




CIKM 2024: MODRL-TA:A Multi-Objective Deep Reinforcement Learning Framework for Traffic Allocation in E-Commerce Search
链接: https://dl.acm.org/doi/10.1145/3627673.3679964
摘要:流量调控是通过调整商品在搜索后阶段的位置来重新分配自然流量的过程,旨在有效促进商家增长、精确满足客户需求,并确保电商平台上各方利益的最大化。现有的排序学习方法忽视了流量分配的长期价值,而强化学习方法则难以在真实数据环境中平衡多个目标和解决冷启动问题。为了解决这些问题,本文提出了一种多目标深度强化学习框架,包括多目标Q学习(MOQ)、基于交叉熵方法的决策融合算法(DFM)以及渐进数据增强系统(PDA)。具体来说,MOQ构建了多个强化学习模型,每个模型专注于一个目标,如点击率、转化率等。这些模型分别决定商品的位置,旨在从个体角度估计多个目标的长期价值。然后,我们使用DFM动态调整各目标之间的权重,以最大化长期价值,解决电商场景中目标偏好的时间动态变化。最初,PDA使用离线日志中的模拟数据训练MOQ。随着实验的进行,它策略性地整合了真实用户交互数据,最终替换模拟数据集,以缓解分布变化和冷启动问题。在京东主搜上的实验结果显示,MODRL-TA显著提升了性能,并已成功部署。
1、背景/现状介绍
在现代电商平台中,流量调控系统是一个至关重要的组成部分。流量调控是搜索排序后链路中的关键环节,通过调整商品在搜索结果中的展示位置,将自然流量重新分配给各个商品。其目的是有效促进商家增长,精准满足客户需求,并确保平台上各方利益的最大化。在京东零售这样的电商平台上,搜索领域是最大的流量场域,承担着提升自然流量可运营能力的重要任务。如何通过有效的流量调控系统来增强商家对自然流量的运营能力,成为平台和商家共同关注的焦点。

2、挑战与困难
现有的启发式方法可以用于实现流量分配。然而,这些启发式方法仅关注单个商品的收益,忽视了一个商品的分配策略变化可能会影响其他商品的最优策略这一现实。因此,许多研究致力于开发基于强化学习的技术,这些技术可以在与消费者的互动中不断更新其广告策略,并通过最大化预期的长期累积收益来制定最优策略。
然而,大多数现有研究专注于最大化单一商品的效用,而忽略了商品和商家的多重效用,如转化率、点击率或加购率。多目标强化学习方法可以通过多重奖励塑造或集成学习在多个目标之间取得平衡,但它们的最优策略相对静态。具体来说,商家的业务目标会随着时间动态变化。例如,对于新加入平台的商家,用户点击实际上比订单更重要(以培养吸引用户浏览的思维),但经过一段时间后,商家会更加关注订单和GMV。多目标强化学习强调寻找静态的帕累托最优解,而在我们的场景中,需要实时动态调整目标权重。此外,上述强化学习方法在在线部署初期由于真实数据稀疏而面临冷启动问题。
3、解决方案 MODRL-TA
为了应对现有方法的不足,本文提出了一种多目标深度强化学习框架MODRL-TA。该框架由多目标Q学习(MOQ)、基于交叉熵方法的决策融合算法(DFM)和渐进数据增强系统(PDA)组成。具体来说,MOQ通过构建集成强化学习模型,每个模型专注于一个目标(如点击率、转化率等),从个体角度估计多个目标的长期价值。
随后,DFM通过动态调整目标之间的权重来最大化长期价值,解决电商场景中目标偏好随时间变化的问题。PDA最初使用离线日志中的模拟数据训练MOQ,随着实验的进行,逐步整合真实用户交互数据,最终取代模拟数据集,以缓解分布偏移和冷启动问题。
接下来,将从多目标Q学习(MOQ)、基于交叉熵方法的决策融合算法(DFM)和渐进数据增强系统(PDA)三个部分来介绍MODRL-TA多目标深度强化学习框架。
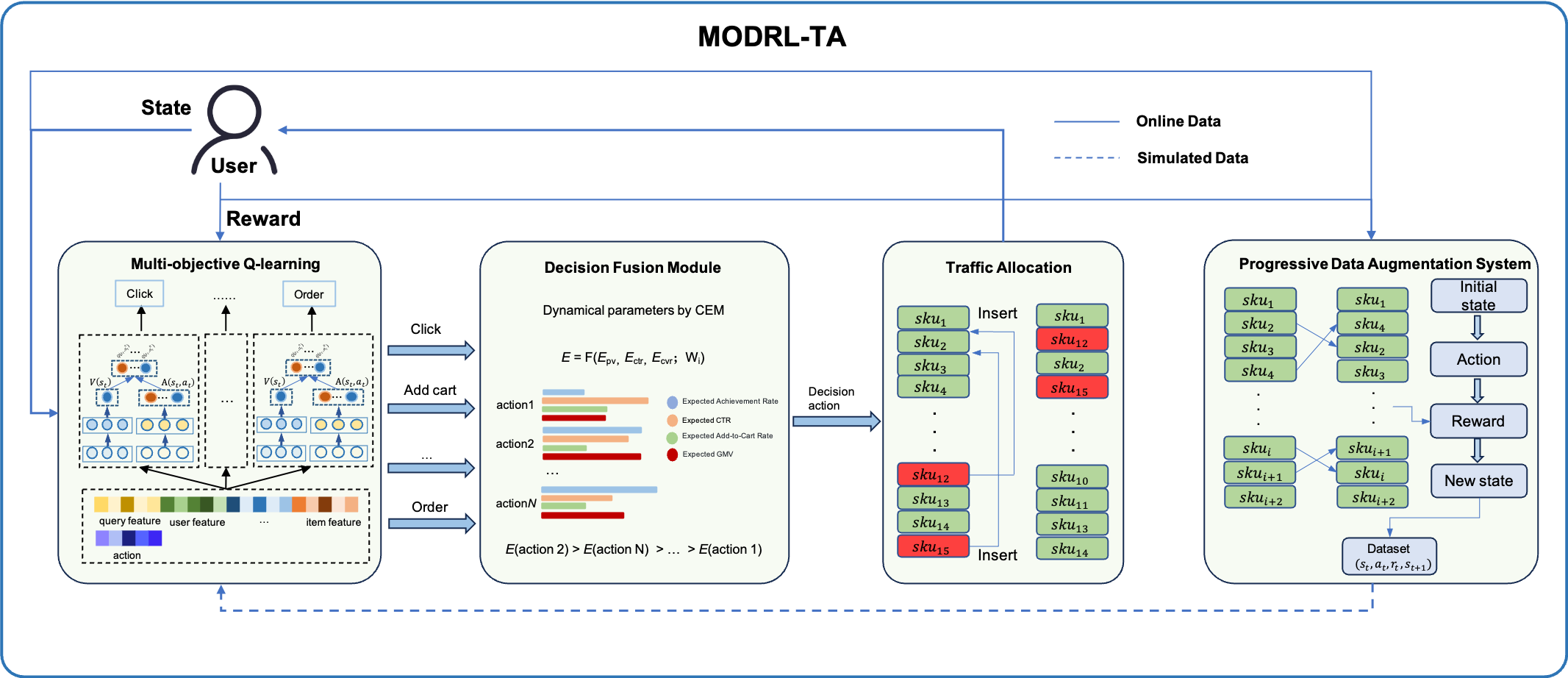
3.1 多目标Q学习(MOQ)
为了解决这些问题,我们提出了多目标Q-Learning(MOQ),即使用多个独立的RL模型而不是传统的MORL。传统MORL方法通常寻找一个静态的帕累托最优解,但我们的场景需要实时动态调整目标权重。独立的RL模型不仅满足了动态权重调整的需求,还具有良好的可扩展性。当商家提出新的目标需求时,只需针对该新目标训练一个新模型即可,无需对现有模型进行重新训练,从而显著提高了训练效率。
MOQ的核心在于其能够同时处理多个优化目标,例如提升用户满意度、增加商家销售额和优化平台收益等。在实际应用中,MOQ通过对历史数据的学习,能够动态调整策略,以适应不断变化的市场环境和用户需求。这种灵活性使得MOQ在电商平台的流量调控中具有显著的优势。
模型选择
我们选择经典的Deep Q-Network(DQN)作为MODRL-TA的基础RL模型。DQN能够有效处理高维状态空间,并具有良好的扩展性和稳定性。
状态与动作
在我们的强化学习模型中,状态主要包括以下几个部分:
- 用户画像特征:包括性别、年龄段等。
- 查询属性特征:包括意图分类等。
- 用户历史行为特征:包括用户点击过的商品(加入购物车/下单)、商品类别等。
- 上下文特征:包括与商品相关的特征。
- 用户新商品历史行为特征:包括用户点击过的新产品等。
- 总反馈特征:用于控制目标的特征。这些特征包括用户和查询的固定属性特征、通过建模用户历史行为获得的用户序列偏好特征,以及当前请求下展示的商品列表特征。
这些特征的组合使得RL模型能够整合来自用户、查询和商品的信息,从而在请求级别实现个性化建模。对于动作空间,是用于插入所选商品的位置(给定一个包含L个商品的列表)。
Reward设计
由于我们使用多目标强化学习,我们利用多个强化学习模型,每个模型控制一个特定的目标。在本文中,我们讨论了优化目标的策略,以点击和订单为例。具体来说,模型A专注于提高点击率,而模型B则专注于增加订单数量。这些强化学习模型之间的区别在于它们的Reward设计。对于控制点击的模型A,当用户点击特定商品时,我们将状态的Reward设为1,如果没有点击则设为-1。控制订单的模型的Reward设计类似:
训练任务
深度Q网络,即第i个RL模型的动作价值函数,可以通过最小化一系列损失函数来优化:
其中,目标为当前迭代的目标:
我们引入了独立的评估网络和目标网络来帮助平滑学习过程并避免参数的发散,其中表示评估网络的所有参数,而目标网络的参数在优化损失函数时是固定的。
损失函数对参数的导数为:
在本文中,所有RL模型共享输入,并共同更新输入层的参数,而其余参数则独立更新,这使得模型在学习过程中能够共享知识。总损失为:
这种设计使得我们能够有效地同时优化多个目标,并在新增目标时快速适应。
3.2 基于交叉熵方法的决策融合算法(DFM)
在对不同目标的长期期望进行建模后,下一步是考虑如何平衡这些目标,以满足商家动态变化的需求。决策融合模块(DFM)采用交叉熵法(CEM)作为平衡策略。CEM是一种进化算法,擅长在复杂的高维空间中优化参数。由于其简单性和适应性,CEM非常适合用于各种优化问题。在电子商务中,CEM能够有效处理动态流量和即时反馈调整,能够快速根据商家的反馈调整参数,并通过初始交互克服新产品或用户的冷启动问题。CEM的主要思想是维护一个潜在最优解的分布,然后根据样本和从黑箱查询得到的样本值来更新该分布。
为了应对电子商务中的多目标任务,我们提出了一种增益融合方法,该方法线性组合了不同目标的增益。类似于第3.1节,我们以点击和订单的优化目标为例。具体来说,我们定义了组合增益函数为:
其中,表示控制点击的模型的Q值,表示控制订单的模型的Q值。权重和是可调参数,用于根据业务优先级平衡点击和订单的重要性。此外,这些权重会受到的性能指标的影响。例如,ROC曲线下面积(AUC)可以用作不同任务的性能指标:
我们的目标是在参数迭代过程中最大化目标任务的AUC,以实现最佳性能。该方法使我们能够动态调整和优化不同目标之间的权衡,确保系统能够响应商家需求和市场条件的变化。
3.3 渐进数据增强系统(PDA)
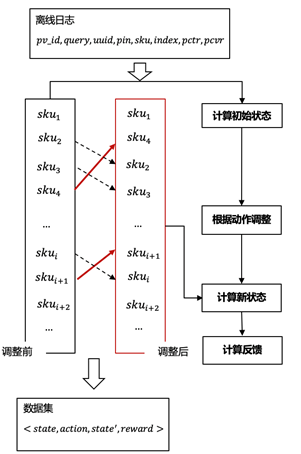
在系统冷启动阶段,由于没有可用于强化学习模型训练的在线真实数据,我们设计了一个渐进的数据增强系统,以获取冷启动阶段的训练数据。具体来说,我们调整候选商品的展示位置,然后计算所有候选商品的位置变化。在调整商品位置后,预测点击率(pCTR)会发生变化。当调整候选商品位置后出现位置冲突时,我们为原本排名较高的商品设置更高的优先级,优先级较低的商品则向后移动。
在使用离线模拟数据获取冷启动训练数据后,训练好的模型会被部署到线上,从而开始积累真实的在线数据。随着真实数据量的增加,我们逐步用真实的在线数据替换离线模型数据。经过一段时间后,真实数据将覆盖训练数据的100%。
4、离在线效果
4.1 离线效果
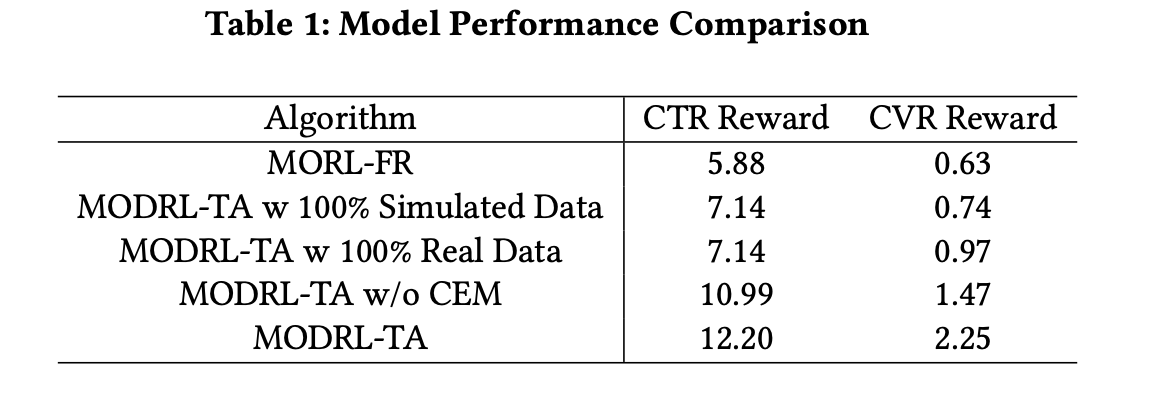
以MORL-FR作为base(CTR Reward:5.88,CVR Reward:0.63),下面展示了通过各种MODRL-TA配置实现的改进。使用100%模拟数据时,MODRL-TA超越了base,显示出其在没有真实数据情况下的有效性。在使用100%真实数据时,CTR Reward 保持不变,但CVR Reward 跃升至0.97,强调了真实数据在提高转化效率方面的价值。
值得注意的是,即使没有使用CEM,MODRL-TA也显著超过了base,表明即便没有CEM,其表现也很强。经过完全优化的MODRL-TA达到了最高结果(CTR Reward:12.20,CVR Reward:2.25),展示了该框架在提升电子商务指标方面的全面有效性。这一进展也突显了深度强化学习在提升数字平台上的参与度和转化率方面的潜力。
4.2 在线效果
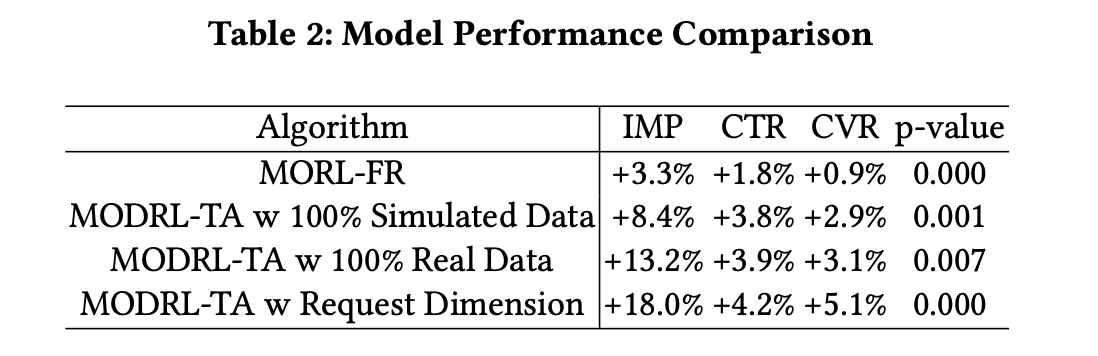
在离线评估中获得收益后,我们进行了为期两周的在线A/B测试。与PID算法相比,特别是在集成请求维度时,MODRL-TA显著提升了性能,展示量(IMP)最多增加18.0%、点击率(CTR)最多增加4.2%、转化率(CVR)最多增加5.1%。这些结果表明,从MORL到MODRL-TA优化的转变,并进一步将真实数据和请求维度纳入学习过程时,各项指标的性能都有显著提升。该模型已经成功部署在线上,为每天约6亿活跃用户服务。
5、未来展望
未来的研究需要更加精细的算法设计和更强大的计算能力,以应对不断变化的市场需求和复杂的业务环境。如何在实际应用中有效地集成多目标学习算法,并在不确定和动态环境中保持算法的稳定性和效率,是未来的重要研究课题。
这些努力将进一步推动电商平台流量调控系统的发展,帮助商家更好地运营自然流量,实现业务目标。未来的流量调控系统可能会更加智能化和自动化,利用大数据和人工智能技术,实现更高效的流量分配和管理。这不仅有助于提升平台的竞争力,也为商家提供了更大的发展空间。通过持续的技术创新和优化,流量调控系统将在电商生态系统中扮演越来越重要的角色。
团队介绍:
京东搜索算法团队,负责京东零售主搜的商品搜索算法,包括意图识别、召回、相关性、排序、机制等技术方向。团队成员来自国内外顶尖高校,我们致力于打造电商搜索一流团队,用前沿的技术驱动业务发展,提升数亿用户的搜索体验,也乐于把实践经验分享给业界,先后在KDD、SIGIR、WWW、EMNLP、ICLR等核心期刊发表论文30余篇。
欢迎有技术情怀、有创新活力的你加入我们,期待与您在京东相遇!简历投递邮箱:org.search.jobs1@jd.com
欢迎内推活水!!! HC需求编码 ZP2412069556
作者介绍:
程鹏 王彗木
京东 算法工程师
程鹏 硕士毕业于北京大学,研究方向为强化学习、大模型,KDD Cup 强化学习挑战赛(RL Track)世界冠军,目前在京东从事主搜排序及流量调控工作。
王彗木博士 中科院自动化所博士,研究方向为大模型、强化学习,亦城优秀人才,CCF 中国计算机学会专业会员,目前在京东从事主搜排序及生成式召排工作。






