%221329%22%20x%3D%22493.5%22%3E%3C%2Frect%3E%3Ctext%20style%3D%22text-anchor%3A%20middle%3B%20font-size%3A%2016px%3B%20font-weight%3A%20400%3B%22%20class%3D%22actor%22%20alignment-baseline%3D%22central%22%20dominant-baseline%3D%22central%22%20y%3D%221361.5%22%20x%3D%22568.5%22%3E%3Ctspan%20dy%3D%220%22%20x%3D%22568.5%22%3EDUCC%E9%85%8D%E7%BD%AE%E4%B8%AD%E5%BF%83%3C%2Ftspan%3E%3C%2Ftext%3E%3C%2Fg%3E%3Cg%3E%3Crect%20class%3D%22actor%20actor-bottom%22%20ry%3D%223%22%20rx%3D%223%22%20name%3D%22Admin%22%20height%3D%2265%22%20width%3D%22173%22%20stroke%3D%22%23666%22%20fill%3D%22%23eaeaea%22%20y%3D%221329%22%20x%3D%220%22%3E%3C%2Frect%3E%3Ctext%20style%3D%22text-anchor%3A%20middle%3B%20font-size%3A%2016px%3B%20font-weight%3A%20400%3B%22%20class%3D%22actor%22%20alignment-baseline%3D%22central%22%20dominant-baseline%3D%22central%22%20y%3D%221361.5%22%20x%3D%2286.5%22%3E%3Ctspan%20dy%3D%220%22%20x%3D%2286.5%22%3E%E8%A7%84%E5%88%99%E7%AE%A1%E7%90%86%E5%90%8E%E5%8F%B0(Admin)%3C%2Ftspan%3E%3C%2Ftext%3E%3C%2Fg%3E%3Cg%3E%3Cline%20stroke%3D%22%23999%22%20stroke-width%3D%220.5px%22%20class%3D%22200%22%20y2%3D%221329%22%20x2%3D%221685%22%20y1%3D%225%22%20x1%3D%221685%22%20id%3D%22actor4%22%3E%3C%2Fline%3E%3Cg%20id%3D%22root-4%22%3E%3Crect%20class%3D%22actor%20actor-top%22%20ry%3D%223%22%20rx%3D%223%22%20name%3D%22Cache%22%20height%3D%2265%22%20width%3D%22281%22%20stroke%3D%22%23666%22%20fill%3D%22%23eaeaea%22%20y%3D%220%22%20x%3D%221544.5%22%3E%3C%2Frect%3E%3Ctext%20style%3D%22text-anchor%3A%20middle%3B%20font-size%3A%2016px%3B%20font-weight%3A%20400%3B%22%20class%3D%22actor%22%20alignment-baseline%3D%22central%22%20dominant-baseline%3D%22central%22%20y%3D%2232.5%22%20x%3D%221685%22%3E%3Ctspan%20dy%3D%220%22%20x%3D%221685%22%3E%E8%A7%84%E5%88%99%E7%BC%93%E5%AD%98(Map%26lt%3BString%2C%20Expression%26gt%3B)%3C%2Ftspan%3E%3C%2Ftext%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%3E%3Cline%20stroke%3D%22%23999%22%20stroke-width%3D%220.5px%22%20class%3D%22200%22%20y2%3D%221329%22%20x2%3D%221402.5%22%20y1%3D%225%22%20x1%3D%221402.5%22%20id%3D%22actor3%22%3E%3C%2Fline%3E%3Cg%20id%3D%22root-3%22%3E%3Crect%20class%3D%22actor%20actor-top%22%20ry%3D%223%22%20rx%3D%223%22%20name%3D%22Aviator%22%20height%3D%2265%22%20width%3D%22184%22%20stroke%3D%22%23666%22%20fill%3D%22%23eaeaea%22%20y%3D%220%22%20x%3D%221310.5%22%3E%3C%2Frect%3E%3Ctext%20style%3D%22text-anchor%3A%20middle%3B%20font-size%3A%2016px%3B%20font-weight%3A%20400%3B%22%20class%3D%22actor%22%20alignment-baseline%3D%22central%22%20dominant-baseline%3D%22central%22%20y%3D%2232.5%22%20x%3D%221402.5%22%3E%3Ctspan%20dy%3D%220%22%20x%3D%221402.5%22%3EAviatorEvaluator(%E5%BC%95%E6%93%8E)%3C%2Ftspan%3E%3C%2Ftext%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%3E%3Cline%20stroke%3D%22%23999%22%20stroke-width%3D%220.5px%22%20class%3D%22200%22%20y2%3D%221329%22%20x2%3D%22948.5%22%20y1%3D%225%22%20x1%3D%22948.5%22%20id%3D%22actor2%22%3E%3C%2Fline%3E%3Cg%20id%3D%22root-2%22%3E%3Crect%20class%3D%22actor%20actor-top%22%20ry%3D%223%22%20rx%3D%223%22%20name%3D%22Service%22%20height%3D%2265%22%20width%3D%22261%22%20stroke%3D%22%23666%22%20fill%3D%22%23eaeaea%22%20y%3D%220%22%20x%3D%22818%22%3E%3C%2Frect%3E%3Ctext%20style%3D%22text-anchor%3A%20middle%3B%20font-size%3A%2016px%3B%20font-weight%3A%20400%3B%22%20class%3D%22actor%22%20alignment-baseline%3D%22central%22%20dominant-baseline%3D%22central%22%20y%3D%2232.5%22%20x%3D%22948.5%22%3E%3Ctspan%20dy%3D%220%22%20x%3D%22948.5%22%3EMyCouponRuleService(%E5%BA%94%E7%94%A8%E6%9C%8D%E5%8A%A1)%3C%2Ftspan%3E%3C%2Ftext%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%3E%3Cline%20stroke%3D%22%23999%22%20stroke-width%3D%220.5px%22%20class%3D%22200%22%20y2%3D%221329%22%20x2%3D%22568.5%22%20y1%3D%225%22%20x1%3D%22568.5%22%20id%3D%22actor1%22%3E%3C%2Fline%3E%3Cg%20id%3D%22root-1%22%3E%3Crect%20class%3D%22actor%20actor-top%22%20ry%3D%223%22%20rx%3D%223%22%20name%3D%22Ducc%22%20height%3D%2265%22%20width%3D%22150%22%20stroke%3D%22%23666%22%20fill%3D%22%23eaeaea%22%20y%3D%220%22%20x%3D%22493.5%22%3E%3C%2Frect%3E%3Ctext%20style%3D%22text-anchor%3A%20middle%3B%20font-size%3A%2016px%3B%20font-weight%3A%20400%3B%22%20class%3D%22actor%22%20alignment-baseline%3D%22central%22%20dominant-baseline%3D%22central%22%20y%3D%2232.5%22%20x%3D%22568.5%22%3E%3Ctspan%20dy%3D%220%22%20x%3D%22568.5%22%3EDUCC%E9%85%8D%E7%BD%AE%E4%B8%AD%E5%BF%83%3C%2Ftspan%3E%3C%2Ftext%3E%3C%2Fg%3E%3C%2Fg%3E%3Cg%3E%3Cline%20stroke%3D%22%23999%22%20stroke-width%3D%220.5px%22%20class%3D%22200%22%20y2%3D%221329%22%20x2%3D%2286.5%22%20y1%3D%225%22%20x1%3D%2286.5%22%20id%3D%22actor0%22%3E%3C%2Fline%3E%3Cg%20id%3D%22root-0%22%3E%3Crect%20class%3D%22actor%20actor-top%22%20ry%3D%223%22%20rx%3D%223%22%20name%3D%22Admin%22%20height%3D%2265%22%20width%3D%22173%22%20stroke%3D%22%23666%22%20fill%3D%22%23eaeaea%22%20y%3D%220%22%20x%3D%220%22%3E%3C%2Frect%3E%3Ctext%20style%3D%22text-anchor%3A%20middle%3B%20font-size%3A%2016px%3B%20font-weight%3A%20400%3B%22%20class%3D%22actor%22%20alignment-baseline%3D%22central%22%20dominant-baseline%3D%22central%22%20y%3D%2232.5%22%20x%3D%2286.5%22%3E%3Ctspan%20dy%3D%220%22%20x%3D%2286.5%22%3E%E8%A7%84%E5%88%99%E7%AE%A1%E7%90%86%E5%90%8E%E5%8F%B0(Admin)%3C%2Ftspan%3E%3C%2Ftext%3E%3C%2Fg%3E%3C%2Fg%3E%3Cstyle%3E%23mermaidchart-W2gYjJ%7Bfont-family%3A%22trebuchet%20ms%22%2Cverdana%2Carial%2Csans-serif%3Bfont-size%3A16px%3Bfill%3A%23333%3B%7D%23mermaidchart-W2gYjJ%20.error-icon%7Bfill%3A%23552222%3B%7D%23mermaidchart-W2gYjJ%20.error-text%7Bfill%3A%23552222%3Bstroke%3A%23552222%3B%7D%23mermaidchart-W2gYjJ%20.edge-thickness-normal%7Bstroke-width%3A2px%3B%7D%23mermaidchart-W2gYjJ%20.edge-thickness-thick%7Bstroke-width%3A3.5px%3B%7D%23mermaidchart-W2gYjJ%20.edge-pattern-solid%7Bstroke-dasharray%3A0%3B%7D%23mermaidchart-W2gYjJ%20.edge-pattern-dashed%7Bstroke-dasharray%3A3%3B%7D%23mermaidchart-W2gYjJ%20.edge-pattern-dotted%7Bstroke-dasharray%3A2%3B%7D%23mermaidchart-W2gYjJ%20.marker%7Bfill%3A%23333333%3Bstroke%3A%23333333%3B%7D%23mermaidchart-W2gYjJ%20.marker.cross%7Bstroke%3A%23333333%3B%7D%23mermaidchart-W2gYjJ%20svg%7Bfont-family%3A%22trebuchet%20ms%22%2Cverdana%2Carial%2Csans-serif%3Bfont-size%3A16px%3B%7D%23mermaidchart-W2gYjJ%20.actor%7Bstroke%3Ahsl(259.6261682243%2C%2059.7765363128%25%2C%2087.9019607843%25)%3Bfill%3A%23ECECFF%3B%7D%23mermaidchart-W2gYjJ%20text.actor%26gt%3Btspan%7Bfill%3Ablack%3Bstroke%3Anone%3B%7D%23mermaidchart-W2gYjJ%20.actor-line%7Bstroke%3Agrey%3B%7D%23mermaidchart-W2gYjJ%20.messageLine0%7Bstroke-width%3A1.5%3Bstroke-dasharray%3Anone%3Bstroke%3A%23333%3B%7D%23mermaidchart-W2gYjJ%20.messageLine1%7Bstroke-width%3A1.5%3Bstroke-dasharray%3A2%2C2%3Bstroke%3A%23333%3B%7D%23mermaidchart-W2gYjJ%20%23arrowhead%20path%7Bfill%3A%23333%3Bstroke%3A%23333%3B%7D%23mermaidchart-W2gYjJ%20.sequenceNumber%7Bfill%3Awhite%3B%7D%23mermaidchart-W2gYjJ%20%23sequencenumber%7Bfill%3A%23333%3B%7D%23mermaidchart-W2gYjJ%20%23crosshead%20path%7Bfill%3A%23333%3Bstroke%3A%23333%3B%7D%23mermaidchart-W2gYjJ%20.messageText%7Bfill%3A%23333%3Bstroke%3Anone%3B%7D%23mermaidchart-W2gYjJ%20.labelBox%7Bstroke%3Ahsl(259.6261682243%2C%2059.7765363128%25%2C%2087.9019607843%25)%3Bfill%3A%23ECECFF%3B%7D%23mermaidchart-W2gYjJ%20.labelText%2C%23mermaidchart-W2gYjJ%20.labelText%26gt%3Btspan%7Bfill%3Ablack%3Bstroke%3Anone%3B%7D%23mermaidchart-W2gYjJ%20.loopText%2C%23mermaidchart-W2gYjJ%20.loopText%26gt%3Btspan%7Bfill%3Ablack%3Bstroke%3Anone%3B%7D%23mermaidchart-W2gYjJ%20.loopLine%7Bstroke-width%3A2px%3Bstroke-dasharray%3A2%2C2%3Bstroke%3Ahsl(259.6261682243%2C%2059.7765363128%25%2C%2087.9019607843%25)%3Bfill%3Ahsl(259.6261682243%2C%2059.7765363128%25%2C%2087.9019607843%25)%3B%7D%23mermaidchart-W2gYjJ%20.note%7Bstroke%3A%23aaaa33%3Bfill%3A%23fff5ad%3B%7D%23mermaidchart-W2gYjJ%20.noteText%2C%23mermaidchart-W2gYjJ%20.noteText%26gt%3Btspan%7Bfill%3Ablack%3Bstroke%3Anone%3B%7D%23mermaidchart-W2gYjJ%20.activation0%7Bfill%3A%23f4f4f4%3Bstroke%3A%23666%3B%7D%23mermaidchart-W2gYjJ%20.activation1%7Bfill%3A%23f4f4f4%3Bstroke%3A%23666%3B%7D%23mermaidchart-W2gYjJ%20.activation2%7Bfill%3A%23f4f4f4%3Bstroke%3A%23666%3B%7D%23mermaidchart-W2gYjJ%20.actorPopupMenu%7Bposition%3Aabsolute%3B%7D%23mermaidchart-W2gYjJ%20.actorPopupMenuPanel%7Bposition%3Aabsolute%3Bfill%3A%23ECECFF%3Bbox-shadow%3A0px%208px%2016px%200px%20rgba(0%2C0%2C0%2C0.2)%3Bfilter%3Adrop-shadow(3px%205px%202px%20rgb(0%200%200%20%2F%200.4))%3B%7D%23mermaidchart-W2gYjJ%20.actor-man%20line%7Bstroke%3Ahsl(259.6261682243%2C%2059.7765363128%25%2C%2087.9019607843%25)%3Bfill%3A%23ECECFF%3B%7D%23mermaidchart-W2gYjJ%20.actor-man%20circle%2C%23mermaidchart-W2gYjJ%20line%7Bstroke%3Ahsl(259.6261682243%2C%2059.7765363128%25%2C%2087.9019607843%25)%3Bfill%3A%23ECECFF%3Bstroke-width%3A2px%3B%7D%23mermaidchart-W2gYjJ%20%3Aroot%7B--mermaid-font-family%3A%22trebuchet%20ms%22%2Cverdana%2Carial%2Csans-serif%3B%7D%3C%2Fstyle%3E%3Cg%3E%3C%2Fg%3E%3Cdefs%3E%3Csymbol%20height%3D%2224%22%20width%3D%2224%22%20id%3D%22computer%22%3E%3Cpath%20d%3D%22M2%202v13h20v-13h-20zm18%2011h-16v-9h16v9zm-10.228%206l.466-1h3.524l.467%201h-4.457zm14.228%203h-24l2-6h2.104l-1.33%204h18.45l-1.297-4h2.073l2%206zm-5-10h-14v-7h14v7z%22%20transform%3D%22scale(.5)%22%3E%3C%2Fpath%3E%3C%2Fsymbol%3E%3C%2Fdefs%3E%3Cdefs%3E%3Csymbol%20clip-rule%3D%22evenodd%22%20fill-rule%3D%22evenodd%22%20id%3D%22database%22%3E%3Cpath%20d%3D%22M12.258.001l.256.004.255.005.253.008.251.01.249.012.247.015.246.016.242.019.241.02.239.023.236.024.233.027.231.028.229.031.225.032.223.034.22.036.217.038.214.04.211.041.208.043.205.045.201.046.198.048.194.05.191.051.187.053.183.054.18.056.175.057.172.059.168.06.163.061.16.063.155.064.15.066.074.033.073.033.071.034.07.034.069.035.068.035.067.035.066.035.064.036.064.036.062.036.06.036.06.037.058.037.058.037.055.038.055.038.053.038.052.038.051.039.05.039.048.039.047.039.045.04.044.04.043.04.041.04.04.041.039.041.037.041.036.041.034.041.033.042.032.042.03.042.029.042.027.042.026.043.024.043.023.043.021.043.02.043.018.044.017.043.015.044.013.044.012.044.011.045.009.044.007.045.006.045.004.045.002.045.001.045v17l-.001.045-.002.045-.004.045-.006.045-.007.045-.009.044-.011.045-.012.044-.013.044-.015.044-.017.043-.018.044-.02.043-.021.043-.023.043-.024.043-.026.043-.027.042-.029.042-.03.042-.032.042-.033.042-.034.041-.036.041-.037.041-.039.041-.04.041-.041.04-.043.04-.044.04-.045.04-.047.039-.048.039-.05.039-.051.039-.052.038-.053.038-.055.038-.055.038-.058.037-.058.037-.06.037-.06.036-.062.036-.064.036-.064.036-.066.035-.067.035-.068.035-.069.035-.07.034-.071.034-.073.033-.074.033-.15.066-.155.064-.16.063-.163.061-.168.06-.172.059-.175.057-.18.056-.183.054-.187.053-.191.051-.194.05-.198.048-.201.046-.205.045-.208.043-.211.041-.214.04-.217.038-.22.036-.223.034-.225.032-.229.031-.231.028-.233.027-.236.024-.239.023-.241.02-.242.019-.246.016-.247.015-.249.012-.251.01-.253.008-.255.005-.256.004-.258.001-.258-.001-.256-.004-.255-.005-.253-.008-.251-.01-.249-.012-.247-.015-.245-.016-.243-.019-.241-.02-.238-.023-.236-.024-.234-.027-.231-.028-.228-.031-.226-.032-.223-.034-.22-.036-.217-.038-.214-.04-.211-.041-.208-.043-.204-.045-.201-.046-.198-.048-.195-.05-.19-.051-.187-.053-.184-.054-.179-.056-.176-.057-.172-.059-.167-.06-.164-.061-.159-.063-.155-.064-.151-.066-.074-.033-.072-.033-.072-.034-.07-.034-.069-.035-.068-.035-.067-.035-.066-.035-.064-.036-.063-.036-.062-.036-.061-.036-.06-.037-.058-.037-.057-.037-.056-.038-.055-.038-.053-.038-.052-.038-.051-.039-.049-.039-.049-.039-.046-.039-.046-.04-.044-.04-.043-.04-.041-.04-.04-.041-.039-.041-.037-.041-.036-.041-.034-.041-.033-.042-.032-.042-.03-.042-.029-.042-.027-.042-.026-.043-.024-.043-.023-.043-.021-.043-.02-.043-.018-.044-.017-.043-.015-.044-.013-.044-.012-.044-.011-.045-.009-.044-.007-.045-.006-.045-.004-.045-.002-.045-.001-.045v-17l.001-.045.002-.045.004-.045.006-.045.007-.045.009-.044.011-.045.012-.044.013-.044.015-.044.017-.043.018-.044.02-.043.021-.043.023-.043.024-.043.026-.043.027-.042.029-.042.03-.042.032-.042.033-.042.034-.041.036-.041.037-.041.039-.041.04-.041.041-.04.043-.04.044-.04.046-.04.046-.039.049-.039.049-.039.051-.039.052-.038.053-.038.055-.038.056-.038.057-.037.058-.037.06-.037.061-.036.062-.036.063-.036.064-.036.066-.035.067-.035.068-.035.069-.035.07-.034.072-.034.072-.033.074-.033.151-.066.155-.064.159-.063.164-.061.167-.06.172-.059.176-.057.179-.056.184-.054.187-.053.19-.051.195-.05.198-.048.201-.046.204-.045.208-.043.211-.041.214-.04.217-.038.22-.036.223-.034.226-.032.228-.031.231-.028.234-.027.236-.024.238-.023.241-.02.243-.019.245-.016.247-.015.249-.012.251-.01.253-.008.255-.005.256-.004.258-.001.258.001zm-9.258%2020.499v.01l.001.021.003.021.004.022.005.021.006.022.007.022.009.023.01.022.011.023.012.023.013.023.015.023.016.024.017.023.018.024.019.024.021.024.022.025.023.024.024.025.052.049.056.05.061.051.066.051.07.051.075.051.079.052.084.052.088.052.092.052