



背景
采购系统(BIP)在经历多年演进后,系统整体复杂度和数据量俨然已经极具规模,本文着重讨论海量数据的治理
存储现状:工程端实时订单库采用MySQL 5.5集群,其中主库配置为32C/48G/6000G,无法归档的订单热数据占磁盘空间85%(5.1T)
痛点:6T磁盘已经单容器最大,无法继续扩容,剩余磁盘余量过小,难适应未来发展
目标
降低磁盘容量,优化数据模型,提升系统稳定性
调研
首先,既然是要解决存储容量的问题,就要对详细的容量情况有个更加清楚的了解。总结下当前存储容量问题,最大的表是订单操作日志表lifecycle共1.3T,大于500G的表2张共1.5T;100G~500G的表10张共2.6T。以下是优化前库里大表(大于100G)的详细空间占用情况:
| 序号 | 表名 | 空间大小(行数|总大小|数据大小|索引大小) |
|---|---|---|
| 1 | lifecycle | 46亿 | 1.3T | 856G | 328G |
| 2 | cgfenpei | 5.8亿 | 665G | 518G | 147G |
| 3 | cgtable | 5.8亿 | 491G | 287G | 204G |
| 4 | cgdetail | 5.5亿 | 405G | 308G | 97G |
| 5 | po_asn_receipt_detail | 4.5亿 | 351G |167G | 184G |
| 6 | po_data | 2.5亿 | 321G | 312G | 9G |
| 7 | purchase_order_extension | 4.2亿 | 293G | 166G | 127G |
| 8 | po_stock_detail | 7.3亿 | 204G | 104G | 100G |
| 9 | po_channel | 6.1亿 | 191G | 70G | 121G |
| 10 | cgtablesubtable | 6亿 | 154G | 62G | 92G |
| 11 | unduprecord | 4.2亿 | 138G | 138G | 0G |
| 12 | po_stock | 2.8亿 | 126G | 63G | 63G |
| 合计 | 4.6T |
其次,确认当前最高效的优化思路是将lifecycle表迁移到其他库,原因有二:1.lifecycle表的含义是操作日志,在业务上不算订单域内最核心的模型,风险可控;2.占用空间大,单表46亿行数据,空间占用1.3T,一张表占了磁盘空间的22%,优化的ROI高
最后,想说明下,为什么没有直接将整个库,从传统MySQL切换到JED,原因也有二:1.JED和MySQL的查询语法还是有一定差异,直接切换,成本和风险极高;2.切换存储中间件,获取分布式架构下更大的存储空间并不是银弹,理智告诉我们要结合系统现状,不可盲目下定论
挑战
保障海量数据(存量46亿行,增量600w+行/天,TPS峰值:500+,QPS峰值:200+)迁移期间读、写稳定和准确。需要补充一下:lifecycle虽然不算订单最核心业务模型,但依旧是辅助业务决策的关键数据,也非常重要
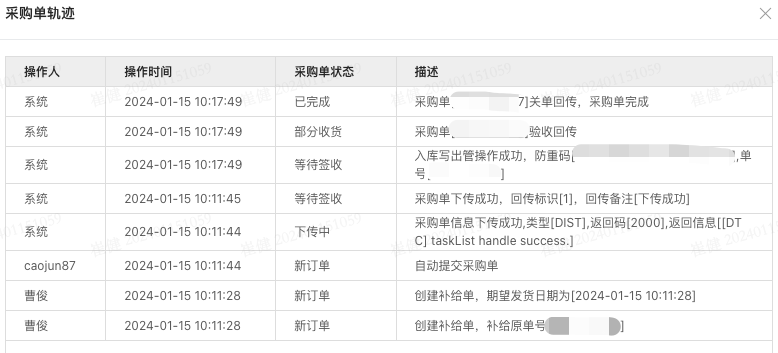
例子:
方案
整体方案
数据同步 -> 双读 -> 双写 -> 离线验证 -> 数据清理
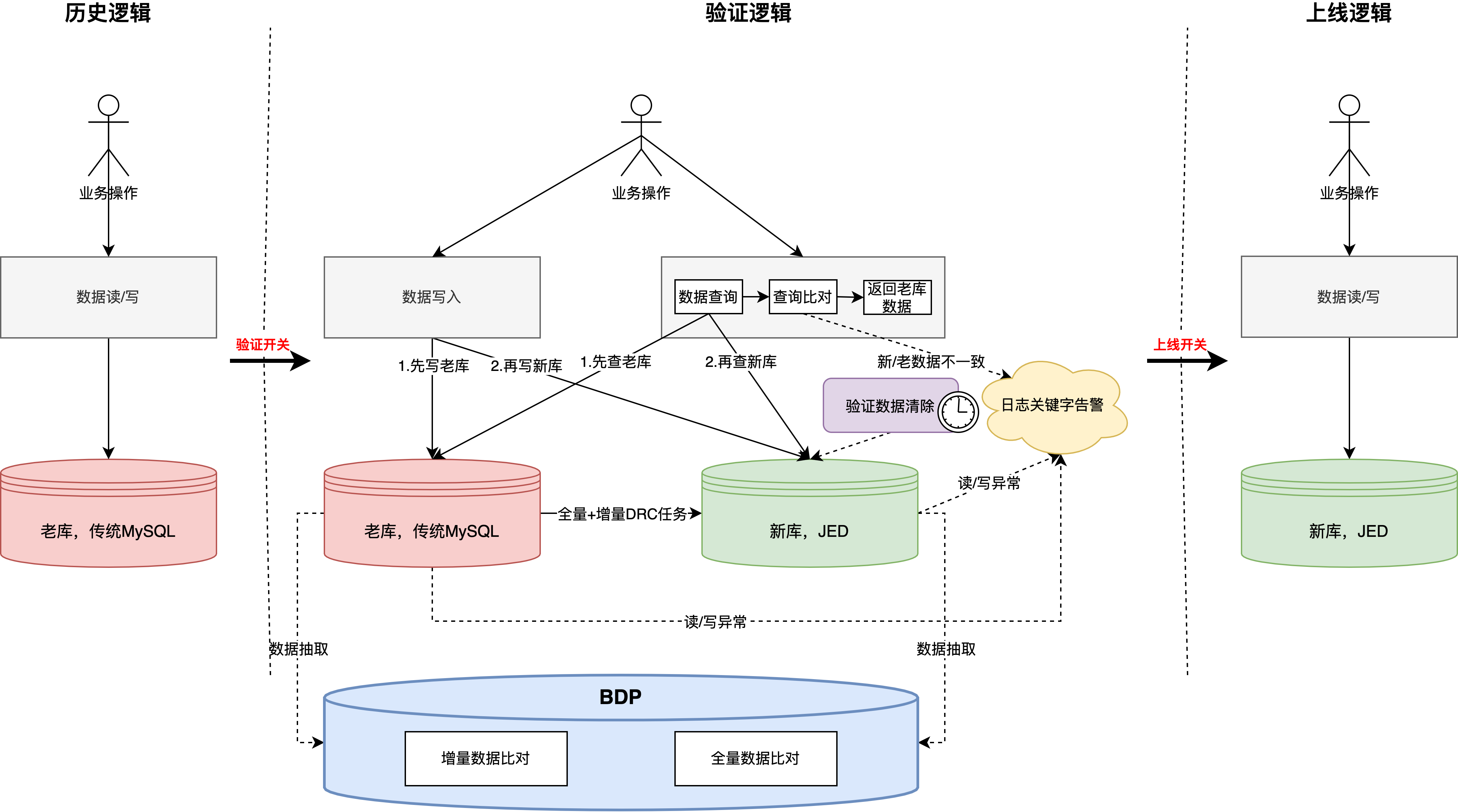
详细设计
- 数据同步,通过DRC实现,历史全量+增量,其中有以下几点使用心得:
- 同步速度问题,本次是使用传统MySQL5.5 -> JED 底层MySQL 8.0 单表同步,效率大概是4M/S,一共花了3天半左右
- 数据同步过程中不要操作暂停,否则任务重启后,会重新同步历史数据,导致数据同步周期变长。详情参考: 关于全量任务暂停重启之后数据同步慢的原因
- 字段兼容问题,老库历史时间字段类型是datetime,新库需要改为datetime(3),这种数据同步是可以兼容的(下文会讲为什么要优化时间字段精度)
- 数据验证问题,当时在历史数据全量同步完毕后开启了DRC数据验证,但是许久未执行完成,收到DRC运维告知出现大量报错,最终结论是暂时不支持这两个版本的数据比对(5.5->8.0),这也是为什么整体架构上采用BDP抽数比对数据的主要原因
- 数据验证,业务程序完成双写、双读改造
- 双写
- 为什么采用双写?答:控制风险。1.团队内还没有应用直接写入多分片JED的先例,而且新、老库的底层MySQL版本也差异比较大(5.5 vs 8.0),当时通过分批次灰度上线完成逐步切量验证;2.方便进行数据验证,lifecycle是业务操作日志,基本涵盖了所有的写入场景,其中因为历史问题,不乏一部分逻辑和订单更新在同一事务中,现在迁移到新库,本地事务会存在不生效的场景
