



在电商推荐系统中,推荐模型长期面临着两个核心矛盾:一方面,传统的多阶段级联推荐系统存在目标不一致和误差累积的问题;另一方面,直接引入大型语言模型LLM虽然能带来强大的推理能力,但其高昂的延迟和计算成本在工业级应用中难以承受。更重要的是,现有的生成式推荐方法在多场景扩展性上面临巨大瓶颈--每个场景都需要独立训练和部署,导致资源利用率低下、维护成本高昂。
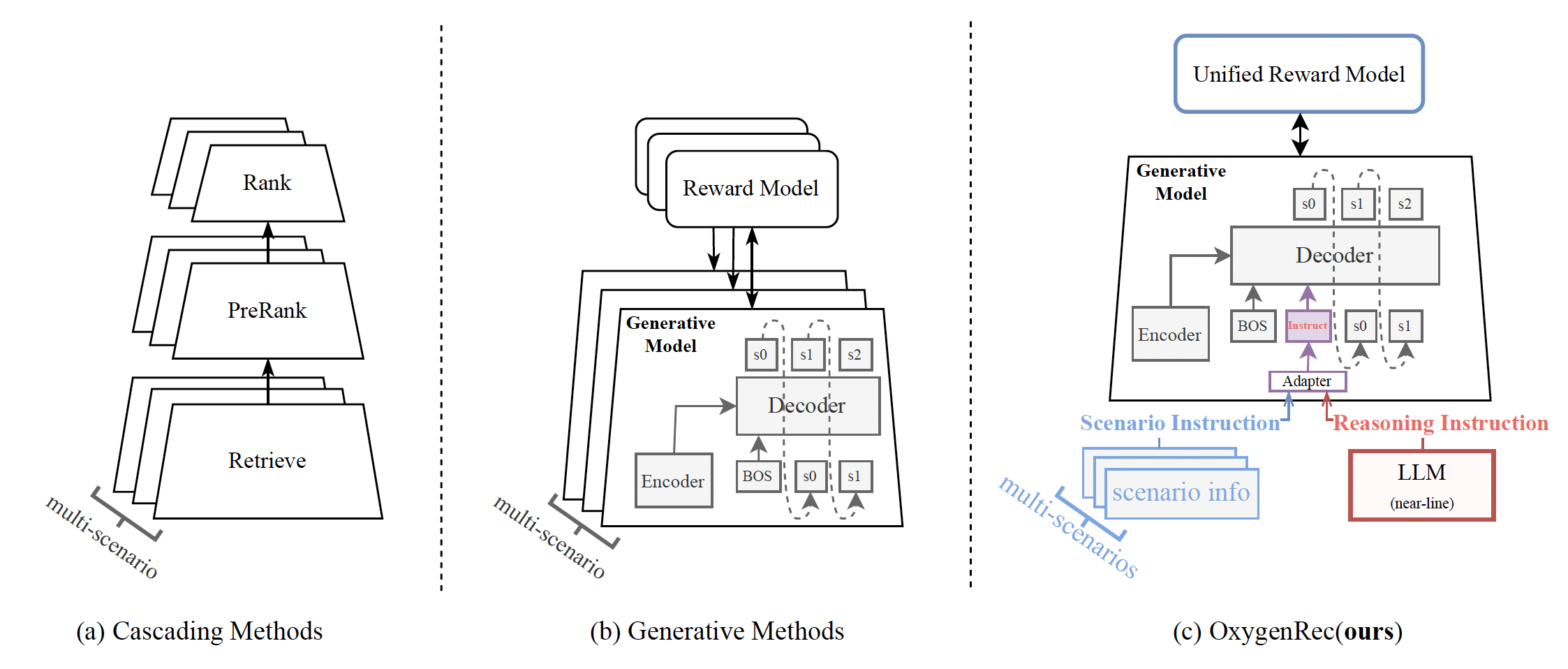
京东零售OxygenREC团队在论文《OxygenREC: An Instruction-Following Generative Framework for E-commerce Recommendation》中提出了一种全新的解决方案:OxygenREC。这是一个基于“快慢思考”的指令跟随生成式推荐框架,不仅解决了推理能力与延迟之间的矛盾,更实现了“一次训练,多处部署”的多场景统一高效解决方案。
一、 关键挑战
OxygenREC 旨在解决当前推荐系统,特别是生成式推荐范式下的三大核心难题:
- 有限的演绎推理能力:现有的生成式推荐方法主要从用户海量行为中进行归纳学习,但在需要结合现实世界知识进行深度演绎推理的场景下表现不佳。比如下边两个例子:
- 当推荐的时空背景和用户画像是“成都冬至时的年轻宝妈”时,传统模型可能只是推荐“冬季外套”这样的商品,而无法深度推理出此时成都是“冷湿环境”,这位年轻母亲潜在的需求可能是“婴儿排汗睡衣”。
- 有个户外运动vlogger在购物行为中反复对比华为Mate 70和iPhone 16 Pro两款手机,传统系统因为用户频繁的交互历史,只会不断加强重复推荐这两款商品进行比价,而无法推理出其真正诉求可能是“高质量的移动影像”,从而模型未能精准推荐‘华为Pura’系列这一真正符合用户诉求的目标商品。
- 多场景适应与资源效率的矛盾:大部分推荐平台拥有首页、频道流、购物车、搜索等多种推荐场景。现有生成式推荐模型如果为每个场景训练独立模型,会带来巨大的运营和计算成本,而使用简单的统一模型又会面临“负迁移”问题--不同场景间的知识相互干扰,导致性能下降。
- 工业级部署的工程挑战:将LLM的深度推理能力与推荐系统的大规模稀疏特征、严格延迟要求相结合,是一个巨大的系统工程挑战。它需要同时处理推荐系统典型的TB级稀疏嵌入和LLM典型的十亿级稠密参数,这对训练框架和推理引擎都提出了极高要求。
二、 核心贡献
