



导读
随着京东业务增长、平台商家数的大幅增加,京东的订单量急剧上涨,尤其是2025年京东发力本地生活业务,给B端订单存储带来较大压力;另一方面京喜自营做为京东低价策略心智的店铺,业务增长也是非常迅猛,一个店铺订单相当于几十近百个店铺单量总和。基于以上订单ES存储面临极大挑战,系统架构升级迫在眉睫。
本文主要介绍B端pop订单异构系统当前系统架构现状,阐述下我们面临的主要问题、以及解决思路和技术升级方案(后续持续更会有更多的技术方案细节文章);一方面为了介绍下我们当时解决问题的一些心路历程,另一方面也未了能让大家更好的了解目前这套运行了多年的系统为什么以这种形式存在、以及目前我们遇到的核心问题有哪些,对于订单ES架构存储的升级方案是什么样的。
一、系统现状
1.1 业务背景介绍:
POP订单ES最早定位是对商家提供待履约订单查询服务(非C端检索)。系统核心是写和读两个服务,写服务消费订单管道消息、pop订单JED的binlog、OFW的ODC变更消息、台账系统对账消息等更新订单ES数据;读服务提供订单列表(商家维度)、订单详情的检索服务。
系统之初仅支持已付款且达到可履约状态的订单(不包含未付款订单)检索,用户商家订单履约,主要服务于开放订单API检索及京麦端订单检索。随着业务的发展,后续消费了提单、订单拆分、预售订单等消息,对未付款订单、预售订单存储、兼容处理。
随着百万商家项目推进,服务商、自研KA商家及中小开发者对开放API提出了更多的诉求,期望能够通过更少的接口获取更多的数据,提升开发者对接及日常维护效率,开放平台侧启动开放RESTful API项目,其中订单做为商家的核心业务数据,历史开放接口不够内聚,开发者需要多个接口才能获取完整的订单信息,基于以上pop订单还异构了发票、promise、售后、评价等系统的状态信息,这些都给POP订单ES存储带来较大的挑战。
