



Hudi系列:Hudi核心概念(版本1.0)
•Hudi架构
◦一. 时间轴(TimeLine)
▪1.1 时间轴(TimeLine)概念
▪1.2 Hudi的时间线由组成
▪1.3 时间线上的Instant action操作类型
▪1.4 时间线上State状态类型
▪1.5 时间线官网实例
◦二. 文件布局
◦三. 索引
▪3.1 简介
▪3.2 对比Hive没有索引的区别
▪3.3 Hudi索引类型
▪3.4 全局索引与非全局索引
◦四. 表类型
▪4.1 COW:(Copy on Write)写时复制表
▪4.1.1 概念
▪4.1.2 COW工作原理
▪4.1.3 COW表对表的管理方式改进点
▪4.2 MOR:(Merge on Read)读时复制表
▪4.2.1 概念
▪4.2.2 MOR表工作原理
▪4.3 总结了两种表类型之间的权衡
◦五. 查询类型
▪5.1 Snapshot Queries
▪5.2 Incremental Queries
▪5.3 Read Optimized Query
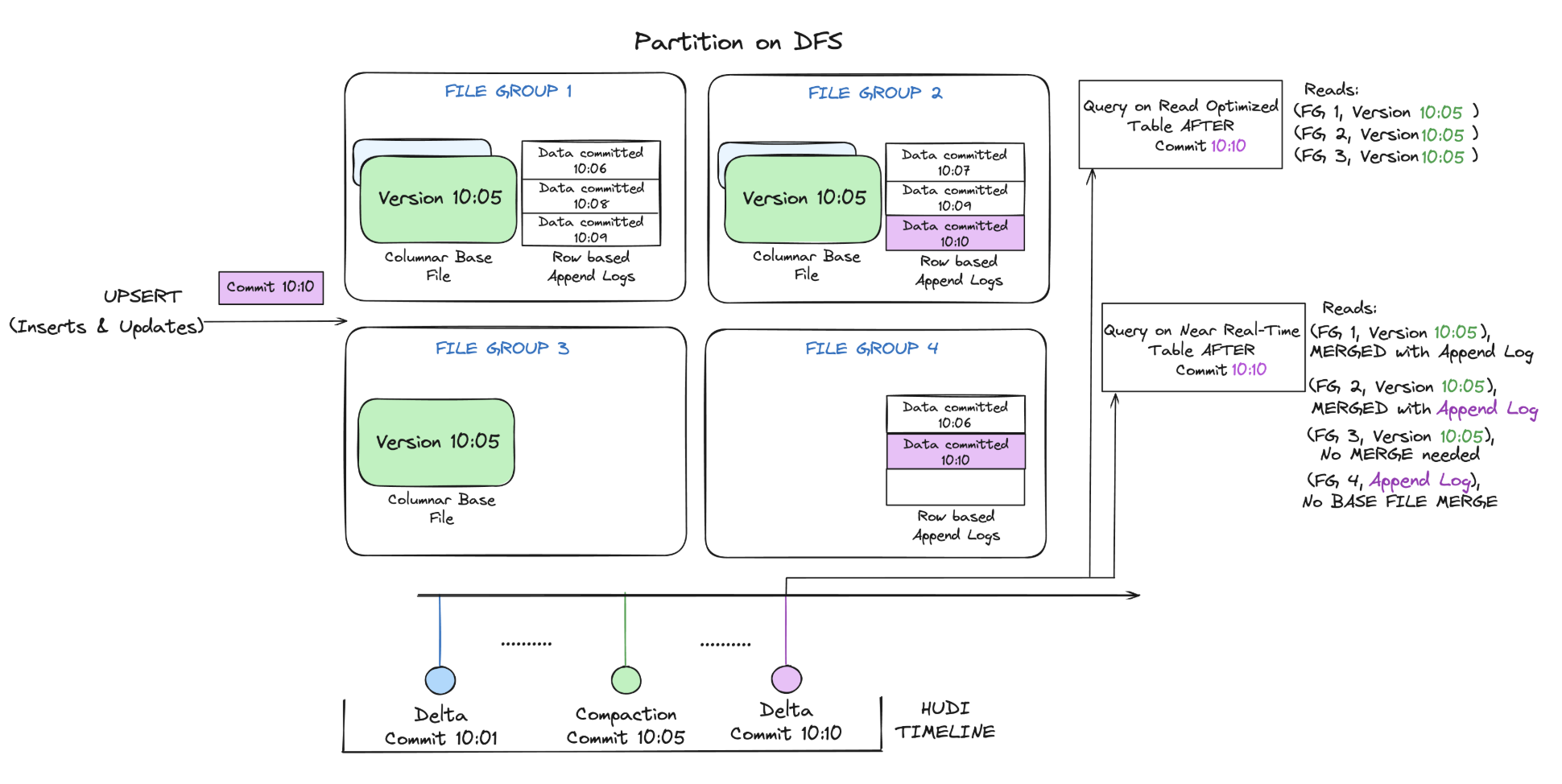
下面描述了 Hudi 表存储文件的一般组织方式。
- Hudi 将数据表组织到存储中基本路径下的目录结构中。
- 根据表架构中定义的分区列,表可以选择性地分为多个分区。
- 在每个分区中,文件被组织成文件组,由文件 ID (uuid) 唯一标识
- 每个文件组包含多个文件切片。
- 每个切片包含一个基本文件 (parquet/orc/hfile)(由配置 - hoodie.table.base.file.format 定义),由在特定时刻完成的提交写入,以及一组日志文件 (.log.),由在下一个基本文件请求时刻之前完成的提交写入。
- Hudi 采用多版本并发控制 (MVCC),其中压缩操作合并日志和基本文件以生成新的文件切片,清理操作删除未使用/较旧的文件切片以回收文件系统上的空间。
- 所有元数据(包括时间线、元数据表)都存储在基本路径下的特殊 .hoodie 目录中。
- 基础文件
基础文件存储完整记录,而更改记录则存储在下面的增量日志文件中。Hudi 目前支持以下基础文件格式。
用于矢量化读取、列压缩和高效列式访问的列式格式,适用于分析/数据科学用于快速扫描以读取整个记录的行式 avro 文件用于高效搜索索引记录的随机访问优化 HFile(基于 SSTable 格式)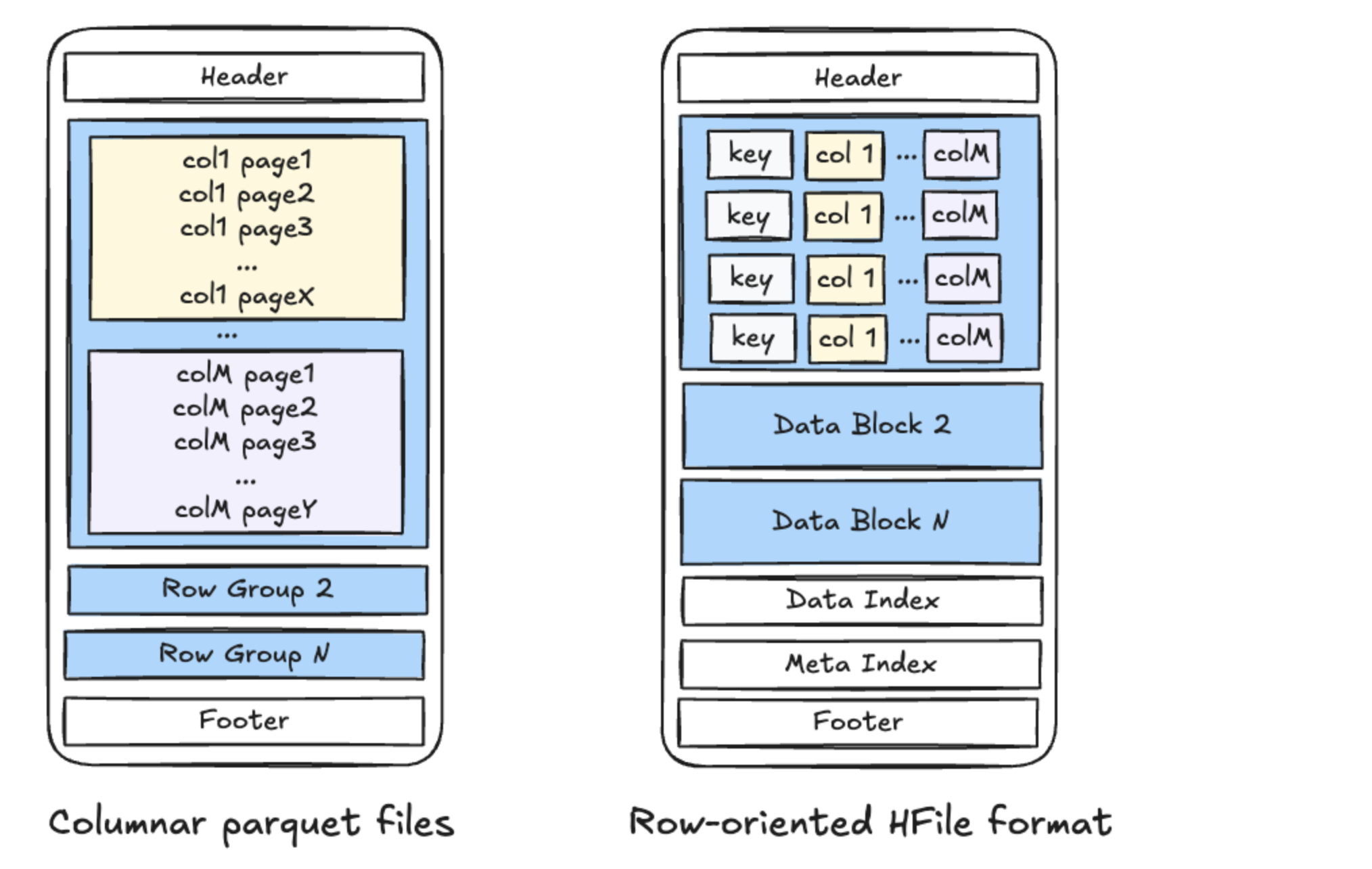
2.日志文件
日志文件存储基础文件创建后对基础文件的增量更改(部分或全部),例如更新、插入和删除。日志文件包含不同的块(数据、命令、删除块等),这些块对基础文件的特定更改进行编码。数据块对基础文件的更新/插入进行编码,并可自定义以支持不同的需求。
面向行的 avro 文件,用于快速/轻量级写入随机访问优化的 HFile,用于高效搜索索引记录(基于 SSTable 格式)列式 parquet 文件,用于矢量化日志合并。3. 存储格式版本控制
Hudi 存储格式的元素(如日志格式、日志块结构、时间线文件/数据模式)都是版本化的,并与给定的表版本相关联。表版本是一个单调递增的数字,每次存储中产生的某些位发生变化时,该数字就会增加。
Backwards compatible reading
Hudi 版本向后兼容,以确保新软件版本可以读取最近的旧表版本。跨不同引擎升级 Hudi 的推荐方法是首先升级所有读取器(例如使用表的交互式查询引擎),然后升级任何/所有写入器和表服务。
