



一、业务背景
在物流私域体系构建中,形成了多个微信群生态,需要投放自动回复机器人来自动化回复用户问题,希望能够用最小的成本满足基本问答。由于需要从头开始自建全流程算法问答体系,需要面临一下几个问题:
- 数据不外流:用户数属于隐私数据,不可以直接调用外部API接口,防止数据泄露。
- 回答准确:用户提问各种各样,需要精准匹配用户问题,避免“答非所问”。
- 大模型幻像:面对直接ToC业务,尽可能避免大模型产生“幻觉”,机器人已读乱回容易为公司招致法律风险。
二、技术方案
1. 项目背景:
当前现有数据为业务方提供的200+条左右的问答数据,我们需要根据用户的query来匹配问答库中最相似的知识,并整合成标准回答,返还给用户。整理流程分为召回,精排,改写,总共三个过程。
2. 技术细节
(1)数据清洗
业务方所提供数据不甚规整,是客服人员手工写的excel表格,格式很随意,需要花费一些时间将数据清洗成指定格式,我们希望的格式为query-answer对:
{"query": "更换电池时是否有旧电池回收的服务?", "answer": "电池更换时会提供一个旧电池回收的价格链接,所以更换下来的电池是不需要寄回的哦~"}
这样构造数据集的好处:
- 能够更方便为DNN模型构造正负样本标注。正样本就是本条query对应的answer,负样本就是随机选取10个其他query对应的answer
- 能够同时利用query语义信息和answer语义信息,能够匹配用户提问更加精准。
(2)数据增强
- 为什么要做数据增强?
- 现有数据量太少,难以用于支撑模型训练,需要增加数据量。
- 并且用户提问方式复杂多样,query改写有助于增加模型命中正确答案概率。
- 同一条answer中可能包含了多个知识点,可以把这些涵盖的知识点进行拆分,形成多个query- answer对,丰富知识文本库能够覆盖的范围。
- 具体怎么做的数据增强?
利用大模型的生成能力对训练数据进行改写和增加,我们提供一个示例prompt,具体可根据业务场景进行改写。值得注意的是,{question_num}这个变量为 answer的token总数除以40,即每40个token生成一个QA pair。这样能够尽可能的保证长文本被切割为多个知识点。
zh_prompt_template = """
如下三个反引号中是{product}的相关知识信息, 请基于这部分知识信息自动生成{question_num}个问题以及对应答案
```
{knowledge}
```
要求尽可能详细全面, 并且遵循如下规则:
1. 生成的内容不要超出反引号中信息的范围
2. 问题部分需要以"Question:"开始
3. 答案部分需要以"Answer:"开始
"""
- 最终整合的数据形式如下:
- 对该数据,仅需按比例切割为训练集和测试集数据即可。
- 注意:可能会有同学有疑问,由于该部分数据已经被增强过,即同一个原始QA pair经过增强后可能产生多个相似的衍生QA pair,这样的数据随机进入训练集和测试集会不会导致数据穿透、评估结果虚高?我仔细思考了一下这个问题,结合业务场景,我认为过拟合(overfit)是一个相对过程,我们的目标就是把测试集最大程度接近于线上数据,并非认为线上数据完全是陌生数据。对训练集中的类似数据能够正确识别,也算做模型的正向效果,故不认为有数据穿透的风险。
Question: 甲醛治理所用的光触媒有什么作用?
Answer: 甲醛治理通常需要用到的工具包括气泵,标准的药剂有三种:甲醛捕捉剂、TVOC清除剂和光触媒。
=====
Question: 佳能打印机使用的定影方式是什么?
Answer: 佳能打印机使用的是高温定影方式。这种方式通过高温加热使墨粉附着在纸张上,从而完成打印过程。然而,这种高温定影方式不适用于打印不干胶,因为不干胶在加热过程中会融化,可能会损坏打印机。
```
=====
Question: 对于C3326及以上机型,扫描处一次可以放多少张纸?
Answer: 您好,对于C3326及以上机型,扫描处最多可以放100张纸一起扫描。
```
=====
Question: 使用服务+ 的光触媒技术除甲醛的效果如何?
