



一、背景
从事数据开发将近四年,过程中有大量任务交接或阅读同事代码的场景。在这些场景中发现有些SQL读起来赏心悦目,可以一目了然地了解业务逻辑,一些复杂的业务需求实现方法也可以做到简洁优雅,同时在性能上也有良好表现。而有些SQL读起来非常艰难,时常要跨越几百行寻找WHERE条件或者关联字段,甚至充斥着大量相同的子查询命名,除了作者可能少有人能快速看懂。

为此,基于个人经验、理解与实践,我总结了一些方法和技巧,能让SQL尽量变得优雅,即兼顾代码可读性和执行性能两方面的提升。
二、方法与技巧
1.子查询与谓词下推
很多同事在写关联逻辑时,习惯于直接将原表关联,随后在最下方用一大段WHERE语句进行条件过滤,如下示例:
// -------------------- Bad Codes ------------------------
SELECT
f1.pin,
c1.site_id,
c2.site_name
FROM
fdm.fdm1 AS f1
LEFT JOIN cdm.cdm1 AS c1
ON
f1.erp = lower(c1.account_number)
LEFT JOIN cdm.cdm2 AS c2
ON
c1.site_id = c2.site_code
WHERE
f1.start_date <= '""" + start_date + """'
AND f1.end_date > '""" + start_date + """'
AND f1.status = 1
AND c1.dt = '""" + start_date + """'
AND c2.yn = 1
GROUP BY
f1.pin,
c1.site_id,
c2.site_name
这段SQL主要有两个问题:
- cdm1和cdm2的条件写在LEFT JOIN之后,因为cdm1和cdm2是NULL补充表(NULL 补充表: 右表被称为 NULL 补充表,意味着它的存在是为了补充左表中可能缺失的值。即使在右表中没有与左表匹配的行,左表中的行仍然会被返回,右表的相关列会填充为 NULL),那么19和20行无法进行谓词下推,这会导致关联时fdm1和cdm1,cdm2先进行全表关联,再按照WHERE条件过滤分区。如果cdm1是每天全量的表,先关联全表所扫描的数据量可想而知是相当大的。
- 全表关联时没有对关联键进行NULL值处理,如果相关表的对应字段存在大量NULL值,会引起数据倾斜。
第一个问题涉及SQL的谓词下推,即写条件时,应该在不影响结果的情况下,尽量将过滤条件下推到join之前进行(“下推”指将条件推到靠近数据源的位置而不是SQL语句的方位)。谓词下推后,过滤条件在map端执行,减少了map端的输出,降低了数据在集群上传输的量,节约了集群的资源,也可以提升任务的性能。
对于常用的INNER JOIN和LEFT OUTER JOIN,谓词下推规则如下:
| INNER JOIN | LEFT OUTER JOIN | |||
| 左表 | 右表 | 左表 | 右表 | |
| ON条件 | 下推 | 下推 | 不下推 | 下推 |
| WHERE条件 | 下推 | 下推 | 下推 | 不下推 |
如果使用上述示例的写法,主要关注的是LEFT OUTER JOIN时WHERE语句里的条件是否会引起谓词不下推。如果不想记这些看起来很复杂的规则怎么办?可以如下所示直接使用子查询:
// -------------------- Good Codes 👍🏻------------------------
SELECT
f1.pin,
c1.site_id,
c2.site_name
FROM
(
SELECT erp, pin FROM fdm.fdm1 WHERE dp = 'ACTIVE' AND status = 1
)
f1
LEFT JOIN
(
SELECT
site_id,
lower(account_number) AS account_number
FROM
cdm.cdm1
WHERE
dt = '""" + start_date + """'
)
c1
ON
f1.erp = c1.account_number
LEFT JOIN
(
SELECT site_code, site_name FROM cdm.cdm2 WHERE yn = 1
)
c2
ON
c1.site_id = c2.site_code
GROUP BY
f1.pin,
c1.site_id,
c2.site_name
将原来WHERE语句里的各个条件下推到每个表的子查询中,可以先过滤掉不必要的行,提升关联效率。同时可读性大大提高,能清晰地看出每个来源表都取了哪些数据。还有一些其它细节,比如BDP平台的fdm拉链表,大部分业务场景下,都可以用dp='ACTIVE'代替start_date <= '""" + start_date + """' AND end_date > '""" + start_date + """'。同时注意列裁剪问题,尽量少用SELECT * FROM,只选取必要的列以减少内存开销。
2.去重难题
为了保证数据粒度的准确,几乎所有的SQL脚本编写时,都要考虑去重问题。常见的方法有:
- GROUP BY
- DISTINCT
- ROW_NUMBER开窗
- COLLECT_SET
1)GROUP BY 真的更好吗?
