您好!
欢迎来到京东云开发者社区
登录
首页
博文
课程
大赛
工具
用户中心
开源
首页
博文
课程
大赛
工具
开源
更多
用户中心
开发者社区
>
博文
>
为什么《程序员修炼之道》评分高达 9.1?
分享
打开微信扫码分享
点击前往QQ分享
点击前往微博分享
点击复制链接
为什么《程序员修炼之道》评分高达 9.1?
wy****
2024-12-05
IP归属:北京
730浏览
开始接触到《程序员修炼之道:通向务实的最高境界》这本书是在豆瓣图书的高分榜单上,它的评分高达 9.1,其中有条蛮有意思的书评非常吸引我:“这本书我读过 5 遍信不信,每个字都磨出了感情... 爱看技术书的程序员,看看可以往上走走;不爱看技术书的程序员,看看可以轻松刷出阅读成就感”。所以,本着刷阅读成就感并希望磨炼技术的态度便开始了本书的阅读,抽业余时间读完,其中有部分收获能和大家分享,当然更希望大家去看原书。 ### 1\. DRY 原则 DRY 是书中强调和多次出现的原则,它的中文释义是“干的;干燥的”。在文中强调的是:在系统中,对于每一处的知识都要保持单一和明确。初看上去这个原则是值得坚持和肯定的,但其中提到了关于注释不要重复代码实现的想法,我对此并不是很同意,我觉得在接口层加入详细的注释还是有必要的。 以较为复杂的查询接口为例,如果不添加详细的注释的话,那么调用者需要深入到接口实现中去找、去看必要了解的知识,如果这个查询接口比较复杂,那么便需要花费比较多的时间。反之,如果有详细的注释,那么便节省了翻看实现的时间,比如说如下查询推荐延保的接口,简略注释只是对方法名的翻译,至于返回值是什么,请求参数需要哪些赋值需要去具体实现中寻找;详细注释则注明了这些内容。 ```java /** * 简略注释:查询推荐的延保 * 详细注释:结果中推荐延保数量至多为 2;入参中分页查询信息 ... **/ Result queryRecommand(Request req); ``` 但书中为什么反对注释重复方法的实现呢?因为它担心修改实现时,忘记维护注释使得注释过时。虽然有理,但是我觉得如果 **将注释看成代码的一部分,并约束修改代码时,同时修改注释**,是能够避免这个问题的,这样不仅仅是提高可读性,还能提高接口的抽象程度。 不过,DRY 原则也有值得坚持的地方,以如下线段类定义为例: ```java class Line { Point start; Point end; double length; } ``` 第一眼看上去貌似没什么问题,线段有起点、终点和长度。但是实际上出现了重复:长度是由起点和终点定义而来的,改变其中之一那么便将引起长度的变化,最好是把长度的定义变成方法,如下: ```java class Line { Point start; Point end; public double length() { return end.distanceTo(start); } } ``` 这样消除了重复。