面对这些挑战,京东零售OxygenREC团队提出了一个基于指令跟随的生成式推荐框架-OxygenREC,首次把LLM中的“快慢思考”模式引入到生成式推荐中来。在OxygenREC框架中,通过基于Transformer 的Encoder-Decoder 作为骨干网络,能够根据特定指令生成语义化物品序列,来执行推荐场景的”快思考"方式。在“慢思考”模式中,引入上下文推理指令--由近线LLM pipeline 生成,将用户行为与上下文合成为可解释的指令。同时多场景对齐中,通过场景指令与基于强化学习的对齐机制,实现“一次训练,多场景部署”。

1. “快慢思考”架构:知识注入与低延迟的平衡
这是整个OxygenREC的基础,其核心思想是将复杂的推理过程“离线化”,保证在线服务的低延迟。
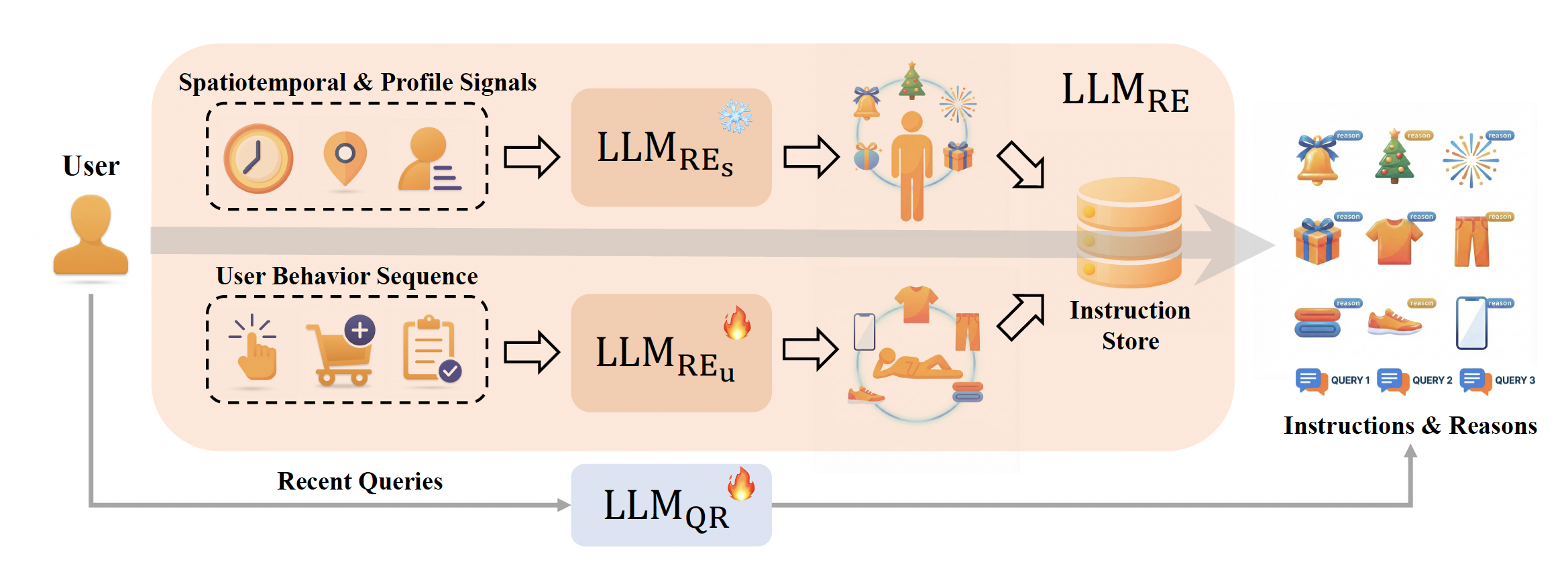
- 慢思考:一个近线的LLM pipeline,综合分析用户的时空上下文、个性化特征和历史行为,生成高质量的“上下文推理指令”。这个过程融合了世界知识,能进行深度演绎推理,但因其是近线批量处理,不增加在线请求的延迟。
- 快思考:一个高效的编码器-解码器骨干网络。它接收“慢思考”生成的指令,结合实时用户信号,在严格的延迟限制下生成推荐序列。该骨干网络本身轻量、高效,专为实时推理优化。
2. 语义对齐的指令控制机制:让指令真正发挥作用