我们经常能在各种大数据技术分享中看到去重时推荐使用GROUP BY代替DISTINCT的观点。不可否认,数据量达到一定程度,去重字段枚举值也很复杂时,GROUP BY确实在性能上更优秀,同时可以避免数据倾斜。但具体情况具体分析,比如下面两段SQL涉及的业务场景:
// --------- Good Codes 👍🏻--------
select
count(distinct ulp_base_age)
from
app.app1
where
dt = sysdate(-1)
// --------- Bad Codes --------
select
count(ulp_base_age)
from
(
select
ulp_base_age
from
app.app1
where
dt = sysdate(-1)
group by
ulp_base_age
) t
底表app1为零售用户画像表,数据量20亿。如果要统计用户年龄分段的枚举值数量,哪一段的执行效率更高呢?先说结论:看到20亿的数据量,可能大家会认为第二段使用GROUP BY的SQL执行更快,但经过HIVE查询多次测试,第一段的平均执行时长约3分钟,第二段的平均执行时长约5分钟。
为了解释这个现象,我们需要了解GROUP BY和DISTINCT的原理。首先,ulp_base_age的枚举值只有7个,从MapReduce角度来看,在Map阶段,每个Map会对ulp_base_age去重。由于ulp_base_age枚举值有限,因而每个Map得到的ulp_base_age也有限,最终得到reduce的数据量也就是map数量*ulp_base_age枚举值的个数,这实质上造成了资源的浪费。而DISTINCT命令会在内存中构建一个hashtable,查找去重的时间复杂度是O(1);GROUP BY在不同版本间变动比较大,有的版本会用构建hashtable的形式去重,有的版本会通过排序的方式, 排序的最优时间复杂度无法到O(1)。另外,第一种方式(GROUP BY)不仅需要进行 shuffle,还需要在每个分区中进行聚合操作,会消耗更多的磁盘网络I/O资源。
这告诉我们,不要过度优化代码,要考虑到数据集的具体情况!!
2)最大化利用分桶
在面对更复杂的数据集时,去重也需要更巧妙的方法。假设有一个数据量极大的页面埋点数据集,其部分数据如下所示:
| click_dt | pin |
| 2024-12-16 | a |
| 2024-12-16 | a |
| 2024-12-16 | a |
| 2024-12-16 | bb |
| 2024-12-16 | bb |
| 2024-12-16 | ccc |
| 2024-12-16 | ccc |
| 2024-12-16 | dddd |
| 2024-12-16 | eee |
| 2024-12-16 | eeee |
如果要统计天维度的UV,如果使用:
// -------------------- Bad Codes --------------------
select
click_dt,
count(distinct pin)as uv
from
log_table
group by
click_dt;
那么假设有五个分桶,其使用情况会如下所示:
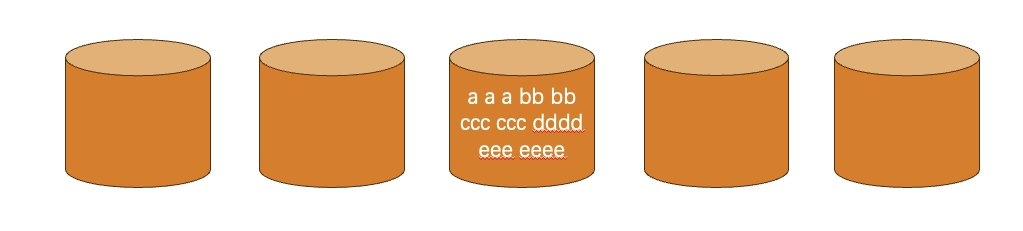
可以看到所有数据都被分配到了同一个桶里,其它桶都闲置,明显造成效率低下。优化代码如下:
// -------------------- Good Codes 👍🏻 --------------------
SELECT
click_dt,
size(collect_set(pin)) AS uv
FROM
(
SELECT click_dt, pin FROM log_table GROUP BY click_dt, pin
)
tmp
GROUP BY
click_dt;
此时桶的使用情况如下:
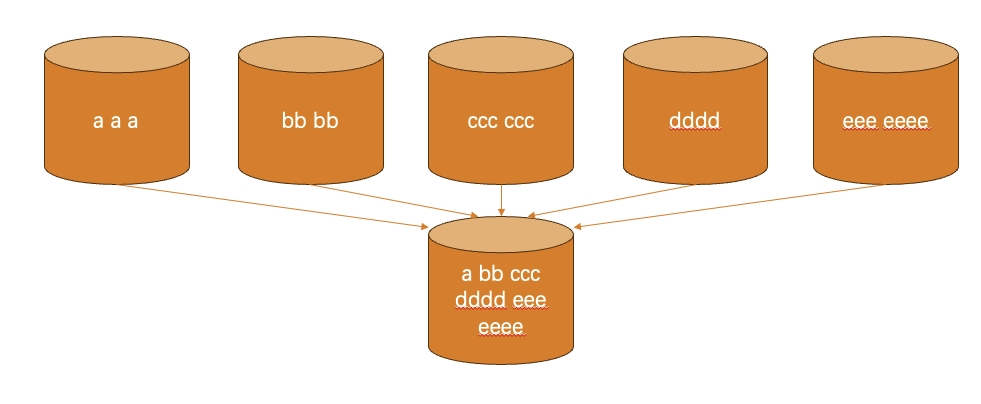
