您好!
欢迎来到京东云开发者社区
登录
首页
博文
课程
大赛
工具
用户中心
开源
首页
博文
课程
大赛
工具
开源
更多
用户中心
开发者社区
>
博文
>
一文理解布隆过滤器和布谷鸟过滤器
分享
打开微信扫码分享
点击前往QQ分享
点击前往微博分享
点击复制链接
一文理解布隆过滤器和布谷鸟过滤器
wy****
2024-11-06
IP归属:北京
1091浏览
最近在大促中使用到了布隆过滤器,所以本次借着机会整理下相关内容,并了解了布谷鸟过滤器,希望对后续学习的同学有启发\~ ### 布隆过滤器 布隆过滤器是 **概率性数据结构**,**用于检查元素是否存在集合中**。布隆过滤器并不存储集合中的所有元素,而是存储元素的哈希表示,因此牺牲了一些精确性:**当布隆过滤报告某元素在集合中不存在时,那么它一定不存在;报告某元素存在时,允许出现“假阳性”,有时会错误地报告某个元素在集合中,而实际上它不存在**,这样的权衡使得布隆过滤器非常节省空间且速度快。 布隆过滤器本质上是由许多位组成的数组。当一个元素 “添加” 到布隆过滤器时,该元素会被哈希,然后将位数组中索引为 `[hashval % nbits]` 的位置设为 1。这与哈希表中桶的映射方式类似,要检查一个元素是否存在,计算其哈希值,并查看相应的位是否被设置为 1。 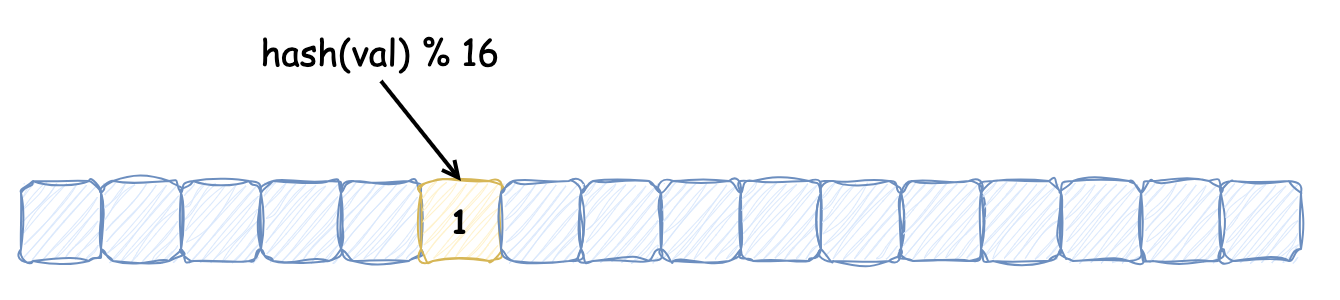 如果发生哈希碰撞,便会出现“假阳性”。为了减少碰撞风险,一个元素可以使用多个位:元素会进行多次哈希(每次哈希使用不同的 Seed 生成不同的哈希值),并将每个哈希值对应的 `hashval % nbits` 位设置为 1。要检查元素是否存在,该元素也会被多次哈希,如果有任何对应的位未被设置,则可以确定该项不存在。每个元素的位数 **在创建过滤器时已经被确定了**。通常,每个元素使用的位越多,假阳性的可能性就越低,如下所示为需要设置 3 位才能确定该元素存在的过滤器: 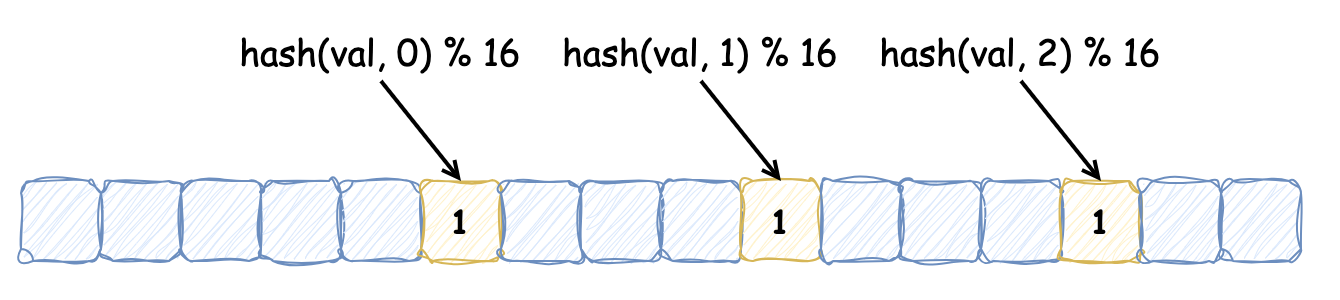 影响布隆过滤器准确度的另一个因素是填充率,即过滤器中实际设置了多少位。如果过滤器设置了绝大多数位,则任何特定查找返回 false 的可能性就会降低,过滤器误报的可能性就会增加,所以过滤器在初始化时会规定容量。 Redis 提供了 **可扩展的布隆过滤器**,来解决布隆过滤器容量固定的问题。当一个布隆过滤器达到容量时,会在其上创建一个新的过滤器。通常,新过滤器的容量比之前的更大,以减少再堆叠另一个过滤器的可能。在可扩展的布隆过滤器中,检查元素是否存在便涉及检查所有过滤器。即使是 Redis 提供了创建可扩展的布隆过滤器的功能,但是了解预期包含多少元素依然很重要,如果初始的过滤器只能包含少量元素,那么随着过滤器的扩展,性能会降低。 向布隆过滤器中插入的时间复杂度为 O(K),其中 k 为哈希函数的数量,对于扩展过滤器,检查元素的复杂度为 O(K) 或 O(K\*(n + 1)),其中 n 是已扩展的过滤器数量。 [Github - bloom](https://github.com/bits-and-blooms/bloom) 仓库是基于 Golang 实现的布隆过滤器,适合学习了解原理。因为该实现全量代码较少,所以将需要关注的逻辑全部列在下面,并表明了注释,供大家参考: ```go type BloomFilter struct { // m 位 m uint // k 个 Hash k uint // 大小为 m 的 BitSet b *bitset.BitSet } // NewWithEstimates 创建布隆过滤器,根据容量和假阳率估算(estimate)位数和要Hash的次数 func NewWithEstimates(n uint, fp float64) *BloomFilter { m, k := EstimateParameters(n, fp) return New(m, k) } // EstimateParameters 根据容量和假阳率估算 位数和Hash次数 func EstimateParameters(n uint, p float64) (m uint, k uint) { // 位数 = (p 的对数的相反数 * 容量 / 2 的对数的平方)的最接近的整数 m = uint(math.Ceil(-1 * float64(n) * math.Log(p) / math.Pow(math.Log(2), 2))) // hash次数 = (2 的对数 * 位数 / 容量) 最接近的整数 k = uint(math.Ceil(math.Log(2) * float64(m) / float64(n))) return } func New(m uint, k uint) *BloomFilter { return &BloomFilter{max(1, m), max(1, k), bitset.New(m)} } func max(x, y uint) uint { if x > y { return x } return y } // Add 添加新的元素到布隆过滤器中,支持链式编程 func (f *BloomFilter) Add(data []byte) *BloomFilter { // 添加验证容量大小的逻辑,如果超过了提示 warn 信息 // four unit64 h := baseHashes(data) for i := uint(0); i < f.k; i++ { // 调用 bitset.BitSet 的 `Set` 方法,将计算出的位置添加到布隆过滤器中 f.b.Set(f.location(h, i)) } return f } // Test 检查某元素是否在布隆过滤器中 func (f *BloomFilter) Test(data []byte) bool { h := baseHashes(data) for i := uint(0); i < f.k; i++ { if !f.b.Test(f.location(h, i)) { return false } } return true } // baseHashes 计算元素的四个哈希值,用于 