前言
本文主要针对供应链计划业务发展过程中系统产生的瓶颈问题的解决方案进行阐述,并且分享一些问题解决过程中用到的一些工具方法,希望对其他业务同类问题提供启发,原理细节不着重介绍,如有兴趣欢迎一起探讨。
业务背景
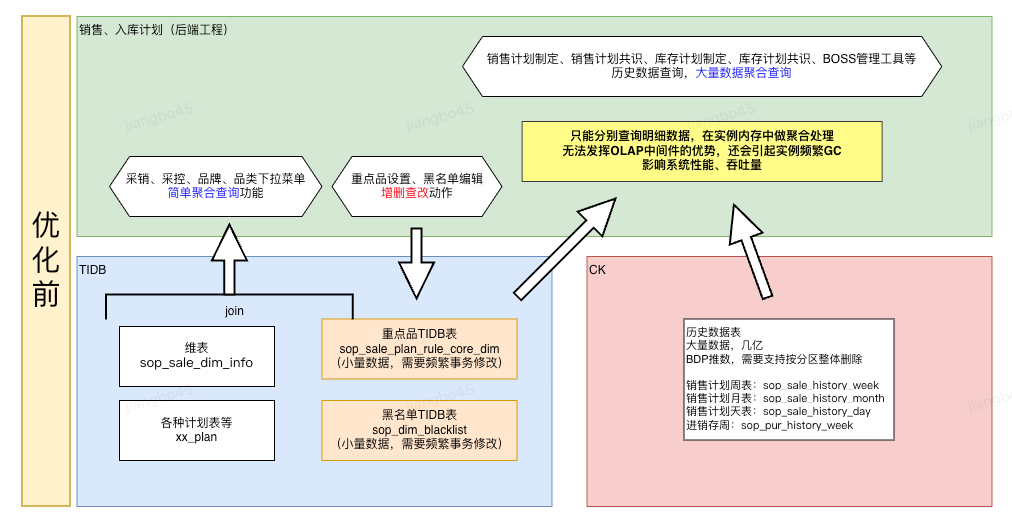
供应链计划业务目前数据库主要使用了Tidb和Clickhouse,Tidb用于存储计划数据、维度数据、业务配置等数据,Clickhouse用于存储量级比较大的历史参考数据。随着业务发展,业务需要在某些场景下对这些历史数据做一些过滤或配置一些业务Tag,并且这些过滤条件和业务Tag需要支持更新、删除。最初我们的解决方案中部分配置的生效方案是将这些配置存在Tidb,然后通过离线抽数到离线大数据表,然后在离线大数据平台对历史数据进行处理后推送到Clickhouse再使用,但是这样业务的生效周期就是T+1,对业务使用的体验非常不友好。还有一些配置生效方案是将Tidb的业务配置和Clickhouse中的历史数据全部读取出来,在实例的内存中进行聚合处理,这种解决方案会导致实例的内存不够用,经常OOM,影响系统稳定性。而且在内存中处理这些数据的逻辑比较重,致使某些场景下的查询非常慢,个别情况一次查询响应时长会达到10秒以上,严重影响用户使用体验。
解决方案
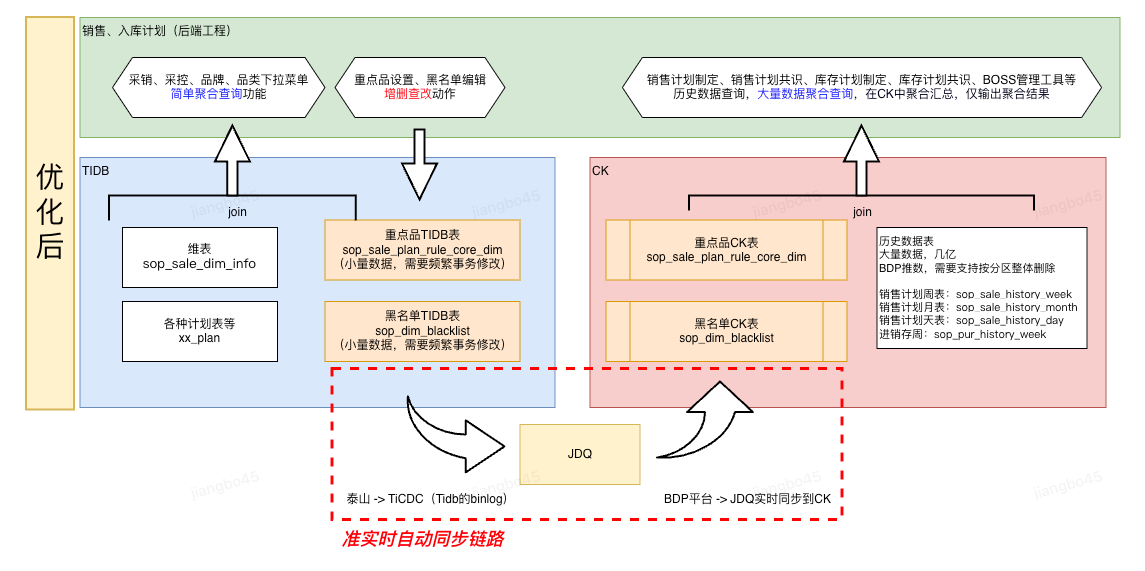
针对以上生效周期长、聚合查询内存占用大、查询慢这些问题,我们在实验后发现,无论实在Tidb还是在Clickhouse中,通过sql聚合查询直接输出聚合结果,要比在内存中聚合要快很多,而且对db也不会造成很大的压力,其效果大概是在内存中执行5秒的逻辑,等比转化到sql中,大约300ms就可以输出结果,这中间涉及IO传输、DB的聚合优化、索引等,具体原理不做过多阐述,有兴趣自行网上查阅即可。 主要优化方向就是将业务配置数据同步到Clickhouse中一份,然后分别在Tidb和Clickhouse中join输出结果数据。
解决方案关键技术分享
1.Clickhouse ReplacingMergeTree建表及维表模式
最初我们查阅官方文档后,决定使用ReplacingMergeTree,然后在使用时使用final关键字保证数据去重,官方文档:https://clickhouse.com/docs/en/engines/table-engines/mergetree-family/replacingmergetree,官方文档的建表和查询示例:
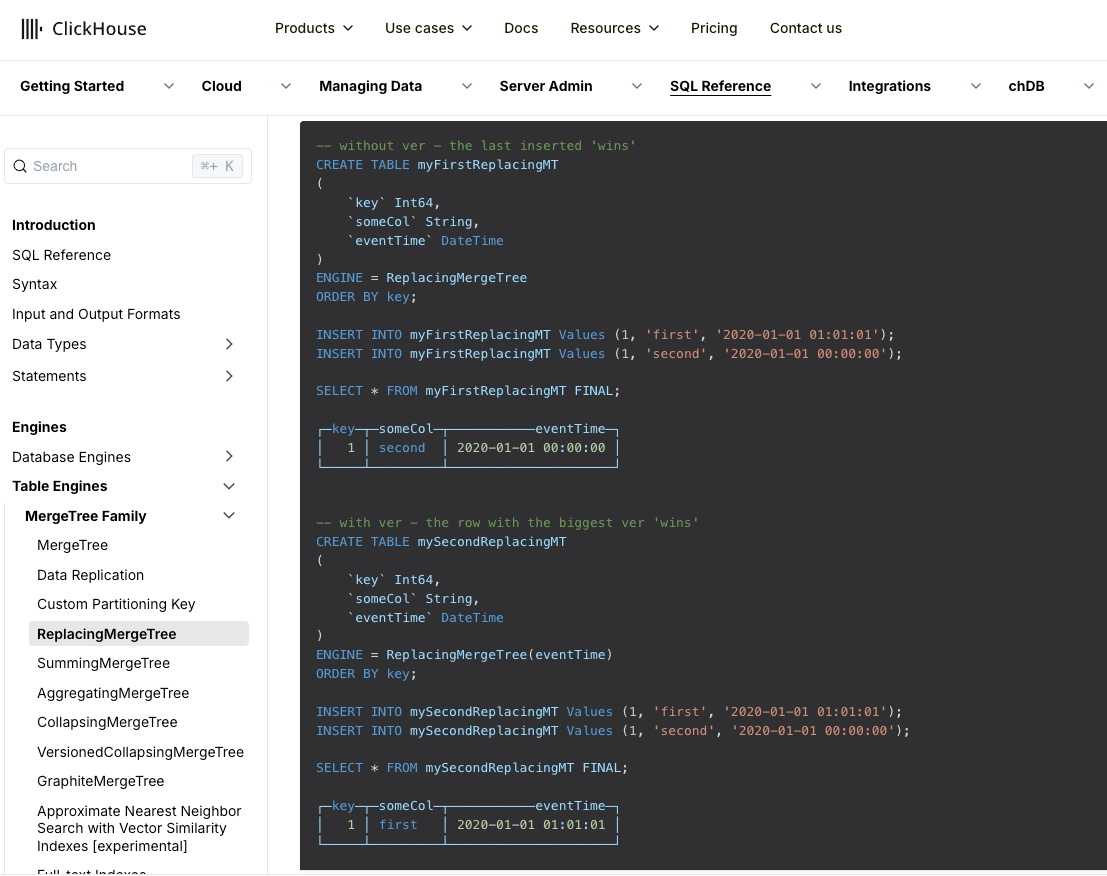
官方文档的示例过于简略了,相当于“Hello Word”,并不能满足我们实际使用需求,想要实际在生产环境应用,需要建成下面这样:
CREATE TABLE IF NOT EXISTS 库名.blacklist ON CLUSTER xx
(
`dept_id_1` Int32 COMMENT '一级部门ID',
`dept_id_2` Int32 COMMENT '二级部门ID',
`dept_id_3` Int32 COMMENT '三级部门ID',
`saler` String COMMENT '销售erp',
`pur_controller` String COMMENT '采控erp',
`update_time` DateTime COMMENT '更新时间',
`is_deleted` UInt8 COMMENT '有效标识 0:标识未删除 1:表示已删除'
)
ENGINE = ReplicatedReplacingMergeTree('/clickhouse/xx/jdob_ha/sop_pre_mix/blacklist/{shard_dict}', '{replica_dict}', update_time)
ORDER BY (dept_id_3, saler, pur_controller)
SETTINGS storage_policy ='jdob_ha';关于上面的建表语句,有几个要点需要解析一下
第一,ReplacingMergeTree需要写成ReplicatedReplacingMergeTree,这个参考了京东ck运营文档里的解释
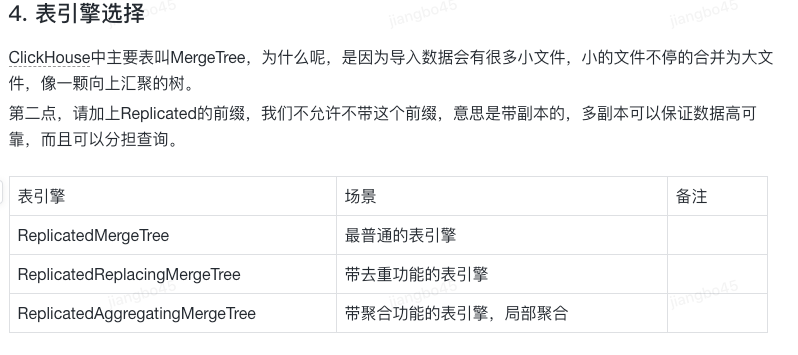
第二,【'/clickhouse/xx/jdob_ha/库名/blacklist/{shard_dict}', '{replica_dict}',】 这个信息不用太关注,是京东存储元数据的key,符合范式即可;
第三,后面跟的update_time ORDER BY,这个有点意思,以上面那个表举例,就是在用final查询 或者 Optimize手工合并时,用ORDER BY中的dept_id_3, saler, pur_controller作为唯一业务主键,用update_time排序,保留最后一条
第四,当前建表方式属于维表模式,维表模式简单说就是每个节点存储一份全量数据。对于维表,如果使用分布式表使用join会有remote查询,节点之间的通讯会增加sql耗时。后面说为什么选择使用维表模式。
