您好!
欢迎来到京东云开发者社区
登录
首页
博文
课程
大赛
工具
用户中心
开源
首页
博文
课程
大赛
工具
开源
更多
用户中心
开发者社区
>
博文
>
由 Mybatis 源码畅谈软件设计(三):简单 SQL 执行流程
分享
打开微信扫码分享
点击前往QQ分享
点击前往微博分享
点击复制链接
由 Mybatis 源码畅谈软件设计(三):简单 SQL 执行流程
wy****
2024-12-25
IP归属:北京
1002浏览
SQL 查询是 Mybatis 中的核心流程,本节我们来介绍简单 SQL 的执行流程,过程会比较长,期间会认识很多重要的组件,比如 `SqlSession`、四大处理器(`Executor`、`StatementHandler`、`ParameterHandler` 和 `ResultSetHandler`)等等,大家先有个脸熟,到具体环节时需要重点关注。在这个过程中会遇到很多设计模式,比如 `SqlSession` 使用的 **门面模式**,需要考虑为什么它会使用该模式呢?**模板方法模式** 和 **策略模式** 在这个过程中被使用的尤其的多。此外,在这里能够很好的理解和区分 **代理模式** 和 **装饰器模式** 等等。在设计原则上,**多用组合,少用继承** 的设计原则有很多体现,**单一职责** 更是随处可见,还有关于方法命名的小细节等等都特别值得关注。不过,一定要记得一点:应用再多原则都是在为 **降低复杂性**,提高可读性和可扩展性努力。 验证该过程源码逻辑采用的单测为 `org.apache.ibatis.session.SqlSessionTest.shouldExecuteSelectOneAuthorUsingMapperClass`,如下: ```java @Test void shouldExecuteSelectOneAuthorUsingMapperClass() { try (SqlSession session = sqlMapper.openSession()) { AuthorMapper mapper = session.getMapper(AuthorMapper.class); Author author = mapper.selectAuthor(101); assertEquals(101, author.getId()); } } ``` 开篇我们便能看到 `SqlSession session = sqlMapper.openSession()` 逻辑,那么就以介绍 `SqlSession` 开始吧: ### SqlSession `org.apache.ibatis.session.SqlSession` 采用了 **门面模式**,封装了对数据库的所有操作,包括查询、插入、更新和删除,也对事务进行管理,它是与数据库进行交互的对象,所有执行逻辑都经过该对象去执行: ```java public interface SqlSession extends Closeable { <E> List<E> selectList(String statement); int insert(String statement); int update(String statement); int delete(String statement); void commit(); void rollback(); // ... } ``` `SqlSession` 在 `org.apache.ibatis.session.defaults.DefaultSqlSessionFactory#openSessionFromDataSource` 方法中创建,有如下逻辑: ```java public class DefaultSqlSessionFactory implements SqlSessionFactory { private final Configuration configuration; private SqlSession openSessionFromDataSource(ExecutorType execType, TransactionIsolationLevel level, boolean autoCommit) { Transaction tx = null; try { final Environment environment = configuration.getEnvironment(); // 事务相关 final TransactionFactory transactionFactory = getTransactionFactoryFromEnvironment(environment); tx = transactionFactory.newTransaction(environment.getDataSource(), level, autoCommit); // 创建 Executor final Executor executor = configuration.newExecutor(tx, execType); return new DefaultSqlSession(configuration, executor, autoCommit); } catch (Exception e) { // may have fetched a connection so lets call close() closeTransaction(tx); throw ExceptionFactory.wrapException("Error opening session. Cause: " + e, e); } finally { ErrorContext.instance().reset(); } } // ... } ``` 根据上述源码可知,在 `SqlSession` 的构造方法中组合了 `Configuration` 和 `Executor` 对象,通过调用它组合的对象来完成 SQL 的执行,这遵循了 **多用组合** 的设计原则。这段逻辑中,需要重点关注的是 `Executor` 对象,接下来我们详细介绍一下它。 ### Executor `org.apache.ibatis.executor.Executor` 执行器是 MyBatis 框架中的核心接口,它定义了执行 SQL 语句、管理事务和处理缓存的基本操作。`Executor` 负责管理 SQL 语句的执行(`update` 和 `query` 方法等)、事务的处理(`commit` 和 `rollBack` 方法)以及缓存的维护(一级缓存在 `BaseExecutor` 中,二级缓存由 `CachingExecutor` 负责)等,如下所示: ```java public interface Executor { ResultHandler NO_RESULT_HANDLER = null; // 该方法用于执行更新操作(包括插入、更新和删除),它接受一个 `MappedStatement` 对象和更新参数,并返回受影响的行数 int update(MappedStatement ms, Object parameter) throws SQLException; // 该方法用于执行查询操作,接受 `MappedStatement` 对象(包含 SQL 语句的映射信息)、查询参数、分页信息、结果处理器等,并返回查询结果的列表 <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey cacheKey, BoundSql boundSql) throws SQLException; <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException; <E> Cursor<E> queryCursor(MappedStatement ms, Object parameter, RowBounds rowBounds) throws SQLException; // 该方法用于刷新批处理语句并返回批处理结果 List<BatchResult> flushStatements() throws SQLException; // 该方法用于提交事务,参数 `required` 表示是否必须提交事务 void commit(boolean required) throws SQLException; // 该方法用于回滚事务。参数 `required` 表示是否必须回滚事务 void rollback(boolean required) throws SQLException; // 该方法用于创建缓存键,缓存键用于标识缓存中的唯一查询结果 CacheKey createCacheKey(MappedStatement ms, Object parameterObject, RowBounds rowBounds, BoundSql boundSql); // 该方法用于检查某个查询结果是否已经缓存在本地 boolean isCached(MappedStatement ms, CacheKey key); // 该方法用于清空一级缓存 void clearLocalCache(); // 该方法用于延迟加载属性 void deferLoad(MappedStatement ms, MetaObject resultObject, String property, CacheKey key, Class<?> targetType); // 该方法用于获取当前的事务对象 Transaction getTransaction(); // 该方法用于关闭执行器。