Answer: 您好,我们使用进口光触媒技术,除醛率可高达97%,并且会出具国家认证的权威CMA检测报告。我们的药剂经过权威检测机构检测,对人体无害。在不添加新污染源的前提下,治理达标后5年内,如有任何问题,您可以随时联系专家免费上门勘察。所有工程师均受过专业培训和严格评选认证,治理工具为原装进口设备。
(3)模型训练
模型部分为两个部分:召回+精排。召回层结合了传统BM25倒排索引和向量索引互补的多路召回方法,精排层采用了复杂度更高的DNN基础的rerank模型,返还最高相似度答案传递给大模型作为背景知识,再把大模型改写后的回答返回消费者。
- BM25召回:倒排索引是一种比较传统的文档检索方法,主要方法是首先对用户输入文本进行分词,然后通过BM25公式进行打分,原理不详细介绍了,感兴趣同学可自行学习。
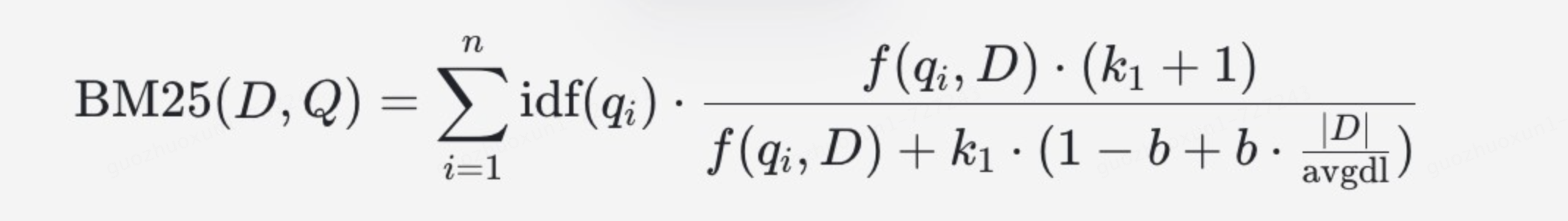
倒排召回的核心还是关键词命中逻辑,通常具有检索速度快、可解释性强等优点。但是,该方法和现有NLP模型相比,缺乏对语义信息的理解,无法理解“一词多义”等情况,容易产生语义层面的大幅偏差。
- 向量召回:
- 为了解决倒排召回语义理解不佳的问题,通常需要结合向量召回来弥补。由于向量召回多由语言模型构成,包含了对文本语义信息的理解,语义相近即可命中,无需term精准匹配。但是,向量召回缺乏对专业词汇的理解、可解释性弱、“一词多义”召回不全,这些又可以通过倒排索引弥补。故两种召回方法相辅相成。
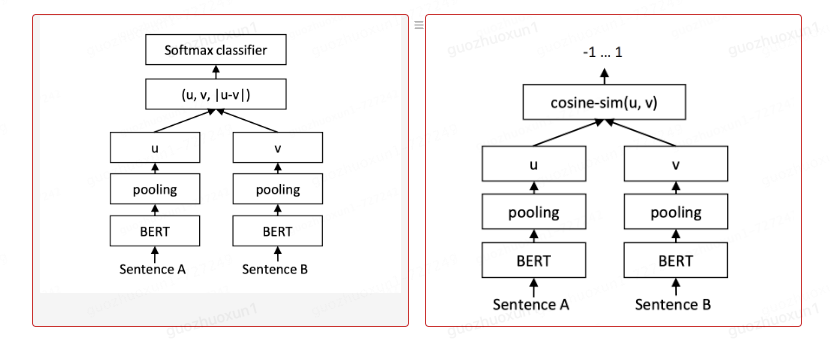
- 向量召回模型工业实践中应用较多的还是Bert为基本框架的变体,比如sentence- Bert等模型作为文本embedding获取方式。(此处没有采用现有大模型来抽象embedding,主要是因为考虑到一方面微调大模型需要更多的计算资源,GPU资源紧缺;另一方面考虑到服务部署生产会实时生成用户问答的embedding,这样直接把消费者信息传给大模型API有合规的问题。)
