



本文主要介绍京东联盟广告业务中,使用生成式推荐大模型,优化线上UCTR与UCVR的一些探索和实践。在我们的业务中,通过使用生成式推荐大模型,已经带来了业务上UCTR指标的提升,而对于CPS广告业务,我们更需要关注另外一个重要指标UCVR。本文聚焦于如何通过基于DPO的对齐范式在保UCTR指标的同时提升UCVR指标。文章开始我们会介绍一些生成式推荐的已有方法和一些基于DPO对齐范式的背景知识,接着介绍我们的一些探索和尝试以及线上表现,最后会简单介绍下我们下一步的尝试方向。
1.从传统推荐到生成式推荐
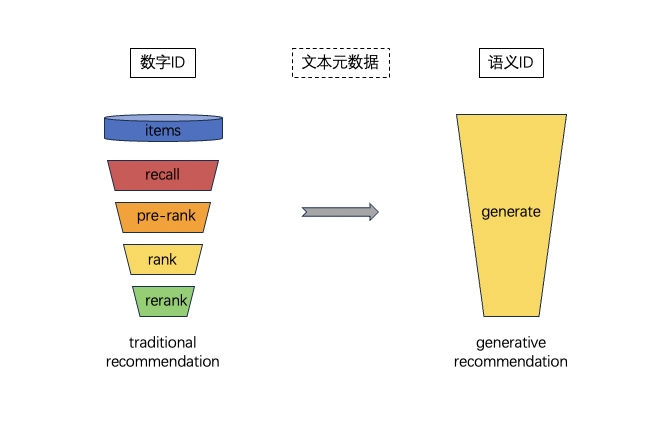
简单而言,生成式推荐相较于传统推荐,旨在流程上做简化,并依靠自己强大的能力来提供更好的泛化性和稳定性。想要更多的了解可以参考这篇综述:生成式推荐系统与京东联盟广告-综述与应用。
2.生成式推荐如何做
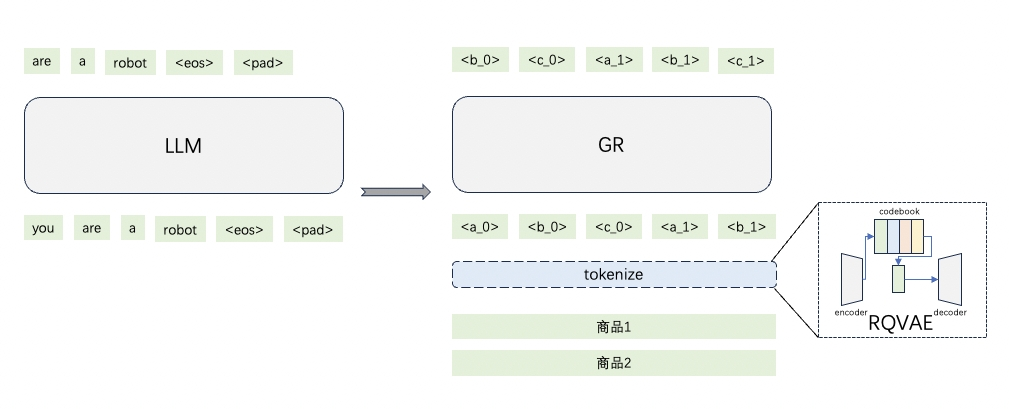
为了简化流程,依靠大模型在自身内部进行商品查询与推荐,我们需要预先构建一个离散化的索引体系来表示商品,然后通过离散化后的索引(语义ID)作为用户历史行为中的商品,输入大模型中,让模型学习和理解用户的行为,最后可以去预测用户的下一个行为。
a)商品离散化
以点击商品为例,在电商场景下,用户点击某个商品,我们预先使用模型将该商品离散化。具体而言,构建一个包含商品标题等重要信息的数据集,通过RQ-VAE框架[1],训练商品表征的离散化表示,最终可以获得N个SID(语义ID),这N个ID来自于从码本的选择结果,使用N个ID作为整体表示该商品。
b)行为序列建模
当获得用户行为序列的离散化表示后,我们可以类比语言模型的方式,将行为按序拼接,通过自回归方式训练,训练目标为next item prediction。在这个过程中,我们发现,加入一些语义ID与自然语言对齐的辅助任务,会有助于模型更好地优化,比如构造一些语义ID预测商品信息或者商品信息预测语义ID的任务。训练过程中,我们尝试了SFT、Pre-train+SFT的方式,发现后者可以更加使得模型训练地更加充分。通过训练,我们的模型在召回指标均上有提升,尤其是在数据稀疏、用户行为不丰富的场景下提升更明显。
3.如何让生成式推荐进行多目标优化
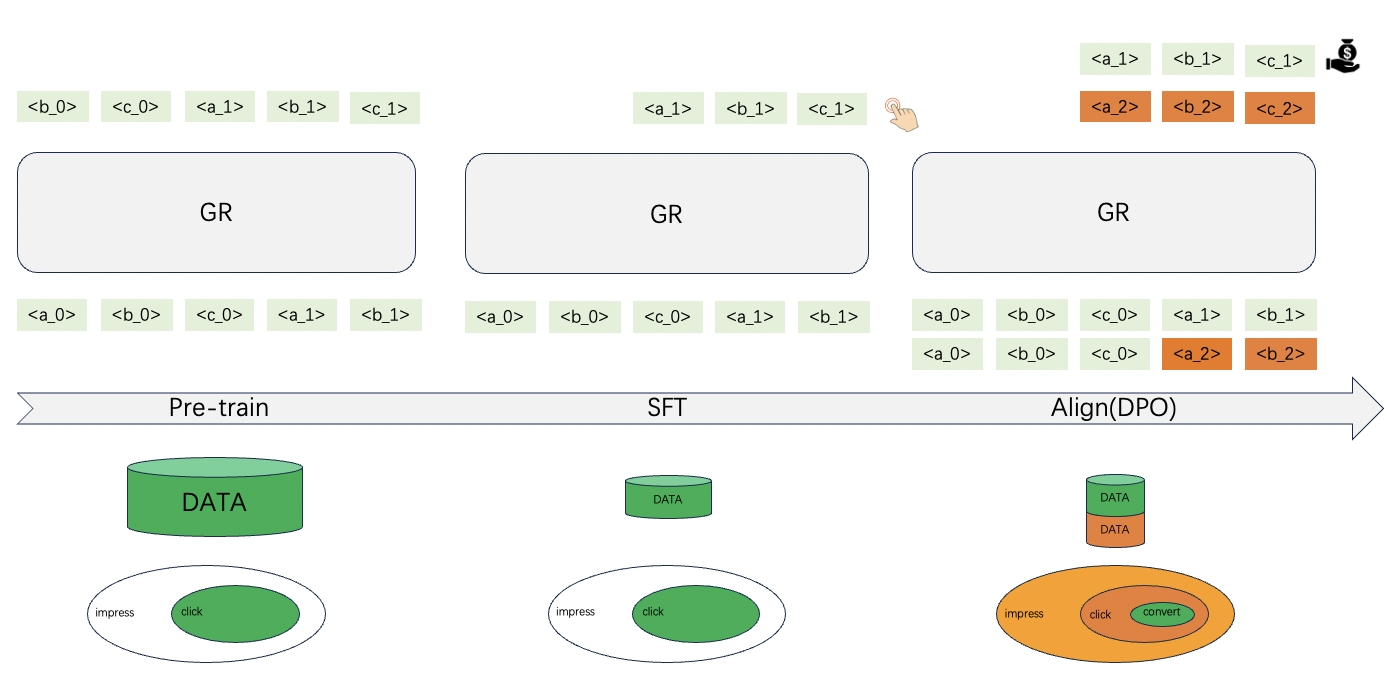
对于CPS业务,我们的最终优化目标是提升转化,同时促进点击。
在Pre-train阶段,我们通过海量的点击行为数据,让模型去记忆和理解用户的各种行为习惯,为模型注入知识。接着在SFT阶段,我们使用小量的数据,让模型在用户的近期行为上进行微调,让模型适应用户行为分布的微小改变。
在完成上述两阶段之后,我们希望模型生成的商品,不光是用户最可能点击的,而且是用户想下单的。比如,在某个时间段,用户看到了A/B/C/D四个商品,其中用户点击了A/B/C三个商品,并且购买了A商品。那我们期望,模型在生成商品的时候,将A的得分要比B/C高,B/C要比D高。为了达成这个目标,我们尝试了利用对齐范式,对监督微调后的模型进行对齐。
a)背景知识
PPO in InstructGPT
InstructGPT[2]中的PPO算法优化目标为最大化模型在生成数据上奖励期望,其中是需要优化的策略模型。
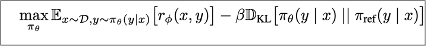
DPO
DPO算法[3]
- 引入BT/PL model
- Bradley-Terry[4]
- Plackett-Luce[5]
从排序角度看,Bradley-Terry model是对一对候选排序,最终结果是期望结果的概率;Plackett-Luce model是对多个候选排序,全排列中期望结果的概率,比如期望结果A>B>C,其概率为,f为某个打分函数,这个概率表示A比BC都好且B比C好的概率。
