您好!
欢迎来到京东云开发者社区
登录
首页
博文
课程
大赛
工具
用户中心
开源
首页
博文
课程
大赛
工具
开源
更多
用户中心
开发者社区
>
博文
>
图解AI核心技术:大模型、RAG、智能体、MCP
分享
打开微信扫码分享
点击前往QQ分享
点击前往微博分享
点击复制链接
图解AI核心技术:大模型、RAG、智能体、MCP
jd****
2025-10-09
IP归属:北京
905浏览
## 简介 本文整理了来自Daily Dose of Data Science最热门或最新的文章,其中极具特色的动图以生动形象的方式,帮助我们更好的理解AI中的一些核心技术,希望能够帮助大家更好的理解和使用AI。 ## 大模型 ### Transformer vs. Mixture of Experts 混合专家 (MoE) 是一种流行的架构,它使用不同的“专家”来改进 Transformer 模型。 下图解释了它们与 Transformers 的区别。 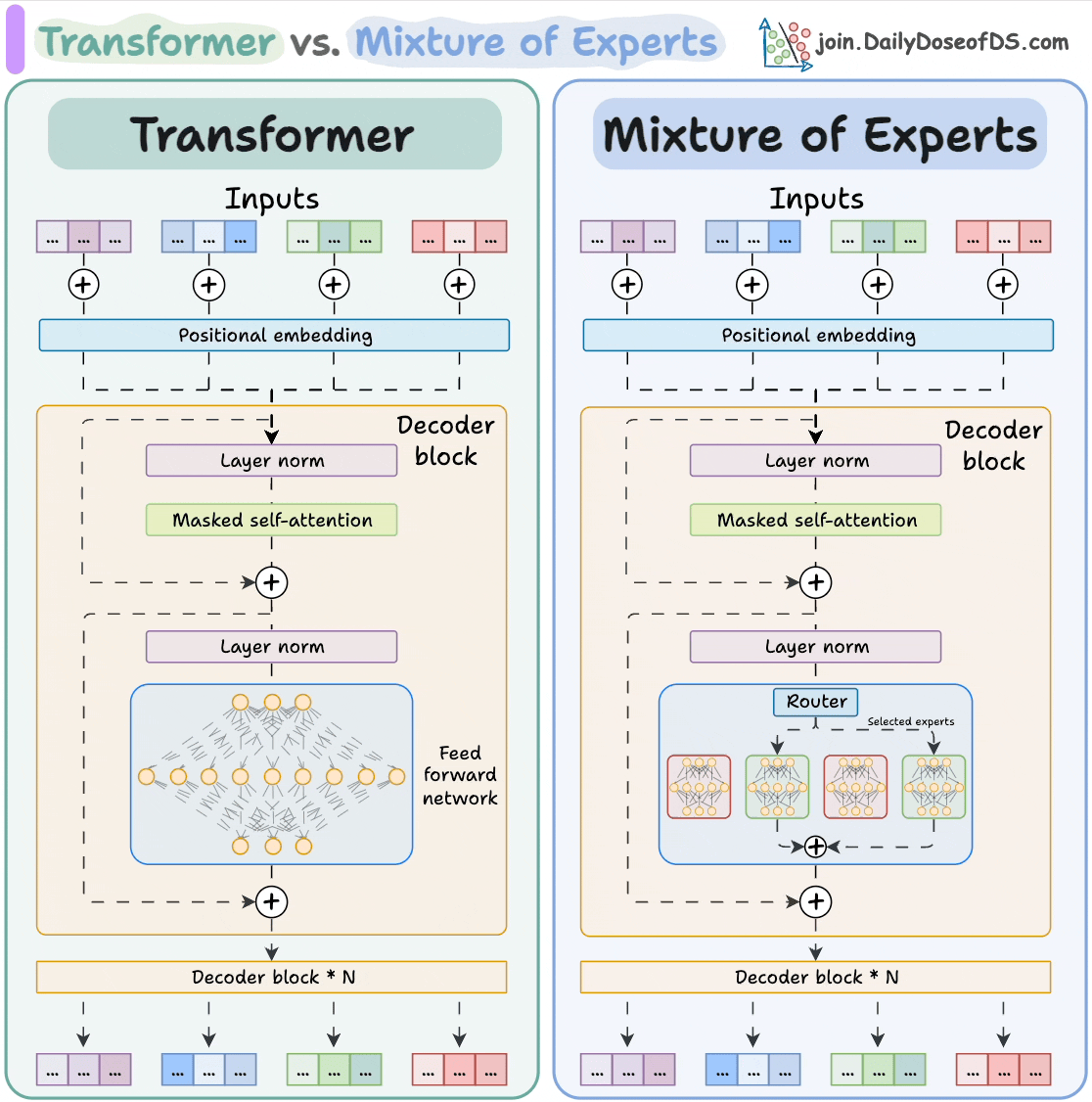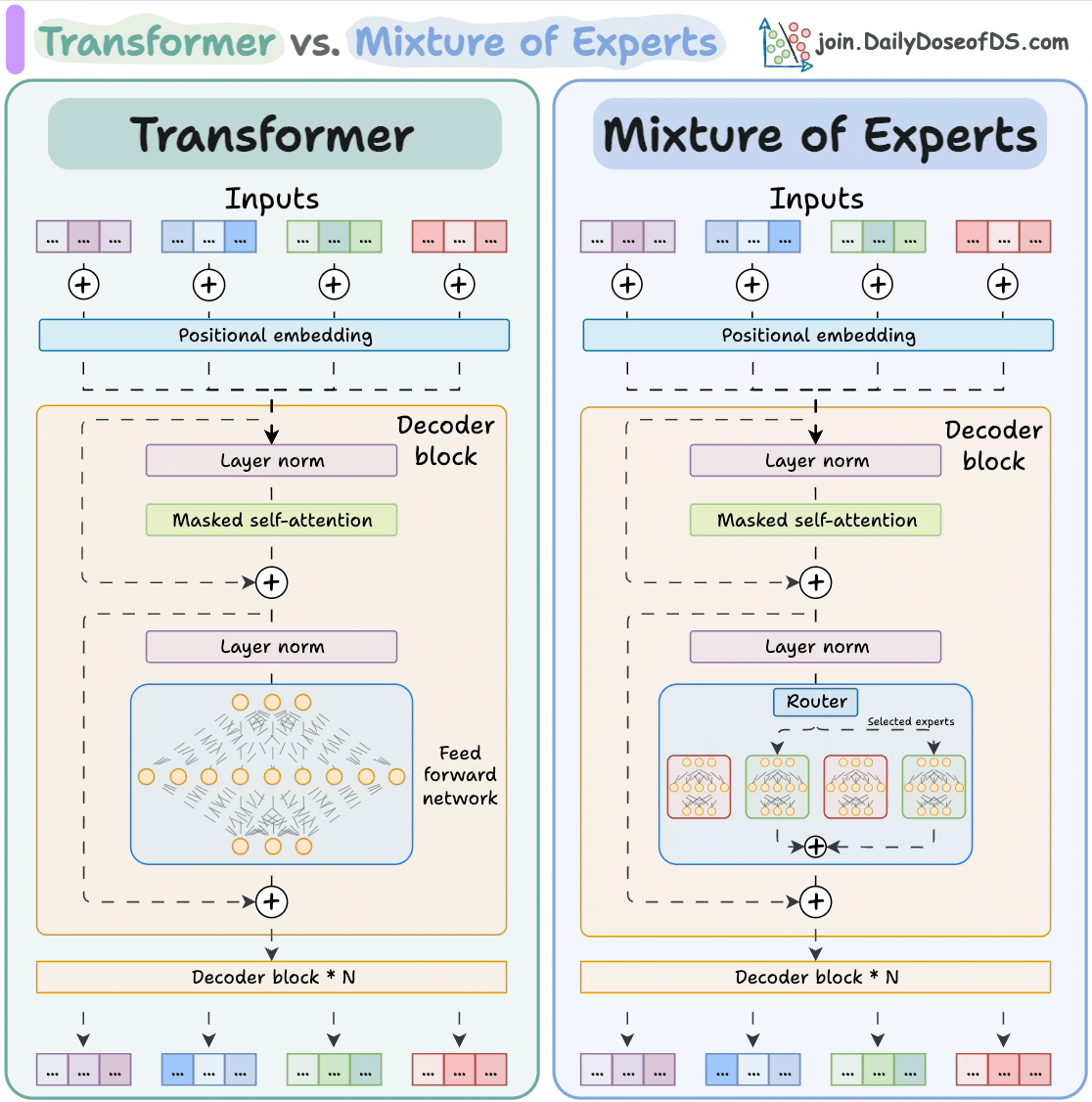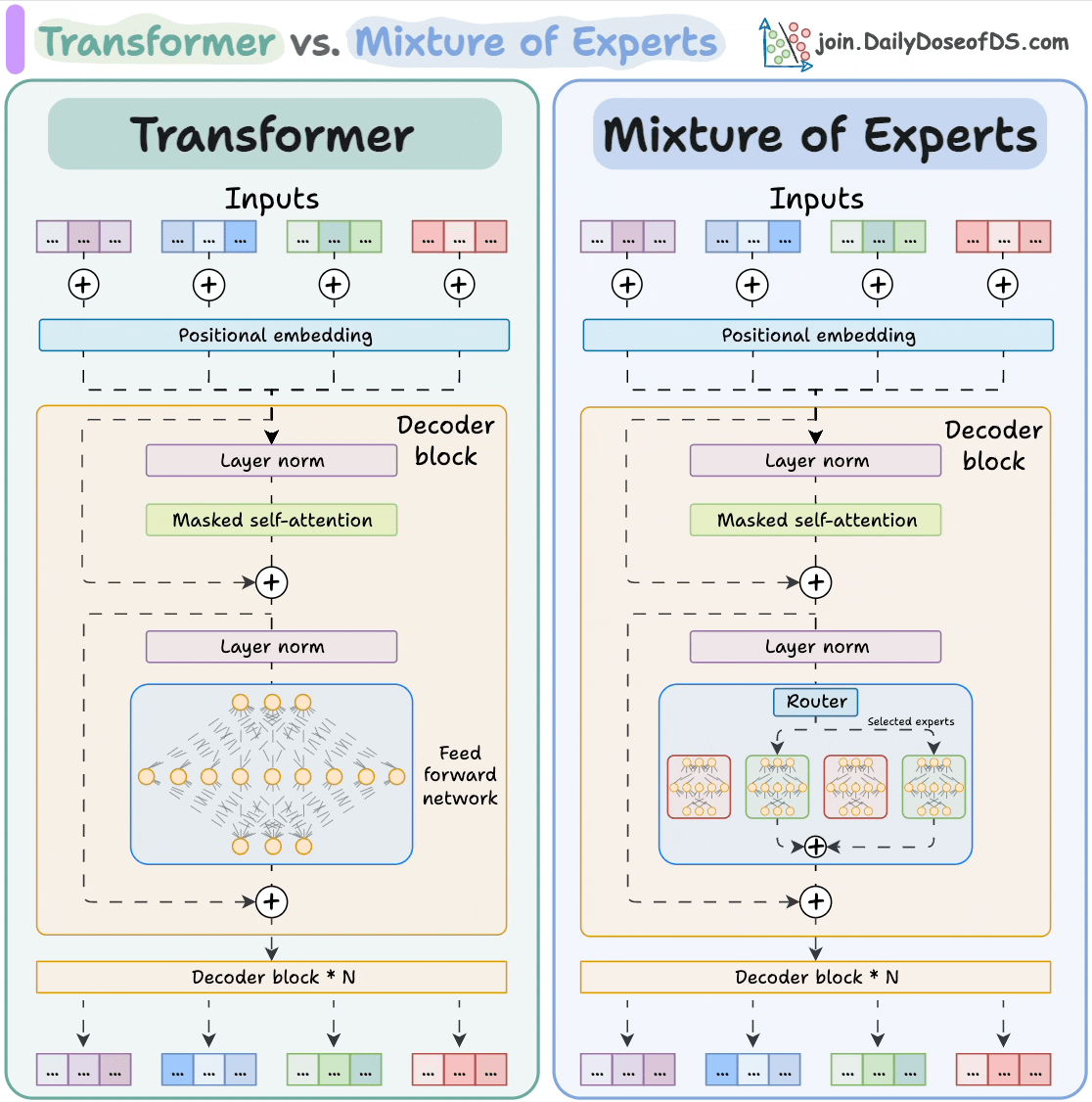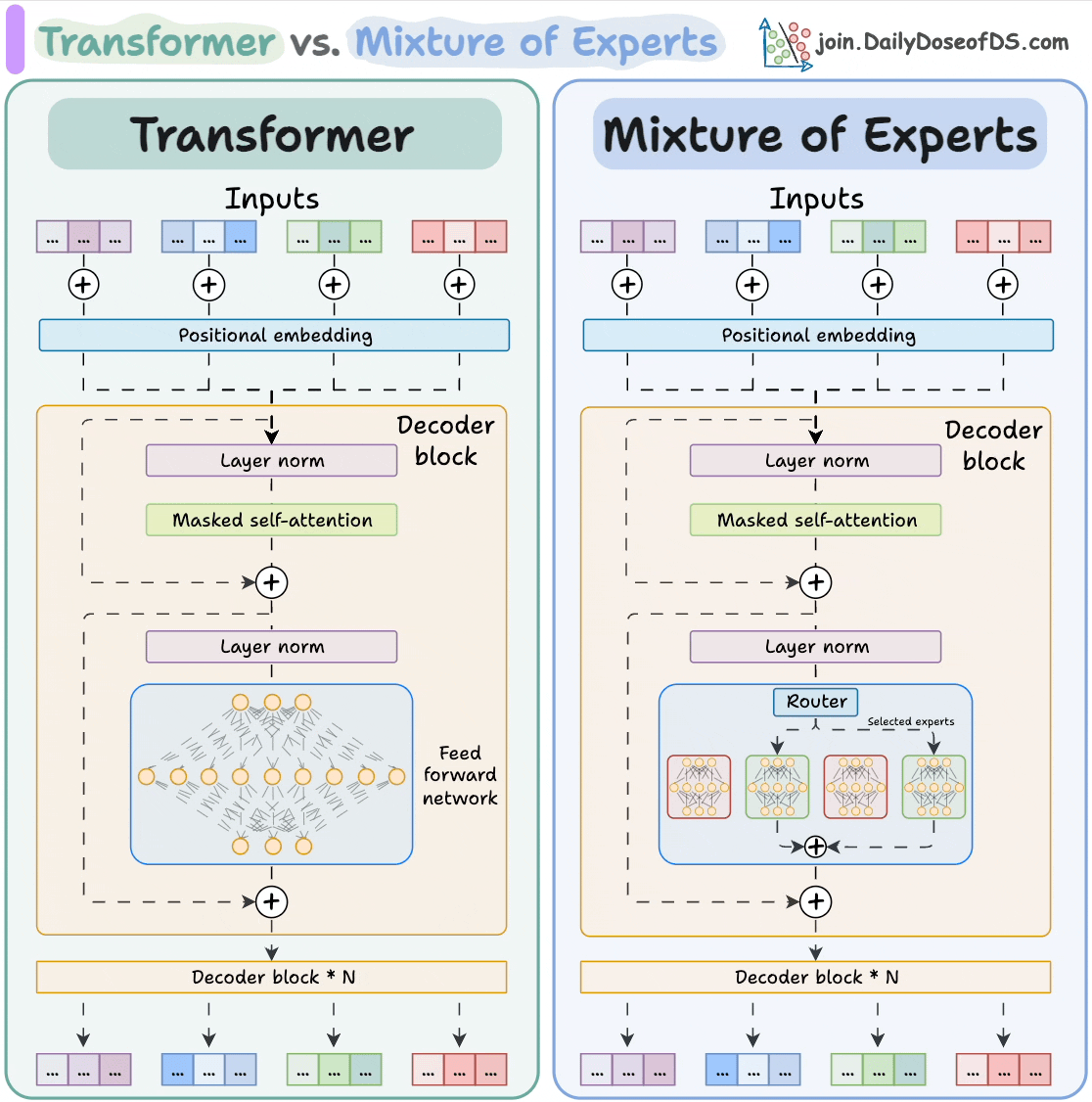 * Transformer 使用前馈网络。 * MoE 使用专家,它们是前馈网络,但与 Transformer 中的网络相比规模较小。在推理过程中,会选择一部分专家。这使得 MoE 中的推理速度更快。 ### Fine-tuning LLMs 传统的微调(如下图所示)对于 LLM 来说是不可行的,因为这些模型具有数十亿个参数并且大小为数百 GB,并且并非每个人都可以使用这样的计算基础设施。 