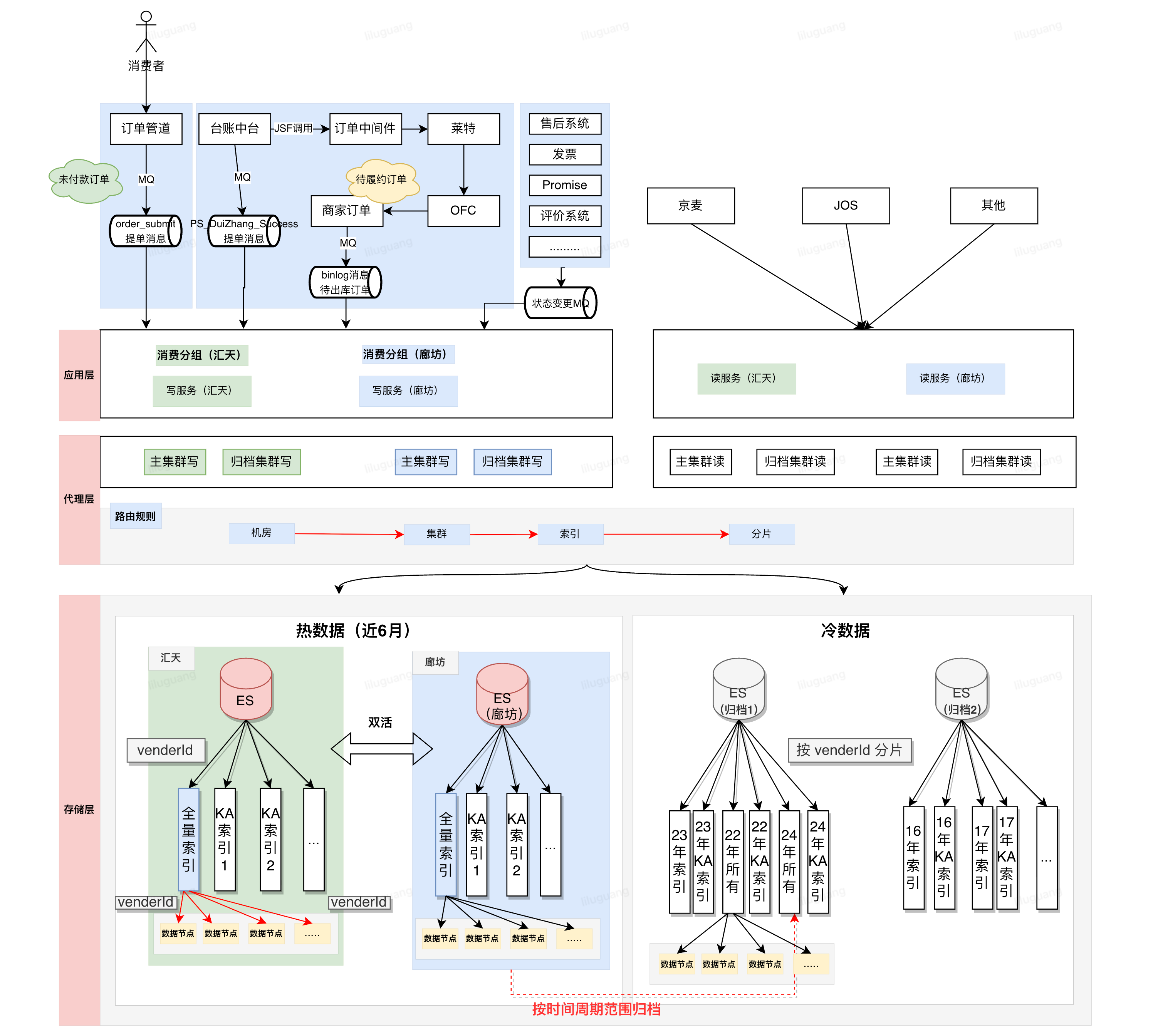
1.2 系统架构简介:
•应用层做业务处理,写服务负责消费上游各方MQ处理业务务处理,之后调用代理层服务更新订单信息;读服务核心对外提供订单列表、详情两个服务。大促高峰时可达到每分钟70万次更新写入,每分钟50万的检索查询;
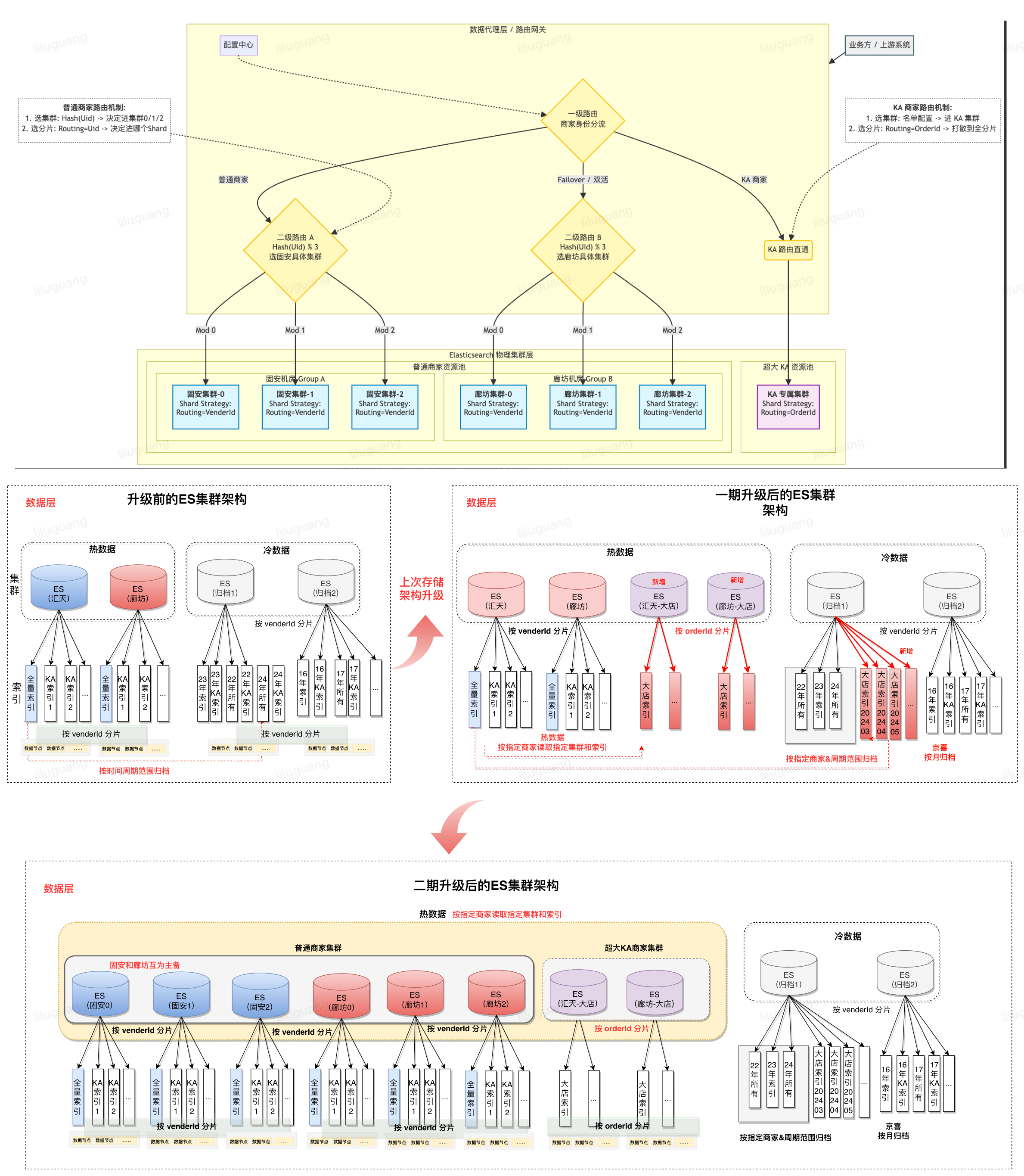
•代理层负责数据路由、读取与写入。划分为热集群读写代理、归档集群读写代理。热集群通过设置不同topic分组隔离消费实现双流架构,汇天廊坊互为主备保证系统高可用。读服务支持动态路由配置,可根据ES负载情况动态分配流量,如汇天、廊坊各百分之50流量,或汇天20%,廊坊80%;同时可以将某个商家查询流量路由到固定机房。目前归档集群考虑成本暂时并未升级至双流架构,通过ES副本机制来保障高可用。
•存储层采用ES做为存储介质,分为热集群、归档集群;热集群存储近8个月的订单数据,单个集群有98个节点(3个主节点,10个网关节点,85个数据节点)。集群中共计12个索引,其中11个KA索引(存储大商家订单数据),每个索引只有1个主分片(1副本);普通商家索引有96各数据分片(1副本);冷集群存储了16年至2024年所有的订单数据,每年创建一个索引,每个索引96分片(1副本)。
pop订单改造前的架构图如下:(为方便让大家更好理解,本图会忽略一些细节便于大家理解):
二、系统当前的核心痛点
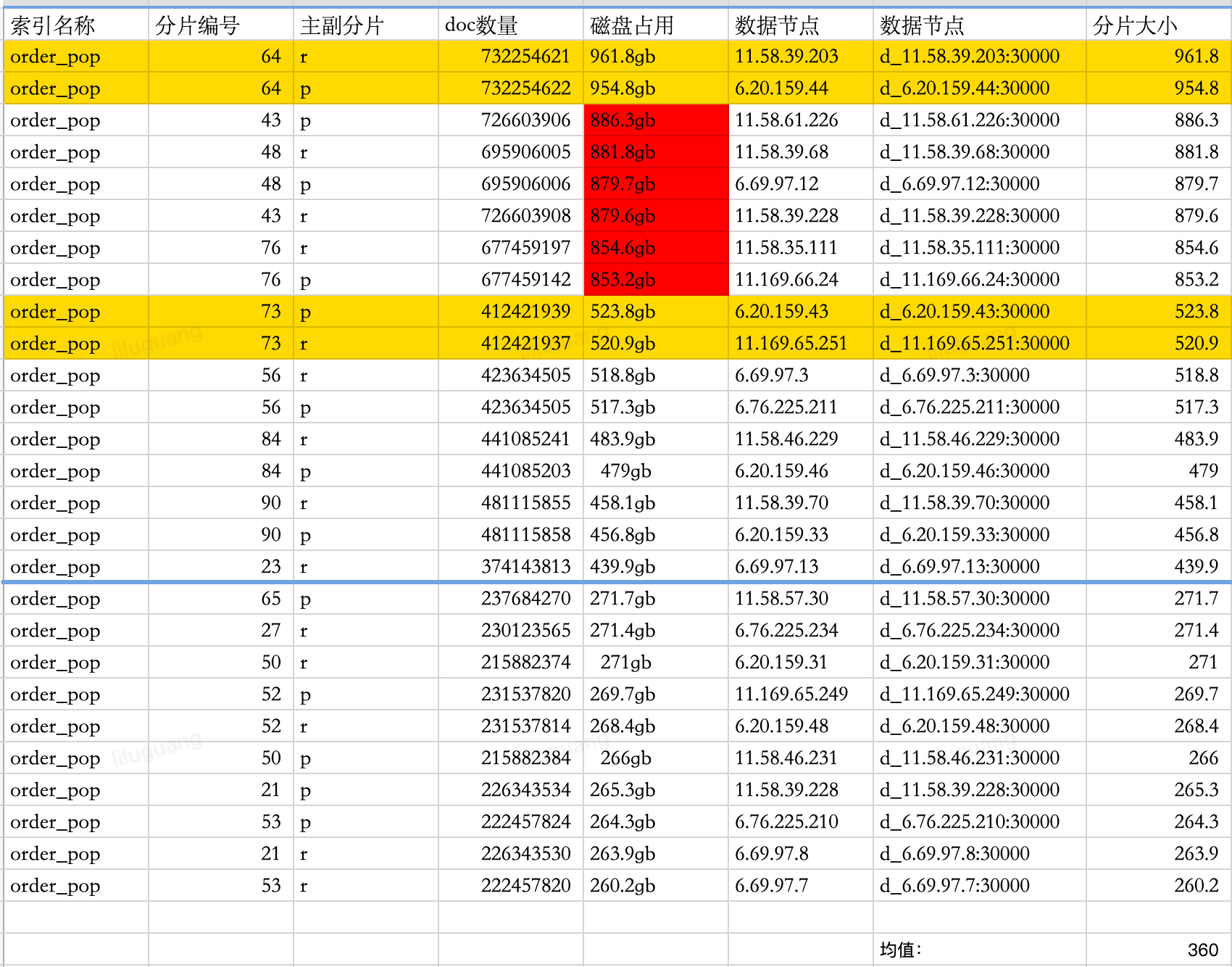