仅仅生成指令是不够的,还必须确保模型能够准确理解并遵循指令。OxygenREC通过两项关键技术实现精准指令控制:
- 查询到物品的对齐损失:在训练阶段,通过一个辅助的Query-to-Item (Q2I) 损失函数,将指令嵌入与目标物品嵌入在同一个语义空间中对齐。这使得指令能够“理解”物品,并用于检索:
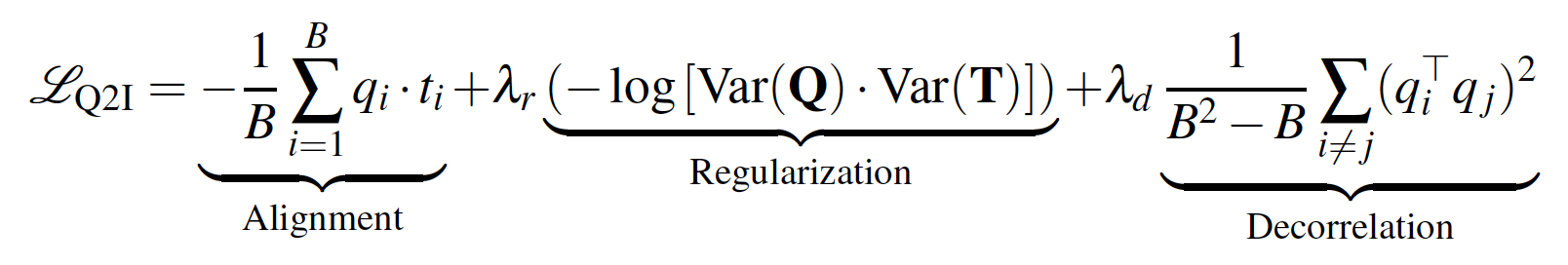
- 指令引导检索(IGR):在生成推荐时,利用对齐后的指令作为查询,从用户长期历史行为中检索出最相关的部分,过滤掉无关的噪声。这确保了模型生成时专注在与当前指令意图最相关的历史信息上,大大提升了可控性和准确性。
3. 基于指令与强化学习的多场景统一对齐:Train-Once-Deploy-Everywhere
这是解决多场景扩展性的关键。OxygenREC摒弃了为每个场景独立建模的思路。
- 场景指令化:将不同的场景信息(如首页、购物车)和可选的触发物品(如用户点击的入口商品)统一编码为“场景指令”,作为模型的条件输入。
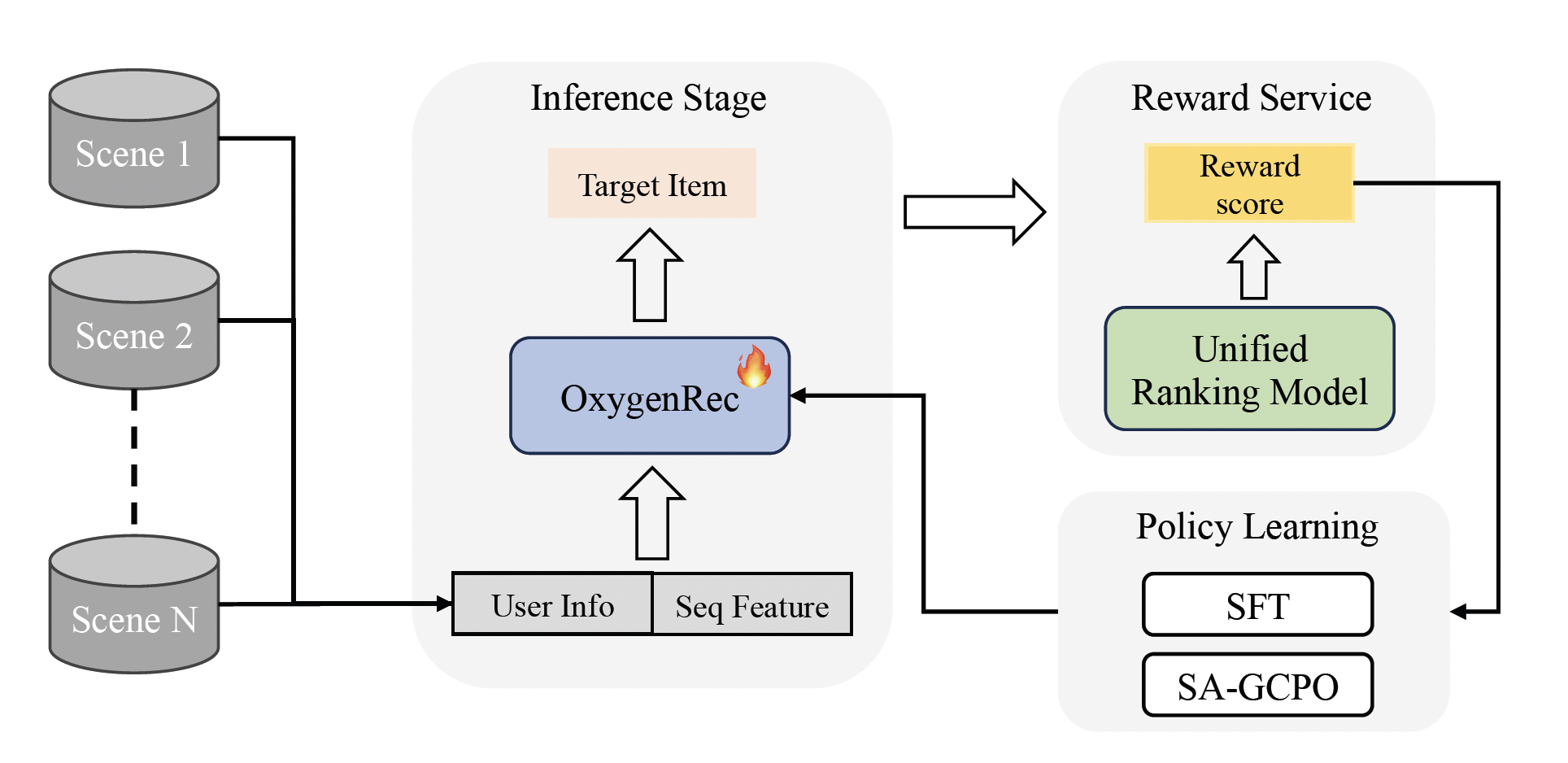