- 该模型的主要原理是抽象query和answer成为embedding 向量表征,再计算cos- similarity或者直接concat向量,用于下游任务计算。为了最终计算用户query- answer的余弦相似度,故采用了cos-similarity作为训练目标。此为向量召回的原理部分(论文链接挂在文末)。
- 精排模型:
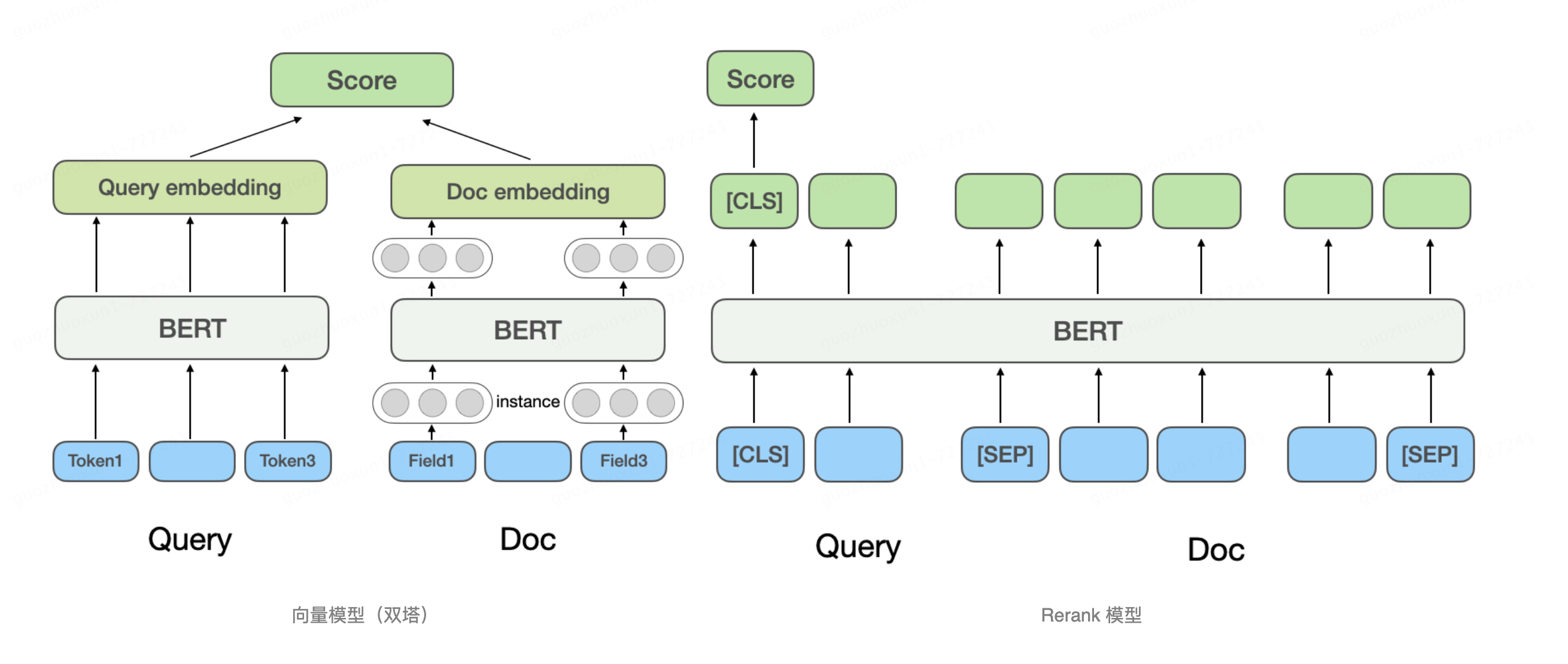
- 精排模型(重排模型)往往需要结合多路召回的结果,而多路召回的结果又不在同一个评分体系下,因此直接结合多路召回结果可能会差强人意。所以,我们决定再训练一个排序模型来对候选结果进一步打分,此处,可以对比一下向量召回模型和向量重排模型的主要差别。此处截取了aws技术文档的介绍,我觉得比较合理:左侧为向量召回模型(双塔结构),只有当query和answer分别做了embedding之后才会开始交叉,也就是全连接;而rerank模型(右侧)并不会分别对query和answer做embedding,而是在输入端就会把文本进行拼接,用[SEP]分割不同句子,直接对拼合后的长sequence每个token做embedding,也就是从底层就开始交叉,这样作会使模型参数量急剧增加,模型复杂度直线升高,适用于召回后的小样本数量排序。
- 输出阶段:
- 为了避免模型“答非所问”或者“语言生硬”,我们不能把知识库中的知识直接返还给用户,因为可能发生“用户所提问问题本身就不存在于知识库中”的问题,这种情况即便返回最相近的答案也不是用户期望得到的答案。另外,预置于知识库中的回复难免生硬、不变通,即便回答内容正确但是如果表达方式不佳,也会非常影响用户体验。基于这种考量,我门把模型选择出来的QA pair和用户真实query当作背景知识再次喂给大模型,由大模型进行二次改写,来生成最终答案。
- 另外,为解决用户提问不存在知识库中情况,需设置“拒答”兜底逻辑,避免“已读乱回”。我们需要根据具体业务场景获得拒答相似度阈值,当最高相似度文档仍低于设定阈值的情况,判定模型拒答。