参数 `forceRollback` 表示是否在关闭时强制回滚事务 void close(boolean forceRollback); boolean isClosed(); // 该方法用于设置执行器的包装器 void setExecutorWrapper(Executor executor); } ``` `Executor` 在 `org.apache.ibatis.session.Configuration#newExecutor` 方法中被创建: ```java public class Configuration { protected boolean cacheEnabled = true; public Executor newExecutor(Transaction transaction, ExecutorType executorType) { executorType = executorType == null ? defaultExecutorType : executorType; // 创建具体的 Executor 实现类 Executor executor; if (ExecutorType.BATCH == executorType) { executor = new BatchExecutor(this, transaction); } else if (ExecutorType.REUSE == executorType) { executor = new ReuseExecutor(this, transaction); } else { executor = new SimpleExecutor(this, transaction); } // 默认 cacheEnabled 为 true,所以实际创建类型为 CachingExecutor if (cacheEnabled) { executor = new CachingExecutor(executor); } // 插件相关逻辑 return (Executor) interceptorChain.pluginAll(executor); } // ... } ``` 如上所示,MyBatis 提供了多个 `Executor` 的实现类,以支持不同的执行策略和性能优化,灵活地应对不同的性能和资源管理需求,它在定义这些实现类时,使用了 **模板方法模式和策略模式**,在 `BaseExecutor` 定义了方法的模板,子类负责实现其中的逻辑,类图关系如下: 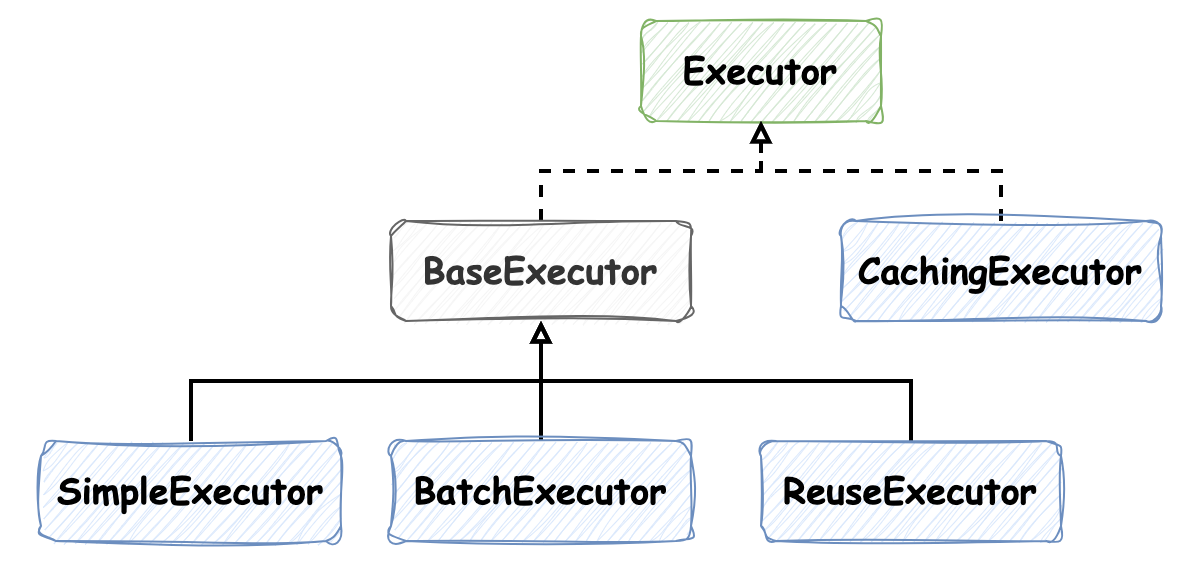 `BaseExecutor` 是所有执行器的基类,它主要用来维护事务对象 `Transaction`、管理一级缓存 `PerpetualCache`、提供模板方法 `query` 和 `update`,具体的执行方法(`doQuery` 和 `doUpdate`)由各子类实现,并提供了缓存管理的方法,如 `clearLocalCache` 和 `flushStatements`。 继续 `Configuration#newExecutor` 方法源码逻辑,`ExecutorType executorType` 类型默认配置为 `ExecutorType.SIMPLE`,所以创建的执行器类型为 `SimpleExecutor`。但需要注意 `protected boolean cacheEnabled = true;` 配置默认为 true,实际创建类型为 `CachingExecutor`,会在 `SimpleExecutor` 外包一层: 我们继续看一下 `CachingExecutor` 的构造方法实现,注意其中的注释信息: ```java public class CachingExecutor implements Executor { // 采用了静态代理模式,delegate 为被代理对象,在本次样例中,它为 SimpleExecutor 类型 private final Executor delegate; public CachingExecutor(Executor delegate) { this.delegate = delegate; delegate.setExecutorWrapper(this); } // ... } ``` `CachingExecutor` 的实现使用了 **静态代理模式**,它是代理对象,负责处理 **二级缓存** 相关的逻辑,实际的查询逻辑由被代理对象 `Executor delegate` 执行(`SimpleExecutor`);逻辑 `delegate.setExecutorWrapper(this);` 会执行 `BaseExecutor` 中的 `setExecutorWrapper` 方法,并用 `wrapper` 字段引用最外层的执行器,Mybatis 将其命名为 `wrapper`,但是实际上在源码中并没有应用到 **装饰器模式**,不过这样设计提供了使用装饰器模式的可能。 ```java public abstract class BaseExecutor implements Executor { // 装饰器模式 protected Executor wrapper; @Override public void setExecutorWrapper(Executor wrapper) { this.wrapper = wrapper; } // ... } ``` 现在 `SqlSession session = sqlMapper.openSession()` 逻辑已经被执行完了,准备进入获取 Mapper 的逻辑: ```java @Test void shouldExecuteSelectOneAuthorUsingMapperClass() { try (SqlSession session = sqlMapper.openSession()) { // 在会话中获取 Mapper AuthorMapper mapper = session.getMapper(AuthorMapper.class); Author author = mapper.selectAuthor(101); assertEquals(101, author.getId()); } } ``` 它会执行到 `org.apache.ibatis.binding.MapperRegistry#getMapper` 方法,注意其中的注释信息: ```java public class MapperRegistry { private final Configuration config; // 所有的 Mapper 对应的 MapperProxyFactory 已经在 Mybatis 配置加载时初始化好了(对应 mybatis.xml 配置文件中的 <mappers> 标签) private final Map<Class<?>, MapperProxyFactory<?>> knownMappers = new ConcurrentHashMap<>(); public MapperRegistry(Configuration config) { this.config = config; } @SuppressWarnings("unchecked") public <T> T getMapper(Class<T> type, SqlSession sqlSession) { final MapperProxyFactory<T> mapperProxyFactory = (MapperProxyFactory<T>) knownMappers.get(type); if (mapperProxyFactory == null) { throw new BindingException("Type " + type + " is not known to the MapperRegistry."); } try { // 通过 MapperProxyFactory 工厂创建 MapperProxy return mapperProxyFactory.newInstance(sqlSession); } catch (Exception e) { throw new BindingException("Error getting mapper instance. Cause: " + e, e); } } } ``` `mapperProxyFactory.newInstance(sqlSession);` 方法创建了 `MapperProxy` 对象,虽然它将类命名中包含 `Factory`,但是它并没有使用工厂模式,而是采用了 **简单工厂的编程风格**,将创建 `MapperProxy` 对象的逻辑封装起来: ```java public class MapperProxyFactory<T> { // ... public T newInstance(SqlSession sqlSession) { final MapperProxy<T> mapperProxy = new MapperProxy<>(sqlSession, mapperInterface, methodCache); return newInstance(mapperProxy); } @SuppressWarnings("unchecked") protected T newInstance(MapperProxy<T> mapperProxy) { return (T) Proxy.newProxyInstance(mapperInterface.getClassLoader(), new Class[]{mapperInterface}, mapperProxy); } } ``` `MapperProxy` 对象使用了 **动态代理模式**,它实现了 `InvocationHandler` 接口,主要代理的功能为创建并缓存 `MapperMethodInvoker` 对象,衔接了 Mapper 接口方法与 SQL 