2.Clickhouse本地join
今天我们主要说一说本地Join,为什么主要说它呢,第一因为它好,第二因为这次我用了😋
本地join的优势
在Clickhouse中,与本地join对应的是Global Join,就拿最简单的两表join来说,Clickhouse的执行流程是:左表,先在每个分布式节点查一次,然后将查询结果远程传输到聚合节点上,右表,也是先在每个分布式节点查一次,然后将查询结果远程传输到聚合节点上,再在聚合节点上join两份结果,最终输出;本地join是在每个分布式节点上进行join,然后将每个节点的join结果远程传输到聚合节点上,合并结果最终输出;两者对比,本地join的性能和资源开销都远超Global Join。
本地join对于数据散列方式的要求
如果是两张分布式表,那就要保证分布函数要完全一致,举个例子,我们平时建分布式表的语句如下:
-- 分布式表
CREATE TABLE IF NOT EXISTS sop_pre_mix.history ON CLUSTER xx AS sop_pre_mix.history_local ENGINE = Distributed
(
'xx',
'sop_pre_mix',
'history_local',
rand()
) ;分布函数就是这个rand(),如果想要对两个分布式表使用本地join,就要保证这个分布函数对于维度相同的数据,算出来完全一致的结果,rand()肯定是不能用,可以参考一致性hash算法。
我们本次使用的场景,左表是一个分布式表,是纯散列的,右表我建成了维表,维表上面我们也写了它的形式,每个节点存储一份全量数据,刚好命中可以使用本地join的场景。
查询语法的要求
另外,本地join对于sql语法上也有要求,我就踩了一下语法的这个坑
在京东Clickhouse运维文档里摘录了一下精华,本地 Join是用 a.dis join b.local,对于左表a(分布式表)的过滤条件需要写成 select * from a.dis join b.local where a.cond1(千万不能写成子查询的 如 select * from (select * from a.dis where a.cond1 )join b.local ),这样没法正确的执行本地join,使得查询结果不正确,对于b 本地表的过滤条件则需要放到子查询中,那么正确的样式应该是select * froma.dis join (select * from b.local where b.cond2) where a.cond1.
