



一、前言
随着系统数量增多,复杂度提高,线上应急问题时有发生;加之需投入大量人力进行服务治理和验证,为了减少日常应急问题及提前排除风险,发起对生产系统的持续综合性治理,实现常态化稳定性治理。在常态化治理过程中我们将识别问题等重复性有规律的工作实现自动化,技术人员更专注于解决问题。

二、稳定性治理常态化
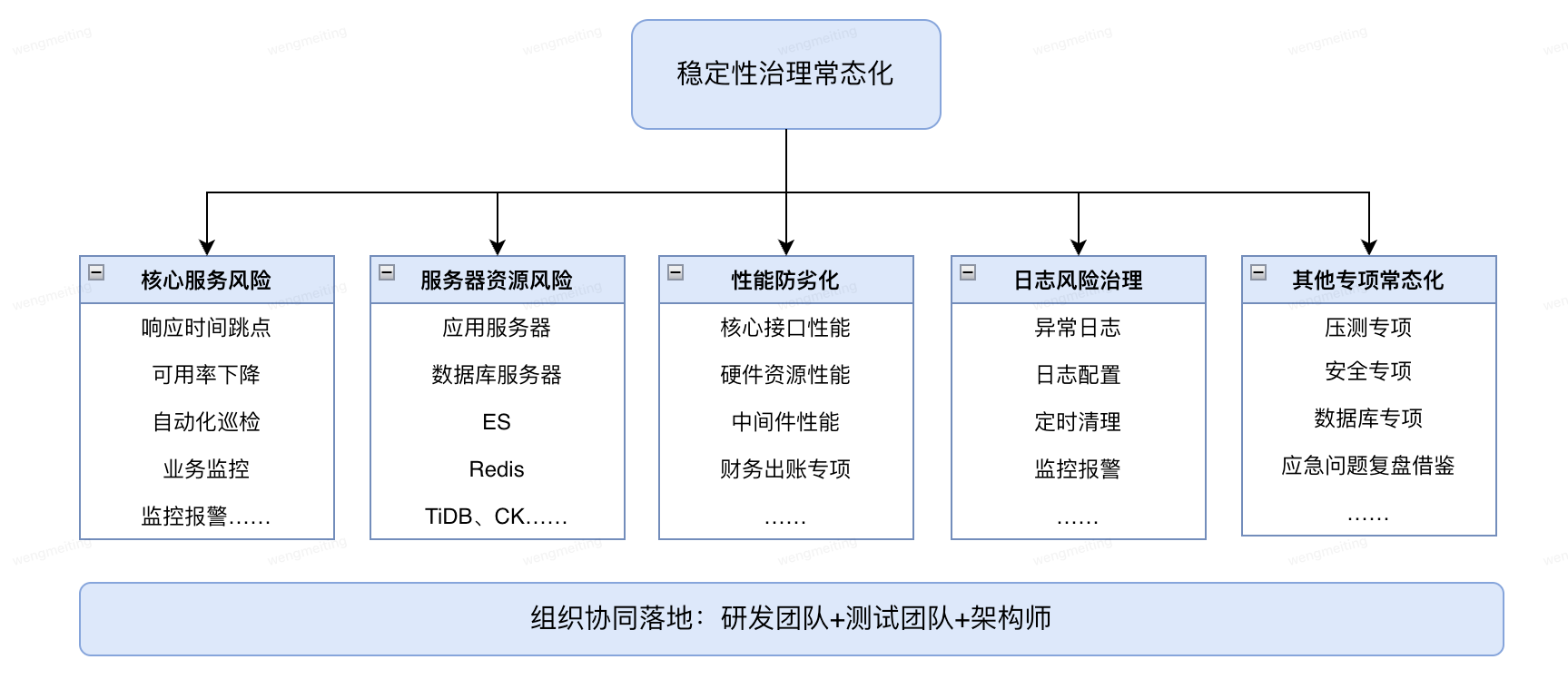
保障稳定性治理常态化,部门组建了一支由研发团队、测试团队、架构师组成的稳定性治理队伍,对部门核心应用,核心服务风险、服务器资源风险、日志风险、性能防劣化、以及技术专项等多维度持续风险识别和治理。
1、核心服务风险:重点关注服务响应时间TP99跳点、响应时间max跳点、可用率小于100%、秒级调用量1500次以上TP99性能等。
2、服务器资源风险:巡检的服务器有应用服务器、DB、MDC、ES、Redis、Tidb、ClickHouse等;关注指标:CPU、内存、磁盘、网络……;注意不同的服务器关注的指标侧重点不同。
3、性能防劣化:针对服务和资源的性能指标分析峰值、趋势、对比及偏差情况识别系统的劣化发生。服务维度:UMP调用量、响应时间、可用率;资源维度:主机CPU、内存、磁盘,数据库慢SQL、QPS;其他中间件:JVM等。
4、日志风险治理:日志问题包含异常日志治理、日志规范性、日志清理及磁盘监控、日志级别动态配置等方面。
5、其他专项常态化:性能测试覆盖日常架构升级、重点项目需求,安全测试针对代码安全、组件安全、敏感接口、数据安全的专项测试,数据库慢SQL、数据结转、主从延迟等,针对内部外的应急问题架构和质量复盘借鉴,识别自身系统可以改进提升项。
此外,应急薄弱点专项、应急演练、接口限流风险等各类稳定性保障专项持续推进。
三、稳定性治理自动化
常态化治理的痛点:部门应用多,覆盖全部应用耗费大量时间人力,当增加review项时,工作量大幅增加,落地难度增大。如何提升review效率和可落地性?
自动化解决问题
1、线上问题巡检自动化,降低重复性人力工作,研发更专注于问题优化和高可用建设。
2、丰富风险项检测,风险项扩充不会额外增加大量人力排查
3、部门全盘稳定性监控,问题检测能力复用,从核心服务review复制到全量不需要增加人力。
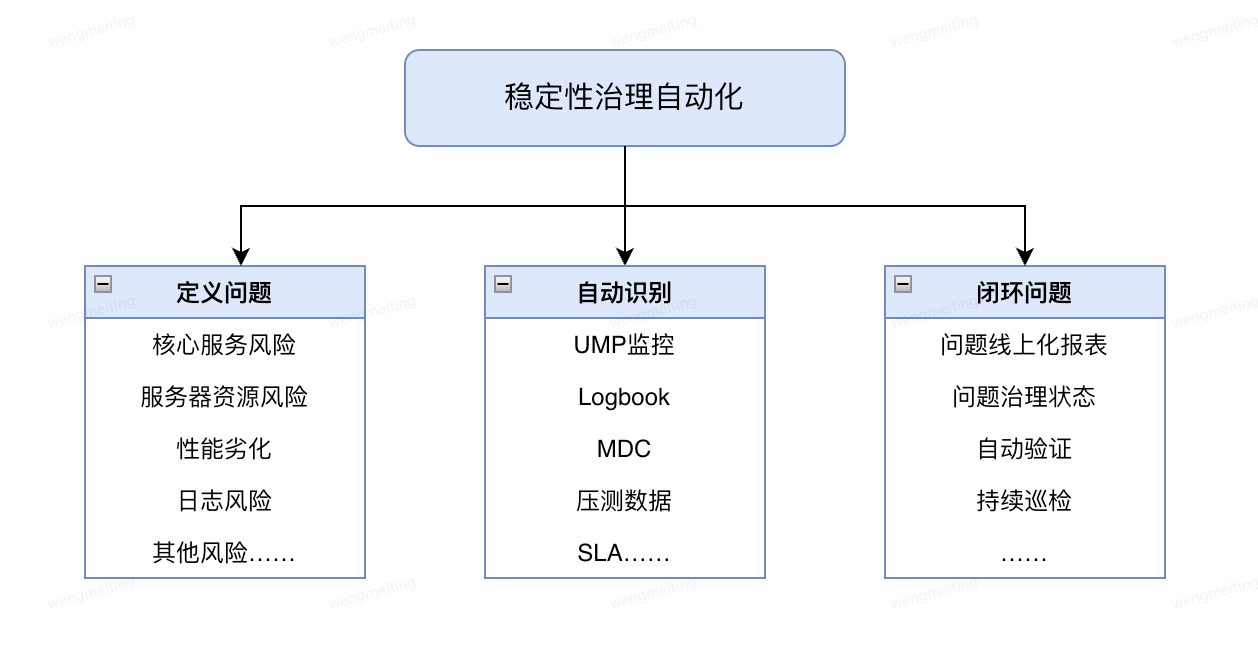
自动化过程
1、定义问题:明确指标,确定异常规则。在稳定性常态治理过程沉淀了一套覆盖核心服务风险、服务器资源风险、日志风险、性能防劣化、以及其他专项的风险项和识别方法,这部分是问题的来源。