操作的绑定和执行过程: ```java public class MapperProxy<T> implements InvocationHandler, Serializable { // ... @Override public Object invoke(Object proxy, Method method, Object[] args) throws Throwable { try { // 是否为 Object 类的方法,如果是直接执行,不做代理相关逻辑 if (Object.class.equals(method.getDeclaringClass())) { return method.invoke(this, args); } // 否则缓存和获取 MapperMethodInvoker 实例,再执行 return cachedInvoker(method).invoke(proxy, method, args, sqlSession); } catch (Throwable t) { throw ExceptionUtil.unwrapThrowable(t); } } } ``` 其中 `cachedInvoker` 方法值得关注,它为每个 mapper 方法创建并缓存 `MapperMethodInvoker`: ```java public class MapperProxy<T> implements InvocationHandler, Serializable { // ... // 缓存 MapperMethodInvoker private final Map<Method, MapperMethodInvoker> methodCache; private MapperMethodInvoker cachedInvoker(Method method) throws Throwable { try { return MapUtil.computeIfAbsent(methodCache, method, m -> { // mapper 中声明的 SQL 执行方法均为非default方法 if (!m.isDefault()) { return new PlainMethodInvoker(new MapperMethod(mapperInterface, method, sqlSession.getConfiguration())); } // default 方法:声明在 interface 中,使用 default 标记,并提供了默认实现 // default 方法使用 DefaultMethodInvoker 执行,了解即可 try { if (privateLookupInMethod == null) { return new DefaultMethodInvoker(getMethodHandleJava8(method)); } return new DefaultMethodInvoker(getMethodHandleJava9(method)); } catch (IllegalAccessException | InstantiationException | InvocationTargetException | NoSuchMethodException e) { throw new RuntimeException(e); } }); } catch (RuntimeException re) { Throwable cause = re.getCause(); throw cause == null ? re : cause; } } } ``` `PlainMethodInvoker` 和 `DefaultMethodInvoker` 对象中的逻辑非常简单,不过是在方法执行对象上套了一层壳,但是如此设计还是很有必要的,它使用到了 **策略模式**: ```java public class MapperProxy<T> implements InvocationHandler, Serializable { // ... interface MapperMethodInvoker { Object invoke(Object proxy, Method method, Object[] args, SqlSession sqlSession) throws Throwable; } private static class PlainMethodInvoker implements MapperMethodInvoker { private final MapperMethod mapperMethod; public PlainMethodInvoker(MapperMethod mapperMethod) { this.mapperMethod = mapperMethod; } @Override public Object invoke(Object proxy, Method method, Object[] args, SqlSession sqlSession) throws Throwable { return mapperMethod.execute(sqlSession, args); } } private static class DefaultMethodInvoker implements MapperMethodInvoker { private final MethodHandle methodHandle; public DefaultMethodInvoker(MethodHandle methodHandle) { this.methodHandle = methodHandle; } @Override public Object invoke(Object proxy, Method method, Object[] args, SqlSession sqlSession) throws Throwable { return methodHandle.bindTo(proxy).invokeWithArguments(args); } } } ``` 这样设计的好处是: 1. **单一职责**:`PlainMethodInvoker` 通过封装 `MapperMethod` 的调用逻辑,实现了职责分离。这样做可以将方法调用的具体实现与代理的其他逻辑(如缓存处理、事务管理等)分开,保持代码的清晰和可维护性 2. **灵活性和扩展性**:封装调用逻辑使得以后可以更容易地扩展或修改调用过程,而不需要直接修改 `MapperProxy` 的代码(如果需要在调用前后添加额外的逻辑,可以实现不同的 `MethodInvoker`) 3. **提供一致的接口**:`MapperProxy` 可以在调用方法时不关心具体的实现细节,只需调用 `MethodInvoker#invoke` 方法。`MapperMethodInvoker` 的另一个实现 `DefaultMethodInvoker` 内封装的是 `MethodHandle`,显然与 `MapperMethod` 对象执行方法的逻辑不一致,但是 `MethodInvoker` 只对外暴露 `invoke` 方法,外部调用逻辑便无需针对不同的类型做改动了 现在我们已经清楚了 `PlainMethodInvoker` 是 `MapperMethod` 的执行器,这便需要我们重点了解下 `MapperMethod` 的逻辑: ```java public class MapperMethod { // 主要用于记录 SQL 类型: SELECT、INSERT、DELETE 和 UPDATE 等 private final SqlCommand command; // 记录返回值等信息 private final MethodSignature method; public MapperMethod(Class<?> mapperInterface, Method method, Configuration config) { this.command = new SqlCommand(config, mapperInterface, method); this.method = new MethodSignature(config, mapperInterface, method); } // ... } ``` `MapperMethod` 被实例化时,会创建 `SqlCommand` 和 `MethodSignature` 对象,这两个类均定义在 `MapperMethod` 类内部。