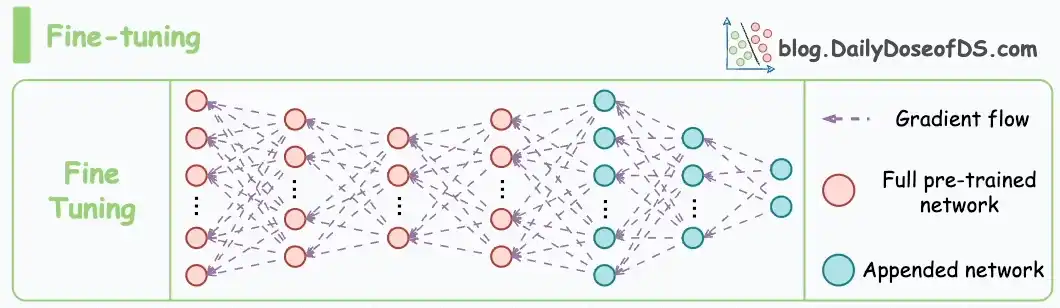 值得庆幸的是,今天我们有许多最佳方法来微调 LLM,下面描述了五种流行的技术: 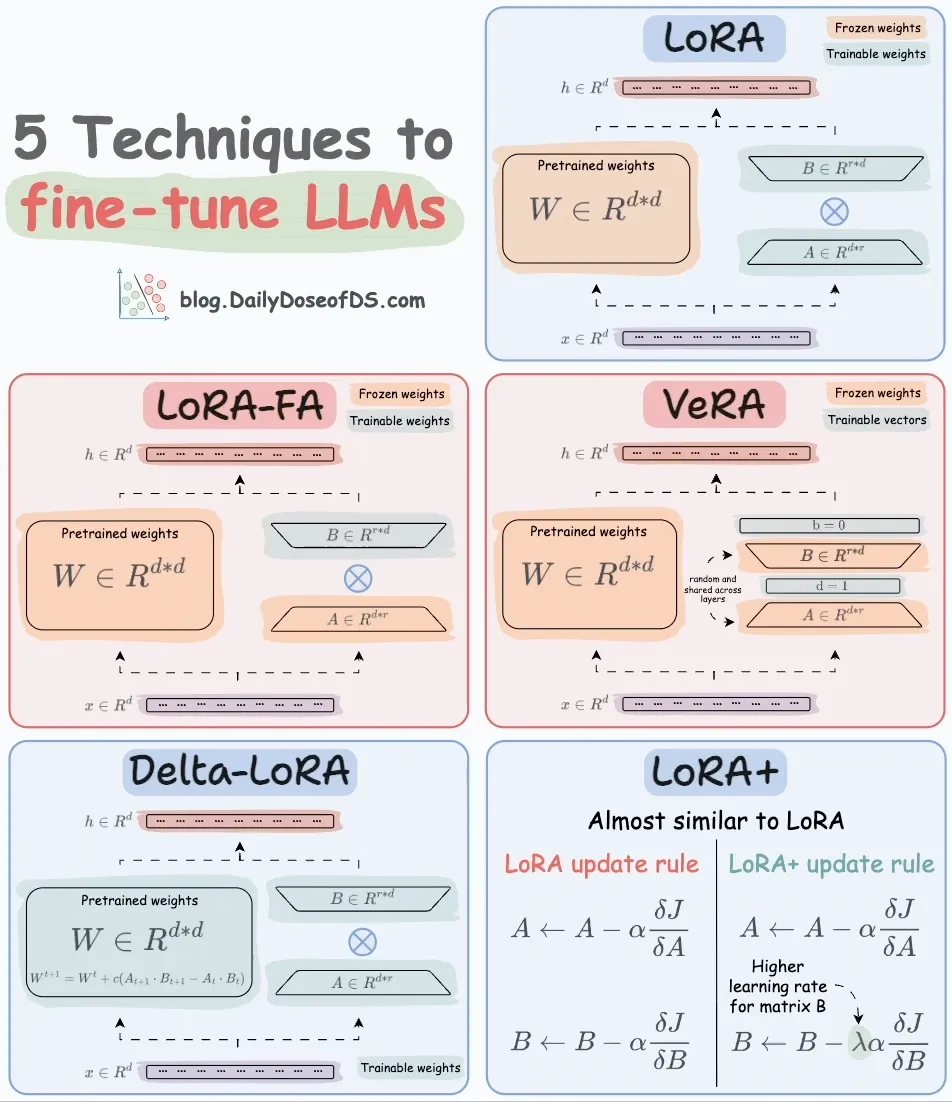 * LoRA :添加两个低秩矩阵 A ,以及 B包含可训练参数的权重矩阵。无需进行微调W,只需调整这些低秩矩阵中的更新即可。 * LoRA-FA :虽然 LoRA 显著减少了可训练参数的总量,但它仍然需要大量的激活记忆来更新低秩权重。LoRA-FA(FA 代表 Frozen-A)会冻结矩阵,A并且仅更新矩阵B。 * VeRA :在 LoRA 中,每一层都有一对不同的低秩矩阵A和B,并且这两个矩阵都经过训练。然而,在 VeRA 中,矩阵A和B是冻结的、随机的,并在所有模型层之间共享。VeRA 专注于学习较小的、特定于层的缩放向量,记为b和d,它们是此设置中唯一可训练的参数。 * Delta-LoRA :除了训练低秩矩阵之外,W还会对矩阵进行调整,但不是以传统方式。相反,将两个连续训练步骤中低秩矩阵乘积与之间的差值(或增量)A添加B到W。 * LoRA+ :在 LoRA 中,矩阵A和B都以相同的学习率更新。作者发现,为矩阵设置更高的学习率B可以获得更优的收敛效果。 ## RAG(检索增强生成) ### 传统RAG 传统RAG系统存在以下一些问题: 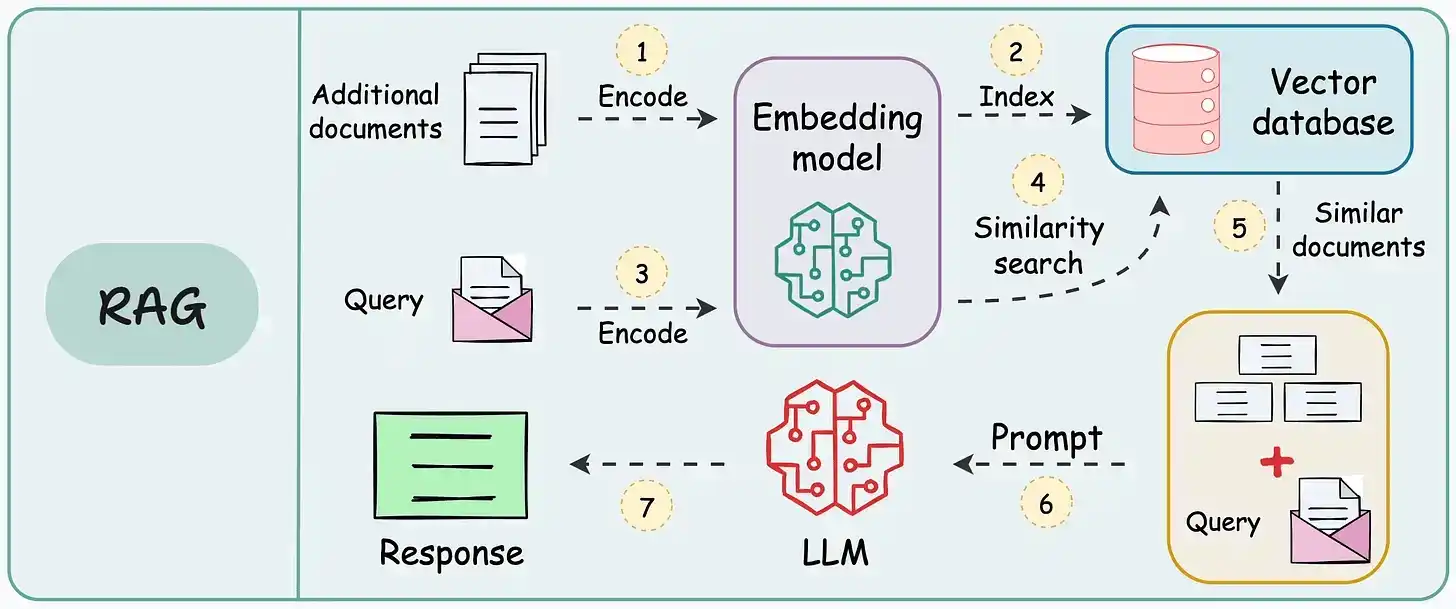 * 这些系统检索一次,生成一次。这意味着如果检索到的上下文不够,LLM就无法动态搜索更多信息。 * RAG 系统可以提供相关的上下文,但无法通过复杂的查询进行推理。如果查询需要多个检索步骤,传统的 RAG 就显得力不从心了。 * 适应性较差。LLM 无法根据实际问题调整策略。 ### Agentic RAG Agentic RAG 的工作流程如下: 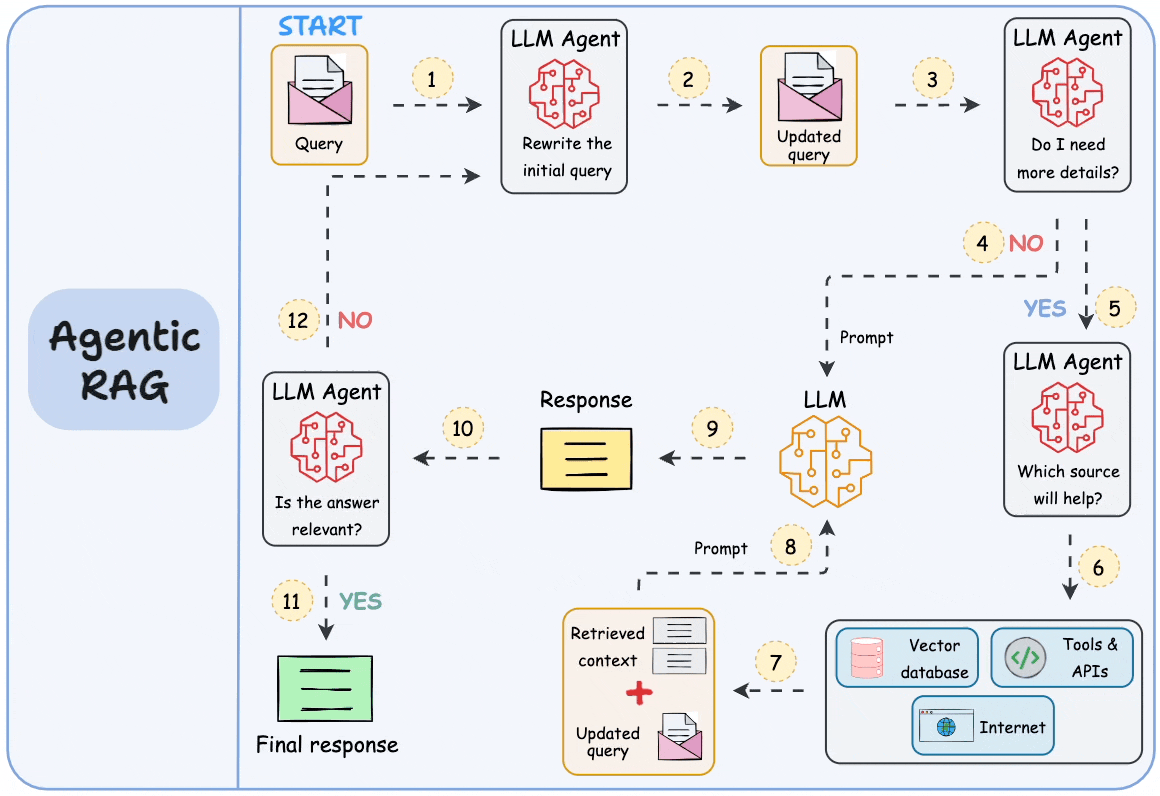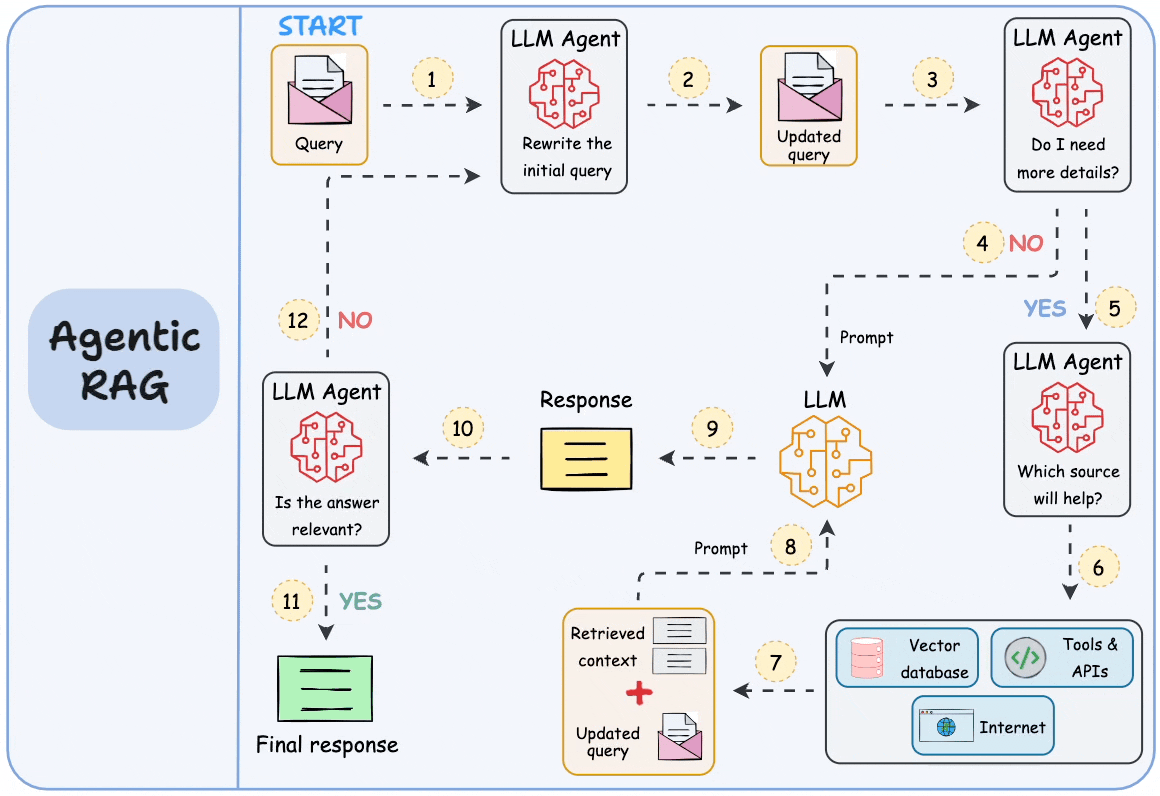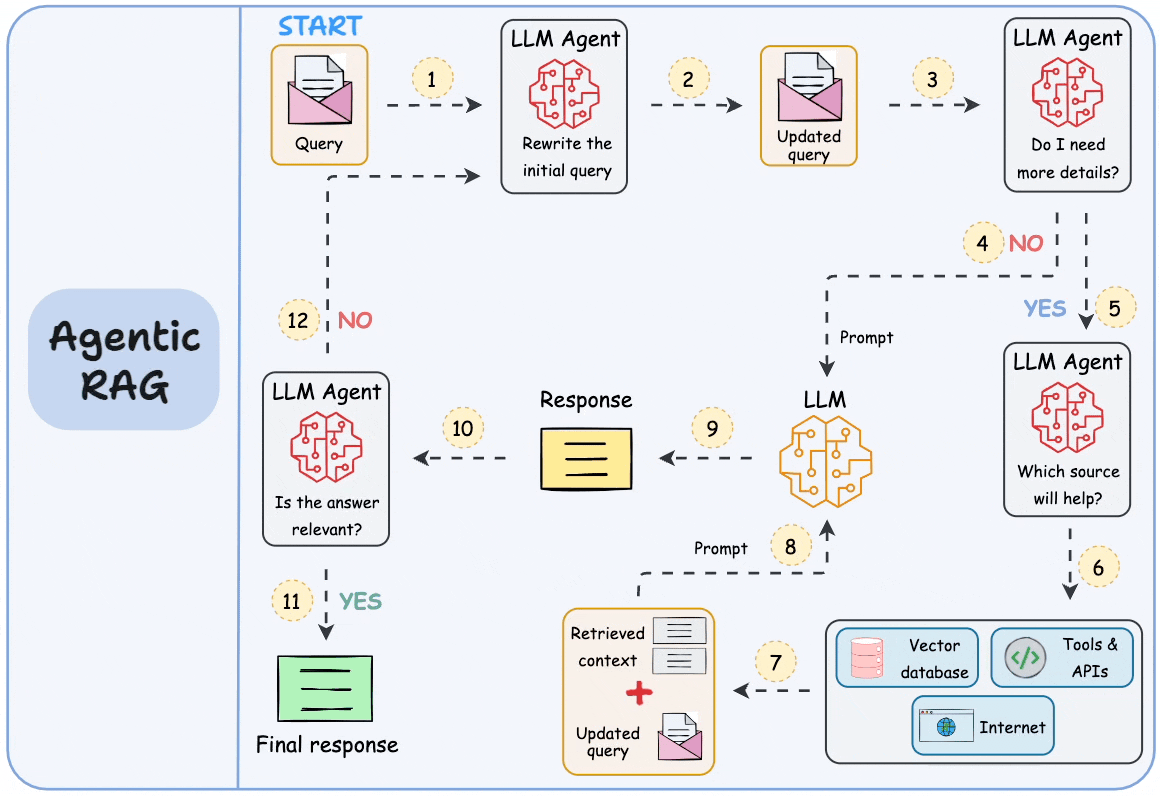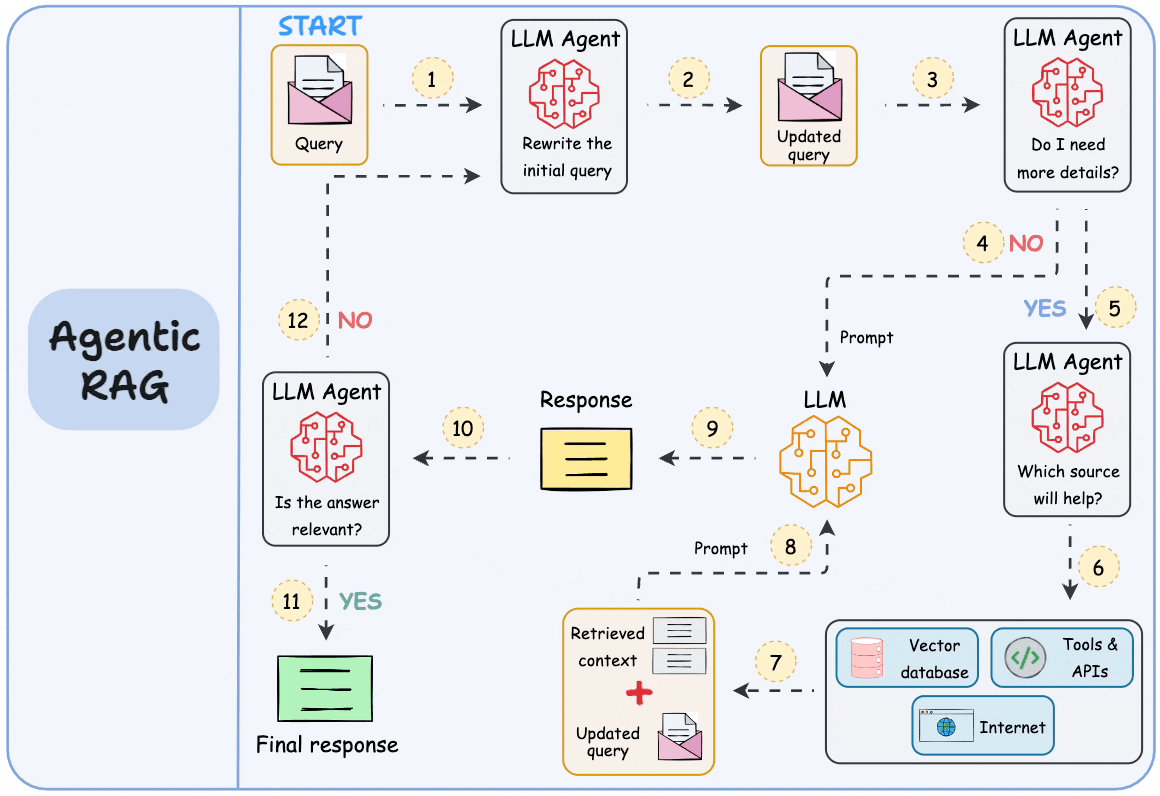 如上所示,我们的想法是在 RAG 的每个阶段引入代理行为。 > 我们可以把智能体想象成能够主动思考任务的人——规划、调整、迭代,直到找到最佳解决方案,而不仅仅是遵循既定的指令。LLM 的强大功能使这一切成为可能。 > 让我们逐步理解这一点: * 步骤 1-2)用户输入查询,代理重写它(删除拼写错误,简化嵌入等) * 步骤 3)另一个代理决定是否需要更多细节来回答查询。 * 步骤4)如果不是,则将重写的查询作为提示发送给LLM。 * 步骤 5-8) 如果答案是肯定的,另一个代理会查看其可以访问的相关资源(矢量数据库、工具和 API 以及互联网),并决定哪个资源有用。检索相关上下文并将其作为提示发送给 LLM。 * 步骤9)以上两条路径中的任意一条都会产生响应。 * 步骤 10)最后一个代理检查答案是否与查询和上下文相关。 * 步骤11)如果是,则返回响应。 * 步骤 12)如果不是,则返回步骤 1。此过程持续几次迭代,直到系统承认它无法回答查询。 这使得 RAG 更加稳健,因为在每一步中,代理行为都能确保个体结果与最终目标保持一致。 ### Corrective RAG Corrective RAG(CRAG)是改进 RAG 系统的常用技术。