Hudi 存储引擎还实现了自动升级功能,可以在后续写入操作中优雅地执行表版本升级,通过自动执行任何必要的步骤而无需停机查询/读取。Backwards compatible writing
但是,这可能并非总是可行的,因为基于 Hudi 构建的数据平台可能具有可以同时充当读取器和写入器的多阶段管道。在这种情况下,Hudi 升级需要通过首先升级最下游的作业来执行,一直跟踪
到可能由摄取系统写入的第一个 Hudi 表。为了简化此过程,Hudi 还允许写入最近的旧表版本,以便可以首先在同一个旧表版本之上在整个部署中推出新的 Hudi 软件二进制文件。一旦所有作
业和引擎都有了新的二进制文件,那么就可以按任何顺序升级到较新的表版本,并且读者将动态适应4. 配置
以下写入器配置控制写入旧表版本和自动升级行为。
| 配置名称 | 默认 | 描述 |
|---|---|---|
| hoodie.write.table.version | latest (Optional) | 此写入器存储表的表版本。如果表已存在,则此版本应与当前表版本匹配。按上述方法升级时,请将此版本设置为较低的版本。 |
| hoodie.write.auto.upgrade | true (Optional) | 假如设置为enabled, 如果当前表版本较低,则写入器会自动将表迁移到指定的写入表版本。 |
文献: https://hudi.apache.org/docs/overview
更多可以参考(1.0以下的版本): http://xingyun.jd.com/shendeng/article/detail/29584?forumId=31&jdme_router=jdme://web/202206081297?url%3Dhttp%3A%2F%2Fsd.jd.com%2Farticle%2F29584