在 Mybatis 源码中多处都遵循了这种设计原则: 1. **单一职责**:这个是经常提到的原则,定义两个不同的对象来分别做不同的功能体现了该原则 2. **高内聚**:`SqlCommand` 和 `MethodSignature` 与 `MapperMethod` 直接相关,封装为静态内部类体现该原则 3. **信息隐藏**:`SqlCommand` 和 `MethodSignature` 的实现细节都作为内部类,不对外公开,其他类无需关注具体实现,也没有对外公开使用 4. **最少知识原则**:其思想是“一个对象应当对其他对象有尽可能少的了解,只与直接的朋友通信,而不与陌生对象通信”,此处也遵循了该思想 `SqlCommand` 定义非常简单,其中字段 `name` 和 `type` 分别记录了方法全路径名和 SQL 类型: ```java public class MapperMethod { // ... public static class SqlCommand { // eg: org.apache.ibatis.domain.blog.mappers.AuthorMapper.selectAuthor private final String name; // eg: SELECT private final SqlCommandType type; // ... } } ``` `MethodSignature` 中定义的字段内容稍多一些,请关注注释,具体的字段赋值逻辑并不复杂,便不在这里详细解释了: ```java public class MapperMethod { // ... public static class MethodSignature { // 结果是否返回一个集合 private final boolean returnsMany; // 返回值是否使用了 org.apache.ibatis.annotations.MapKey 注解,标记了作为 Map 的 key 的值 // 使用方法详见注解的注释内容 private final String mapKey; // 结果是否返回 Map private final boolean returnsMap; // 结果是否返回 void private final boolean returnsVoid; // 结果是否返回 cursor private final boolean returnsCursor; // 结果是否返回 optional private final boolean returnsOptional; // 返回值类型 private final Class<?> returnType; // resultHandler 在参数中的索引值,无则为 null private final Integer resultHandlerIndex; // rowBounds 用于分页的参数对象的索引值,无则为 null private final Integer rowBoundsIndex; // 用于解析方法参数名称的工具,它用于处理方法参数的名称,以便在执行 SQL 语句时正确地将参数传递给 SQL 语句,常见的 @Param 注解便在这里生效 // 该工具类中的注释描述很清楚,其中封装了 names 字段来表示参数名和索引值的对应关系,例子如下 // aMethod(@Param("M") int a, @Param("N") int b) -> {{0, "M"}, {1, "N"}} // aMethod(int a, int b) -> {{0, "0"}, {1, "1"}} // aMethod(int a, RowBounds rb, int b) -> {{0, "0"}, {2, "1"}} private final ParamNameResolver paramNameResolver; // ... } } ``` `MethodSignature` 中定义的 `ParamNameResolver` 中有一段比较有意思的代码,在这里稍稍提一下: ```java public class ParamNameResolver { // key: 索引 value: 参数值 private final SortedMap<Integer, String> names; // ... public ParamNameResolver(Configuration config, Method method) { final SortedMap<Integer, String> map = new TreeMap<>(); // ... names = Collections.unmodifiableSortedMap(map); } } ``` 其中使用到了 `Collections.unmodifiableSortedMap(map)` 方法,表示该 `Map` 初始化完成后是不能修改的,如果业务中也有不可修改的对象,可以参考使用该逻辑。此外,该 `Map` 类型使用的是 `TreeMap` 红黑树,想具体了解经典红黑树可以参考这篇文章 [深入理解经典红黑树](http://sd.jd.com/article/26149?shareId=53471&isHideShareButton=1)。 `MapperMethod` 中的组件已经介绍完了,下面来看一下 `execute` 方法,因为该方法相对复杂,我们先集中精力看一下 SELECT 相关的流程: ```java public class MapperMethod { // ... private final SqlCommand command; private final MethodSignature method; public Object execute(SqlSession sqlSession, Object[] args) { Object result; switch (command.getType()) { case INSERT: { // ... } case UPDATE: { // ... } case DELETE: { // ... } case SELECT: // 返回值为 void 并且在入参中指定了 ResultHandler if (method.returnsVoid() && method.hasResultHandler()) { executeWithResultHandler(sqlSession, args); result = null; // 结果返回集合 } else if (method.returnsMany()) { result = executeForMany(sqlSession, args); // 结果返回 Map } else if (method.returnsMap()) { result = executeForMap(sqlSession, args); // 结果返回 Cursor } else if (method.returnsCursor()) { result = executeForCursor(sqlSession, args); } else { // 结果返回单个对象 Object param = method.convertArgsToSqlCommandParam(args); result = sqlSession.selectOne(command.getName(), param); if (method.returnsOptional() && (result == null || !method.getReturnType().equals(result.getClass()))) { result = Optional.ofNullable(result); } } break; } // ... return result; } } ``` 根据单测用例,我们先看一个返回单个对象的分支,`MethodSignature#convertArgsToSqlCommandParam` 方法见名知意,它会将入参转换成执行 SQL 命令的参数,由此也可以发现 Mybatis 中各个操作的命名不需要注释信息也能表达清楚。接下来就要执行到关键方法 `org.apache.ibatis.session.defaults.DefaultSqlSession#selectOne` 了,现在又将 `SqlSession` 的内容接上了: ```java public class DefaultSqlSession implements SqlSession { // ... @Override public <T> T selectOne(String statement, Object parameter) { // Popular vote was to return null on 0 results and throw exception on too many. List<T> list = this.selectList(statement, parameter); if (list.size() == 1) { return list.get(0); } if (list.size() > 1) { throw new TooManyResultsException( "Expected one result (or null) to be returned by selectOne(), but found: " + list.size()); } else { return null; } } } ``` 可以发现 `selectOne` 方法复用的是 `selectList` 方法,这种代码风格也值得我们参考:**封装通用的方法尽可能的复用**,减少开发工作量。其中的注释也蛮有意思,这么写的原因也是经过大家讨论的结果: > Popular vote was to return null on 0 results and throw exception on too many. > 受欢迎的设计是无结果时返回 null,多个结果时抛出异常 其中 `DefaultSqlSession#selectList` 方法的代码风格也值得参考,它使用了 **方法的重载**,定义了一个私有的(private)接受全量参数的方法,其他公开出的同名方法入参不同,但本质上调用的都是私有方法(Spring 框架中也有类似的代码)。在《软件设计哲学》中提到过相关的观点,它提倡寻找更 **通用的设计**,即使在不考虑复用的情况下,通用性的代码也更合理。