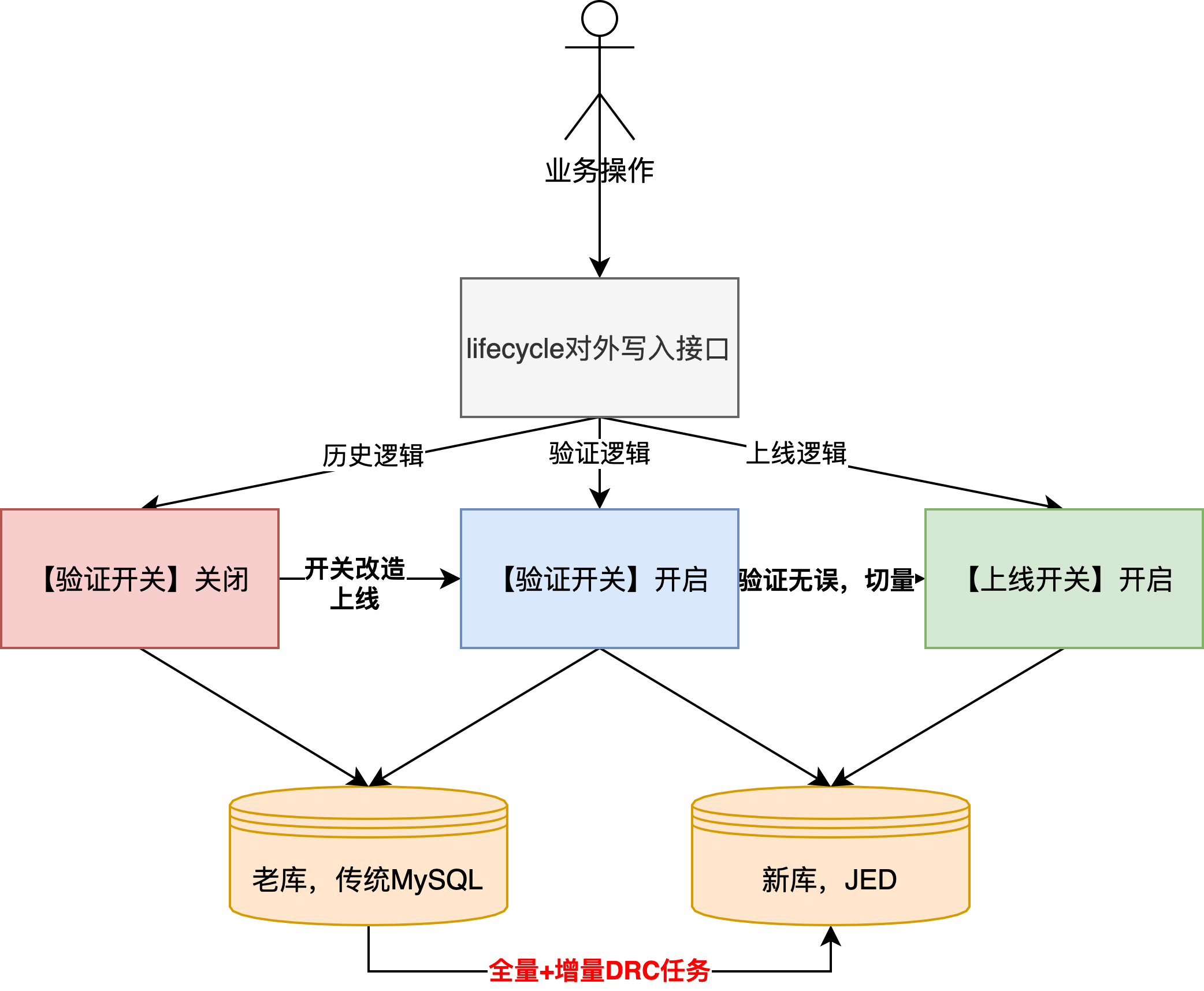
- 具体改造方案:
- 新增【验证开关】,开启后新/老库双写,另外需要要引入vitess驱动,目前只支持JDK8及以上
- 新增【上线开关】,开启后只写新库,此开关是在验证逻辑无问题后,最终切换的开关,代表迁移完成
- 注意,开关改造完成上线后,“全量+增量DRC任务”在验证期间是一直启用的,也就是说验证期间,增量数据会写两份到新库
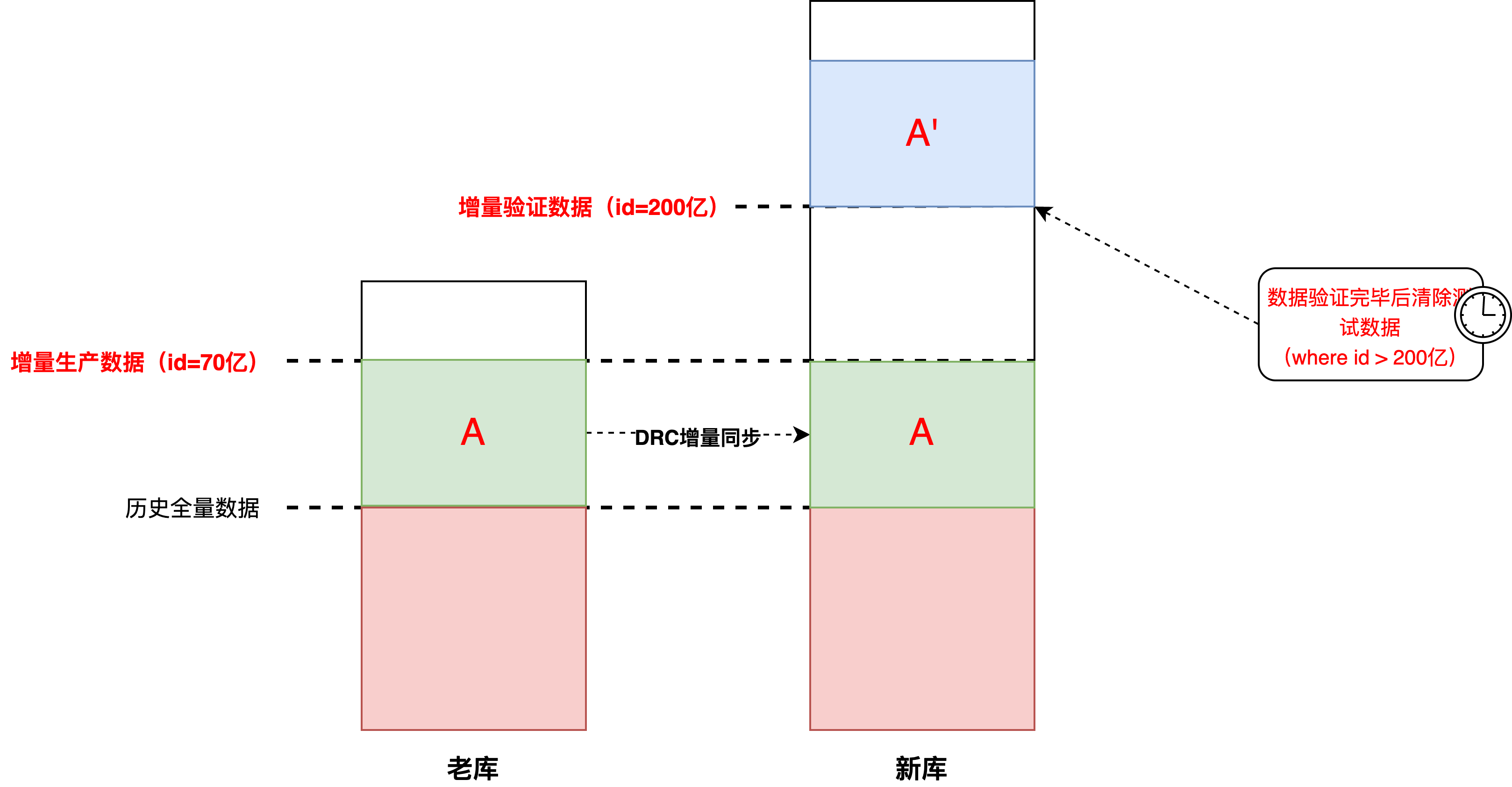
- 一部分是实际的生产数据,一部分是待验证的测试数据。那么就带来另一个问题,如何识别和区分这两部分数据,我们采用的方案是:JED建表指定趋势自增的最小id(200亿)+【验证开关】开启的时间戳进行区分
- 如下图,其中A和A'都是【验证开关】切换后的增量数据,由于老库的id已经自增写到了70亿,并且DRC同步任务也是指定id写入,所以建表时指定新增数据id是200亿(详情参考: 数据库自增ID列设置 ),和老数据之间存在一定gap方便识别。BDP脚本数据比对的也是:老库.A和新库.A'(这里默认DRC增量同步的数据是准确的)
- 清除测试数据,真正完成【上线开关】切换,需要提前清除测试数据,只需指定id>200亿的物理删除即可。注意:针对多分片的JED物理删除delete语句,我们程序上如果为了防止大事务,而采用“for循环+limit n”的方式执行,实际的每次SQL语句执行结果是多个分片的n的聚合,而不是n,如果程序上对结果有判断逻辑,需要额外注意
- 双读
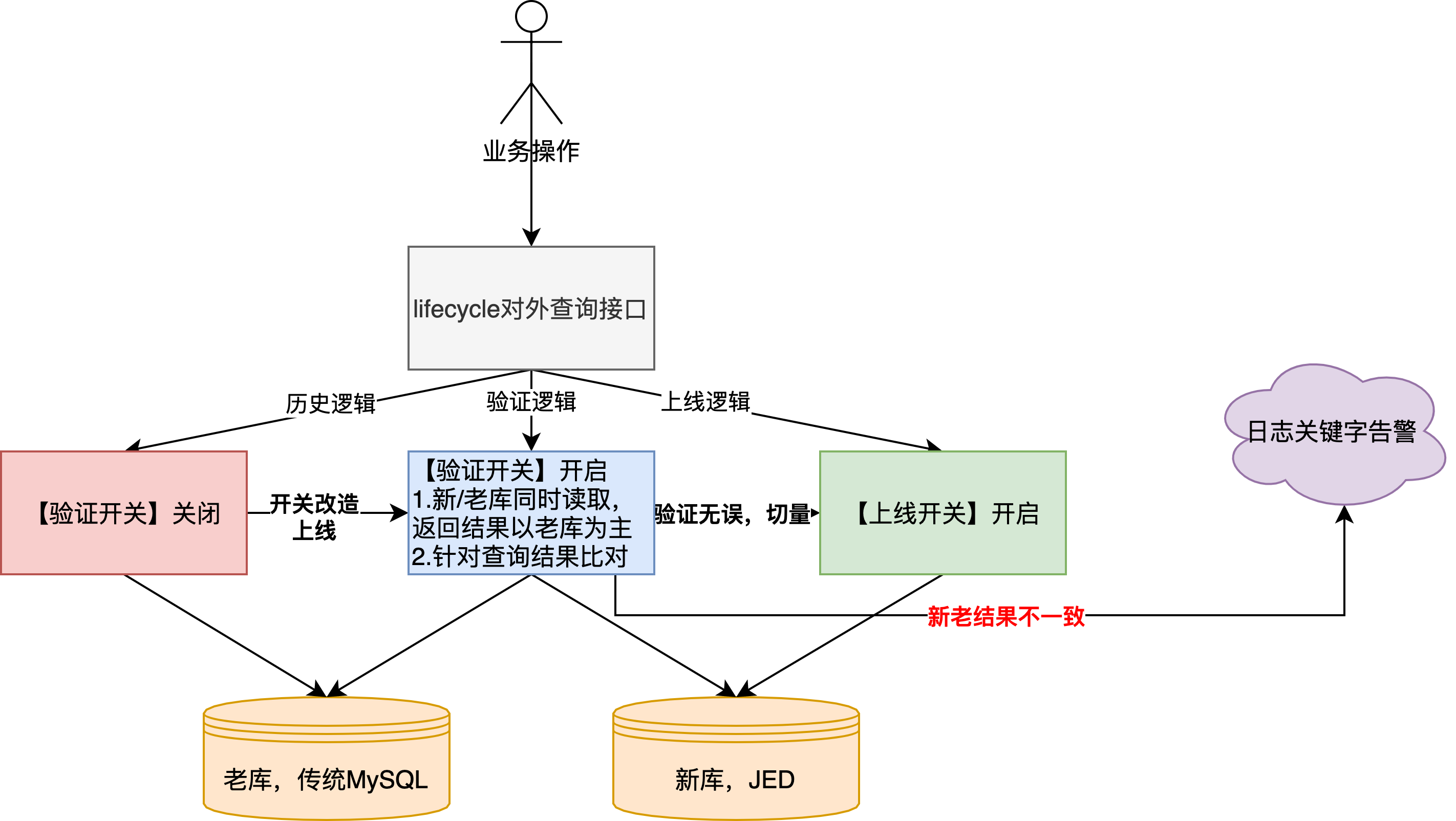
- 整体逻辑基本复用写入期间已有开关,其中针对新库当中DRC实时同步的数据(上图:新库.A)会根据开关开启时间进行过滤
- 其中,在验证期间,新、老库都会根据采购单号进行查询并实际返回老库的查询结果,其中还会进行结果比对,出现数据不一致会输出异常日志关键字
- 另外,因为lifecycle操作日志数据是有先后顺序的,老库的处理方式是根据自增id进行倒排,到了新库以后,由于采用的是JED分片(分布式存储的磁盘空间更大),考虑到开发成本,数据id采用的是趋势递增的自增主键(详情参考: Vitess全局唯一ID生成的实现方案 ),这时多集群并行写入无法继续使用基于id倒排的方式返回结果(后写入的数据可能id较小,可以参考sequece发号器的ID生成),所以将原始的数据写入时间戳从datetime提高精度到datetime(3),通过数据写入时间进行倒排,这里也解释了上文,新库DRC数据同步为什么要考虑字段兼容的问题
- 补充1:这里基于时间倒排在业务上是准确的,因为lifecycle数据是根据订单号进行分片的,所以同一订单一定落在单分片上,也就是说不存在不同分片时钟偏移的问题,单订单的操作日志的时间序列一定是按照写入顺序逐渐增加的
- 补充2:新库字段类型变更(datetime->datetime(3)),32分片,共46亿行数据,执行了大概1小时,期间主从延迟最高30分钟,容器负载正常