1、目前POP订单ES存在较严重的数据倾斜问题,由于是B端订单检索为了不跨索引和分片检索数据,是以venderId维度进行路由分片,确保同一个商家的订单数据存储在同一个分片。但商家的经营情况差异较大,如上边所说京喜自营做为一个京东自己运营的店铺,订单体量可以占到总订单量的1/4,类似于这样的大商家落到一个数据分片会导致某个数据分片存储超级大,最大的数据分片已经到了1TB以上。大商家的一个复杂检索查询会对所有在该分片上的商家产生较大性能波动,同时若硬件故障大分片数据在恢复迁移时都是在灾难性的。下边是升级前汇天集群部分分片数据的统计信息,数据差异达5倍之多。
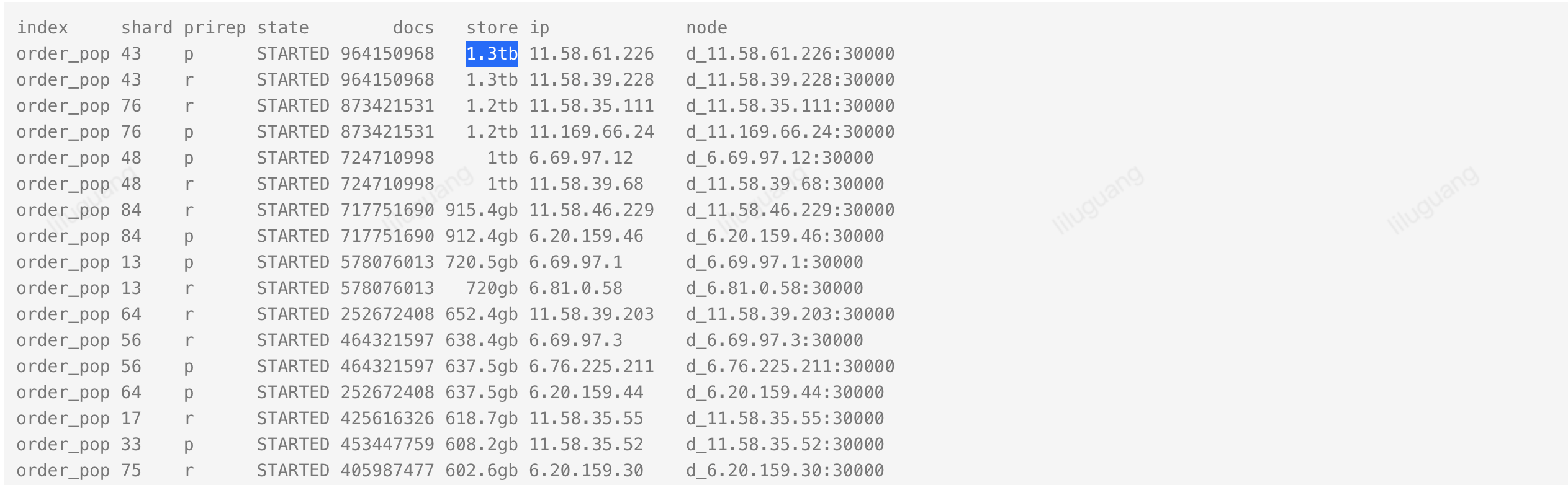
2、随着业务增长,自身的订单ES数据量持续增加,部分分片数据高达1TBG以上,ES官方推荐分片数据在50-100G,已经是官方推荐值的50倍。京喜自营订单属于二段单逻辑,C端京喜大店下单,订单会由供货商去履约,供货商同时还会是京东的一个pop商家,这个订单在京喜店铺存储一份,同时会在供应商店铺下会在存储一份,京喜大店业务给整个存储带来了0.5倍增长。
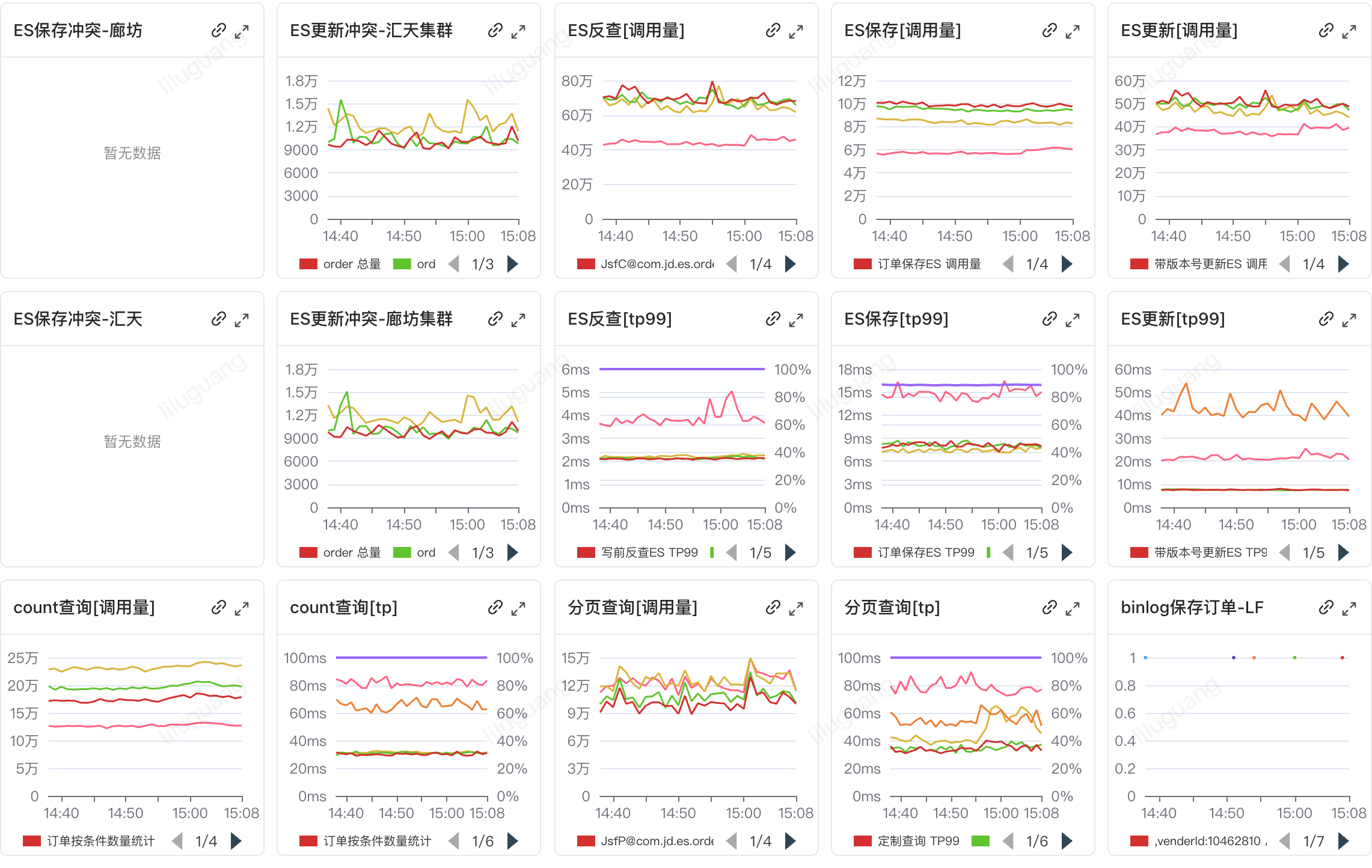
3、ES的核心数据源是上游订单数据库的binlog消息,随着业务不断迭代,接入了更多的消息如:order_submit(提单)、delete_parent_order(拆单)、orderpipe_edit_v2(管道修改)、ODC(锁定、解锁、取消)、order_state_zanting(暂停)、afs_status(售后状态)、comment_change(备注变更)等将近10+的消息。订单ES更新频次持续增加,每分钟高达30万,每新增一个MQ消费,每个订单至少会增加1次更新操作。ES的更新冲突明显增加,对于订单检索的时效性也带来了很大压力。
