您好!
欢迎来到京东云开发者社区
登录
首页
博文
课程
大赛
工具
用户中心
开源
首页
博文
课程
大赛
工具
开源
更多
用户中心
开发者社区
>
博文
>
由 Mybatis 源码畅谈软件设计(九):“能用就行” 其实远远不够
分享
打开微信扫码分享
点击前往QQ分享
点击前往微博分享
点击复制链接
由 Mybatis 源码畅谈软件设计(九):“能用就行” 其实远远不够
wy****
2024-12-30
IP归属:北京
967浏览
到本节 Mybatis 源码中核心逻辑基本已经介绍完了,在这里我想借助 Mybatis 其他部分源码来介绍一些我认为在编程中能 **最快提高编码质量的小方法**,它们可能比较细碎,希望能对大家有所启发。 ### 关于方法的长度和方法拆分 之前我在读完《代码整洁之道》时,非常痴迷于写小方法这件事,它强调“每个方法只做一件事,方法的长度不能超过 5 行”等观点。 记得某次代码评审时,有同事对将一个大方法拆分成多个小方法提出了异议:拆分出的小方法不能算作做了一件事,它们都只是大方法中的一个“动作”而已,所以不应该拆分巴拉巴拉。 这个观点让我说不出什么,后来我也在想:如果按照这个观点,多大的方法都可以概括成只做了一件事,那么我们就需要将所有的逻辑都“摊”到一个方法中吗?我觉得拆分方法目的不是在界定一件事还是一个动作上,而是 **关注方法的可读性**,拆分方法太多确实让代码变得不好读,需要辗转在多个方法之间,但是不拆的可读性也会差,所以接下来我想根据 Mybatis 这段代码来简单谈谈我对写方法的观点: ```java public class XMLConfigBuilder extends BaseBuilder { private void parseConfiguration(XNode root) { try { propertiesElement(root.evalNode("properties")); Properties settings = settingsAsProperties(root.evalNode("settings")); loadCustomVfsImpl(settings); loadCustomLogImpl(settings); typeAliasesElement(root.evalNode("typeAliases")); pluginsElement(root.evalNode("plugins")); objectFactoryElement(root.evalNode("objectFactory")); objectWrapperFactoryElement(root.evalNode("objectWrapperFactory")); reflectorFactoryElement(root.evalNode("reflectorFactory")); settingsElement(settings); environmentsElement(root.evalNode("environments")); databaseIdProviderElement(root.evalNode("databaseIdProvider")); typeHandlersElement(root.evalNode("typeHandlers")); mappersElement(root.evalNode("mappers")); } catch (Exception e) { throw new BuilderException("Error parsing SQL Mapper Configuration. Cause: " + e, e); } } } ``` 如上是 Mybatis 解析配置文件中各个标签的方法,它将每个标签的解析都单独定义出了一个方法,这也是我一直遵循的写方法的观点:**最顶层的入口方法应该是短小清晰的步骤**,在主方法中编排好方法的执行内容,这样主方法便是清晰明了的执行流程,我们便能一眼清晰的知道该方法做了什么事情,而针对各个具体的环节或者要改动哪些逻辑,直接跳转到对应的方法即可。 至于该不该将某段逻辑抽象成一个方法,我的观点是 **能不能一眼看明白这段逻辑在干什么,如果不能,那么就应该被抽象到一个方法中,否则将其保留在原方法中也是没有问题的**,**对方法的抽象从来都不在于方法的长度**,**可读性** 应得到更多的关注。 