2、自动识别:自动巡检,识别线上异常。数据来源于两部分,已有的UMP、Logbook、MDC,此外来源还有压测数据、SLA定义等。
3、闭环问题:工单跟进,提升闭环效率,通过问题线上报表跟踪治理进度,每日/每周的定时巡检,回归验证,检验修复效果。
四、治理实践
从UMP异常、资源异常、性能防劣化、logbook异常关键字、等维度线上服务稳定性治理实践案例。
1、UMP异常-可用率<100%
案例:
1、定义问题:可用率<100%
2、自动识别问题:获取T+1的UMPkey监控数据,获取可用率小于100异常点信息,统计可用率小于100的次数,最低可用率及对应的时间为辅助排查问题的依据。
3、问题跟进:UMP监控XXXServiceImpl.buildBusinessSummary可用率经常小于100%,排查因为正常业务问题未从方法监控ump可用率中剔除,通过主动上报提高报警精准度。

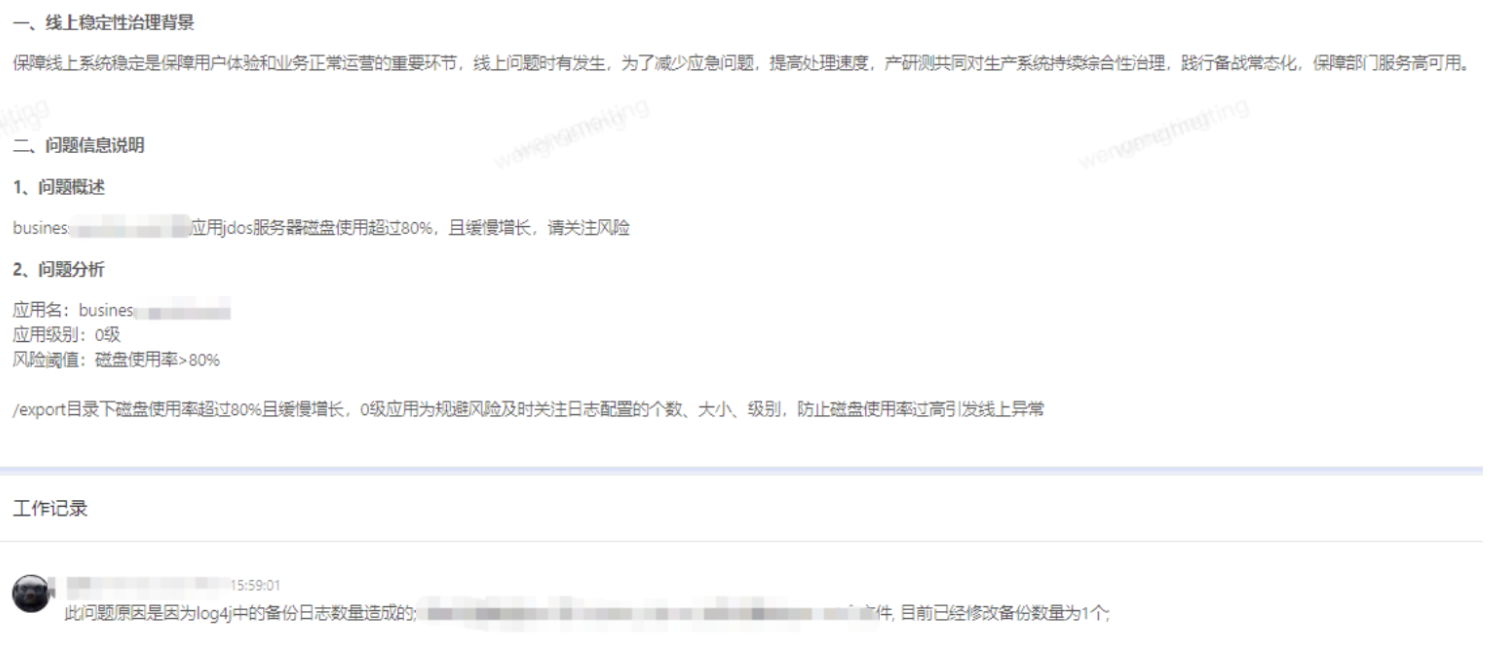
2、资源异常-磁盘使用率风险
案例:
1、定义问题:磁盘使用率>80%
2、自动识别问题:获取T+1的资源监控数据,获取磁盘/和/export的磁盘使用率>80%信息,统计出现次数,最高利用率及对应的时间。