带入到实际开发中,可以尝试思考如下问题来引导自己找出更通用的设计: * 满足当前需求最简单的接口是什么? * 这个方法会在多少种情况下被使用? * 目前通用的 API 使用起来是否简单? ```java public class DefaultSqlSession implements SqlSession { // ... @Override public <E> List<E> selectList(String statement) { return this.selectList(statement, null); } @Override public <E> List<E> selectList(String statement, Object parameter) { return this.selectList(statement, parameter, RowBounds.DEFAULT); } @Override public <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds) { return selectList(statement, parameter, rowBounds, Executor.NO_RESULT_HANDLER); } private <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds, ResultHandler handler) { try { MappedStatement ms = configuration.getMappedStatement(statement); dirty |= ms.isDirtySelect(); return executor.query(ms, wrapCollection(parameter), rowBounds, handler); } catch (Exception e) { throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e); } finally { ErrorContext.instance().reset(); } } } ``` 上文中我们提到过,`Executor` 实际创建类型为 `CachingExecutor`,接下来继续看下它的 `org.apache.ibatis.executor.CachingExecutor#query` 方法,分为 3 个主要步骤: ```java public class CachingExecutor implements Executor { // ... @Override public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException { // 1. 获取 BoundSql BoundSql boundSql = ms.getBoundSql(parameterObject); // 2. 创建缓存 key 用于一级、二级缓存的获取 CacheKey key = createCacheKey(ms, parameterObject, rowBounds, boundSql); // 3. 执行查询逻辑 return query(ms, parameterObject, rowBounds, resultHandler, key, boundSql); } } ``` 第一步获取 `BoundSql` 对象本质上执行的是 `org.apache.ibatis.mapping.SqlSource#getBoundSql` 方法,上一节中我们提到过,不包含动态标签的 SQL 最终会被解析成 `RawSqlSource` 并在内部组合 `StaticSqlSource`,`SqlSource#getBoundSql` 做的事情是将 SQL 字符串,参数映射,参数和配置信息保存在 `BoundSql` 中: ```java public class StaticSqlSource implements SqlSource { // ... @Override public BoundSql getBoundSql(Object parameterObject) { return new BoundSql(configuration, sql, parameterMappings, parameterObject); } } ``` 借此我们也介绍下 `BoundSql`,它的主要功能是保存 SQL 语句及其参数的详细信息: ```java public class BoundSql { // 经过 SqlSource#getBoundSql 处理的 SQL,可能包含 ? 占位符 private final String sql; // 参数映射 private final List<ParameterMapping> parameterMappings; // 实际入参 private final Object parameterObject; // 用于存储附加的参数,这些参数可能是在运行时动态添加的,通常用于处理动态 SQL 中的额外需求 private final Map<String, Object> additionalParameters; // 用于方便地访问 additionalParameters 中的属性 private final MetaObject metaParameters; // ... } ``` 第二步创建一级、二级缓存的 key 值,具体逻辑相对简单,它会根据 SQL 和参数等信息来创建,具体方法参见 `org.apache.ibatis.executor.BaseExecutor#createCacheKey`,无需特别关注。 第三步执行查询逻辑,具体逻辑如下,与 **二级缓存** 相关,如果想详细了解二级缓存的机制,请参考 [从根上理解 Mybatis 二级缓存](http://sd.jd.com/article/40792?shareId=53471&isHideShareButton=1)。 ```java public class CachingExecutor implements Executor { // ... @Override public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException { // 二级缓存相关逻辑 Cache cache = ms.getCache(); if (cache != null) { flushCacheIfRequired(ms); if (ms.isUseCache() && resultHandler == null) { ensureNoOutParams(ms, boundSql); @SuppressWarnings("unchecked") List<E> list = (List<E>) tcm.getObject(cache, key); if (list == null) { list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql); tcm.putObject(cache, key, list); // issue #578 and #116 } return list; } } // 查询逻辑 return delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql); } } ``` 我们主要关注 `delegate.query` 方法的逻辑,如下所示,其中涉及了一级缓存相关的内容,详细了解请参考 [从根上理解 Mybatis 一级缓存](http://sd.jd.com/article/40791?shareId=53471&isHideShareButton=1),在此就不再赘述了。 ```java public abstract class BaseExecutor implements Executor { // ... @Override public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException { ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId()); if (closed) { throw new ExecutorException("Executor was closed."); } if (queryStack == 0 && ms.isFlushCacheRequired()) { clearLocalCache(); } List<E> list; try { queryStack++; // 一级缓存 list = resultHandler == null ? (List<E>) localCache.getObject(key) : null; if (list != null) { // 存储过程相关逻辑 handleLocallyCachedOutputParameters(ms, key, parameter, boundSql); } else { // 未命中一级缓存,查询数据库 list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql); } } finally { queryStack--; } if (queryStack == 0) { for (DeferredLoad deferredLoad : deferredLoads) { deferredLoad.load(); } // issue #601 deferredLoads.clear(); if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) { // issue #482 clearLocalCache(); } } return list; } private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException { List<E> list; // 一级缓存占位 localCache.putObject(key, EXECUTION_PLACEHOLDER); try { list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql); } finally { // 查询完成后清除一级缓存 localCache.removeObject(key); } // 添加到一级缓存中 localCache.putObject(key, list); // 存储过程相关逻辑 if (ms.getStatementType() == StatementType.CALLABLE) { localOutputParameterCache.putObject(key, parameter); } return list; } } ``` 这里我们重点关注 `BaseExecutor#queryFromDatabase` 方法设计,它使用到了 **模板方法模式**,定义了方法的模板,具体执行逻辑 `doQuery` 由具体子类去实现,而在我们测试的样例中,“具体的子类” 是 `SimpleExecutor`,执行的方法如下: ```java public class SimpleExecutor extends BaseExecutor { // ... @Override public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException { Statement stmt = null; try { Configuration configuration = ms.getConfiguration(); // 创建 StatementHandler StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql); // 准备 Statement stmt = prepareStatement(handler, ms.getStatementLog()); // 由 StatementHandler 执行 query 方法 return handler.query(stmt, resultHandler); } finally { closeStatement(stmt); } } } ``` 首先便会创建 `StatementHandler`,其中逻辑蛮有意思,我们重点看一下: ### StatementHandler `StatementHandler` 在 `Configuration#newStatementHandler` 方法中被创建,实际类型为 `RoutingStatementHandler`: ```java public class Configuration { public StatementHandler newStatementHandler(Executor executor, MappedStatement mappedStatement, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) { StatementHandler statementHandler = new RoutingStatementHandler(executor, mappedStatement, parameterObject, rowBounds, resultHandler, boundSql); // 拦截器相关逻辑 return (StatementHandler) interceptorChain.pluginAll(statementHandler); } } ``` `RoutingStatementHandler` 使用了 **静态代理模式**,命名中 `Routing` 即表示它代理的作用:根据 `statementType` 创建不同的 `StatementHandler`,并去执行相关的逻辑,不配置 `statementType` 参数的话,默认为 **PREPARED**,如下所示: ```java public class RoutingStatementHandler implements StatementHandler { // 代理对象 private final StatementHandler delegate; public RoutingStatementHandler(Executor executor, MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) { // 在调用构造方法时,根据 statementType 字段为代理对象 delegate 赋值,那么这样便实现了复杂度隐藏,只由代理对象去帮忙路由具体的实现即可 switch (ms.getStatementType()) { case STATEMENT: delegate = new SimpleStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql); break; case PREPARED: delegate = new PreparedStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql); break; case CALLABLE: delegate = new CallableStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql); break; default: throw new ExecutorException("Unknown statement type: " + ms.getStatementType()); } } @Override public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException { return delegate.query(statement, resultHandler); } // ... } ``` 在这里我们详细介绍下 `org.apache.ibatis.executor.statement.StatementHandler` SQL 处理器,它是 MyBatis 框架中的一个接口,定义了处理 SQL 语句的核心方法,**提供统一的接口供框架调用**。它的主要职责是 **准备(prepare)、承接封装 SQL 执行参数的逻辑和承接处理结果集的逻辑**,这里描述成“承接”的意思是这两部分职责并不是由它处理,而是分别由 `ParameterHandler` 和 `ResultSetHandler` 完成。`StatementHandler` 是 MyBatis 执行 SQL 语句的关键组件之一,`Executor` 借助它与数据库进行交互。继承关系图如下(`BaseStatementHandler` 为抽象类,但并没有在命名中添加 Abstract): 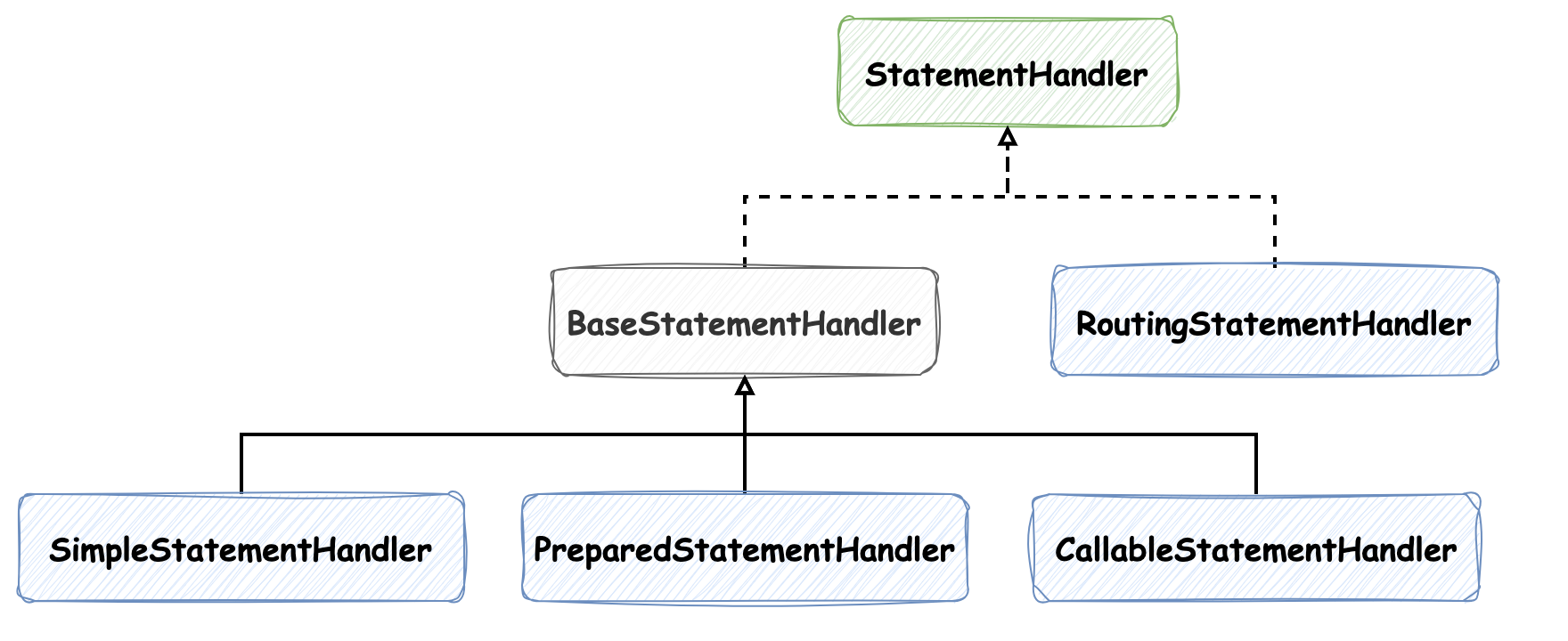 继续回到 `SimpleExecutor#doQuery` 方法 **准备 Statement** `prepareStatement` 方法中: ```java public class SimpleExecutor extends BaseExecutor { // ... private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException { Statement stmt; Connection connection = getConnection(statementLog); stmt = handler.prepare(connection, transaction.getTimeout()); // 封装SQL语句中的参数 handler.parameterize(stmt); return stmt; } } ``` 它会调用 `StatementHandler#prepare` 方法,该方法使用了 **模板方法模式** 定义了算法骨架,具体的步骤 `instantiateStatement` 分别由具体实现类去实现: ```java public abstract class BaseStatementHandler implements StatementHandler { // ... @Override public Statement prepare(Connection connection, Integer transactionTimeout) throws SQLException { ErrorContext.instance().sql(boundSql.getSql()); Statement statement = null; try { // 实例化 Statement 方法 statement = instantiateStatement(connection); // 赋值查询超时时间 setStatementTimeout(statement, transactionTimeout); // 赋值结果集获取数量 setFetchSize(statement); return statement; } catch (SQLException e) { closeStatement(statement); throw e; } catch (Exception e) { closeStatement(statement); throw new ExecutorException("Error preparing statement. Cause: " + e, e); } } protected abstract Statement instantiateStatement(Connection connection) throws SQLException; } ``` 在这里实例化 `Statement` 的方法被命名为 `instantiateStatement`,**instantiate 表示实例化的意思**,后续我们在为构造对象的方法命名时也可以采用 `instantiateXxx` 的形式,一眼便能知道该方法的作用。相应地,为对象的字段赋值的方法可以命名为 `initialXxx` 表示为已知实例封装了某些字段值。 继续回到源码逻辑中,`StatementHandler` 实际创建类型为 `PreparedStatementHandler`,`instantiateStatement` 方法创建的 `Statement` 类型为 `ClientPreparedStatement`,它是 JDBC 相关的内容,就不再多赘述了。 回到 `SimpleExecutor#prepareStatement` 方法,创建完 `Statement` 会调用 `StatementHandler#parameterize` 方法封装参数,其中会使用到 `DefaultParameterHandler` 完成该操作,它是 `ParameterHandler` 接口的默认实现类,我们详细介绍下它: ### ParameterHandler `ParameterHandler` 的核心逻辑如下,它会完成占位符和指定参数值的对应关系: ```java public class DefaultParameterHandler implements ParameterHandler { // ... @Override public void setParameters(PreparedStatement ps) { ErrorContext.instance().activity("setting parameters").object(mappedStatement.getParameterMap().getId()); // 获取参数映射,以便处理用户传入的参数 List<ParameterMapping> parameterMappings = boundSql.getParameterMappings(); if (parameterMappings != null) { MetaObject metaObject = null; for (int i = 0; i < parameterMappings.size(); i++) { ParameterMapping parameterMapping = parameterMappings.get(i); if (parameterMapping.getMode() != ParameterMode.OUT) { Object value; String propertyName = parameterMapping.getProperty(); if (boundSql.hasAdditionalParameter(propertyName)) { // issue #448 ask first for additional params value = boundSql.getAdditionalParameter(propertyName); } else if (parameterObject == null) { value = null; } else if (typeHandlerRegistry.hasTypeHandler(parameterObject.getClass())) { // 已定义类型处理器,这些类型能直接取对应值 value = parameterObject; } else { // 使用反射,根据参数映射中定义的字段值获取对应的参数值 if (metaObject == null) { metaObject = configuration.newMetaObject(parameterObject); } value = metaObject.getValue(propertyName); } TypeHandler typeHandler = parameterMapping.getTypeHandler(); JdbcType jdbcType = parameterMapping.getJdbcType(); if (value == null && jdbcType == null) { jdbcType = configuration.getJdbcTypeForNull(); } try { // 将对应的参数值设置到对应的占位符顺序上 typeHandler.setParameter(ps, i + 1, value, jdbcType); } catch (TypeException | SQLException e) { throw new TypeException("Could not set parameters for mapping: " + parameterMapping + ". Cause: " + e, e); } } } } } } ``` 它本身的逻辑并不复杂,其中重要的组件 `TypeHandler` 我们来介绍下:对于字符串、整数、布尔值等基本数据类型的转换,Mybatis 框架定义了默认 `TypeHandler` 实现(`StringTypeHandler`, `BooleanTypeHandler`...),它其中定义了四个方法: ```java public interface TypeHandler<T> { // 用于将 Java 类型的数据设置到 JDBC 的 PreparedStatement 中,以便执行 SQL 语句时正确传递参数,替换掉对应顺序的占位符 void setParameter(PreparedStatement ps, int i, T parameter, JdbcType jdbcType) throws SQLException; // 用于从 ResultSet 中根据列名获取数据,并将其转换为Java类型 T getResult(ResultSet rs, String columnName) throws SQLException; // 用于从 ResultSet 中根据列索引获取数据,并将其转换为Java类型 T getResult(ResultSet rs, int columnIndex) throws SQLException; // 用于从 CallableStatement 存储过程中获取存储过程的输出参数,并将其转换为 Java 类型 T getResult(CallableStatement cs, int columnIndex) throws SQLException; } ``` 不难发现,它的作用是将 Java 类型的数据设置到正确的占位符索引位置上;根据 SQL 查询结果,将数据库中数据转换为 Java 类型。在 `TypeHandlerRegistry` 可以看到默认初始化的类型处理器,这些处理器的实现使用了 **策略模式和模板方法模式**:  如上图所示,`TypeHandler` 根据不同的 JavaType 来实现不同的策略,由于其中部分逻辑是通用的,所以抽出了抽象层定义方法模板来实现代码的复用。 现在 `SimpleExecutor#prepareStatement` 方法已经执行完毕了,这时 SQL 已经准备好了,对应的参数已经映射到对应的占位符上了,现在便是执行对应 SQL 的逻辑,它的执行流程在 JDBC 的 `PreparedStatement#execute` 方法中已经封装好了,感兴趣的同学可以去了解下,在这里我们需要看下 `resultSetHandler.handleResultSets(ps)` 处理结果的逻辑: ```java public class PreparedStatementHandler extends BaseStatementHandler { // ... @Override public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException { PreparedStatement ps = (PreparedStatement) statement; ps.execute(); // 处理从数据库中返回的结果 return resultSetHandler.handleResultSets(ps); } } ``` 结果由 `ResultSetHandler` 处理,它也是非常重要的组件之一。 ### ResultSetHandler 它包含以下三个方法,我们关注 `ResultSetHandler#handleResultSets` 方法即可: ```java public interface ResultSetHandler { /** * 处理 Statement 对象并返回结果对象 * * @param stmt SQL 语句执行后返回的 Statement 对象 * @return 映射后的结果对象列表 */ <E> List<E> handleResultSets(Statement stmt) throws SQLException; /** * 处理 Statement 对象并返回一个 Cursor 对象 * 它用于处理从数据库中获取的大量结果集,与传统的 List 或 Collection 不同,Cursor 提供了一种流式处理结果集的方式, * 这在处理大数据量时非常有用,因为它可以避免将所有数据加载到内存中 * * @param stmt SQL 语句执行后返回的 Statement 对象 * @return 游标对象,用于迭代结果集 */ <E> Cursor<E> handleCursorResultSets(Statement stmt) throws SQLException; /** * 处理存储过程的输出参数 * * @param cs 存储过程调用的 CallableStatement 对象 */ void handleOutputParameters(CallableStatement cs) throws SQLException; } ``` 它的默认实现类是 `DefaultResultSetHandler`,将 `ResultSet` 转换成对应 Java 对象的核心逻辑(根据声明的数据库列和 Java 对象字段的映射关系来赋值),总体上比较简单,关注注释信息即可: ```java public class DefaultResultSetHandler implements ResultSetHandler { // ... private void handleRowValuesForSimpleResultMap(ResultSetWrapper rsw, ResultMap resultMap, ResultHandler<?