k 次哈希计算 func baseHashes(data []byte) [4]uint64 { var d digest128 // murmur hashing hash1, hash2, hash3, hash4 := d.sum256(data) return [4]uint64{ hash1, hash2, hash3, hash4, } } // 将第 i 个哈希位置映射到布隆过滤器的位数组中 func (f *BloomFilter) location(h [4]uint64, i uint) uint { return uint(location(h, i) % uint64(f.m)) } // 计算第 i 个哈希值 func location(h [4]uint64, i uint) uint64 { ii := uint64(i) return h[ii%2] + ii*h[2+(((ii+(ii%2))%4)/2)] } ``` #### 应用布隆过滤器 Redisson 提供了操作布隆过滤器的简单易用 API,以下是使用布隆过滤器的示例: * 引入依赖 ```xml <dependency> <groupId>org.redisson</groupId> <artifactId>redisson</artifactId> <version>3.37.0</version> </dependency> ``` * 使用示例 ```java private void redisson() { RedissonClient redissonClient = Redisson.create(); RBloomFilter<Object> bloomFilter = redissonClient.getBloomFilter("bloomFilter"); // 初始化大小为 10亿,假阳率为 0.001(在使用布隆过滤器之前,必须完成初始化操作) bloomFilter.tryInit(1000000000, 0.001); Object object = new Object(); // 添加元素 bloomFilter.add(object); // 检查元素是否存在 boolean exist = bloomFilter.contains(object); } ``` Guava 也提供了 BloomFilter 实现,用于高效地判断一个元素是否存在于集合中,在 23.0 及之后版本中,是线程安全的。以下是 Guava 中布隆过滤器使用示例: * 引入依赖 ```xml <dependency> <groupId>com.google.guava</groupId> <artifactId>guava</artifactId> <!