- 怎么定义呢
- 对PPO求解
将PPO中的优化问题转化为最小化策略分布与的KL散度问题,那么最优情况下,二者相等,从而得到了策略分布和奖励函数之间的关系,便可以得出策略最优解下奖励函数的表达形式了,即。
- 将带入BT/PL模型
Softmax-DPO
- multi-negatives
在实际的任务中,多负例是一种很常见的情况,需要对DPO拓展至多负例情形,将PL模型的第一项取出来,就可以去优化multi-negatives的情况了,也就是Softmax-DPO[6]的做法
- 损失函数
下面是Softmax-DPO的损失函数,红框是和DPO损失函数的主要区别所在,它表示负例的集合,当只有一个负例,损失函数就会变成原始DPO的损失函数形式了。logsumexp作为max函数的一个平滑近似[7],通过这个损失函数会针对与正例的奖励偏差最小的一项进行优化。

- gradient comparison
从梯度角度看S-DPO和DPO对模型优化,二者区别主要表现在对负例的梯度上。对于多个负例,在S-DPO下,每个负例会为各自的梯度配上一个权重,这个权重取决于它与正例的奖励偏差,偏差越小权重就会越大,当面对多个难易程度不同的负例时,即hard negative items和easy negative items,它会增大对前者的关注,使得训练比DPO更加高效和稳定。

β-DPO
在优化DPO的过程中,最终效果会对β参数和数据质量比较敏感。β-DPO[8]发现,β值会因pair数据信息量而异,因此提出了通过batch级别信息量的统计来修正β值,同时过滤一些异常样本的影响。该作者定义pair数据差异为信息量,构造了高gap数据和低gap数据,其中高gap数据使用Anthropic HH数据集[9],同时使用Pythia-2.8B[10]构造一些负例,与数据集中的正例组成低gap数据集。通过实验发现,低gap数据训练的模型,win rate指标[3]会随β变大而下降,而高gap数据集则反之,因此提出通过pair数据差异来动态调整β值。
- β矫正
使用正负例奖励差异作为pair差异衡量标准,并根据这个差异的差分值进行修正,为了稳定训练,在mini-batch内统计这个差异。具体计算如下:,其中为超参数,为初始β值,为差异的差分值,,同时通过移动平均进行更新。
- β样本过滤
对于样本中的一些异常样本,也可以根据上述的差异进行过滤,在一个mini-batch内,按照单个样本的奖励差异在整体样本奖励差异分布上的概率进行采样出特定比例个样本。这个概率通过如下计算近似可得,,其中。
b)数据构造
我们选择了DPO对齐算法,DPO算法要求构建pair数据,pair由正例和负例构成,对应希望奖励高和奖励低的输出。在我们的场景下,下单商品的奖励要高于点击的奖励,点击的奖励要高于曝光的奖励。具体的,我们尝试了三种数据构造,分别为<下单商品,点击未下单商品>,<下单商品,曝光未点击商品>,<下单商品,曝光未下单商品>,并对三种方案进行了离线实验对比,我们统计hit@1/5/10指标,本文仅列出hit@1指标的结果(与未对齐模型的绝对差值),在其他指标上也是同样的效果。
| 点击测试集hit@1 | 转化测试集hit@1 | |
|---|---|---|
| <下单商品,点击未下单商品> | -0.0017 | +0.0528 |
| <下单商品,曝光未点击商品> | -0.0076 | +0.0795 |
| <下单商品,曝光未下单商品> | -0.0054 | +0.0477 |
上述实验可以看到,三种数据方案上,在点击指标上模型有轻微的下降,但在转化指标上的提升幅度会更明显。