- 统一奖励映射与策略优化:设计了一个统一的奖励映射服务,将不同场景、不同业务目标(如GMV,转化率,合法性,多样性)的奖励信号归一化。在此基础上,提出了Soft Adaptive Group Clip Policy Optimization (SA-GCPO) 算法进行强化学习训练:
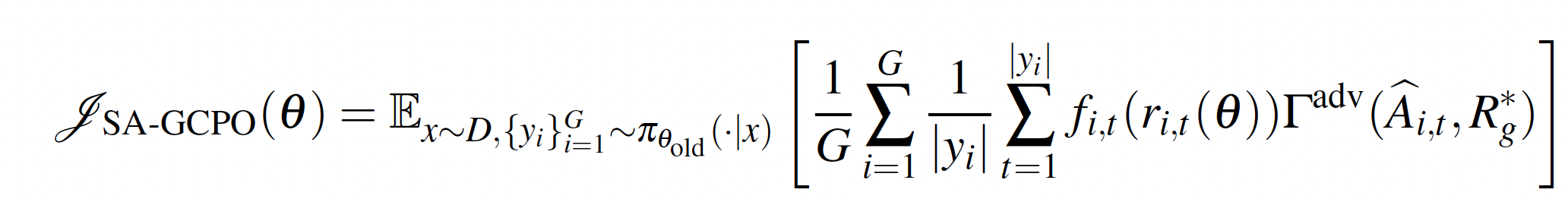
- 该算法用自适应门控函数替代传统基于GRPO的硬截断方式(hard clip):
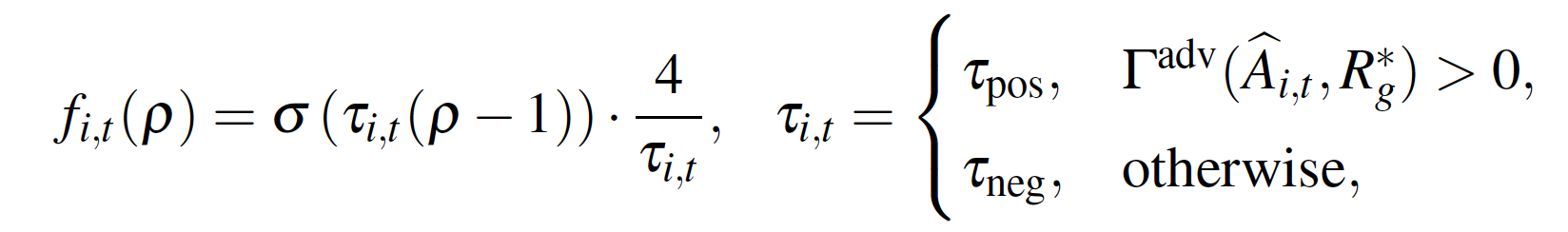
- 并以基于用户真实反馈的奖励分数作为阈值区分正负advantage样本,显著提升了多任务、多场景下策略学习的稳定性和效率:
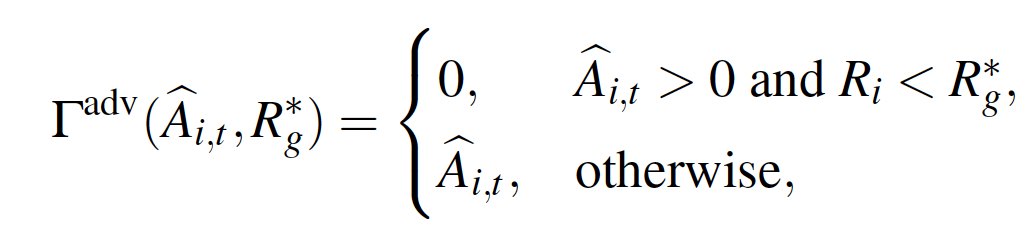
4. 大规模生产级系统实现
为了支撑以上创新,团队构建了完整的工程体系:
- 统一训练框架:基于PyTorch,深度融合了工业级稀疏嵌入引擎和LLM稠密训练引擎,在128张H800 GPU集群上实现了40%的模型FLOPs利用率。
- 高性能推理引擎xLLM:针对生成式推荐长上下文、大候选集的特点,定制开发了xLLM推理框架,通过xSchedule(系统调度)、xAttention(算子优化)、xBeam(束搜索优化)三级优化,满足线上严格的服务级别目标。