它引入了对检索到的文档进行自我评估的步骤,有助于保留生成的响应的相关性。 以下是其工作原理的概述: 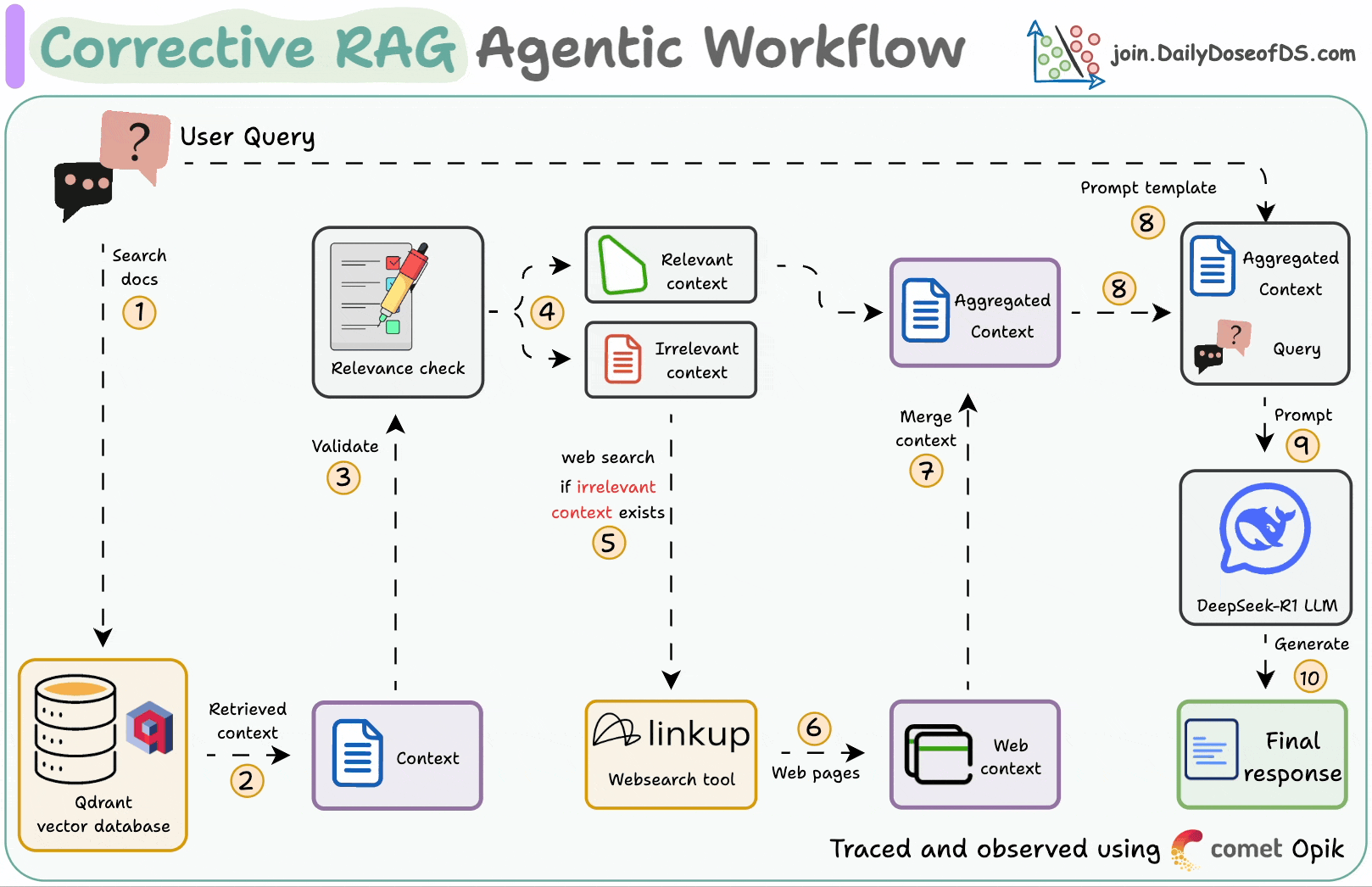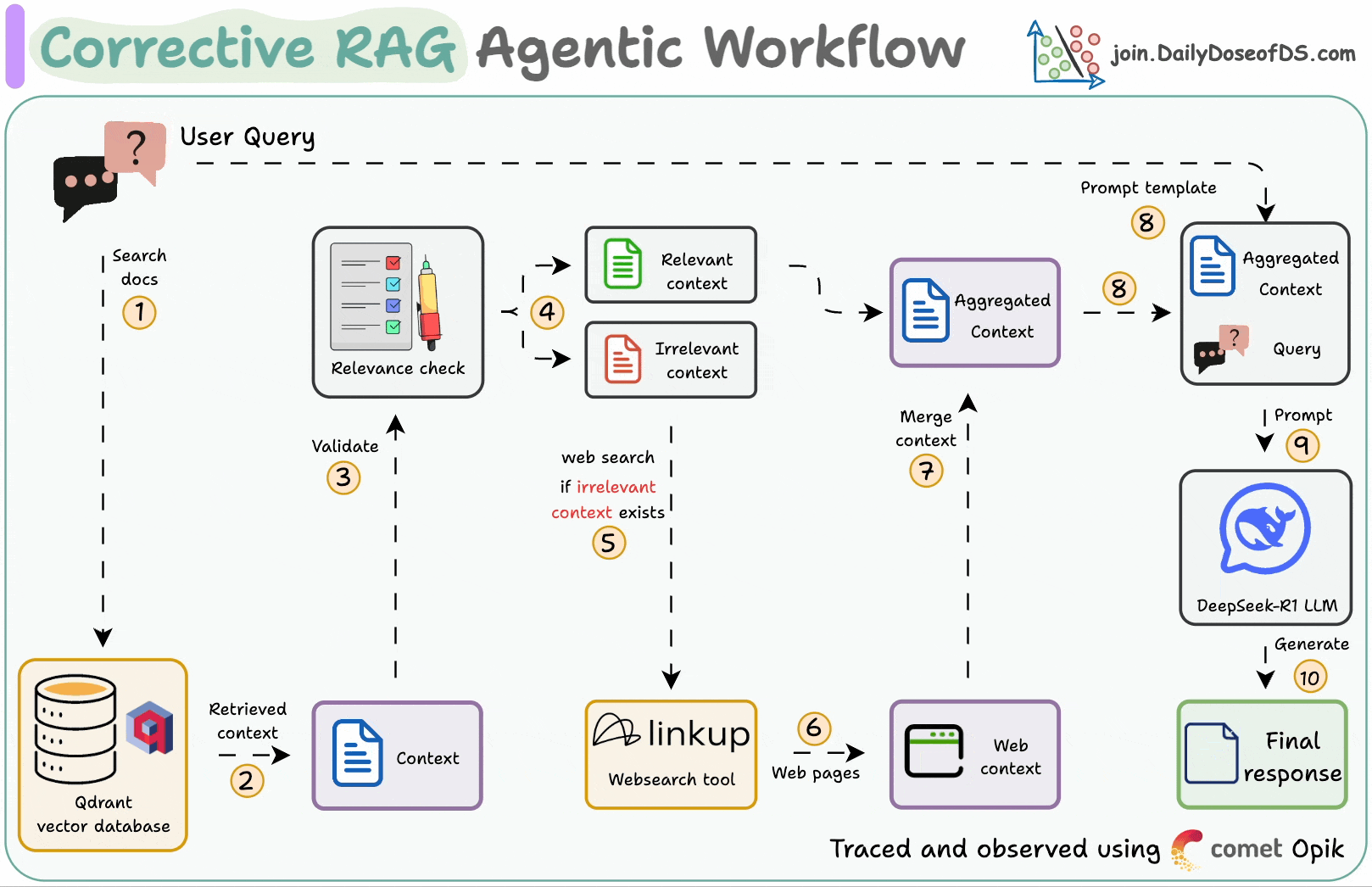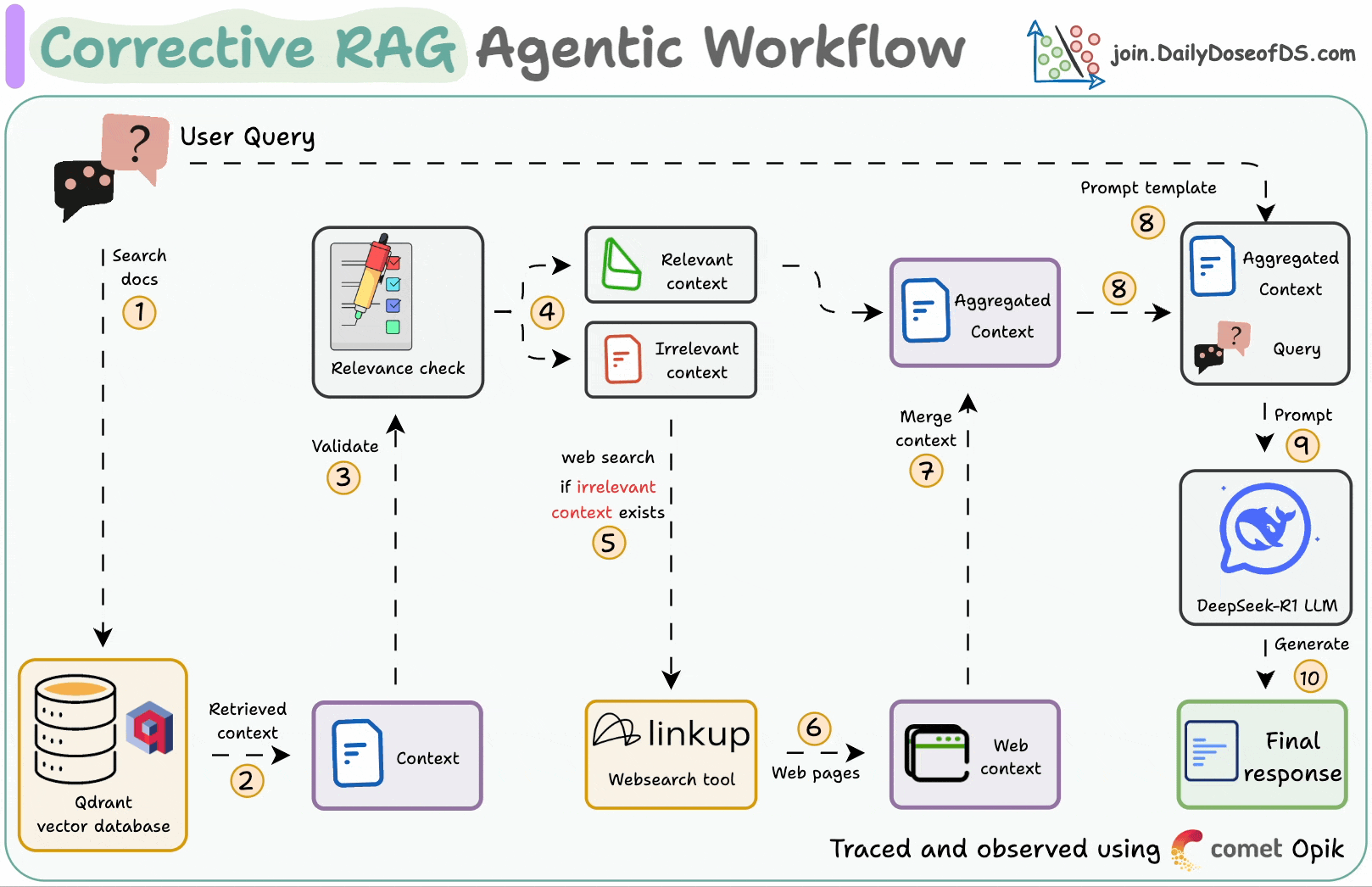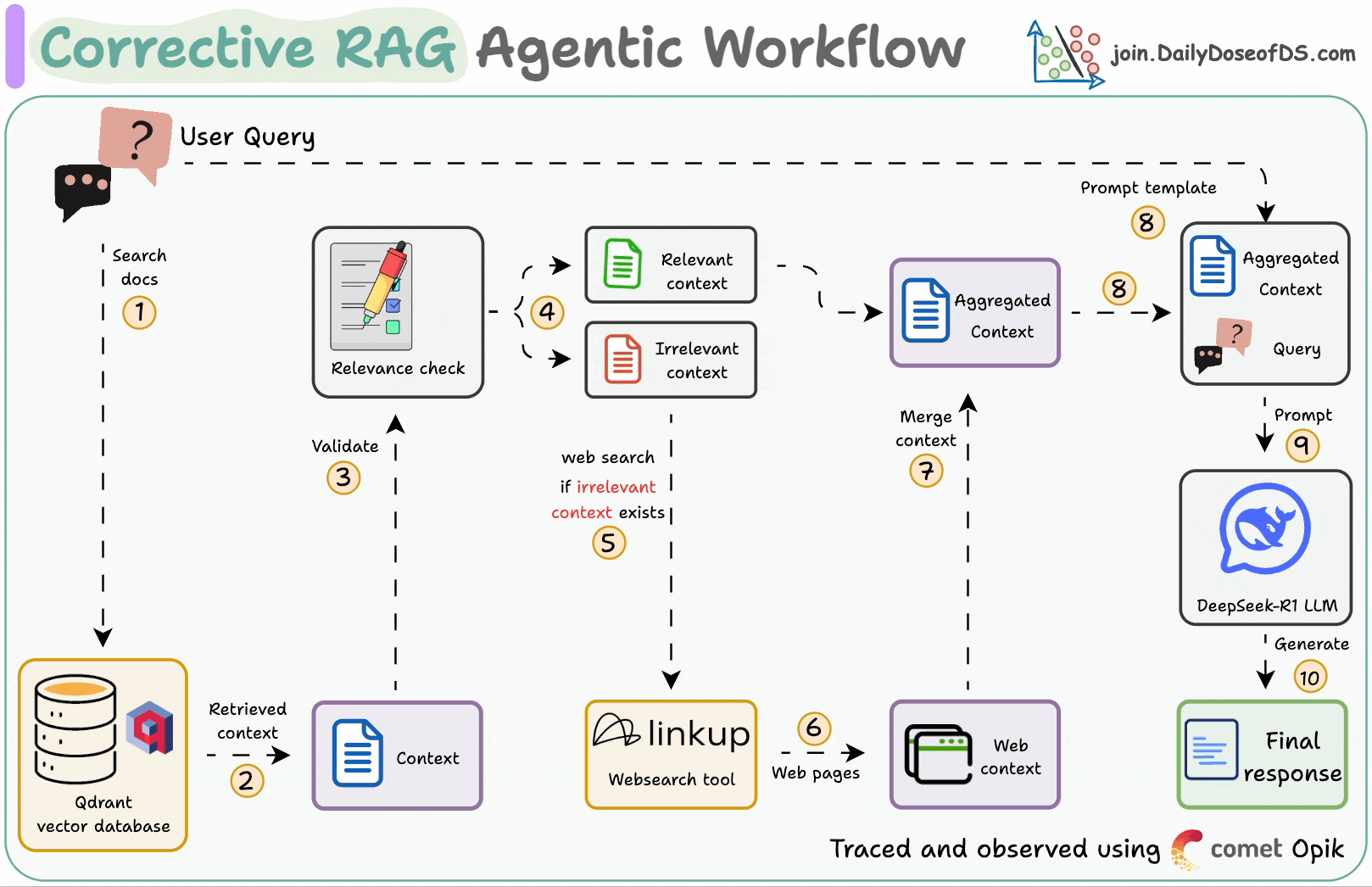 * 首先根据用户查询搜索文档。 * 使用 LLM 评估检索到的上下文是否相关。 * 仅保留相关上下文。 * 如果需要的话,进行网络搜索。 * 聚合上下文并生成响应。 ### RAG 的 5 种分块策略 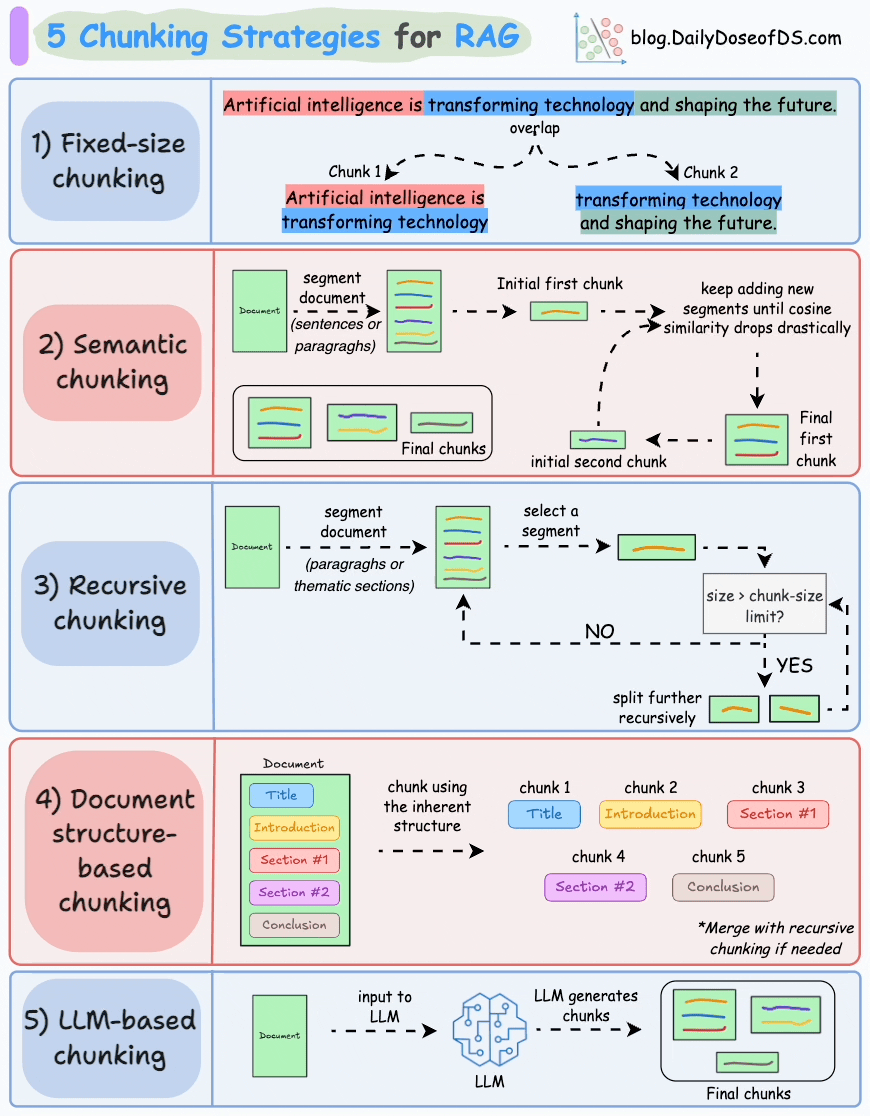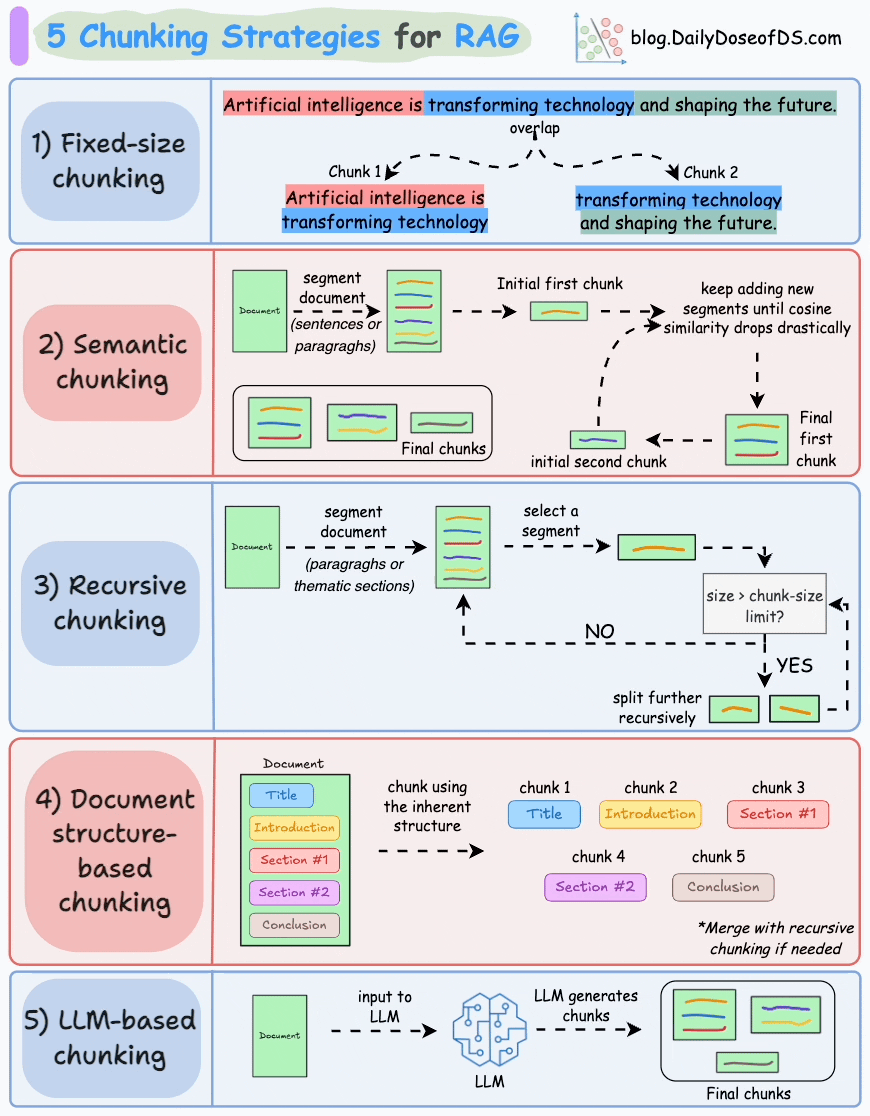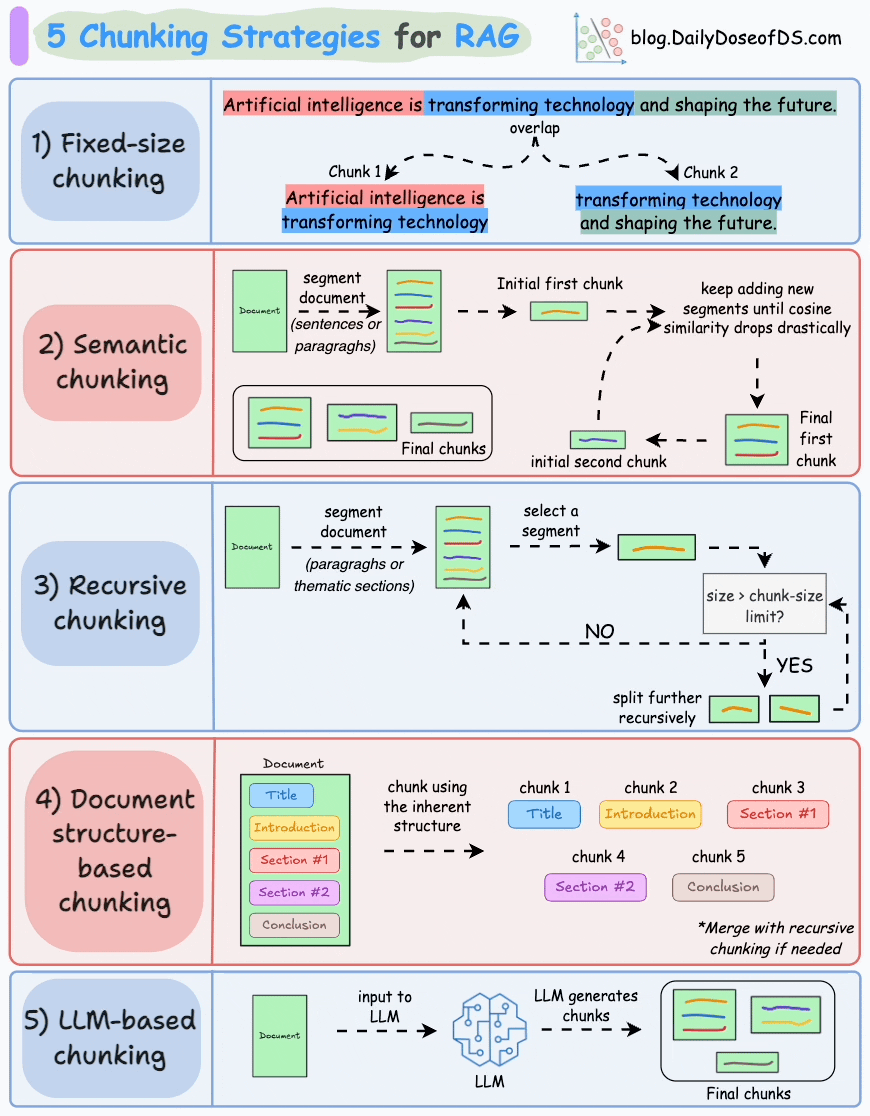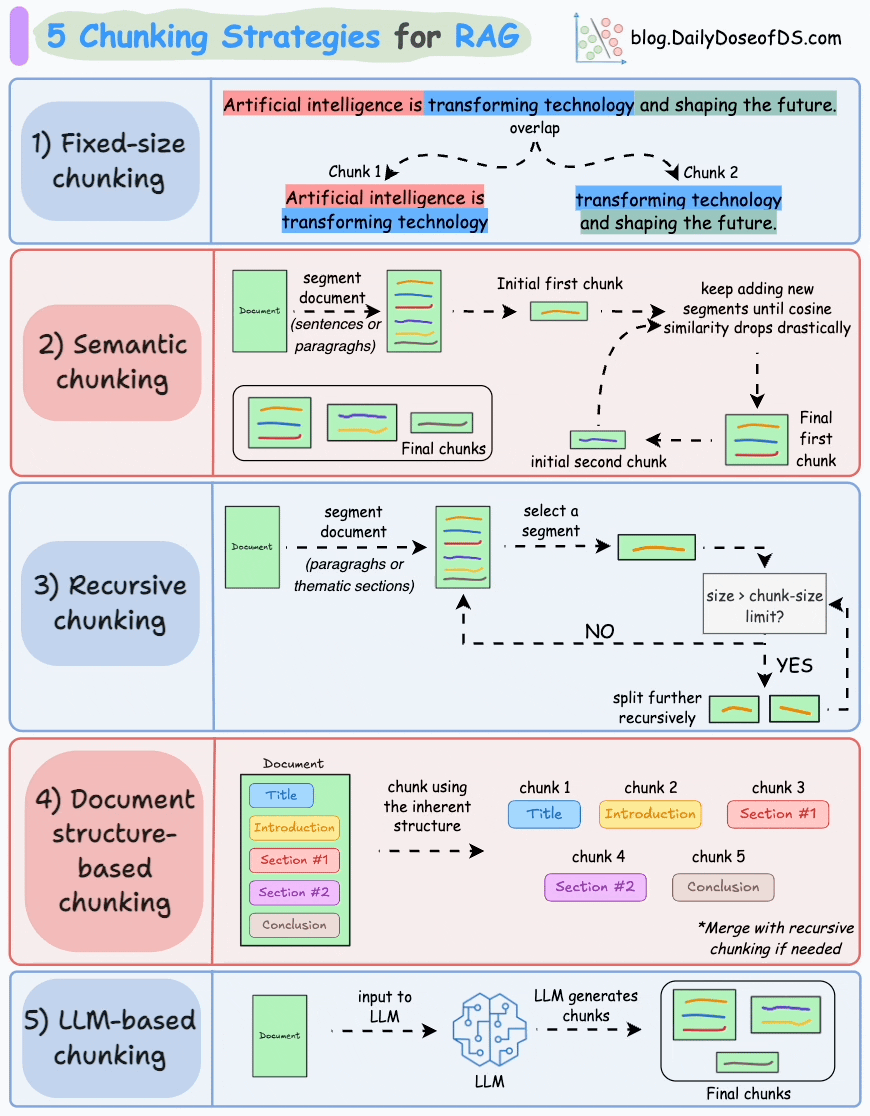 ## 智能体 ### 5种智能体设计模式 Agentic behaviors允许 LLM 通过结合自我评估、规划和协作来改进他们的输出! 下图展示了构建 AI 代理时采用的 5 种最流行的设计模式。 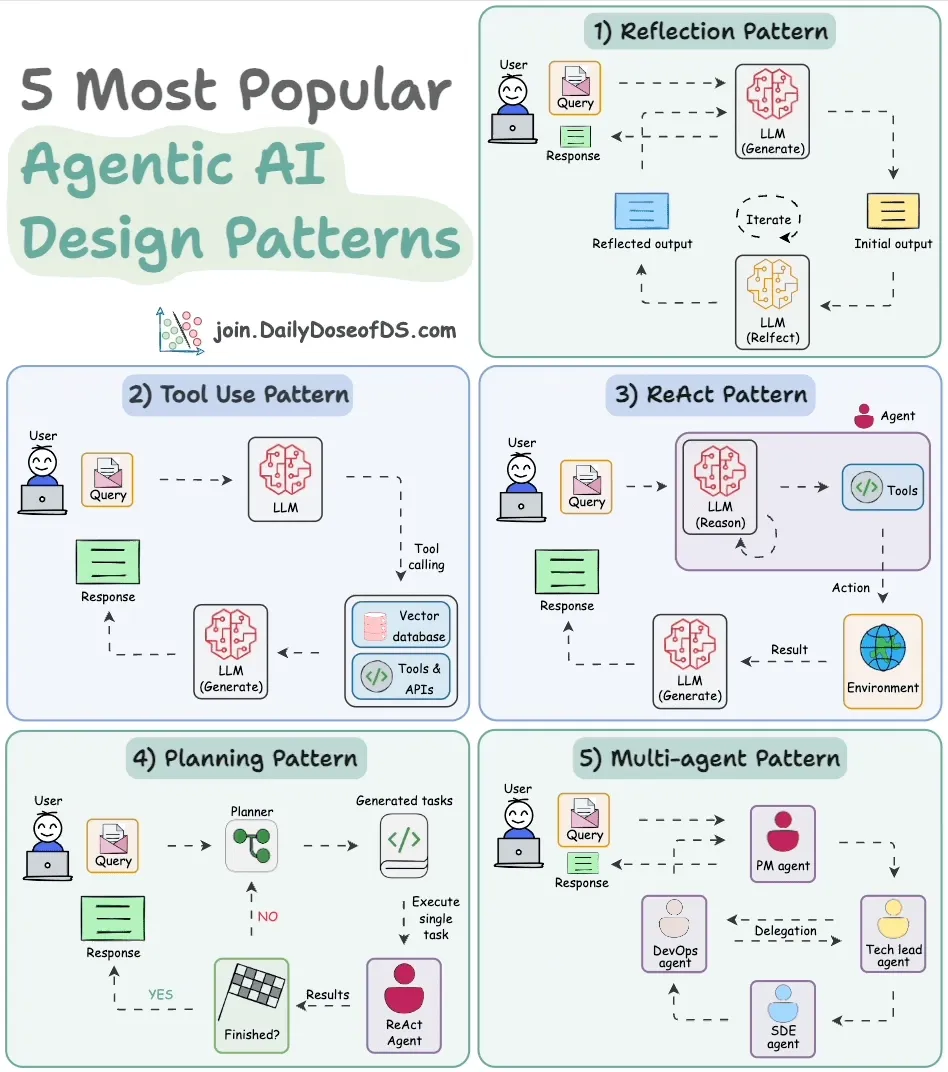 #### 反射模式 LLM会审查其工作以发现错误并不断迭代直到产生最终的响应。 #### 工具使用模式 工具允许 LLM 通过以下方式收集更多信息: * 查询矢量数据库 * 执行 Python 脚本 * 调用API等 这很有帮助,因为 LLM 不仅仅依赖于其内部知识。 #### ReAct(Reason and Action)模式 ReAct 结合了以上两种模式: * 代理可以反映生成的输出。 * 它可以使用工具与世界互动。 这使得它成为当今使用最强大的模式之一。 #### 规划模式 AI 不会一次性解决请求,而是通过以下方式创建路线图: * 细分任务 * 概述目标 这种战略思维可以更有效地解决任务。 #### Multi-agent模式 在此设置中: * 我们有几个agent。 * 每个agent都被分配了专门的角色和任务。 * 每个agent还可以访问工具。 所有agent共同努力以交付最终结果,同时在需要时将任务委派给其他agent。 ### 智能体系统的5个等级 Agentic AI 系统不仅仅生成文本;它们还可以做出决策、调用函数,甚至运行自主工作流程。 该图解释了人工智能代理的 5 个级别——从简单的响应者到完全自主的代理。 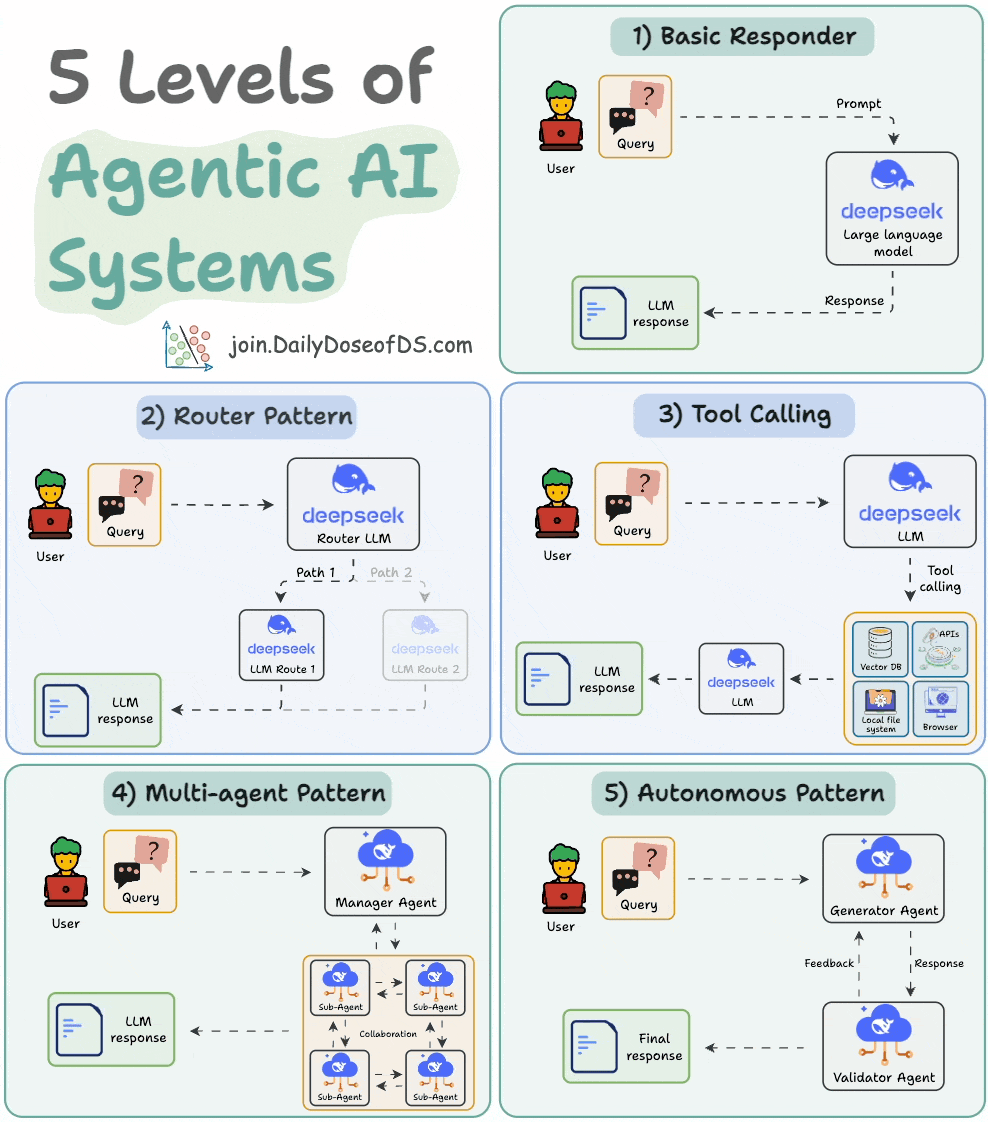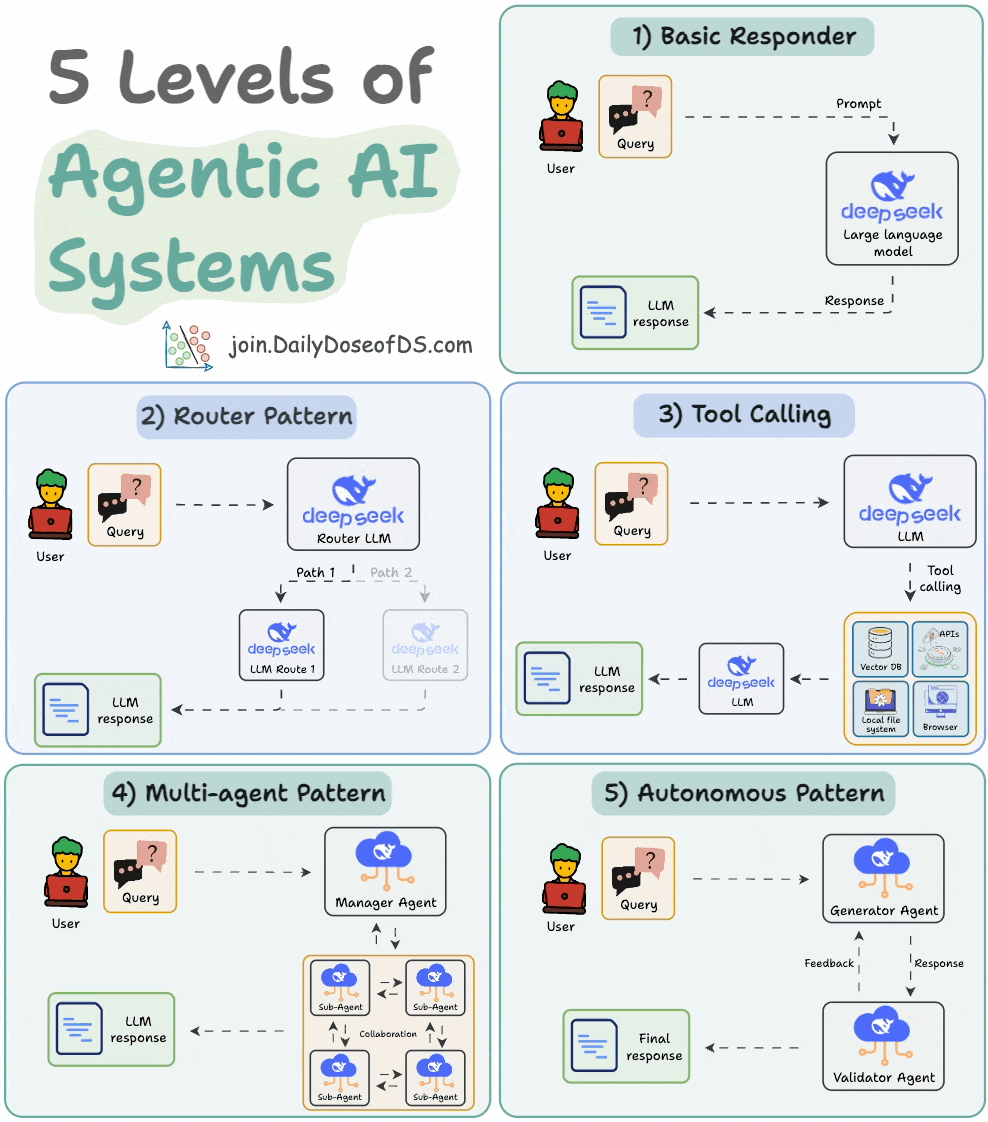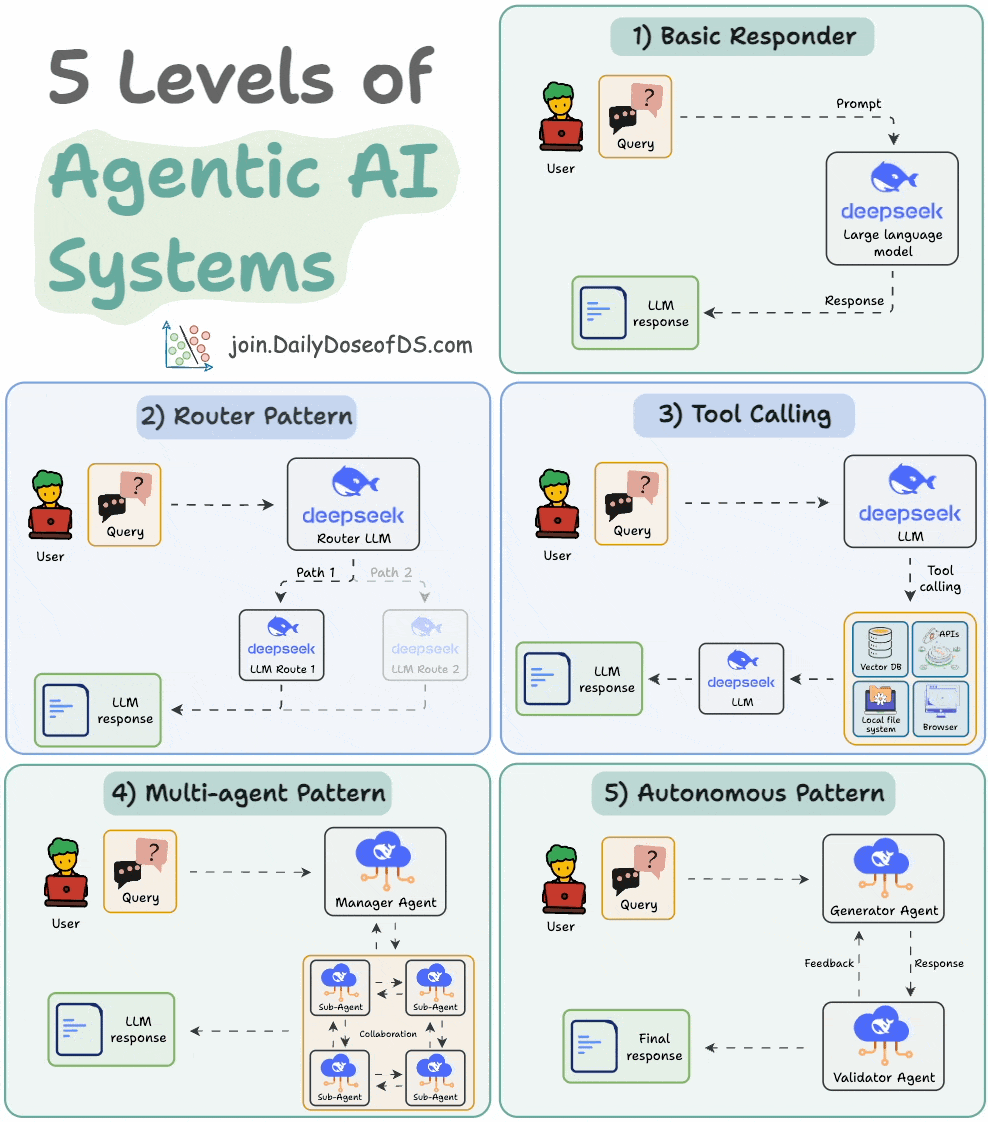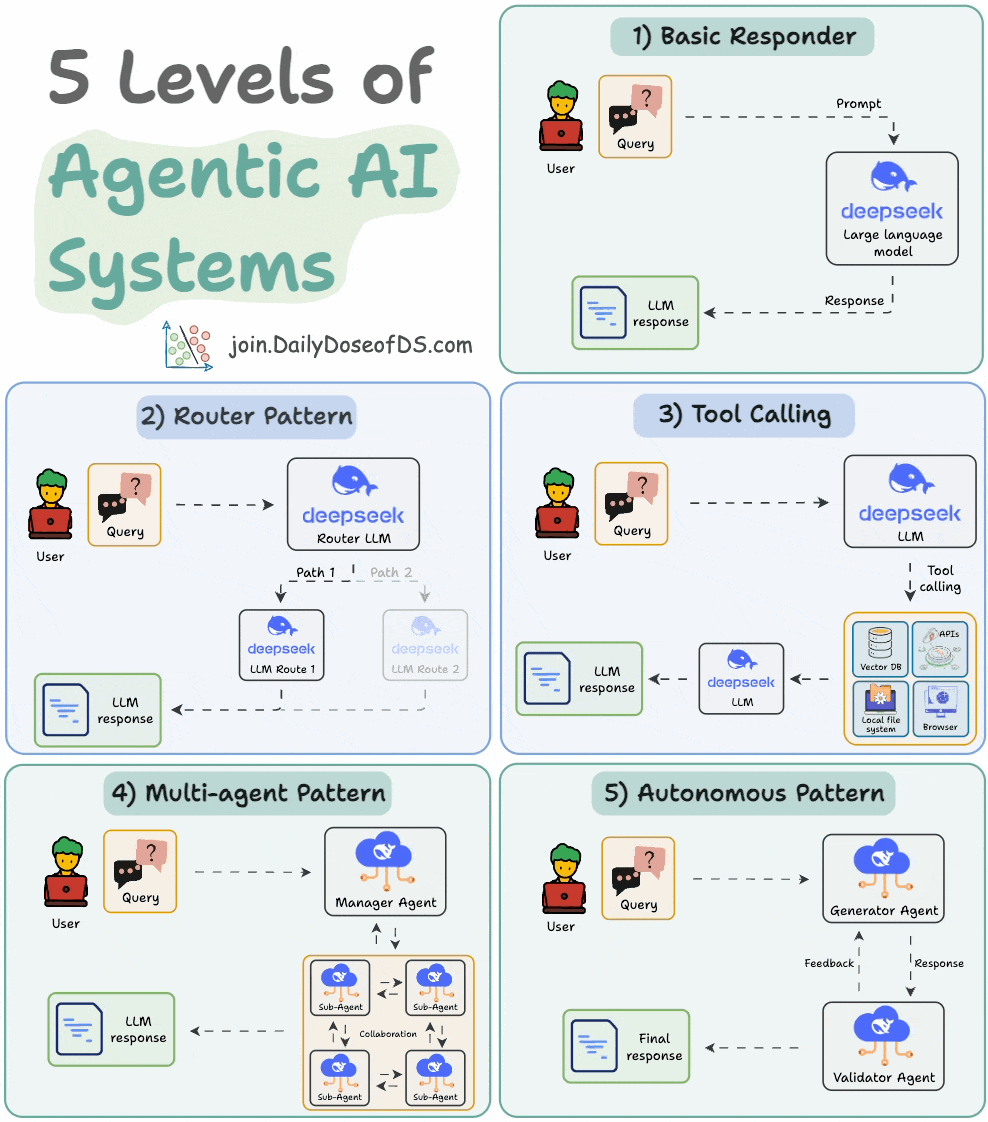 1. 基本响应器仅生成文本 2. 路由器模式决定何时采取路径 3. 工具调用选择并运行工具 4. 多代理模式管理多个代理 5. 自主模式完全独立运作 ## MCP ### Function calling & MCP 在 MCP 成为主流(或像现在这样流行)之前,大多数 AI 工作流程依赖于传统的函数调用。 现在,MCP(模型上下文协议)正在改变开发人员为代理构建工具访问和编排的方式。 以下是解释函数调用和 MCP 的视觉说明: 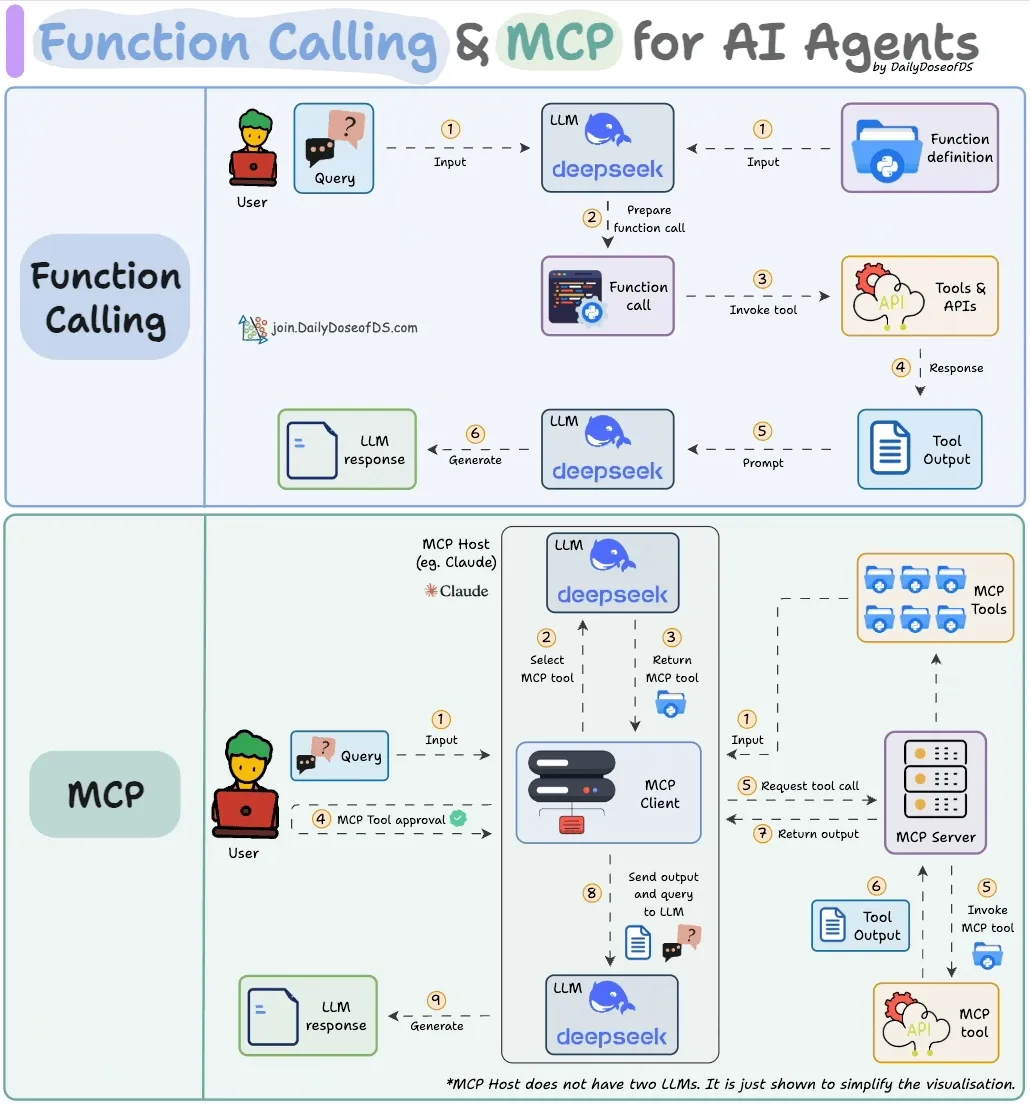 #### Function calling(函数调用) 函数调用是一种机制,它允许 LLM 根据用户的输入识别它需要什么工具以及何时调用它。 它通常的工作方式如下: * LLM 收到来自用户的提示。 * LLM 决定其所需的工具。 * 程序员实现程序来接受来自 LLM 的工具调用请求并准备函数调用。 * 函数调用(带有参数)被传递给处理实际执行的后端服务。 #### MCP(模型上下文协议) 函数调用关注的是模型想要做什么,而 MCP 关注的是如何让工具变得可发现和可用——尤其是跨多个代理、模型或平台。 MCP 无需在每个应用程序或代理中都安装硬接线工具,而是: * 标准化工具的定义、托管和向 LLM 公开的方式。 * 使 LLM 能够轻松发现可用的工具、了解其模式并使用它们。 * 在调用工具之前提供批准和审计工作流程。 * 将工具实施与消费的关注点分开。 ### MCP & A2A Agent2Agent (A2A) 协议让 AI 代理可以连接到其他代理。 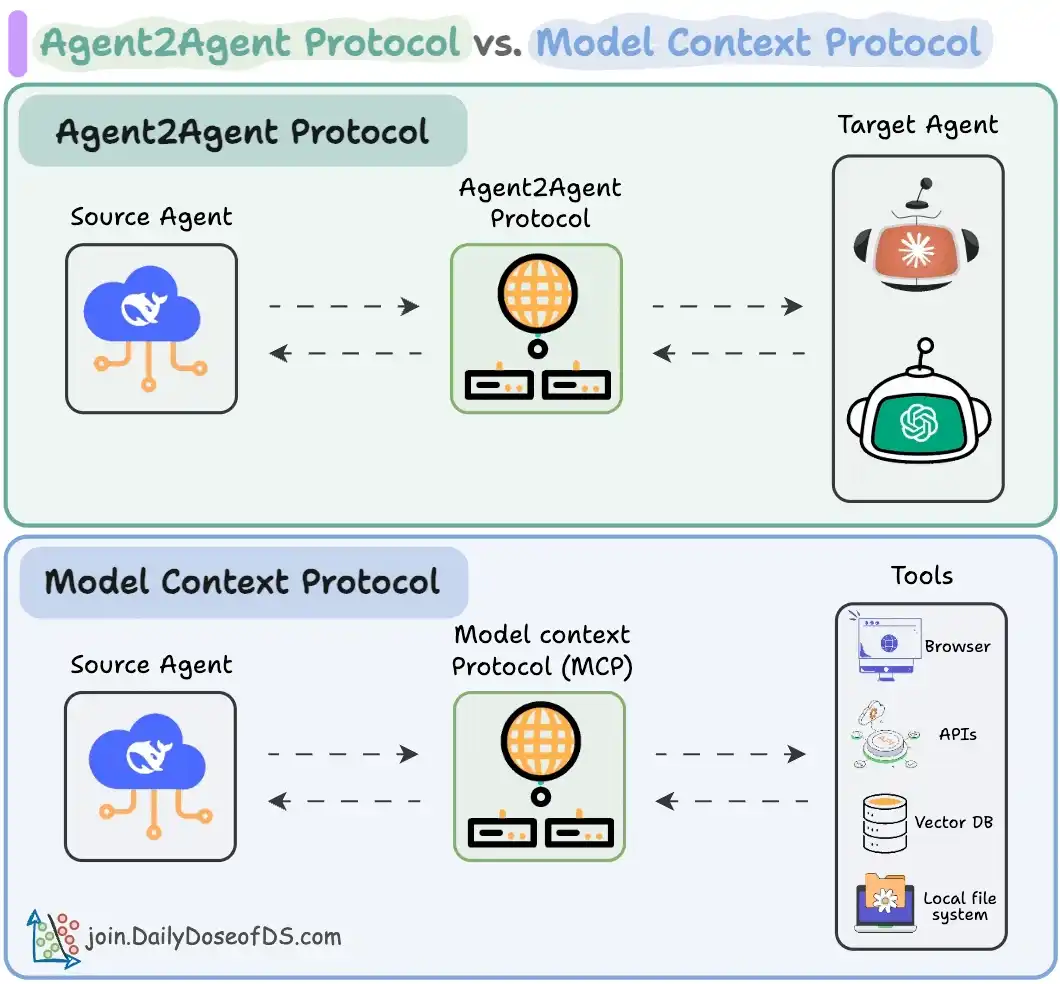 * MCP 为代理提供访问工具的权限。 * 而 A2A 允许代理与其他代理连接并以团队形式协作。 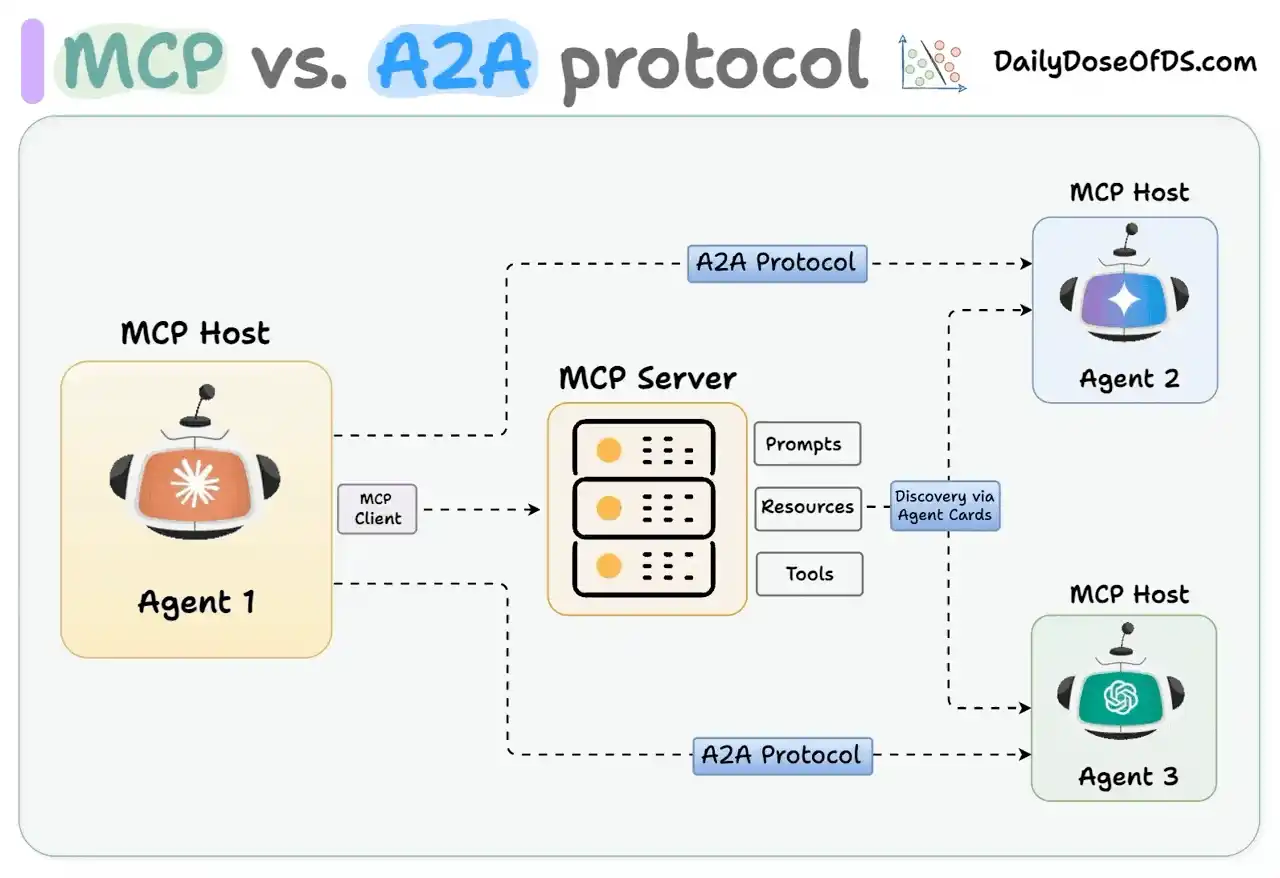 ## Next thing 在代理领域: * MCP 标准化了代理到工具的通信。 * Agent2Agent 协议标准化了 Agent 到 Agent 的通信。 但还缺少一件东西…… 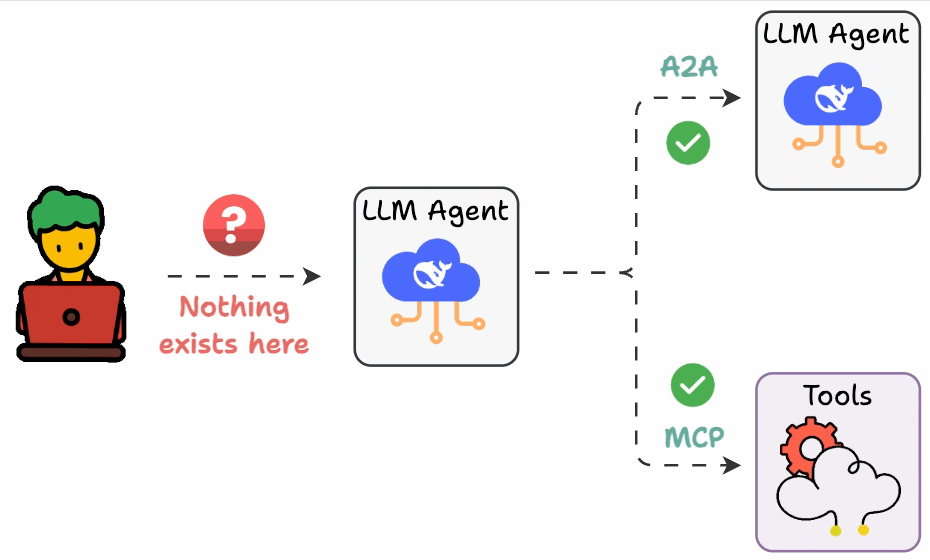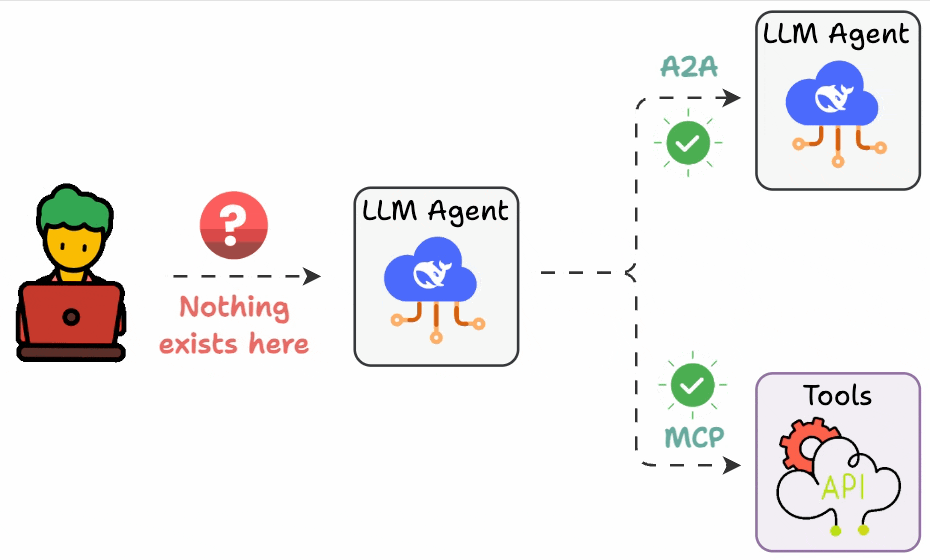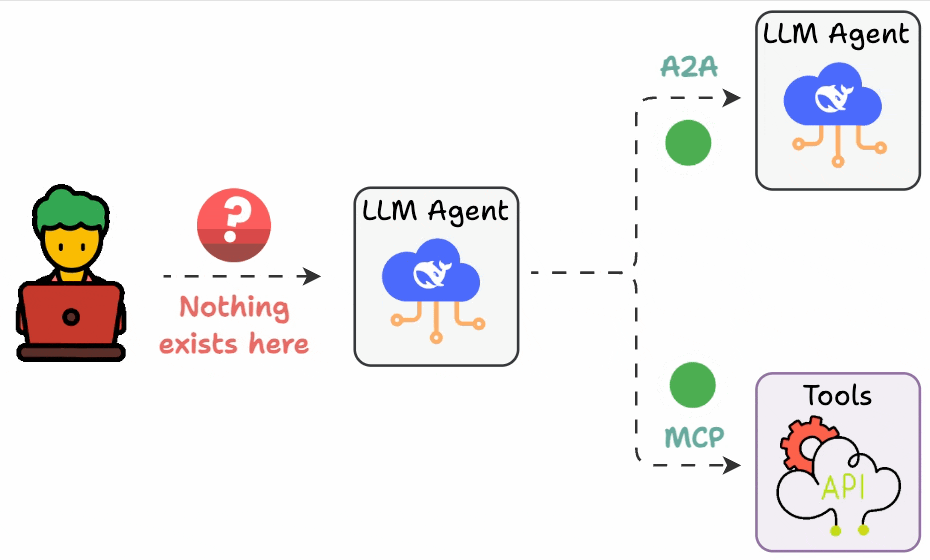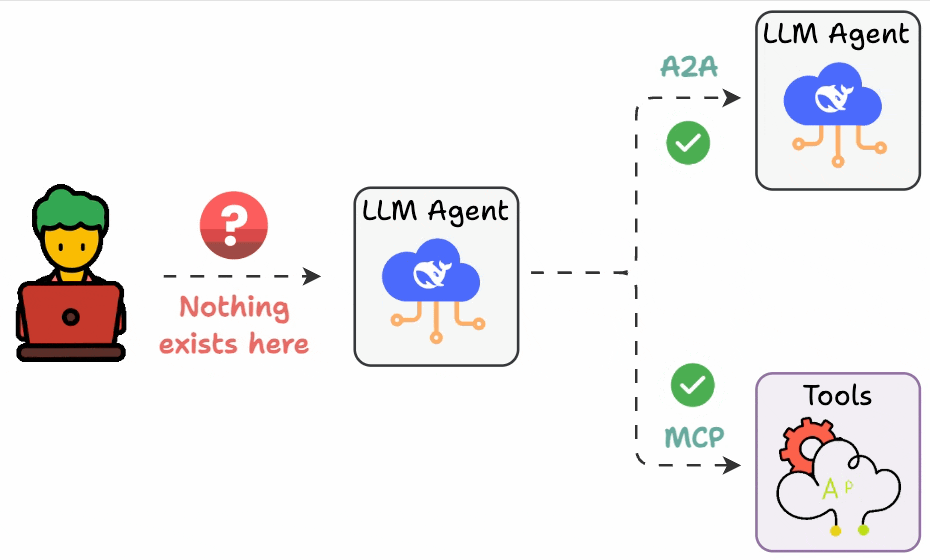 AG-UI(代理-用户交互协议)标准化了后端代理和前端 UI 之间的交互层(下图绿色层)。 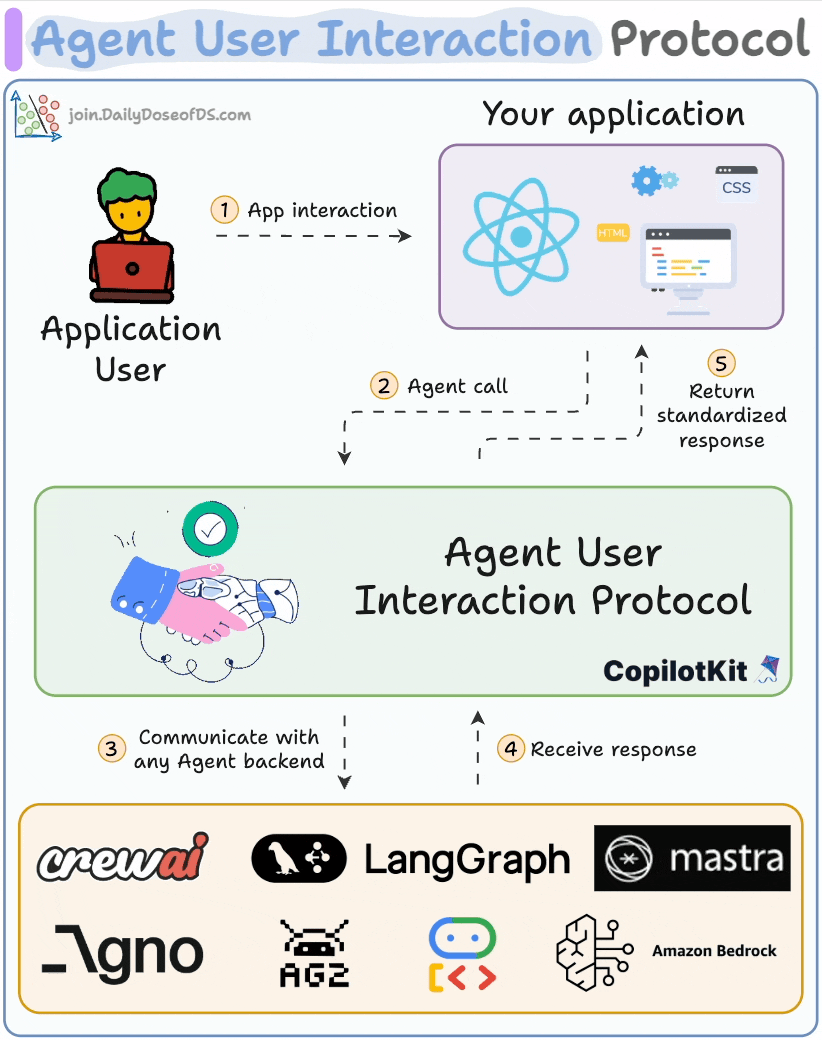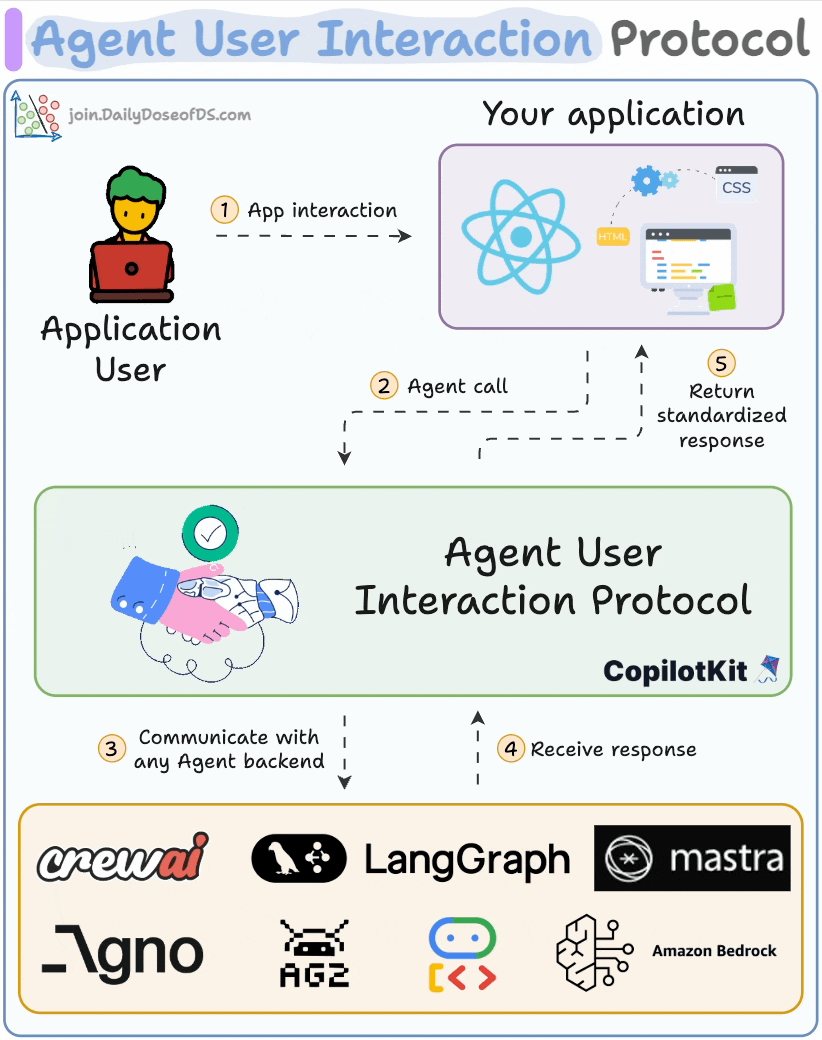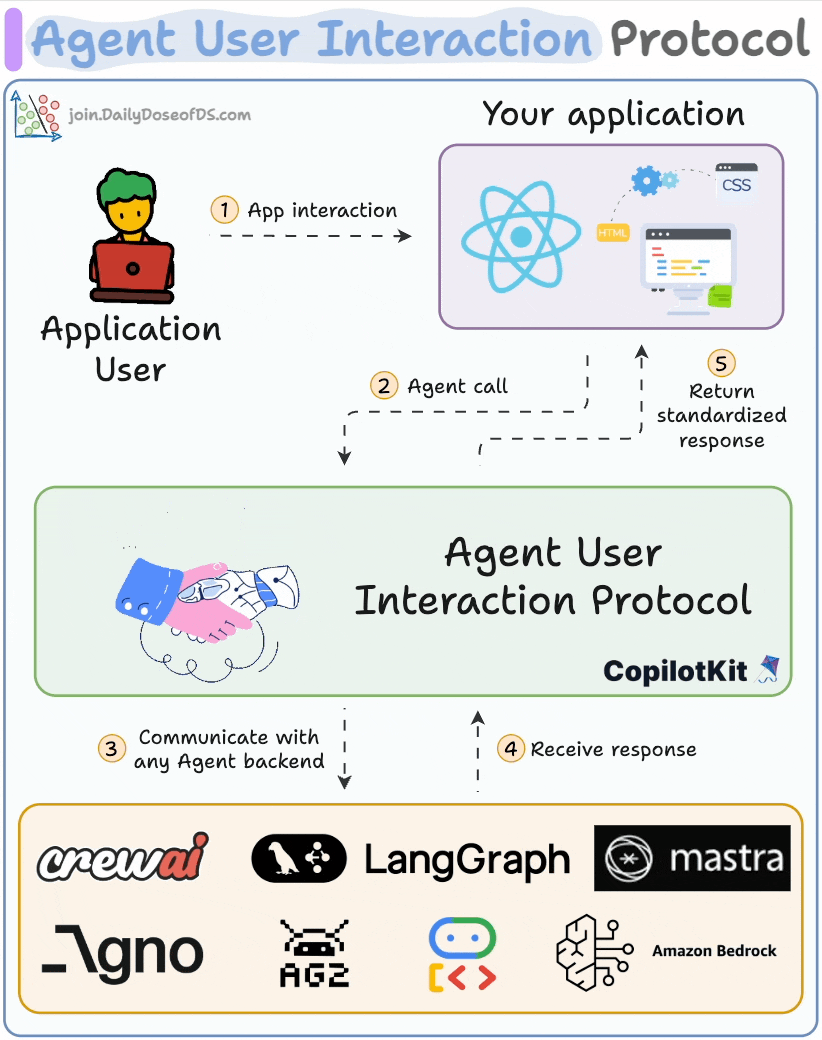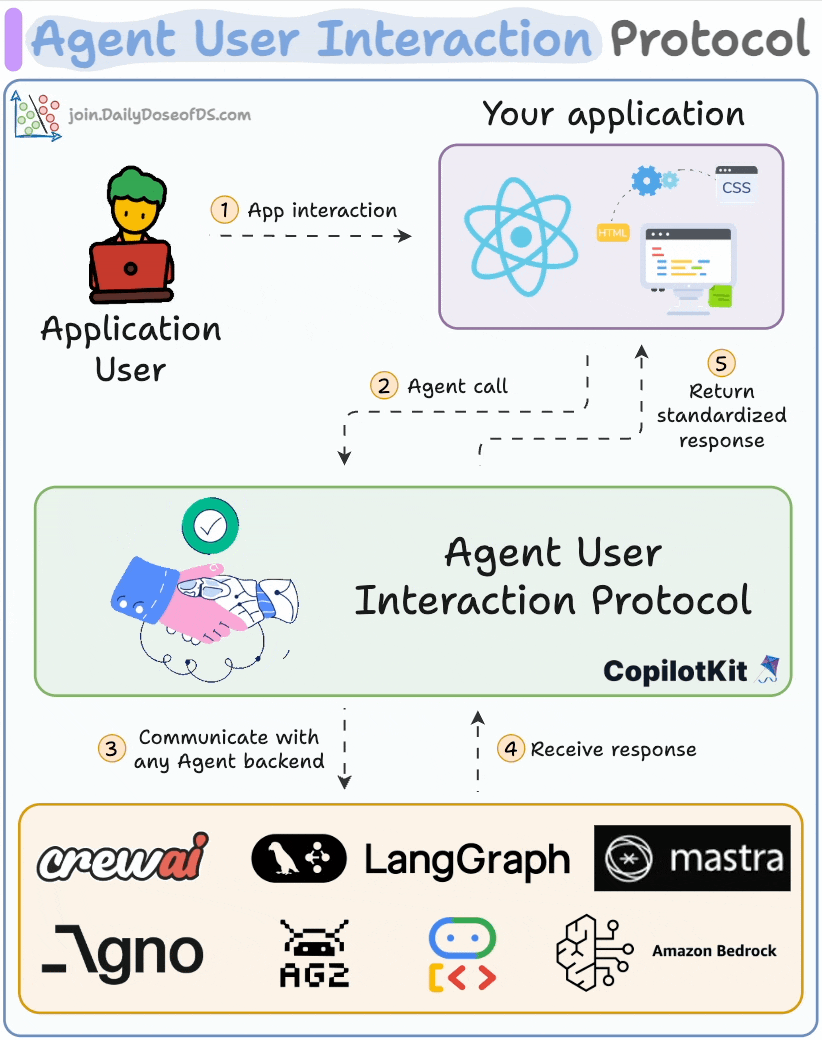
上一篇: 理赔即营销:场景化保险理赔的一站到底
下一篇:Hudi系列:Hudi核心概念之索引(Indexs)
jd****
文章数
9
阅读量
28360
作者其他文章
01
TS版LangChain实战(一):基于文档的增强检索(RAG)
LangChainLangChain是一个以 LLM (大语言模型)模型为核心的开发框架,LangChain的主要特性:可以连接多种数据源,比如网页链接、本地PDF文件、向量数据库等允许语言模型与其环境交互封装了Model I/O(输入/输出)、Retrieval(检索器)、Memory(记忆)、Agents(决策和调度)等核心组件可以使用链的方式组装这些组件,以便最好地完成特定用例。围绕以上设计
01
Webpack5构建性能优化:构建耗时从150s到60s再到10s
优化前现状历史项目基于Vue3 + Webpack5技术栈,其中webpack配置项由开发者自己维护(没有使用@vue/cli-service),并且做了环境分离。项目体量大约5000个modules左右,每次本地构建build时耗时约150s左右。优化细节环境分离之前已经设计了环境分离,但是一些优化细节没有处理好:基础配置文件:webpack.base.js,主要配置了基础的loader和plu