语法踩坑:低版本引擎的Clickhouse,本地join时,维表需要带库名前缀,不然执行算子会报找不到表的错误,对应下面sql片段【sop_pre_mix.sop_sale_plan_rule_core_dim】,这里必须写上sop_pre_mix
展示一下本地join的最终呈现
左表的建表语句(分布式表模式),数据量约2.9亿
CREATE TABLE IF NOT EXISTS sop_prod_mix.sop_sale_history_week_local ON CLUSTER xx
(
dept_id_1 Int32 COMMENT '一级部门id',
dept_name_1 String COMMENT '一级部门名称',
……一堆维度指标字段,略
sale_amount_lunar_sp Decimal(20, 2) COMMENT '同期自营销售出库金额',
dt String COMMENT '数据日期'
)
ENGINE = ReplicatedMergeTree
(
'/clickhouse/LFRH_CK_Pub_115/jdob_ha/sop_prod_mix/sop_sale_history_week_local/{shard}',
'{replica}'
)
PARTITION BY dt
ORDER BY (dept_id_1,dept_id_2,dept_id_3,saler,pur_controller,cate_id_3,ym,ymw)
SETTINGS storage_policy = 'jdob_ha',
index_granularity = 8192;
-- 分布式表
CREATE TABLE IF NOT EXISTS sop_prod_mix.sop_sale_history_week ON CLUSTER xx AS sop_prod_mix.sop_sale_history_week_local ENGINE = Distributed
(
'xx',
'sop_prod_mix',
'sop_sale_history_week_local',
rand()
) ;右表的建表语句(维表模式),数据量约4500+条
CREATE TABLE IF NOT EXISTS sop_pre_mix.sop_dim_blacklist ON CLUSTER xx
(
`dept_id_1` Int32 COMMENT '一级部门ID',
`dept_id_2` Int32 COMMENT '二级部门ID',
`dept_id_3` Int32 COMMENT '三级部门ID',
`saler` String COMMENT '销售erp',
`pur_controller` String COMMENT '采控erp',
`update_time` DateTime COMMENT '更新时间',
`is_deleted` UInt8 COMMENT '有效标识 0:标识未删除 1:表示已删除'
)
ENGINE = ReplicatedReplacingMergeTree('/clickhouse/xx/jdob_ha/sop_pre_mix/sop_dim_blacklist/{shard_dict}', '{replica_dict}', update_time)
ORDER BY (dept_id_3, saler, pur_controller)
SETTINGS storage_policy ='jdob_ha';命中本地join的查询sql
此sql只是动态sql生成的其中一种,实际项目中动态场景很多,主要依赖mybatis动态sql实现
SELECT
a.ymw AS ymw,
a.dept_id_2 AS dept_id_2,
a.dept_id_3 AS dept_id_3,
a.week AS week,
a.cold_type AS cold_type,
a.year AS YEAR,
a.net_type AS net_type,
a.saler AS saler,