4、数据维护成本高,目前我们有冷热两个集群,每年两次大促前需要将热集群中超过5个月以上的订单迁移至归档集群,这个过程相对比较繁琐耗时长,DUCC变更、迁移数据、比对数据、灰度切流等等。周期较长主要是以下两个原因:
1.数据迁移范围强依赖上游订单JED线上库,速度过快对线上有影响,同时还会反查ES数据比对给线上ES也带来较大查询压力,导致无法再白天运行。
2.整个写入过程均为单个订单写入、删除ES,过程中会产生大量的Segment merge,将小段合并成大段,会影响写入性能,导致正常订单更新延迟。

三、解决方案
3.1 数据倾斜问题
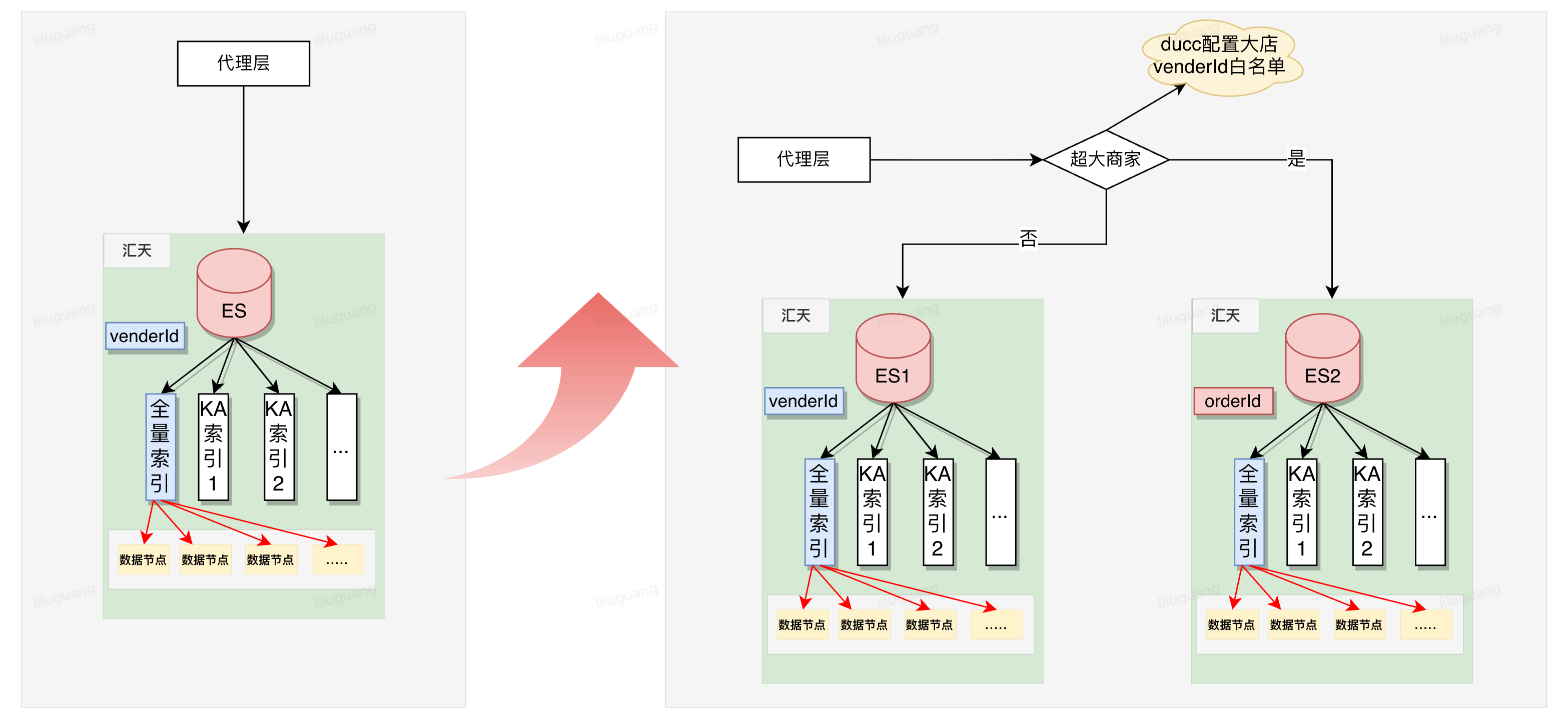
数据倾斜问题核心是我们采用了venderId进行路由,商家的体量不可控,在最初相关同学已经考虑到了这种情况,在热集群中创建了对应的单独索引进行隔离,但当时这个索引创建的时候只有一个shards,数据集中在一个分片上,并不能解决数据倾斜问题(数据仍集中在一个分片上,可能考虑跨分片聚合数据的性能问题)。
1.物理层隔离,降低影响:为大商家申请独立集群进行存储,在独立集群中为每个商家创建独立索引并根据体量配置不同的分片数量。代理层增加大商家虚拟路由逻辑,将大商家的请求routing到独立集群中指定索引,降低了大商家对其他商家带来的不确定性影响。
2.灵活的路由分片策略:原有路由策略仅支持商家维度,在代理层对集群分片路由规则做扩展支持,针对大商家存储集群的分片路由商家维度升级为订单维度,根据订单号进行路由保证各分片数据的均等。