.097.052.102.051.105.052.11.052.114.051.119.051.123.051.127.05.131.05.135.05.139.048.144.049.147.047.152.047.155.047.16.045.163.045.167.043.171.043.176.041.178.041.183.039.187.039.19.037.194.035.197.035.202.033.204.031.209.03.212.029.216.027.219.025.222.024.226.021.23.02.233.018.236.016.24.015.243.012.246.01.249.008.253.005.256.004.259.001.26-.001.257-.004.254-.005.25-.008.247-.011.244-.012.241-.014.237-.016.233-.018.231-.021.226-.021.224-.024.22-.026.216-.027.212-.028.21-.031.205-.031.202-.034.198-.034.194-.036.191-.037.187-.039.183-.04.179-.04.175-.042.172-.043.168-.044.163-.045.16-.046.155-.046.152-.047.148-.048.143-.049.139-.049.136-.05.131-.05.126-.05.123-.051.118-.052.114-.051.11-.052.106-.052.101-.052.096-.052.092-.052.088-.053.083-.051.079-.052.074-.052.07-.051.065-.051.06-.051.056-.05.051-.05.023-.024.023-.025.021-.024.02-.024.019-.024.018-.024.017-.024.015-.023.014-.024.013-.023.012-.023.01-.023.01-.022.008-.022.006-.022.006-.022.004-.022.004-.021.001-.021.001-.021v-4.127l-.077.055-.08.053-.083.054-.085.053-.087.052-.09.052-.093.051-.095.05-.097.05-.1.049-.102.049-.105.048-.106.047-.109.047-.111.046-.114.045-.115.045-.118.044-.12.043-.122.042-.124.042-.126.041-.128.04-.13.04-.132.038-.134.038-.135.037-.138.037-.139.035-.142.035-.143.034-.144.033-.147.032-.148.031-.15.03-.151.03-.153.029-.154.027-.156.027-.158.026-.159.025-.161.024-.162.023-.163.022-.165.021-.166.02-.167.019-.169.018-.169.017-.171.016-.173.015-.173.014-.175.013-.175.012-.177.011-.178.01-.179.008-.179.008-.181.006-.182.005-.182.004-.184.003-.184.002h-.37l-.184-.002-.184-.003-.182-.004-.182-.005-.181-.006-.179-.008-.179-.008-.178-.01-.176-.011-.176-.012-.175-.013-.173-.014-.172-.015-.171-.016-.17-.017-.169-.018-.167-.019-.166-.02-.165-.021-.163-.022-.162-.023-.161-.024-.159-.025-.157-.026-.156-.027-.155-.027-.153-.029-.151-.03-.15-.03-.148-.031-.146-.032-.145-.033-.143-.034-.141-.035-.14-.035-.137-.037-.136-.037-.134-.038-.132-.038-.13-.04-.128-.04-.126-.041-.124-.042-.122-.042-.12-.044-.117-.043-.116-.045-.113-.045-.112-.046-.109-.047-.106-.047-.105-.048-.102-.049-.1-.049-.097-.05-.095-.05-.093-.052-.09-.051-.087-.052-.085-.053-.083-.054-.08-.054-.077-.054v4.127zm0-5.654v.011l.001.021.003.021.004.021.005.022.006.022.007.022.009.022.01.022.011.023.012.023.013.023.015.024.016.023.017.024.018.024.019.024.021.024.022.024.023.025.024.024.052.05.056.05.061.05.066.051.07.051.075.052.079.051.084.052.088.052.092.052.097.052.102.052.105.052.11.051.114.051.119.052.123.05.127.051.131.05.135.049.139.049.144.048.147.048.152.047.155.046.16.045.163.045.167.044.171.042.176.042.178.04.183.04.187.038.19.037.194.036.197.034.202.033.204.032.209.03.212.028.216.027.219.025.222.024.226.022.23.02.233.018.236.016.24.014.243.012.246.01.249.008.253.006.256.003.259.001.26-.001.257-.003.254-.006.25-.008.247-.01.244-.012.241-.015.237-.016.233-.018.231-.02.226-.022.224-.024.22-.025.216-.027.212-.029.21-.03.205-.032.202-.033.198-.035.194-.036.191-.037.187-.039.183-.039.179-.041.175-.042.172-.043.168-.044.163-.045.16-.045.155-.047.152-.047.148-.048.143-.048.139-.05.136-.049.131-.05.126-.051.123-.051.118-.051.114-.052.11-.052.106-.052.101-.052.096-.052.092-.052.088-.052.083-.052.079-.052.074-.051.07-.052.065-.051.06-.05.056-.051.051-.049.023-.025.023-.024.021-.025.02-.024.019-.024.018-.024.017-.024.015-.023.014-.023.013-.024.012-.022.01-.023.01-.023.008-.022.006-.022.006-.022.004-.021.004-.022.001-.021.001-.021v-4.139l-.077.054-.08.054-.083.054-.085.052-.087.053-.09.051-.093.051-.095.051-.097.05-.1.049-.102.049-.105.048-.106.047-.109.047-.111.046-.114.045-.115.044-.118.044-.12.044-.122.042-.124.042-.126.041-.128.04-.13.039-.132.039-.134.038-.135.037-.138.036-.139.036-.142.035-.143.033-.144.033-.147.033-.148.031-.15.03-.151.03-.153.028-.154.028-.156.027-.158.026-.159.025-.161.024-.162.023-.163.022-.165.021-.166.02-.167.019-.169.018-.169.017-.171.016-.173.015-.173.014-.175.013-.175.012-.177.011-.178.009-.179.009-.179.007-.181.007-.182.005-.182.004-.184.003-.184.002h-.37l-.184-.002-.184-.003-.182-.004-.182-.005-.181-.007-.179-.007-.179-.009-.178-.009-.176-.011-.176-.012-.175-.013-.173-.014-.172-.015-.171-.016-.17-.017-.169-.018-.167-.019-.166-.02-.165-.021-.163-.022-.162-.023-.161-.024-.159-.025-.157-.026-.156-.027-.155-.028-.153-.028-.151-.03-.15-.03-.148-.031-.146-.033-.145-.033-.143-.033-.141-.035-.14-.036-.137-.036-.136-.037-.134-.038-.132-.039-.13-.039-.128-.04-.126-.041-.124-.042-.122-.043-.12-.043-.117-.044-.116-.044-.113-.046-.112-.046-.109-.046-.106-.047-.105-.048-.102-.049-.1-.049-.097-.05-.095-.051-.093-.051-.09-.051-.087-.053-.085-.052-.083-.054-.08-.054-.077-.054v4.139zm0-5.666v.011l.001.02.003.022.004.021.005.022.006.021.007.022.009.023.01.022.011.023.012.023.013.023.015.023.016.024.017.024.018.023.019.024.021.025.022.024.023.024.024.025.052.05.056.05.061.05.066.051.07.051.075.052.079.051.084.052.088.052.092.052.097.052.102.052.105.051.11.052.114.051.119.051.123.051.127.05.131.05.135.05.139.049.144.048.147.048.152.047.155.046.16.045.163.045.167.043.171.043.176.042.178.04.183.04.187.038.19.037.194.036.197.034.202.033.204.032.209.03.212.028.216.027.219.025.222.024.226.021.23.02.233.018.236.017.24.014.243.012.246.01.249.008.253.006.256.003.259.001.26-.001.257-.003.254-.006.25-.008.247-.01.244-.013.241-.014.237-.016.233-.018.231-.02.226-.022.224-.024.22-.025.216-.027.212-.029.21-.03.205-.032.202-.033.198-.035.194-.036.191-.037.187-.039.183-.039.179-.041.175-.042.172-.043.168-.044.163-.045.16-.045.155-.047.152-.047.148-.048.143-.049.139-.049.136-.049.131-.051.126-.05.123-.051.118-.052.114-.051.11-.052.106-.052.101-.052.096-.052.092-.052.088-.052.083-.052.079-.052.074-.052.07-.051.065-.051.06-.051.056-.05.051-.049.023-.025.023-.025.021-.024.02-.024.019-.024.018-.024.017-.024.015-.023.014-.024.013-.023.012-.023.01-.022.01-.023.008-.022.006-.022.006-.022.004-.022.004-.021.001-.021.001-.021v-4.153l-.077.054-.08.054-.083.053-.085.053-.087.053-.09.051-.093.051-.095.051-.097.05-.1.049-.102.048-.105.048-.106.048-.109.046-.111.046-.114.046-.115.044-.118.044-.12.043-.122.043-.124.042-.126.041-.128.04-.13.039-.132.039-.134.038-.135.037-.138.036-.139.036-.142.034-.143.034-.144.033-.147.032-.148.032-.15.03-.151.03-.153.028-.154.028-.156.027-.158.026-.159.024-.161.024-.162.023-.163.023-.165.021-.166.02-.167.019-.169.018-.169.017-.171.016-.173.015-.173.014-.175.013-.175.012-.177.01-.178.01-.179.009-.179.007-.181.006-.182.006-.182.004-.184.003-