- 近线指令服务:推理指令通过近线服务批量生成并存入KV数据库,线上推荐模型直接读取,实现了零在线LLM调用,兼顾了语义丰富性和低延迟。
三、 实验成果
OxygenREC在京东几个核心场景的大量离线实验和在线A/B测试中取得了显著效果,证明OxygenREC 基于生成式推荐的方法在大规模工业级推荐系统中的有效性。
1. 基于快慢思考的生成式框架有效性验证
- 语义ID:通过多源对比学习(文本、图像、行为关联)构建的层次化语义ID,在保持高类别纯度(92.8%)的同时,实现了极低的ID碰撞,证明了其强大的表达和区分能力。
- 指令跟随:消融实验证明,在BOS右侧插入指令的方式为最佳;融合了场景ID和触发物品ID的指令效果显著优于单一组件;IGR和Q2I对齐机制共同作用带来了显著的性能提升。
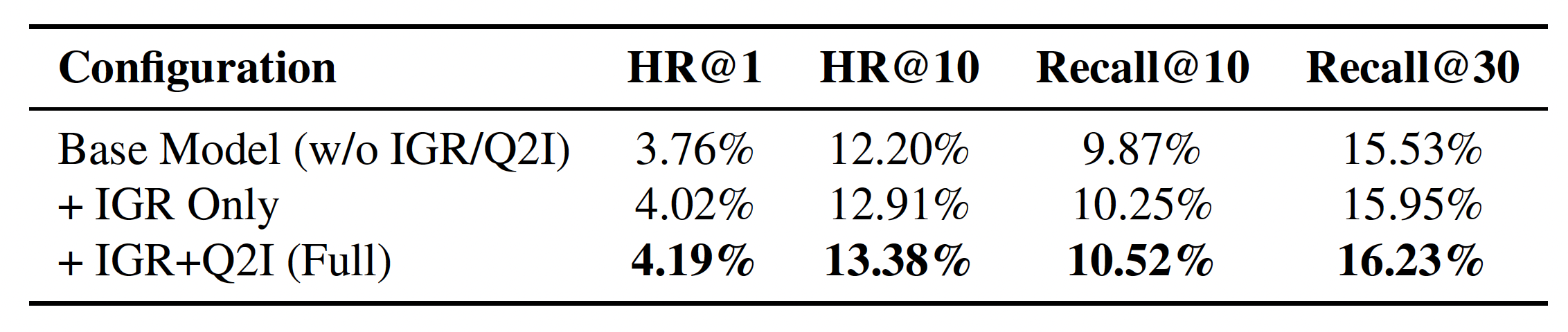
- 统一模型 vs. 独立模型:在六个核心场景的对比中,统一的OxygenREC模型全面超越了为每个场景独立微调的基线模型,验证了OxygenREC框架在场景间正向迁移的有效性。
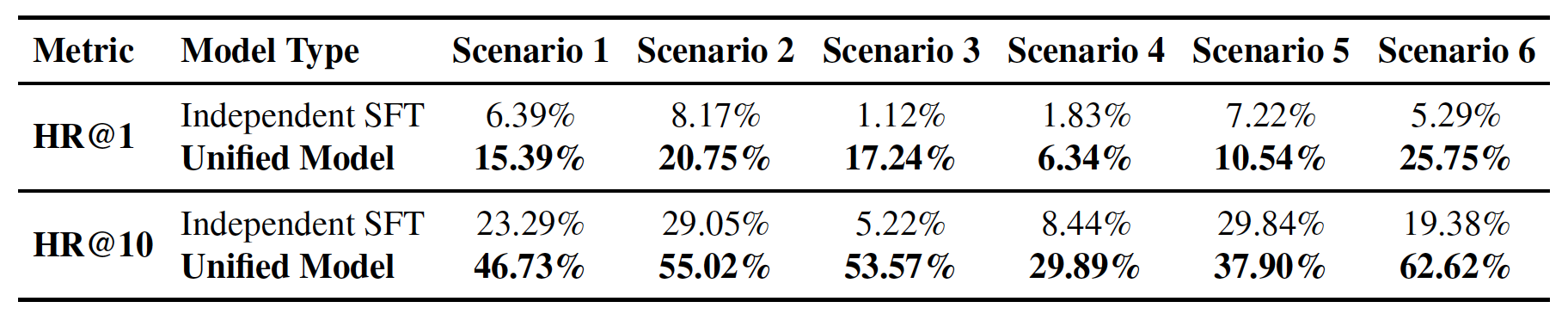
2. 基于SA-GCPO后训练的有效性验证
在后续训练阶段,提出的SA-GCPO算法在合成数据比例变化时表现更稳定,且性能显著优于传统的GRPO及其变体GSPO。例如,在33%合成数据比例下,SA-GCPO在HR@1和HR@10上有显著提升。

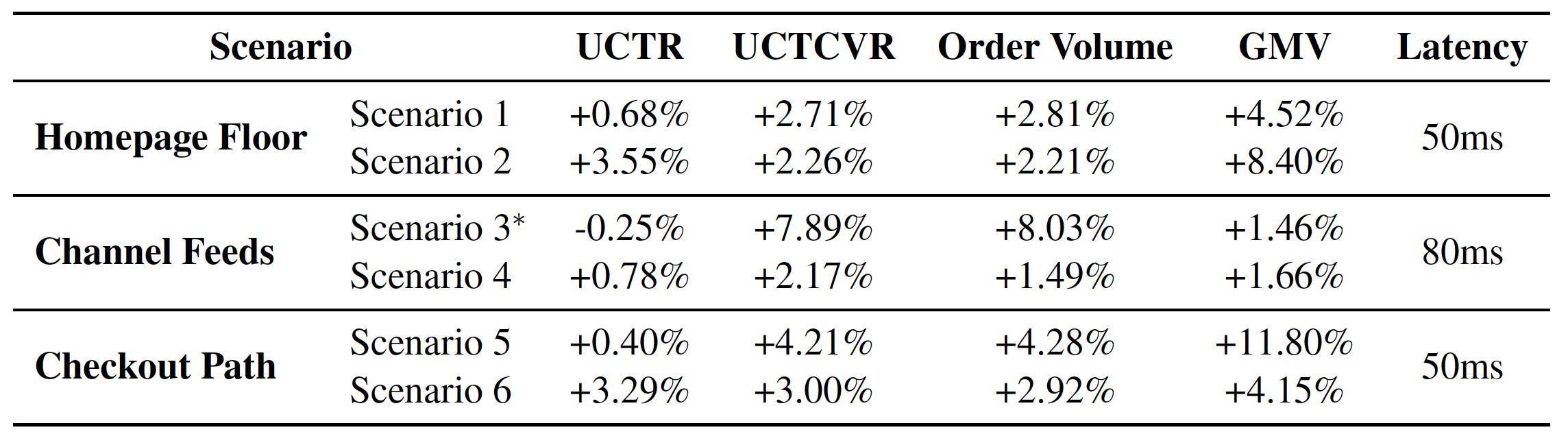
3. 电商场景在线A/B测试的商业效果
OxygenREC已在京东App上形成覆盖用户购物全链路的部署闭环:首页导流(场景1、2)-> 频道浏览(场景3、4)-> 商品结算转化(场景5、6)。在线测试结果表明,该模型在所有关键业务指标上均带来显著提升:
- 首页场景:GMV提升4.52%-8.40%。
- 频道流场景:其中一个场景的订单量提升了8.03%,显示出模型精准匹配购买意图的能力。
- 结算路径场景:在用户强购买意图下,GMV提升高达11.80%。
与行业上其他生成式推荐方式对比:
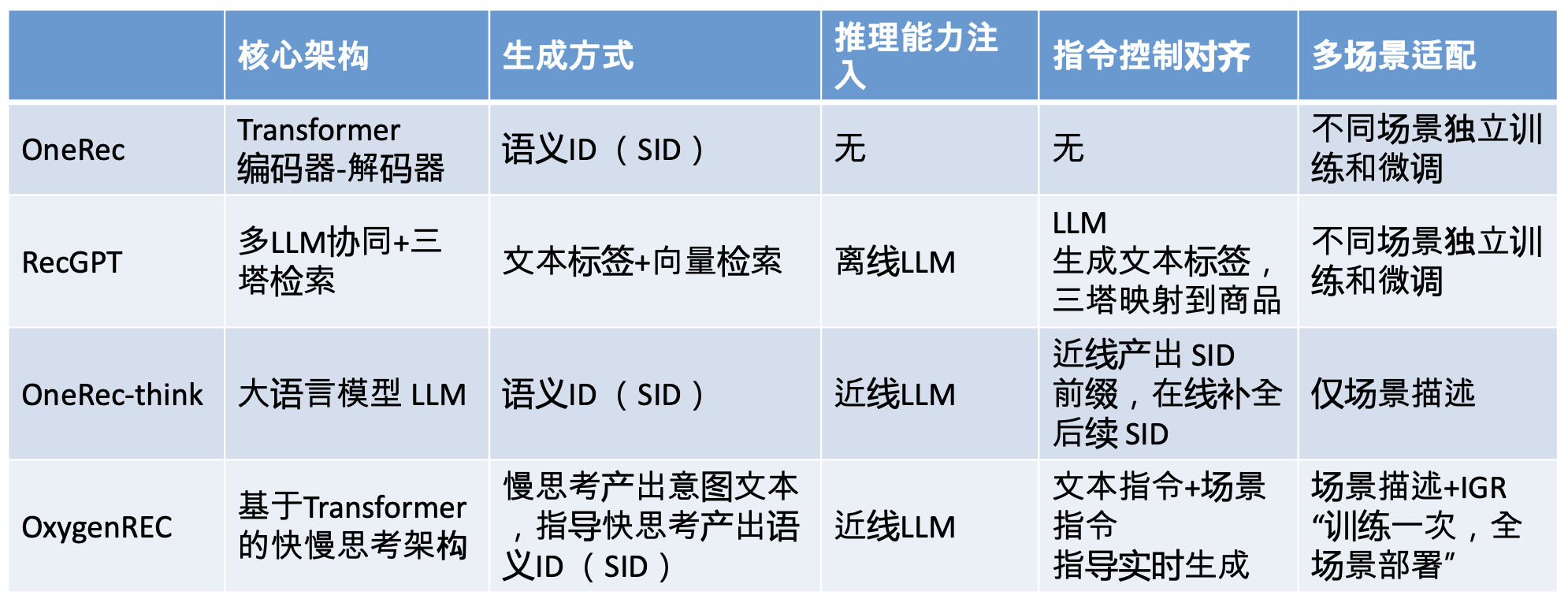
OxygenREC 在几个关键维度上进行了生成式推荐的范式革新:
- 架构上,用“快慢思考”破解了推理与延迟的死结。
- 效率上,用“统一指令模型”破解了多场景训练的困局。
- 控制上,用“语义对齐与引导检索”构建了生成式推荐模型的指令跟随能力。