3.2 集群中单数据分片过大问题
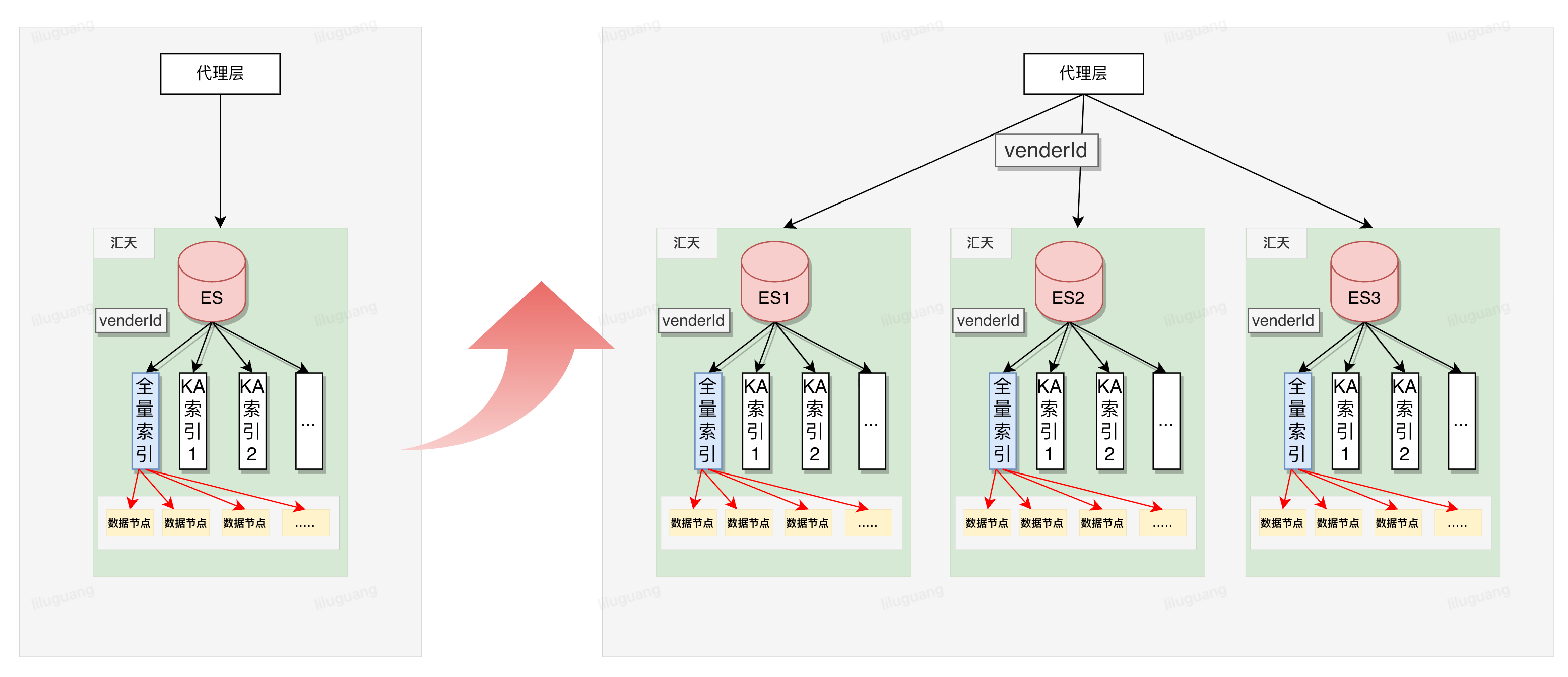
ES官方建议单分片数据控制在50-100G,同时ES集群节点(网关、主节点、数据节点)数量控制在100个以内(故障恢复时长考虑,可参考附录5)。基于这两个原则,单集群已无法满足存储诉求,当时也考虑了更换存储介质,考虑到端上丰富的查询诉求,团队内部研讨后决定继续采用ES。
我们决定将热集群中普通商家的ES集群由1个扩展至3个(基于当前业务发展及成本综合考量决定)。在数据代理层扩展集群路由逻辑,基于商家id哈希将商家数据分散到3个ES集群。
3.3 ES频繁更新的问题
当前系统采用了ES的乐观锁更新机制,在收到上游消息后,第一步获取ES版本号,第二部设置更新字段,第三部保存更新,保存更新版本冲突会发送一个重试MQ进行重试。
经过分析订单变为待出库前的消息比较集中,上游各系统基本都是同步消费订单管道消息完成业务操作后对外广播消息,这些消息同时到达我们系统,一方面存在并发冲突问题,第二方面是给ES带来了较大的更新压力。为了降低ES的更新压力,考虑增加一个挡板对消息进行汇总整型降低ES的更新次数,同时减少ES的更新冲突问题。

3.4 日常数据维护成本高的问题
受限于ES集群节点数量是有上限,大促前都需要对热集群订单数据进行归档操作,由热集群迁移至冷集群。系统初始是通过一个归档任务来进行迁移操作。首先圈定迁移数据的范围逐条读取--->逐条写入归档集群--->比对数据无误--->删除热集群数据。业务高峰期无法操作,新增、修改、删除对频繁删除会产生很多的段文件,ES定期对段文件进行merge操作(详情可参照附录部分内容),单次数据迁移大概耗时1个月左右时间,操作过程也较繁琐。我们的目标是全流程自动化的数据迁移无需人工介入,仅需要关注相关业务监控即可。考虑到资源及ROI问题,数据迁移改造共经历了两个阶段:
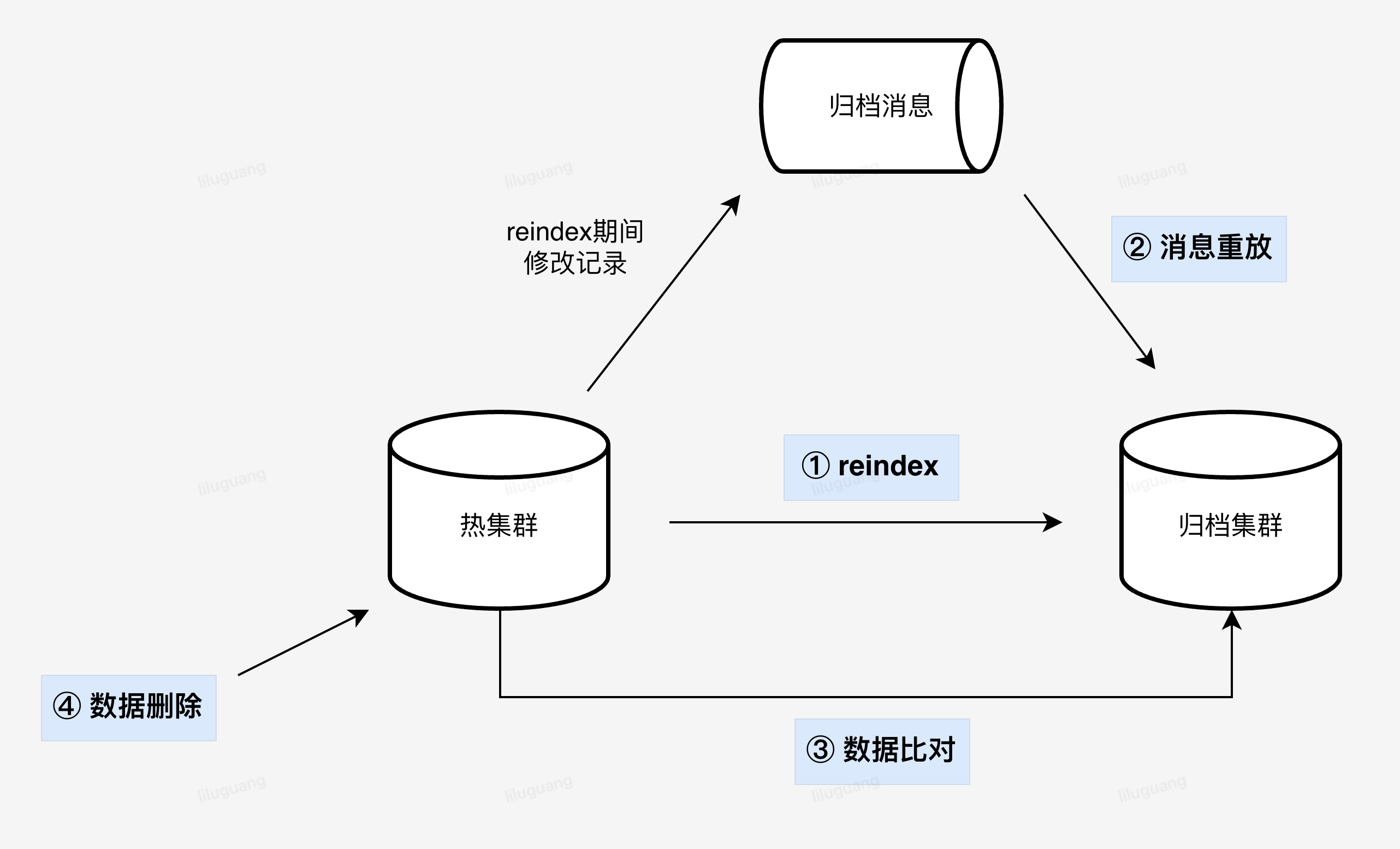
第一阶段通过通过reindex方式迁移数据,然后通过回放归档消息的方式追齐过程中的数据变更。该方案一定程度缩减了整体的时间及工作量,相较之前效率上大幅提升,时间大概由原来的20多天缩减至10天左右。
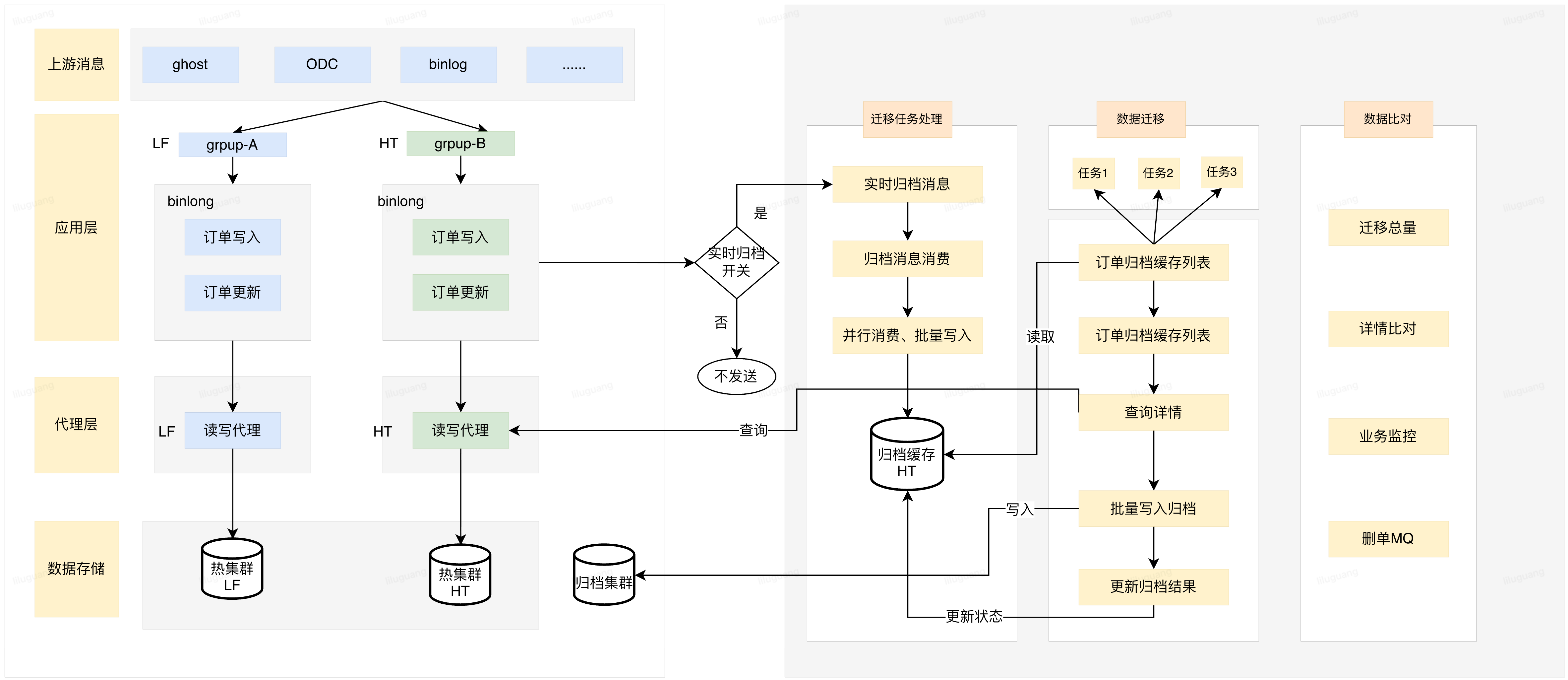
第二阶实现数据归档的全流程自动化操作。新建归档ES缓存,每天一个索引,把每天订单变更记录保存至索引中。通过一个定时任务批量读取、比对、写入同时删除原集群中数据。
3.4 终局方案
本次升级通过 “租户分级隔离 + 双层 Hash 路由 + 差异化分片策略 + 双活物理底座” 的组合拳,成功构建了一个 高性能、高扩展、高可用 的企业级订单检索与分析平台,完美支撑了业务量的爆发式增长。
四、附录:
4.1 超大集群维护的挑战
ES 是一个 P2P(对等)架构的分布式系统,虽然有 Master 节点,但所有节点都需要保存集群的状态。核心瓶颈:Cluster State(集群状态)的广播
ES 的 Master 节点负责维护 Cluster State(包含所有索引的 Mapping、Setting、分片路由表等元数据)。
每一次变更(如创建索引、Mapping 变更、节点上下线),Master 都要把更新后的 Cluster State 广播给集群内的所有节点;所有节点收到后,都需要向 Master 确认(Ack)。
当节点数超过 100 时会面临以下问题:
1)网络风暴: Master 发布一次状态更新,需要处理大量的网络包。如果更新频繁(例如大量创建索引),Master 的带宽和 CPU 会瞬间饱和。
2)收敛慢: 必须等待绝大多数节点确认,集群状态才能生效。节点越多,遇到“慢节点”拖累整体变更速度的概率就越大。
3)Full GC 风险: 大集群通常意味着分片数巨多。Cluster State 对象在内存中会变得非常大(几十 MB 甚至上百 MB)。Master 节点在处理这个巨型对象时,极易发生 Full GC 导致假死。
4.2 ES更新细节
要理解压力的来源,必须理解 ES(基于 Lucene)的 “不可变性” (Immutability) 原则。核心机制:伪更新 (Delete + Insert)
在 ES 内部,根本不存在物理意义上的“修改”操作。当你执行一个 Update 请求时,ES 实际上在做以下三步:
1.读取 (Read): 取出旧文档(如果是 Partial Update,它需要先通过 _source 字段获取完整文档)。
2.标记删除 (Soft Delete): 在旧的 Segment(段)文件中,将旧文档的 ID 标记为 .del(逻辑删除,类似墓碑)。
3.写入新文档 (Insert): 将修改后的新文档作为一个全新的 Document 写入到新的 Segment 中,并分配新的 _version 号。
这意味着,更新不仅仅是 IO 操作,它还涉及大量的 CPU 计算(重新分词、重新索引)。
4.3 频繁更新带来的四大压力:
1、磁盘 I/O 爆炸与 Segment Merge(段合并)风暴
•现象: 磁盘 I/O 持续 100%,写入拒绝(Rejection)。