01
Web Components实践:如何搭建一个框架无关的AI组件库
一、让人又爱又恨的Web ComponentsWeb Components是一种用于构建可重用的Web元素的技术。它允许开发者创建自定义的HTML元素,这些元素可以在不同的Web应用程序中重复使用,并且具有自己的样式、行为和功能。 Web Components并非一项新技术,而是一组持续演进的、由W3C标准化的组件化API。最早可以追溯到2011年左右,大约在2016年左右各个浏览器才实现了Cus
01
感受Vue3的魔法力量
近半年有幸参与了一个创新项目,由于没有任何历史包袱,所以选择了Vue3技术栈,总体来说感受如下:setup语法糖<script setup lang="ts">摆脱了书写声明式的代码,用起来很流畅,提升不少效率可以通过Composition API(组合式API)封装可复用逻辑,将UI和逻辑分离,提高复用性,View层代码展示更清晰和Vue3更搭配的状态管理库Pinia,少去了很多配置,使用起来更
jd****
文章数
9
阅读量
28360
作者其他文章
01
TS版LangChain实战(一):基于文档的增强检索(RAG)
01
Webpack5构建性能优化:构建耗时从150s到60s再到10s
01
Web Components实践:如何搭建一个框架无关的AI组件库
01
感受Vue3的魔法力量
添加企业微信
获取1V1专业服务
扫码关注
京东云开发者公众号




 jd****
jd**** 2025-10-09
2025-10-09 905浏览
905浏览