-- 请根据需要选择合适的版本 --> <version>33.3.1-jre</version> </dependency> ``` * 使用示例 ```java import com.google.common.hash.BloomFilter; import com.google.common.hash.Funnels; public class BloomFilterExample { public static void main(String[] args) { // 创建一个布隆过滤器,预计插入 3000000 个整数,假阳率为0.01 BloomFilter<Integer> bloomFilter = BloomFilter.create( Funnels.integerFunnel(), 3000000, 0.01); // 向布隆过滤器中添加元素 for (int i = 0; i < 3000000; i++) { bloomFilter.put(i); } // 测试布隆过滤器 for (int i = 0; i < 3001000; i++) { if (bloomFilter.mightContain(i)) { System.out.println(i + " might be in the filter."); } else { System.out.println(i + " is definitely not in the filter."); } } } } ``` *** ### 布谷鸟过滤器 布隆过滤器不记录元素本身,并且存在一个位被多个元素共用的情况,所以它不支持删除元素。布谷鸟过滤器(详细了解可以参考这篇论文[《布谷鸟过滤器:实际上优于布隆过滤器》](http://www.linvon.cn/posts/cuckoo/))的提出解决了这个问题,它**支持删除操作**,此外它还带来了其他优势: 1. **查找性能更高**:布隆过滤器要采用多种哈希函数进行多次哈希,而布谷鸟过滤器只需一次哈希 2. **节省更多空间**:布谷鸟过滤器记录元素更加紧凑,论文中提到,如果期望误报率在 3% 以下,半排序桶布谷鸟过滤器每个元素所占用的空间要比布隆过滤器中单个元素占用空间要小 > 布谷鸟过滤器之所以被称为“布谷鸟”,是因为它的工作原理类似于布谷鸟在自然界中的行为。布谷鸟以将自己的蛋产在其他鸟类的巢中而闻名,这样一来,寄主鸟就会抚养布谷鸟的幼鸟。 </n> > 在布谷鸟过滤器中,如果一个位置已经被占用,新元素会“驱逐”现有元素,将其移到其他位置。这种“驱逐”行为类似于布谷鸟将其他鸟蛋推出巢外,以便安置自己的蛋。因此,这种过滤器得名为“布谷鸟”过滤器。 布谷鸟过滤器本质上是一个 **桶数组**,每个桶中保存若干数量的 **指纹**(指纹由元素的部分 Hash 值计算出来)。定义一个布谷鸟过滤器,每个桶记录 2 个指纹,5 号桶和 11 号桶分别记录保存 a, b 和 c, d 元素的指纹,如下所示: 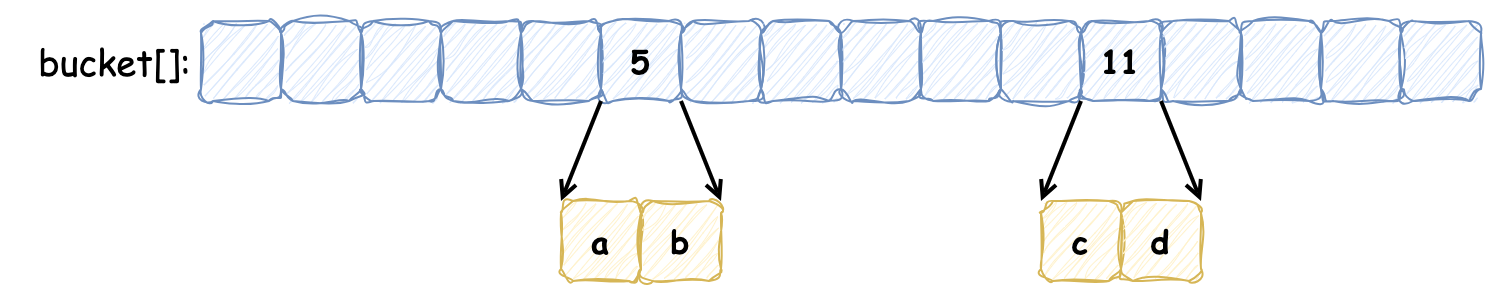 此时,向其中插入新的元素 e,发现它被哈希到的两个候选桶分别为 5 号 和 11 号,但是这两个桶中的元素已经添加满了: 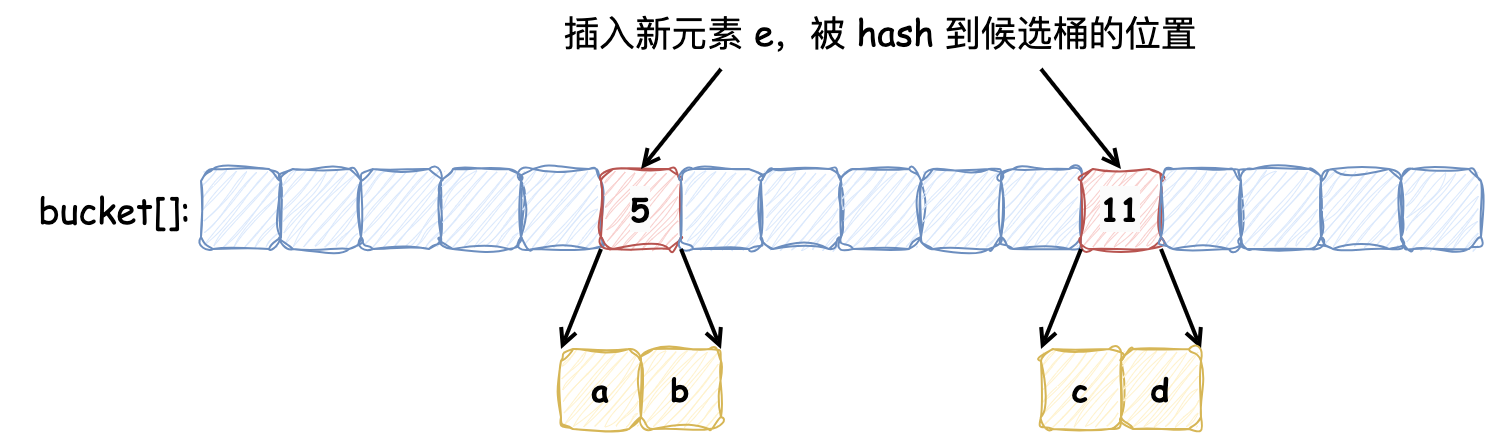 按照布谷鸟过滤器的特性,它会将其中的一个元素重哈希到其他的桶中(具体选择哪个元素,由具体的算法指定),新元素占据该元素的位置,如下: 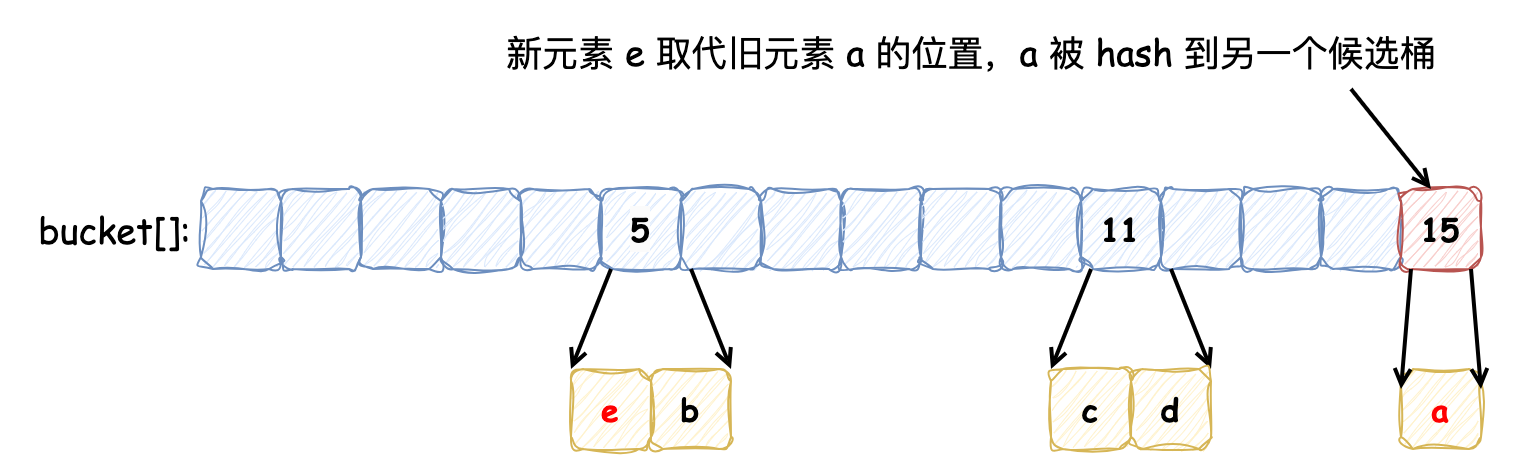 以上便是向布谷鸟过滤器中添加元素并发生冲突时的操作流程,在我们的例子中,重新放置元素 e 触发了另一个重置,将现有的项 a 从桶 5 踢到桶 15。