此外,还有一个能提高代码可读性的方法是:**“合理使用换行符”**,如下代码所示: ```java public class Configuration { // ... public Configuration() { typeAliasRegistry.registerAlias("JDBC", JdbcTransactionFactory.class); typeAliasRegistry.registerAlias("MANAGED", ManagedTransactionFactory.class); typeAliasRegistry.registerAlias("JNDI", JndiDataSourceFactory.class); typeAliasRegistry.registerAlias("POOLED", PooledDataSourceFactory.class); typeAliasRegistry.registerAlias("UNPOOLED", UnpooledDataSourceFactory.class); typeAliasRegistry.registerAlias("PERPETUAL", PerpetualCache.class); typeAliasRegistry.registerAlias("FIFO", FifoCache.class); typeAliasRegistry.registerAlias("LRU", LruCache.class); typeAliasRegistry.registerAlias("SOFT", SoftCache.class); typeAliasRegistry.registerAlias("WEAK", WeakCache.class); typeAliasRegistry.registerAlias("DB_VENDOR", VendorDatabaseIdProvider.class); typeAliasRegistry.registerAlias("XML", XMLLanguageDriver.class); typeAliasRegistry.registerAlias("RAW", RawLanguageDriver.class); typeAliasRegistry.registerAlias("SLF4J", Slf4jImpl.class); typeAliasRegistry.registerAlias("COMMONS_LOGGING", JakartaCommonsLoggingImpl.class); typeAliasRegistry.registerAlias("LOG4J", Log4jImpl.class); typeAliasRegistry.registerAlias("LOG4J2", Log4j2Impl.class); typeAliasRegistry.registerAlias("JDK_LOGGING", Jdk14LoggingImpl.class); typeAliasRegistry.registerAlias("STDOUT_LOGGING", StdOutImpl.class); typeAliasRegistry.registerAlias("NO_LOGGING", NoLoggingImpl.class); typeAliasRegistry.registerAlias("CGLIB", CglibProxyFactory.class); typeAliasRegistry.registerAlias("JAVASSIST", JavassistProxyFactory.class); languageRegistry.setDefaultDriverClass(XMLLanguageDriver.class); languageRegistry.register(RawLanguageDriver.class); } } ``` 在 `Configuration` 的构造方法中,进行注册别名操作时使用了换行符进行分割,它将 `TransactionFactory` 相关的紧挨在一起作为一组,再将 `DataSourceFactory` 相关的紧挨在一起等等,这样在分门别类查看这段代码便是清晰的,即使它们都在一个方法中。 ### 方法的编排 在《代码整洁之道》中提出了代码中 **方法要从上到下排列,读方法就像读报纸一样**,因为方法被抽象提炼出来,阅读时必然会造成在多个方法间切换的问题,那么如果我们将方法从上到下依次排列,能够在屏幕中同时看到所有相关方法的话,那么这样的确方便了阅读,比如 `methodA` 依赖 `commonMethod` 方法的排列: ```java @Override public void methodA() { commonMethod(); } private void commonMethod() { // ... } ``` 此时如果增加 `methodB()` 也要复用 `commonMethod()` 的话,那么我并不会像下面这样排列方法: ```java @Override public void methodA() { commonMethod(); } private void commonMethod() { // ... } @Override public void methodB() { commonMethod(); } ``` 因为我们在看一个方法时,始终要坚持 **自上往下读** 的原则,不能在看 `methodB()` 的时候,再跳回到上面去,而是需要像这样: ```java @Override public void methodA() { commonMethod(); } @Override public void methodB() { commonMethod(); } private void commonMethod() { // ... } ``` 那么这也就意味着:如果 **某个方法被复用的次数过多,它的位置则越靠近类的下方**。在《软件设计哲学》中也提到过 **专用方法上移,通用方法下移** 的观点,这也是在提醒开发者,当看见某个私有方法在类的尾部时,它可能是一个非常通用的方法,对它的修改就需要特别谨慎。 ### 方法的声明 在业务代码中经常会看到接口中某方法声明抛出异常: ```java public interface Demo { void method(Object parameter) throws Exception; } ``` 但是对要抛出的异常类型并没有明确的声明,只知道会抛出 `Exception`,对于具体的原因一无所知。如果想清楚的了解,可以借助注释(如果有的话),否则就需要去探究它的具体实现,这对想直接调用该方法的研发人员来说非常不友好,增加了 **“认知负荷”**,那该怎么办呢? 《图解Java多线程设计模式》中提到过一个例子非常有启发性,它说方法签名中标记 `throws InterruptedException` 能表示两种含义:第一种比较容易被想到,表示该方法可以被打断/取消;第二种含义是,**这个方法耗时可能比较长**。 比如 `Thread.join()` 方法,它声明了 `throws InterruptedException`,它的作用是让当前执行的线程暂停运行,直到调用 `join()` 方法的线程执行完毕。当我们在一个线程实例上调用 `join()` 方法时,当前执行的线程将被阻塞,阻塞时间可能会很长,如果在阻塞期间如果另一个线程中断(`interrupt`)了它,那么它将抛出一个 `InterruptedException`。所以,我们能够在 `throws` 声明中,获取某方法关于某异常的信息。 在 Mybatis 源码中也有类似的例子,如下: ```java public interface Executor { int update(MappedStatement ms, Object parameter) throws SQLException; } ``` 它声明出 `throws SQLException` 表示 SQL 执行的异常,它被抛出了我们便能知道是 SQL 写的有问题。我认为直接将方法上声明 `throws Exception` 的签名并不添加任何注释是一种懒惰。异常精细化能给我们带来很多好处,比如日常报警容易看,增加方法可读性,能够通过声明知道这个方法会抛出关于什么类型的异常,便能让接口的调用者判断是处理异常还是抛出异常。 方法的参数声明也很重要,我认为在业务代码中除了要遵循方法入参不要过多以外,还需要遵循 **随着重要程度向后排序** 的原则,以 Mybatis 中如下方法为反例: ```java public class DefaultResultSetHandler implements ResultSetHandler { // ... private final Map<String, Object> ancestorObjects = new HashMap<>(); private void putAncestor(Object resultObject, String resultMapId) { ancestorObjects.put(resultMapId, resultObject); } } ``` 向缓存中添加元素的方法 `putAncestor` 将入参 `String resultMapId` 放在第一位更合适。 ### 关于代码自解释 每次提到命名或者在为接口命名时,之前我都会有一种非常强烈的让它自解释的想法,但是随着对软件开发理解的变化,这种想法的欲望在逐渐降低,原因有二: 1. **阅读习惯**:对国人来说,可能大多数人没有先去读英文的习惯,更倾向于读中文相关的内容,比如注释 2. **英语水平参差**:可能有时候想要自解释的初心是好的,但是如果使接口名变成了长难句,可读性将降低 当然,花时间来好好为变量和方法命名,是非常值得的,它能大大的提高可读性,最好的情况是:当读者看到它时,就已经基本领会了它的作用。尽可能的让它们明确、直观且不太长。如果很难为变量或方法找到一个简单的名称,这可能暗示底层对象的设计不够简洁,《软件设计哲学》提出了一种观点:考虑 **拆分成多个分别定义** 或者为其 **添加上必要的注释**。此外,我觉得命名保持一致性也非常重要,比如在项目中对于补购已经命名为 `AddBuy`,那么便不要再引入 `SupplementaryPurchase` 和 `Replenishment` 等命名,团队内成员将知识统一才是最好的,并不在于它在英文语境下是否表达准确。 但是,Mybatis 为什么能够在很少注释的情况下又保证了它的源码自解释呢?而且在《代码整洁之道》中也持有对注释的消极观点: > ... 注释最多只能算是一种不得已而为之的手段。若编程语言有足够的表达力,或者我们长于用这些语言来表达意图,就不那么需要注释——也许根本不需要。 注释的恰当用法是弥补我们在代码中未能表达清楚的内容... 注释总是代表着失败,我们总有不用注释便很难表达代码意图的时候,所以总要有注释,这并不值得庆贺。 因为 Mybatis 中方法做的事情足够简单,像简单的 `query` 和 `doQuery` 方法,或者再复杂一些的 `handleRowValuesForNestedResultMap` 也能知道它是在处理循环引用的结果映射集。而在业务代码中就不太一样了,仅靠几个简短的词语并不能将方法的作用解释清楚,想让它自解释就会导致方法名写的很长,而且多数情况下,研发同事并不愿意花精力去翻译那冗长又蹩脚的方法名,给人更多的感受是:“这写的都是什么?”。如果想在业务代码中保证“代码自解释”的话,还是需要认真的去写注释。因为业务功能相对复杂,而方法名本身所能表现的东西又非常有限,通常并不能仅通过方法名来表达其含义,注释能够在此处为方法表达带来增益。但因此认为注释是弥补方法名表达能力欠佳的补丁,就有些偏颇了,因为随着注释写的越来越多,你会发现:**注释其实是代码的一部分**,它不光提供代码之外的重要信息,还能隐藏复杂性,提高抽象程度,这还反映了开发者对代码的设计和重视,随着时间的推移,有新的开发者加入时,也能让他快速理解代码,降低出现 Bug 的概率。 不过,也有一些命名方法能够帮我们提高方法的可读性,比如 `instantiateXxx` 表示创建某对象,`initialXxx` 表示为某对象中字段赋值。 还有一点值得学习,Mybatis 源码中会在目录下创建 `package-info.java` 来注释包路径,以 `src/main/java/org/apache/ibatis/cache/decorators/package-info.java` 为例,它注释了该目录都是缓存的装饰器: ```java /** * Contains cache decorators. */ package org.apache.ibatis.cache.decorators; ``` 这样我们就能够知道该路径下的定义是与什么有关了。不过,这会使得该文件夹杂在各个类之中,如果能在命名前加上 `a-` 成为 `a-package-info.java` 被置于顶部的话,会更整洁一些: 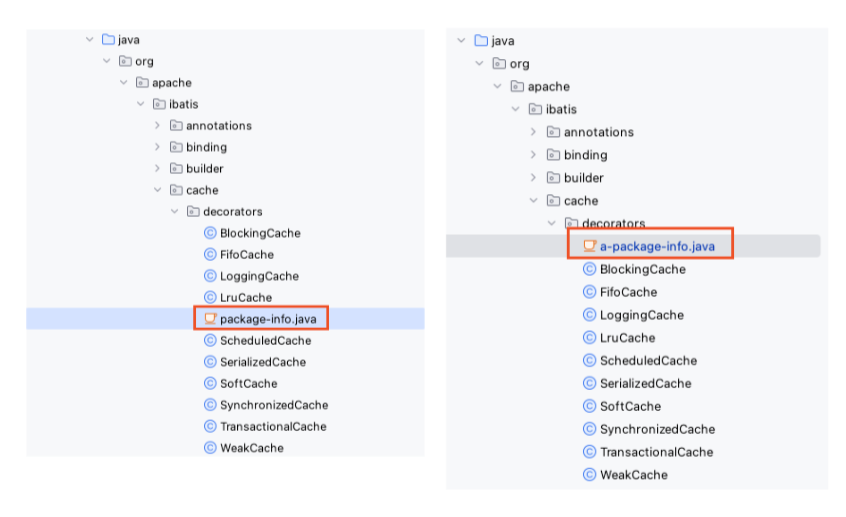 ### “能用就行” 其实远远不够 “代码整洁与否不是一件主观的事情,这需要始终站在阅读者的角度考虑”是学习软件设计带给我最大的启发,“该如何设计能让开发者更轻松得读懂”也成了在写代码时常常考虑的问题。《软件设计哲学》中提到过“永远不要反驳他人对代码可读性的评价”的观点也正是在强调这些。 到现在回看本专栏,发现真正的讲好设计原则和代码的写法并不是一件很容易的事情,因为我不想只讲理论,而想结合实践又需要结合大部分 Mybatis 源码,所以它们在内容上,源码介绍会占得更多一些,当然这也是我觉得稍有遗憾的点,如果这都能给大家带来一些启发的话,实在感激涕零。 虽然本专栏始终围绕着如何将代码写得更整洁和优雅做讨论,但是我们还是需要学会“负重前行”:**和凌乱的代码相处**。一些凌乱的代码可能写过一次后便不再变更,所以有时候没有必要为了优雅强迫症而去重构它们,它们可能始终会被隐藏在某个方法后面,默默地提供着稳定的功能,如果你深受其扰,可以考虑在你读过之后为这段代码添加注释,之后看这段代码的开发者也能理解和感谢你的用心,否则因为优雅的重构导致线上生产事故,可就得不偿失了。 实际上,能写好代码对于程序员来说并不是一件特别厉害的事情,它只能算是一项基本要求,而且随着 AI 的不断发展,它在未来可能会帮我们生成很好的设计。当然,这也不是放任的理由,写烂代码的行为还是需要被摒弃的。在最后我想借先前读过的雷军的博客《我十年的程序员生涯》的节选来结束本专栏: > 有的人学习编程技术,是把高级程序员做为追求的目标,甚至是终身的奋斗目标。后来参与了真正的商品化软件开发后,反而困惑了,茫然了。 > > 一个人只要有韧性和灵性,有机会接触并学习电脑的编程技术,就会成为一个不错的程序员。刚开始写程序,这时候学得多的人写的好,到了后来,大家都上了一个层次,谁写的好只取决于这个人是否细心、有韧性、有灵性。掌握多一点或少一点,很快就能补上。成为一个高级程序员并不是件困难的事。 > > 当我上学的时候,高级程序员也曾是我的目标,我希望我的技术能得到别人的承认。后来发现无论多么高级的程序员都没用,**关键是你是否能够出想法出产品**,你的劳动是否能被社会承认,能为社会创造财富。**成为高级程序员绝对不是追求的目标**。 **希望大家不仅能写出好代码,还能做出属于自己的产品,为生活乃至世界添一份彩。**
上一篇:业务监控—一站式搭建jmeter+telegraf+influxdb+Grafana看板
下一篇:京东供应链创新与实践:应用数据驱动的库存选品和调拨算法提升履约效率
wy****
文章数
47
阅读量
42711
作者其他文章
01
用“分区”来面对超大数据集和超大吞吐量
1. 为什么要分区?分区(partitions) 也被称为 分片(sharding),通常采用对数据进行分区的方式来增加系统的 可伸缩性,以此来面对非常大的数据集或非常高的吞吐量,避免出现热点。分区通常和复制结合使用,使得每个分区的副本存储在多个节点上,保证数据副本的 高可用。如下图所示,如果数据库被分区,每个分区都有一个主库。不同分区的主库可能在不同的节点上,每个节点可能是某些分区的主库,同时是
01
深入理解分布式共识算法 Raft
“不可靠的网络”、“不稳定的时钟”和“节点的故障”都是在分布式系统中常见的问题,在文章开始前,我们先来看一下:如果在分布式系统中网络不可靠会发生什么样的问题。有以下 3 个服务构成的分布式集群,并在 server_1 中发生写请求变更 A = 1,“正常情况下” server_1 将 A 值同步给 server_2 和 server_3,保证集群的数据一致性:但是如果在数据变更时发生网络问题(延迟
01
缓存之美:从根上理解 ConcurrentHashMap
本文将详细介绍 ConcurrentHashMap 构造方法、添加值方法和扩容操作等源码实现。ConcurrentHashMap 是线程安全的哈希表,此哈希表的设计主要目的是在最小化更新操作对哈希表的占用,以保持并发可读性,次要目的是保持空间消耗与 HashMap 相同或更好,并支持利用多线程在空表上高效地插入初始值。在 Java 8 及之后的版本,使用 CAS 操作、 synchronized
01
缓存之美:万文详解 Caffeine 实现原理(上)
由于神灯社区最大字数限制,本文章将分为两篇,第二篇文章为缓存之美:万文详解 Caffeine 实现原理(下)文章将采用“总-分-总”的结构对配置固定大小元素驱逐策略的 Caffeine 缓存进行介绍,首先会讲解它的实现原理,在大家对它有一个概念之后再深入具体源码的细节之中,理解它的设计理念,从中能学习到用于统计元素访问频率的 Count-Min Sketch 数据结构、理解内存屏障和如何避免缓存伪
wy****
文章数
47
阅读量
42711
作者其他文章
01
用“分区”来面对超大数据集和超大吞吐量
01
深入理解分布式共识算法 Raft
01
缓存之美:从根上理解 ConcurrentHashMap
01
缓存之美:万文详解 Caffeine 实现原理(上)
添加企业微信
获取1V1专业服务
扫码关注
京东云开发者公众号




 wy****
wy**** 2024-12-30
2024-12-30 967浏览
967浏览