a.pur_controller AS pur_controller,
a.dept_id_1 AS dept_id_1,
a.month AS MONTH,
a.ym AS ym,
CASE
WHEN a.dept_id_1 != c.dept_id_1
OR c.dept_id_1 IS NULL
THEN - 100
ELSE c.core_dim_id
END AS core_dim_id,
CASE
WHEN a.dept_id_1 != c.dept_id_1
OR c.dept_id_1 IS NULL
THEN - 100
ELSE c.core_dim_id
END AS brand_id,
SUM(initial_inv_amount) AS initial_inv_amount,
……一堆指标,略
SUM(gmv_lunar_sp) AS gmvLunarSp
FROM
sop_pur_history_week a
LEFT JOIN
(
SELECT
dept_id_2,
dept_id_3,
pur_controller,
saler
FROM
sop_pre_mix.sop_dim_blacklist final
WHERE
is_deleted = 0
AND dept_id_3 IN(12345, 23456,……)
)
b
ON
a.dept_id_3 = b.dept_id_3
AND a.pur_controller = b.pur_controller
AND a.saler = b.saler
LEFT JOIN
(
SELECT
dept_id_1,
dept_id_2,
dept_id_3,
pur_controller,
saler,
core_dim_id
FROM
sop_pre_mix.sop_sale_plan_rule_core_dim final
WHERE
is_deleted = 0
AND dept_id_3 IN(12345, 23456,……)
AND core_dim_id IN(12310)
AND plan_dim = 'brand'
)
c
ON
a.dept_id_1 = c.dept_id_1
AND a.dept_id_2 = c.dept_id_2
AND a.dept_id_3 = c.dept_id_3
AND a.saler = c.saler
AND a.pur_controller = c.pur_controller
AND a.brand_id = c.core_dim_id
WHERE
dt = '2023-12-16'
AND a.dept_id_3 IN(12345, 23456,……)
AND a.brand_id IN(12310)
AND
(
a.dept_id_3 != b.dept_id_3
OR b.dept_id_3 IS NULL
)
GROUP BY
a.ymw,
a.dept_id_2,
a.dept_id_3,
a.week,
a.cold_type,
a.year,
a.net_type,
a.saler,
a.pur_controller,
a.dept_id_1,
a.month,
a.ym,
c.dept_id_1,
core_dim_id
走本地join和不走本地join对资源开销的差别

很明显能看到走本地join的查询行数和内存占用是小了很多的,我们测试用的这个集群是9分片18节点的,就节约了一倍多的资源……分片越多效果越明显
3.Tidb到Clickhouse准实时同步链路
这部分见我另外一篇神灯文章,TiCDC接入JDQ实践: http://sd.jd.com/article/41284?shareId=54243&isHideShareButton=1
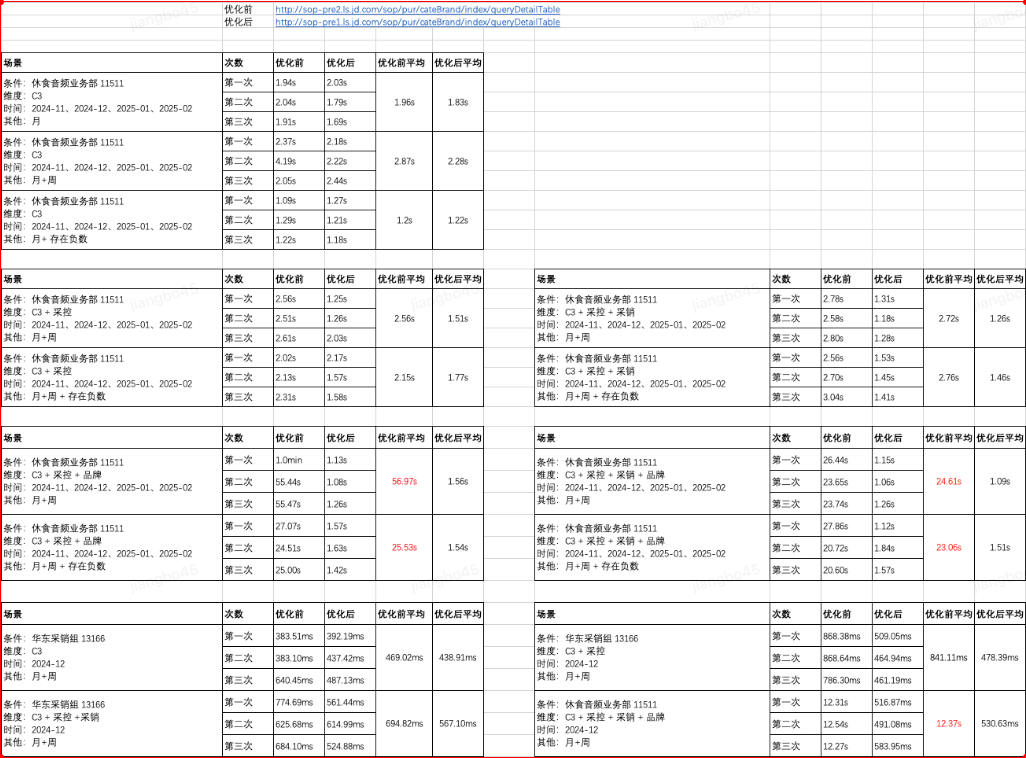
最终优化效果
首先,解决了常规查询情况下实例经常OOM的问题;
其次,对于查询性能也有了稳定的提升
下面是我在测试环境对比的一些实验数据:(线上实际性能比图中都要好)