3、问题跟进:0级应用服务器磁盘使用超过80%,优化log4j配置,补充监控报警。
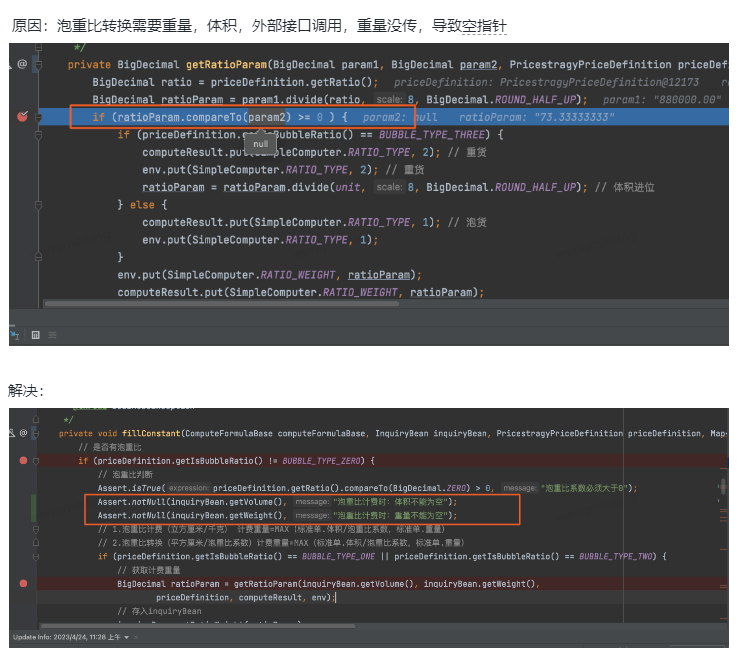
3、Logbook关键字-空指针异常
案例:
1、定义问题:
log关键字分为程序类异常和业务类异常关键字:
(1)业务类异常:业务异常时主动输出的错误日志,例如“下单失败”,各系统根据需要自行打印和配置
(2)程序类异常:程序出现预期外的异常,自动抛出的错误日志,例如:NullPointerException
2、识别问题:某应用日志报空指针异常。
4、 性能防劣化-CPU劣化
案例:CPU劣化案例
2月5日11:00-19:20之间核心鉴权服务分组机器12台服务器CPU使用率先后峰值13%到27%异常增长,并持续高于日常值,对外提供服务无明显异常,客户无感知。对服务JVM分析发现,频繁FullGC引起CPU升高,打印堆栈信息某中间件占用内存1.4G(JVM共4G),经与中间件团队沟通当前版本存在线程池资源无法释放问题。

五、结语
通过自动化的方式每日对线上核心UMP、Logbook、主机、数据库、ES、Redis风险进行巡检,降低人工review工作量。稳定性治理重在持续,过程中可能会遇到痛点和艰难,值得技术人用技术不断提升。