> resultHandler, RowBounds rowBounds, ResultMapping parentMapping) throws SQLException { DefaultResultContext<Object> resultContext = new DefaultResultContext<>(); ResultSet resultSet = rsw.getResultSet(); skipRows(resultSet, rowBounds); // 逐个按行解析成 Java 对象 while (shouldProcessMoreRows(resultContext, rowBounds) && !resultSet.isClosed() && resultSet.next()) { ResultMap discriminatedResultMap = resolveDiscriminatedResultMap(resultSet, resultMap, null); Object rowValue = getRowValue(rsw, discriminatedResultMap, null); storeObject(resultHandler, resultContext, rowValue, parentMapping, resultSet); } } private Object getRowValue(ResultSetWrapper rsw, ResultMap resultMap, String columnPrefix) throws SQLException { final ResultLoaderMap lazyLoader = new ResultLoaderMap(); // 根据返回值对象类型调用其构造方法,该结果中所有字段未生成值 Object rowValue = createResultObject(rsw, resultMap, lazyLoader, columnPrefix); if (rowValue != null && !hasTypeHandlerForResultObject(rsw, resultMap.getType())) { // 元对象 final MetaObject metaObject = configuration.newMetaObject(rowValue); boolean foundValues = this.useConstructorMappings; // 根据配置信息是否处理自动字段和列的映射,默认为 ture if (shouldApplyAutomaticMappings(resultMap, false)) { // 在这里处理 result map 中没用定义的字段和列关系的映射 // 在 Mybatis 框架下默认情况下,只有字段值和数据库列相同才能完成映射,如果想将数据库列转换成驼峰式的 Java 字段定义,需要配置 mapUnderscoreToCamelCase 为 true foundValues = applyAutomaticMappings(rsw, resultMap, metaObject, columnPrefix) || foundValues; } // 根据 result mapping 中配置的字段和数据库列的映射关系,从 resultSet 中取值后封装给 metaObject foundValues = applyPropertyMappings(rsw, resultMap, metaObject, lazyLoader, columnPrefix) || foundValues; foundValues = lazyLoader.size() > 0 || foundValues; rowValue = foundValues || configuration.isReturnInstanceForEmptyRow() ? rowValue : null; } return rowValue; } private void storeObject(ResultHandler<?> resultHandler, DefaultResultContext<Object> resultContext, Object rowValue, ResultMapping parentMapping, ResultSet rs) throws SQLException { if (parentMapping != null) { linkToParents(rs, parentMapping, rowValue); } else { callResultHandler(resultHandler, resultContext, rowValue); } } } ``` 在这里便完成数据库中数据和 Java 类对象的转换,转换完成后便是不断的方法返回,最终由 Mapper 接口返回结果。这样,一条简单 SQL 的查询便结束了,想要了解该过程非常需要大家 Debug 根据代码代码流程。我们来整理下时序图: ### 总结 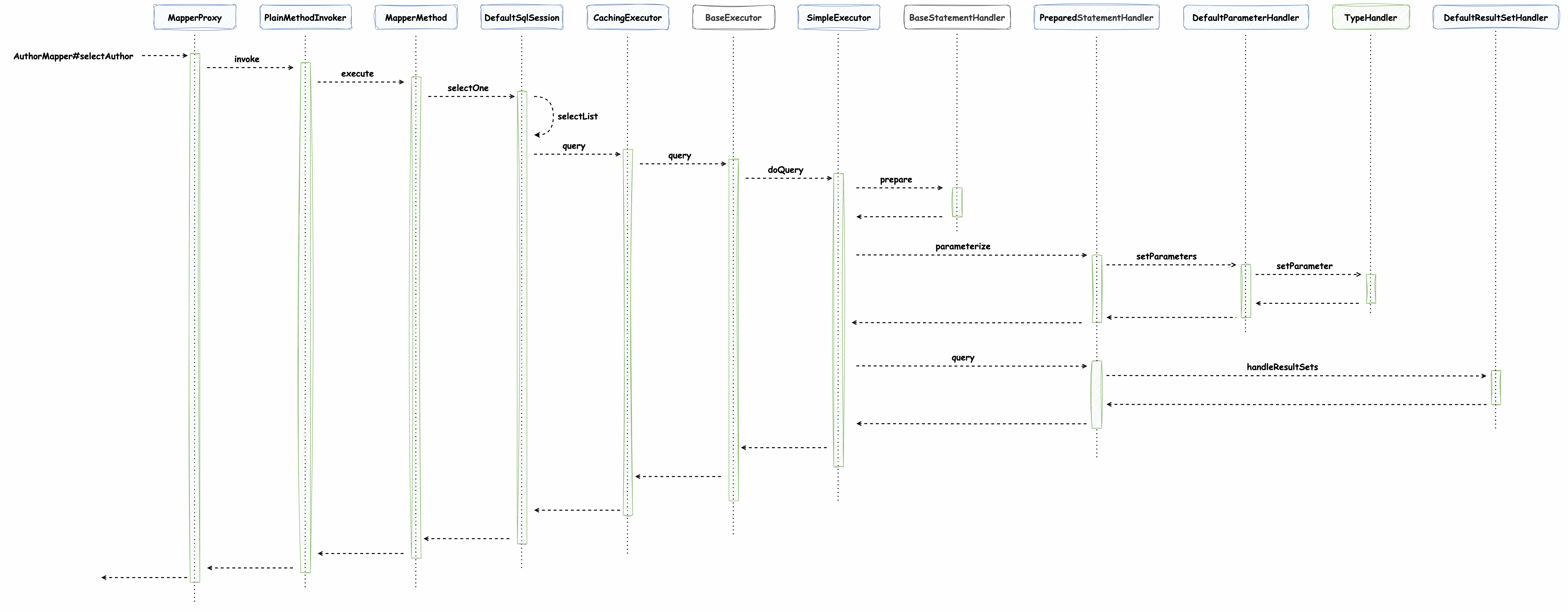 每个声明 SQL 查询语句的 Mapper 接口都会被 `MapperProxy` 代理,接口中每个方法都会被定义为 `MapperMethod` 对象,借助 `PlainMethodInvoker` 执行。当方法被执行时,会先调用 `SqlSession` 中的查询方法,由 **执行器** `Executor` 去承接,接下来会调用 **SQL 处理器** `StatementHandler` 的方法完成 SQL 准备,而封装参数则由 **参数处理器** `DefaultParameterHandler` 和 `TypeHandler` 完成,`ResultSet` 结果的处理:将数据库中数据转换成所需要的 Java 对象由 **结果处理器** `DefaultResultSetHandler` 完成。
上一篇:由 Mybatis 源码畅谈软件设计(六):Interceptor 拦截器的设计
下一篇:设计模式之代理模式:武器附魔之道
wy****
文章数
47
阅读量
37759
作者其他文章
01
用“分区”来面对超大数据集和超大吞吐量
1. 为什么要分区?分区(partitions) 也被称为 分片(sharding),通常采用对数据进行分区的方式来增加系统的 可伸缩性,以此来面对非常大的数据集或非常高的吞吐量,避免出现热点。分区通常和复制结合使用,使得每个分区的副本存储在多个节点上,保证数据副本的 高可用。如下图所示,如果数据库被分区,每个分区都有一个主库。不同分区的主库可能在不同的节点上,每个节点可能是某些分区的主库,同时是
01
深入理解分布式共识算法 Raft
“不可靠的网络”、“不稳定的时钟”和“节点的故障”都是在分布式系统中常见的问题,在文章开始前,我们先来看一下:如果在分布式系统中网络不可靠会发生什么样的问题。有以下 3 个服务构成的分布式集群,并在 server_1 中发生写请求变更 A = 1,“正常情况下” server_1 将 A 值同步给 server_2 和 server_3,保证集群的数据一致性:但是如果在数据变更时发生网络问题(延迟
01
缓存之美:从根上理解 ConcurrentHashMap
本文将详细介绍 ConcurrentHashMap 构造方法、添加值方法和扩容操作等源码实现。ConcurrentHashMap 是线程安全的哈希表,此哈希表的设计主要目的是在最小化更新操作对哈希表的占用,以保持并发可读性,次要目的是保持空间消耗与 HashMap 相同或更好,并支持利用多线程在空表上高效地插入初始值。在 Java 8 及之后的版本,使用 CAS 操作、 synchronized
01
缓存之美:万文详解 Caffeine 实现原理(上)
由于神灯社区最大字数限制,本文章将分为两篇,第二篇文章为缓存之美:万文详解 Caffeine 实现原理(下)文章将采用“总-分-总”的结构对配置固定大小元素驱逐策略的 Caffeine 缓存进行介绍,首先会讲解它的实现原理,在大家对它有一个概念之后再深入具体源码的细节之中,理解它的设计理念,从中能学习到用于统计元素访问频率的 Count-Min Sketch 数据结构、理解内存屏障和如何避免缓存伪
wy****
文章数
47
阅读量
37759
作者其他文章
01
用“分区”来面对超大数据集和超大吞吐量
01
深入理解分布式共识算法 Raft
01
缓存之美:从根上理解 ConcurrentHashMap
01
缓存之美:万文详解 Caffeine 实现原理(上)
添加企业微信
获取1V1专业服务
扫码关注
京东云开发者公众号




 wy****
wy**** 2024-12-25
2024-12-25 1002浏览
1002浏览