但是如果该计算非常耗费性能,这样定义可能并不合适,还是需要为长度计算的结果,冗余出字段来保存,如下: ```java class Line { private Point start; private Point end; private double length; public void setStart(Point p) { this.start = p; calculateLength(); } private void calculateLength() { this.length = end.distanceTo(start); } public double length() { return length; } } ``` 所以,DRY 原则还是需要被辩证地看待。当然,程序中最明显的代码重复还是非常值得去处理的,将它们抽象提出来,能够 **让复用变得更容易**。 ### 2\. 继承税 **“少用继承,多用组合”** 是之前在学习设计模式时接触到的原则,但是当时我对此并没有什么感触,甚至觉得继承蛮好用的,比如在应用模板方法模式时,使用抽象类来定义方法模板。不过在书中又提到了这个原则,它称之为“继承税”,并做出了一段蛮有意思的描述: > 你想要一根香蕉,但得到的却是一只拿着香蕉的大猩猩,甚至还有整个森林 其表达的意思也不难理解:强调继承带来的父类与子类之间的 **耦合太深** 了,**父类中通用字段、方法的变更对子类来说可能带来意想不到的后果**: 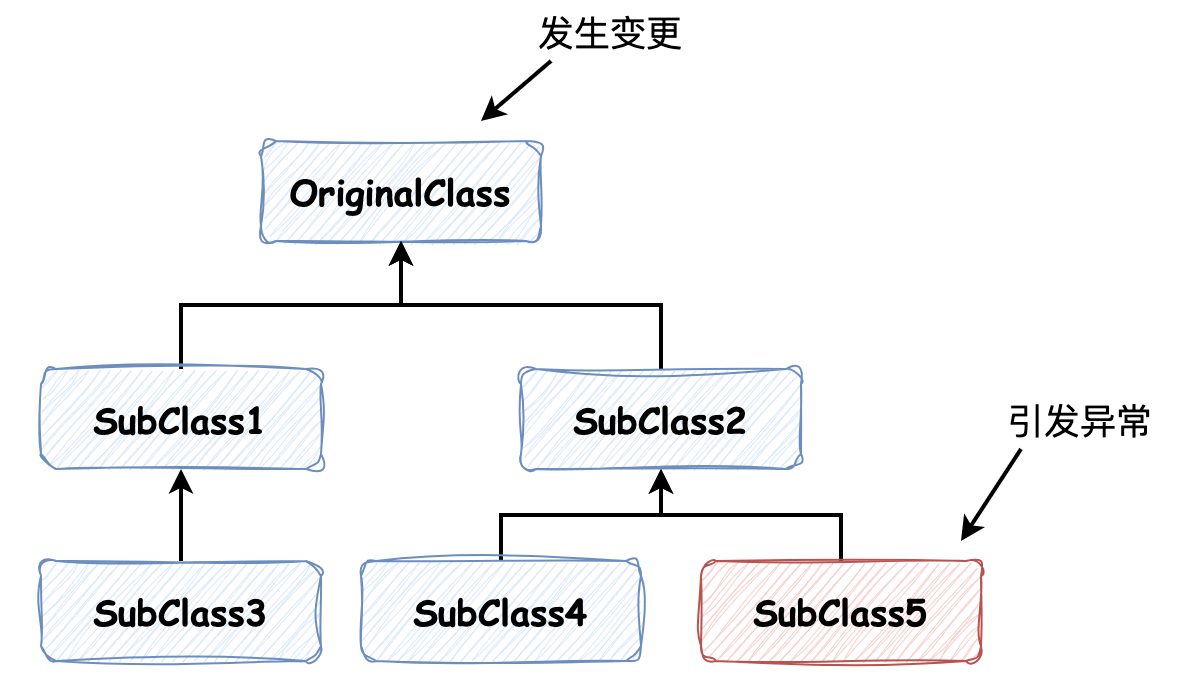 以如上继承关系为例,如果最高父类中某些内容发生变更,子类中对其使用的话,那么可能会引起子类行为的改变,而这种改变没有导致编译时异常,可能是没办法发现的,这样使得代码的可维护性大大降低,而且维护在每个类中的知识会在继承关系之间波动,暴露了太多的知识出来,做不到抽象和信息隐藏。 那么不用继承该怎么办呢? 1. 使用 **接口实现来代替类的继承**,保证多态性又不会造成信息的紧耦合 2. 使用 **组合代替继承**:比如想要香蕉,那么直接将包含香蕉的类注入进来,不再通过继承去获取了 从这也能理解为什么 C++ 语言中的多继承被诟病。此外,我觉得继承也并不能被一票否决,在 Java 源码中常用容器的实现里,都是有抽象层的(`AbstractList`, `AbstractMap` 等等),通过继承它们,实现了大量代码复用,为各种不同容器的具体实现提供了很多方便之处。但是我觉得继承能被这么应用需要具备前提条件:一是 **抽象出来的父类不会或很少再变动**;二是 **开发者变动的前提是对此有清晰的了解**。 如果不是这样,在业务代码中引入继承树,那带来的复杂性就太高了。 ### 3\. 重构 先前我对重构的观点是:如果能用,尽量避免重构,当代码实在难以满足需求时,再推翻它重新来。但是书中提出的观点则不同:**代码需要演化,它不是静态的东西。** 当遇到绊脚石或是注意到有两件事的确需要合并,又或是被其他什么事情触动而心生悔意时,那么请不要犹豫,去改掉它。并且它主张的重构是一项日复一日、小步快走的工作,并不是“大厦的倒塌重建”,这样低风险小步骤进行改造有助于使代码更易于维护和更改。 不过理想总是好的,在现实中重构总会面临一些问题: 1. **时间压力**:这个需求预计 3 天能开发完,但是为了优化代码设计和逻辑,需要增加 2 天时间。增加出的额外时间,可能并不会被接受 2. **改动带来的风险**:如何才能保证重构的影响全部在可控的范围内非常值得思考,如果重构会引发 Bug,那么开发者会宁愿重构并没有开始 事实上,时间压力并不太能站得住脚,因为随着功能增加,复杂度会不断累积,那么未来便需要投入更多的时间来修复,并且将引发更大规模的改动,带来 Bug 的风险也会增加;而对于改动带来的风险,我觉得本书强调“小步、多次”重构也是想将此风险降低,它更像是一项慢慢地、有意地、仔细地进行的活动,除此之外使重构安全的方法是在重构之后有良好的测试,如果我们有 **完善的业务场景的单元测试用例**,在重构完能及时发现问题所在,也不至于对重构这件事情畏手畏脚了。 此外,不对代码进行重构往往会触发开发者心中的“破窗效应”,在已经很难维护的代码上继续叠加功能,而不是对其进行改善,使得代码更加难以维护,还会拿“这段代码已经很烂了”作为“合理的借口”。所以,重构该成为日常开发中,需要注意和进行的活动。 > 破窗效应:一种社会心理学理论,它表明环境的恶化会导致人们行为的恶化。该理论认为,如果一个社区的某个小问题没有及时得到修复,那么这个小问题的存在就会给人一种信号,即这个地方被忽视或者管理不善。这种信号会诱使人们模仿这种不良行为,从而导致更多的窗户被破坏,最终可能导致整个社区的秩序崩溃。 ### 4\. 命名 每次提到命名或者在为接口命名时,我都会有一种非常强烈的让它自解释的想法,但是我最近这种想法的欲望逐渐降低,原因有二: 1. **阅读习惯**:对国人来说,可能大多数人没有先去读英文的习惯,更倾向于读中文相关的内容,比如注释 2. **英语水平参差**:可能有时候想要自解释的初心是好的,但是如果使接口名变成了长难句,可读性将降低 即使是这样,也并不能降低命名的标准,应该有一个适度的折中:不引入长难句,将其中难以表达的内容考虑使用注释来补充。此外,我觉得命名保持一致性也非常重要,比如在项目中对于补购已经命名为 `AddBuy`,那么便不要再引入 `SupplementaryPurchase` 和 `Replenishment` 等命名,团队内成员将知识统一才是最好的,并不在于它在英文语境下是否表达准确。但是对于这一项工作,我还没有发现团队花费心血来做这件事,如果不去翻看原有代码的话,冒然的命名可能不符合系统内现有规范,所以我觉得可以创建相关的文档或者在 `README` 中将这些命名规范记录下来,这不光降低了命名难度,而且使得团队内成员能够统一,也方便交流。 除了在方法自解释上下功夫外,方法的表达也值得注意,比如定义一个打折的方法: ```java void deductPercent(double amount); ``` `deductPercent` 扣除百分比指的是 **要做的事情**,但是扣除什么的百分比是不明确的,其次,入参 `amount` 也容易让人疑惑,是绝对值呢?还是百分数?应该有几位小数?所以,换一种方式会更好一些: ```java void applyDiscount(Percentage discount); ``` `applyDiscount` 方法名表达了折扣的意图,并且将 `double` 类型换成了对象类型,在对象中进行准确的定义,也是一种方法。当然,如果仍然采用 `double` 类型的入参也没有问题,在注释中注明容易让人迷惑的部分也是不错的方案。 ### 5\. 终 我觉得这本书更多的是在传达一种 **务实的工程师精神和责任**,不只是要编写好的代码,还要为你编写的代码负责,积极地为编码添加上 `@author` 的标志,当开发者看到你的名字时,他们能联想这段逻辑是可靠的、可读性好的和易于维护的,也是专业性的体现。 除了本文中提到的内容之外,其中还有关于基础工具的使用、编码的习惯、需求管理和人生哲学等内容,我觉得用它的结尾来作为本文的结尾也再合适不过: **你要为自己的人生做主,精心营造,与人分享,并为之喝彩!**
上一篇:移动端设备上稀奇古怪的前端问题收集(一)
下一篇:AIGC项目中的【模板进程】方案的设计实践
wy****
文章数
47
阅读量
37456
作者其他文章
01
用“分区”来面对超大数据集和超大吞吐量
1. 为什么要分区?分区(partitions) 也被称为 分片(sharding),通常采用对数据进行分区的方式来增加系统的 可伸缩性,以此来面对非常大的数据集或非常高的吞吐量,避免出现热点。分区通常和复制结合使用,使得每个分区的副本存储在多个节点上,保证数据副本的 高可用。如下图所示,如果数据库被分区,每个分区都有一个主库。不同分区的主库可能在不同的节点上,每个节点可能是某些分区的主库,同时是
01
深入理解分布式共识算法 Raft
“不可靠的网络”、“不稳定的时钟”和“节点的故障”都是在分布式系统中常见的问题,在文章开始前,我们先来看一下:如果在分布式系统中网络不可靠会发生什么样的问题。有以下 3 个服务构成的分布式集群,并在 server_1 中发生写请求变更 A = 1,“正常情况下” server_1 将 A 值同步给 server_2 和 server_3,保证集群的数据一致性:但是如果在数据变更时发生网络问题(延迟
01
缓存之美:从根上理解 ConcurrentHashMap
本文将详细介绍 ConcurrentHashMap 构造方法、添加值方法和扩容操作等源码实现。ConcurrentHashMap 是线程安全的哈希表,此哈希表的设计主要目的是在最小化更新操作对哈希表的占用,以保持并发可读性,次要目的是保持空间消耗与 HashMap 相同或更好,并支持利用多线程在空表上高效地插入初始值。在 Java 8 及之后的版本,使用 CAS 操作、 synchronized
01
缓存之美:万文详解 Caffeine 实现原理(上)
由于神灯社区最大字数限制,本文章将分为两篇,第二篇文章为缓存之美:万文详解 Caffeine 实现原理(下)文章将采用“总-分-总”的结构对配置固定大小元素驱逐策略的 Caffeine 缓存进行介绍,首先会讲解它的实现原理,在大家对它有一个概念之后再深入具体源码的细节之中,理解它的设计理念,从中能学习到用于统计元素访问频率的 Count-Min Sketch 数据结构、理解内存屏障和如何避免缓存伪
wy****
文章数
47
阅读量
37456
作者其他文章
01
用“分区”来面对超大数据集和超大吞吐量
01
深入理解分布式共识算法 Raft
01
缓存之美:从根上理解 ConcurrentHashMap
01
缓存之美:万文详解 Caffeine 实现原理(上)
添加企业微信
获取1V1专业服务
扫码关注
京东云开发者公众号




 wy****
wy**** 2024-12-05
2024-12-05 730浏览
730浏览