- 优化上,用“SA-GCPO”和全栈系统优化,确保了技术在工业巨量流量下的可行性、稳定性和卓越性能。
总结与展望
OxygenREC的成功,标志着生成式推荐在工业落地上迈出了关键一步。它通过“快慢思考”巧妙平衡了深度推理与低延迟,通过“指令跟随”实现了对推荐过程的精准可控,并通过统一的奖励与策略学习破解了多场景扩展的难题,真正实现了“一次训练,多场景部署”的pipeline。
未来,京东零售OxygenREC团队计划从两个方向继续探索:
- 一是向基于语言扩散模型的非自回归生成范式演进,从根本上突破序列生成延迟与列表长度的线性关系,满足更高吞吐需求;
- 二是开展跨场景用户轨迹建模,从用户在首页、搜索、购物车、结算等多场景的连贯行为中挖掘更深层的用户意图,实现更长周期的价值推荐。
OxygenREC不仅是一个高效的推荐系统,更为工业级生成式AI应用的大模型设计提供了宝贵范式--如何将大模型的“脑”与小模型的“身手”结合,如何在复杂多目标任务中实现稳定高效的学习,这其中的思想值得广泛借鉴。
论文原文:OxygenREC: An Instruction-Following Generative Framework for E-commerce Recommendation
训练框架: Oxygen 9N-LLM生成式推荐训练