此时充分利用了五个桶,实现了并行操作,单个桶的负担大大下降。但如果此时第二步的结果集太大,还是容易造成OOM的问题。面对海量数据集,代码还可以继续优化:
// ------------------- Even Better Codes 👍🏻👍🏻👍🏻 -------------------
SELECT
click_dt,
SUM(uv_tmp) AS uv
FROM
(
SELECT
len_pin,
click_dt,
size(collect_set(pin)) AS uv_tmp
FROM
(
SELECT click_dt, pin, LENGTH(pin) AS len_pin FROM log_table
)
log_table_tmp
GROUP BY
len_pin,
click_dt
)
tmp
GROUP BY
click_dt
在聚合维度中加上pin的长度作为新维度,此时桶的使用如下:
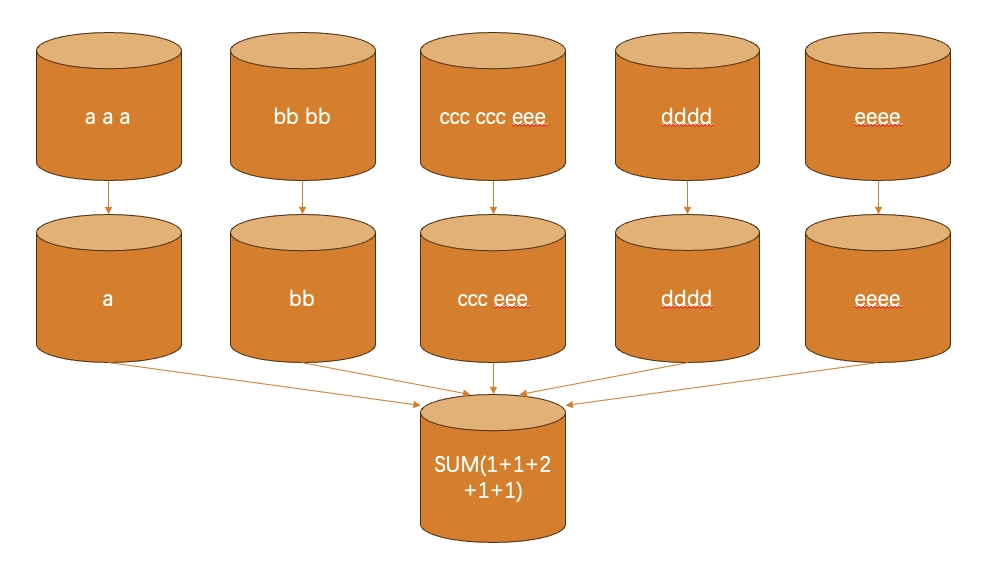
此处使用pin的长度来预聚合pin,用一种分桶分步预聚合的方法,较为巧妙地把一个集合去重问题最终转化为相加问题,避开了单个jvm去重承受过大压力,面对海量数据集较为实用。具体开发场景中,也可以使用首末字母等有共性的属性来预聚合。
3.充分使用平台工具
由于曾经长期手动修改时间参数来回刷数据,操作繁琐的同时还容易出错。回刷涉及上下游表时,工作量更是巨大。直到我发现了平台的任务补录功能,并且可以通过Python和SQL的交互来实现灵活控制脚本里的时间参数来达到补录时的时间控制,才解决这个痛点。
比如在任务调度的py脚本里,可以利用sys.argv来控制时间参数。sys.argv的第一个元素是默认的,内容为脚本名称。而通过判断sys.argv的长度,可以在SQL内容之前使用如下Python代码来设置参数:
if len(sys.argv) == 1:
# BDP不传参数的情况下使用,仅适用于BDP线上调度
curday = ht.oneday(0)
today = datetime.datetime.strptime(curday, '%Y-%m-%d')
start_date = str((today + datetime.timedelta(days=-1)).strftime("%Y-%m-%d"))[0:10]
end_date = str(today)[0:10]
last31Day = start_date
elif len(sys.argv) == 2:
# BDP线上调度使用 配合BDP参数 ${fmt(add(NTIME(),-1,'day'),'yyyy-MM-dd')}
end_date = str(datetime.datetime.strptime(sys.argv[1], "%Y-%m-%d"))[0:10]
start_date = str(
(datetime.datetime.strptime(end_date, "%Y-%m-%d")).replace(day=1))[0:10]
last31Day = (datetime.datetime.strptime(end_date, "%Y-%m-%d") +
datetime.timedelta(days=-30)).strftime("%Y-%m-%d")
elif len(sys.argv) == 3:
# 回刷使用,直接调用python脚本,并且需要传递两个日期参数,开始日期,结束日期
start_date = str(datetime.datetime.strptime(sys.argv[1], "%Y-%m-%d"))[0:10]
end_date = str(datetime.datetime.strptime(sys.argv[2], "%Y-%m-%d"))[0:10]
else:
print('parameter error')
sys.exit(1)
同时需要在SQL内容后使用如下Python代码:
if (len(sys.argv) == 1) | (len(sys.argv) == 2):
ht.exec_sql(
schema_name='app',
# 补数调度
# sql=showsql.format(htYDay_B=start_date, htYDay=end_date),
# 批量调度
sql=showsql.format(htYDay_B=start_date, htYDay=end_date),
table_name='app1',
exec_engine='spark',
spark_resource_level='high',
retry_with_hive=False,
spark_args=[
'--conf spark.sql.hive.mergeFiles=true',
'--conf spark.sql.adaptive.enabled=true',
'--conf spark.sql.adaptive.repartition.enabled=true',
'--conf spark.sql.adaptive.join.enabled=true',
'--conf spark.sql.adaptive.skewedJoin.enabled=true',
'--conf spark.hadoop.hive.exec.orc.split.strategy=ETL',
'--conf spark.sql.shuffle.partitions=1200',
'--conf spark.driver.maxResultSize=8g',
'--conf spark.executor.memory=32g'
])
elif len(sys.argv) == 3:
ht.exec_sql(
schema_name='app',
# 补数调度
sql=showsql.format(htYDay_B=start_date, htYDay=end_date),
# 批量调度
# sql=showsql.format(htYDay_B=last31Day, htYDay=end_date),
table_name='app1',
exec_engine='spark',
spark_resource_level='high',
retry_with_hive=False,
spark_args=[
'--conf spark.sql.hive.mergeFiles=true',
'--conf spark.sql.adaptive.enabled=true',
'--conf spark.sql.adaptive.repartition.enabled=true',
'--conf spark.sql.adaptive.join.enabled=true',
'--conf spark.sql.adaptive.skewedJoin.enabled=true',
'--conf spark.hadoop.hive.exec.orc.split.strategy=ETL',
'--conf spark.sql.shuffle.partitions=1200',
'--conf spark.driver.maxResultSize=8g',
'--conf spark.executor.memory=32g'
])
else:
print('parameter error')
sys.exit(1)
IF的第一个分支的作用是线上调度任务不配置参数时,可以将昨天的日期和今天的日期赋值给htYDay_B和htYDay;第二个分支则是线上脚本配置${fmt(add(NTIME(),-1,'day'),'yyyy-MM-dd')}等参数时,可以根据该参数计算并赋值htYDay_B和htYDay;第三个分支是任务补录时使用,通过上传时间范围的开始时间和结束时间,直接赋值htYDay_B和htYDay,来控制脚本中取数时间范围。
数据开发工程师往往会每天面对海量的业务需求,理解业务需求、数据探查会花费掉研发人员大量的时间,而日常开发有时会忽略写出的代码是否优雅和高效。如果对SQL优化的原理有一定认知,积累了足够的经验,或许能做到编写代码时下意识地写出更优雅的SQL代码。
参考文章: https://www.jhelp.net/p/foafP0Vuwt7Qaa12