- 补充3:应用的关键字告警配置,日志文件仅支持以error.log、err.log、exception.log结尾,并开启历史日志的路径
- 最后,双读期间共通过业务的实际查询流量发现数据不一致问题2个+,在并未影响到业务使用的前提下及时发现了系统异常
- 离线验证
- lifecycle归根结底还是写多读少的业务场景,为了防止出现上文数据比对验证的遗漏,我们会采用BDP离线任务会分别开启增量数据+历史全量数据验证。通过对新、老库的全量数据字段相互sql inner join的方式完成比对,其中会忽略id和写入时间,因为新库的id不是单调递增、时间精确到了毫秒。期间共发现有效数据问题3个+,均是因为本地事务回滚导致的数据不一致的场景
- 收尾工作
- 完成【上线开关】切换,只读、写新库,完成整体平滑迁移。在无QA参与前提下,验证期间未出现过数据丢失、重复、错误等异常
- 切换完成后,老库老表和DRC同步任务依旧保留了一周的时间,防止出现场景遗漏,产生数据丢失
- 46亿行大表清理,采用drop+create的方式实现效率、稳定性更高,在业务低峰期完成脚本执行,大概花费10秒的时间,容器负载、内存等指标正常。但是当时碰上了DBA的备份任务,导致有一个从库主从延迟升高,这个后续需要注意
成果
- 采购系统订单实时库磁盘容量减少1.3T,占用比率从85%下降到63%,结合已有数据归档程序,可以支撑未来三年的业务发展
- 由于历史原因,先前lifecycle有21亿冷数据存储在另外一个大规格JED集群,也一并完成读、写流量摘除,预计2024Q1完成下线,届时会节省800C+、内存2T+、磁盘35T+的容器资源