**这个过程可能会重复,直到找到一个能容纳元素的桶,这就使得布谷鸟哈希表更加紧凑,因此可以更加节省空间**。如果没有找到空桶则认为此哈希表太满,无法插入。虽然布谷鸟哈希可能执行一系列重置,但其均摊插入时间为 **O(1)**。 与布隆过滤器一样,布谷鸟过滤器同样会造成假阳性,造成假阳性的有以下原因: 1. **有限的空间**:布谷鸟过滤器使用有限数量的桶和每个桶中的有限空间来存储元素的指纹。当多个元素的指纹映射到相同的桶时,可能会导致不同元素的指纹存储在同一位置 2. **指纹冲突**:由于指纹是元素的哈希值的缩减版本,可能会有不同的元素产生相同的指纹。当查询一个不存在的元素时,可能会发现其指纹已经存在于过滤器中,从而导致假阳性 3. **哈希函数的性质**:哈希函数的选择和指纹长度决定了指纹的唯一性和冲突概率。较短的指纹更容易产生冲突,从而增加假阳性的概率 4. **负载因子**:随着过滤器接近满载,冲突的概率增加,这会导致更多的“驱逐”操作。在高负载情况下,假阳性率也可能上升 [Github - cuckoofilter](https://github.com/seiflotfy/cuckoofilter) 是 Github 上 Star 数较多的一个仓库,它参考了论文内容,并用 Golang 实现了布谷鸟过滤器,大家感兴趣的话可以直接去参考它的源码。该过滤器重要的参数如下: 1. 每个元素有 2 个候选桶,每个桶记录 4 个指纹:该配置能够使桶的利用率达到 95%,能够满足多数场景,当指定假阳性率在 0.00001 和 0.002 之间时,可以将每个元素占用空间最小化 2. 指纹的静态大小为 8 位:指定误报率为 0.03,根据公式 `f >= log2(2b/r)` b为桶的大小 r为误报率,计算出指纹大小为 8。在 2 个候选桶和 4 个指纹的配置下,随着指纹大小变大,空间利用率不会再随之增加,仅降低假阳率 我们在此讨论下它的删除方法实现: ```go // Delete 删除过滤器中的指纹 func (cf *Filter) Delete(data []byte) bool { // 尝试在首选桶中删除 i1, fp := getIndexAndFingerprint(data, cf.bucketPow) if cf.delete(fp, i1) { return true } // 删除失败,则尝试从备用桶删除 i2 := getAltIndex(fp, i1, cf.bucketPow) return cf.delete(fp, i2) } ``` 它的删除方法实现比较简单:它检查给定元素的两个候选桶,如果在首选桶中匹配到则将该指纹移除,否则去备用桶中匹配,在备用桶中则移除备用桶指纹,如果备用桶中没有,则会提示删除失败。如果两个元素 a, b 发生碰撞(共享桶和指纹),那么在 a 元素删除后,因为 b 元素的存在,仍然会判断 a 元素在过滤器中,表现出假阳性。需要注意的是,**想要安全的删除某元素,必须事先插入它**,否则删除插入项可能会无意中删除共享指纹的真实存在的项,而且如果多次插入重复元素,想要将其删除干净还需要知道该元素插入了多少次。 此外,相比于布隆过滤器它也存在一些的劣势: 1. **插入性能可能会受到影响**:随着插入元素越多,空间利用率不断提高,发生冲突的可能性越大,发生冲突之后,可能会不断的触发元素的重定位,插入性能会变差,一般通过最大重试次数来限制 2. **插入重复元素次数存在上限**:布隆过滤器插入重复元素没有负面影响,只是再标记相同的位,而布谷鸟过滤器插入重复元素会触发元素的重定位,因此它的重复元素插入存在上限 对于过滤器缓存的使用,大部分情景都是读多写少的,而重复插入并没有什么意义,布谷鸟过滤器的删除虽然不完美但总好过没有(因为布隆过滤器想要删除元素便需要重建,上亿甚至几十亿的数据重建缓存也蛮花时间),同时还有更优的查询和存储效率,应该说在绝大多数情况下其都是一个性价比更高的选择。 *** ### 适用场景 * **检测用户名是否存在**:将所有已注册用户名使用布隆过滤器,新用户创建用户名时,检查该用户名是否存在于布隆过滤器中 * **广告投放**:为每个用户创建一个布隆过滤器,保存所有已购买的商品,在进行商品广告投放时,检查该商品是否在布隆过滤器中 > **延保业务实践**:商城订单详情页延保信息只有在商品进入完成态时才有。在大促期间,用户在购买完商品时,会习惯性点击订详查看,此时会有大量的无效请求进来,直接查询数据库,为了避免数据库击穿,将所有完成的订单保存在布隆过滤器中,这样便能过滤大量请求 *** ### 巨人的肩膀 * [Redis - Bloom filter](https://redis.io/docs/latest/develop/data-types/probabilistic/bloom-filter/) * [Github - bloom](https://github.com/bits-and-blooms/bloom) * [Redisson - Bloom filter](https://redisson.org/docs/data-and-services/objects/#bloom-filter) * [Redis - Cuckoo filter](https://redis.io/docs/latest/develop/data-types/probabilistic/cuckoo-filter/) * [Linvon - 布谷鸟过滤器:实际上优于布隆过滤器](http://www.linvon.cn/posts/cuckoo/) * [COOLSHELL - Cuckoo Filter:设计与实现](https://coolshell.cn/articles/17225.html) * [木鸟杂技 - 布谷鸟哈希和布谷鸟过滤器](https://www.qtmuniao.com/2021/12/07/cuckoo-hash-and-cuckoo-filter/) * [Github - cuckoofilter](https://github.com/seiflotfy/cuckoofilter)
上一篇:探索设计稿自动生成Flutter代码的技术方案
下一篇: AI对话魔法|Prompt Engineering 探索指南
wy****
文章数
47
阅读量
44195
作者其他文章
01
用“分区”来面对超大数据集和超大吞吐量
1. 为什么要分区?分区(partitions) 也被称为 分片(sharding),通常采用对数据进行分区的方式来增加系统的 可伸缩性,以此来面对非常大的数据集或非常高的吞吐量,避免出现热点。分区通常和复制结合使用,使得每个分区的副本存储在多个节点上,保证数据副本的 高可用。如下图所示,如果数据库被分区,每个分区都有一个主库。不同分区的主库可能在不同的节点上,每个节点可能是某些分区的主库,同时是
01
深入理解分布式共识算法 Raft
“不可靠的网络”、“不稳定的时钟”和“节点的故障”都是在分布式系统中常见的问题,在文章开始前,我们先来看一下:如果在分布式系统中网络不可靠会发生什么样的问题。有以下 3 个服务构成的分布式集群,并在 server_1 中发生写请求变更 A = 1,“正常情况下” server_1 将 A 值同步给 server_2 和 server_3,保证集群的数据一致性:但是如果在数据变更时发生网络问题(延迟
01
缓存之美:从根上理解 ConcurrentHashMap
本文将详细介绍 ConcurrentHashMap 构造方法、添加值方法和扩容操作等源码实现。ConcurrentHashMap 是线程安全的哈希表,此哈希表的设计主要目的是在最小化更新操作对哈希表的占用,以保持并发可读性,次要目的是保持空间消耗与 HashMap 相同或更好,并支持利用多线程在空表上高效地插入初始值。在 Java 8 及之后的版本,使用 CAS 操作、 synchronized
01
缓存之美:万文详解 Caffeine 实现原理(上)
由于神灯社区最大字数限制,本文章将分为两篇,第二篇文章为缓存之美:万文详解 Caffeine 实现原理(下)文章将采用“总-分-总”的结构对配置固定大小元素驱逐策略的 Caffeine 缓存进行介绍,首先会讲解它的实现原理,在大家对它有一个概念之后再深入具体源码的细节之中,理解它的设计理念,从中能学习到用于统计元素访问频率的 Count-Min Sketch 数据结构、理解内存屏障和如何避免缓存伪
wy****
文章数
47
阅读量
44195
作者其他文章
01
用“分区”来面对超大数据集和超大吞吐量
01
深入理解分布式共识算法 Raft
01
缓存之美:从根上理解 ConcurrentHashMap
01
缓存之美:万文详解 Caffeine 实现原理(上)
添加企业微信
获取1V1专业服务
扫码关注
京东云开发者公众号




 wy****
wy**** 2024-11-06
2024-11-06 1091浏览
1091浏览