c)目标函数调整
用户的行为数据中,会存在一些多个下单与多个未下单的情形,我们尝试构建multiple negatives,并利用Softmax-DPO进行训练。除此之外,在训练DPO模型的过程中,我们也遇到了β参数对模型效果的影响比较明显的情况,因此我们也利用β-DPO方法进行训练。下表中列的是与DPO模型效果的绝对差值。
| 点击测试集 hit@1 | 转化测试集 hit@1 | |
|---|---|---|
| β-DPO | -0.0041 | 0 |
| Softmax-DPO | +0.0028 | -0.0253 |
β-DPO确实可以缓解超参过于敏感的问题,但在最终效果提升上表现不明显。而增加了多负例的Softmax-DPO方法,在转化指标上相较于DPO有所下降,有可能是多负例情况下会忽略负例间位序信息带来的冲突,影响了效果。虽然相较于DPO模型二者提升下降有不同,但相较于未对齐模型二者仍旧有较明显的提升。
4.线上表现
我们将对齐模型进行线上小流量A/B实验,对比与未经过对齐模型的指标,经过线上多天的观察,在我们的深海业务场景上,在点击率轻微提升的情况下,明显地提升了转化率指标,达到了预期效果。
| uctr | ucvr | |
|---|---|---|
| 对齐模型 | +0.6% | +8.0% |
5.未来计划
我们的目标是提升转化的同时,促进点击。我们验证了通过DPO的方式的有效性。我们仍旧可以有两个问题,一是DPO方式是否可以进一步探索,二是多目标的优化方式是否只有对齐这种方式。我们的实践中发现,对齐方式仍旧存在“alignment tax”[2]问题,在DPO方式下,我们能否通过引入多个单目标强大的reference model来进行优化,缓解提升一方面就需要减弱一方面的问题,mrpo[11]算法提供了一种可能。抛开DPO方式,能通过多目标多输出的SFT方式就直接达成目标呢,我们也在尝试中。除此之外,我们的业务还存在多场景、多行为等复杂问题,如何在生成式推荐范式下更好的建模这些问题,也是我们下一步的探索方向。
6.引用
[1]Zeghidour, N., Luebs, A., Omran, A., Skoglund, J., & Tagliasacchi, M. (2021). SoundStream: An End-to-End Neural Audio Codec.IEEE/ACM Transactions on Audio, Speech, and Language Processing, 30, 495-507.
[2]Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C.L., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., Schulman, J., Hilton, J., Kelton, F., Miller, L.E., Simens, M., Askell, A., Welinder, P., Christiano, P.F., Leike, J., & Lowe, R.J. (2022). Training language models to follow instructions with human feedback.ArXiv, abs/2203.02155.
[3]Rafailov, R., Sharma, A., Mitchell, E., Ermon, S., Manning, C.D., & Finn, C. (2023). Direct Preference Optimization: Your Language Model is Secretly a Reward Model.ArXiv, abs/2305.18290.
[4]Bradley, R.A., & Terry, M.E. (1952). Rank Analysis of Incomplete Block Designs: I. The Method of Paired Comparisons.Biometrika, 39, 324.
[5]Plackett, R.L. (1975). The Analysis of Permutations.Journal of The Royal Statistical Society Series C-applied Statistics, 24, 193-202.
[6]Chen, Y., Tan, J., Zhang, A., Yang, Z., Sheng, L., Zhang, E., Wang, X., & Chua, T. (2024). On Softmax Direct Preference Optimization for Recommendation.ArXiv, abs/2406.09215.
[7]https://kexue.fm/archives/9070
[8]Wu, J., Xie, Y., Yang, Z., Wu, J., Gao, J., Ding, B., Wang, X., & He, X. (2024). β-DPO: Direct Preference Optimization with Dynamic β.ArXiv, abs/2407.08639.
[9]Bai, Y., Jones, A., Ndousse, K., Askell, A., Chen, A., Dassarma, N., Drain, D., Fort, S., Ganguli, D., Henighan, T., Joseph, N., Kadavath, S., Kernion, J., Conerly, T., El-Showk, S., Elhage, N., Hatfield-Dodds, Z., Hernandez, D., Hume, T., Johnston, S., Kravec, S., Lovitt, L., Nanda, N., Olsson, C., Amodei, D., Brown, T.B., Clark, J., McCandlish, S., Olah, C., Mann, B., & Kaplan, J. (2022). Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback.ArXiv, abs/2204.05862.
[10]Biderman, S., Schoelkopf, H., Anthony, Q.G., Bradley, H., O'Brien, K., Hallahan, E., Khan, M., Purohit, S., Prashanth, U.S., Raff, E., Skowron, A., Sutawika, L., & Wal, O.V. (2023). Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling.ArXiv, abs/2304.01373.
[11]Le, H., Tran, Q., Nguyen, D., Do, K., Mittal, S., Ogueji, K., & Venkatesh, S. (2024). Multi-Reference Preference Optimization for Large Language Models.ArXiv, abs/2405.16388.