•原因: 每次 Update 都会产生一个新的小 Segment。ES 后台为了优化查询,会不断触发 Segment Merge,将小段合并成大段,并物理剔除被标记为 .del 的数据。
•压力点: 高频更新会导致 Merge 线程极其繁忙,消耗大量的磁盘 IOPS 和 CPU。如果 Merge 速度跟不上产生碎片的速度,ES 会启动 Throttling(写入限流),导致你的写入请求被阻塞。
2、查询性能随着“墓碑”增加而衰退
•现象: 即使数据量看起来没变,查询延迟却越来越高。
•原因: 虽然旧文档被标记删除了,但在物理合并发生前,它们依然存在于索引中。
•搜索开销: 查询时,ES 必须扫描所有文档(包括旧的),然后在最后阶段通过 .del 文件过滤掉已删除的文档。如果你的索引中有 50% 是“墓碑”数据,查询效率就会大打折扣。
•BitSet 内存占用: 维护大量的删除标记需要消耗堆内存。
3、缓存失效 (Cache Invalidation)
•现象: Filter Cache(Node Query Cache)命中率极低。
•原因: ES 的 Filter Cache 是基于 Segment 的。一旦 Segment 因为 Merge 发生了变化,或者产生了新的 Segment,旧的缓存就会失效。高频更新导致 Segment 频繁变动,缓存根本热不起来,查询请求会直接击穿到底层磁盘。
4、GC (垃圾回收) 压力
•原因: Update 过程涉及将旧文档读入内存、反序列化、修改、再序列化。这会产生大量的临时对象,增加 JVM 的 Young GC 频率。如果 Merge 压力过大导致内存堆积,甚至可能触发 Old GC 或 Full GC,导致节点 "Stop-the-World"。