.184.001-.185.001-.185-.001-.184-.001-.184-.003-.182-.004-.182-.006-.181-.006-.179-.007-.179-.009-.178-.01-.176-.01-.176-.012-.175-.013-.173-.014-.172-.015-.171-.016-.17-.017-.169-.018-.167-.019-.166-.02-.165-.021-.163-.023-.162-.023-.161-.024-.159-.024-.157-.026-.156-.027-.155-.028-.153-.028-.151-.03-.15-.03-.148-.032-.146-.032-.145-.033-.143-.034-.141-.034-.14-.036-.137-.036-.136-.037-.134-.038-.132-.039-.13-.039-.128-.041-.126-.041-.124-.041-.122-.043-.12-.043-.117-.044-.116-.044-.113-.046-.112-.046-.109-.046-.106-.048-.105-.048-.102-.048-.1-.05-.097-.049-.095-.051-.093-.051-.09-.052-.087-.052-.085-.053-.083-.053-.08-.054-.077-.054v4.153zm8.74-8.179l-.257.004-.254.005-.25.008-.247.011-.244.012-.241.014-.237.016-.233.018-.231.021-.226.022-.224.023-.22.026-.216.027-.212.028-.21.031-.205.032-.202.033-.198.034-.194.036-.191.038-.187.038-.183.04-.179.041-.175.042-.172.043-.168.043-.163.045-.16.046-.155.046-.152.048-.148.048-.143.048-.139.049-.136.05-.131.05-.126.051-.123.051-.118.051-.114.052-.11.052-.106.052-.101.052-.096.052-.092.052-.088.052-.083.052-.079.052-.074.051-.07.052-.065.051-.06.05-.056.05-.051.05-.023.025-.023.024-.021.024-.02.025-.019.024-.018.024-.017.023-.015.024-.014.023-.013.023-.012.023-.01.023-.01.022-.008.022-.006.023-.006.021-.004.022-.004.021-.001.021-.001.021.001.021.001.021.004.021.004.022.006.021.006.023.008.022.01.022.01.023.012.023.013.023.014.023.015.024.017.023.018.024.019.024.02.025.021.024.023.024.023.025.051.05.056.05.06.05.065.051.07.052.074.051.079.052.083.052.088.052.092.052.096.052.101.052.106.052.11.052.114.052.118.051.123.051.126.051.131.05.136.05.139.049.143.048.148.048.152.048.155.046.16.046.163.045.168.043.172.043.175.042.179.041.183.04.187.038.191.038.194.036.198.034.202.033.205.032.21.031.212.028.216.027.22.026.224.023.226.022.231.021.233.018.237.016.241.014.244.012.247.011.25.008.254.005.257.004.26.001.26-.001.257-.004.254-.005.25-.008.247-.011.244-.012.241-.014.237-.016.233-.018.231-.021.226-.022.224-.023.22-.026.216-.027.212-.028.21-.031.205-.032.202-.033.198-.034.194-.036.191-.038.187-.038.183-.04.179-.041.175-.042.172-.043.168-.043.163-.045.16-.046.155-.046.152-.048.148-.048.143-.048.139-.049.136-.05.131-.05.126-.051.123-.051.118-.051.114-.052.11-.052.106-.052.101-.052.096-.052.092-.052.088-.052.083-.052.079-.052.074-.051.07-.052.065-.051.06-.05.056-.05.051-.05.023-.025.023-.024.021-.024.02-.025.019-.024.018-.024.017-.023.015-.024.014-.023.013-.023.012-.023.01-.023.01-.022.008-.022.006-.023.006-.021.004-.022.004-.021.001-.021.001-.021-.001-.021-.001-.021-.004-.021-.004-.022-.006-.021-.006-.023-.008-.022-.01-.022-.01-.023-.012-.023-.013-.023-.014-.023-.015-.024-.017-.023-.018-.024-.019-.024-.02-.025-.021-.024-.023-.024-.023-.025-.051-.05-.056-.05-.06-.05-.065-.051-.07-.052-.074-.051-.079-.052-.083-.052-.088-.052-.092-.052-.096-.052-.101-.052-.106-.052-.11-.052-.114-.052-.118-.051-.123-.051-.126-.051-.131-.05-.136-.05-.139-.049-.143-.048-.148-.048-.152-.048-.155-.046-.16-.046-.163-.045-.168-.043-.172-.043-.175-.042-.179-.041-.183-.04-.187-.038-.191-.038-.194-.036-.198-.034-.202-.033-.205-.032-.21-.031-.212-.028-.216-.027-.22-.026-.224-.023-.226-.022-.231-.021-.233-.018-.237-.016-.241-.014-.244-.012-.247-.011-.25-.008-.254-.005-.257-.004-.26-.001-.26.001z%22%20transform%3D%22scale(.5)%22%3E%3C%2Fpath%3E%3C%2Fsymbol%3E%3C%2Fdefs%3E%3Cdefs%3E%3Csymbol%20height%3D%2224%22%20width%3D%2224%22%20id%3D%22clock%22%3E%3Cpath%20d%3D%22M12%202c5.514%200%2010%204.486%2010%2010s-4.486%2010-10%2010-10-4.486-10-10%204.486-10%2010-10zm0-2c-6.627%200-12%205.373-12%2012s5.373%2012%2012%2012%2012-5.373%2012-12-5.373-12-12-12zm5.848%2012.459c.202.038.202.333.001.372-1.907.361-6.045%201.111-6.547%201.111-.719%200-1.301-.582-1.301-1.301%200-.512.77-5.447%201.125-7.445.034-.192.312-.181.343.014l.985%206.238%205.394%201.011z%22%20transform%3D%22scale(.5)%22%3E%3C%2Fpath%3E%3C%2Fsymbol%3E%3C%2Fdefs%3E%3Cdefs%3E%3Cmarker%20orient%3D%22auto%22%20markerHeight%3D%2212%22%20markerWidth%3D%2212%22%20markerUnits%3D%22userSpaceOnUse%22%20refY%3D%225%22%20refX%3D%227.9%22%20id%3D%22arrowhead%22%3E%3Cpath%20d%3D%22M%200%200%20L%2010%205%20L%200%2010%20z%22%3E%3C%2Fpath%3E%3C%2Fmarker%3E%3C%2Fdefs%3E%3Cdefs%3E%3Cmarker%20refY%3D%224.5%22%20refX%3D%224%22%20orient%3D%22auto%22%20markerHeight%3D%228%22%20markerWidth%3D%2215%22%20id%3D%22crosshead%22%3E%3Cpath%20style%3D%22stroke-dasharray%3A%200%2C%200%3B%22%20d%3D%22M%201%2C2%20L%206%2C7%20M%206%2C2%20L%201%2C7%22%20stroke-width%3D%221pt%22%20stroke%3D%22%23000000%22%20fill%3D%22none%22%3E%3C%2Fpath%3E%3C%2Fmarker%3E%3C%2Fdefs%3E%3Cdefs%3E%3Cmarker%20orient%3D%22auto%22%20markerHeight%3D%2228%22%20markerWidth%3D%2220%22%20refY%3D%227%22%20refX%3D%2215.5%22%20id%3D%22filled-head%22%3E%3Cpath%20d%3D%22M%2018%2C7%20L9%2C13%20L14%2C7%20L9%2C1%20Z%22%3E%3C%2Fpath%3E%3C%2Fmarker%3E%3C%2Fdefs%3E%3Cdefs%3E%3Cmarker%20orient%3D%22auto%22%20markerHeight%3D%2240%22%20markerWidth%3D%2260%22%20refY%3D%2215%22%20refX%3D%2215%22%20id%3D%22sequencenumber%22%3E%3Ccircle%20r%3D%226%22%20cy%3D%2215%22%20cx%3D%2215%22%3E%3C%2Fcircle%3E%3C%2Fmarker%3E%3C%2Fdefs%3E%3Cg%3E%3Crect%20class%3D%22note%22%20ry%3D%220%22%20rx%3D%220%22%20height%3D%2239%22%20width%3D%22532%22%20stroke%3D%22%23666%22%20fill%3D%22%23EDF2AE%22%20y%3D%2275%22%20x%3D%2261.5%22%3E%3C%2Frect%3E%3Ctext%20style%3D%22font-size%3A%2016px%3B%20font-weight%3A%20400%3B%22%20dy%3D%221em%22%20class%3D%22noteText%22%20alignment-baseline%3D%22middle%22%20dominant-baseline%3D%22middle%22%20text-anchor%3D%22middle%22%20y%3D%2280%22%20x%3D%22328%22%3E%3Ctspan%20x%3D%22328%22%3E%E8%BF%90%E8%90%A5%2F%E5%BC%80%E5%8F%91%E5%9C%A8%E5%90%8E%E5%8F%B0%E9%85%8D%E7%BD%AE%E8%A7%84%E5%88%99%3C%2Ftspan%3E%3C%2Ftext%3E%3C%2Fg%3E%3Cg%3E%3Crect%20class%3D%22note%22%20ry%3D%220%22%20rx%3D%220%22%20height%3D%2239%22%20width%3D%22786.5%22%20stroke%3D%22%23666%22%20fill%3D%22%23EDF2AE%22%20y%3D%22289%22%20x%3D%22923.5%22%3E%3C%2Frect%3E%3Ctext%20style%3D%22font-size%3A%2016px%3B%20font-weight%3A%20400%3B%22%20dy%3D%221em%22%20class%3D%22noteText%22%20alignment-baseline%3D%22middle%22%20dominant-baseline%3D%22middle%22%20text-anchor%3D%22middle%22%20y%3D%22294%22%20x%3D%221317%22%3E%3Ctspan%20x%3D%221317%22%3E%E5%BA%94%E7%94%A8%E7%AB%AF%E5%AE%9E%E6%97%B6%E6%84%9F%E7%9F%A5%E5%B9%B6%E7%83%AD%E6%9B%B4%E6%96%B0%3C%2Ftspan%3E%3C%2Ftext%3E%3C%2Fg%3E%3Cg%3E%3Crect%20class%3D%22activation0%22%20ry%3D%220%22%20rx%3D%220%22%20height%3D%22876%22%20width%3D%2210%22%20stroke%3D%22%23666%22%20fill%3D%22%23EDF2AE%22%20y%3D%22384%22%20x%3D%22943.5%22%3E%3C%2Frect%3E%3C%2Fg%3E%3Cg%3E%3Crect%20class%3D%22note%22%20ry%3D%220%22%20rx%3D%220%22%20height%3D%2257%22%20width%3D%22341%22%20stroke%3D%22%23666%22%20fill%3D%22%23EDF2AE%22%20y%3D%22890%22%20x%3D%22973.5%22%3E%3C%2Frect%3E%3Ctext%20style%3D%22font-size%3A%2016px%3B%20font-weight%3A%20400%3B%22%20dy%3D%221em%22%20class%3D%22noteText%22%20alignment-baseline%3D%22middle%22%20dominant-baseline%3D%22middle%22%20text-anchor%3D%22middle%22%20y%3D%22895%22%20x%3D%221144%22%3E%3Ctspan%20x%3D%221144%22%3E%E8%BD%AC%E6%8D%A2%E9%80%BB%E8%BE%91%EF%BC%9A%3C%2Ftspan%3E%3C%2Ftext%3E%3Ctext%20style%3D%22font-size%3A%2016px%3B%20font-weight%3A%20400%3B%22%20dy%3D%221em%22%20class%3D%22noteText%22%20alignment-baseline%3D%22middle%22%20dominant-baseline%3D%22middle%22%20text-anchor%3D%22middle%22%20y%3D%22914%22%20x%3D%221144%22%3E%3Ctspan%20x%3D%221144%22%3EMap%20-%26gt%3B%20%22(include(seq.list(1%2C2)%2C%20type))%20%26amp%3B%26amp%3B%20...%22%3C%2Ftspan%3E%3C%2Ftext%3E%3C%2Fg%3E%3Cg%3E%3Crect%20class%3D%22activation0%22%20ry%3D%220%22%20rx%3D%220%22%20height%3D%2254%22%20width%3D%2210%22%20stroke%3D%22%23666%22%20fill%3D%22%23EDF2AE%22%20y%3D%221005%22%20x%3D%221397.5%22%3E%3C%2Frect%3E%3C%2Fg%3E%3Cg%3E%3Crect%20class%3D%22note%22%20ry%3D%220%22%20rx%3D%220%22%20height%3D%2239%22%20width%3D%22261%22%20stroke%3D%22%23666%22%20fill%3D%22%23EDF2AE%22%20y%3D%221211%22%20x%3D%22973.5%22%3E%3C%2Frect%3E%3Ctext%20style%3D%22font-size%3A%2016px%3B%20font-weight%3A%20400%3B%22%20dy%3D%221em%22%20class%3D%22noteText%22%20alignment-baseline%3D%22middle%22%20dominant-baseline%3D%22middle%22%20text-anchor%3D%22middle%22%20y%3D%221216%22%20x%3D%221104%22%3E%3Ctspan%20x%3D%221104%22%3E%E7%A1%AE%E4%BF%9D%E9%AB%98%E4%BC%98%E5%85%88%E7%BA%A7%E8%A7%84%E5%88%99%E6%8E%92%E5%9C%A8%E5%89%8D%E9%9D%A2%3C%2Ftspan%3E%3C%2Ftext%3E%3C%2Fg%3E%3Cg%3E%3Cline%20class%3D%22loopLine%22%20y2%3D%22480%22%20x2%3D%221696%22%20y1%3D%22480%22%20x1%3D%22759.5%22%3E%3C%2Fline%3E%3Cline%20class%3D%22loopLine%22%20y2%3D%221260%22%20x2%3D%221696%22%20y1%3D%22480%22%20x1%3D%221696%22%3E%3C%2Fline%3E%3Cline%20class%3D%22loopLine%22%20y2%3D%221260%22%20x2%3D%221696%22%20y1%3D%221260%22%20x1%3D%22759.5%22%3E%3C%2Fline%3E%3Cline%20class%3D%22loopLine%22%20y2%3D%221260%22%20x2%3D%22759.5%22%20y1%3D%22480%22%20x1%3D%22759.5%22%3E%3C%2Fline%3E%3Cline%20style%3D%22stroke-dasharray%3A%203%2C%203%3B%22%20class%3D%22loopLine%22%20y2%3D%22675%22%20x2%3D%221696%22%20y1%3D%22675%22%20x1%3D%22759.5%22%3E%3C%2Fline%3E%3Cpolygon%20class%3D%22labelBox%22%20points%3D%22759.5%2C480%20809.5%2C480%20809.5%2C493%20801.1%2C500%20759.5%2C500%22%3E%3C%2Fpolygon%3E%3Ctext%20style%3D%22font-size%3A%2016px%3B%20font-weight%3A%20400%3B%22%20class%3D%22labelText%22%20alignment-baseline%3D%22middle%22%20dominant-baseline%3D%22middle%22%20text-anchor%3D%22middle%22%20y%3D%22493%22%20x%3D%22785%22%3Ealt%3C%2Ftext%3E%3Ctext%20style%3D%22font-size%3A%2016px%3B%20font-weight%3A%20400%3B%22%20class%3D%22loopText%22%20text-anchor%3D%22middle%22%20y%3D%22498%22%20x%3D%221252.75%22%3E%3Ctspan%20x%3D%221252.75%22%3E%5B%E9%85%8D%E7%BD%AE%E5%80%BC%E4%B8%BA%E7%A9%BA%2F%E6%97%A0%E6%95%88%5D%3C%2Ftspan%3E%3C%2Ftext%3E%3Ctext%20style%3D%22font-size%3A%2016px%3B%20font-weight%3A%20400%3B%22%20class%3D%22loopText%22%20text-anchor%3D%22middle%22%20y%3D%22693%22%20x%3D%221227.75%22%3E%5B%E9%85%8D%E7%BD%AE%E5%80%BC%E4%B8%BA%E6%9C%89%E6%95%88%20JSON%5D%3C%2Ftext%3E%3C%2Fg%3E%3Cg%3E%3Crect%20class%3D%22note%22%20ry%3D%220%22%20rx%3D%220%22%20height%3D%2239%22%20width%3D%22786.5%22%20stroke%3D%22%23666%22%20fill%3D%22%23EDF2AE%22%20y%3D%221270%22%20x%3D%22923.5%22%3E%3C%2Frect%3E%3Ctext%20style%3D%22font-size%3A%2016px%3B%20font-weight%3A%20400%3B%22%20dy%3D%221em%22%20class%3D%22noteText%22%20alignment-baseline%3D%22middle%22%20dominant-baseline%3D%22middle%22%20text-anchor%3D%22middle%22%20y%3D%221275%22%20x%3D%221317%22%3E%3Ctspan%20x%3D%221317%22%3E%E6%B5%81%E7%A8%8B%E7%BB%93%E6%9D%9F%EF%BC%8C%E6%96%B0%E8%A7%84%E5%88%99%E5%8D%B3%E5%88%BB%E7%94%9F%E6%95%88%3C%2Ftspan%3E%3C%2Ftext%3E%3C%2Fg%3E%3Ctext%20style%3D%22font-size%3A%2016px%3B%20font-weight%3A%20400%3B%22%20dy%3D%221em%22%20class%3D%22messageText%22%20alignment-baseline%3D%22middle%22%20dominant-baseline%3D%22middle%22%20text-anchor%3D%22middle%22%20y%3D%22129%22%20x%3D%2288%22%3E1.%20%E8%BF%90%E8%90%A5%E9%85%8D%E7%BD%AE%E8%A7%84%E5%88%99%20(JSON%E6%A0%BC%E5%BC%8F)%3C%2Ftext%3E%3Ctext%20style%3D%22font-size%3A%2016px%3B%20font-weight%3A%20400%3B%22%20dy%3D%221em%22%20class%3D%22messageText%22%20alignment-baseline%3D%22middle%22%20dominant-baseline%3D%22middle%22%20text-anchor%3D%22middle%22%20y%3D%22148%22%20x%3D%2288%22%3E(%E5%90%ABmatchRule%2C%20configDetail%E7%AD%89)%3C%2Ftext%3E%3Cpath%20style%3D%22fill%3A%20none%3B%22%20marker-start%3D%22url(%23sequencenumber)%22%20marker-end%3D%22url(%23arrowhead)%22%20stroke%3D%22none%22%20stroke-width%3D%222%22%20class%3D%22messageLine0%22%20d%3D%22M%2087.5%2C193%20C%20147.5%2C183%20147.5%2C223%2087.5%2C213%22%3E%3C%2Fpath%3E%3Ctext%20class%3D%22sequenceNumber%22%20text-anchor%3D%22middle%22%20font-size%3D%2212px%22%20font-family%3D%22sans-serif%22%20y%3D%22197%22%20x%3D%2287.5%22%3E1%3C%2Ftext%3E%3Ctext%20style%3D%22font-size%3A%2016px%3B%20font-weight%3A%20400%3B%22%20dy%3D%221em%22%20class%3D%22messageText%22%20alignment-baseline%3D%22middle%22%20dominant-baseline%3D%22middle%22%20text-anchor%3D%22middle%22%20y%3D%22238%22%20x%3D%22326%22%3E2.%20%E6%8E%A8%E9%80%81%E9%85%8D%E7%BD%AE%E5%8F%98%E6%9B%B4%20(Key%3A%20rights.myCoupon.rule.release.xxx)%3C%2Ftext%3E%3Cline%20style%3D%22fill%3A%20none%3B%22%20marker-start%3D%22url(%23sequencenumber)%22%20marker-end%3D%22url(%23arrowhead)%22%20stroke%3D%22none%22%20stroke-width%3D%222%22%20class%3D%22messageLine0%22%20y2%3D%22279%22%20x2%3D%22564.5%22%20y1%3D%22279%22%20x1%3D%2287.5%22%3E%3C%2Fline%3E%3Ctext%20class%3D%22sequenceNumber%22%20text-anchor%3D%22middle%22%20font-size%3D%2212px%22%20font-family%3D%22sans-serif%22%20y%3D%22283%22%20x%3D%2287.5%22%3E2%3C%2Ftext%3E%3Ctext%20style%3D%22font-size%3A%2016px%3B%20font-weight%3A%20400%3B%22%20dy%3D%221em%22%20class%3D%22messageText%22%20alignment-baseline%3D%22middle%22%20dominant-baseline%3D%22middle%22%20text-anchor%3D%22middle%22%20y%3D%22343%22%20x%3D%22757%22%3E3.%20%E8%A7%A6%E5%8F%91%E7%9B%91%E5%90%AC%E5%9B%9E%E8%B0%83%20(PrefixListener.onUpdate)%3C%2Ftext%3E%3Cline%20style%3D%22fill%3A%20none%3B%22%20marker-start%3D%22url(%23sequencenumber)%22%20marker-end%3D%22url(%23arrowhead)%22%20stroke%3D%22none%22%20stroke-width%3D%222%22%20class%3D%22messageLine0%22%20y2%3D%22384%22%20x2%3D%22944.5%22%20y1%3D%22384%22%20x1%3D%22569.5%22%3E%3C%2Fline%3E%3Ctext%20class%3D%22sequenceNumber%22%20text-anchor%3D%22middle%22%20font-size%3D%2212px%22%20font-family%3D%22sans-serif%22%20y%3D%22388%22%20x%3D%22569.5%22%3E3%3C%2Ftext%3E%3Ctext%20style%3D%22font-size%3A%2016px%3B%20font-weight%3A%20400%3B%22%20dy%3D%221em%22%20class%3D%22messageText%22%20alignment-baseline%3D%22middle%22%20dominant-baseline%3D%22middle%22%20text-anchor%3D%22middle%22%20y%3D%22399%22%20x%3D%22954%22%3E4.%20%E8%8E%B7%E5%8F%96%E5%8F%98%E6%9B%B4%E5%90%8E%E7%9A%84%20JSON%20%E5%AD%97%E7%AC%A6%E4%B8%B2%3C%2Ftext%3E%3Cpath%20style%3D%22fill%3A%20none%3B%22%20marker-start%3D%22url(%23sequencenumber)%22%20marker-end%3D%22url(%23arrowhead)%22%20stroke%3D%22none%22%20stroke-width%3D%222%22%20class%3D%22messageLine0%22%20d%3D%22M%20953.5%2C440%20C%201013.5%2C430%201013.5%2C470%20953.5%2C460%22%3E%3C%2Fpath%3E%3Ctext%20class%3D%22sequenceNumber%22%20text-anchor%3D%22middle%22%20font-size%3D%2212px%22%20font-family%3D%22sans-serif%22%20y%3D%22444%22%20x%3D%22953.5%22%3E4%3C%2Ftext%3E%3Ctext%20style%3D%22font-size%3A%2016px%3B%20font-weight%3A%20400%3B%22%20dy%3D%221em%22%20class%3D%22messageText%22%20alignment-baseline%3D%22middle%22%20dominant-baseline%3D%22middle%22%20text-anchor%3D%22middle%22%20y%3D%22533%22%20x%3D%221317%22%3E5.%20%E7%A7%BB%E9%99%A4%E5%AF%B9%E5%BA%94%E8%A7%84%E5%88%99%20(Remove%20Key)%3C%2Ftext%3E%3Cline%20style%3D%22fill%3A%20none%3B%22%20marker-start%3D%22url(%23sequencenumber)%22%20marker-end%3D%22url(%23arrowhead)%22%20stroke%3D%22none%22%20stroke-width%3D%222%22%20class%3D%22messageLine0%22%20y2%3D%22574%22%20x2%3D%221681%22%20y1%3D%22574%22%20x1%3D%22953.5%22%3E%3C%2Fline%3E%3Ctext%20class%3D%22sequenceNumber%22%20text-anchor%3D%22middle%22%20font-size%3D%2212px%22%20font-family%3D%22sans-serif%22%20y%3D%22578%22%20x%3D%22953.5%22%3E5%3C%2Ftext%3E%3Ctext%20style%3D%22font-size%3A%2016px%3B%20font-weight%3A%20400%3B%22%20dy%3D%221em%22%20class%3D%22messageText%22%20alignment-baseline%3D%22middle%22%20dominant-baseline%3D%22middle%22%20text-anchor%3D%22middle%22%20y%3D%22589%22%20x%3D%22954%22%3E%E6%9B%B4%E6%96%B0%E6%9C%AC%E5%9C%B0%E8%A7%84%E5%88%99%E5%88%97%E8%A1%A8%20(Sort)%3C%2Ftext%3E%3Cpath%20style%3D%22stroke-dasharray%3A%203%2C%203%3B%20fill%3A%20none%3B%22%20marker-start%3D%22url(%23sequencenumber)%22%20marker-end%3D%22url(%23arrowhead)%22%20stroke%3D%22none%22%20stroke-width%3D%222%22%20class%3D%22messageLine1%22%20d%3D%22M%20953.5%2C630%20C%201013.5%2C620%201013.5%2C660%20953.5%2C650%22%3E%3C%2Fpath%3E%3Ctext%20class%3D%22sequenceNumber%22%20text-anchor%3D%22middle%22%20font-size%3D%2212px%22%20font-family%3D%22sans-serif%22%20y%3D%22634%22%20x%3D%22953.5%22%3E6%3C%2Ftext%3E%3Ctext%20style%3D%22font-size%3A%2016px%3B%20font-weight%3A%20400%3B%22%20dy%3D%221em%22%20class%3D%22messageText%22%20alignment-baseline%3D%22middle%22%20dominant-baseline%3D%22middle%22%20text-anchor%3D%22middle%22%20y%3D%22723%22%20x%3D%22954%22%3E6.%20JSON%20%E5%8F%8D%E5%BA%8F%E5%88%97%E5%8C%96%20-%26gt%3B%20CouponConfigBean%3C%2Ftext%3E%3Cpath%20style%3D%22fill%3A%20none%3B%22%20marker-start%3D%22url(%23sequencenumber)%22%20marker-end%3D%22url(%23arrowhead)%22%20stroke%3D%22none%22%20stroke-width%3D%222%22%20class%3D%22messageLine0%22%20d%3D%22M%20953.5%2C764%20C%201013.5%2C754%201013.5%2C794%20953.5%2C784%22%3E%3C%2Fpath%3E%3Ctext%20class%3D%22sequenceNumber%22%20text-anchor%3D%22middle%22%20font-size%3D%2212px%22%20font-family%3D%22sans-serif%22%20y%3D%22768%22%20x%3D%22953.5%22%3E7%3C%2Ftext%3E%3Ctext%20style%3D%22font-size%3A%2016px%3B%20font-weight%3A%20400%3B%22%20dy%3D%221em%22%20class%3D%22messageText%22%20alignment-baseline%3D%22middle%22%20dominant-baseline%3D%22middle%22%20text-anchor%3D%22middle%22%20y%3D%22809%22%20x%3D%22954%22%3E7.%20%E5%B0%86%20matchRule%20Map%20%E8%BD%AC%E6%8D%A2%E4%B8%BA%20Aviator%20%E8%A1%A8%E8%BE%BE%E5%BC%8F%E5%AD%97%E7%AC%A6%E4%B8%B2%3C%2Ftext%3E%3Cpath%20style%3D%22fill%3A%20none%3B%22%20marker-start%3D%22url(%23sequencenumber)%22%20marker-end%3D%22url(%23arrowhead)%22%20stroke%3D%22none%22%20stroke-width%3D%222%22%20class%3D%22messageLine0%22%20d%3D%22M%20953.5%2C850%20C%201013.5%2C840%201013.5%2C880%20953.5%2C870%22%3E%3C%2Fpath%3E%3Ctext%20class%3D%22sequenceNumber%22%20text-anchor%3D%22middle%22%20font-size%3D%2212px%22%20font-family%3D%22sans-serif%22%20y%3D%22854%22%20x%3D%22953.5%22%3E8%3C%2Ftext%3E%3Ctext%20style%3D%22font-size%3A%2016px%3B%20font-weight%3A%20400%3B%22%20dy%3D%221em%22%20class%3D%22messageText%22%20alignment-baseline%3D%22middle%22%20dominant-baseline%3D%22middle%22%20text-anchor%3D%22middle%22%20y%3D%22962%22%20x%3D%221176%22%3E8.%20%E7%BC%96%E8%AF%91%E8%A1%A8%E8%BE%BE%E5%BC%8F%3A%20AviatorEvaluator.compile(script%2C%20true)%3C%2Ftext%3E%3Cline%20style%3D%22fill%3A%20none%3B%22%20marker-start%3D%22url(%23sequencenumber)%22%20marker-end%3D%22url(%23arrowhead)%22%20stroke%3D%22none%22%20stroke-width%3D%222%22%20class%3D%22messageLine0%22%20y2%3D%221003%22%20x2%3D%221398.5%22%20y1%3D%221003%22%20x1%3D%22953.5%22%3E%3C%2Fline%3E%3Ctext%20class%3D%22sequenceNumber%22%20text-anchor%3D%22middle%22%20font-size%3D%2212px%22%20font-family%3D%22sans-serif%22%20y%3D%221007%22%20x%3D%22953.5%22%3E9%3C%2Ftext%3E%3Ctext%20style%3D%22font-size%3A%2016px%3B%20font-weight%3A%20400%3B%22%20dy%3D%221em%22%20class%3D%22messageText%22%20alignment-baseline%3D%22middle%22%20dominant-baseline%3D%22middle%22%20text-anchor%3D%22middle%22%20y%3D%221018%22%20x%3D%221177%22%3E9.%20%E8%BF%94%E5%9B%9E%E7%BC%96%E8%AF%91%E5%90%8E%E7%9A%84%20Expression%20%E5%AF%B9%E8%B1%A1%3C%2Ftext%3E%3Cline%20style%3D%22stroke-dasharray%3A%203%2C%203%3B%20fill%3A%20none%3B%22%20marker-start%3D%22url(%23sequencenumber)%22%20marker-end%3D%22url(%23arrowhead)%22%20stroke%3D%22none%22%20stroke-width%3D%222%22%20class%3D%22messageLine1%22%20y2%3D%221059%22%20x2%3D%22956.5%22%20y1%3D%221059%22%20x1%3D%221397.5%22%3E%3C%2Fline%3E%3Ctext%20class%3D%22sequenceNumber%22%20text-anchor%3D%22middle%22%20font-size%3D%2212px%22%20font-family%3D%22sans-serif%22%20y%3D%221063%22%20x%3D%221397.5%22%3E10%3C%2Ftext%3E%3Ctext%20style%3D%22font-size%3A%2016px%3B%20font-weight%3A%20400%3B%22%20dy%3D%221em%22%20class%3D%22messageText%22%20alignment-baseline%3D%22middle%22%20dominant-baseline%3D%22middle%22%20text-anchor%3D%22middle%22%20y%3D%221074%22%20x%3D%221317%22%3E10.%20%E6%9B%B4%E6%96%B0%E7%BC%93%E5%AD%98%3A%20map.put(ruleId%2C%20Expression)%3C%2Ftext%3E%3Cline%20style%3D%22fill%3A%20none%3B%22%20marker-start%3D%22url(%23sequencenumber)%22%20marker-end%3D%22url(%23arrowhead)%22%20stroke%3D%22none%22%20stroke-width%3D%222%22%20class%3D%22messageLine0%22%20y2%3D%221115%22%20x2%3D%221681%22%20y1%3D%221115%22%20x1%3D%22953.5%22%3E%3C%2Fline%3E%3Ctext%20class%3D%22sequenceNumber%22%20text-anchor%3D%22middle%22%20font-size%3D%2212px%22%20font-family%3D%22sans-serif%22%20y%3D%221119%22%20x%3D%22953.5%22%3E11%3C%2Ftext%3E%3Ctext%20style%3D%22font-size%3A%2016px%3B%20font-weight%3A%20400%3B%22%20dy%3D%221em%22%20class%3D%22messageText%22%20alignment-baseline%3D%22middle%22%20dominant-baseline%3D%22middle%22%20text-anchor%3D%22middle%22%20y%3D%221130%22%20x%3D%22954%22%3E11.%20%E9%87%8D%E6%96%B0%E6%8E%92%E5%BA%8F%E8%A7%84%E5%88%99%E5%88%97%E8%A1%A8%20(%E6%8C%89%20Score%20%E5%80%92%E5%BA%8F)%3C%2Ftext%3E%3Cpath%20style%3D%22fill%3A%20none%3B%22%20marker-start%3D%22url(%23sequencenumber)%22%20marker-end%3D%22url(%23arrowhead)%22%20stroke%3D%22none%22%20stroke-width%3D%222%22%20class%3D%22messageLine0%22%20d%3D%22M%20953.5%2C1171%20C%201013.5%2C1161%201013.5%2C1201%20953.5%2C1191%22%3E%3C%2Fpath%3E%3Ctext%20class%3D%22sequenceNumber%22%20text-anchor%3D%22middle%22%20font-size%3D%2212px%22%20font-family%3D%22sans-serif%22%20y%3D%221175%22%20x%3D%22953.5%22%3E12%3C%2Ftext%3E%3C%2Fsvg%3E)
流程图关键点解析:
- 触发源 :流程始于管理后台的配置变更,通过 DUCC 的推送机制触发应用端的监听器。
- 核心转换 (Translation):应用服务 (
MyCouponRuleService) 充当了适配器的角色,将静态的 JSON 配置(业务视图)转换为可执行的 Aviator 脚本字符串(机器视图)。 - 预编译 :
- 关键步骤 8:显式调用
AviatorEvaluator.compile(script, true)。 - 目的:将脚本编译为 Java 字节码并生成
Expression对象。 - 避坑:这里只在配置变更时执行一次,避免了在运行时高频请求中重复编译,彻底杜绝了 Metaspace 内存泄漏的风险。
- 缓存更新 :编译后的
Expression对象被存入内存 Map 中,后续的业务请求直接从 Map 中获取对象执行execute(),性能极高。 - 重排序 :每次规则更新后,都会触发一次列表重排序,保证高权重的规则(Score 高)始终优先匹配。
3.2.2 配置类型层设计
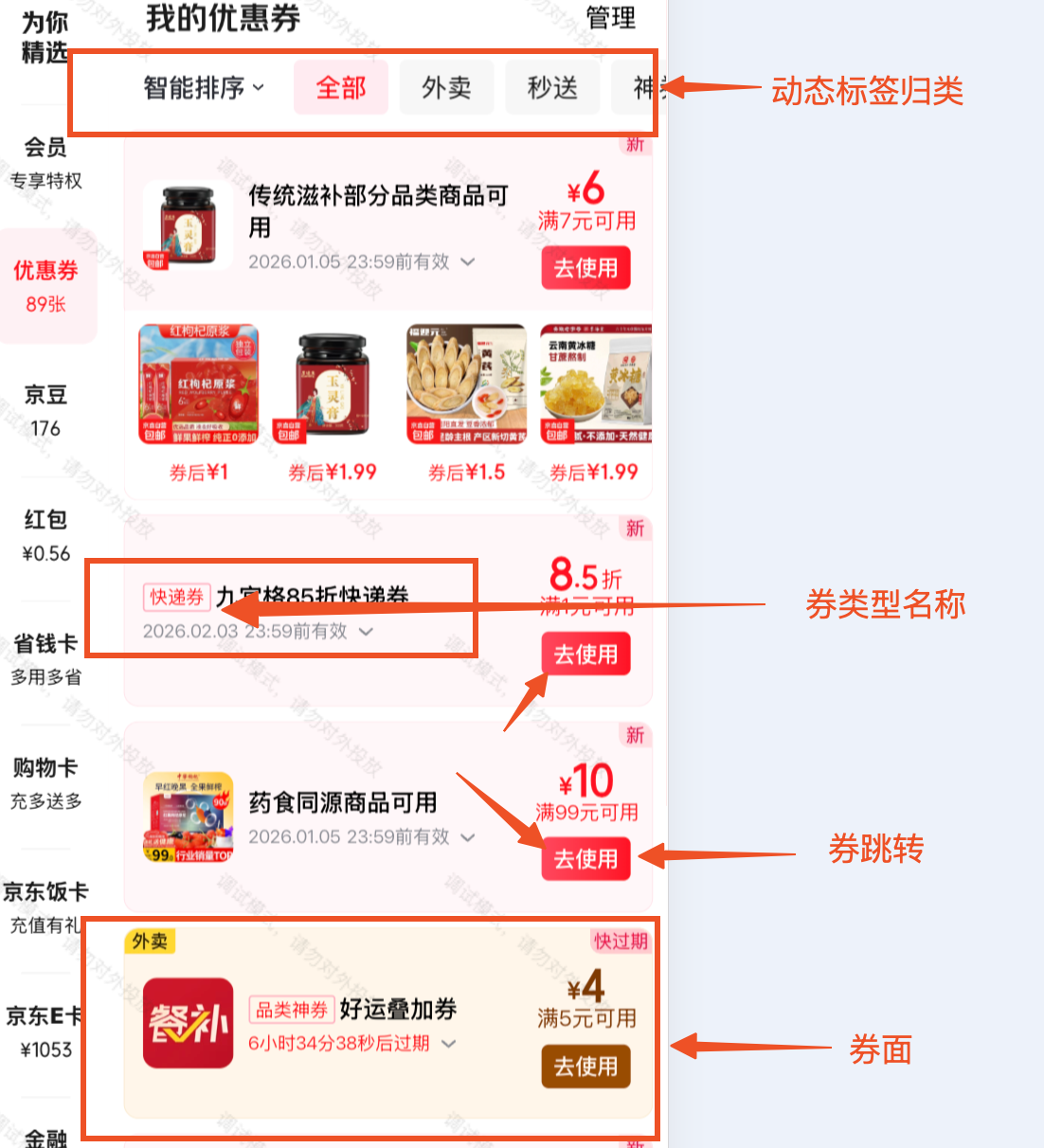
券面配置
券面配置控制优惠券在用户端的展示效果:包含各种背景,字体颜色,文案描述等组成的券视图。
跳转配置
跳转配置,即用户点击去使用按钮跳转的落地页。 支持分端语言配置跳转链接或者下发弹窗文案。
标签归类配置
标签配置实现券的动态标签归类。 归类规则由产品提供。
券类型名称规则配置
券类型名称,即展示当前券类型展示的类型文案。
3.2.3 配置引擎层设计
配置解析器(Config Parser)
配置解析器负责将JSON配置转换为可执行的规则脚本对象:可以类比翻译器。如下表,实现定制化的转换器。将matchRule 转换为aviatorRule 。将静态的 JSON 配置(业务视图)转换为可执行的 Aviator 脚本字符串(机器视图)
| 输入 | 输出 |
|---|---|
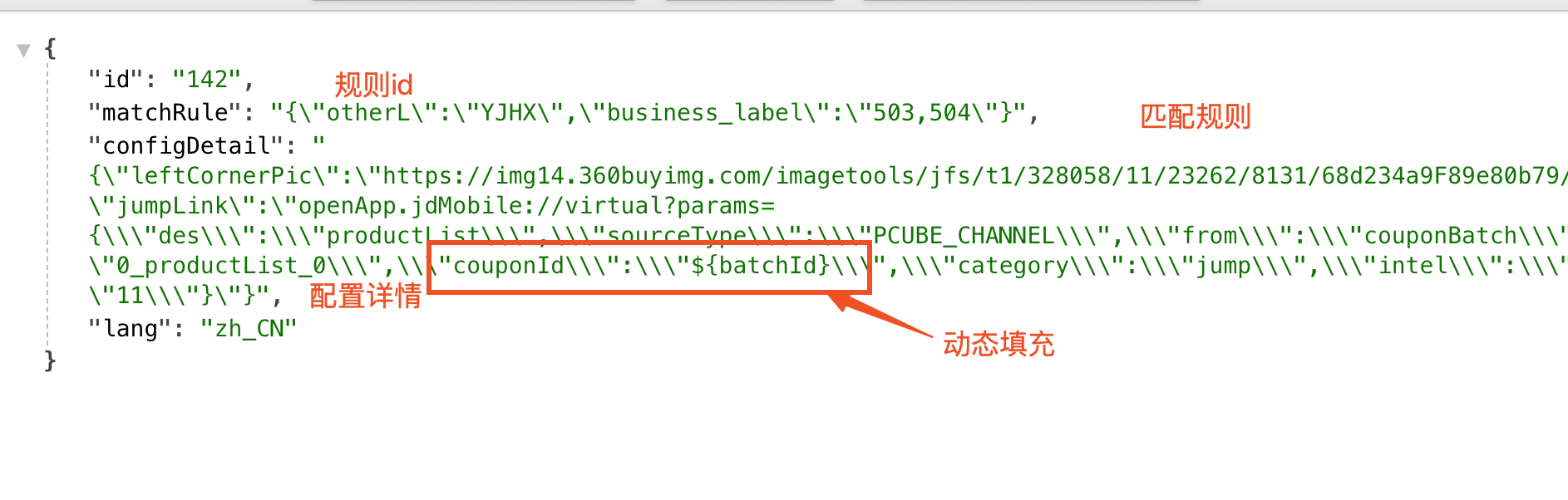 | 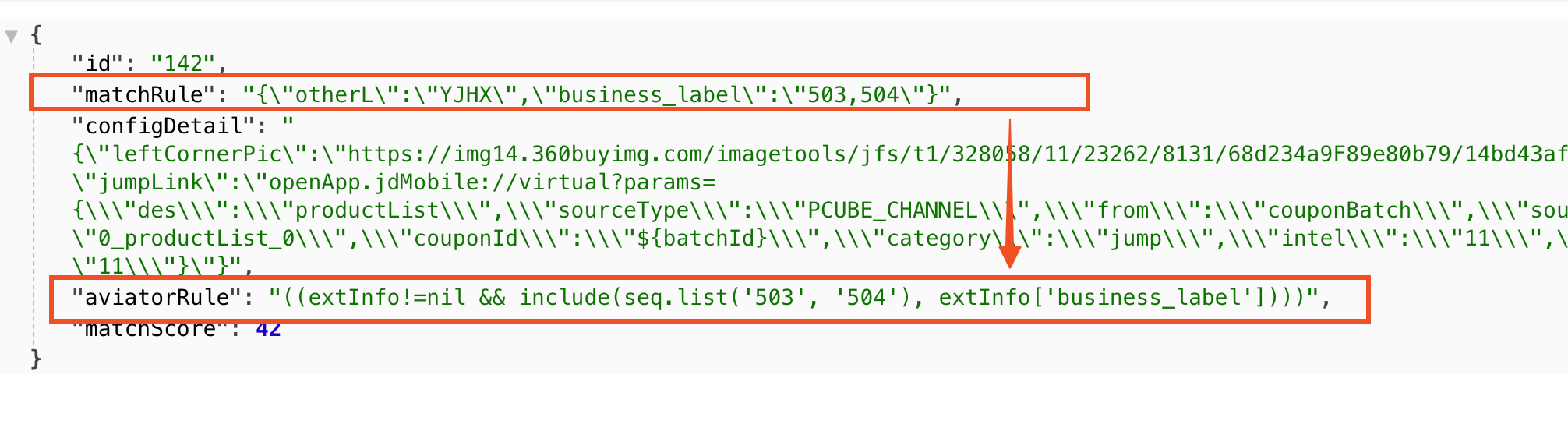 |
配置缓存(Config Cache)
解析转换后的规则脚本会被预编译,预编译结果会进行缓存 。
配置热更新(Hot Reload)
配置热更新机制确保配置变更能够实时生效。具体是利用ducc的变更监听回调机制实现。
Aviator规则引擎集成
通过Aviator规则引擎为复杂业务规则提供强大的匹配计算能力。
3.3 配置化能力展示
通过动态化架构设计,权益中心券列表展示以及券跳转实现在多个功能点位实现了配置化展示能力。
| 配置化功能设计 | 实现方式 | 备注 | 动态配置位置 |
|---|---|---|---|
| 标签过滤项 | ducc+规则引擎(aviator) | 研发配置:动态下发自定义过滤选项。产品需提供该过滤选项即券业务类型的识别方式,即根据券组合属性打标。 |  |
| 排序选项 | ducc+jsonPath | 研发配置:动态下发支持按照指定字段指定的排序 | |
| 券左角标 | ducc+规则引擎(aviator)+本地缓存 | 产品配置:券面管理后台 | |
| 券右角标 | ducc | 研发配置:根据时间优先级配置 | |
| 券说明文案 | ducc+jsonPath | 动态指定多个券属性取值 | |
| 券背景图 | ducc+规则引擎(aviator)+本地缓存 | 产品配置:券面管理后台 | |
| 券跳转 | ducc+规则引擎(aviator)+本地缓存 | 产品配置:券面管理后台 |
4. 核心技术实现
4.1 规则引擎技术选型
在决定引入规则引擎后,我们对市面上的主流方案进行了深度调研。
| 维度 | AviatorScript | Groovy | Drools | QLExpress |
|---|---|---|---|---|
| 定位 | 高性能表达式求值引擎 | 动态语言,全功能 JVM 语言 | 重量级规则引擎,支持推理 | 阿里开源,类 Java 语法 |
| 性能 | 极高(编译为字节码,ASM 实现) | 高(但在高并发下 ClassLoader 压力大) | 中(Rete 算法复杂,初始化慢) | 高 |
| 轻量级 | 极轻(Jar 包仅几百 KB,无繁重依赖) | 较重(需引入 Groovy SDK) | 极重(适合复杂推理场景) | 轻 |
| 学习成本 | 低(类 Java 语法,专注于表达式) | 中(需掌握 Groovy 语法) | 高(DRL 语法复杂) | 低 |
| 安全性 | 高(沙箱模式,限制类加载) | 低(可调用任意 Java API,风险大) | 中 | 中 |
最终选择 Aviator 的核心理由:
- 性能为王:Aviator 专门为高性能表达式计算设计,它通过 ASM 动态生成字节码,执行效率接近原生 Java 代码。对于优惠券列表这种 核心接口,性能是第一考量。
- 纯粹与轻量:我们不需要 Drools 那样复杂的推理能力(Rete 算法),也不希望引入 Groovy 那样庞大的运行时。我们只需要一个能快速计算
A && B || C的“计算器”。 - 自定义函数支持:Aviator 允许我们注册自定义 Java 函数(如
include(),checkUserTag()),这使得我们可以将复杂的业务逻辑封装为函数,让运营配置的规则脚本更加简洁易读。
4.2 规则匹配算法:基于 Score 机制的最佳匹配
配置化上线后,最大的挑战是规则冲突。当一张券同时满足“全品类券规则”和“PLUS 会员专属规则”时,系统该听谁的?
我们设计了一套基于特征权重的打分算法 ,确保最“精准”、最“特殊”的规则优先生效。
4.2.1 评分维度与权重设计
我们根据规则条件的稀缺性和具体程度来分配权重:
- 关键词 (Keywords) —— 权重 (示例权重)
- 逻辑:这是运营强干预的手段。如果运营明确指定了某个关键词匹配,说明这是最高优先级的特例。
- Example:
keywords="PLUS_ANNIVERSARY" - 批次号 (BatchId) —— 权重 (示例权重)
- 逻辑:批次号对应具体的某一次发券活动。指定了批次号的规则,比通用的类目规则更具体。
- Example:
batchId=123456 - 限品类/限店铺 (LimitOrg/Platform) —— 权重 (示例权重)
- 逻辑:限制了适用范围,属于中等粒度的规则。
- 用户画像/标签 (UserLabel) —— 权重 (示例权重)
- 逻辑:针对特定人群的规则。
- 基础属性 (BizType/CouponType) —— 权重 (示例权重)
- 逻辑:最宽泛的规则,作为兜底。
4.2.2 算法实现细节
在 MyCouponRuleService 中,我们遍历所有配置的规则,实时计算每条规则针对当前上下文的得分:
示例代码:
public static intget Score(Map<String, String>condition) {
// 1. 基础分:规则条件的数量越多,分值越高(匹配越精确)
intscore=condition.keySet().size() **;
// 2. 维度加权
if (condition.containsKey("keywords") &&StringUtil.isNotBlank(condition.get("keywords"))) {
score+=******; // 关键词极其特殊,权重最高
score+=condition.get("keywords").length(); // 甚至考虑关键词长度,越长越具体
}
if (condition.containsKey("batchId")) {
score+=******; // 批次维度
}
if (condition.containsKey("limit_organization")) {
score+=******; // 组织维度
}
// ... 其他维度
returnscore;
}
匹配流程:
- 系统加载所有规则。
- 对每条规则计算静态 Score。
- 将规则列表按 Score 倒序排列(
Comparator.comparingInt(CouponShowConfig::getMatchScore).reversed())。 - 运行时,按顺序遍历规则列表,一旦命中(Execute 返回 true),立即返回。
这保证了系统总是优先匹配“最特殊、最具体”的规则,完美解决了规则冲突问题。
4.3 系统高可用-性能优化,引入缓存机制
实时匹配引入的性能问题
完成规则转换,规则匹配。对于一个高可用的系统来说,其实只是完成了基础的功能,后续的优化才是需要花精力去完善的事情。 引入规则引擎虽然解耦了业务逻辑,但也引入了 计算密集型操作。每一次规则匹配,本质上都是一次表达式求值运算。
假设上线后,我们要面临的流量如下:
- 单机 QPS :100(保守估计,大促高峰期远超此数)
- 每页券数量 :20 张
- 规则集数量 :40 条(且随着业务发展,规则只会越来越多)
那么cpu每秒计算100*20*20(取中间值)=40000次;
资源消耗分析 :
- CPU 密集 :Aviator 表达式虽然编译为字节码,但每次执行仍涉及上下文构建 ( Map 封装)、反射调用和逻辑运算。4万次/秒的复杂运算可能会让单核 CPU 维持在较高使用率。
- 性能耗时:如果单次匹配耗时 0.1ms,那么处理一次请求(20张券)仅规则匹配就要消耗 20 * 40 * 0.1ms = 80ms 。80ms/4c = 20ms 。这对于 TP99 要求 百毫秒以内的核心接口是绝对无法接受的。
如果没有缓存机制,引入规则引擎等同于引入了一个性能炸弹 ,随着流量或规则量的线性增长,系统 CPU 将呈现指数级崩坏。
缓存切入点:券批次batchId
之前我们已经对券批次做了介绍,券的本质是营销活动,创券即创建一个活动,活动需要绑定批次号,一个批次对应一批券实体的模版。也就是说优惠券的数据结构,有一个关键特征:
同一批次(BatchId)的优惠券,其静态属性(面额、适用范围、券类型、券业务属性)是完全一致的。
差异仅在于,用户领取后,券实体增加了一些属性:
- 券实例 ID (CouponId)
- 用户状态(是否已领取、是否已使用)等
这意味着,对于 规则匹配 和 标签归类计算 这两个最耗 CPU 的环节,只要 BatchId 相同,计算结果就是一样的。所以最佳的缓存维度是按照批次缓存改批次所对应的配置信息。
缓存方案的选择-本地缓存
在缓存设计中,我们通常会面临“本地缓存 vs 分布式缓存(Redis) vs 多级缓存”的选择。针对本场景,我们选择了纯本地缓存(Caffeine)方案。
1. 为什么不用 Redis(分布式缓存)?
- 网络 I/O 开销 :Redis 虽然快,但仍涉及网络传输和序列化/反序列化。对于计算结果这种“小而密”的数据,网络 I/O 的耗时(约 1-3ms)可能比直接在本地计算一遍还要慢。我们的目标是微秒级的响应,Redis 反而成了瓶颈。
- 爆炸半径风险 :如果使用 Redis 存储规则匹配结果,一旦 Redis 出现抖动或该 Key 被污染(例如某个规则计算出了错误结果并被写入 Redis),那么 全集群、所有用户 都会看到错误的券面。这将是一场全局性的线上事故。
- 数据一致性难题 :规则变更时,需要同时清理 Redis 和本地缓存,增加了系统的复杂度。
2. 为什么选择本地缓存(Caffeine)?
- 极致性能 :Caffeine 基于内存引用,读取耗时为 纳秒级 ,完全消除了网络开销。对于计算密集型场景,数据离 CPU 越近越好。
- 天然隔离(Bulkhead Pattern) :
- 故障隔离 :每台机器独立维护自己的缓存。假设某台机器出现匹配异常(极低概率),也只会影响该机器上的少量请求,不会扩散到整个集群。
- 计算在本机,缓存在本机 :这是最符合Data Locality(数据局部性)原则的设计。
- 适用性契合 :
- BatchId 维度 :我们的缓存 Key 是 BatchId 。虽然用户量有亿级,但有效的活动批次号(BatchId)通常只有几千到几万个。日常批次号在2w左右。
- 内存可控 :设置50,000 个 Map<String, String> 对象占用的堆内存仅数十 MB,对于现代服务器(8G/16G Heap)来说九牛一毛。日常监控下来,缓存批次维持在w记左右。
在“规则匹配”这个特定场景下, 本地缓存 是兼顾性能、稳定性和架构简单性的最佳解选择。
最终,我们选择本地缓存之王Caffeine 并对local Cache进行了一些参数调优。 主要是优化基于容量和过期策略的本地缓存配置。
示例代码:
public static final LoadingCache<Long, Map<String, String>> couponTagCache = Caffeine.newBuilder()
// 1. 容量限制:设置最大缓存条目数,防止内存溢出
.maximumSize(*)
// 2. 随机过期时间(Jitter):防止缓存雪崩
// 如果设置为固定的 10 分钟,可能导致大量热点缓存在同一时刻失效,瞬间击穿 DB/CPU
.expireAfter(new Expiry<Long, Map<String, String>>() {
@Override
public long expireAfterCreate(Long key, Map<String, String> value, long currentTime) {
// 在 [15, 30] 分钟之间随机生成失效时间
int expireTime = 15 + tagRandom.nextInt(15);
return TimeUnit.MINUTES.toNanos(expireTime);
}
// Update 和 Read 不重置过期时间,保证缓存能够按时刷新,避免脏数据长期驻留
@Override
public long expireAfterUpdate(...) { return currentDuration; }
@Override
public long expireAfterRead(...) { return currentDuration; }
})
// 3. 统计监控:开启 Stats,便于在监控大盘看到缓存命中率
.recordStats()
.build(key -> null);
缓存命中密度计算监控: 引入本地缓存后,缓存命中率在95%左右。 当规则变更会清理缓存,缓存失效。
4.4 系统高可用-规则灰度发布验证
在生产环境中,直接全量发布规则是极高风险的操作。一旦配置了错误的规则(例如将“满1000减500”的券配展示成了“无门槛标识”),可能会导致巨大的客诉资损。因此, 灰度验证机制是系统高可用的一道重要防线。任何规则变更,都必须经过“测试->预发验证 -> 线上白名单gray -> 全量生效”的晋级流程。
我们在 DUCC 配置中心定义了两套并行的规则集:
Release 规则集 ( rule.release.* ):面向全网用户生效的稳定规则。
Gray 规则集 ( rule.gray.* ):仅面向特定白名单用户生效的实验规则。
白名单验证环境,规则会被同步到Gray 规则集,白名单验证通过,全量推送后,规则被同步到Release 规则集 。
同时,配合一个 白名单配置 ( gray.pins ),存储用于测试的内部人员或特定业务用户的 PIN。
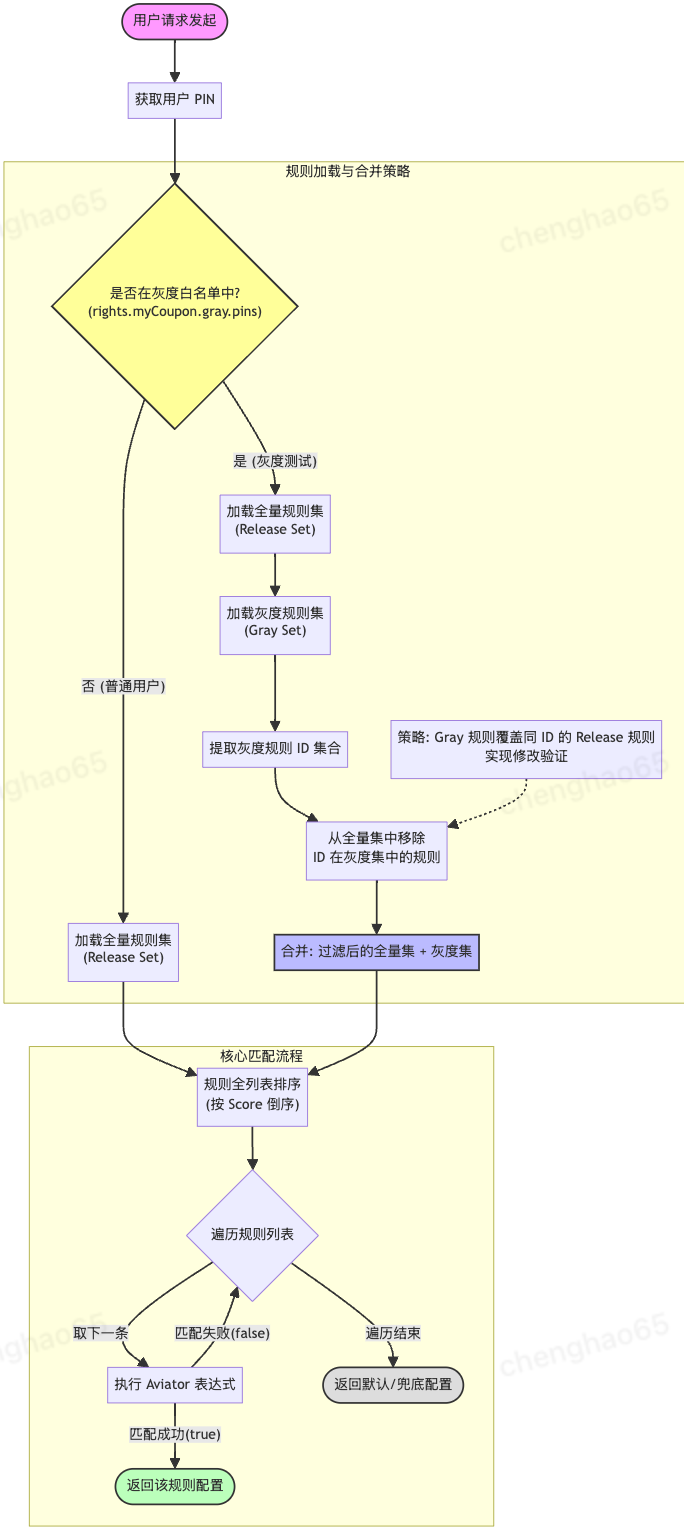
核心流程:
1. 身份判定 :当用户请求到来时,首先判断用户的 PIN 是否在灰度白名单中。
2. 规则合并 :
- 普通用户 :只加载 Release 规则集。
- 灰度用户 :加载 Release + Gray 的并集。
- 冲突处理 :如果同一个规则 ID 同时存在于 Release 和 Gray 集合中(即正在对某条线上规则进行修改验证),则 Gray 规则覆盖 Release 规则 。
3. 统一排序 :将合并后的规则列表重新进行 Score 排序,确保优先级逻辑正确。
4.5 系统高可用-上线前的压测
压测是系统上线前的关键环节,通过模拟高并发和大数据量场景,可以提前发现系统性能瓶颈,确保系统在高负载下仍能稳定运行,保障用户体验。同时,压测结果有助于合理规划资源,避免资源浪费或不足,降低系统上线后的风险,为业务决策提供数据支持。
尤其是新接口新技术的引入,我们需要进行接口压测,观察系统指标,接口性能指标是否在设计范围内,优惠券接口在上线前安排了一次压测,日常单机承载数百QPS,压测目标为单机千级QPS 。系统负载在1.0以下,cpu在30%以下。
但是在压测30qps的时候,服务直接OOM内存溢出了,然后用内存分析工具发现,和aviator对应的threaLocal有关,查询相关类似解决方案后,升级到最新版本,再次压测,危机解除,压测性能指标达到预期。 可以上线 。
大家可以想象下,如果没有经过压测,直接上线,将会带来什么样的后果。
篇幅有限,内存泄漏分析参考文章:
5. 总结
通过权益中心优惠券功能模块的配置化能力架构建设,我们不仅解决了之前面临的技术痛点,也为未来的业务发展奠定了坚实的技术基础。这次分享的目的也是希望可以为其他业务系统提供有价值的参考和借鉴。
需要强调的是,配置化能力的建设是一个持续演进的过程,需要在实践中不断优化和完善。我们将继续关注业界最佳实践,结合自身业务特点,持续提升配置化平台的能力和价值,为业务发展提供更强有力的技术支撑。
最后感谢在权益中心优惠券功能模块建设过程中辛苦付出的产品同学,测试同学。 同时 也非常感谢优惠券中台相关同事的耐心协助,以及原券功能团队的大力支持,此外,还要感谢我所研发团队给予的信任和指导,让我有机会发挥自己的一份力量,推动业务顺利落地。