(4)效果评估
下面仅展示几个向量召回对比效果的demo,用来直观感受一下finetune前后的效果。由于本实验同时利用了训练集数据中的query和answer数据,故向量召回分为了qq(query-to-query)和qa(query-to-answer)两种:
- qa召回对比finetune前后效果(左:未finetune & 右:finetune之后):
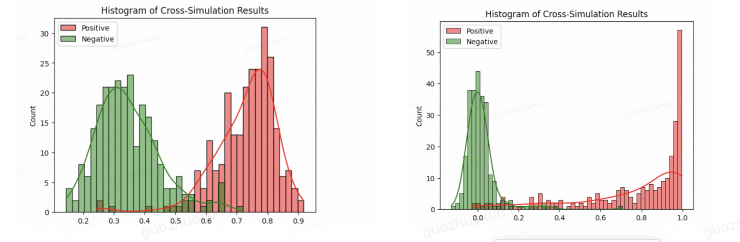
- qq召回对比finetune前后效果(左:未finetune & 右:finetune之后):
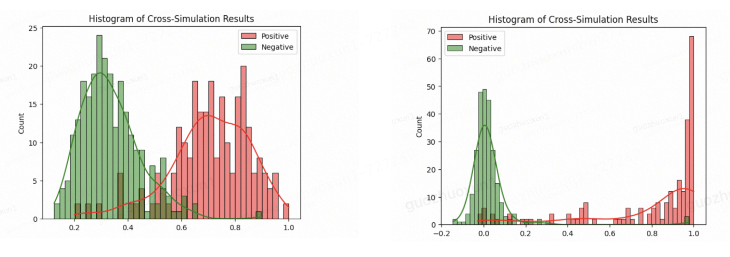
- 分析:可以从左右图对比中发现finetune后(右)的正负样本得分分布分隔更加明显,交叉程度更小,由此可见垂类模型训练的效果提升。
三、线上部署
- 本实验由于包含了复杂的模型判断、前后处理流程,故无法单独包装为torchscript、onnx等高性能模式,但是可借助九数中台或者行运构造镜像部署至生产。
四、参考资料
本方案参考了亚马逊公开的算法技术方案,并在物流场景下重训练了模型,原始参考文档如下。
这些文档里包含了git连接和部分工程代码可供借鉴:
- https://aws.amazon.com/cn/blogs/china/practice-of-knowledge-question-answering-application-based-on-llm-knowledge-base-construction-part-3/
- https://aws.amazon.com/cn/blogs/china/practice-of-knowledge-question-answering-application-based-on-llm-knowledge-base-construction-part-4/
sbert论文链接:





